基于網頁瀏覽內容的心理健康預測模型的研究
2019-06-06 03:22:40蔡偉鴻劉健全
汕頭大學學報(自然科學版) 2019年2期
蔡偉鴻,胡 江,劉健全,杜 鑫
(1.汕頭大學工學院計算機系,廣東 汕頭 515063;2.日本NEC 公司,日本 東京 211-8666)
0 引言
隨著社會的發展和科技的進步,人們的生活水平得到了極大的提高,身體健康已不再是制約個人發展的主要因素,而和人們密切相關的另一個因素:心理健康[1],逐漸浮現出來,成為了社會關注和研究的新焦點.心理問題在嚴重的情況下會導致精神障礙,進而對個體健康和社會穩定產生消極影響[2].有研究表明,心理問題會對個體的主觀幸福感造成不利影響[3],導致情感失衡和對生活的滿意度下降.另外,心理健康與身體健康之間存在著千絲萬縷的聯系[4],與一般人群相比,存在心理問題的個體的身體健康更容易出現問題[5],患有精神障礙的人群的慢性病的發病率和死亡率均高于一般人群[6].同時,心理問題也是導致人群“失能”的主要原因[7],到2020年有很大可能會成為僅次于HIV 的社會疾病負擔[7].據調查,心理問題在我國人群中的覆蓋率已經達到了17.5%[8].在中國,心理治療非常昂貴而且繁瑣,大量的精神障礙患者因為得不到有效的治療而不得不忍受病痛帶來的折磨,所以,做好有效的心理健康問題預防工作是非常迫切和必要的.
1 背景知識及相關工作
1.1 背景知識
通常,需要先獲取個體的心理狀態才能對其提供合適的心理健康服務,獲取心理狀態的方法之一就是進行“心理狀態評估”.但是,心理狀態具有內隱性,不能被直接觀察到,比如嫉妒心理產生時大都不為主體所察覺,具有明顯的內隱性[9],因此必須先將心理狀態外顯化和形象化才能進行下一步的心理狀態評估,簡單來說,就是通過設定一些合適的外顯指標來進行間接的測量,這種方法就是心理測量.目前主流的心理測量技術是心理測評量表(如圖1),因其在問卷編制、施測操作和結果統計等方面所具有的客觀性、高效性和量化性,已經獲得了在心理測量領域的廣泛臨床應用.但是,心理測評量表的測量結果的準確性會受到個體主觀意識的影響,因為個體在填寫量表時,既是“被觀察個體”,又是“觀察主體”,其回答會不可避免地受到其認知能力和社會虛榮心理的影響.為了克服心理測評量表存在的缺陷,本文提出利用用戶的網頁瀏覽內容作為外顯指標來預測其心理狀態(如圖2),從用戶的網頁瀏覽內容中提取出相關特征,進而訓練出心理健康預測模型.

圖1 傳統心理健康測量方法

圖2 本文提出的心理健康測量方法
1.2 相關工作
心理健康和身體健康缺一不可,都是主體健康的必要條件.隨著互聯網的發展與應用,網絡行為逐漸成為主體行為的重要組成部分,能夠作為主體心理狀態的外顯指標,反映出主體的一部分內心世界.所以,將網絡行為用于心理狀態預測,是非常具有前景的研究方向.目前,國內外已經有學者和機構開始著手于網絡行為與心理狀態之間關系的研究,并取得了一些成果.王麗等人將神經網絡技術用于預測研究生這一群體的心理健康狀況[10],取得了較好的預測效果,在一定程度上為我國高校心理教育工作提供了有價值的研究成果,為高校完善心理教育工作提供了幫助.張磊等人通過分析中國龐大的社交網絡,利用個體樣本的主體特征和動態詞典特征提取方法實現了對社交網絡用戶的心理指標的預測,找出了社交網絡特征與心理指標之間的關系[11],更新了國內心理指標預測的記錄.田瑋等人采用深度學習技術對微博用戶作出自殺風險預測,實驗結果表明,基于深度學習的算法模型可以有效地對微博用戶的自殺風險進行預測,為自殺預防工作開辟了新的方向[12].朱廷劭等人通過對用戶的網絡行為進行時頻分析來預測其抑郁狀況[13],實驗結果表明,用戶的網絡行為的時頻特征能夠有效地反映用戶心理健康狀況的變化,有助于公共心理健康服務的廣泛提供.郝碧波等人使用半監督學習的方法來預測社交網絡用戶的人格[14],實驗結果表明,使用未標記數據可以提高預測的準確性,促進心理學人格研究的發展.朱廷劭等人發現用戶的智能手機使用行為與其主觀幸福感之間存在一定的聯系[15],基于這些研究結果,他們利用智能手機的使用行為訓練了主觀幸福感的預測模型,實驗結果表明,利用采集到的用戶智能手機的使用瀏覽記錄可以較好地預測其主觀幸福感.郝碧波等人提出利用用戶新浪微博的使用行為來衡量其大五人格[16],通過使用多任務回歸算法和增量回歸算法來預測在線行為中的大五人格.實驗結果表明,通過用戶的新浪微博使用行為可以對其大五人格進行預測.朱廷劭等人通過建立決策樹模型來找出網絡用戶的網絡行為與其心理健康狀態之間的關系[17],實驗結果表明,預測模型的準確率和召回率表現良好.此外,朱廷劭等人將機器學習應用于認知行為治療過程,開發了一套心理健康自助系統.通過對隨機用戶進行比對調查,實驗結果表明,這套系統可以有效地緩解用戶的抑郁癥[18].再者,朱廷劭等人提出利用用戶看過的文章內容來預測其情緒,開發了一個帶有可選加權系數的情感字典,并且訓練了支持向量機模型和樸素貝葉斯模型,實驗結果表明,預測模型的準確率、召回率表現良好[19].
通過對以上的工作進行詳細調研,我們可以得到如下結論:
1.網絡行為與心理狀態顯著性相關,網絡行為能夠用于預測心理狀態;
2.國內外關于將網絡行為用于心理健康預測的研究較少,并且截至目前還沒有將網頁瀏覽內容用于心理健康預測的相關研究;
3.很多研究收集網絡行為的形式都是問卷調查,無法獲得更加詳實的用戶的網絡訪問記錄,這更凸顯出了本文的工作意義.
網頁瀏覽內容是網絡行為的一種內容載體,能夠用于心理狀態的預測,而且比一般性的網絡行為更加具體和可信.所以,利用用戶的網絡行為預測其心理狀態是可行的.
2 心理健康預測模型
在本章節中,我們提出了自己的心理健康預測模型,介紹了它的原理和涉及到的算法應用.構建的模型流程可以分為數據收集、數據處理、模型訓練、模型評估,具體流程如圖3 所示.
2.1 模型的原理
在Brunswik 提出的“透鏡模型”理論中指出,個體的周邊環境中會包含有一些能夠預示該個體精神狀態的信息線索[20],這些信息線索可以看作是不同場景下的“行為殘余”[21].用戶的網絡訪問歷史會被記錄在訪問控制系統的日志中,這些日志數據是客觀而且準確的,可以從中獲取更加精準和客觀的用戶網絡行為數據.通過這種方式,不僅可以充分利用互聯網的普及性和便利性進行大范圍的數據采集,而且能夠解決心理測評量表的測量結果會受到個體主觀意識影響的問題.
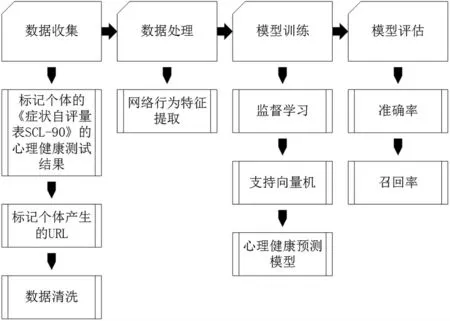
圖3 心理健康預測模型構建流程
正是因為個體的網絡行為是其在互聯網上的行為殘余,并且也屬于人類行為總體的一部分,所以可以利用個體樣本的網絡行為作為外顯指標來推測其心理狀態.但是目前并沒有一套公認的網絡行為分類方法,由于本模型只需要能夠顯著反映心理健康狀態的網絡行為,為了使對心理健康的預測更加準確,所以用戶的網頁瀏覽內容這一網絡行為在模型的原理中顯的格外重要.
2.2 模型訓練和評估
《癥狀自評量表SCL-90》是目前世界上最出名的心理健康測評量表之一,該量表共有90 個項目,包含有較為廣泛的精神病癥學內容,這90 個項目包含9 個因子,分別是軀體化(somatization)、強迫癥狀(obsessive-compulsive)、人際關系敏感(interpersonal sensitivity)、抑郁(depression)、焦慮(anxiety)、敵對(hostility)、恐怖(phobic anxiety)、偏執(paranoid ideation)及精神病性(psychoticism)。
本文利用機器學習中的監督學習方式,采用支持向量機建立了一個關于心理健康狀態的分類模型.這種模型是一種典型的二類分類模型,它的定義域和函數的表示如下:
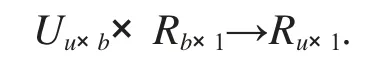
U是標記個體樣本的網絡行為特征矩陣,P 是標記個體樣本的心理健康狀態矩陣,R 是一個能夠揭示標記個體的網絡行為特征和心理健康狀態之間潛在映射關系的投影矩陣.每個用戶的網絡行為特征是一個b 維的特征向量,定義為《癥狀自評量表SCL-90》某個因子下的項目個數.如果我們能夠收集到標記個體樣本的網絡行為特征,就能建立起U;如果我們能夠收集到標記樣本的《癥狀自評量表SCL-90》的測評結果,就能建立起P.當U 和P 都建立好之后,就能建立起在心理健康預測模型中能夠預測心理健康狀態的關鍵的R.為了能夠得到最優的R,我們定義了如下對象函數:
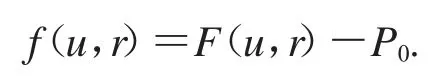
P0是《癥狀自評量表SCL-90》的測試結果,r是投影矩陣,本文的任務就是找到一個能夠最小化f的r:
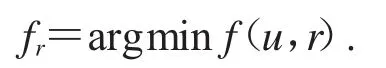
這種二類分類模型對應的評價指標被設定為精確率(precision)和召回率(recall).

表1 混淆矩陣
表1 所示的矩陣是一個二類分類模型的混淆矩陣(confusion matrix).混淆矩陣是數據科學、數據分析和機器學習中總結分類模型預測結果的情形分析表,以矩陣的形式將數據集中的記錄按照真實的類別與分類模型作出的分類判斷進行匯總,是對分類模型進行性能評價的重要工具.計算精確率和召回率需要用到4 個數值,它們分別是真陽值tp(true positive)、假陽值fp(false positive)、真陰值tn(true negative)和假陰值fn(false negative),這4 個數值的總和是樣本集中樣本的總數,即tp+fp+tn+fn=n,n 是樣本的總數.
精確率衡量的是模型預測結果的精確度,對于一個二類分類模型,分為positive 類和negative 類,可以分別計算它們的精確率,計算公式如下:

召回率衡量的是樣本集中樣本被成功預測出的比率,positive 類和negative 類的召回率計算公式如下:

模型的準確率計算公式如下:
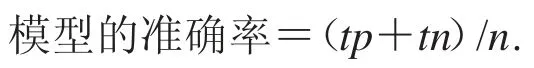
3 模型的實現
根據上文中的內容,我們根據理論模型搭建起了一整套系統,并對模型進行了實驗和評估.在這節中詳細介紹了兩部分內容:1.模型實現的步驟和遇到的問題;2.將不同的算法進行對比,對它們的預測效果進行評估.
具體來說,首先需要收集模型建立過程中所需要的原始數據并進行數據清洗以達到實驗標準,這一過程會利用現有技術和設備實現.其次,結合網絡行為指標體系[22]從處理好的數據中提取出網絡行為特征.接著,采用機器學習中的監督學習方式并利用支持向量機建立起基于網頁瀏覽內容的心理健康預測模型.最后,結合現有預測模型的評價指標對基于網頁瀏覽內容的心理健康預測模型的性能進行評估.
3.1 數據收集
本次實驗中的樣本數據收集來自課題組的80 位成員,62 位作為訓練樣本,18 位作為測試樣本,實驗周期為一年,從2016年1月1日至2017年1月1日.在實驗周期內,收集了樣本個人的上網記錄,并標記了每個人的上網行為,對所有的數據進行脫敏,通過替代法去除隱私信息.最后,在這些完成后對他們進行《癥狀自評量表SCL-90》測試.需要注意的是,在這個過程中,我們計算統計出該標記樣本在每一個因子下的得分,如圖4 所示.
接下來需要獲取標記樣本產生的URL.為了獲取標記樣本在網絡訪問過程中產生的URL,需要在訪問控制系統中部署網絡流量監測設備,能夠收集所有流經網關的數據包.網關是標記樣本與互聯網之間連接的關口,標記樣本產生的所有網絡訪問請求都必須經過網關才能訪問互聯網.課題組所在實驗室的網關處部署了一套訪問控制系統,其中的網絡流量監測設備會記錄下所有的網絡訪問行為.該網絡流量監測設備記錄的網絡訪問行為日志較為詳細,有用戶ID、組名、源IP、終端類型、位置、目標IP、網站分類、標題、訪問域名、URL 地址、時間,收集到的數據即刻利用替代法進行脫敏.
當網絡流量監控設備截獲到標記樣本產生的數據包后,通過分析這些數據包的結構,解析出其中的URL,如圖5 所示.
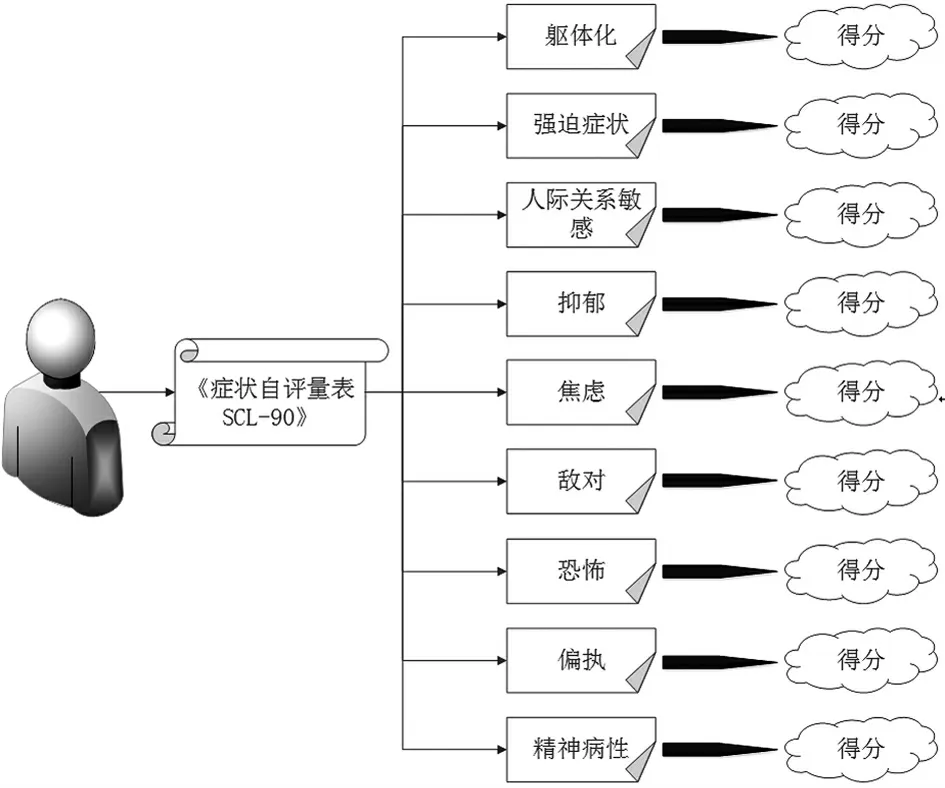
圖4 獲取標記個體的《癥狀自評量表SCL-90》的測量結果
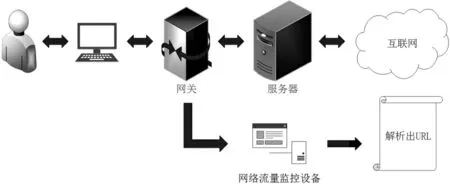
圖5 獲取標記個體產生的URL
在獲取到某個標記樣本產生的URL 之后,需要對URL 進行過濾和清理.因為不是所有的URL 都指向包含內容的HTML 文件,而且也有可能存在URL 重復的情況,所以有必要進行數據清理.首先去除重復和冗余的URL,然后清理掉指向非HTML 文件的URL.這一過程可以通過爬蟲框架Scrapy 完成,使用的過濾規則如表2 所示.

表2 URL地址清理類別
3.2 數據處理
在這一個階段,本文結合現有網絡行為指標體系[22]和網絡行為研究成果[23],從標記樣本產生的網頁URL 對應的網頁瀏覽內容當中提取出標記樣本的網絡行為特征,即需要從這些網頁瀏覽內容當中抽象出具有一般性和代表性的網絡行為特征,提取流程如圖6 所示.
Elasticsearch 是一個開源的全文搜索引擎框架,提供分布式多用戶能力,可以快速地存儲、搜索和分析海量數據.本文以標記個體訪問的網頁URL 作為源數據,使用Elasticsearch 即可得到屬于該標記樣本的搜索引擎實例,具體流程如圖7 所示.
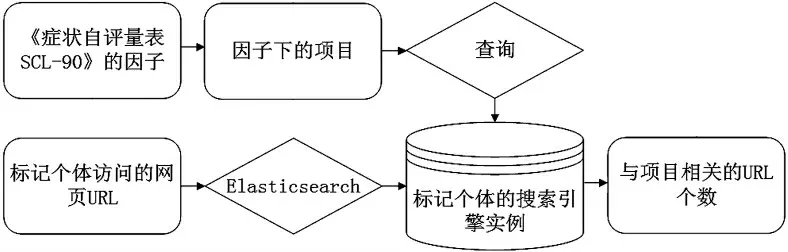
圖6 網絡行為特征提取流程

圖7 標記樣本的搜索引擎實例構建流程
《癥狀自評量表SCL-90》有9 個因子,每個因子下有一系列項目.標記樣本的搜索引擎實例構建完成之后,在標記樣本的搜索引擎實例中查詢某個項目,得到與該項目相關的URL 個數,作為標記樣本的網頁瀏覽內容特征數據.具體流程如圖8 所示.

圖8 標記樣本的網頁瀏覽內容特征數據獲取流程
例如,在“軀體化”因子下,有“頭痛”、“頭暈和昏倒”、“胸痛”、“腰痛”、“惡心或胃部不舒服”、“肌肉酸痛”、“呼吸有困難”、“一陣陣發冷或發熱”、“身體發麻或刺痛”、“喉嚨有梗塞感”、“感到身體的某一部分軟弱無力”和“感到手腳發重”這12 個項目,以某個項目作為查詢,在標記樣本的搜索引擎實例中進行查找,得到與該項目相關的URL 個數,如圖9 所示,實際結果如表3 所示.
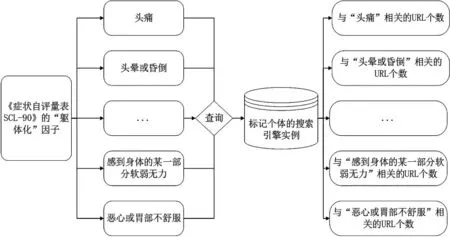
圖9 網絡行為特征獲取流程示例

表3 “軀體化”因子下所有標記個體的網絡行為特征
通過相同的方法,我們統計得出了“強迫癥狀”、“人際關系敏感”、“抑郁”、“焦慮”、“敵對”、“恐怖”、“偏執”及“精神病性”共8 種網絡行為特征.
3.3 心理健康預測模型的建立
我們已經建立了數據基礎,接下來是構建心理健康預測系統的詳細步驟.相關原理已經在上文中有了充分的闡述.在接下來的系統建立中,主要工作是對標記樣本的《癥狀自評量表SCL-90》的測評成績進行處理.
進行這種處理的根據來源于心理學.研究表明心理狀態是一個連續變化的過程,人群中的大部分個體的心理健康狀態是穩定和積極的,相鄰區間的差異較小.本文實驗關注的目標是那些有可能存在心理健康問題的人群,為了盡可能地篩選出這部分人群,在心理測量學中,公認的測量方法是將所有被測試樣本的心理測評量表的得分情況劃分為高分組和低分組,即極端健康的樣本組和極端不健康的樣本組,希望能夠通過這種劃分找出顯著的心理狀態特征,高分組的樣本有很大可能存在心理健康問題,低分組的樣本存在心理健康問題的可能性較小.本文的實驗即采取了這種劃分方法.
首先,在每個因子下,根據標記樣本的得分進行排序.然后,在每個因子下,根據排序結果,取前27%的標記樣本作為低分組,用標簽“-1”代表,取后27%的標記樣本作為高分組,用標簽“+1”代表.最后,利用之前收集好的每個因子下的標記樣本的網絡行為特征,再結合每個因子下的標記樣本的分組結果,就得到了可用于模型訓練的支撐數據,如表4 所示.

表4 “軀體化”因子下的訓練數據
在得到每個因子下的訓練數據之后,使用支持向量機為9 個因子分別建立了預測模型,這9 個預測模型相互獨立.其中,模型訓練所使用的程序來自LIBSVM,訓練過程中使用的核函數是RBF(Radial Basis Function),并進行了相關參數調優,每個因子下的預測模型的參數如表5 所示.

表5 每個因子下的預測模型訓練時所使用的參數
通過以上這種形式,該實驗建立了成型的系統,區分出了研究樣本的具體參數的不同,并得到了每個對象心理健康的預測結果.
3.4 心理健康預測模型的評估
為了體現該模型的實用性和準確性,我們將本模型中使用的支持向量機與隨機森林、樸素貝葉斯這兩種傳統機器學習算法進行了詳細對比.它們都在9 個因子上進行了預測,并進行了5 折交叉驗證,分別從模型準確率(如圖10)與高分組召回率(如圖11)進行了對照.
通過實驗結果對比,可以得到使用支持向量機建立的預測模型的準確率平均值為89.39%,而使用隨機森林和樸素貝葉斯建立的預測模型的準確率平均值分別為87.21%和82.28%.特別是支持向量機在“焦慮”因子下建立的預測模型的準確率最高,達到了95.01%,并且其高分組召回率也最高,達到了95.62%,反映出它可以很好地召回“焦慮”因子下的高分組人群.另一方面,使用支持向量機建立的預測模型的高分組召回率平均值為88.19%,而使用隨機森林和樸素貝葉斯建立的預測模型的高分組召回率平均值分別為85.57%和81.13%.
綜上可以得出,在本次實驗的環境下,使用支持向量機建立的模型的預測效果整體上遠優于使用隨機森林和樸素貝葉斯建立的模型的預測效果.這種評估結果充分說明了本文中選擇的機器學習算法的創新性和實用性.
4 結語
本文使用支持向量機分別為《癥狀自評量表SCL-90》的9 個因子建立了基于網頁瀏覽內容的心理健康預測模型.在給出理論基礎的前提下,設計出了區別于傳統方式的心理健康模型.不僅如此,為了驗證模型的可行性和準確性,本文展開了一系列具體的實驗和結果評估,最終得到了良好的實驗效果,充分說明本文提出的方法模型能夠在一定程度上替代傳統的心理測評量表,為心理衛生事業的發展提供幫助.
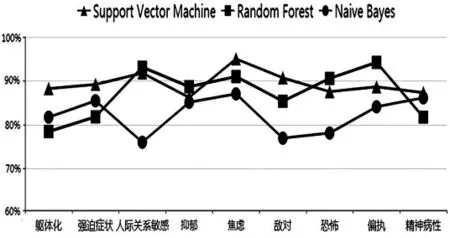
圖10 模型準確率對比結果
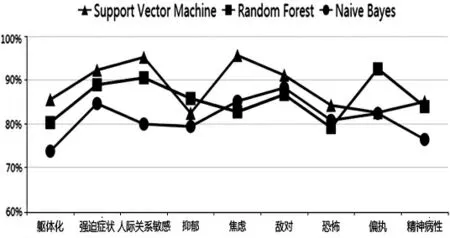
圖11 高分組召回率對比結果
雖然本文提出的模型取得了一些創造性的發現和效果,但仍然存在一些可以改進的地方,比如采取更加高效的機器學習算法來訓練更加準確的心理健康預測模型;研究如何提取更加準確和有效的網絡行為特征等.
猜你喜歡
光明少年(2024年5期)2024-05-31 10:25:59
當代陜西(2022年4期)2022-04-19 12:08:54
品牌研究(2022年9期)2022-04-06 02:41:56
品牌研究(2022年8期)2022-03-23 06:49:06
品牌研究(2022年6期)2022-03-23 05:25:50
品牌研究(2022年1期)2022-03-18 02:01:10
娃娃畫報(2019年11期)2019-12-20 08:39:45
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
