基于深度卷積神經網絡的柑橘目標識別方法
2019-06-04 01:10:54陳俊文
農業機械學報 2019年5期
畢 松 高 峰 陳俊文 張 潞
(北方工業大學電氣與控制工程學院, 北京 100041)
0 引言
我國為世界上重要的水果生產國之一,自2012年以來,我國柑橘、蘋果等主要水果品種的種植面積和產量已居世界第一。2017年,我國柑橘產量為3 816.78萬t[1],占世界柑橘產量的四分之一。采摘是水果生產過程中勞動力投入最大的作業環節,柑橘采摘勞動量為整個生產過程工作量的50%~70%,所處環境的復雜性導致水果采摘仍然以人工作業為主[2]。水果自動化采摘對于解決勞動力不足、保證水果適時采摘、提高采摘品質和市場競爭力等具有重要意義。因此,研究水果自動化采摘技術迫在眉睫[3]。
柑橘目標識別是自動采摘的基礎,眾多研究者主要從顏色、紋理、邊緣等多個特征綜合角度出發,研究了限定環境下或自然環境下果實目標識別方法[4-17]。利用多種分類和聚類算法設計目標識別模型,獲得了較好的目標檢測效果。但上述方法的基礎是從果實自身特征出發獲得圖像特征,當存在光線變化、陰影覆蓋、著色不均、枝葉遮擋和果實重疊等多種自然采摘環境下常見干擾因素時,果實特征發生明顯變化,使得用于描述果實的特征也出現明顯的不同,因此基于圖像特征的柑橘識別方法在自然環境下檢測效果不理想。
自然環境下柑橘圖像的特征在不同干擾因素下具有明顯的差異。自然環境下干擾因素較多且變化較大,難以獲得涵蓋上述所有干擾情形的柑橘目標特征,因此基于圖像分析的柑橘目標識別方法難以應對自然環境下多種干擾因素同時存在的情況。
針對戶外柑橘采摘機器人的目標識別定位問題,本文設計基于深度卷積神經網絡的自然環境下柑橘目標識別模型。對實際采收環境下的柑橘目標進行數據測試。
1 柑橘目標識別方法
基于圖像的柑橘目標識別的基礎在于獲得可穩定描述自然環境下柑橘目標的圖像特征,而大部分傳統的目標特征提取方法都是在提取目標物體的淺層特征,如HOG特征、SIFT特征、顏色特征、局部二值特征等。這些人工設計的特征只適用于某些特定場景,復雜場景中表現的并不盡如人意,致使構建的目標識別模型難以滿足復雜田間場景的需求,檢測效果很不穩定。深度學習模型具有模型層次深、特征表達能力強的特點,能自適應地從大規模數據集中學習當前任務所需要的特征表達[18],在目標識別領域,盧宏濤等[19]認為使用深度學習方法提取到的特征具有傳統手工特征所不具備的重要特性,其通過逐層訓練學習,最終得到蘊涵清晰語義信息的特征表示,從而大大提高識別率。自然采摘環境的干擾因素多是典型的復雜場景,目標隨環境干擾因素變化而難以獲得完備的目標特征集,基于深度卷積神經網絡模型的柑橘目標視覺識別方法,可以克服自然環境下的多種干擾條件影響,獲得較高的識別準確性和穩定性。
基于深度卷積神經網絡的柑橘識別模型主要分為圖像預處理模塊、深度特征提取模塊、特征處理模塊。柑橘識別模型結構如圖1所示。

圖1 自然環境下的柑橘識別模型網絡結構Fig.1 Network structure diagram of citrus recognition system in natural environment
圖像預處理模塊對圖像進行降噪和數據擴展等操作,調節圖像的色調、飽和度和亮度后,圖像在輸入網絡之前進行預處理,尺寸縮放到416像素×416像素。深度特征提取模塊實現了基于DARKNET19網絡[20]的卷積池化構建方法,提取完整圖像的高階特征,經過卷積池化層后得到13×13特征圖。
特征處理模塊分為區域生成網絡模塊(Region proposal network,RPN)和預測框特征提取分類模塊。特征處理模塊通過多個交叉的卷積層對特征降維,并利用池化操作提取柑橘圖像的高階特征,進而對特征進行分類。區域生成網絡模塊利用錨框(Anchor boxes)方法在獲得的特征圖上預測初始預選框。利于K均值聚類(K-means clustering)算法求取錨框參數并預測出錨框尺寸和比例,K是聚類算法將樣本集劃分成簇的數量,實驗測得K=5時錨框預測的正確率最高。深度特征提取模塊中,圖像經過卷積池化層后,特征圖維數為13×13。對特征圖的每個網格按照預測出的比例劃出5個錨框(以圖1中13×13特征圖的第1行第1列網格為例,網格(1,1)表示該網格)并將這5個錨框映射回原圖得到初始預選框。預測框特征提取分類模塊的結構基于DARKNET19網絡,在網絡訓練階段移除DARKNET19網絡最后一個卷積層,增加3個3×3×1 024的卷積層,并且在后面與1個1×1×512的卷積層和2個1×1×30的卷積層交叉,從而提高模型的特征抽取能力。由于經過多層卷積后特征向量的維度大幅增高,不利于數據分類與訓練收斂,加大了網絡的訓練和預測時間,因此設計3層3×3卷積層和3層1×1卷積層交叉結構對特征降維,從而降低其深度以提高系統的訓練效率與實時性。
將提取到的圖像特征全局平均池化,并將其輸入到Softmax層進行分類得出預測結果。預測結果包含6個元素:對應網格的偏移量x和y、預測出的柑橘目標邊界框的寬度w和高度h、有無目標置信度(Box confidence score)和柑橘目標置信度。有無目標置信度表示該目標框包含柑橘目標的可能性,柑橘目標置信度表示如果包含柑橘目標,則該目標是柑橘的可能性,因此預測結果維度為(13,13,5×(4+1+C)),其中C是目標類別。由于只需檢測柑橘,因此C=1,預測結果的維度即為(13,13,30)。本文在訓練階段利用Softmax分類器將輸出數值與標簽數據比較得到其總損失,進而使用隨機梯度下降(Stochastic gradient descent, SGD)優化損失函數使其收斂。在檢測階段,每個組合的結果分別是預選框位置相對于標簽位置偏移量,有目標的置信度、以及有某個指定目標的置信度,柑橘識別模型只需要柑橘置信度,因此只有一類。
2 基于遷移學習的網絡初始化
遷移學習利用預先訓練好的具有良好學習能力的網絡模型參數初始化某個小型訓練集模型參數,這種參數初始化方法可以將已學習的知識能力遷移到另一個網絡中,使得新網絡具有快速學習能力[21],從而顯著改善因訓練數據集不足帶來的網絡過擬合問題,增加識別模型在復雜自然條件下柑橘目標識別的泛化能力。
ImageNet數據集是目前圖像深度學習領域應用較廣的數據集,與圖像分類、定位、檢測相關的工作大多基于此數據集展開,成為目前深度學習圖像領域算法性能檢驗的“標準”數據集。本文使用標準ImageNet1000類數據集預訓練柑橘識別模型。對于每個網格5個預選框給出的30個數值,每個目標只需要一個預選框預測器,根據預測區域與標簽區域之間的重疊比例(IOU)最高值確定預測目標,從而使預測器更好地適應柑橘識別任務,從而改善整體召回率。訓練期間的損失函數(Loss function)包含位置誤差和分類誤差。
若目標存在于該網格單元中,則損失函數僅懲罰分類錯誤;若預測器負責實際邊界框,則也懲罰邊界框坐標錯誤。網絡更加重視預測到目標的預測框,加入預測到目標的預測框系數λcoord來提高其數值占比。在VOC2007數據集下,這一數值為5,相應的,對于沒有檢測到目標的預測框,加入未預測到目標的預測框系數λnoobj來降低其數值占比,本文取0.5。在訓練過程中,通過優化算法使得Loss函數收斂到最小。在預測階段,由于網格設計強化了邊界框預測中的空間多樣性,一些較大或靠近多個網格單元邊界的目標可能會被多個網格單元定位,因此本文使用非極大值抑制算法[22]來修正多重檢測,從而獲得準確的識別結果。
3 遷移學習結果與分析
3.1 實驗設計
為保證數據集能夠較好地反映自然環境下柑橘目標的真實特點,在廣西合浦柑橘種植園拍攝了1 200幅柑橘樣本圖像,拍攝時間包括晴天正午、晴天傍晚以及陰天正午3個時段。選用Basler acA2440-20gc型工業相機采集圖像數據,采用焦距為8 mm的定焦鏡頭。經過人工挑選后制作了包括1 000幅柑橘圖像的VOC2007格式的數據集。為保證訓練集的有效性,訓練集中包含光照不均圖像241幅、前背景相似圖像134幅、果實以及枝葉相互遮擋圖像246幅、陰影覆蓋圖像211幅、過曝圖像168幅。將1 000幅圖像按照訓練集、測試集、驗證集7∶2∶1的比例配置。以端到端訓練方式對上述訓練集進行訓練,并計算平均損失率和在全體測試集和驗證集上的平均準確率(Mean average precision,MAP)。
同時為了驗證本文方法的有效性,將可變性部件模型[23](Deformable part model,DPM)與本文模型進行對比測試。DPM算法提取目標的HOG特征,并使用支持向量機分類器,源碼版本選擇voc-release 4.01,訓練50 000次,數據集依然采用VOC2007格式,按照訓練集、測試集7∶3的配置分配訓練。
3.2 實驗數據性能指標計算方法
本文方法和DPM算法均使用VOC2007格式數據集和P-R曲線測試網絡性能。P-R曲線的數據插值方法使用VOC2007規范,即11點插值法(Eleven-point interpolation)。對于網絡檢測出來的目標,定為Positive樣本,未檢測出來的目標定為Negative樣本。采用0.5為IOU閾值,大于0.5的認定為檢測正確,檢測結果為T;反之,則為檢測錯誤,檢測結果為F。故實驗結果有4種,分別為檢測出來的IOU值小于等于0.5的目標FP、檢測出來的IOU值大于0.5的目標TP、未檢測出來的真值目標FN、TN。本文不統計TN類樣本。準確率(Precision)的計算方法為
(1)
式中TP——檢測出來的IOU值大于0.5的目標數量
FP——檢測出來的IOU值小于等于0.5的目標數量
召回率(Recall)為識別出的柑橘數占圖像中總目標數的比例,其計算方法為
(2)
式中FN——未檢測出來的真值目標數量
3.3 結果分析
遷移學習具有良好的泛化能力且具有良好的抑制過擬合能力,本文利用遷移學習和非遷移學習訓練柑橘目標識別模型,訓練損失如圖2所示。
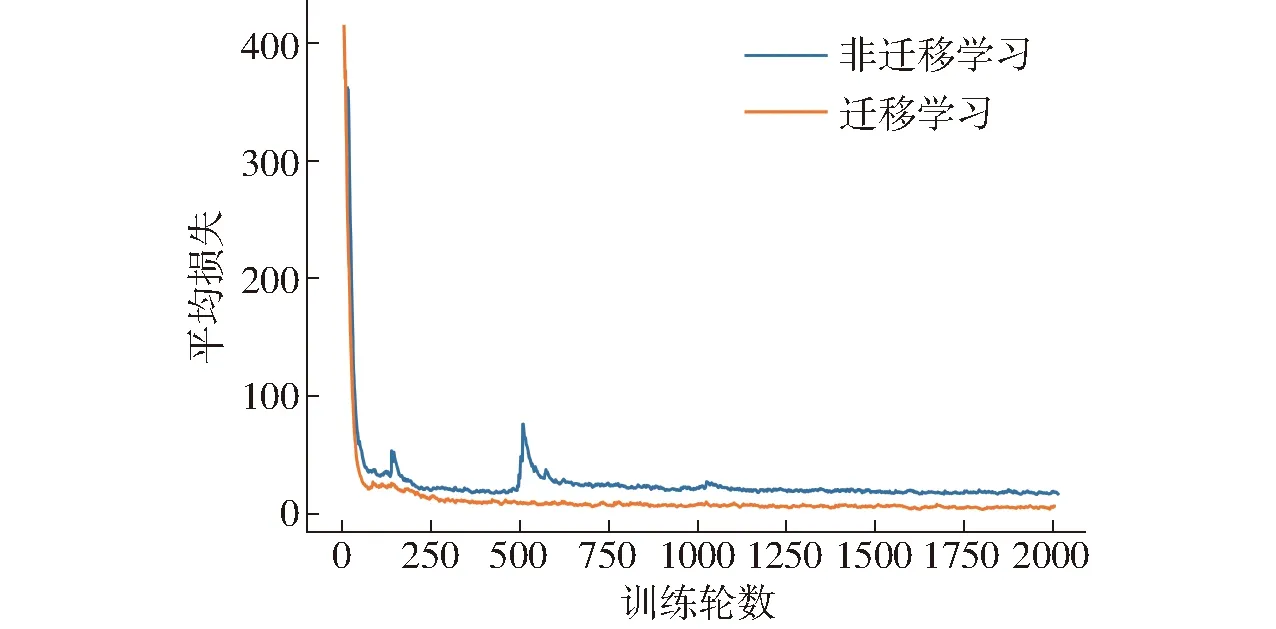
圖2 遷移學習與非遷移學習方法訓練損失Fig.2 Training loss of transfer learning and non-transfer learning methods
從圖2可知,遷移學習可以使得訓練過程更加平滑,在相同訓練輪數下,其平均損失遠低于未使用遷移學習。訓練結束后,遷移學習在召回率大于后者的情況下,依然可以取得更好的平均準確率。兩種訓練方法的參數如表1所示。
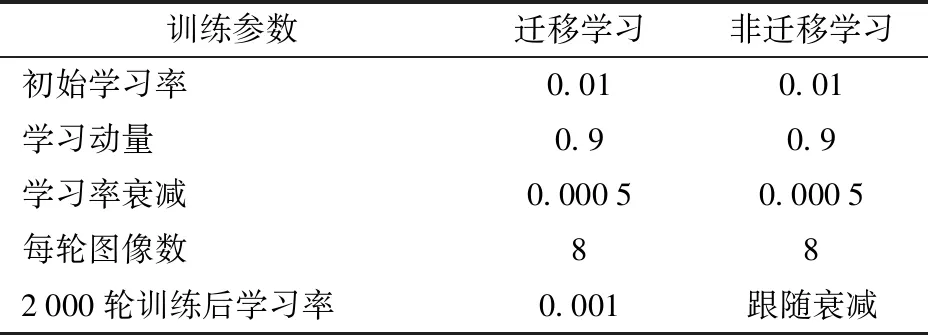
表1 遷移學習與非遷移學習訓練參數Tab.1 Training parameters of transfer learning and non-transfer learning methods
遷移學習與非遷移學習方法的基本訓練參數相同,初始學習率取0.01,動量為0.9,學習衰減率為0.000 5,每輪訓練圖像數量為8。2 000輪訓練后,遷移學習的學習率固定,陷入局部最優。未使用遷移學習的網絡在達到局部最優后,即使降低學習率也并不能使得網絡平均損失率明顯下降。遷移學習和非遷移學習訓練方法的平均損失、最大召回率和平均準確率如表2所示。

表2 遷移學習與非遷移學習訓練結果Tab.2 Training results of transfer learning and non-transfer learning methods
由表2可知,非遷移學習訓練的柑橘目標識別模型獲得的平均損失為20.5,本文通過降低學習率的方法使得平均損失下降了12.8,最終平均損失達到了7.7。訓練結束后,在驗證、測試數據集上計算平均準確率,分別為86.9%和78.3%。基于遷移學習方法訓練的模型平均損失較低,平均準確率較高,有效提高了模型的性能。
使用遷移學習和未使用遷移學習訓練模型的柑橘目標檢測結果如圖3所示。

圖3 遷移學習和非遷移學習訓練模型檢測結果Fig.3 Test results of transfer learning and non-transfer learning methods
圖3a中標號1的結果將兩個識別條件良好的柑橘識別成了一個,而且還存在目標框重疊問題,標號2結果將兩個相互重疊的柑橘識別成一個目標。作為對比,圖3b中標號1、2的檢測結果都能正確區分并識別柑橘,并且圖3b識別出了更多的柑橘,可以看出遷移學習的檢測系統具有更高的召回率。由圖3可知,兩種訓練方法都識別出柑橘目標,但常規訓練下的網絡識別出的柑橘目標框存在較大的誤差與較低的召回率。由此可知遷移學習可以提高網絡的目標檢測性能。
DPM算法是目前常用目標檢測算法之一。DPM算法與本文方法在自然采摘環境下柑橘目標識別的P-R曲線如圖4所示。測試集和驗證集共包含300幅圖像,包括光照不均、前背景相似、果實以及枝葉相互遮擋、陰影覆蓋、過曝。

圖4 兩種方法的P-R曲線Fig.4 P-R curves of two methods
圖4a中DPM算法的P-R曲線平均準確率為67.56%,遠低于本文方法的86.91%。本文方法較DPM算法具有更高的召回率,且P-R曲線較DPM算法曲線更加平滑穩定,在較高召回率情況下,依舊可以保持較高的準確率。以人工進行柑橘目標識別標注的結果為標準,在不同干擾因素下,DPM算法與本文方法的識別平均準確率對比如表3所示。
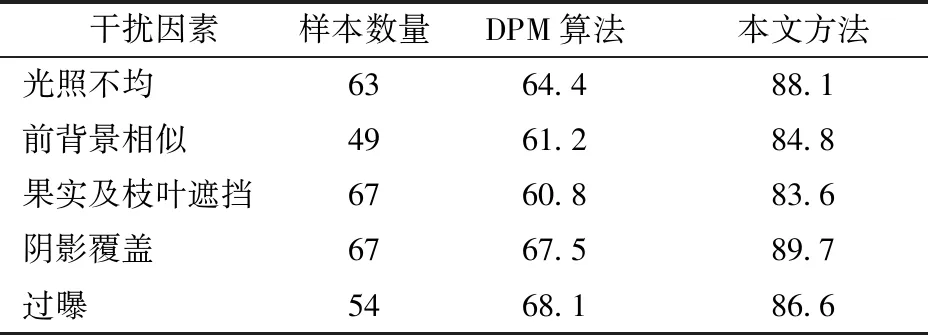
表3 DPM算法與本文方法識別平均準確率對比Tab.3 Experimental result of citrus using DPM and proposed method %
從表3可知,DPM算法的準確率遠低于本文方法。針對果實與枝葉遮擋條件,評估所用數據集包含67幅存在果實與枝葉遮擋的圖像,遮擋率的計算方法為67幅遮擋圖中被遮擋柑橘的遮擋面積占其總面積的比率均值,經統計,平均遮擋率為48%,DPM算法檢測的準確率只有60.8%,而本文方法準確率為83.6%。同時,本文方法在表3的多個影響因素下的識別平均準確率的均值為86.6%。
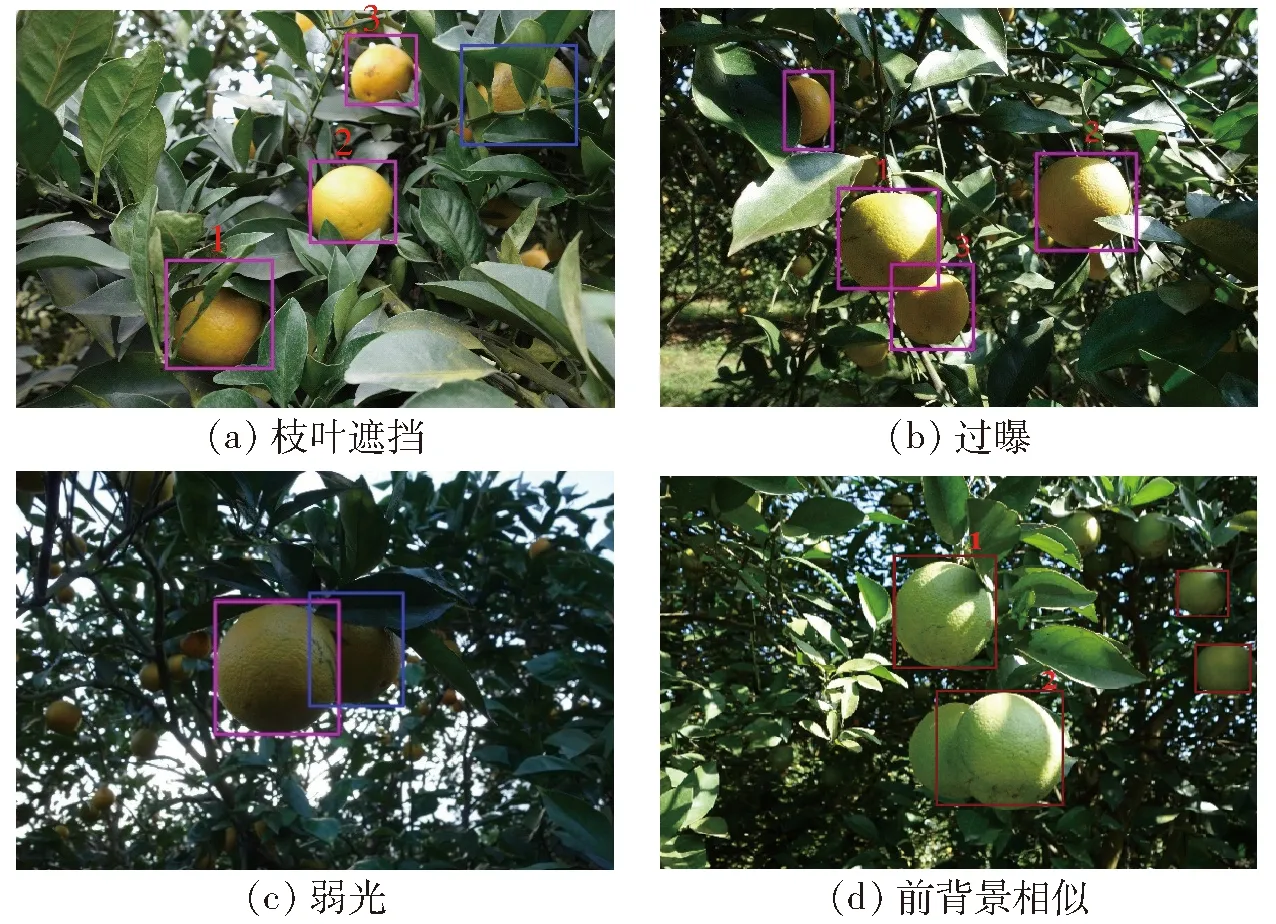
圖5 本文方法對自然條件下柑橘目標識別結果Fig.5 Detecting results of citrus by proposed method under natural conditions
本文方法的目標識別結果如圖5所示。圖5a中,枝葉遮擋面積小于50%(圖中標號1、2、3),其IOU值分別為0.8、0.95、0.9。但如果遮擋面積過大,則依舊無法成功識別(圖中藍框)。藍框中的柑橘具有標簽值,但未被識別,相當于IOU值為0,分類結果為FN。其他情形以此類推。圖5b中,標號1、2、3的樣本存在陰影覆蓋和過曝,本文方法依然可以識別柑橘目標。圖5c中,弱光條件下,柑橘紋理不明顯,同時顏色也有較大變化,個別位置甚至可能出現柑橘和枝葉顏色混合的現象,這時不管是SIFT特征還是HOG特征效果較差。但使用本文方法均可準確識別柑橘。藍框標出的柑橘由于光照條件太差,顏色信息損失太多并未成功識別。圖5d中,在前背景相似情況下,柑橘顏色幾乎和枝葉顏色融為一體,同時還伴有光照變化和陰影覆蓋等情況存在。本文所設計的模型取得了較好的效果,其中識別效果較差的2號柑橘的IOU仍可達到0.8,分類結果為TP。由圖5識別結果可知,本文方法能夠有效地應對多種戶外采摘條件下的干擾因素。
實地拍攝的圖像尺寸為2 448像素×2 448像素,由于圖像像素較大,柑橘較小,因此將圖像分成4幅有重疊的子圖進行識別,子圖尺寸為1 000像素×1 000像素。識別模型將子圖縮放到416像素×416像素,識別完成后將識別結果聚合,以此實現多尺度圖像的識別。本文所設計的柑橘目標識別模型的運算平臺為i7-6850K CPU,Nvidia GTX 1080Ti GPU,內存32 GB。識別時間為從將圖像分割成4幅子圖到將4幅子圖識別結果聚合在一起輸出最后識別結果的總時間。經測試,1 000幅圖像的平均識別速度為12.5幀/s,因此該模型具有良好的實時性,能夠滿足實際自動化采摘的目標識別速度要求。
4 結論
(1)設計的基于深度卷積神經網絡的柑橘目標識別模型對光照變化、亮度不勻、前背景相似、果實及枝葉相互遮擋、陰影覆蓋等實際采摘環境下常見干擾因素及其疊加情形具有良好的魯棒性,可為柑橘采摘機器人設計提供參考。
(2)本文方法對柑橘識別的平均準確率均值達到了86.6%,平均損失為7.7,最大召回率為93%,實驗結果表明,該模型能夠在自然采摘環境下進行準確和快速的柑橘目標識別及定位。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
