基于條件隨機場多特征融合的中文地名、機構名實體識別
2019-06-01 05:54:24馬孟鋮艾斯卡爾艾木都拉吐爾地托合提
現代計算機 2019年12期
關鍵詞:特征
馬孟鋮,艾斯卡爾·艾木都拉,吐爾地·托合提
(新疆大學信息科學與工程學院,烏魯木齊 830046)
命名實體識別是自然語言處理的基礎任務,其中通用領域語料下的復雜地名、機構名實體識別效果還有待提高。針對這一問題,提出一種多特征融合的中文地名、機構名實體識別方法,該方法以條件隨機場為框架,結合實驗語料的特點,選取統計特征,將局部特征、復合特征與規則知識庫相融合,對中文語料進行命名實體識別。實驗結果表明,1998年1月《人民日報》語料上的測試結果,地名實體的F1 值提高2.2%,達到97.70%,機構名實體的F1 值提高6.2%,達到92.80%。
命名實體;多特征融合;自然語言處理;條件隨機場
0 引言
命名實體識別是自然語言處理研究領域中的一項很重要的基礎性任務[1],是實體關系抽取和事件抽取等高層任務重要基石,旨在從如今互聯網時代很容易獲得的海量非結構文本中提取出能夠體現現實世界中存在的客觀具體或者抽象實體的單詞或者詞組,例如人名、地名和組織機構名等[2]。
中文命名實體識別研究近年來發展迅速,中文命名實體識別的方法主要是基于規則的方法、基于統計的方法和深度學習[3]的方法[4]。Huang 等[5]提出了Bi-Lstm-CRF 模型,同時還融合了其他語言學特征以提升模型性能。Collobert[6]等采用CNN 進行特征抽取,同時提出一種句級對數似然函數,通過融合其他特征取得了不錯的結果。基于機器學習的命名方法通常被當作序列標注任務[7],張華平等[8]應用隱馬爾可夫模型并使用角色標注的方法來進行實體識別,胡文博[9]提出一種基于多層條件隨機場的命名實體識別的方法,對各粗分詞串先在底層進行簡單實體的識別,將結果傳入到高層模型再進行復雜實體的識別,取得了不錯的效果。對于醫療文本中存在大量復合疾病名稱實體等問題,王鵬遠[10]提出了基于多標簽CRF 的疾病名稱抽取方法,對數據標注多層標簽進行訓練,最后用標簽對實體進行分離,且取得了不錯的效果。以《人民日報》語料為代表的通用領域語料,其復合地名、機構名實體由于具有很強的隨意性,弱化了構詞規律,而且二者之間易相互嵌套,使得其識別的效果相對較差。本文基于條件隨機場模型,充分利用通用領域語料的特點,選取原子特征、組合特征、語義特征等,通過構建原子模板和復合模板,與知識庫相結合的方式識別地名、機構名實體,實驗結果表明,該方法取得了較好的效果。
1 條件隨機場
條件隨機場是一個在給定輸入節點條件下計算輸出節點的條件概率的無向圖模型。條件隨機場是在給定需要標記的觀察序列的條件下,計算整個標記序列的聯合概率分布,而不是在給定當前狀態條件下,計算下一個狀態的狀態分布。對于觀察值序列W 和狀態序列O,可以定義一個線性的CRF 模型,形式如下:
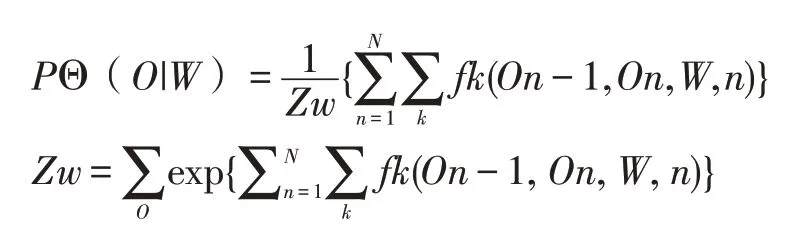
其中,Zw 是歸一化參數,它使得給定輸入的所有可能狀態序列的概率之和為1。Fk(On-1,On,W,n)是對于整個觀察序列W,標記位于N 和N-1 之間的特征函數,特征函數可以是0、1值,也可以是任意實數。Θ=θ1θ2…θk是特征函數對應的權重。對與W 來說,目標是搜索概率最大的O*=argmaxP(W|O)。
2 基于CRFs的命名實體識別
對于條件隨機場模型而言,觀察序列x 即輸入的句子是已知的,可以得到任意位置的觀測值,而狀態序列y 需要人工標注,但并不計入特征函數,只是用于最后標定標記聯合概率分布的參考。使用特征構建特征模板,進而得到特征函數。本文采用的訓練工具是:CRF++0.58;CRF++是著名的條件隨機場的開源工具,也是目前綜合性能最佳的CRF 工具。它可以自動生成一系列的特征函數,而不用我們自己生成特征函數,我們要做的就是尋找特征,基于條件隨機場命名實體識別流程圖如圖1 所示。

圖1 基于條件隨機場命名實體識別流程圖
2.1 類別標注
狀態序列需要進行標注。原始語料中文本已被分成詞語的形式,如“忠誠/a 的/u 共產主義/n 戰士/n”,我們對語料中的實體進行標注,用“B-”、“I-”、“E-”、“S-”表示出上下文的語義關系。如“[西藏/ns 自治區/n 政府/n]nt 副/b 主席/n”標注成“西藏B-nt 自治區I-nt 政府E-nt 副O 主席O”。這樣我們可以將語料中的人名、地名、機構名實體標注出來作為狀態序列。
2.2 特征選擇
在基于統計機器學習的命名實體識別方法中,特征的選擇能夠直接影響最終識別性能的好壞。本文著重對地名、機構名實體研究,提取出合適的特征。
(1)詞語本身標記為WORD:本文選取的1998年人民日報語料,通過NLPIR-ICTCLAS 分詞系統將原始文本進行切分形成詞語。詞語是表達中基本的形式,含有豐富的信息。
(2)詞性標記為POS;分詞系統切分詞語的過程中會標注詞語的詞性。地名、機構名實體的詞性一般為名詞、名詞短語、動詞或動詞短語,而幾乎不會是介詞、連詞等詞性。故可認為與實體有一定的相關性。
(3)實體的特征核心詞標記為CORE:對語料下的復合地名、復合機構名實體研究發現,這些實體一般都含有核心詞,如“地區”,“自治區”出現時大概率會出現地名,如“日喀則地區”,“新疆維吾爾自治區”。對于機構實體而言,“公司”,“委員會”很大程度上是機構名的中心詞,如“中國文聯出版公司”,“美國聯邦儲備委員會”。針對這一特點,我們添加實體的核心詞作為特征。
(4)實體的右邊界詞標記為Right_Boundary;中文地名和機構名的組成隨意性較大,如果能夠確定實體邊界,就能提高實體的識別效果。分析語料,我們發現實體的上下文出現的詞是有規律的,如“位于河南附近”,位于一般是地名的左邊界詞,附近也可作為地名的右邊界詞。考慮到一些地名開頭的復合機構名易誤識別成地名,如“新疆大學”可能只識別出“新疆”,所以我們選取實體的右邊界詞作為特征,能夠區分地名和機構名邊界。
(5)復雜機構名的左右邊界限定標記為Ins_Limit;語料中一些復雜的機構名識別率較低,對其分析,發現其存在以下幾個特點:一是字符長度較長,增加了識別難度;二是該類實體一般由地名+簡單機構名組合而成。識別過程中容易誤識別或漏識別。針對這一問題,我們利用該類實體的特點,通過判斷實體開頭是否為地名構建復合機構限定詞詞典,對測試集進行標注。
2.3 特征模板
選取實體特征后,驗證特征是否對于實體識別有提高需要組合不同的特征進行實驗對比,組合特征需要根據特征類型構建模板。所以特征模板的構建也是實體識別的關鍵。
CRF++工具包通過固定格式的特征模板來定義特征集,允許在一個上下文中按一元(Unigram)、二元(Bigram)、三元(Trigram)來使用特征。以下列出了特征模板實例,如表1 所示。

表1 特征模板實例
表中每一行%x[#,#]表示生成一個條件隨機場中的點函數:f(S,O),其中S 為t 時刻的標簽,O 為t 時刻的上下文,如表2 中的訓練語料所示。
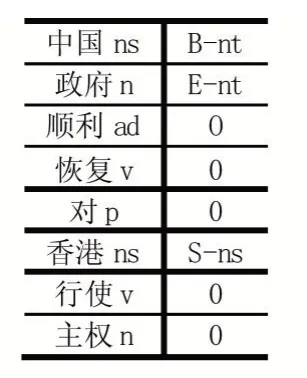
表2 訓練語料模板
當前考慮的位置t 為“順利”,本文選取的上下文窗口大小為5;
表1 中U00-U04 特征模板:表示某個位置與當前位置的詞的關系,如U04:%x[2,0]表示“順利”和“對”之間的聯系。
U05-U07 特征模板:表示某個位置與當前位置的詞性的關系,如U06:%x[-1,1]表示“政府”的詞性“n”和“順利”的詞性“ad”之間的聯系。
同理U08-U09 特征模板:表示某兩個位置與當前位置的詞的關系;U10-U12 表示某兩個位置與當前位置的詞性的關系;U13-U15 特征模板表示表示某三個位置與當前位置的詞性的關系。
隨著特征的不斷增多,特征模板的數量也快速增加,這會加重實驗的數據處理量,增加訓練的復雜度,甚至會降低實體識別的準確度。可見,如何根據特征的效果有選擇地構建特征模板,也是命名實體識別研究的關鍵。
3 實驗及結果分析
3.1 實驗數據集及實驗設計
實驗所用語料為1998年1月的人民日報語料,該語料為通用領域語料,其中復雜地名、機構名實體的識別效果還有待提高。本文隨機抽取10000 條句子作為訓練語料,3000 條句子作為測試語料。
本文將采用準確率(P)、召回率(R)和F 值等三個指標來評價實驗的性能。

3.2 特征選取及地名、機構名識別實驗
根據語料的特點選擇不同的特征,特征的選取決定了命名實體識別效果的好壞。除了詞和詞性特征意外,本文選取了三項特征加入特征模板。
選取特征時,以“組織”一詞為例,如果把“組織”作為特征進行標記,則應該把語料中所有出現的“組織”都進行標記。但是“組織”在“世界衛生組織”中是實體的中心詞,在“組織當地群眾開展……”中就不是中心詞了。這可能會導致數據稀疏問題。所以我們通過設定閾值,滿足條件的詞添加標記作為特征。不同閾值下得到的右邊界詞個數如表1 所示。
如表3、表4 所示,實體右邊界詞特征的閾值取0時做標記詞數為25807 個。閾值取0.05 時,該特征標記下的詞數為19851 個,語料中詞語標注的數目下降了1/5。實體中心詞特征的閾值取0 時做標記詞數為23665 個。閾值取0.3 時,該特征標記下的詞數為10290 個。標記數目下降1/2,有效避免了數據稀疏問題。雖然實體右邊界詞特征閾值取0.1 時,語料中詞語標記數下降了1/2,但是實體右邊界詞也減少了2/3,會使得該特征對于語料中的實體表示不夠充分,造成識別效果下降。所以實體中心詞特征的閾值設為0.3,實體右邊界詞特征的閾值設為0.05。
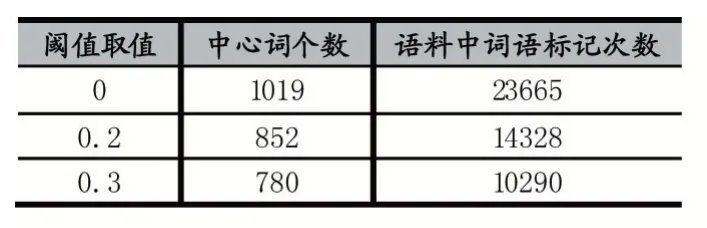
表3 不同閾值下實體中心詞個數及語料中詞語標記數
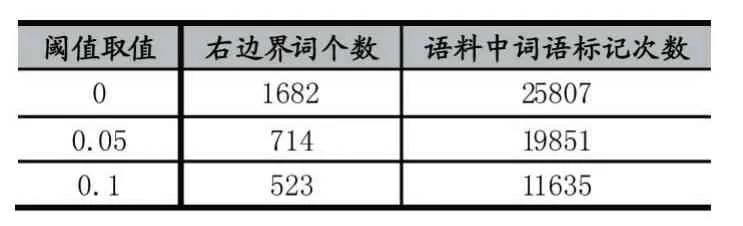
表4 不同閾值下實體右邊界詞個數及語料中詞語標記數
通過設定不同閾值獲得特征后,選取不同特征構建特征模板進行實驗對比,構造組合特征進行對比實驗。原子、組合特征模板如表5 所示。
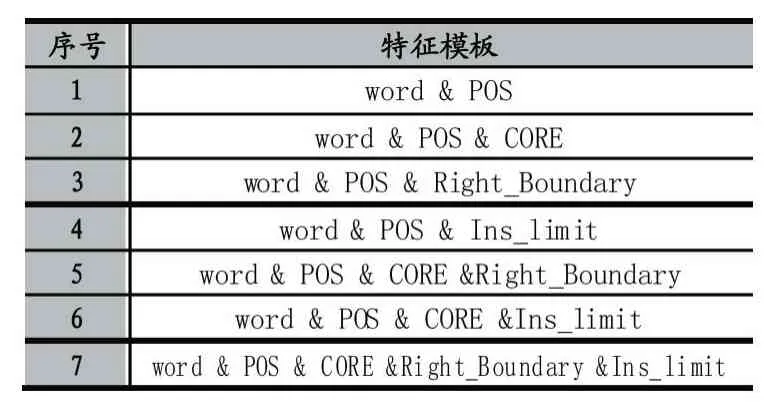
表5 原子、組合特征模板
3.3 實驗結果分析
選取不同特征,構造特征模板對添加特征的效果進行實驗,如表6 所示。
4 結語
本文針對通用領域下地名、機構名實體的特點,通過選取地名、機構名實體的原子特征,復合特征和語義特征,利用條件隨機場模型根據訓練模型對地名、機構名實體進行識別。實驗結果表明:該方法能夠有效地識別通用語料下地名、機構名實體。地名實體的F1 值達到了97.70%,機構名實體的F1 值提高了6.2%,達到了92.80%。

表6 不同特征模板下地名、機構名識別的效果
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化(高中版.高考數學)(2022年3期)2022-04-26 14:04:16
數學年刊A輯(中文版)(2020年1期)2020-05-19 00:30:36
空間科學學報(2020年2期)2020-04-01 03:50:40
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中等數學(2019年8期)2019-11-25 01:38:14
當代陜西(2019年10期)2019-06-03 10:12:04
新聞傳播(2018年11期)2018-08-29 08:15:24
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
