基于深度強化學習的機械臂避障路徑規劃研究
2019-05-29 11:18:10李廣創程良倫
軟件工程 2019年3期
關鍵詞:機械臂
李廣創 程良倫

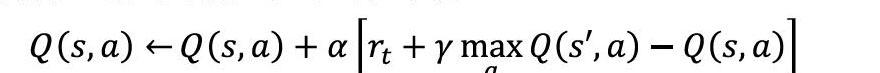

摘? 要:為了解決現有的機械臂焊接系統調整動作的難度大,缺乏靈活性的問題,本文采用了深度強化學習算法來解決機械臂的路徑規劃問題;該方法使用一個三層的DNN網絡,輸入為機械臂的狀態信息,輸出為機械臂的運動關節角度,通過離線訓練,機械臂能夠自行訓練出一條接近于最優的運動軌跡,能夠成功地避開障礙物到達目標點;仿真在一個三自由度點焊機器人的模擬平臺上進行,仿真實驗表明,采用深度強化學習技術的機械臂能為焊接機械臂規劃出一條無碰撞的路徑,具有較強的避障能力。
關鍵詞:機械臂;強化學習;碰撞檢測;路徑規劃
中圖分類號:TP391.9? ? ?文獻標識碼:A
Abstract:In order to solve the difficulty of adjusting the existing mechanical arm welding system and the lack of flexibility,this paper adopts a deep reinforcement learning algorithm to solve the path planning problem of the mechanical arm;the method uses a three-layer DNN network with the input of mechanical state information and the output of the joint angle of the arm.Through offline training,the mechanical arm can be trained to move a nearly optimal motion trajectory and successfully avoid obstacles to reach the target point;the simulation is carried out in a three-degree-of-freedom welding robot simulation platform.The simulation experiment shows that the mechanical arm with deep reinforcement learning technology can plan a collision-free path for the welding mechanical arm and has strong obstacle avoidance ability.
Keywords:mechanical arm;reinforcement learning;collision detection;path planning
1? ?引言(Introduction)
在集裝箱的焊接作業中,為了實現高效的作業需求,焊接機械臂大規模地應用到集裝箱生產線中,而作業的空間存在較多的障礙物,需要在自動化焊接的過程中考慮碰撞的避免,為了順利地執行焊接作業,對機械臂的避障路徑規劃的研究十分有必要。
針對機械臂的避障路徑規劃的問題,國內外很多學者都進行了深入的研究。賈慶軒等人[1]將笛卡爾空間障礙向構型空間障礙進行轉換,然后使用A*算法進行無碰撞路徑規劃。張云峰等人[2]采用將機械臂從J空間(Joint Space)中隨機采樣后通過正向運動學映射到C空間(Configuration Space),然后采用改進的RRT算法進行路徑規劃。姬偉等人[3]采用人工勢場法進行機械臂的路徑規劃,在障礙物處人工模擬一個斥力場,在目標點處模擬一個引力場,機械臂在這兩個場的作用下運動。韓濤等人[4]采用遺傳算法來進行機械臂的路徑規劃。尹建軍等人[5]將機械臂工作空間映射到平面的二維空間,再在平面空間上使用A*算法進行路徑規劃,但是該方法只能使用與指定的場景,缺乏靈活性。以上的這些方法需要精確的環境構建模型,在復雜的工業環境下不能很好地適用。
在本文中,采用強化學習的方法來解決避障路徑規劃的問題,這個方法可以使用一個通用的框架來解決指定的任務。對于高維空間的復雜任務,例如機械臂系統,基于強化學習的無模型方法可以解決這樣的問題。如利用DQN技術對三個關節的機械手臂進行端對端的控制[6],用將深度強化學習技術應用于七自由度機械臂的插孔任務中[7]。q-learning是一個經典的強化學習方法,由于q-learning算法需要一個巨大的Q表,導致在高維空間占用的內存巨大,并且不易收斂,因此,本文使用一種DQN的算法。與以往大多數碰撞檢測算法不同,這個方法是一個無模型的方法,不需要針對每一種場景來建模,因此具有良好的通用性,該方法分為離線軌跡生成和在線應用。最后通過仿真,對本文提出的方法的有效性進行了驗證。
2? 強化學習基礎(Foundation of reinforcementlearning)
2.1? ?馬爾科夫決策過程
大多數強化學習算法可以在同一個框架下描述,這個框架稱為馬爾科夫決策過程,簡稱MDP。一個完整的馬爾科夫決策過程可以利用元組(S,A,P,R,γ)來表示。其中S是狀態集,A是動作集,P是狀態轉移概率,也就是對應著環境和智能體模型,R為回報函數,γ為折扣因子,用于計算累計回報R[8,9],累計回報的計算公式為,其中0≤γ≤1。
定義策略π為在給定狀態S時,動作集上的分布。
定義狀態—動作值函數為:累計回報在狀態s和動作a處的期望值:
強化學習的目標是給定一個馬爾科夫決策過程,尋找最優策略π,使該決策下的累計回報期望最大,即:
2.2? ?q-learning算法
機械臂的避障屬于強化學習的控制問題,控制問題可以表示為:給定強化學習的五個要素:狀態集S、動作集A、即時獎勵R、衰減因子γ、探索率,求解最優的動作價值函數和最優策略。
q-learning算法是一種使用時序差分求解強化學習控制問題的方法,這一類強化學習的問題求解不需要環境的狀態轉化模型,是不基于模型的強化學習問題求解方法。它屬于時序差分中的離線控制方法,也即會使用兩個控制策略,一個策略用于選擇新的動作,另一個策略用于更新價值函數[9,10]。
第一個策略,它先用策略在當前狀態S選擇出動作A,執行動作A得到S';第二個策略,基于狀態S',使用貪婪法選擇A',也就是說,選擇使Q(S',a)最大的動作A'來更新價值函數。用數學公式表示為:
此時選擇的動作只會參與價值函數的更新,不會真正的執行。價值函數更新后,新的執行動作需要基于狀態S',基于策略一,用策略重新選擇得到用表格表示的動作價值函數,使用貪婪策略,即每次尋找最優的動作便可以得到機械臂的控制。
2.3? ?深度Q網絡(DQN)
在q-learning算法中,動作價值函數Q(S,a)對應著一張表,索引對應著狀態-行為對。值函數的迭代更新對應實際上就是這張表的迭代更新,當狀態空間的維數很大,或者狀態空間是連續空間,則此時值函數無法用一張表格來表示,此時可以用函數逼近的方法來表示價值函數,這個函數可以用參數w來表示,最常見的表示方法是使用神經網絡[11],具體的形式為:。
一般情況,使用的網絡結構為輸入是狀態S的特征向量,動作集合有多少個動作,神經網絡就有多少個輸出,中間的結構可以DNN、CNN、RNN等,沒有特別的限制。
神經網絡的訓練需要帶標簽的樣本,DQN使用經驗回放技巧來解決這個問題,也即將每次和環境交互得到的獎勵與狀態更新情況都保存在經驗池D中,然后從經驗池D中采樣m個樣本用于后面目標Q值的更新。
在神經網絡中使用作為輸入,得到所有動作對應的Q值輸出。用策略在當前Q值輸出中選擇對應的動作A,在狀態S執行當前動作A,得到新狀態S'下,對應的特征向量,獎勵R和終止狀態標志is_end;也即5元組:,它對應的目標Q值為:
由此,根據反向傳播準則,可以使用均方差損失函數來更新神經網絡的參數。
同時,為了減少目標Q值和當前Q值的相關性,DQN使用兩個結構完全相同的網絡,一個“當前網絡Q”用來選擇動作和更新模型參數,另一個“目標網絡Q'”用來計算目標Q值。目標網絡Q'的網絡參數不需要迭代更新,而是每隔一段時間從當前網絡Q復制過來,即延時更新。
3? 機械臂避障系統(Obstacle avoidance system of the mechanical arm)
3.1? ?空間機械臂模型
本文將深度強化學習技術應用于機械臂的路徑規劃中,首先要對機械臂進行建模,機械臂采用D-H法建立數學模型,如圖1和圖2所示。機械臂相鄰連杠的關系用一個4*4的齊次變換矩陣來描述,旋轉關節的齊次變換矩陣的一般形式為:
機械臂末端位置和姿態的求解是正運動學問題,表示為各個相鄰齊次變換矩陣的連乘,機械臂的正運動學方程為:。
3.2? ?碰撞檢測
三維空間障礙物一般具有不規則的形狀,為了分析專注于核心問題的分析,將三維障礙物簡化為空間球體。強化學習每一步需要檢測當前機械臂與環境的狀態,也即需要判斷機器人的當前位置是否與障礙物發生碰撞,設球形障礙物的中心為,半徑為;圓柱體機械臂的半徑為;機械臂軸線的兩個端點分別為、,如圖3所示。
設障礙物到直線的投影點為:
直線的方向向量為:
根據AB的空間直線方程,得:
根據障礙物與投影點的連線與直線相交得:
根據上面兩式可以求出投影點坐標;進而確定障礙物到機械臂的距離:
障礙物到端點的距離:
碰撞檢測算法的描述為:
(1)對于每個軸
a.若障礙物的投影在線段區域內,即,則計算球心到線段AB的距離,如果,則判斷為安全,否則判斷為碰撞。
b.若障礙物的投影不在線段的區域內,即,則計算球心到端點的距離,如果,則判斷為安全,否則判斷為碰撞。
(2)若三個軸都不與障礙物發生碰撞,則判斷為安全,否則判斷為碰撞。
3.3? ?機械臂避障系統相關參數的設定
獎勵r:機械臂每執行一個動作,環境會產生一個獎勵,獎勵函數的設置至關重要,直接影響著算法是否能收斂,針對機械臂路徑規劃問題,希望機械臂能順利避開障礙物并到達目標點,同時產生的步數盡量少,因此獎勵函數的設置為:
狀態s:機械臂與環境的交互產生的狀態,分別用下面的變量表示:末端點的坐標,第三個端點的坐標,是否碰撞,是否到達目標點,末端點與目標點的距離,第三個端點與目標點的距離。將狀態量用一個向量的形式表示為:。
行為a:機械臂的行為是關節的轉動的角度,用一個向量的形式表示為:。
3.4? ?基于DQN的械臂路徑規劃算法的實施
本文采用三層DNN的網絡作為DQN的網絡主體,其具體的機械臂避障路徑規劃算法描述如下:
隨機初始化所有的動作和狀態對應的價值Q,隨機初始化當前Q網絡的所有參數w,初始化目標網絡Q'的參數w'=w,清空經驗回放集合D
1)從環境中獲得機械臂的初始狀態S。
4.1? ?實驗配置
本文的仿真環境在MATLAB和python下搭建,在MATLAB下完成機械臂及碰撞檢測模型的搭建,在python下完成深度強化學習模型的搭建。
神經網絡的輸入是機械臂的狀態,用一個10維向量表示:;輸出為機械臂的角度轉動量,本文允許機械臂的轉角為。
DQN迭代的最大輪數設置為10000輪,每一輪最大的步數設置為250步;本文設置的機械臂3個杠長為[50,100,100],起點坐標為(118.3,-68.3,13.3);終點坐標為(50,70,30)。障礙物1的坐標為(40,30,30),障礙物2的坐標為(70,-20,60),障礙物的半徑為20,為了簡化起見,將機械臂設置為點桿模型。
4.2? ?實驗結果與分析
機械臂經過訓練好的神經網絡,每一步輸出一個最大Q值得動作,然后使用正運動學來控制機械臂的行走;機械臂的避障結果如圖4所示:機械臂經過強化學習模型的訓練,成功地避開兩個障礙物,到達目標點,機械臂的運動步數為32步,接近于最優;從圖5可以看出,機械臂每一輪的累計回報逐漸增加,大約在6300輪迭代后收斂;從圖6可以看出,機械臂每一輪的迭代步數逐漸減少,并最終穩定收斂。
5? ?結論(Conclusion)
本文以點焊機械臂為研究對象,將機械臂在三維空間的自動點焊轉化為機械臂的避障路徑規劃問題。本文首先介紹了強化學習的基本原理,然后通過建立機械臂模型,采用深度強化學習的方法進行機械臂避障路徑規劃的求解,分別在MATLAB和TensorFlow平臺上建立機械臂模型和強化學習模型;仿真結果表明,通過一定的訓練步驟,機械臂能順利規劃處一條無碰撞的焊接路徑。相比于傳統的規劃方法,本文的基于強化學習的規劃方法簡單,而且具有較高的通用性。
參考文獻(References)
[1] 賈慶軒,陳鋼,孫漢旭,等.基于A~*算法的空間機械臂避障路徑規劃[J].機械工程學報,2010,46(13):109-115.
[2] 張云峰,馬振書,孫華剛,等.基于改進快速擴展隨機樹的機械臂路徑規劃[J].火力與指揮控制,2016,41(05):25-30.
[3] 姬偉,程風儀,趙德安,等.基于改進人工勢場的蘋果采摘機器人機械手避障方法[J].農業機械學報,2013,44(11):253-259.
[4] 韓濤,吳懷宇,杜釗君,等.基于遺傳算法的機械臂實時避障路徑規劃研究[J].計算機應用研究,2013,30(05):1373-1376.
[5] 尹建軍,武傳宇,Yang Simon X,等.番茄采摘機器人機械臂避障路徑規劃[J].農業機械學報,2012,43(12):171-175;157.
[6] Wonchul Kim,Taewan Kim,et al.Three-link Planar Arm Control Using Reinforcement Learning[C].International Conference on Ubiquitous Robots and Ambient Intelligence,2017:424-428.
[7] Tadanobu Inoue,Giovanni De Magistris,et al.Deep Reinforcement Learning for High Precision Assembly Tasks[C].IEEE International Conference on Intelligent Robots and Systems,2017:819-825.
[8] 劉全,翟建偉,章宗長,等.深度強化學習綜述[J].計算機學報,2018,41(01):1-27.
[9] Kober,Jens,J.Andrew Bagnell,et al.Reinforcement learning in robotics:A survey[C].The International Journal of Robotics Research,2013:1238-1274.
[10] 方小菊.基于強化學習的采摘機器人采摘臂避碰設計[J].農機化研究,2017,39(11):198-202.
[11] 王曌,胡立生.基于深度Q學習的工業機械臂路徑規劃方法[J].化工自動化及儀表,2018,45(02):141-145;171.
作者簡介:
李廣創(1994-),男,碩士生.研究領域:機器學習,機器人.
程良倫(1965-),男,博士,教授.研究領域:人工智能,工業大數據.
猜你喜歡
科技與創新(2016年23期)2017-03-30 04:12:23
中國科技縱橫(2017年3期)2017-03-29 18:50:48
山東工業技術(2017年4期)2017-03-28 07:56:48
求知導刊(2017年1期)2017-03-24 22:25:58
物聯網技術(2017年2期)2017-03-15 17:04:47
中國科技博覽(2016年27期)2017-01-23 01:32:28
農機使用與維修(2016年12期)2017-01-17 15:23:12
安徽理工大學學報·自然科學版(2016年1期)2016-12-14 22:15:06
計算機教育(2016年7期)2016-11-10 09:01:27
中國科技博覽(2016年9期)2016-04-25 10:13:28
