面向短文本分類的特征提取與算法研究
2019-05-27 06:25:14劉曉鵬楊嘉佳田昌海
網絡安全與數據管理 2019年5期
劉曉鵬,楊嘉佳,盧 凱,田昌海,唐 球
(1.華北計算機系統工程研究所,北京 100083;2.軍事科學院 軍事科學信息研究中心,北京 100142)
0 引言
在信息化時代背景下,各行業產生了大量的多源異構數據。對這些數據的信息挖掘,衍生出很多基于傳統行業的新實踐和新業務模式[1]。這些數據中存在著大量的超短文本,因此可以通過自然語言處理領域的知識方法,并結合已經提出的計算機科學方法,挖掘出許多高價值的信息。在某些短文本分類任務中,如通過標題劃分可以避免對全文進行分類,可以節省大量計算資源;而在爬蟲任務中,由當前頁面附帶鏈接的短文本分類,則避免了進入鏈接爬取數據,節省了大量網絡資源。本文主要研究面向短文本分類不同的特征提取與算法差異。
1 特征提取方法介紹
1.1 獨熱編碼
獨熱編碼(one-hot encoding,one-hot),又稱一位有效編碼。在文本分類中,即每一位對應一個單詞,以0代表該詞沒有出現,以1代表該詞已經出現,通過固定順序的詞表,將每一個文本使用獨熱編碼方式向量化。獨熱編碼因為單詞數量太多,在實際實驗中,有時達到60 000以上的維度,直接導致了維度爆炸;而超短文本數據每條單詞只有3~10個,又導致了數據的高度稀疏。
1.2 Word2Vec
Word2Vec[2]是一種Distributed representation生成詞向量方法。Distributed representation最早由Hinton在1986 年提出。其依賴思想是:詞語的語義是通過上下文信息來確定的,即相同語境出現的詞,其語義也相近。
Word2Vec采用CBOW和Skip-Gram兩種模型,以及Hierarchical Softmax和Negative Sampling兩種方法,使用神經網絡訓練,將單詞映射到同一坐標系下,得到數值向量。在實驗中,用數據集訓練出的模型泛化性能不好。分析得出,Word2Vec訓練模型,文本需要大致在8 GB以上才會有較好效果。本文實驗數據集只有200 MB。根據語料特征,最終采用已經訓練好的谷歌新聞Word2Vec模型。
Word2Vec向量化采用300維度,避免了獨熱編碼造成的維度爆炸、數據稀疏問題。在訓練Word2Vec知識圖譜過程中,引入大量數據,進一步提升模型的泛化能力。
1.3 詞頻-逆文件頻率
詞頻-逆文件頻率(Term Frequency-Inverse Document Frequency,TF-IDF)[3]是一種用于資訊檢索與資訊探勘的常用加權技術。TF-IDF是一種統計方法,用以評估一個詞對于一個文件集或一個語料庫中的其中一份文件的重要程度。字詞的重要性隨著它在文件中出現的次數成正比增加,但同時會隨著它在語料庫中出現的頻率成反比下降。即一個詞語在一篇文章中出現次數越多,同時在所有文檔中出現次數越少,越能夠代表該文章。
每條文本數據每個維度的詞頻-逆文件頻率計算公式如下:
TF-IDF=TF×IDF
(1)
其中:
(2)
(3)
1.4 主成分分析
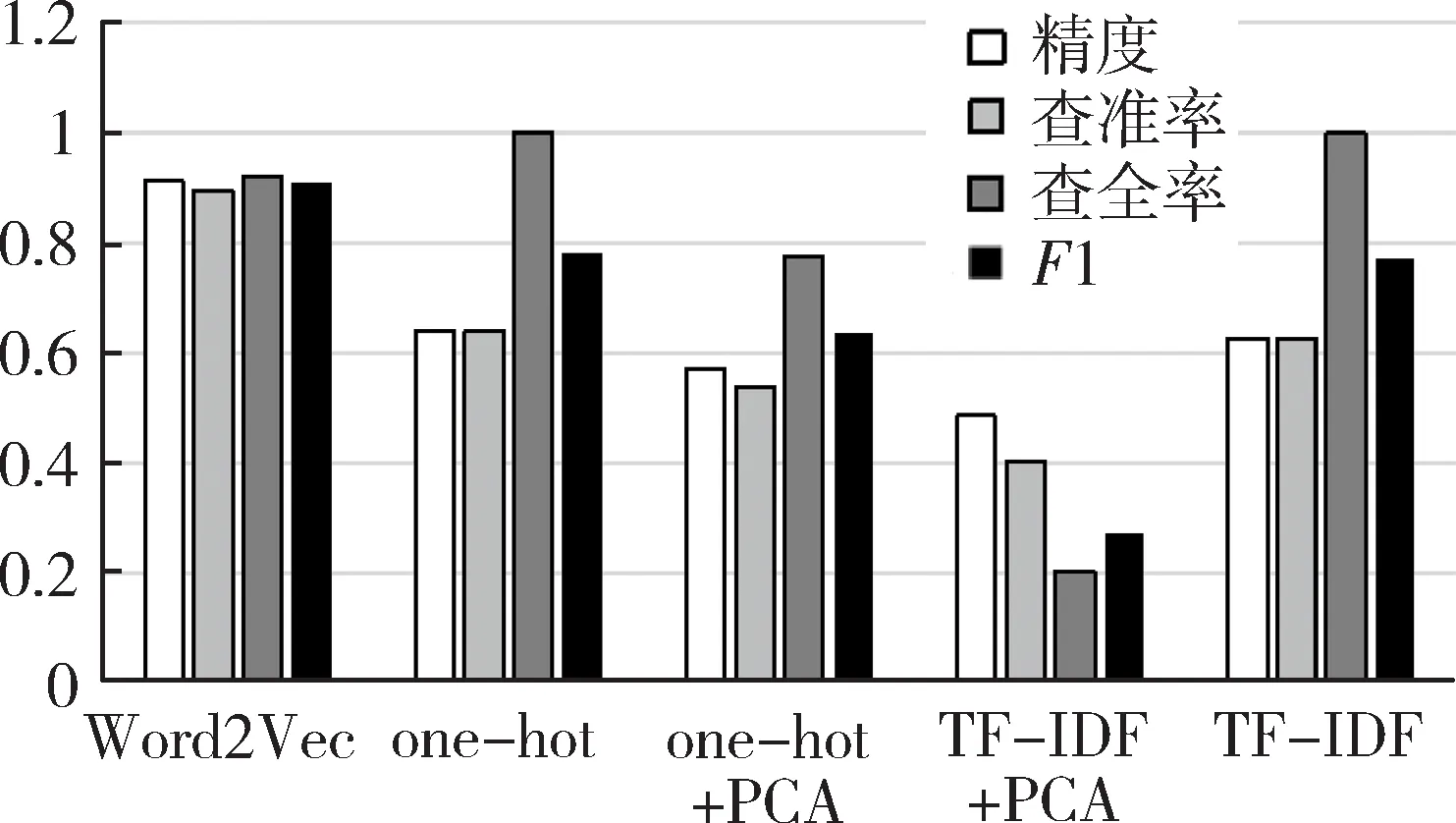
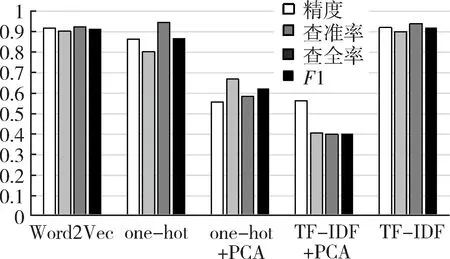
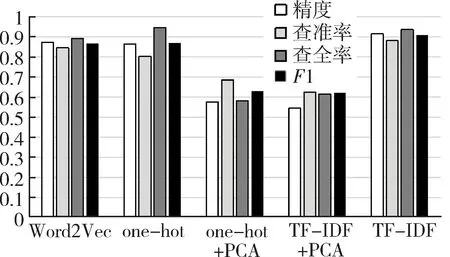
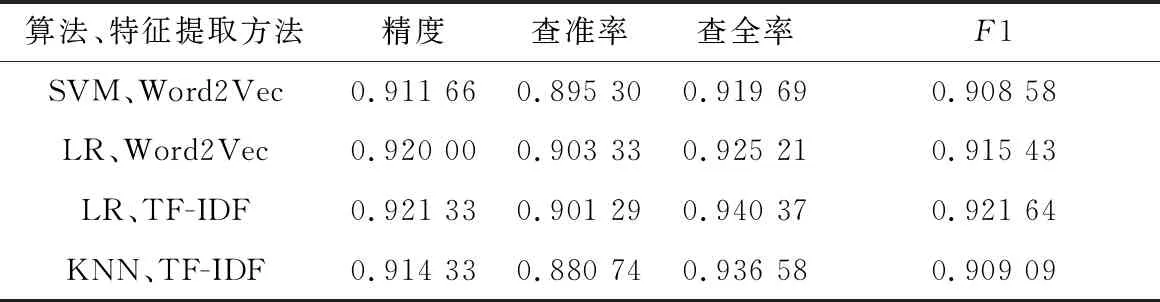
主成分分析(Principal Component Analysis,PCA)[4]是一種常用的數據降維方法。主成分分析通過矩陣變換,將n維特征映射到k維上(k< 在獨熱編碼和詞頻-逆文件頻率特征提取中,需要對每一個單詞設立一個維度,導致向量化后的數據維度太高,模型訓練對算力形成了較大的負擔,經主成分分析,數據維度降低到原來的0.5%,大大降低了訓練和測試的計算負擔。 支持向量機(Support Vector Machine,SVM)[5]是AT&TBell實驗室的Cortes和Vapnik在1995年提出的一種分類算法。SVM目標是在數據中找到一個分類超平面,達到分類目的。SVM自身可以正則化,分類超平面依賴于支持向量,因此在樣本較少以及抽樣不均衡的時候有較好結果。 SVM在文本分類和高維數據中擁有良好的性能,被選為機器學習十大算法之一,在2000年前后直接掀起了“統計學習”的高潮,是迄今為止使用最廣的學習算法。 邏輯回歸算法(Logic Regression,LR)[6]屬于對數線性模型的一種,核心思想是利用現有數據對分類邊界建立回歸方程,以此進行分類。該算法簡單高效。LR衍生出的Softmax將LR推廣至多分類任務中。 邏輯回歸算法因為其高效性及不俗的效果,是現在工業界應用最廣泛的算法之一。 K近鄰算法(K-Nearest Neighbor,KNN)[7]通過與最近K個點比較,投票選出類別。K近鄰不具有顯示的學習過程,分類中有計算量大的缺點。 K近鄰算法簡單成熟,在很多機器學習任務中有很好的效果,也是機器學習十大算法之一。 本文實驗采用kaggle上公開的News Aggregator Dataset[8]作為測試數據集。News Aggregator Dataset包含2014年間40萬條已經分類的新聞,數據集屬性如表1所示。 表1 數據集屬性描述表 此次實驗主要采用TITLE屬性作為超短文本的分類語料,類別標簽采用CATEGORY屬性。TITLE屬性中包含的文本,長度大部分集中在3~15個單詞之間,符合超短文本范疇;CATEGORY包含4種屬性:商業、科技、娛樂、健康,比例大致為27%、25%、36%、10%,類別基本均衡,符合實驗要求。 本次實驗采用4個機器學習中分類常用的評價指標:精度、查準率、查全率與F1值。 在二分類問題中,根據樣本真實類別與模型預測結果的組合定義真正例(True Positive,TP)、假正例(False Positive,FP)、真反例(True Negative,TN)、假反例(False Negative,FN),分類結果混淆矩陣如表2所示[9]。 表2 分類結果混淆矩陣 3.2.1 精度 精度是分類正確的樣本數在總樣本數中的比例。精度acc定義為: (4) 精度是分類任務中最常用、最基本但同時也是最重要的一個評價指標。 3.2.2 查準率 查準率P定義為: (5) 查準率反映了分類為正例中被正確分類的概率。 3.2.3 查全率 查全率R,也叫召回率,定義為: (6) 查全率反映了正例中被正確分類的概率。 3.2.4F1值 F1值是基于查準率與查全率的調和平均,定義為: (7) 查全率與查準率是一組相反的指標,相同模型下,查準率越高,查全率越低;F1值是對查準率和查全率的均衡反映。 系統環境:Ubuntu16.04LTS。 Python版本:Python3.6。 編碼格式:utf-8。 首先,刪去實驗中不需要的屬性ID、URL等,只保留CATEGORY和TITLE,以CATEGORY為標簽,以TITLE為文本數據。接著對文本數據進行分詞,分詞過程中,去除無實際含義的停詞、特殊符號、標點。最終生成的文本文件,每一行為一條數據,格式為“類別標簽,分詞”。最后,將生成的文件分成兩個文件:訓練集和測試集。 使用支持向量機、邏輯回歸算法、K近鄰算法三種算法,對獨熱編碼、詞頻-逆文件頻率、Word2Vec以及對獨熱編碼和詞頻-逆文件頻率結果分別進行主成分分析降維這五種特征提取方法得到的訓練集特征向量進行訓練,然后用測試集進行測試。 將每種算法所對應的所有特征提取方法的實驗視為一輪實驗。每一輪實驗主要包含特征提取和模型訓練兩個部分。 3.5.1 特征提取 建立詞表,詞表中包含所有文本數據中出現的分詞,大致60 000個。分別用獨熱編碼、詞頻-逆文件頻率和Word2Vec提取訓練集特征,Word2Vec采用訓練好的谷歌新聞知識圖譜,為300維;個別模型需要對獨熱編碼和詞頻-逆文件頻率提取的特征向量進行主成分分析,再進行模型訓練。根據不同算法模型,每次提取特征的訓練集大小不同。 3.5.2 模型訓練 本數據集有四個類別,是一個四分類問題,查準率、查全率和F1值對應的是二分類問題中的評價標準,因此,將四分類問題轉換為二分類問題。在每一輪實驗中,將四種類別兩兩作為一類,共有三種組合,對所有組合進行模型訓練測試。訓練過程中,對于類別的輕微不均衡,通過調參均衡數據。四個評價指標中,精度為首要指標。在每一輪實驗中,選取最好的分類結果作為這一輪實驗的最終結果。 3.6.1 支持向量機各特征提取方法的結果 圖1從精度、查準率、查全率和F1四個維度來對比Word2Vec、one-hot、one-hot+PCA、TF-IDF+PCA和TF-IDF的性能。可以看出,在最重要的衡量指標精度方面,Word2Vec表現最為優異。而且從所有指標的均衡性來看,Word2Vec的性能最為穩定,明顯優先于其他特征提取方法。因此,以支持向量機為基礎算法,組合Word2Vec特征提取算法能獲取最佳效果。 圖1 SVM實驗結果 3.6.2 邏輯回歸算法各特征提取方法的結果 從圖2可以看出,以邏輯回歸算法為基礎,Word2Vec、詞頻-逆文件頻率等提取特征方法的效果較為顯著且差別不大,獨熱編碼略次于前兩種方法。因此,以邏輯回歸為基礎算法,組合Word2Vec、獨熱編碼以及詞頻-逆文件頻率等提取特征方法能獲取最佳效果且精度、查準率、查全率和F1四個衡量指標較為穩定。 圖2 LR實驗結果 3.6.3 K近鄰算法各特征提取方法的結果 K近鄰算法在Word2Vec、one-hot和TF-IDF上性能較好,且明顯優于one-hot+PCA、TF-IDF+PCA,如圖3所示。以K近鄰算法為基礎算法,組合Word2Vec、獨熱編碼以及詞頻-逆文件頻率等提取特征方法能獲取最佳效果且精度、查準率、查全率和F1四個衡量指標較為穩定。但由于K近鄰算法需要與各個數據進行相似度計算,其計算開銷很大,不適合應用于對計算時間復雜度有要求的場景。 圖3 KNN實驗結果 在支持向量機算法中,Word2Vec的特征選擇方法明顯是最優異的,各項指標較為均衡,大部分評價指標均遠好于其他方法;在邏輯回歸算法中,Word2Vec與TF-IDF優于其余特征提取方法,TF-IDF查全率有少許優勢,綜合來說,Word2Vec與TF-IDF在該文件邏輯回歸算法中,均有較好表現;在K近鄰算法中,Word2Vec與獨熱編碼方法較好,效果較一致,Word2Vec各指標更加均衡,TF-IDF更加優于前兩種方法。四種表現最佳模型最終結果如表3所示。 表3 四種最優模型實驗結果 表3中給出的四種最優的方法,精度相差無幾,而結合其他評價指標,以詞頻-逆文件頻率為特征提取方法、以邏輯回歸為算法的模型為最優的算法。Word2Vec特征提取方法對于大多數算法都有不錯的效果,同時,在個別算法中詞頻-逆文件頻率也有著很好的效果。2 機器學習算法介紹
2.1 支持向量機
2.2 邏輯回歸算法
2.3 K近鄰算法
3 算法設計及實現
3.1 數據集介紹
3.2 評價指標

3.3 實驗環境
3.4 數據預處理
3.5 實驗過程
3.6 實驗結果
4 結果分析
5 結論
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
電子制作(2019年15期)2019-08-27 01:12:00
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
