屬性與關系的再認識
——社會網絡分析研究現狀與演進
2019-05-08 02:40:54龐云黠
新聞與傳播評論(輯刊) 2019年3期
龐云黠
現階段國內傳播學研究已經開始大量使用社會網絡分析法(social network analysis,SNA),可以看到學者們面對大數據的挑戰,對于新的、具有解釋力的研究方法的期待。
社會網絡分析方法之所以在近些年被大家廣泛使用,最核心的吸引力在于它的分析對象從以前“絞肉機”似的“屬性數據”(attribute data)[1]轉到了具有一定結構要素的“關系數據”(relational data),在社交網站廣泛使用的今天,SNA無疑非常具有吸引力。
但是如果認為SNA的分析僅僅是對于關系數據的分析就比較片面了,事實上,國外傳播學者對SNA的使用經歷了一個漸進的演化過程。早在2011年Miller等[2]在對組織傳播的量化研究方法發展歷史進行綜述時就提到:在組織傳播研究中,從20世紀70—80年代,社會網分析法主要被用在研究個體在社會網中所處的位置如何影響人們對他的認知、屬性、行為的理解,因為這期間,如果關注社會網絡結構的話,主要能夠討論三個方面的指標:結構對等性(structural equivalence)、直接關系(direct relations)以及中介性(brokerage)。到了20世紀90年代,研究者已經不滿足于簡單的研究關系數據,而開始同時對關系數據和屬性數據進行考量,看他們如何共同影響研究對象。當然這種轉變也是因為有了新的分析工具,主要包括:指數隨機圖模型(ERGM,exponential random graph models),主要解決同時考量關系變量和屬性變量的問題,實證網絡分析仿真研究(SIENA,simulation investigation for empirical network analysis),主要側重研究個體驅動的動態網絡演化,也可以同時考量關系變量和屬性變量。
沿著上述學者關于“關系數據”與“屬性數據”的結合的期待,筆者希望考察的是,如果單純從組織傳播的視角來看呈現了上述的方法變遷,兩類數據走向結合,那么擴展到傳播學其他類型研究,SNA的使用現狀是一種怎樣的狀態?這種狀態從方法上或是理念上體現了什么新趨勢?
一、個體網研究:屬性與關系的分離
超越組織傳播的研究范圍來看,自上述綜述的2011年以來,“屬性”與“關系”分離的研究仍是個體網研究當中的主流。
社會網絡分析主要有兩大類分析對象,一類是整體網(whole network),一類是個體網(ego-network)。整體網主要研究網絡中的結構要素,主要的研究指標包括:網絡密度、中心度、成分、派系等等,個體網主要分析以特定的行動者為研究中心,只考慮與該行動者相關的聯系,主要研究中介性、個體網絡同質化、多元化、關系強度等等。
在大量的個體網研究當中,關系數據既可以做研究的因變量,研究個人的屬性如何影響這種“關系”變量;也可以作為自變量,同時結合個人的“屬性”數據,共同解釋其他的研究變量。注意這里雖然同時考察屬性和關系變量,但他們是彼此獨立的,即不同于開篇提到的將兩者結合進行研究的情況,這個內容在第二部分探討ERGM的應用前提時一并論述。
個體網較為常見的“關系”變量包括:關系強度、彼此之間的互惠性、親密性、同質化或多元化等,也包括關鍵的指標比如中介性以及閉合程度等(brokerage and closure)。
具體來看,以“關系”為因變量,“屬性”為自變量的研究,可以分析個人的性格(內向或外向等)如何影響個人討論網的多元化程度以及個人政治參與的積極性問題[3],或者網絡使用是否會改變個人討論網絡的多元性問題,因為線下討論網絡的關系一般是同質性的,那么網絡使用增加了多元化接觸的機會是否會改變多元化個人討論網絡的性質[4]?當然這里的“關系”變量可以不僅存在于個人中,也可以存在于國家間,探討國家間在臉書平臺上的友誼關系構建被哪些因素所決定,最后發現有效的影響因素包括:是否具有共同的邊境,語言,文明類型以及移民流動[5]。
另外,在社會網的研究中,很早即關注了因種族隔離帶來的空間上社會隔離的問題,因為同樣種族的人通常更喜歡聚居在一起,但是新技術產生之后能否突破這種空間上的限制,形成多元化的跨種族之間的溝通,就成了一個非常有價值的問題。例如,有學者研究了手機的使用對種族隔離的效果,最后發現,是形成多元化還是保持社會分層,最終要看個體的屬性,主流群體通常通過ICT使用維持和加強自己的組內溝通(in-group),強化已有的優勢,證明了社會分層理論;而少數派群體則是通過ICT的使用加強自己的多元化溝通(out-group),證明了社會多元化理論[6]。
更多的研究集中在以“關系”為自變量的研究當中。
如以“關系”強度為自變量的研究,可以分析諸如強弱連帶對使用者的志愿行為、慈善捐助行為態度的影響程度[7],對個人的社會耐受力(social tolerance)的影響[8]。除了強度以外,個體網還會單獨討論個體網中某個點的中介性和閉合程度,把他們作為重要的自變量,Shen等檢驗個人游戲網絡的中介性和閉合程度在進行MMOG(多人線上游戲)過程中,如何影響他們游戲任務的完成水平以及和其他玩家的信賴程度[9]。
在政治傳播的研究中,個體網研究的核心集中在個人討論網絡(discussion network)的研究中,主要關注群體討論的同質性或者多元化的問題。例如,討論多元化和同質化是否會影響公民政治參與(political participation)程度的問題[10],討論網絡多元化和意見極化程度關系的研究也是這個領域中主要關注的內容之一[11]。
可見,在個體網研究中,無論是屬性變量、關系變量分別成為自變量、因變量,還是兩者共同作為獨立的自變量,兩者都是首先被認為是相互獨立的兩個要素,這種獨立雖然會被后面的研究提出一定的質疑,但是不可否認的是在SNA普及之后,它依然有其自身的意義,而且這類研究依然活躍,畢竟個人網的存在狀況是整體網的基礎。
二、組織傳播側重歷時性研究
在總結和展望未來的組織傳播研究趨勢與重點時,Monge等提到了兩個大的方面:一是組織的歷時性發展與轉變(change and development over time);二是分屬不同層次的個體、小的組織單元、組織之間的彼此關系研究(relationships among people,units,organizations,and meanings),即他一直強調進行多層次(multilevel)結合的研究[12]。
Monge等人提到的應該把研究的側重轉移到歷時性研究上,已經在近七年的研究中得到了充分的體現[13]。可以說近七年的組織傳播研究很多使用的都是歷時性數據,進行的都是網絡變遷的研究。
不過在研究歷時性變遷的過程中,屬性變量和關系變量常常被結合起來考察,這一點與上述個體網絡相對獨立分析兩者形成了鮮明的對比。能夠把兩類變量結合起來的重要原因是新的分析工具的出現:ERGM和SIENA。這兩個模型除了能夠解決點屬性和關系屬性結合分析以外,還有一個重要的特點在于可以處理彼此非獨立的個體,因為社會網絡數據本身是有關聯的,而以前建立在個體獨立性假設基礎之上的“標準”統計方法(例如回歸分析等)用在這里是不合適的[14]。
這里需要強調的是ERGM和SIENA在對關系變量和屬性變量進行分析時,會把兩者分別轉為兩類變量:一類是內生變量,一類是外生變量。內生變量實際上就是網絡中的關系變量,例如網絡中心度、互惠性、傳遞性、中心勢和網絡密度等等,它們本身被用來闡釋關系的結構趨勢;而外生變量則是網絡個體的屬性,是除了關系屬性以外的其他屬性,包括成員屬性(如年齡、性別等),這里的內生變量不可由外生變量預測,而兩者都用來解釋網絡的結構趨勢[14]。無論是內生還是外生變量,都是多層次(multilevel)的:內生變量可以包含個體層面的中心度,二元層面的相互性、互惠性,三元層面的傳遞性、循環性;而外生變量可以包含個體層面的年齡、性別,二元層面的屬性相同性,比如同年齡、同黨派等等。
兩者影響網絡結構的方式可以通過具體的計算來實現:即對比某個變量影響下的網絡中建立關系的概率是否高于沒有該變量時。
以內生變量的點中心度為例,實際網絡當中具有更高中心度的點,更有可能與其他點建立連接,而這個計算只需要通過對比該點的實際形成連接比率與隨機產生的網絡中的點比率進行對比即可,如果對比結果顯著,則能夠說明中心度這個內生變量能夠影響網絡構建。如圖1,隨機網絡的獲取方式是:設定與實際觀測網絡相同的網絡大小、密度、度數分布值,然后獲取1000個隨機網絡,圖中的點為觀測值(即實際值),箱體為隨機網絡的相應數值范圍,如果點的取值在箱體圖外,則表明該值具有顯著性。
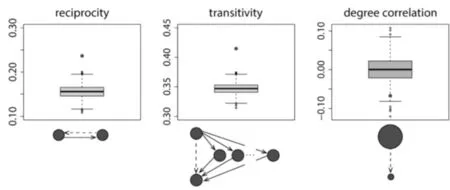
圖1 觀測網絡與隨機網絡之間的差異[15]
具體來看較為典型的組織傳播相關研究,如有學者探討與HIV有關的NGO網絡變遷過程,研究他們在選擇對外鏈接的過程中,是如何保留或者放棄相應的鏈接,不同的NGO屬性如何影響這種鏈接的選擇與變化[16]。
Margolin等則著眼于組織之間的一些重要事件的發生,比如新的規范的確立,對組織之間的關系構建產生怎樣的影響。例如新頒布的規范性內容對NGO網絡結構的影響,看組織會如何調整他們和老牌機構或者新興機構之間的關系,會更注意保留或者切斷哪些類型機構的聯系,網絡結構的互惠性或者傾向性(preferential attachment)是否會改變等,使用的分析模型是SEINA。[17]
更為明確的對于兩類變量的探討體現在下文的分析當中。
三、控制關系變量之后的屬性、關系效果對比
關系變量與屬性變量進行結合分析的典型例子反而并不是體現在兩者的共同效果上,而是體現在學者開始逐漸區分出“關系變量”與“屬性變量”兩者不同的效果中,下面我們來看兩個遞進的研究。
這兩個研究的核心初衷都是一致的,即認為此前新聞傳播學院的排名一般是依賴教師的研究論文數量等指標,但他們提出一個新的評估新思路:即用博士生畢業的流動情況來衡量這些院系的相關博士生項目(doctoral program)的質量好壞,主要考察的是各個項目輸出(student placement)和引入博士(faculty hiring)的情況,綜合考慮兩者來最終評定一個項目的好壞。
第一個研究由Barnett等完成[18],研究發現,對外輸出學生時,各種中心度,諸如closeness centrality,in-degree centrality,eigenvector centrality高的,學校的信譽度(reputation)也的確比較高,似乎用輸出能力評價學校的信譽度是可行的。
但2016年,賓夕法尼亞大學的幾位學者把Barnett的研究深入下去,最后卻呈現了完全不同于前述研究的結論。他們研究對象仍然是傳播學領域的PHD項目在雇傭(hiring)和輸出(placement)過程中形成的網絡,他們的最初目標也是希望找到一套不一樣的標準,能夠更客觀、更有效地評價現有的博士生項目。[15]
文章分析了2007—2014年7年之間的博士畢業生的流動狀況,但是最后發現教師雇傭(facultyhiring)并非簡單地反應博士教育的質量,這種雇傭的人才流動,其實具有內在的慣性。也就是說一些網絡的“內生變量”,包括網絡的互惠性、連通性(transitivity)以及累積優勢(cumulative advantage)是影響網絡結構的主要因素;而一旦控制了這些內生變量,則發現其他的“外生變量”,包括傳統的教學質量評價體系中重要的,如機構的美譽度(institutional prestige)、師資的年資(faculty seniority)、學校的排名情況等雖然部分要素仍會影響網絡構建,但效果相比來說十分微弱,只能被認為是影響博士雇傭與流動的次要因素,文章使用了ERGM模型進行上述分析。
所以文章結論指出,他們挑戰(challenge)了早先Barnett等的研究結論,博士的輸入與輸出并不是教學質量的反映,而主要源于結構的內生動力,人們在雇傭師資的過程中可能更多的是依照此前的經驗,身邊的朋友推薦,或者自己的個人網絡,雇傭行為更多的是一種內部信息的流轉。
這兩個連續的研究恰恰說明了本文在第二部分談到的問題,內生變量不可以由外生變量來預測,在個體彼此具有較強相關性的前提下,傳統的統計工具可能會得出錯誤的結論,這也是ERGM等模型應用的價值所在。
這種逐漸把內生變量和外生變量進行區分的研究,在近三四年中開始逐漸豐富起來。比如有研究發現相比以前提出的個體的性格、動機、能力、社會政治地位等因素,一般的討論以及網絡相關的內生性因素(general discussion and network-endogenous factors)是個人討論網構建以及互動模式的更好的預測指標,文章也使用了ERGM模型進行了上述關系屬性與點屬性的分離,分別討論了內生變量與外生變量的作用。[19]
還有研究把網絡結構的影響效果從個人是否使用社交媒體中分離出來,他們希望能夠解釋個人在網絡中獲得社會支持(social support)的感知,是因為個體在不斷使用社交網絡(比如在臉書上更新自己的狀態或者與他人私聊),還是因為個人的網絡結構本身?結果發現,如果控制了網絡結構這個內生變量,社交媒體的使用行為中臉書狀態更新(status updates)仍然與社會支持(social support)的感知呈現正相關,但是行為使用中的私聊行為(private messaging)原本與情感的社會支持感知是顯著正相關的,但是控制了網絡結構之后,這種顯著性消失了。所以作者提出應該重視網絡結構本身對于社會支持感知的影響。[20]
較為典型的組織傳播研究也開始類似的探討。如關注組織內眾包行為,針對雇員網絡以及創意網絡兩類網絡,從結構上分別探討網絡結構效果(結構上的馬太效應)與點屬性(包括地理同質性、是否同為高級職員等)對于創意網絡討論情況的影響。研究發現,從結構上來講,存在顯著的馬太效果:一些創新度超級活躍的雇員的中心度很高,中心度很高的創意吸引了大多數雇員的注意。而從點屬性來看,如果控制了上述的關系屬性,則地理同質性與支持相同創意的相關度雖然顯著但是微小;而資歷高的人并未比資歷淺的人的更愿意在眾包平臺上表達支持某個創意,也就是說該相關缺乏顯著性[21]。
上述各個領域對于關系變量與屬性變量進行分離分析的研究似乎在表明,結構本身具有自己的內在動力與邏輯,雖然個體在構建網絡結構時依據了自身屬性,但是在這種網絡構建完成之后,關系屬性可能就具有了更強的反作用,甚至超越個體屬性本身。
當然上述研究也表明,并不是每一次對內生的變量控制之后,所有的點屬性都會變得不顯著,也說明這種結構的內生性需要進一步深入探討。
四、全網環境下的整體網相關研究
之所以本部分確定為全網環境下的整體網研究,與前幾個部分的區分主要體現在兩方面:一方面是數據來源,前述研究的數據多采用個體報告的方法,部分組織傳播研究采用二手數據,而本部分的數據則多來自網絡直接抓取;另一方面是研究視角,本部分主要研究側重整體網的結構研究。
當然數據和視角都是相對而言的,因為有些研究的數據來源方式其實很多元,網絡抓取、問卷調查、深度訪談等等都會出現,但網絡抓取是主要的數據來源方式;研究視角也可能既有個體網也有整體網兩方面的探討,但是整體網視角為主要考量。
(一)結構化網絡聚類與屬性挖掘
全網環境下的整體網分析中,較多的研究集中于最終形成的網絡結構,尤其是網絡聚類(cluster),這種結構本身是整體網分析最關注的問題,使用的方法通常是社會網絡分析軟件中的各種聚類分析,當然這種分析的工具正在不斷演進中。
較早的該類型研究多是對超鏈接進行分析,如有兩篇全面描述博客網絡的文章,一篇是描述阿拉伯世界的博客[22],另一篇則是分析古巴的博客[23]。在對阿拉伯世界的博客分析中,文章通過分析發現博客形成小團體(clusters)的界限標準,首先為國界,大體分為埃及、黎巴嫩、敘利亞、沙特阿拉伯以及科威特,此外還有一個圈落為橋群體,主要是既說阿語,又說英語的群體,因此語言成為第二個邊界形成要素。而在每個國家的內部圈落形成的情況又各不相同。其中,埃及為最大的圈落,主要分為世俗改革派(secular reformist sub-cluster)、廣泛的反對派(wider opposition sub-cluster)、埃及青年組織(Egyptian Youth)等等。
更多的研究則集中在政治黨派個體之間的關系狀態,看兩者是否會形成同質化的結構圈子。典型的研究如有韓國學者研究了韓國政治領導人的線上可見(visibility)網絡,選擇了18th National As-sembly的278名成員,分析了他們之間網頁上的共現(co-occurrence)網絡,共現網絡出現了明顯的結構極化。[24]
群體的聚類研究也可以體現在某個具體的事件中,學者研究2008年韓國網上出現的反對進口美國牛肉的抗議事件,最后發現,雖然開始的時候不可避免地出現兩個對立的群體,但是后來隨著主要的關鍵性blog開始提供中立的意見,導致了最后中立群體的不斷擴大,因此文章認為網絡公共空間是可控的[25]。
可以看到,SNA的整體網結構研究中,尤其是超鏈接的研究中,“屬性”變量也可以被看作類似為因變量,或者類似數據挖掘后呈現的一種研究發現,是基于分析工具進行聚類之后產生的研究結果,而不是對事先假設的驗證,比如研究最終發現了政黨、文化、國家、正反兩種意見的不同圈落。
需要注意的是,上述研究都是發現了不同群體形成各自的聚類的。同樣是研究政治派系,或者話題沖突,也會出現完全相反的結果。
例如,Dvir-Gvirsman的研究對象是以色列的普通民眾,在搜集了民眾選舉前七周的網站訪問數據(web logs直接獲取的行為數據)后,他發現以色列民眾對于不同意識形態的網站的關注(左翼或者右翼)基本不存在差異,人們的網站瀏覽是非常多元化的,并沒有出現回音室效果,即沒有選擇性注意的情況;通過社會網分析方法獲得了訪問各類網站的社會網絡圖,也并沒有出現類似美國的分立格局。[26]
與韓國發現的事件討論中中立群體的擴大不同,一個形成鮮明對比的研究關注的是政治傳播中的謠言傳播問題,最后發現Twitter沒有很明顯的自我凈化的功能,因為在同質化的網絡結構中,傳謠者會形成一個黨派化(partisan)的結構,核心的群體只傳播對手的負面信息,而且拒絕更正謠言;相反,拒絕謠言者沒有辦法形成一個明確的團體結構,或者形成一個集中的社群,所以從整體來看,謠言的拒絕率只有3.37%。[27]
產生上述的研究結果差異,是因為兩對研究分別選擇分析了不同的群體屬性(普通民眾VS政治精英),不同的話題屬性(政治謠言VS事實選擇),因而造成最后的結構分析出現了不同的結果。這些對于群體屬性或者話題屬性的控制與選擇其實并不出現在研究本身當中,主要是學者們在選題時的考量因素,因此只是在這里作為一個與本文相關的內容稍做討論,這種屬性體現的更多的是一個研究語境,或者研究背景問題,但是無疑是非常重要也容易被忽略的一種“屬性”數據。
回到結構化的呈現與屬性挖掘,類似的研究還有從受眾中心角度,探討受眾中心網絡與互聯網基礎設施結構(technical infrastructure)網絡的不同,最后研究發現后者的網絡是中心化的,而前者的網絡是去中心化的,受眾中心網絡主要依靠語言進行區分,文化的區隔是核心[28]。同樣從受眾中心的角度出發,有研究對新媒體時代受眾碎片化結構提出了駁斥,作者以觀看的節目為節點(node),超過一定比例的重復受眾則會構建一個連接,最后通過社會網絡分析發現,受眾在觀看236個媒體節目過程中,有很大一部分是重復的,而并沒有形成所謂的孤立的忠實受眾。因此作者對不少文化學者提出的網絡時代會形成大量平行的文化提出了自己的質疑。作者認為未來的受眾的中心集中度仍然會很高,不應該迷戀所謂的長尾,受眾的分離,贏者通吃(winner-take-all)仍然是主要規律。[29]當然,如果增加了前面對于研究對象的背景性考慮之后,研究就會更加深入,例如后期的學者又針對這個話題進行了跨國家的研究,結果發現更嚴重的碎片應該發生在不同的小的、新興的媒體之間,而大媒體的受眾重合度還是非常高的。[30]
可以看到,大數據的挖掘體現出的屬性差異還相對有限,基本都是以國家、語言、文化等差異為主,分析發現的維度并不多,缺乏更豐富的闡釋深度。
(二)整體網中的屬性自變量
在整體網中,屬性數據也有不少直接做類似自變量的,但針對這種“點屬性”,基本上進行的都是描述性的說明,沒有更多的量化方法直接支持關于點屬性方面的判斷。
如學者研究了國際音樂貿易的相關情況,通過2002—2006年5年的數據分析發現:美國、歐洲國家,包括德國、英國、荷蘭處在貿易的中心地位。從五年的時段分析來看,這種結構非常穩定[31]。這里,研究者其實是直接通過對數據的總結,得到了中心節點大多來自歐洲國家這個屬性化的總結。用同樣的理念,有研究分析了世界互聯網的物理連接狀態,8年間的網絡密度從0.03增加到了0.034,MENA(中東北非)國家在8年中有不少進入了網絡的中心圈,包括阿聯酋、卡塔爾、埃及以及沙特阿拉伯,但是整體來看發展仍然符合強者恒強的規律。另一個有趣的發現在于,政治運動會通過互聯網進行傳播,阿拉伯之春是在中東北非的網絡連通進入中心圈之后迅速產生的[32]。可見,對國家的地理屬性的分析,歐洲、中東、北非等是這類研究的主要發現維度,而且這種發現相對簡單,只是對網絡構成的一種現象性的總結。
還有一類研究雖然對點屬性進行了更為量化的分析,但是采用的分析工具是傳統的SPSS對均值差異進行顯著性檢驗。
例如,有學者發現女性學者相較于男性學者只能獲得更少的學術引用,這種性別的差距在學術引用時依然非常明顯。作者首先通過引用網絡分析得到了個體被引以及引用的相關數據,然后對包含性別在內的各項類目進行多維度的ANOVA分析得到了上述結論。作者采用了社會網的視角來解讀,之所以出現這一現象是因為女性較難構筑自己的學術共同體,相比較而言,男性更傾向于與同性別的人進行學術合作。[33]如果從個體具有較強相關性的角度來看這個數據分析,可能就會有一定的質疑。
當然在全網數據環境下,也出現了使用ERGM等方法進行分析的結構性研究。如有研究關注美國國會議員在Twitter上的關注網與互動網,結果發現關注網呈現了很強的黨派同質性,影響互動網同質性的因素包括是否屬于同一個州、黨派、大眾關注(public concern),如果控制了網絡的內生變量之后,這種同質性程度會降低,所有的連接,包括關注連接和互動連接的存在本身都會增加投同質群體票的幾率。[34]
(三)語義網絡
語義網絡的相關研究是社會網絡研究當中不可缺少的一部分,也被認為是大數據環境下開始取代內容分析的一種方式。[35]但是單純的語義研究與本文的相關度不大。例如在研究埃及革命的語義表達時,revolution一詞的中心度最高,而protest則非常邊緣,體現了大家對此次事件的定性[36];或者幾個中國學者研究中國人現階段的隱私觀念,用新浪微博上18000條包含“隱私”一詞微博構建一個詞匯“共現”語義網絡,然后通過聚類分析(cluster analysis)發現11個不同的語義網絡等等[37]。因為語義本身具有自己的含義,直接對其分析即可,因此多數都從框架理論或者詞義角度進行分析,也可以從議程設置理論等視角直接進行分析[38],這與屬性數據的研究并沒有關系。
但是如果語義網絡與使用者網絡結合進行分析,使用者屬性就成為影響語義網絡的重要要素,使用者屬性成為自變量。
如學者討論美國Twitter上群體互動的模式(pattern),主要進行兩類研究:第一,在預先選定的幾個關鍵詞之下,考察用戶(user)之間相互轉發而形成的彼此連接情況,會發現用戶大體分為多少個群組(cluster),這是話題討論主題的聚類分析。第二,在群組之內,分析每條信息(message)的政治傾向,進行內容編碼;同時看每條信息中提供了哪些鏈接,對鏈接的內容進行編碼。這部分是話題立場分析。每個話題都選擇了最近對此話題發表看法的500個使用者(node)。最后發現:從群組的角度看,極化明顯,不同的群組中,自由派與保守派的比例呈現顯著差異。而且圈子當中意見表達的信息條數數量越多(無論左右,加總的總量越多),則自由派與保守派比例相差越懸殊,也就是說群體極化越嚴重。[39]
隨后Himelboim等考察了每個話題網絡中的情感取向問題。他們發現一個網絡當中有一種占主導的情感。整個討論大致形成正向、中心和負面三種情感分別主導的圈落。而每個圈子的情感是哪種屬性主要與其話題的內容、話題的意識形態有關,自由主義有更多的肯定性情緒,而保守主義則更多的是否定性情緒。該文是同質性的一次擴展,作者認為可以說發現了“情緒回音壁”(affective echo chambers)。[40]
五、我國的SNA研究
前面分析的研究都是來自國外傳播學頂級期刊中發表的文章,它們在方法的傳承上有較為明顯的脈絡,發展相對連續、有邏輯。本部分則主要考察一下國內的相關研究狀況。
與國外SNA相對清晰的脈絡不同,我國傳播學中的SNA研究一開始就體現出對“關系研究”的極大興趣,尤其是與整體網結構相關的內容,諸如網絡中心勢、各類中心度、網絡密度、網絡子群等等。主要原因是我國開始較為豐富的SNA研究時就已經是社交網絡相對較為盛行的年代,學者亟須對社交網絡進行整體化、結構化的分析。因此,相比國外延續社會學傳統,關注個體網中屬性數據的重要性不同,我國的屬性研究是非常有限的。比較典型的,如羅昕等在對廣州的兩個跑群的分析中,發現交流環境、組織管理、專業指導、社會資本、忠誠度等因素是影響虛擬社群信任網絡生成的重要因素。[41]韋路等研究了各國的媒介機構在Twitter上的網絡構建情況,發現除了所在大洲的發達程度外,社會化媒體使用程度、地理接近性和文化接近性等國家因素都能夠顯著預測媒介機構之間的雙向鏈接關系。[42]
在大量的SNA研究中,成果最為豐富的領域是在知識圖譜方面。主要體現出學者們期待能夠更系統地了解國外在某類研究方面的現狀,從而為具體話題的研究者提供一個全景性的認知導引,減少因為語言在閱讀和了解文獻上面的早期障礙,這部分研究大體都是純粹的結構性分析,加上一些描述性內容,基本沒有與屬性變量結合進行復雜量化分析的案例。例如劉毅對國外輿論學研究的“知識圖景”的研究[43],包洪巖等對健康傳播學的知識圖譜的可視化研究[44],陳艷紅等對國外微博研究熱點、趨勢及研究方法的分析[45],丁漢青等對境外傳媒經濟研究熱點與場域的探索[46]等等。
當然國內關于網絡結構的各項指標的研究也會涉及各種熱點話題,比如近期對于“一帶一路”高峰論壇在Twitter上傳播的子群結構的研究[47]。
值得注意的是,我國已經有青年學者開始關注屬性與關系之間的競爭關系,這體現出年輕學者與國際學術研究正在逐漸接軌。張倫在分析社交網絡中的好友關系構建時,考察了個體特征、對偶特征以及網絡結構特征對在線關系構建的影響,結果發現,網絡結構特征相比于其他特征對于個體在線關系的構建更為重要[48],這一結論與第三部分Mai等人的研究[15]是非常一致的,即發現了既有的結構性因素其實超越了個體的屬性因素,成為網絡關系新連接的核心影響因素。
六、結語:關系與屬性數據的再結合
Shumate等曾經把社會網絡分析的諸多研究依據他們之間形成關系內容的不同,劃分為四種類型:親近關系(affinity)、信息流(flow)、所屬關系(representational)以及語義網絡(semantic)。[35]他們認為依據“關系”進行分類的方法適用于人際、組織、大眾、健康、政治傳播以及計算機中介傳播(CMC),打破了傳統的依據點狀態區分為人際、組織、群體、大眾的習慣性思維。從這種分類的思路中可以看出社會網絡學者們期待從社會網絡的“關系”視角重新審視和思考傳播學的諸多子領域的研究。
而Cappella在2017年也發表了一篇文章[49],談大眾傳播與人際傳播未來的研究方向,他提到其中的一個方向就是未來需要融合人際傳播與大眾傳播,融合的方式就是從因素(factor)的研究,或者說是變量(variable)研究過度到個體(actor)的研究。他也強調,以前對于變量或者說因素的研究前提是作為變量載體的人是彼此獨立的,但是如果人是彼此聯系的,可能就需要轉換思路,把研究的核心換為個體(actor),這是社交網絡普及的今天所需要的。基本的理念就是個體作為多個變量的攜帶者(carrier),以前是K個獨立的個體擁有N個變量的模型,而現在則是擁有一個N?K變量的模型,可以認為變量是一種對大眾傳播過程的描述,而個體則體現了對人際傳播結構的重視。代理人基模型(agent-based modeling,ABM),當然也包括多層次模型(multilevel models)可以實現上述目標,作者非常期待傳播學者能夠運用各種新的研究工具,同時考量個體與變量兩類內容。
以ABM為例,該模型的主要理念是把現實抽象為個體(agent)和環境(environment),個體可以是任何具有主動性的主體,包括個人、公司、國家等,然后把個人與環境、個人與個人的互動抽象為可表達的數學公式。比如,在群體暴力模型中可以抽象出的個體為激進分子、平民和警察,三者都會與環境互動,三者之間彼此也會互動。如果平民會產生暴力行為的影響因素之一是其群體具有的憤怒情緒,而該情緒的憤怒程度可以抽象為:專制性?(1-合法性),即主體對政府的專制程度以及合法性的態度的函數,可以代表該主體的憤怒指數。當憤怒指數到達角色轉變點時,平民會發生角色轉變,成為激進分子;類似的,還可以構建多個模型,包括主體被警察抓到的概率等等,當概率超過一定水平時,主體會放棄轉變為激進分子。當所有的變量間以及變量和環境間模型構筑好之后,通過仿真模型再現群體暴力的場景,進而從定量的角度分析產生暴力行為的動力學特征。[50]
Cappella從大眾傳播與人際傳播結合的角度賦予了“關系”變量與“屬性”變量結合的一個更廣泛,也更具理論內涵的意義。隨著新的技術的發展,社會網絡研究的學者應該也會在個體與屬性的結合上繼續進行探討,而不僅僅局限在現在使用較多的ERGM和SIENA模型,后兩者的研究雖然基于關系數據與屬性數據的結合處理,但是最終解決的問題相對單一,即兩個點之間構建連接的概率是否大于隨機網絡下構建連接的概率,側重點仍然在于網絡的構建,未來應該期待更為豐富的方法與理論的支持。
猜你喜歡
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
天津外國語大學學報(2021年3期)2021-08-13 08:32:18
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
電子制作(2018年18期)2018-11-14 01:48:24
汽車工程學報(2017年2期)2017-07-05 08:13:02
山東工業技術(2016年15期)2016-12-01 05:31:22
中國中醫藥現代遠程教育(2014年11期)2014-08-08 13:23:44
