自適應的SVM增量算法*
2019-05-07 06:02:16韓克平
計算機與生活 2019年4期
何 麗,韓克平,劉 穎
天津財經大學 理工學院,天津 300222
1 引言
隨著現代計算機和信息技術的發展,數字信息爆炸式增長。為了滿足用戶快速準確的信息查詢需求,分類已經成為智能信息檢索的關鍵技術之一,且在模式識別、圖像處理和自然語言處理等領域得到了廣泛應用。SVM(support vector machine)算法具有較高的分類準確率和較好的魯棒性,被廣泛應用于解決分類問題[1-2]。為了獲得最佳的數據分布估計,傳統SVM算法需要將全部待學習數據作為訓練樣本一起訓練。但是,隨著數據規模的指數級增長,實際應用中逐漸增加的數據會產生新的分類需求,傳統SVM分類算法難以滿足這些新的分類需求。增量學習方法是解決這些問題的有效方法之一。增量學習一方面可以根據增量樣本的特征分布來動態調整分類決策函數,從而保持較高的分類準確率;另一方面,相較于重新訓練一個系統的時間成本更低。
SVM訓練的最終目的是根據訓練集樣本在特征空間的分布來確定最優超平面,確定最終超平面的樣本被稱為支持向量。在SVM增量學習過程中,最優超平面會隨著訓練集中樣本特征空間分布的變化而被動態調整。因此,如何將最有可能成為新支持向量的樣本加入到增量訓練集中是SVM增量學習的關鍵。目前,大多數基于SVM的增量學習算法通過將更多對超平面劃分有影響的樣本加入到新訓練集中的方法來改進SVM增量訓練過程。Syed等人最早提出了基于SVM的增量學習算法[3],該算法僅保留支持向量樣本,舍棄所有非支持向量的樣本。當新樣本加入訓練時,將原支持向量集與新增樣本集合并形成新的訓練集。該算法充分考慮了新增樣本對分類結果的影響,但是忽略了原訓練集中的非支持向量與新增樣本在特征空間分布上可能存在差異,在某些情況下會導致分類器最終性能下降。文獻[4-5]通過判斷KKT(Karush-Kuhn-Tucker)條件的方法調整訓練集,在增量學習過程中僅使用不滿足KKT條件的新樣本,忽略了新樣本加入時最優超平面的變化,可能會造成分類知識的丟失,導致分類準確率下降。文獻[6-7]以入侵檢測為背景,用環形區域選擇法和half-partition選擇法構建保留集來選擇初始樣本并進行增量訓練,但是這種方法會使加入保留集的樣本存在冗余或漏選的現象。李妍坊等人[8]在文獻[6-7]的基礎上,提出了基于縮放平移選擇法構建保留集的方法,同時將部分新增樣本加入到保留集中,該算法縮小了保留集的選取范圍,但是仍未解決保留集冗余的問題。Zheng等人[9]提出了一種基于學習原型和支持向量的在線增量SVM算法,該算法不僅支持樣本增量學習,而且支持類別增量學習。劉國欣[10]通過將增量樣本的邊界向量與原樣本的邊界向量進行合并,形成增量學習的訓練集,該算法在提取邊界向量時重復計算不同類別樣本之間的距離,導致時間復雜度較高。Li等人[11]提出了一種基于超平面距離的SVM增量學習算法,該算法根據支持向量的幾何特征,利用超平面距離提取樣本,選擇最有可能成為支持向量的樣本形成邊界向量集,但是該算法沒有考慮到新增樣本和原始樣本在增量學習訓練中對模型影響的差異性。
上述這些SVM增量學習算法雖然獲得了較好的分類性能,但是存在樣本冗余和信息缺失等問題,可能造成分類器性能不穩定或者訓練時間效率較低。本文根據SVM結構化風險最小的優化目標,提出了一種基于超平面幾何距離的自適應SVM增量學習算法,該算法根據樣本到超平面的幾何距離,以不同的權重篩選出新增樣本和原始樣本集中包含分類知識的樣本。該算法能夠在保持較好分類準確率和魯棒性的前提下,有效控制參與增量訓練的樣本規模,從而減少SVM增量學習的訓練時間。
2 SVM理論基礎
SVM分類器訓練目標是在特征空間中找到一個最優超平面,使訓練樣本的分類間隔最大[1]。假設給定訓練數據集為 {(xi,yi)},i=1,2,…,n,xi∈Rm,yi∈{+1,-1}。則設超平面方程為:

在實際問題中有些數據會存在噪聲,出現離群點,為了降低離群點對分類模型的影響,引入“松弛變量”ξi≥0,用以表征樣本點xi偏離函數間隔的程度。同時,為了最大化間隔同時保證誤分點個數最少,引入一個常數C>0作為懲罰參數,可將優化問題描述為:
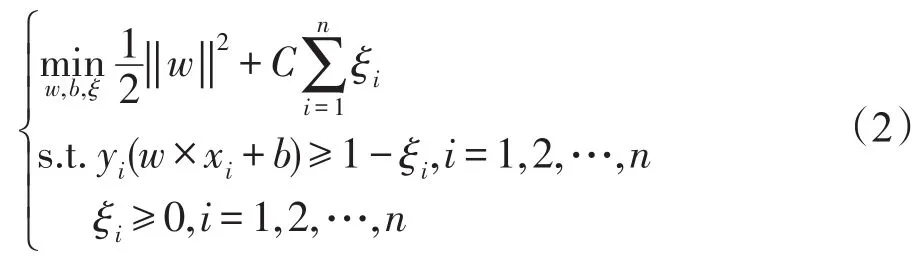
其對偶問題為:
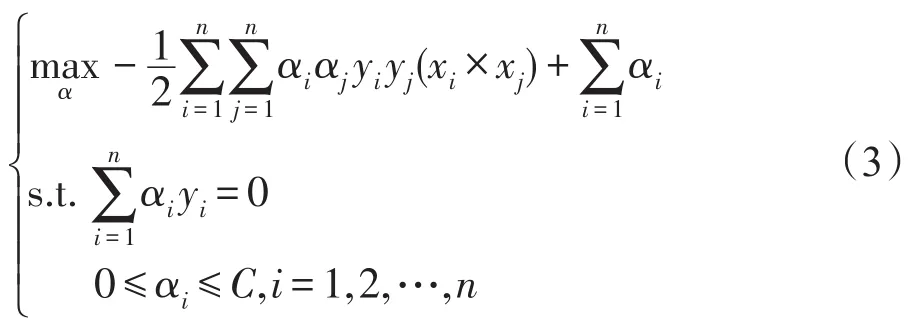
其中,αi為拉格朗日乘子。通過求對偶問題的最優解α=[α1α2…αn],使得每個樣本都滿足優化問題的KKT條件:
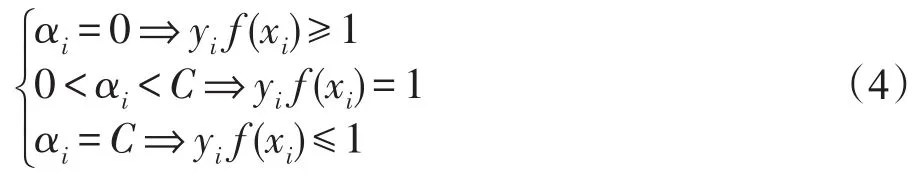
從KKT條件的定義可以看出,αi=0時,其樣本對決策函數沒有影響;αi>0時,對應的樣本為支持向量。
由此可知,只有訓練集中的支持向量對分類超平面有影響,因此,在訓練集不變的情況下,支持向量集和訓練集是等價的。但是,新增樣本加入時,可能會導致這種等價關系的破裂。根據文獻[12]的研究結果,當新增樣本全部滿足KKT條件時,新增樣本的加入不會影響當前的支持向量集,分類器的決策函數不會發生改變;若存在不滿足KKT條件的新增樣本時,支持向量集會發生改變,當前分類器的決策函數也會隨之發生變化。文獻[13]也提出,當新增樣本中存在違背當前分類器KKT條件的樣本時,原始樣本集中的非支持向量有可能在增量訓練中轉化為支持向量。
圖1中用S0表示原始訓練集,S1表示新增樣本集,原樣本集中靠近超平面1/3處的樣本用黑色圓圈標出,用與分類超平面平行的紅色直線劃出距離超平面1/3處樣本與超平面之間的樣本。其中,(a)表示新增樣本集與原始樣本集分布基本一致時的分類超平面的變化,(b)表示新樣本集與原始樣本集的數據分布變化較大時的分類超平面的變化情況。從圖中可以看出,新增樣本的數據分布對原模型的分類超平面有直接影響。
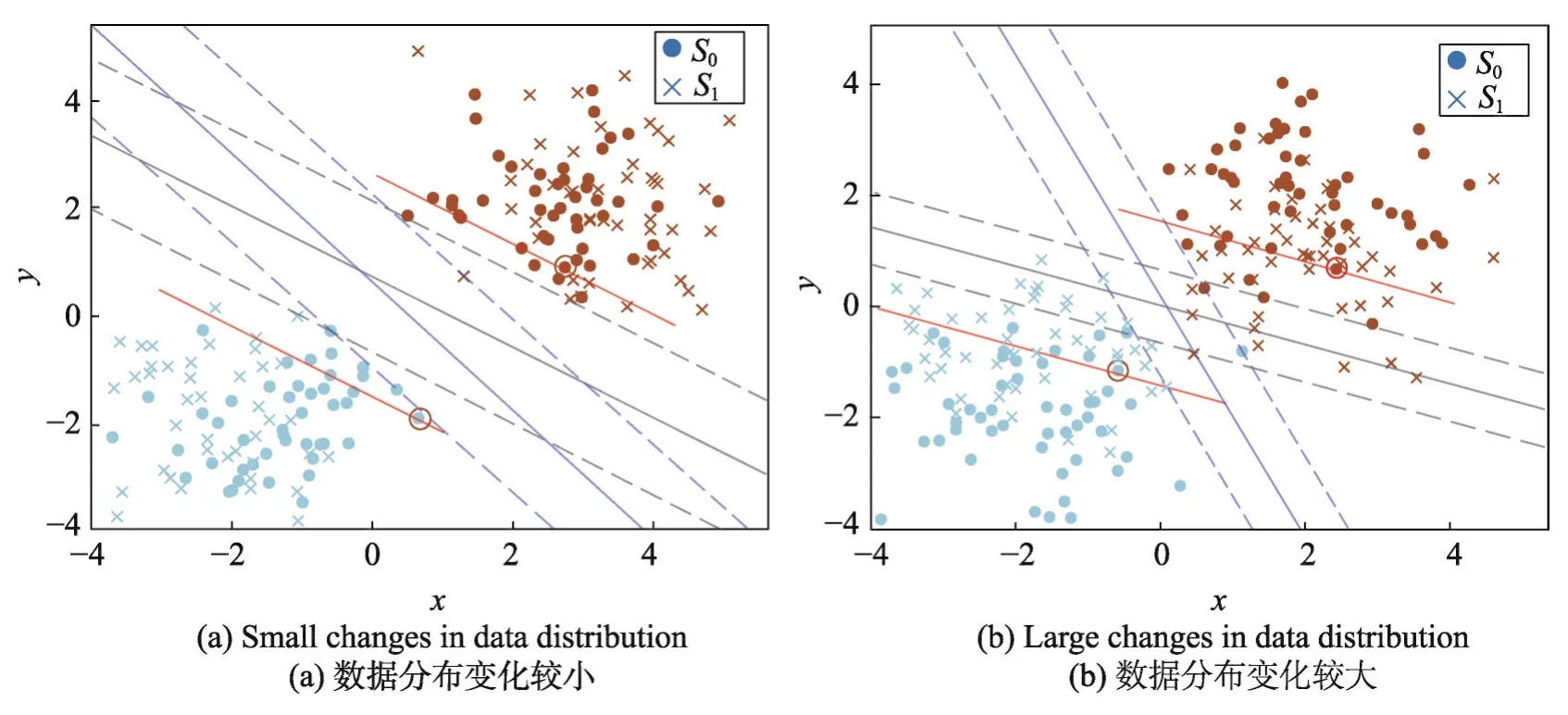
Fig.1 New samples influence on SVM classification圖1 新增樣本對SVM分類面的影響
在圖(a)中,由于新樣本集中不滿足原模型KKT條件的樣本較少,因此在新樣本集S1加入后,分類超平面的偏轉較小,并且,原模型訓練集S0中距離超平面較近的部分非支持向量變成了支持向量。
在圖(b)中,新樣本集S1加入后,由于新樣本集的數據分布變化較大,使得分類超平面的偏轉較大。并且,從圖中可以看出,新樣本集中滿足原模型KKT條件的部分樣本也變成了新模型的支持向量。
同時,從圖1中可以看出,在增量過程中,樣本成為新支持向量的可能性與其到超平面的幾何距離有關。在超平面發生偏轉后,原模型非支持向量集中轉化為新模型支持向量的樣本,大都位于原樣本集中靠近超平面1/3處的樣本與分類超平面之間。
3 自適應的SVM增量學習算法
根據樣本的空間分布特征以及支持向量集的變化規律,本文提出了一種自適應的SVM增量學習算法(self-adaptive incremental support vector machine,SD-ISVM)。該算法以增量樣本和新增樣本空間分布的相似性為調整系數,分別為原訓練集和增量樣本集設置不同的篩選閾值,并根據樣本到超平面的幾何距離確定邊界向量。
定義1(幾何距離) 給定樣本集D={(xi,yi),i=1,2,…,n},xi∈Rm,yi∈{+1,-1}和超平面 (w,b),樣本點 (xi,yi)到超平面(w,b)的幾何距離γi的計算方法如式(5)。

3.1 原模型保留集構建方法
在現有的增量SVM算法中,許多學者在進行增量學習時,都會考慮到原模型中非支持向量樣本,但是大部分算法沒有考慮增量情況的不同,而且保留方法比較復雜,從而造成算法效率偏低。實際上,當原始樣本集與新增樣本集的分布相似時,原樣本集中的邊界向量在新模型支持向量中占比較高;反之,原始樣本集中的邊界向量在新模型支持向量中占比較低。在增量過程中,原模型中非支持向量成為新模型支持向量的可能性與其到超平面的幾何距離的大小有關,并且從圖1的支持向量變化情況分析可知,原始樣本集中的邊界向量大都在距離超平面幾何距離1/3處的樣本與原模型的分類超平面之間。為此,本文選擇樣本到超平面的幾何距離作為篩選條件來構建原模型保留集。在設定原模型保留集的篩選閾值時,根據原樣本集和新增樣本集的分布變化情況,使用sim函數來實現閾值的動態變化,以減少原樣本保留集的冗余。
為方便表達,令原始樣本集中正例樣本到超平面幾何距離的集合為,原樣本集中負例樣本到超平面幾何距離的集合為,且集合中樣本按γi的升序排列,D0為的并集。同樣地,新增樣本集中正例樣本到超平面幾何距離的集合為,新增樣本集中負例樣本到超平面幾何距離的集合為,且集合中樣本均按γi值升序排列,D1為的并集,m和n分別為集合中樣本的總數,。為了適應樣本空間分布的變化,引入了自適應閾值θold,計算方法如式(6)。
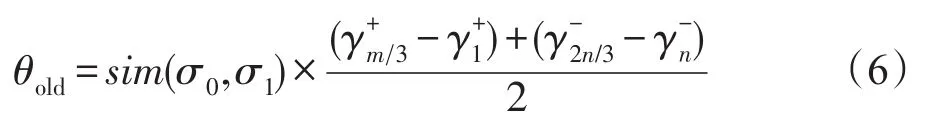
其中,σ0和σ1分別為D0和D1上的樣本總體方差;sim()是新舊樣本在特征空間分布的相似度計算函數,定義如下:
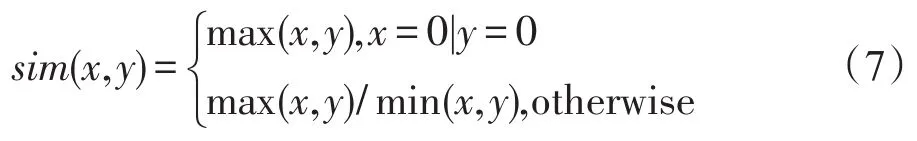
當增量樣本中出現不滿足KKT條件的樣本時,從原模型的非支持向量集中保留距離超平面幾何距離小于等于θold的樣本,加入到原模型的保留集中。
當篩選閾值設定的距離過大時,會造成保留集中樣本冗余,而設定的距離過小時,則可能丟失有用的分類知識。根據前面的分析,這里分別使用集合中靠近超平面1/3處的樣本與對應集合中最靠近超平面的樣本之間差值的平均來計算θold。其中,sim函數根據特征空間分布相似性來控制θold。為保持分類器的穩定性,當sim函數的值越大時,需要從原模型中保留的樣本數量就會越多;反之,當原樣本和新樣本在特征空間的相似度越高,即sim函數的值越小時,需要保留的樣本數量就會減少。
3.2 新增樣本保留集構建
目前流行的增量SVM算法在增量訓練時大多選擇舍棄新增樣本中滿足KKT條件的樣本,但是,從圖1的分析可知,當新增樣本中存在不滿足原模型KKT條件的樣本時,當前的SVM決策超平面和支持向量集都會受到影響,新增樣本中滿足原模型KKT條件的樣本也可能會成為新模型的支持向量。文獻[6]雖然考慮了這部分樣本的保留問題,但是沒有根據新增樣本滿足原模型KKT條件的具體情況進行討論,并且這些文獻中大都使用固定閾值進行樣本篩選,這樣可能會造成新增樣本保留集的過度冗余,從而影響模型的泛化性能和效率。同時,當新增樣本中滿足原模型KKT條件的比例不同時,分類超平面的偏轉情況也是不同的。針對這一情況,本文在確定新樣本保留集時,設置了動態的新樣本篩選閾值θinc,以適應不同增量特征分布的變化情況,θinc的計算方法如式(8)。
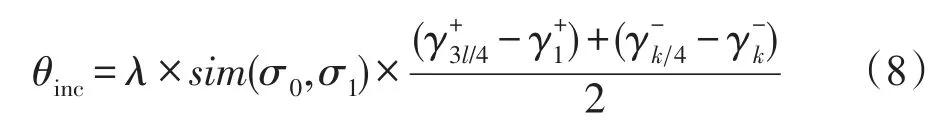
其中,σ0和σ1分別為D0和D1上的樣本總體方差;λ為基于當前模型分類準確率的調整系數,定義為:

式中,r為增量樣本中符合原模型KKT條件的樣本數占增量樣本總數的比例,表示增量樣本被正確分類的比例,l和k分別為集合中樣本的總數,。
考慮到新增樣本是首次參與SVM訓練,相比于原模型樣本保留集的構造,對新增樣本保留集的構建,分別使用集合中靠近超平面3/4處的樣本與對應集合中最靠近超平面的樣本之間差值的平均來計算θinc。
當增量樣本中出現不滿足KKT條件的樣本時,保留增量樣本集中滿足KKT條件且超平面幾何距離小于等于閾值θinc的樣本。
由圖1可以看出,增量樣本中滿足KKT條件的樣本越多,即r越大,新模型的分類超平面發生的偏轉越小,增量樣本中包含新分類知識的樣本就越少,因此,需要保留的樣本就越少;反之,增量樣本中滿足KKT條件的樣本越少,即r越小,新模型的分類超平面發生的偏轉越大,增量樣本中包含新分類知識的樣本就越多,最后需要保留的樣本就越多。為適應r的變化,這里使用λ動態調整篩選閾值θinc,當r變大時,λ減小,θinc也隨之減小,使得保留的樣本數減少;反之,增大λ,使保留的樣本數增加。
3.3 自適應的SVM增量學習算法
本文根據特征空間分布的相似性和樣本到超平面的距離,同時保留原樣本集和新增樣本集中滿足KKT條件的樣本蘊含的分類知識,提出了一種新的SVM增量學習算法SD-ISVM。SD-ISVM的算法描述如下:
輸入:原樣本集X0,新增樣本X1,當前原分類模型Ω0。
輸出:增量學習后的模型Ω。

4 實驗
4.1 實驗設計
為了驗證本文提出算法的可行性和有效性,使用了4個不同領域的開放數據集:APS、Mushroom、Bank和KDD Cup。實驗中將每個訓練集隨機分為10份,將其中的1份作為原始訓練集,其余作為新增樣本集1~9進行增量,并對每一次增量訓練產生的分類模型在測試集上進行測試。各數據集的訓練樣本、測試樣本個數和特征維度、正負樣本比例和各增量數據集與訓練數據集正、負類特征中心距離的均值如表1所示。
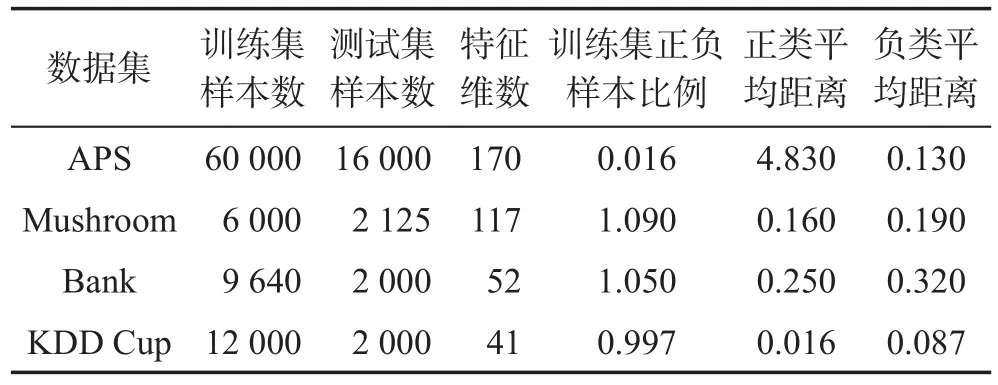
Table 1 Experimental datasets表1 實驗數據集
由表1可知,各個數據集上,新增樣本集與訓練數據集的特征分布存在一定的差異,尤其是APS的正、負類樣本比例與特征空間分布都表現出明顯的不平衡性,且正類增量樣本在特征分布上的變化較大。為驗證SD-ISVM算法的有效性和泛化性能,本文使用上述幾種不同特性的數據集進行了實驗,同時使用KKT-ISVM(Karush Kuhn Tucher-incremental support vector machine)[4]、CRS-ISVM(combined reserved set-incremental support vector machine)[8]、HD-ISVM(hyperplane distance-incremental support vector machine)[11]算法作為對比實驗項。實驗環境為24 GHz的Xeon e5-2630處理器,16 GB內存,軟件環境采用python 2.7.13。
4.2 性能評估
分類器的性能度量是對分類器的分類性能和泛化能力的評估,常用的評價指標主要包括:正確率、召回率、敏感性、特異性等。AUC(area under curve)是一種結合敏感性和特異性的性能評價指標。PACBayes(probably approximately correct learning-Bayes)邊界是分類器上最緊的泛化邊界,能夠用來評價學習算法的泛化性能[14-18]。本文使用PAC-Bayes邊界和AUC對SVM增量學習過程中產生的分類器泛化性能進行驗證和分析。
4.2.1 準確率和AUC
準確率表示被正確分類的樣本占總樣本的百分比。準確率越高,分類器的性能越好。正確率評價指標ACC的計算方法如式(10)。

其中,TP、FP、TN和FN分別表示真陽性、假陽性、真陰性和假陰性的樣本數量。
AUC表示“受試者工程特征”(receiver operating characteristic,ROC)曲線下方的面積。AUC的值越大,分類器的性能越好。假定ROC曲線是由坐標為{(x1,y1),(x2,y2),…,(xm,ym)}的點按序連接而形成的(x1=0,xm=1),則AUC計算方法如式(11)。
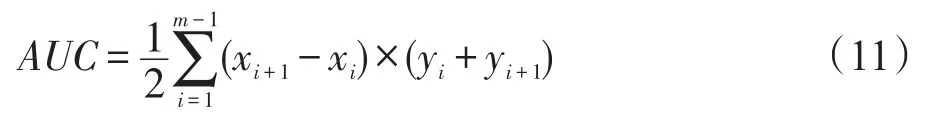
4.2.2 泛化誤差邊界
PAC-Bayes理論融合了Bayes定理和隨機分類器的優勢,能夠為各種學習算法提供最緊的泛化誤差邊界[14]。根據文獻[14]的PAC-Bayes定理,PAC-Bayes邊界越低,分類器的真實誤差越小,分類器的泛化性能會越好。因此,本文使用PAC-Bayes邊界來衡量SVM增量學習模型的泛化風險邊界。
4.3 實驗結果及分析
4.3.1 穩定性對比
圖2描述了不同算法在不斷加入增量樣本后AUC的變化情況,曲線的波動越大,表示算法的性能越不穩定;反之,說明穩定性越好。從圖2中可以看出,相比于其他3個數據集的AUC值能夠快速穩定在較好的水平,APS數據集在前4次增量訓練過程中出現了明顯波動。造成這種波動的原因是,APS數據集中的正負樣本比例和增量樣本特征空間分布均處于極不平衡狀態。即使在這種極不平衡的情況下,本文提出的SD-ISVM算法仍然能得到一個穩定且分類性能良好的超平面,這是其他幾種對比算法不能達到的。
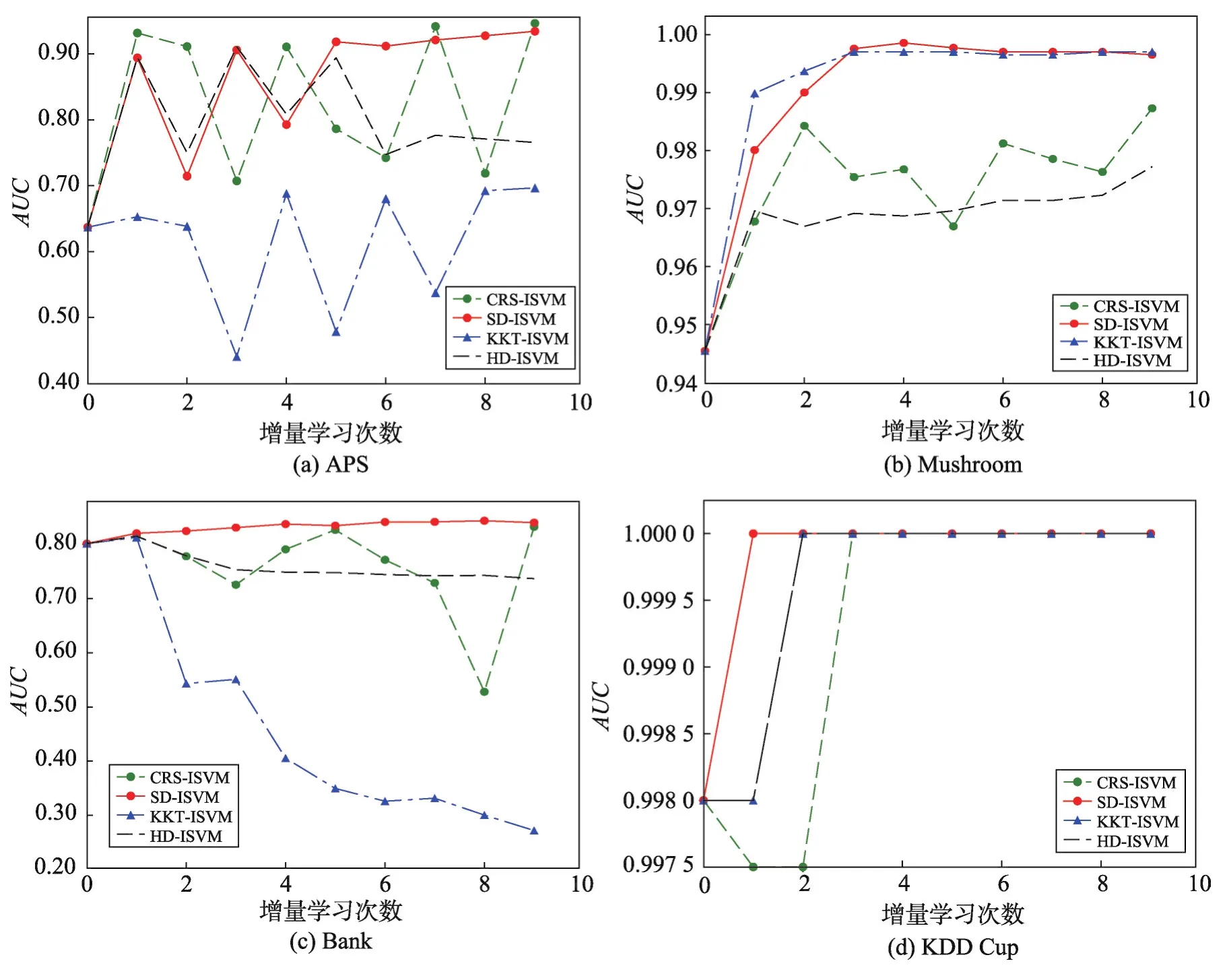
Fig.2 Contrast ofAUC圖2 AUC對比
對比各種算法在4個數據集上的AUC曲線可以發現,SD-ISVM算法在每個數據集上的AUC值總體上表現最好。分析原因主要是因為SD-ISVM算法在樣本保留的過程中,使用了支持向量的空間特征和增量過程中超平面的變化情況,盡可能地保留了新舊樣本中對分類決策函數有貢獻的樣本,彌補了其他算法在增量過程中分類知識丟失的問題,從而獲得了較好的穩定性。這說明本文提出的SD-ISVM算法具有更好的分類性能。
4.3.2 泛化能力對比
表2為各種算法在不同數據集上增量學習得到的模型PAC-Bayes最優邊界值和分類準確率,PBB(PAC-Bayes bound)表示PAC-Bayes最優邊界。分類準確率和PAC-Bayes邊界有很高的負相關性,即分類準確率越高,PAC-Bayes邊界會越低。對SVM算法來說,PAC-Bayes邊界越低,算法的分類邊界會越緊,分類器的泛化性能越好。分類準確率與PACBayes邊界的和越接近1,模型的分類效果越好。從表2中可以看出,在大部分數據集上,各算法的分類準確率與PBB之和均接近于1。在分類準確率相同時,CRS-ISVM、KKT-ISVM和HD-ISVM算法的PACBayes最優邊界都稍大于SD-ISVM算法。以上說明,SD-ISVM算法的模型泛化性能與其他算法基本保持一致,甚至會在某些數據集上高于其他算法。
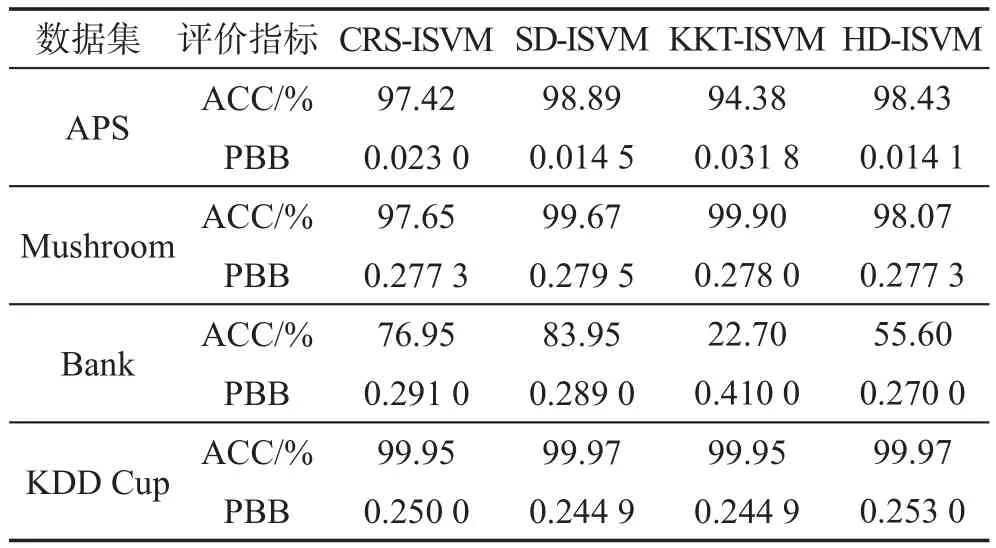
Table 2 Contrast of classification accuracy and PBB表2 分類準確率和PBB對比
4.3.3 訓練時間對比
圖3描述不同算法在各個數據集上增量訓練時間對比情況。從圖中可以看出,在APS和Bank數據集上分類時間最長的算法是KKT-ISVM,這是由于KKT-ISVM算法在進行增量時需要多次訓練分類器;在Mushroom和KDD Cup數據集上CRS-ISVM算法分類耗時最多,是其他算法的2~3倍,這是因為CRSISVM算法計算保留集的時間復雜度不會隨著數據集的復雜度降低而減少。同時可以看出,在大多數數據集上,本文提出的SD-ISVM算法都獲得了較好的結果。SD-ISVM在增量學習訓練集構建時,可以根據新舊數據集在特征空間分布的相似度變化自動調整新舊樣本的篩選閾值,適應增量樣本在特征空間分布的變化,從而有效地控制增量學習訓練的規模,提高分類器訓練的速度。
從上述的實驗結果對比可以看出,在所有實驗數據集上,相比于其他三種典型的SVM增量學習算法,本文提出的SD-ISVM算法在模型的穩定性、泛化能力和訓練時間上總體上保持了較明顯的優勢。相比于其他幾種算法,SD-ISVM算法不僅解決了有貢獻樣本丟失問題,還有效減少了樣本冗余,加快了增量學習的速度。
5 總結
針對現有的SVM增量學習算法在增量過程中分類知識丟失以及時間效率偏低的問題,提出了一種基于特征空間分布的SD-ISVM算法,該算法不僅保留了原始樣本集和增量樣本集中滿足KKT條件的邊界樣本,還根據新舊樣本在特征空間分布的變化情況,從新舊樣本集中篩選出滿足KKT條件但可能在增量學習過程中轉變為支持向量的樣本參與訓練,以減少新增樣本加入時分類知識的丟失,并控制參與增量學習的邊界樣本數量,來提高分類速度。實驗結果表明,本文提出的SD-ISVM算法能夠在保持較好分類準確率的前提下,獲得更好的穩定性和SVM增量學習的訓練速度。
Fig.3 Contrast of training time圖3 訓練時間對比
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
