自然最近鄰優化的密度峰值聚類算法*
2019-05-07 06:02:30錢雪忠
計算機與生活 2019年4期
金 輝,錢雪忠
江南大學 物聯網工程學院 物聯網技術應用教育部工程研究中心,江蘇 無錫 214122
1 引言
聚類分析是對一組數據對象或者物理對象進行處理,最終將對象分成幾類,使得同一類對象之間的相似度更大,不同類對象之間的相似度更小。聚類分析已經應用在了數據挖掘、圖像壓縮、圖像邊緣檢測、基因識別、面部識別和文檔檢索等領域。
在聚類分析的發展過程中,相繼提出了K-means、DBSCAN(density-based spatial clustering of applications with noise)[1]、FCM(fuzzy C-means clustering algorithm)、AP(affinity propagation)等一系列的聚類算法文獻。2014年Science[2]上發表了一篇“Clustering by fast search and find of fast search”,論文提出一種快速搜索和發現密度峰值的聚類算法。該算法能自動給出數據集樣本的類簇中心,而且對數據集樣本的形狀沒有嚴苛的要求,對任意形狀的數據集樣本都能實現高效的聚類。該算法的核心思想是認定聚類中心同時滿足兩點基本要求:(1)本身的密度很大,即它的周圍鄰居點的密度均沒有它大;(2)與比它密度更大的數據點之間的“距離”更大。然而DPC(clustering by fast search and find of density peaks)算法的劣勢和難點不容小覷:(1)各個領域在使用DPC算法的時候,截斷距離是該算法必須設定的參數,人們一直是手工設定該參數,手工設定存在一定的隨機性和人為因素,影響聚類質量。(2)對較高維度數據的分析處理一直是DPC算法的短板,較高維度數據自身結構擁有稀疏性和空間復雜性,使得傳統的歐式距離在反映數據對象之間的相似性時無法達到準確、合理的目的,因此導致該算法失效。(3)雖然DPC算法聲稱能自動確定聚類結果,但在實際聚類操作中卻需要手動進行聚類結果的選定,聚類結果不能自動給出。
針對DPC聚類算法存在的不足,Zhang等[3]結合該算法和 Chameleon(hierarchical clustering using dynamic modeling)算法,提出了E_CFSFDP(extended fast search clustering algorithm:widely density clusters,no density peaks),解決了CFSFDP(clustering by fast search and find of density peaks)算法中無法處理一個類簇中有一個以上密度峰值點的問題,但是該算法的性能有待進一步提高并且在處理高維數據上的能力有待加強。Liu等[4]提出一種基于K近鄰(Knearest neighbor,KNN)的快速密度峰值搜索并高效分配樣本的算法KNN-DPC,解決了CFSFDP算法聚類結果對截斷距離dc比較敏感和因為一步分配所帶來的連帶分配錯誤的問題,但是該算法的聚類結果對近鄰數K的選取比較敏感。Bie等[5]提出了Fuzzy-CFSFDP算法,將模糊規則用于CFSFDP算法的類簇的中心點確定中,提高了類簇中心點選取和聚類結果的準確率,但在處理復雜數據[6-9]時稍顯不足。
本文針對上述遇到的問題,提出了自然最近鄰[10-11]優化的密度峰值聚類算法(optimized density peak clustering algorithm by natural nearest neighbor,TNDP)。TNDP算法自適應地、不需要參數地、根據每個點的特征來獲得不同的鄰居數,以此來計算每個數據點的局部密度,根據類簇中心局部密度大和被稀疏區域劃分[12]的特點來確定聚類中心,最后引入類間相似度的概念來合并相似度高的類簇。實驗證明,TNDP算法具有更加優秀的聚類效果。
2 自然最近鄰居
最近鄰居概念在早先就已經被提出,且被廣泛應用于模式識別、機器學習等領域。最著名的就是Stevens所提出的兩個鄰居概念,K-最近鄰[13-15]和ε-最近鄰。K-最近鄰的思想是給定一個數據集,設置一個參數K,然后每個數據對象在數據集中找到K個與自身相似度最大或者距離最小的數據對象。ε-最近鄰的基本思想是給定一個數據集,設置一個參數掃描半徑ε,然后求出每個數據對象在其掃描半徑ε內的近鄰數,這樣使得每個數據對象在掃描半徑ε內的近鄰數有可能不同。無論是K-最近鄰還是ε-最近鄰,其近鄰的搜索都是靠人為地設置參數得到的,而不是根據所給數據集自身的特性搜索。
自然最近鄰居(natural nearest neighbor,TN)是一種新的最近鄰居概念[16],它是一種無尺度的最近鄰居,這也是它與K-最近鄰和ε-最近鄰最大的不同之處。自然最近鄰居的基本思想就是數據集中密集區域的數據點擁有較多的鄰居,稀疏區域的數據點擁有較少的鄰居,而數據集中最離群的數據點只有幾個或沒有最近鄰居,自然最近鄰居的特點是計算過程不需要任何的參數,數據點根據數據集自身的屬性特點獲得準確鄰居,鄰居數由于數據的密集程度存在差異,由于噪聲點和異常點沒有鄰居,因此正常點也不會把噪聲點和異常點當作鄰居。
定義1(自然最近鄰居) 基于自然鄰居搜索算法,如果點X屬于點Y的鄰居,而點Y屬于點X的鄰居,那么點X和Y屬于彼此的自然鄰居。
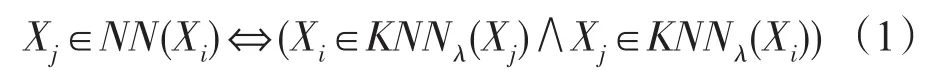
定義2(自然特征值supk) 根據TN-Searching算法,每個點有不同數量的鄰居,對于任何點i,鄰居數量是nb(i)。但是TN-Searching有一個平均數量的鄰居,稱為supk,它是自然特征值。計算supk的公式如下:
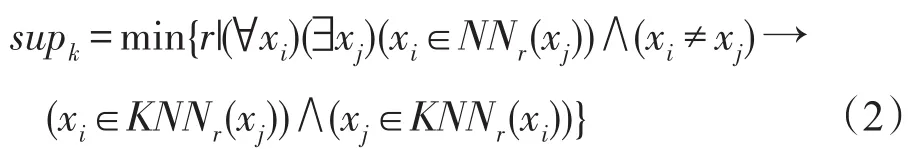
定義3(R-鄰域(R-neighbor))findKNN(xi,r)表示KNN搜索函數,它返回xi的第r個鄰居,KNNr(xi)是X的子集,定義如下:
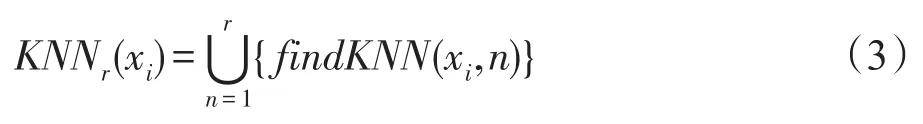
算法1TN-Searching


3 TNDP算法
定義4(數據點的密度Den(Pi)) 基于自然鄰居定義的密度如下:
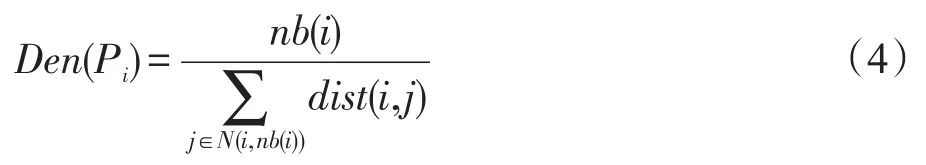
這里nb(i)是根據TN-Searching算法得到的每個點的自然鄰居數,N(i,nb(i))是點i的nb(i)個自然鄰居,dist(i,j)是數據點i和j之間的距離。
定義5(代表點(exemplar)) 數據點q的代表點定義為:
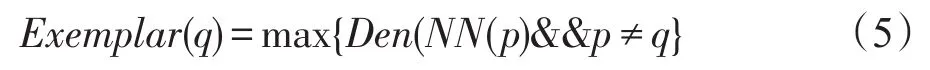
定義6(密度峰(density peak)) 如果數據點p滿足如下條件,就稱數據點p為一個密度峰:
二是建立完善管理責任制度。在天津日報公布了133條(段)納入河長制管理的河道和57名“河長”名單,由“河長”對河道水生態環境管理負總責。各區縣出臺了具體的實施方案,細化分解落實責任至街鎮、單位,有的區縣還明確了街鎮級河長。各區縣制定了保潔養管及巡查制度,組建或利用已有保潔隊伍,對河道進行日常保潔,全市水生態環境管理責任制初步建立。
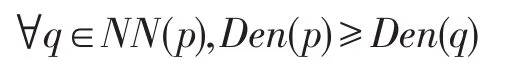
定義7(類間相似度(similarity between clusters))

|Ci?Cj|指的是類Ci和類Cj的公共部分,supk是自然鄰居特征值,Sim(Ci,Cj)的值不小于0,如果這兩個相鄰的初始簇被稀疏區域劃分,則這兩個簇之間的相似性將很小,是兩個單獨的集群。相反,如果這兩個相鄰的初始簇通過密度區域連接,則這兩個相鄰簇之間的相似性會很大,然后這兩個集群將被合并為一個集群。
定義8(稀疏鄰居和密集鄰居(sparse and dense neighbor)) 如果數據點q的密度小于數據點p的密度且q是p的自然鄰居,則稱q是p的稀疏鄰居,相反如果數據點q的密度大于等于數據點p的密度且q是p的自然鄰居,則稱q是p的密集鄰居,定義如下:
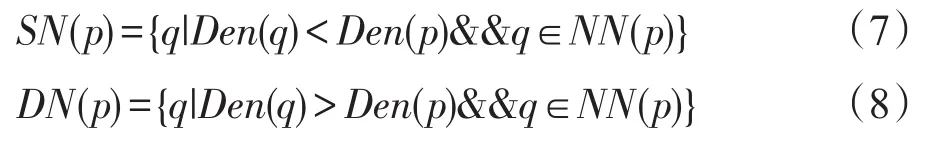
算法2TNDP


根據以上理論,提出TNDP算法,TNDP算法的主要優點:(1)用自然最近鄰居來計算數據點的局部密度,不需要參數,避免了參數敏感問題;(2)用自然最近鄰居計算局部密度,由于自然最近鄰居準確反映數據點的屬性特點,因此這樣計算出來的局部密度能準確表示每個數據點的密度大小,提高聚類效果;(3)由于自然最近鄰居不包含噪聲點和異常點,因此TNDP算法減少了噪聲點和異常點對聚類結果的影響。
TNDP算法的主要流程:
步驟2使用定義5和定義8找到每個數據點的代表點和稀疏鄰居;
步驟3找到所有的密度峰并任意訪問一個密度峰,將它和它的稀疏鄰居分到同一個聚類;
步驟4任意在這個簇中找到一個點,并將這個點的稀疏鄰居和這個點分類為同一個簇,直到這個簇的所有點都被訪問過;
步驟5找到一個未訪問的密度峰并重復上述步驟,直到所有的密度峰都被訪問過;
步驟6劃分好初始類簇,根據初始類簇之間的相似度關系,合并相似度高的初始類簇;
步驟7將類簇中數據個數小于最小自然鄰居數的類簇從聚類結果中除去,并將這些類簇中的數據標記為噪聲點,獲得最終的聚類結果。
如圖1所示,綠色點同時被分類為C1和C2,相似度大于α,C1和C2合并成一類,如果相似度小于α,那么綠色點將被分類到其代表點所屬的集群中。α值越大,聚類越多。實際上,TNDP算法在參數α的選擇上是魯棒的。
因為TNDP算法使用k-d樹來求自然鄰居,所以TNDP的算法復雜度為O(n×lgn)。
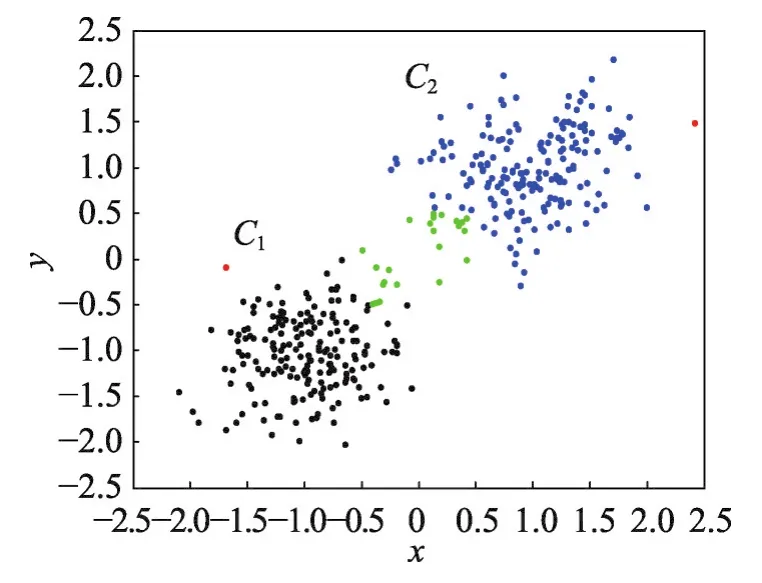
Fig.1 Intersection ofC1andC2圖1 C1和C2的交集
4 實驗結果與分析
為了證明TNDP算法的有效性,將TNDP算法與DPC、DBSCAN、K-means算法在合成數據集和真實數據集上進行實驗,圖2顯示了4個合成數據集。Data1是由兩個流形類組成,共1 500個點。Data2是由3個復雜流形類組成,共3 603個點。Data3由3個球形類、2個復雜流形類和1個稀疏密度類組成。Data4由6個高密度復雜流形類和一些噪聲點組成。對于DPC和DBSCAN算法,進行多次實驗取效果最好的結果進行對比,對于K-means假設事先知道所要劃分的類數進行實驗。
圖3顯示了Data1在DPC、DBSCAN、K-means和TNDP算法上的聚類效果。DPC算法雖然能聚類正確的類簇數,但無法將所有點準確聚類,聚類效果不好,流形簇相互靠近的地方無法正確聚類。K-means算法同樣無法準確聚類兩個流形簇相互靠近的地方,聚類效果不好。DBSCAN算法和TNDP算法都能準確聚類,聚類效果都不錯,明顯比DPC和K-means算法聚類效果要好,但DBSCAN算法需要更多的參數設置。
圖4顯示了Data2在DPC、DBSCAN、K-means和TNDP算法上的聚類效果。DPC和K-means算法雖然選擇了正確的類簇數,但無法將所有點準確聚類,聚類效果不好,只是將復雜流形簇距離近的點聚為一類,DBSCAN聚類算法和TNDP算法都能準確聚類,聚類效果都很好。
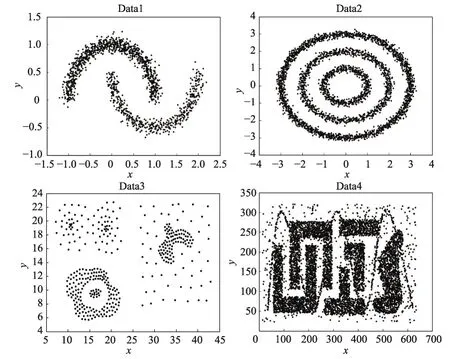
Fig.2 Original datasets圖2 原始數據集
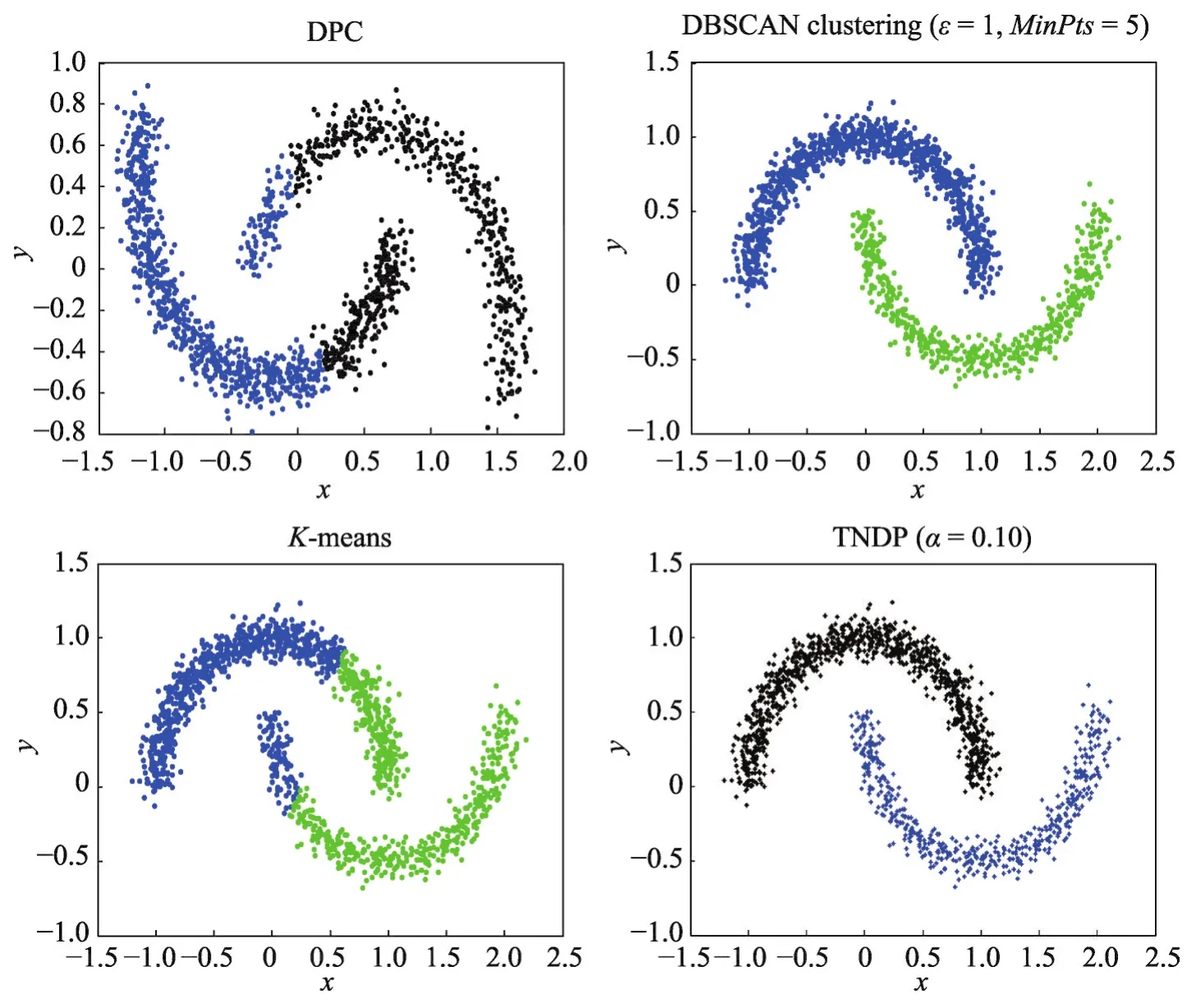
Fig.3 Clustering results of DPC、DBSCAN、K-means and TNDP on Data1圖3 Data1在DPC、DBSCAN、K-means、TNDP上的聚類結果
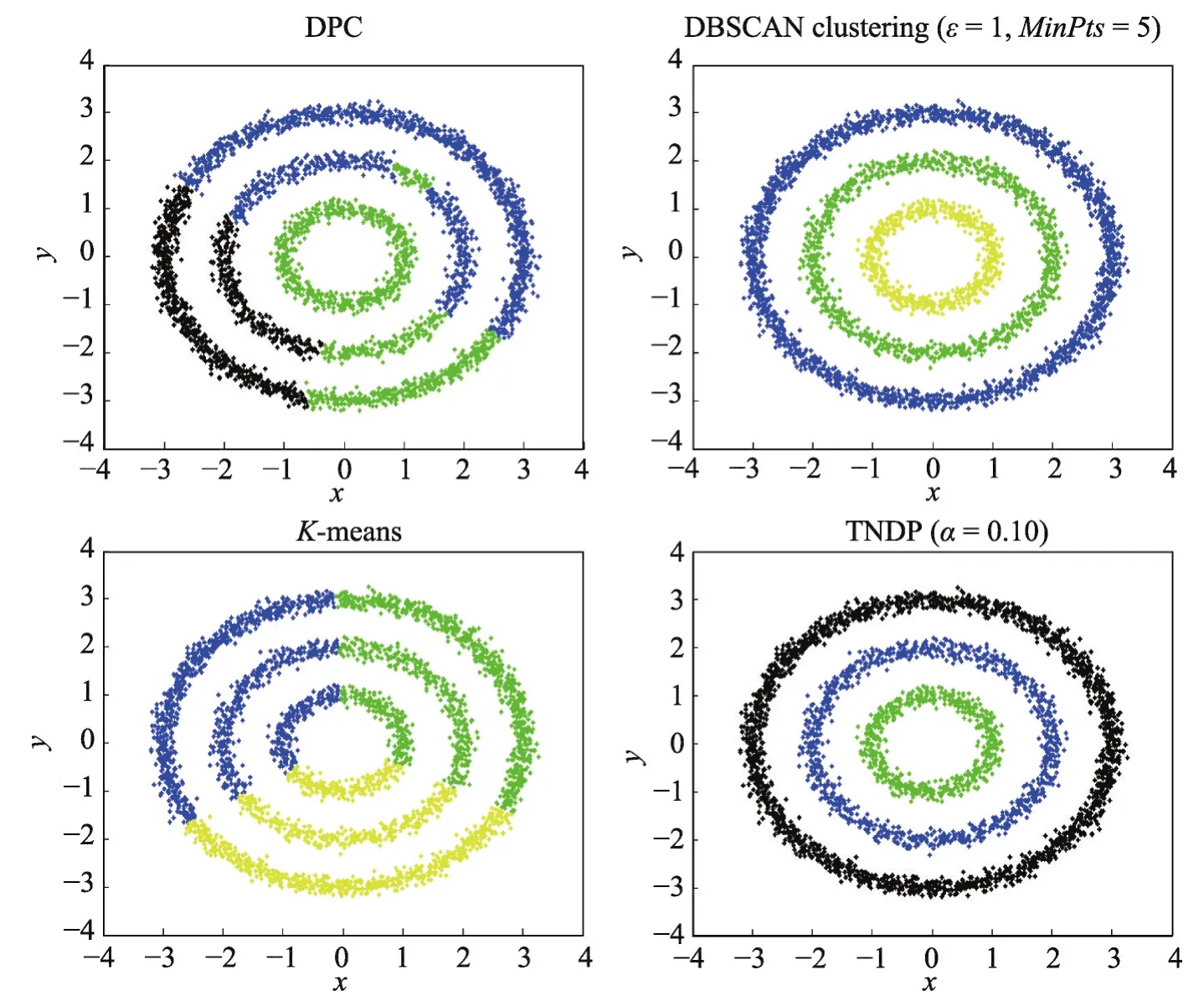
Fig.4 Clustering results of DPC、DBSCAN、K-means and TNDP on Data2圖4 Data2在DPC、DBSCAN、K-means、TNDP上的聚類結果
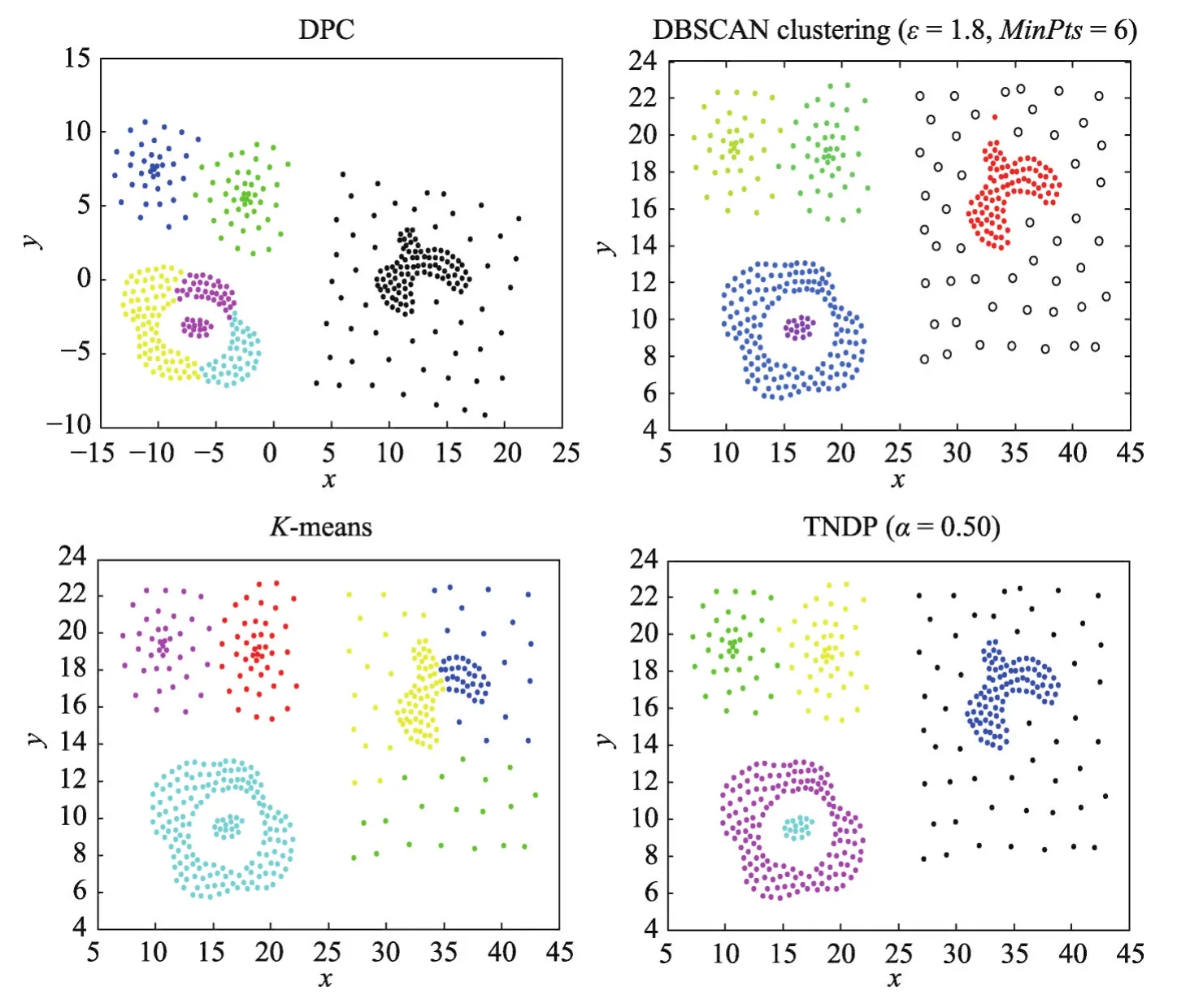
Fig.5 Clustering results of DPC、DBSCAN、K-means and TNDP on Data3圖5 Data3在DPC、DBSCAN、K-means、TNDP上的聚類結果
圖5顯示了Data3在DPC、DBSCAN、K-means和TNDP算法上的聚類效果。DPC算法對球形簇的聚類效果很好,對復雜流形簇也有一定的聚類效果,但是對Data3顯然沒有取得很好的聚類效果,K-means可以聚類球形簇,但是對復雜流形簇聚類效果不好,顯然DBSCAN聚類效果優于DPC和K-means算法,對球形簇和復雜流形簇都有很好的聚類效果,但是對于密度差異較大的類簇聚類效果一般,將一些正常點當作噪聲點,也錯誤地將不同類簇的點聚為一類,TNDP算法聚類效果比DBSCAN更加優秀,不僅準確聚類球形簇和復雜流形簇,對密度差異較大的類簇也準確聚類。
圖6顯示了Data4在DPC、DBSCAN、K-means和TNDP算法上的聚類效果。DPC和K-means算法雖然選擇了正確的類簇數,但對復雜流形簇的聚類效果不好,只是將復雜流形簇相對距離近的點聚為一類,DBSCAN獲得了正確的類簇數,也檢測出了噪聲點,但是正常類簇中的一些點也被DBSCAN視為噪聲點,盡管TNDP未能檢測到Data4中的噪聲,但TNDP獲得了正確的聚類數并正確聚類了所有正常點。
因此,TNDP算法在Data1、Data2、Data3、Data4上的聚類效果明顯優于DPC和K-means算法,在Data3、Data4上的聚類效果明顯優于DBSCAN,且比DBSCAN需要更少的參數,并且對參數的設置具有一定的魯棒性。
接著,將TNDP算法在真實數據集上進行實驗,數據集信息如表1。
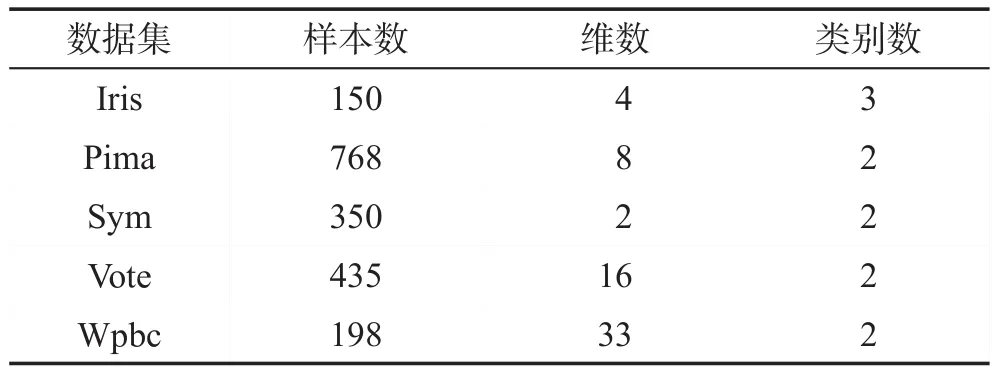
Table 1 Information of datasets表1 數據集信息
在實驗中,采用Acc(準確率)、F-Measure(加權F值)這兩個聚類指標來評價TNDP算法,并將TNDP算法與DPC、DBSCAN、K-means算法對比。
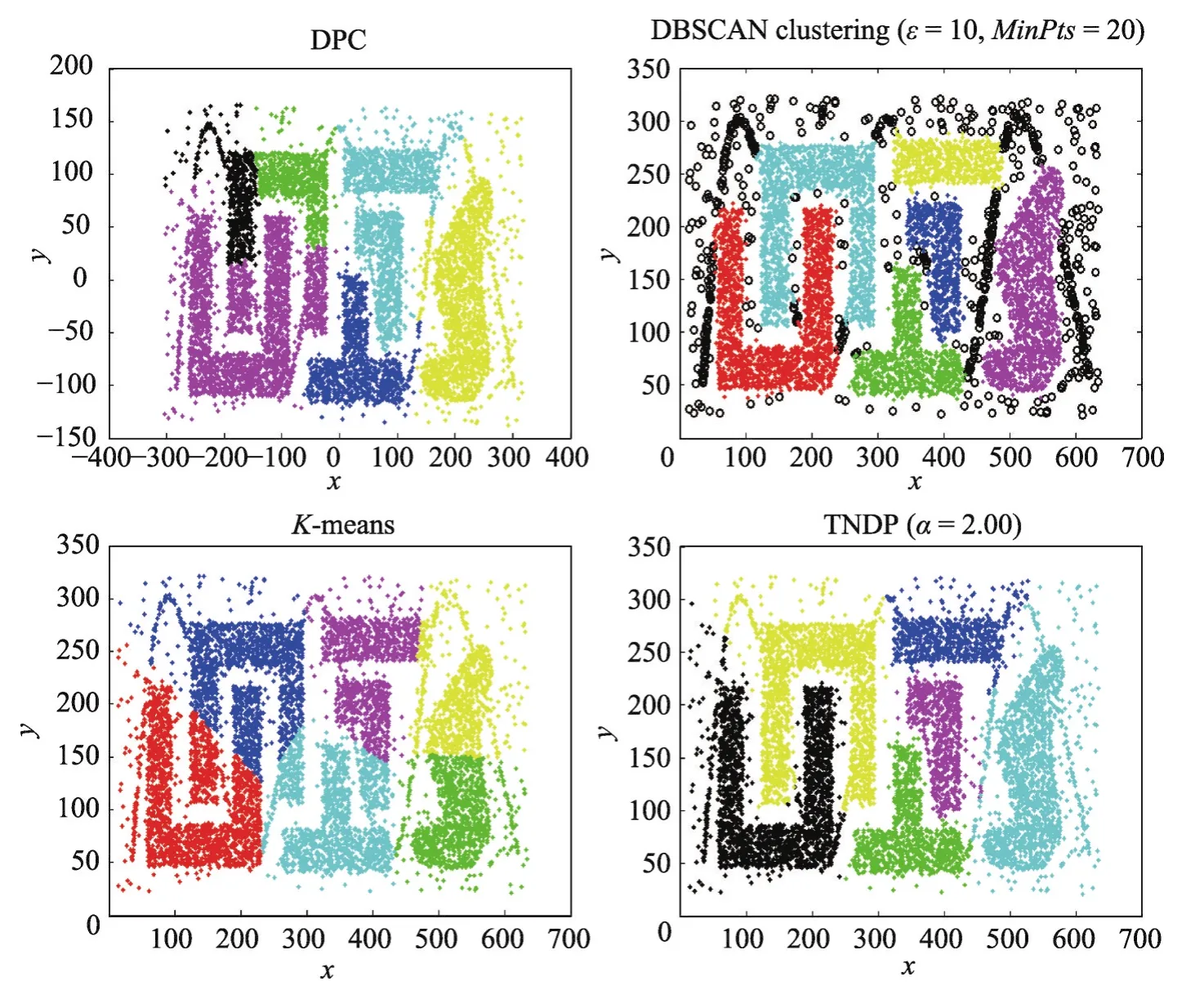
Fig.6 Clustering results of DPC、DBSCAN、K-means and TNDP on Data4圖6 Data4在DPC、DBSCAN、K-means、TNDP上的聚類結果
由表2可知,在準確率上,TNDP算法要明顯優于DPC、DBSCAN、K-means算法,在F值的計算上,除了在Wpbc數據集上DBSCAN要優于TNDP算法,其他數據集上都是TNDP算法要明顯優于DPC、DBSCAN、K-means算法,且對這幾個數據集TNDP算法都能聚類出正確的類數。綜合這三方面,顯然TNDP算法是最優秀的。
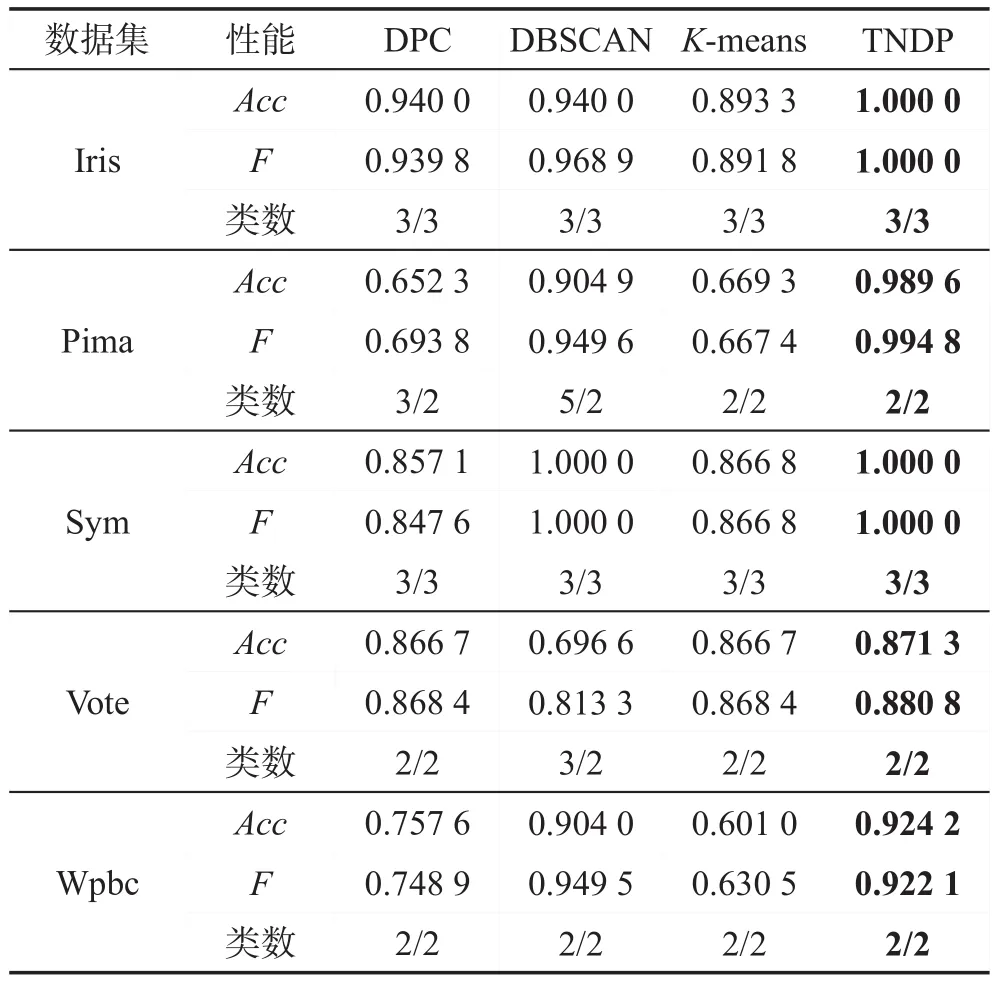
Table 2 Information of clustering index表2 聚類指標信息
TNDP除了在聚類效果上的優越性,在對參數的選擇上也具有一定的魯棒性。如圖7所示,在不同的參數α的選擇下,聚類效果依舊沒有發生變化,只有當α從0.01提高到2.00時,聚類結果才出現了一點點偏差。
因為受到自然最近鄰居的影響,一個類簇中相似初始簇的類簇間相似度會在一個小的范圍內波動,不同類簇之間的相似度一定很小,甚至為0,所以對參數α的取值不是那么敏感。做實驗時一般取所有數據個數的1/100與自然特征值的比值作為初始α。如果α取值過高,原本屬于一個類簇的數據會被分成多個類簇;如果α取值過低,可能原本兩個相似度很小的類簇會被分成一個類簇。
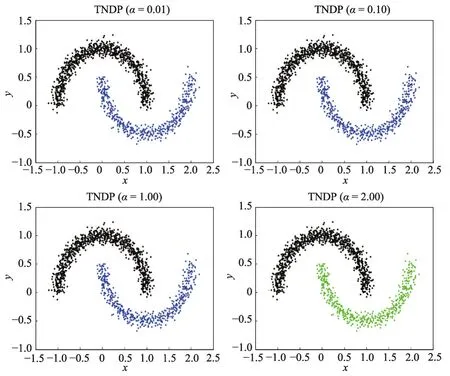
Fig.7 Clustering results of TNDP with different parameter α圖7 不同參數α下TNDP的聚類結果
5 結束語
本文提出了一種新的基于自然最近鄰居的密度峰值聚類算法TNDP。首先,該算法通過引入自然最近鄰居的概念來計算數據點的局部密度,然后通過類簇間被稀疏區域劃分來找到密度峰值,最后通過類簇間相似度的概念來把相似的類簇合并產生最后的聚類結果。通過實驗,TNDP算法在對復雜流形數據和密度變化大的數據的處理上具有相當大的優越性,比DPC、DBSCAN、K-means算法更有效,擁有更少的參數,只有一個類簇間相似度,且對類簇間相似度的選擇具有一定的魯棒性。
猜你喜歡
中老年保健(2021年12期)2021-11-30 02:58:01
海峽姐妹(2020年9期)2021-01-04 01:35:44
VOGUE服飾與美容(2020年9期)2020-09-02 14:47:26
攝影之友(影像視覺)(2019年2期)2019-03-05 08:27:14
中華詩詞(2018年11期)2018-03-26 06:41:34
Coco薇(2016年8期)2016-10-09 02:11:50
山東青年(2016年1期)2016-02-28 14:25:25
中國醫藥科學(2015年19期)2015-02-27 12:33:11
軍事體育學報(2014年3期)2014-02-27 16:00:13
當代修辭學(2014年3期)2014-01-21 02:30:44
