谷歌神經翻譯器英譯漢過程中的詞義排歧問題
2019-04-29 06:29:18
福建質量管理 2019年9期
關鍵詞:文本
(四川大學 四川 成都 610207)
一、背景介紹
機器翻譯這個話題在翻譯界備受關注,人工智能的應用使得機器翻譯輸出的譯文質量大有提升。因此譯者應該充分認識到機器翻譯的重要性,了解機器翻譯并讓其為我們所用。提升機器翻譯譯文質量面臨的一大挑戰便是詞義排歧,一個機器翻譯軟件譯文質量的好壞基本取決于其詞義排歧的能力。許多學者們也著眼于此,期望提升翻譯器的詞義排歧能力。
功夫不負有心人,機器翻譯在某些領域的排歧能力已可媲美人工翻譯,例如實時天氣預報、金融新聞報道以及軟件本地化手冊。于2016年發布的谷歌神經翻譯器也在詞義排歧問題上有了重大突破。據谷歌發表的論文稱,比起之前基于短語的翻譯器,谷歌神經翻譯器在很多語言對翻譯中平均減少了60%的錯誤率,與人工翻譯結果越來越接近。雖然它還是會出現一些人工翻譯不會出現的問題,在排歧方面也還不盡完美,但考慮到語篇的組成成分,歧義在一定程度總是伴隨著語篇存在的。而且開發機器翻譯的初衷是為了輔助譯者更高效地進行翻譯工作,而不是為了取而代之。多數翻譯工作者仍將會是機器翻譯詞義排歧能力提升的受益者。
二、研究目的及方法介紹
本文選取了數個文本來探索谷歌神經翻譯器在排歧方面的表現及錯誤規律,通過對比分析推論出其所擅長翻譯的文本類型,并提出一些可行的方法來提升其詞義排歧的表現。基于在該領域應用機器翻譯的可行性和實用性的現實考量,本文所選取文本為商務信函和商務合同。商務文本專業,嚴謹,凝練和實用的特點奠定了運用機器翻譯的基礎。既然要分析譯文質量,便要有一套可量化的分析標準,學界提出了多種用于分析譯文質量的標準,例如豪斯的翻譯質量評估模式。但考慮到此處是用于分析機器翻譯譯文質量,簡單的分析標準便足夠。因此本文融合了嚴復所提出的“信達雅”以及奈達所提出的“功能對等”理論。由于商務文本的目的是準確專業地傳達譯文信息,因此結合其翻譯目的,本文用于分析谷歌神經翻譯器英文質量的標準為“信”,“達”,以及“術語對等”。
三、歧義與詞義排歧
歧義是自然語言中存在的普遍現象。對機器翻譯來講,如果處理不好詞義排歧問題,那么輸出譯文的質量肯定是堪憂的。在英譯漢過程中,我們面對的歧義主要分為兩大塊:語義歧義和句法歧義(楊良生,1994)。語義歧義主要來源于詞義選擇問題,可進一步分為詞匯歧義和語法歧義。而機器翻譯主要處理的是詞匯層面的歧義。
機器翻譯技術已現世60多年。而詞義排歧問題仍是制約其發展的瓶頸。詞義排歧這一概念是由Weaver在一場機器翻譯大會上首次提出的。他指出,若要使機器習得人類辨別詞語歧義的能力,那么機器必須要會如何在特定語境下選擇某一詞匯的正確含義。語境是影響機器詞義排歧性能的最主要因素。國內外學者提出了多種模型來解決詞義排歧問題。有的模型在進化過程中被淘汰了,例如最大頻率法(most frequency approach)和選擇限制法(selectional restriction approach),有的模型經歷了時間的考驗留存了下來,例如基于語料庫法(corpus-based approach)以及統計法(statistic methods)(馮志偉,2004)。
谷歌神經翻譯器的詞義排歧模型為監督式學習法,通過引入人工智能技術,將文本標記并經過一系列試錯過程來提升其譯文質量。這便是所謂的深度學習。機器將通過反芻被標記的文本,達到修正輸出譯文質量的目的。
四、結果及分析
(一)商務信函排歧錯誤規律分析
商務信函是與商業伙伴建立聯系的一種方式。它比日常收發的電子郵件更為正式。但是,它的正式度又次于商業合同。商務信函特點是簡潔凝練,較為專業,使用商業術語,但應注意其禮貌用法。
筆者選擇了3封商務信函,一封用于建立業務關系,一封用于詢盤,一封用于報價。對比譯本為人工翻譯的正確版本和谷歌神經翻譯器處理的譯本。收集數據階段,本文作者對所選文本按句子數量進行了標注,以便追溯出錯之處。但由于本論文篇幅有限,具體的數據結果無法一一列舉。文章將直接呈現總體的錯誤數量及其類別。錯誤類別按照英文詞性以及商務文件術語劃分為名詞排歧錯誤、動詞排歧錯誤、形容詞排歧錯誤、術語排歧錯誤、代詞排歧錯誤、介詞排歧錯誤以及短語排歧錯誤。
在商務信函中選出了57個單詞和短語,谷歌神經翻譯正確的為8個,錯誤分別為12個名詞,9個動詞,8個形容詞,7個術語,5個代詞,4個介詞,4個短語。
名詞排歧錯誤與單詞的一詞多義密不可分,谷歌在特定語境中沒有選擇出正確的單詞含義;動詞排歧錯誤主要與文本本身的流暢性和全面性有關,谷歌翻譯的版本讓人很費解;形容詞排歧錯誤是由于語境疏忽而造成的;介詞排歧錯誤是谷歌無法確定介詞在句中的成分;谷歌由于缺乏商業知識背景而造成了商業領域常見的代詞,術語和短語的排歧錯誤。
(二)商務合同排歧錯誤規律分析
商業合同具有法律約束力,專業度和嚴謹度高,結構復雜,夾雜各種長難句和復合句。語言特點正式,使用商業術語,古英語,如“hereby,hereunder,and thereafter”。因此,合同翻譯需要大量商務領域的知識。出于同樣的原因,如果機器可以習得商業方面的知識,它將有可能比人工翻譯更加高效。
本文節選了一些商務合同片段,對比譯本為人工翻譯的正確版本和谷歌神經翻譯器處理的譯本。收集數據階段,本文作者對所選文本按句子數量進行了標注,以便追溯出錯之處。但由于篇幅有限,本文將直接呈現總體的錯誤數量及其類別。
在商務合同中選擇了82個單詞和短語,其中谷歌神經翻譯正確的為17個。排歧錯誤分別為16個名詞,9個動詞,8個術語,6個短語,7個形容詞,5個副詞,4個數字表達,4個古英語,2個介詞,2個連詞和2個代詞。
名詞排歧錯誤主要與詞語本身一詞多義的特點及其在商業合同中的恰當含義有關,其中谷歌翻譯的版本未能識別詞語在特定的語境下的正確含義,并且達不到商業合同所要求的正式度;動詞排歧錯誤主要與單詞本身含義不定和文本本身的全面性有關,谷歌翻譯的版本完全錯誤,或與商業合同的背景不符;形容詞排歧錯誤也是對合同背景知識的缺乏造成的;介詞排歧錯誤在于谷歌無法確定介詞在句中的作用,它便直接略譯了此類介詞;商業合同領域的代詞,術語,古英語的排歧錯誤主要在于谷歌商業知識的缺乏。
(三)分析對比結果
為了便于更直接的對比兩類文本的排歧錯誤,筆者制作了以下圖表:每個排歧錯誤率的計算方法為該類排歧錯誤數除以詞語及短語總量。
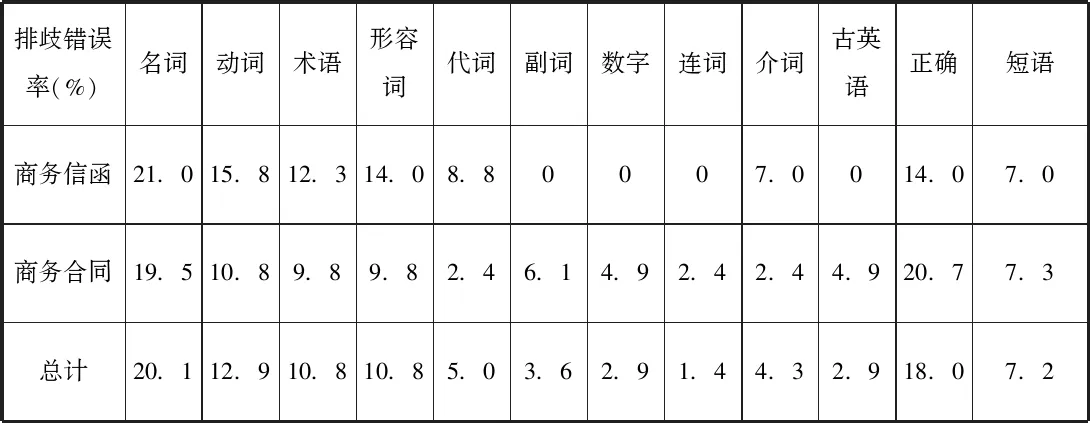
排歧錯誤率(%)名詞 動詞 術語形容詞代詞副詞數字連詞介詞古英語正確短語商務信函21.015.812.314.08.80007.0014.07.0商務合同19.510.89.89.82.46.14.92.42.44.920.77.3總計20.112.910.810.85.03.62.91.44.32.918.07.2
通過對比分析發現,兩種文本類型的排歧錯誤存在相似之處:
商業信函和合同中名詞和動詞排歧錯誤率都屬最高;排歧錯誤主要出現在實義詞中:名詞,動詞,形容詞和代詞,因為實義詞是文本用于傳達信息的主要手段。由于缺乏術語消歧能力,信函和合同的術語排歧錯誤率都相對較高。例如,商業信函中的“quote,enquiries 和 By L/C at sight”應翻譯成“報價,詢價,即期信用證”,而在商業合同中,“documents,negotiation / collection”應該翻譯成“單據,議付/托收”。
兩種類型的排歧錯誤也存在差異:
不同類型的文本中收集的排歧錯誤詞表現出不同的特征。商務信函中的排歧錯誤較為簡短,商務合同出現的排歧錯誤較為冗長復雜,這是兩者現實句子結構差異造成的,商務信函用于業務往來,清晰和簡潔是關鍵;商業合同用于名列法律陳述,需要注重形式和細節,復雜的長難句是常態,使得谷歌難以識別語句序列,從而影響谷歌翻譯在兩類文本中的排歧表現。
分析上表可知,商業合同的詞語排歧準確率為20.7%略高于商業信函的14.0%,這是因為谷歌擅長具有一定規律性的文本的詞義排歧,盡管合同句子結構復雜,但有規律可循,所以谷歌神經翻譯器能夠在其數據庫中找到匹配的語義;與商業合同相比,商務信函正式度大大降低,因此谷歌數據庫中可能無法查找出完全匹配的語義。
就術語排歧而言,谷歌在商業合同語境中的排歧正確率較高,因為商業合同創造了更加商業化的語境,相比之下,商業信函的語境更難確定,使谷歌對術語的排歧能力降低。因此可以推論,谷歌更擅長專業性較強文本的語義排歧。
代詞排歧錯誤與商務信函的禮貌原則有關。因此,信函中使用的代詞,例如“you,your”應該翻譯成“貴公司,貴方”,而不是“您,您的”。相較而言,商業合同中的代詞錯誤沒有這樣的特征。
就副詞和形容詞排歧錯誤而言,多數錯誤是由于谷歌未能識別單詞在特定語境中的正確含義。這其中仍然有一些規律可循,例如,單詞“any”的排歧錯誤中出現了4次,而形容詞總共的排歧錯誤為7個,同一句子中出現的相同錯誤不予考慮。多數情況下,谷歌都無法進行有效正確的排歧。
就介詞排歧錯誤而言,谷歌的漏譯便是錯誤的根源。在商務信函中的4個介詞排歧錯誤中,有3個是由漏譯引起的,而合同中的2個介詞排歧錯誤都是由于漏譯造成的。此外,在排歧錯誤中還出現了文本特定的錯誤,例如商業合同特有的古英語詞和數字錯誤。
五、結論
根據上述論證、比較和分析,本文得出一個明確的結論:谷歌神經翻譯器更擅長專業性強的文本語境下的詞義排歧。谷歌在不同詞性詞義排歧中表現出不同的規律。因此研究者可以通過加強谷歌對邊緣語境的識別能力以及增加對介詞用法訓練的語料庫,來提升谷歌神經翻譯的詞義排歧性能。
這項研究仍有其局限性。由于時間和空間不足,本文的分析樣本受到限制。因此,論文可能不足以用來推翻當前的機器翻譯系統。但是,筆者希望學界能夠對此進行深入研究,改善商務文本英譯中的譯本質量問題。
猜你喜歡
云南教育·小學教師(2022年4期)2022-05-17 14:46:24
新世紀智能(語文備考)(2020年4期)2020-07-25 02:28:52
新世紀智能(語文備考)(2020年4期)2020-07-25 02:28:52
甘肅教育(2020年8期)2020-06-11 06:10:02
藝術評論(2020年3期)2020-02-06 06:29:22
制造技術與機床(2019年10期)2019-10-26 02:48:08
新世紀智能(語文備考)(2018年11期)2018-12-29 12:30:58
電子制作(2018年18期)2018-11-14 01:48:06
小學教學參考(2015年20期)2016-01-15 08:44:38
語文知識(2015年11期)2015-02-28 22:01:59
