面向關系數據庫查詢的能耗建模及計劃評價
2019-04-18 05:14:58國冰磊楊德先
計算機研究與發展 2019年4期
國冰磊 于 炯 楊德先 廖 彬
(新疆大學信息科學與工程學院 烏魯木齊 830008)
大規模數據中心在全球范圍內的廣泛部署使高能耗、高費用、高污染等問題日益突出[1].2014年數據中心能效現狀白皮書報道,2013年世界數據中心能耗總量為8102.5×108kW·h,同年我國數據中心耗電量達772.1×108kW·h,同比增長16.2%.其中IT設備和軟件的能耗占數據中心整體能耗的45.4%.數據中心的能耗逐年攀升,不僅給企業帶來沉重的經濟負擔,產生的全球性碳排放也帶來一系列的社會及環境問題,促使世界各地的政府部門要求IT企業提高數據中心的能耗效率[2-4].根據著名研究機構Gartner[5]報道,IT領域目前的CO2排放量占全球總排放量的2%,并保持著高達11%的年增長率[6],到2020年這一比例將翻一番.
在2008年全球最頂級的數據庫研究會議(Senior Database Researcher Meeting)上,研究人員共同提出“研究與設計低能耗但不犧牲可擴展性的節能DBMS”是未來數據庫領域的研究熱點[7].降低數據庫的能源消耗對提高數據中心整體的能耗效率具有推動作用.數據庫系統的能耗管理問題也成為近期數據庫領域頂級期刊和會議的討論熱點[8-29].傳統數據庫以高性能為主要設計目標,而綠色數據庫系統則是要保障系統性能,同時降低能耗[30].關系數據庫在大數據時代仍然占據著重要地位,所以關注關系數據庫系統的能耗問題、研究面向可持續發展的綠色數據庫系統,具有重要的應用價值和社會意義[20,30-32].
已有研究[13,21,28]指出,在關系數據庫中,存在大量被查詢優化器忽略的節能查詢計劃.因為數據庫在設計之初缺少能耗方面的考慮,查詢優化器會選擇執行時間最短、忽視性能可以接受而且更加節能的計劃.對一條語句而言,其不同查詢計劃之間的響應時間、執行功率及能耗等指標也各不相同.本文構建查詢計劃的能耗預測模型,在語句執行前預測查詢計劃的能耗,利用評價模型使查詢優化器選擇節能的計劃,降低查詢的能量消耗,實現提高數據庫整體能耗效率的目標.Oracle數據庫是目前市場占有比率最大的關系型數據庫,所以選取Oracle數據庫為主要對象研究查詢能耗預測與計劃評價的相關問題.
1 相關研究
已有的數據庫節能工作可從硬件和軟件2個方面進行分類,下文將挑選一些具有代表性的工作進行詳細探討.
1.1 基于硬件的節能方法
基于硬件的節能方法主要有2種思路:1)關閉空閑設備[33];2)用低能耗高效率的設備替換高能耗低效率的設備[27,34-39].Meza等人[33]將數據庫重新配置到更少的磁盤上并關閉空閑的磁盤,只犧牲5%的峰值性能可降低45%的功率.閃存以及固態硬盤相比傳統機械磁盤具有耗電少、無機械延遲等特點.許多研究者都提出應該在綠色數據庫系統中考慮閃存的使用[38-41],并對比了磁盤和閃存的能耗有效性.隨著硬件技術的發展,基于硬件的節能方法利用現代硬件的新特性,在不影響服務級目標的前提下,盡可能地將服務器從高能耗的狀態轉換到低能耗的狀態.動態電壓頻率調整(dynamic voltage and frequency scaling, DVFS)[10,40-43]是常用的CPU功率調節技術,通過動態調節CPU時鐘頻率和供電電壓調整CPU功率,進而降低其能耗.基于硬件的節能方法不需要復雜的能耗管理組件且效果顯著.然而簡單地替換不能充分發揮硬件的特性,對已經部署的大型應用系統批量的硬件替換也會造成成本過高等問題[40,43].
1.2 基于軟件的節能方法
基于軟件的節能方法主要是構建數據庫常用查詢的能耗預測模型,進而實現預測整個數據庫系統能耗的目的[18].根據模型的粒度,可將現有的能耗預測模型分為運算符級的能耗模型與語句級的能耗模型.
運算符級的模型將查詢計劃分解為一個或多個運算符,如全表掃描(table scan)、索引掃描(index scan)、排序(sort)等.Xu等人[13,22]利用運算符的共同資源消耗特征,定義每個元組(CPU處理的普通元組數或索引元組數)和每頁的能耗常量(讀取的磁盤頁面數),為每個運算符構建功耗模型,最終形成整個查詢計劃的功耗模型.基于此,文獻[26,28]利用PostgreSQL查詢優化器中的性能代價估算模型,將CPU與磁盤作為主要的能耗組件,構建動態的運算符級別的能耗模型.Liu等人[44]基于文獻[13]利用CPU檢索的列數與元組數的乘積,為查詢負載構建功耗模型.刑寶平[45]利用數據庫應用層信息和操作系統層信息,建立了基于回歸分析方法的運算符級別的功耗模型.
語句級的能耗模型忽略查詢計劃的內部細節,并不深入研究每個運算符的資源消耗特征,而是將查詢或查詢負載看作一個整體.Rodriguez-Martinez等人[46]通過提取選擇查詢的共同特征(元組數、列數、平均元組長度、謂詞的選擇率(selectivity factor)等)在集群環境下構建了峰值功耗預測模型.楊良懷等人[47]從執行核粒度考察CPU執行頻率及利用率對系統功耗的綜合影響,采用線性回歸方法擬合CPU各個核的利用率、執行頻率、磁盤利用率來預測整個系統的功耗.金培權等人[48-49]采用軟硬件集成的方式,設計出一個用于測試綠色數據庫系統能耗有效性的工具DBPower.楊濮源等人[50]以TPC-H為基準,設計了一個用于測試移動智能終端數據庫查詢能耗的工具TPCDroid.我們已有的工作[51-53]提出一種基于查詢資源消耗最小單位的數據庫動態能耗模型.Sarda等人[54]提出一種基于查詢計劃回收利用的工具PLATIC(plan selection through incre-mental clustering),幫助查詢優化器攤銷優化代價,從而降低優化時間加速查詢執行.Harizopoulos等人[9]提出QED機制(improved query energy-efficiency by introducing explicit delays),引入顯示延遲和設置閾值,對查詢進行聚類并將查詢的公共部分放入隊列統一處理.文獻[29]通過僅處理一次公共子表達式并將其執行結果共享給其他查詢,達到降低執行總時間進而節能的效果.
現有的數據庫能耗建模方法[12-13,22,26,28,44-45]直接使用了PostgreSQL數據庫中的時間代價公式,雖然通過數學方法重新確定了公式中的系數,但是能耗預測值的精度有待提高[30].本文與現有工作不同之處有3點:
1) 已有研究通過定義CPU檢索元組的能耗常量為CPU預測功率[12-13,21-22,26,28,44-46].本文綜合考慮CPU在查詢執行過程中的作用,選取能更好反映CPU工作量的指令數[55-59],通過定義CPU執行指令的能耗常量為CPU預測能耗.
2) 現有研究[12-13,21-22,26,28,44-50]在構建查詢能耗預測模型時,只考慮CPU和磁盤的動態能耗,沒有考慮內存的動態能耗.本文分析并驗證了緩存在內存中的數據對查詢能耗及能耗預測精度的影響,并將內存的動態能耗構建在模型內,提高模型的預測精度.
3) 已有的工作[26-28,46-47]大多集中在構建能耗預測模型,使數據庫系統能夠感知能耗,很少關注具體如何利用能耗模型進一步實現節能.本文在解析查詢處理與查詢優化機制的基礎上,構建適應綠色數據庫系統的查詢計劃評價模型.模型改進了查詢優化器在選擇計劃時忽略能耗因素的缺陷,將功率和能耗也作為優化目標,實現為數據庫系統節能的目的.
2 能耗預測模型
在不考慮性能的情況下,構建節能數據庫是沒有意義的.根據經典能耗公式(式(1)),可以得出2種降低數據庫能耗的方法:1)提高查詢的速度,減少其響應時間,即傳統數據庫的優化目標;2)降低查詢的執行功率.
E=P×T,
(1)
其中,E,P,T分別為能耗、功率、響應時間。本文專注于第2種方法,同時保證性能退化度在可接受的范圍內.
傳統基于存儲的能耗模型[60]未將內存能耗構建在模型內.本文不僅在2.1節中驗證了內存對查詢功率及能耗的影響,而且將內存能耗加入能耗預測模型.
2.1 內存對查詢能耗的影響
查詢語句的處理過程主要包括3個階段:解析(parse)、執行(execute)、提取數據(fetch).3個階段都需要利用緩存在cache結構中的數據來減少I/O或CPU資源的消耗.已有研究[61]指出在查詢執行的過程中內存同樣是服務器中重要的能耗部件,所以在構建查詢能耗模型時,為提高查詢能耗預測的精度,需將內存的動態能耗構建在能耗預測模型內.
為研究緩存在內存中的數據對查詢功率及能耗的影響,分別在2種不同的設置下對20條查詢語句進行測試,收集能耗相關數據.實驗結果如圖1、圖2所示.2種設置分別是:1)緩存數據可用;2)緩存數據不可用,需要從磁盤再次讀入內存并由CPU重新計算得到.

Fig. 1 Power of queries under 2 different settings圖1 查詢語句的功率
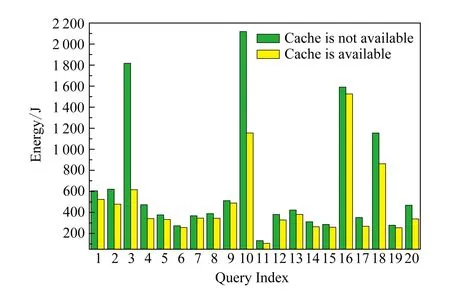
Fig. 2 Energy of queries under 2 different settings圖2 查詢語句的能耗
由圖1、圖2可知,無緩存執行場景下的功率、能耗總是大于有緩存的場景.查詢的總功率在2種情況下的平均差異為2.56%,最高可達5.94%;總能耗的平均差異為30.07%,最高可達195.09%.有緩存時更節能的原因是緩存在buffer cache和shared pool中的數據可以被查詢重復使用,加快查詢的執行,節省查詢執行過程中的資源消耗.說明緩存在內存中的數據是否可用,是影響查詢執行能耗的重要因素.
執行查詢所需的數據的量是固定的[62],一般情況下,這些數據都是從磁盤中讀取.如果內存中存在緩存數據,應區分數據來源(內存或磁盤),將數據獲取過程中產生的能耗進行分類(內存能耗或磁盤能耗).
2.2 系統各組件能耗建模
對數據庫而言,查詢語句的執行代價是由其使用相關資源產生的代價線性累加而成[28,63]:CPU、磁盤I/O、內存和網絡資源(針對分布式數據庫系統).資源的消耗會產生2種基礎代價:時間代價和功率代價,而查詢的能耗代價則是時間代價與功率代價的積分.網絡相關的能耗模型主要針對交換設備,其能耗模型和節能方法與節點服務器有較大不同[60].本文是在多組同配置單節點服務器下進行實驗,所以暫時未考慮網絡資源的能耗.
1) CPU代價.在執行查詢語句時,對數據處理過程中執行的每一步操作都會依據處理量與處理方式的不同請求CPU執行一定數量的指令.已有研究[12-13,21-22,26,44-46]大多基于CPU處理的元組總數對CPU代價進行估算.但是CPU除負責檢索元組外,還需檢索和計算與查詢執行相關的其他重要信息(如解析查詢語句、構建查詢樹、計算查詢代價、選擇最優的查詢計劃、檢索數據字典等),這些操作都需要消耗CPU指令.不同于元組總數,CPU指令總數量能更真實地反應CPU的工作量.本文通過定義CPU執行指令的能耗常量來估算CPU的能耗.
將查詢語句執行過程中消耗的CPU指令總數量設為CPU總指令數(NCPU),為方便計算,CPU指令數以萬為計量單位.對于不同型號的CPU,其處理指令的能力存在較大的差異,指令處理能力是指CPU的指令功率能力(NCPU_watt,即每瓦特完成指令數).設執行每萬條CPU指令的功率為PCPU,時間為TCPU,則CPU的動態能耗ECPU為
ECPU=NCPU(PCPU×TCPU),
(2)
PCPU=10000NCPU_watt.
(3)
2) 磁盤代價.在查詢執行過程中,磁盤產生的時間代價與功率代價取決于磁盤讀取的數據塊數量.從磁盤讀取的數據與緩存在內存中的數據之和等于查詢執行所需數據的總量.在查詢執行過程中常見的I/O類型為:單數據塊讀(single read data block)、多數據塊讀(multiple read data block).當出現索引范圍掃描、索引唯一掃描、索引完全掃描、ROWID訪問表等操作時會出現單數據塊讀操作;當出現全表掃描和快速完全索引掃描時會出現多數據塊讀操作.以Oracle DBMS為例,其讀取磁盤數據的最小I/O單位是數據塊(data block).單數據塊讀是指一次I/O僅從磁盤讀取單個數據塊,并把它讀入共享緩存(buffer cache)中.多數據塊讀是一次I/O操作讀取系統規定數量的數據塊.
將查詢語句執行所需數據塊的總量設為NAll,已緩存在內存中的數據塊總量設為NMem,從磁盤訪問的數據塊總量設為NDisk.在執行查詢語句的過程中,設磁盤產生單數據塊讀操作的總次數為NSingle,磁盤產生多數據塊讀操作的總次數為NMulti,一次多數據塊讀操作從磁盤讀取數據塊的數量為MBRC(multiple blocks read count),由參數db_file_multiblock_read_count決定,則:
NAll=NMem+NDisk.
(4)
NDisk=NSingle+NMulti×MBRC.
(5)
設執行一次單數據塊讀操作的功率為PSingle,時間為TSingle,則磁盤IO類型為單塊讀時,磁盤的動態能耗為
EDisk_Single=NSingle(PSingle×TSingle).
(6)
設執行一次多數據塊讀操作的功率為PMulti,時間為TMulti,則磁盤IO類型為多塊讀時,磁盤的動態能耗為
EDisk_Multi=NMulti(PMulti×TMulti).
(7)
EDisk=NMulti(PMulti×TMulti)+
NSingle(PSingle×TSingle).
(8)
3) 內存代價.內存產生的時間代價和功率代價與內存讀取的數據量大小密切相關.雖然記錄最后一層cache的缺失次數可以對內存吞吐量進行輕量級評估[64].但為更加直觀方便地評估與計算內存的動態能耗,模型將從內存讀取的數據塊總量作為反映內存資源消耗的參數.數據塊總量可以從數據庫系統中獲取,且更加符合數據庫的應用環境.內存和磁盤資源采用同一參數來衡量,也降低計算讀取數據產生的能耗的復雜度.
設從緩存讀取一個數據塊到請求進程消耗的單位功率為PMem,單位時間為TMem,則內存的動態能耗為
EMemory=NAll(PMem×TMem).
(9)
由式(1)~(8)可得,執行查詢語句產生的系統總功率為
P=C+NCPU×PCPU+NSingle×PSingle+
NMulti×PMulti+NAll×PMem,
(10)
其中,C為功率常數.
設查詢執行的總時間為T,由式(1)~(9)可得,當查詢語句的IO類型為單塊讀時系統總能耗為
E=C×T+NCPU(PCPU×TCPU)+
NSingle(PSingle×TSingle)+NAll(PMem×TMem).
(11)
E=C×T+NCPU(PCPU×TCPU)+
NMulti(PMulti×TMulti)+NAll(PMem×TMem).
(12)
E=C×T+NCPU(PCPU×TCPU)+NMulti(PMulti×
TMulti)+NSingle(PSingle×TSingle)+
NAll(PMem×TMem).
(13)
在式(10)~(13)中,利用與查詢能耗關系最緊密的資源信息構建能耗模型,具體的參數說明如表1所示.
精確地獲取統計數據是研究能耗相關問題的重要前提之一.查詢計劃包含的固定信息有消耗每種資源的統計量(即NCPU,NSingle,NMulti,NAll,NDisk,NMem)及響應時間[65].獲取查詢語句的執行計劃有3種常用方式,分別是SQL_Trace、10046事件、10053事件.SQL_Trace和10046事件獲取的計劃是查詢的實際執行計劃,其中,SQL_Trace命令可以跟蹤當前進程和其他用戶進程中的查詢運行情況,將查詢執行的整個過程輸出到一個trace文件;10046事件是SQL_Trace的擴展跟蹤,用于獲取更加詳細的計劃信息.而10053 事件可以獲取查詢優化器為一條語句生成的所有執行計劃,便于了解執行計劃的選擇過程.

Table 1 Parameter Specification of Energy Prediction Model表1 能耗預測模型參數說明
3種方式的跟蹤結果都會輸出一個trace文件,且使用方法類似.首先,啟動事件需要以DBA(database administrator)的身份登錄獲取相關權限.然后,在當前會話中激活事件,設置跟蹤級別(由level參數指定),設置事件的相關參數(timed_statistics:計時信息、max_dump_file_size:trace文件大小、user_dump_dest:文件的寫入路徑).最后,執行語句并關閉事件,性能統計數據會記錄到指定目錄下的跟蹤文件oracle_sid_ora_pid.trc中.Oracle的TKPROF工具可用于規范化trace文件的格式,使文件更具有可讀性,方便統計與分析.
時間常量(即TCPU,TSingle,TMulti,TMem)是系統統計數據的一部分,調用系統提供的dbms_stats包中的存儲過程gather_system_stats來收集系統統計數據,獲取時間常量的值.調用存儲過程后即開始收集統計數據,設置interval參數值可以讓數據庫自動啟動和停止收集過程.統計量和時間常量可以通過事件或包直接獲取,功率常量需要利用訓練集對模型進行求解得到.
3 查詢計劃評價模型

Fig. 3 Green query optimizer schematic圖3 節能查詢優化器原理圖
為獲取最優的查詢計劃,查詢優化器需要盡可能多地創建和評估大量的候選計劃.優化器通過給對象創建不同的訪問方法(access method)、連接算法(join algorithm)以及連接順序(join order),為語句生成一組各不相同的計劃[65-66].每個計劃都是一個唯一的樹狀結構,在這個樹狀結構中,每個節點代表一個操作,并且每個節點下都有一個或多個子操作.操作由上向下調用,數據由底向頂返回.其中常見的訪問方式有全表掃描(full table scan)、 索引范圍掃描(index range scan)、 索引唯一掃描(index unique scan)等.常見的連接算法有nested loop join,sort merge join,Hash join.連接順序的可能排列方式總量是訪問對象數的階乘.除了為語句生成計劃,傳統的查詢優化器還需估算每個計劃的代價,比較計劃的代價,最終選擇一個代價最小的計劃去執行.
因此設計節能的查詢優化器(如圖3所示)是構建綠色數據庫的關鍵.在能耗預測模型的基礎上,評價模型能夠感知查詢計劃的性能、功率及能耗.隨著用戶和服務供應商的多樣化需求(如響應時間、節能、設備可靠性等),評價模型需要將功率和能耗也當作優化目標,并考慮多個優化目標之間的相互關系,利用評價算法在多個目標之間進行權衡,輔助查詢優化器進行計劃選擇.
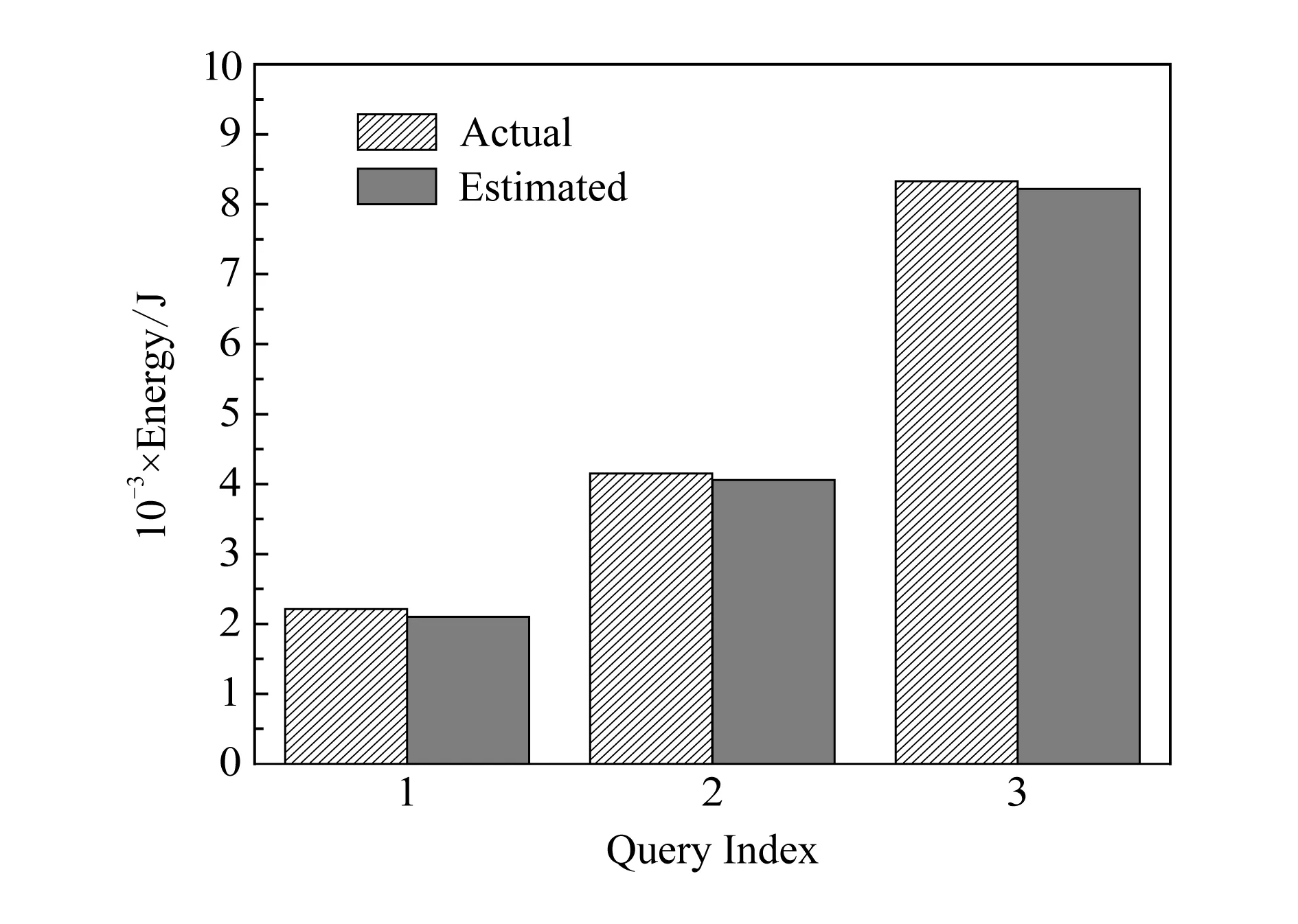
圖3描述了查詢計劃的評價過程:1)查詢優化器接收到一條查詢語句,生成一組查詢計劃{plan1,plan2,…,plann};2)查詢優化器內部的時間代價模型計算查詢計劃的響應時間,并由DBA設置一個可以接受的最低性能需求閾值,得到另一組查詢計劃{plan1,plan2,…,planm}(1≤m C=αP+(1-α)T. (14) C代表計劃的總成本,也是計劃的優先級.模型的默認設置是總是選擇C小的計劃去執行,C越小優先級越高.P代表功率,T代表響應時間(性能).α是調節因子,通過改變α的值,可以調節P和T在總成本(C)中所占的權重,進而調節計劃的成本,達到選擇特定需求計劃的目的.α的取值范圍是[0,1].α的值由DBA設置,DBA根據數據庫系統的當前運行狀態調整優化目標,選擇更加適應需求的計劃.基于式(14),針對任意一條查詢,都可實現3個優化目標(性能、功率、能耗): 1)α=1 查詢優化器的優化目標是功率,評價模型傾向于選擇功率小的計劃. 2)α=0 查詢優化器的優化目標是性能,評價模型傾向于選擇性能好的計劃(即傳統查詢優化器的優化目標). 查詢優化器的優化目標是能耗,評價模型會權衡P和T,并選擇能耗最小的計劃.此時,優先級最高的計劃其能耗也最小,且α值使性能與功率為最佳折中(best trade-off). 更細粒度地調節α的值可以獲得性能與功率不同程度的折中,折中代表性能與功率之間的置換.基于本文的評價模型,當性能退化為原來的1n時,功率降低n(1-α)α(單位為W).但要謹慎選擇α的極值,因為極值會導致性能或功率太差而給節能帶來負面影響. 圖4是實驗部署示意圖.如圖4所示,需要建立能耗模型的服務器B事先設置采樣事件收集自身的資源信息,并通過功率測量儀連接到電源上.服務器A上裝有統計與分析能耗信息的功率監控軟件,通過功率測量儀實時收集電流、電壓和功率信息.服務器B的詳細配置信息如表2所示. Fig. 4 Experimental platform of energy sampling 圖4 能耗測試平臺示意圖 Table 2 Description of Experimental Platform表2 總體實驗環境描述 表2描述了服務器主要部件的靜態功率(無負載運行時的功率)和峰值功率(部件滿載時的功率),為獲取部件的峰值功率,實驗使用Prime95,Stress-MyPC,Memtes等工具對服務器各組件(包括CPU、硬盤、內存)進行壓力測試.在部件滿載的情況下,循環不斷地對硬件進行檢測.每次檢測穩定運行2 h,待溫度及功率穩定后,讀取功率測量儀中的數據. 實驗使用TPC-C基準作為訓練集獲取能耗模型的參數,TPC-H基準作為測試集對能耗模型的有效性進行檢驗.TPC-H基準在生成訓練數據時,通過調節比例因子(scale factor, SF)可以設定生成數據集的大小.TPC-C基準生成測試數據時,通過設定倉庫數目(W)來確定數據集的規模. DBMS獨占系統資源的情況下,執行訓練集,收集統計數據.在MATLAB中,將數據帶入多元線性回歸模型中,采用最小二乘法求解回歸系數,得到處理查詢產生的系統總功率: P=41.88+3.677×10-7×NCPU+ (15) 把求解出的回歸系數帶入式(13)得到系統總能耗: E=41.88+3.15×10-12×NCPU+ (16) 判斷模型是否精確的標準是相對偏差.將模型預測的相對偏差(prediction error rate, PER)定義為EPER,計算公式為 (17) 其中,Actualvalue代表測量的真實值,Predictionvalue代表模型的預測值,通過比較二者的相對偏差,可計算模型預測的精確度. 由2.1節可知,內存對查詢能耗有重要影響.為進一步驗證計算內存能耗對能耗預測模型精確度的影響,在2種場景下對測試集中的22條查詢語句進行功率與能耗的預測(數據庫大小為1 GB):1)計算內存能耗;2)不計算內存能耗.為保證內存當中有一定數量的緩存數據,在執行測試集前運行了一系列面向商務應用且針對標準數據庫的查詢.實驗結果如圖5、圖6所示: Fig. 5 Comparison of power prediction under 2 different settings 圖5 功率預測結果對比圖 Fig. 6 Comparison of energy prediction under 2 different settings圖6 能耗預測結果對比圖 如圖5、圖6所示:當模型包含內存時,查詢的功耗預測精度最高可提高2.81%,平均精度提高0.625%;能耗預測精度最高可提高3.37%,平均精度提高2.06%.內存本身不是一個能耗消費很高的部件,但將內存能耗構建在預測模型內仍然能夠提高2.06%的精度.由此可得,構建存儲相關的能耗模型需要將內存能耗構建在模型內提高預測精度. 在本文的實驗環境下,將本文提出的能耗預測方法與已有的典型數據庫查詢能耗預測方法[28]進行預測精度對比.本文中的方法稱為方法A,將文獻[28]中的方法稱為方法B.方法B采用CPU處理的元組數對CPU功率和能耗進行估算,利用磁盤讀取的頁面數對磁盤功率和能耗進行估算.實驗結果如圖7、圖8所示: Fig. 7 Comparison of power prediction of method A and B圖7 方法A/B功率預測結果對比圖 Fig. 8 Comparison of energy prediction of method A and B圖8 方法A/B能耗預測結果對比圖 由圖7、圖8可知,方法A對單條查詢語句功率和能耗的預測更加接近真實值,平均預測正確率為95.68%.相對于方法B,方法A對功耗和能耗的預測準確度分別平均提高了5.63和5.92個百分點.對CPU的能耗進行估算時,選取CPU執行的指令總數而不是處理的元組總數;在估算讀取數據產生的能耗時,區分數據來源并將內存的動態能耗構建在模型內,這二者對提高模型精確度都有較大的幫助. 由以上實驗可知,本文提出的能耗模型對單個復雜查詢的能耗能夠進行較為精確的預測.為進一步探究模型對不同復雜度的查詢的預測效果,基于測試集(數據庫大小為10 GB),設計了3個簡單查詢(Q1,Q2,Q3).Q1執行的操作是在對Orders范圍掃描后進行等值查詢;Q2中查詢語句執行的操作是在對Supplier和PartSupp范圍掃描后再對兩表進行merge join;Q3中的查詢語句執行的操作是對Customer進行基于索引的范圍掃描.查詢的真實能耗與預測能耗對比如圖9所示: Fig. 9 Comparison of predicted energy and actual energy of simple queries圖9 簡單查詢的能耗預測值與真實值對比圖 由圖9可得,能耗模型對簡單查詢的能耗預測接近其真實值,誤差在1.31%~4.98%之間且預測值總是小于真實值.誤差產生的原因主要有4點: 1) 模型誤差.即能耗模型本身的預測誤差. 2) 主板等其他組件消耗能量.本文不討論單獨將這些組件的資源消耗作為能耗模型的參數,而是以常量(C)的形式構建在模型內. 3) 散熱.本文未將節點服務器散熱當作能耗模型的參數.雖然散熱也消耗能量[67-69],但是采集熱量參數需要額外的硬件設備,且建立模型的方法和本文所陳述的方法有較大差異[1,63]. 4) 系統的穩定性.能耗模型是在線下訓練的,系統的運行狀態相對穩定時能耗預測精度較高.但在真實的環境中無法預測查詢執行時系統的動態變化,導致模型預測精度不穩定.這也要求我們在未來的工作中改進模型的動態自適應性,使之能自動捕獲與分析系統當前的狀態信息,動態調整模型的參數,進而提高模型的預測精度. 實驗使用Oracle提供的外部接口及Java程序模擬節能查詢優化器的工作.通過10053事件獲取查詢的所有計劃,將計劃信息格式化作為Java程序的輸入.能耗模型為每一條查詢計劃估算時間代價、功率代價及能耗代價.然后根據不同的優化目標,調節評價模型中α參數的值,選擇滿足特定需求的計劃并反饋給DBA.DBA根據反饋回來的計劃使用Hint改寫查詢語句.將DBA改寫后的查詢語句按照其優化目標分為3類,批量提交到Oracle中執行.最后比較不同α值下,相同負載的執行時間、功率、能耗,驗證查詢評價模型的有效性. 基于以上的實驗步驟,產生100個測試用戶,從同一個查詢池中隨機獲取語句并同時提交到數據庫,且在1 s內完成全部提交.總共有3組測試,每組測試都包含100個測試用戶,分別采用3個不同的查詢池(pool1,pool2,pool3).每個查詢池中都包含22條查詢語句,但是每個查詢池中的查詢語句都只針對一個優化目標做Hint改寫,pool1中語句的優化目標是性能(α=0),pool2是能耗(α值在折中點),pool3是功率(α=1). 在1 GB,10 GB,30 GB的數據庫大小下重復以上實驗.實驗結果如圖10~12.在生成數據之前,為獲得較好的數據庫性能,在測試前需對數據庫的參數配置進行適當的優化,優化內容如表3所示. Fig. 11 Instant power cost of workload 2 under 10 GB size圖11 3種不同優化目標下查詢負載實時功率(10 GB) Fig. 12 Instant power cost of workload 3 under 30 GB size圖12 3種不同優化目標下查詢負載實時功率(30 GB) Table 3 Optimized System Parameters表3 系統性能配置參數優化 由圖10~12可知,隨著α值的增加,負載的功率逐漸降低.優化目標是性能時,評價模型會選擇性能最佳的計劃,此時負載的實時功率最大;當優化目標是功率時,評價模型會選擇功率最小的計劃,此時負載的實時功率是3種不同運行狀態的最低值;當優化目標是能耗時,評價模型選擇能耗最低的計劃,此時負載的功率介于最大功率與最低功率之間.圖10中出現負載實時功率突然下降的情況,是因為計算密集型(CPU-bound)的查詢先于訪問密集型(I/O-bound)的查詢執行完.功率的突然下降,也說明CPU功率在負載總功率中占相當大的比例,是查詢執行功率的重要組成部分[28,51].實驗中的數據總結如表4所示. 表4中的時間為負載執行花費的總時間,功率為負載運行時的平均動態功率,能耗為平均動態功率與執行時間的積分;功率節約、能耗節約、性能退化分別代表功率、能耗、性能相對于α=0時降低的百分點.對數據庫大小分別是1 GB,10 GB,30 GB的負載來說,當優化目標從性能變為功率時,可以觀測到的功率節約分別是2.69 W,10.29 W,20.41 W;當優化目標由性能變為能耗時,可以觀測到的能耗節約為5.87%,11.13%,11.34%.隨著數據庫數據由少到多,相同查詢涉及的數據量增多,產生的功率及能耗也增大,說明數據庫的規模對查詢的能耗有重要影響.本文提出的查詢評價模型,雖然在功率和能耗上取得了較好的優化效果,但在性能上有不同程度的退化.性能的退化,正說明評價模型的關鍵是調節α的值,以達到性能與功率不同程度的折中,降低能耗.表4中的性能退化度只是相對于最佳性能而言,此外性能的退化可以通過將磁盤替換為更高效的基于閃存的存儲設備來緩解[14,38].文獻[21]指出,如果適當的延遲不會引起性能滿意程度的下降,服務等級協議(service level agreement, SLA)允許查詢運行得更慢,以降低能耗.因為SLA是針對峰值需求來進行設定的,而真正到達峰值負載的概率很低,服務器大部分時間都處在低利用率下,SLA這一靈活的設置提供了創建綠色數據庫的契機[70]. 為進一步研究3種不同的優化目標下查詢計劃的代價變化并深入解析節能原因,對測試集中22條查詢語句進行測試與分析.實驗結果如圖13所示. Table 4 Experimental Results of Query Evaluation Model Verification表4 查詢評價模型實驗結果匯總 Fig. 13 Comparison of plan costs under 3 different optimization goals圖13 3種不同優化目標下查詢計劃的代價比較 如圖13所示,在22條查詢語句中第2,5,11,12,16,21條查詢的功率節約程度小.分析原因是:1)這些節能潛力較差的查詢是一些相對簡單的查詢,涉及大量的表掃描(即I/O密集型查詢)或表關聯操作只涉及2~3個表.查詢優化器為簡單查詢構建的查詢計劃的數量有限,計劃的選擇空間較小.2)能耗模型本身的預測誤差,無論α取何值,評價模型都會選擇同一個計劃或代價相近的計劃.此外,功率節約程度較大的查詢大多是CPU密集型查詢.因此,在不違反SLA的情況下選擇CPU利用率低的查詢計劃能更好地挖掘數據庫的節能潛力. 當優化目標為能耗時,除語句2,5,11,12,16,21外,其他查詢的功率節約程度都較大,但其預測的能耗節約(圖13(e))與真實的能耗節約(圖13(f))都較小.比較圖13(c)與圖13(d)可知,雖然功率節約程度大,但響應時間的增長導致最終的能耗節約程度遠比功率節約程度小.響應時間的增長不可控是導致真實節能效果低于預測節能效果的主要原因.由圖13(e)與圖13(f)可知,對于語句11,17,18,20,當優化目標為功率時(α=1)查詢的能耗比傳統優化目標(α=0)更高,原因也是響應時間的增長.綜上:在查詢優化時,選取α的極值會導致響應時間的過度增長,進而給能耗節約帶來負面影響;在能耗優化時,建議選取適當的α值,在節能的同時保障性能. 能源消耗已經成為數據庫系統設計及實現過程中的重要優化目標.為解決數據庫系統的高能耗問題,越來越多的研究工作投入到設計與實現綠色數據庫系統中.本文根據負載的資源消耗模式,以查詢負載為主要建模對象,構建了一個較精確且可移植的能耗模型.解析查詢優化的關鍵步驟,為查詢優化器的計劃選擇構建簡單且有效的評價模型.實驗設計基于TPC-H基準測試,實驗結果表明模型能夠有效降低系統能耗. 在未來的工作中,我們將繼續對本文提出的模型進行改進.下一步工作主要集中在3個方面: 1) 進一步研究在動態環境下(非數據庫系統獨占服務器資源),如何提高模型的健壯性并將模型擴展到分布式的環境下; 2) 在進行查詢能耗預測時如何減小模型誤差是將來研究的一個方向; 3) 構建集群版本的SQL能耗模型使之能夠自動捕獲系統的動態信息,周期性地更新模型參數,以適應服務器環境的動態變化也是將來研究的一個方向.4 實驗評價與比較
4.1 實驗環境及數據采集


4.2 能耗預測模型求解與驗證
1.282×10-5×NMulti+2.482×10-4×
NSingle+6.74×10-6×NAll.
1.00×10-7×NMulti+3.97×10-7×
NSingle+6.74×10-14×NAll.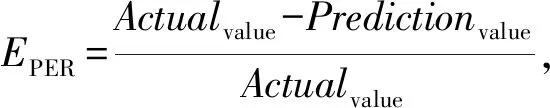




4.3 查詢計劃評價模型驗證





5 總結與展望
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
財經(2017年2期)2017-03-10 14:35:35
光學精密工程(2016年6期)2016-11-07 09:07:19
財經(2016年15期)2016-06-03 07:38:02
