糾刪碼存儲系統中基于網絡計算的高效故障重建方法
2019-04-18 05:14:42唐英杰謝燕文
計算機研究與發展 2019年4期
唐英杰 王 芳 謝燕文
(武漢光電國家研究中心(華中科技大學) 武漢 430074) (信息存儲系統教育部重點實驗室(華中科技大學) 武漢 430074) (深圳華中科技大學研究院 廣東深圳 518000)
隨著大數據時代的來臨,數據的爆炸式增長使得存儲系統的規模不斷增加[1-3],但是存儲設備的可靠性卻一直沒有得到顯著提高.Google的研究發現[4],傳統機械磁盤的年更換率為2%~9%,而固態盤 (solid-state drive, SSD)在4年內的整盤更換率為4%~10%,比磁盤具有更低的更換率,但壞消息是SSD在數據局部損壞方面遠遠高于磁盤.這些問題給數據的持久化存儲帶來了巨大的挑戰.
傳統的分布式存儲系統,比如GFS(Google file system)[5]和HDFS(Hadoop distributed file system)[1]采用多副本策略來保證系統可靠性.其中三副本策略可以容忍任意2個副本數據的丟失,在數據恢復過程中只需要從剩余可用副本拷貝數據即可,并且在并發訪問中,3個副本可以同時提供服務、分擔負載.但是隨著存儲規模越來越大,對每份數據維護3個副本不僅在存儲開銷上代價高昂,而且大大增加系統管理員的負擔.因此大量的數據中心開始部署糾刪碼[2,6-10],以較小的存儲開銷來保證足夠高的系統可靠性.
目前制約糾刪碼系統的主要因素是恢復開銷問題.糾刪碼的冗余策略是將文件分成若干數據塊,然后通過計算產生指定數量的校驗塊,數據塊和校驗塊共同形成了一個稱為條帶的結構.糾刪碼系統的存儲開銷和容錯能力均取決于校驗塊的數量,不過校驗塊與副本不同,在正常情況下,校驗塊沒有任何作用,無法分擔負載.但是當出現設備故障、節點失效等異常情況時,就可以通過條帶上剩余可用的數據塊以及校驗塊進行數據恢復,不過在這個過程中,恢復1個數據塊往往需要讀取數倍的數據,產生大量的I/O請求以及網絡流量,最終導致高的降級讀延遲和顯著的數據重建時間.
糾刪碼系統的恢復開銷一般認為來自于3個方面:編解碼運算、存儲I/O以及網絡傳輸.但是隨著軟硬件技術的發展,通過利用CPU的新指令[11],可以大大提高編解碼效率,因此性能瓶頸主要集中在網絡和存儲上[12-20].
在本文中,我們將優化方向著眼于數據重建路徑,針對數據恢復過程中網絡流量過大的問題,利用軟件定義網絡(software defined networking, SDN)[21]的技術,在交換機上進行部分計算[22],使得數據恢復的解碼計算盡量靠近數據存儲節點,從而避免數據在網絡中大范圍傳輸,克服了恢復節點端的網絡瓶頸問題[18-20].因為整個解碼過程中,數據流在網絡中聚合、計算,然后向下一個交換機傳輸,所以我們將這種基于網絡計算的故障重建方案稱為網絡流水線(in-network pipeline, INP).
本文的主要貢獻有4個方面:
1) 提出了INP這種基于網絡計算的高效故障重建方案,通過利用SDN的技術,在交換機上執行部分解碼運算,從而減少網絡流量,提高降級讀以及數據重建的性能.
2) 通過對解碼過程進行分析,說明INP方案可以適用于多種常見的糾刪碼,比如RS碼(Reed-Solomon code)[23-24]、PC碼(product code)[25]以及LRC碼(local reconstruction code)[13]等,并且INP可以和現有的優化技術[12,16,18-20]相結合,進一步提升恢復性能.
3) 擴展了SDN控制器的功能模塊,使其能夠根據交換機的實時負載情況,靈活地選擇出合適的交換機參與到解碼計算中.
4) 以RS碼為例,評估了INP與傳統糾刪碼系統在降級讀操作中的網絡流量大小.另外在不同的網絡帶寬下,測試了正常讀、傳統降級讀以及基于INP方案的降級讀這3種讀取方式的性能,結果顯示基于INP方案的降級讀方式可以在一定帶寬限制下得到和正常讀接近的性能.
1 相關工作
目前,分布式存儲系統的規模越來越大,故障更加頻繁,存儲系統往往通過存儲冗余數據以保障在故障發生時,數據不丟失,持續可用.而今,越來越多的分布式文件系統采用糾刪碼的冗余數據方案,而不是多副本.糾刪碼在提供足夠的可靠性同時,大大降低了存儲開銷,但代價是高昂的恢復開銷.這使得降級讀和數據重建的完成時間大大增加,前者會導致用戶感受到明顯的訪問時延,而重建窗口的擴大則會降低系統的可靠性,一旦在數據重建階段再次發生節點故障,可能會導致數據無法恢復.在不犧牲系統可靠性以及存儲開銷的前提下,為降低恢復開銷,我們提出了一種基于網絡計算的故障重建方案,利用交換機的計算能力,在網絡中實現數據合并,從而大大減少網絡中的數據流量,提高恢復性能.
現在實際生產系統中,比如Google的ColossusFS[8]、Facebook的HDFS[7]等,分別使用2種不同的RS編碼:RS(6,3)和RS(10,4).RS編碼的優勢在于可以編碼任意k個數據塊,產生任意m個校驗塊,k和m都可以完全由管理員自定義,一旦發生數據丟失,只需要任意k個塊(不管是數據塊還是校驗塊)都能完全恢復出所有數據,即可以容忍任意m個塊的丟失.但RS編碼會導致比較高的恢復開銷,以RS(10,4)為例,10個數據塊編碼產生4個校驗塊,存儲開銷是1.4倍,如果發生數據丟失,則需要從10個節點上讀取數據,恢復開銷是10倍,可以看到RS編碼是在存儲開銷和恢復開銷之間做一個權衡.但是有研究發現,超過98%的數據丟失都是單數據塊丟失,因此有很多針對單塊恢復的優化工作,其中Microsoft Azure Storage[2,13]使用一種稱為LRC的編碼,它編碼12個數據塊,產生2個全局校驗塊,另外每6個數據塊1組編碼產生2個局部校驗塊,如果出現單塊丟失,只需要讀取6個塊即可進行恢復,這種LRC(12,2,2)編碼具有1.33倍的存儲開銷和6倍的單塊恢復開銷,但缺點是犧牲了部分可靠性,不能容忍任意4個塊的丟失.
關于糾刪碼的優化研究大致可以分為2類:1)一種新的編碼方案,比如再生碼[22]、階梯碼[14]等;2)系統級的優化,比如雙糾刪碼系統[16],利用負載中存在的數據訪問傾斜,對頻繁訪問的少量熱數據使用恢復開銷較小的編碼,對大量冷數據使用存儲開銷較小的編碼,從而獲得低的存儲開銷和恢復開銷.這些新型編碼或多或少都是在存儲性能和恢復性能上做一些權衡.另外還有針對數據重建方案的優化[17],傳統的數據重建方案如圖1所示.當系統檢測到塊丟失或者節點故障,則會在某些可用節點上啟動重建任務,以一種并行的方式恢復丟失數據.圖中數據塊D1丟失,需要從其他節點上讀取相應塊進行恢復,當數據通過網絡傳輸到恢復節點時,恢復節點端的網絡帶寬將成為瓶頸,從而限制了恢復性能.
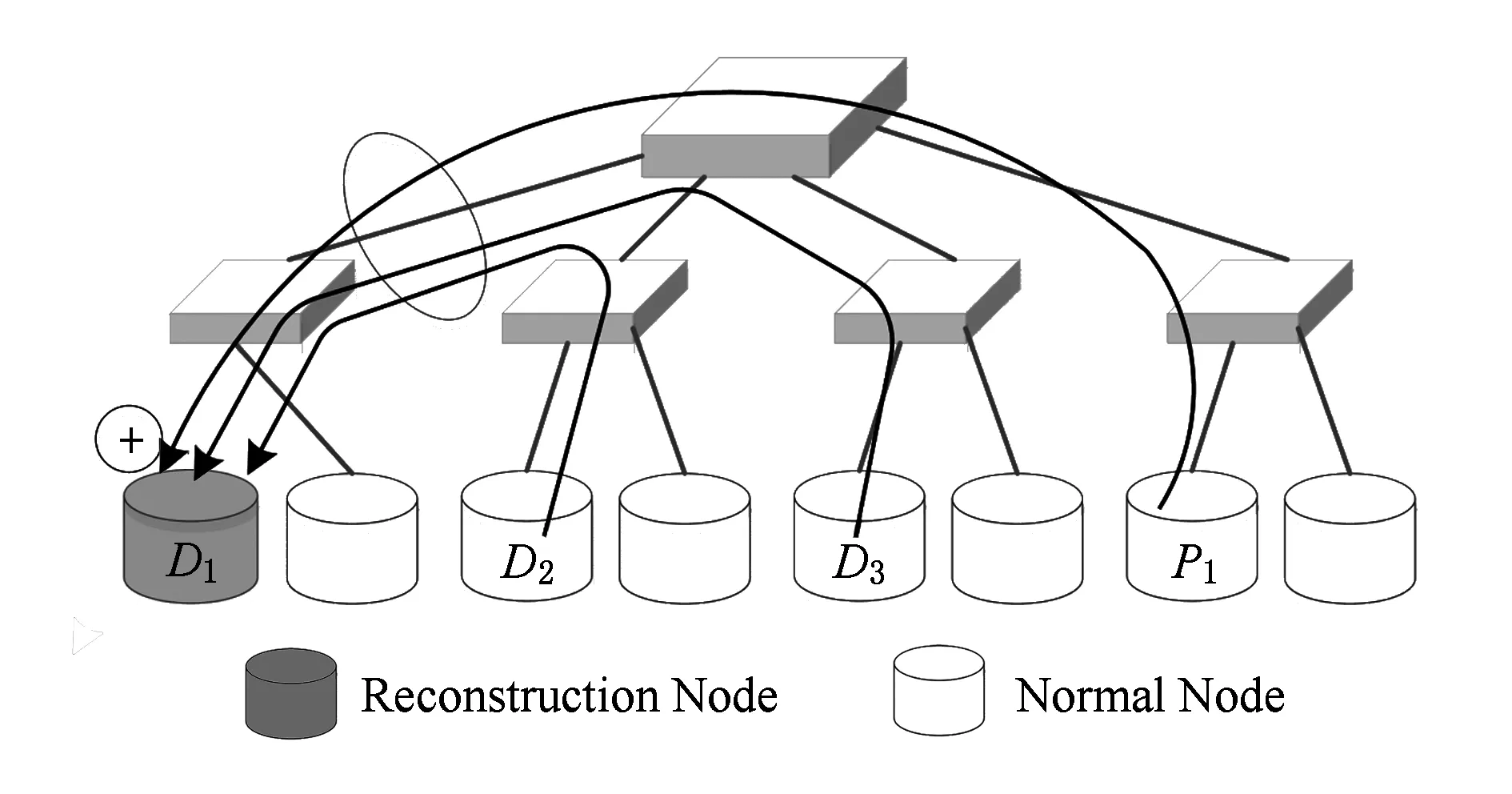
Fig. 1 The traditional erasure code data reconstruction scheme圖1 傳統的糾刪碼數據重建方案
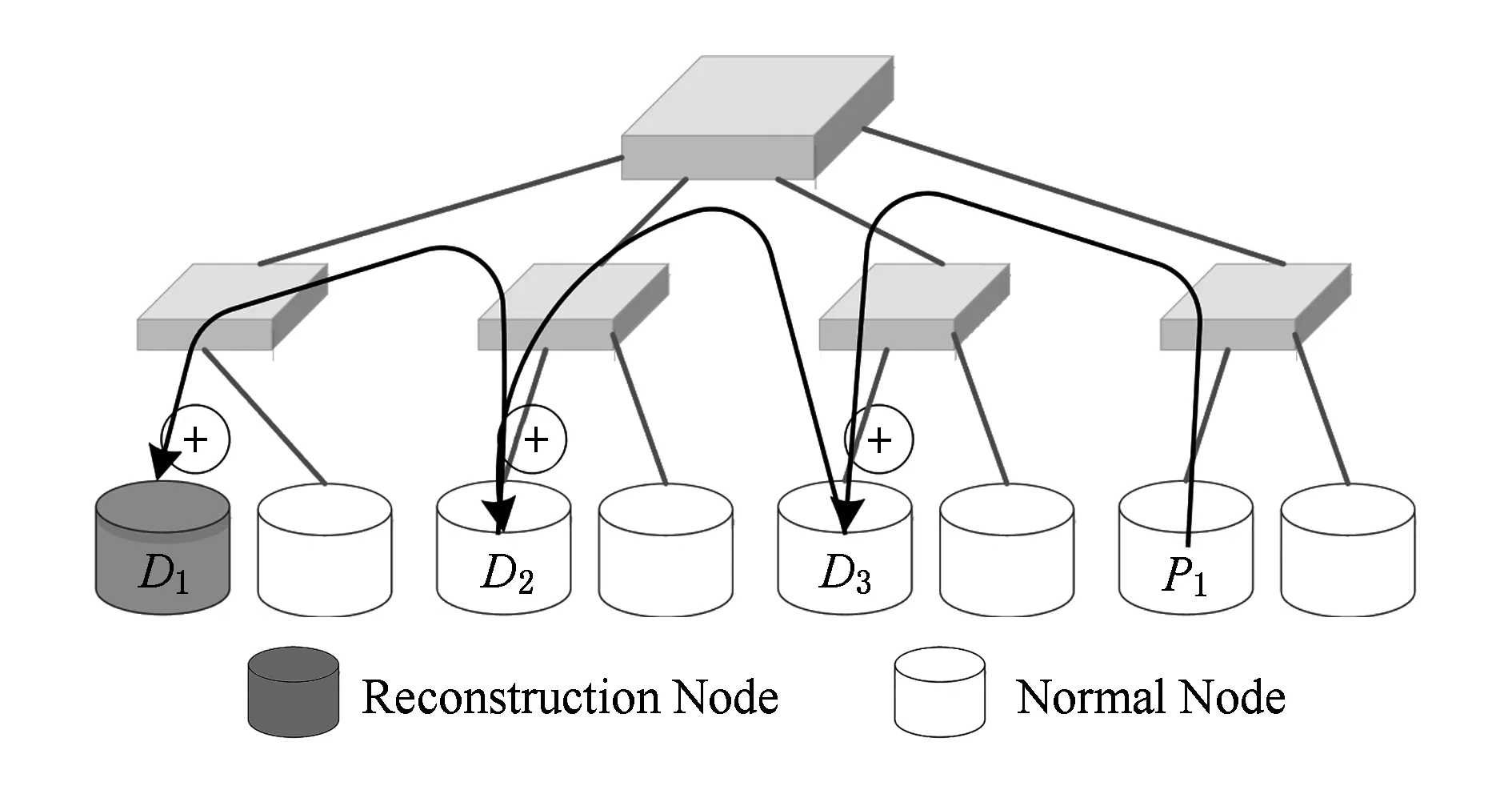
Fig. 2 The erasure code data reconstruction scheme based on pipeline圖2 基于流水線的糾刪碼數據重建方案
文獻[17]中提出一種新的恢復方案,如圖2所示,它充分利用各個節點的帶寬和計算能力,采用流水線的方式,將前一個節點的數據傳輸到下一個節點上進行計算,然后將計算結果繼續向后續節點傳輸,直到到達恢復節點,這種方式能比較好地解決恢復節點的瓶頸問題,但它并沒有減少傳輸過程中的網絡流量.
我們的想法得益于SDN技術的快速發展.SDN是一種新型的可編程網絡架構,其最核心的概念是將網絡設備的控制面和數據面分離,并強調控制面和數據面的可編程性.其中可編程控制面技術已經日趨成熟,現在已經有大量的開源控制器實現方案,控制器由一系列基本網絡服務模塊構成,并通過特定的接口(比如OpenFlow協議標準)與交換機進行通信,以此實現拓撲獲取、流量統計、路由控制等功能.在此基礎上,用戶可以很容易地根據需求開發擴展功能,并對外提供訪問接口.而關于可編程數據面的研究,目前正在逐步完善,其中P4[26]語言已經被設計出來,旨在實現交換機功能的動態配置.
在這樣的背景下,我們運用SDN的技術,提出了基于網絡計算的高效故障重建方案INP,由可編程控制器面實現網絡的拓撲管理和調度功能,由可編程數據面實現數據處理功能.如圖3所示,通過在交換機上對數據進行合并計算,不僅能夠解決網絡瓶頸問題,還能大大減少網絡中的流量,從而提升恢復性能.
設計INP方案主要是為了實現3個目標:
1) 更快的降級讀.當客戶端訪問到不可用的數據塊時,能夠在很短的時間內完成解碼操作,使客戶端感受不到太大的延時.
2) 更短的重建時間.數據重建完成得越快,系統可靠性越高,在新的重建方案下,針對可能發生的多數據塊重建,如何保證高并發非常值得思考.
3) 盡可能小地影響交換機正常工作.因為交換機計算能力有限,在不影響其正常工作的前提下,如何調度交換機也是一個非常重要的工作.
2 設 計
本節首先介紹INP方案的整體結構、包括SDN控制器、OpenFlow交換機網絡等;之后討論INP在降級讀過程中的I/O詳細原理;最后分析解碼計算對交換機性能的影響.
2.1 INP方案結構
INP方案的整體結構如圖4所示,主要由2部分組成:SDN網絡和Hadoop集群.其中SDN網絡又分為SDN控制器和OpenFlow交換機群.SDN控制器維護著整個交換機網絡的拓撲關系,并負責交換機的調度.交換機通過OpenFlow協議與SDN控制器通信,并在數據重建過程中執行部分計算任務.
HDFS-RAID(redundant array of independent disks):INP方案中的Hadoop集群是基于HDFS-RAID的一個擴展.HDFS-RAID是Facebook基于第1代Hadoop開發的支持糾刪碼的系統,它在HDFS的基礎上實現了一個RAID方案,HDFS-RAID將存儲在HDFS中的數據塊編碼產生若干校驗塊,并刪除原來的副本數據塊.一旦發現數據丟失,就會在集群中啟動重建任務執行數據重建操作,如果在數據重建期間,客戶端需要訪問丟失的數據,而此時系統中不存在副本數據,這將導致正常的讀取操作拋出異常,從而開始執行降級讀操作.降級讀本質上也是一種數據重建操作,與一般意義上的數據重建相比,降級讀操作的主要區別在于它不會將重建的數據塊寫回相應的節點,而只是將其返回給訪問的客戶端.在2.2節中,我們將主要討論降級讀操作,因為從原理和性能上來說,降級讀操作和數據重建操作是大體一致的.
1) SDN控制器.在INP方案中,我們對SDN控制器的功能進行了擴展,當HDFS-RAID集群進行降級讀或者數據重建操作時,集群中的某個節點會首先向SDN控制器發出請求,控制器利用自身對交換機網絡的全局視角,選擇出合適的交換機參與解碼計算,并將選擇結果以一種樹型的結構返回給集群,集群憑借該結構與相應交換機建立連接.關于SDN控制器對交換機的選擇策略,基于交換機的性能考慮,在SDN控制器中維護了交換機的狀態信息,以此作為評估標準,避免出現熱點問題.交換機選擇策略的設計將在2.3節中詳細介紹.
2) OpenFlow交換機.在INP方案中,交換機被用來作為聚合節點,通過在交換機上執行一些簡單計算,將來自不同節點的數據流合并,然后將計算結果繼續向后轉發,從而達到減少網絡流量的目的.為了盡可能小地影響交換機正常工作,在整個數據重建過程中,交換機只需要進行異或操作.具體的原理將會在2.3節中介紹.
2.2 INP中的降級讀
本節討論INP方案中完整的數據讀取流程.如圖5所示.1)首先用戶通過HDFS客戶端向HDFS中的數據塊D1發出讀取請求.2)但此時數據塊D1因為某些故障模式導致數據丟失,而系統可能尚未發現該故障或者正處于數據重建過程中,所以訪問的最終結果是拋出異常.3)HDFS客戶端捕獲到讀取異常,了解到數據塊丟失,從而啟動降級讀操作.在后文的后續說明中,均采用的是RS(3,2)編碼,即3個數據塊通過編碼產生2個校驗塊,在這種編碼模式下,如果1個塊丟失,則需要從剩余4個可用塊中任意選出3個塊進行數據重建,在圖5中,當數據塊D1丟失時,選擇從數據塊D3以及校驗塊P1和P2中讀取數據用于數據重建.而在INP架構中,從指定塊讀取數據之前,HDFS客戶端會向SDN 控制器發出請求,在請求消息中,HDFS 客戶端告知SDN控制器需要參與到降級讀操作當中的數據塊和校驗塊所在節點位置,SDN控制器不僅維護著整個OpenFlow交換機網絡的拓撲信息,還掌握著邊緣設備(Hadoop集群節點)與交換機的連接關系,當SDN控制器收到HDFS客戶端的請求后,它根據交換機拓撲信息和節點位置選擇出合適的交換機用于計算.4)SDN控制器將交換機和節點的連接關系通過一種樹型結構返回給HDFS客戶端,我們將這種樹型結構命名為重建樹,如圖6(a)所示.5)HDFS客戶端收到重建樹后,嘗試進行初始化,與各交換機和節點建立連接,在圖5中HDFS客戶端向交換機SW1發出建立連接請求并等待響應,SW1收到請求后按照重建樹結構向交換機SW2和節點D3發出連接請求并等待響應,以此類推.當各節點確認自身狀態,同意建立連接,就會向上一級交換機發出確認信號,當HDFS客戶端收到所有的確認信號,就表示連接建立成功,從而可以開始讀取數據,進行解碼運算.
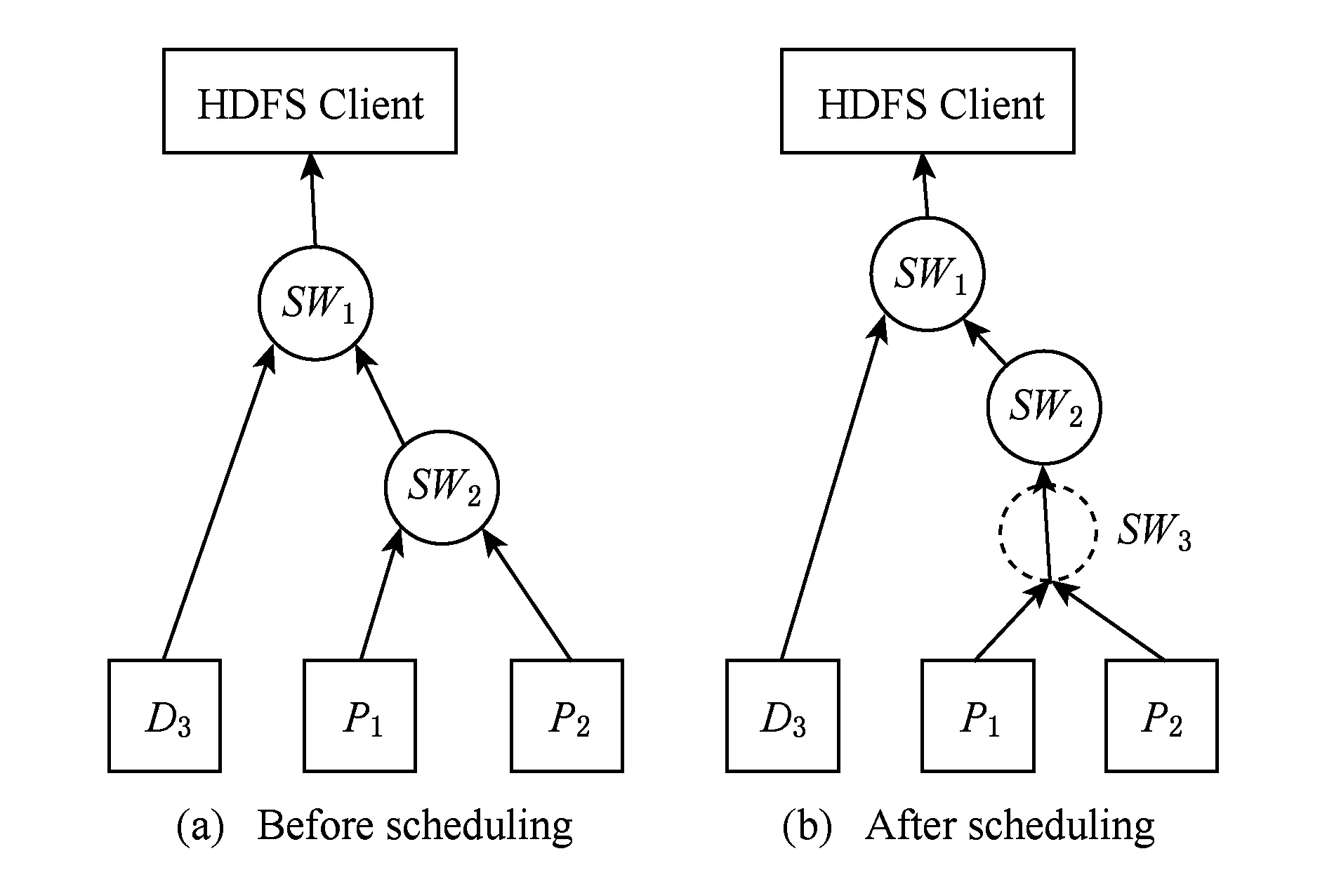
Fig. 6 Structure of reconstruction tree圖6 重建樹結構
2.3 交換機性能分析
在INP方案中,交換機在整個數據重建操作中具有至關重要的作用,它是使得網絡流量減少的關鍵設備,在本節中將重點討論針對交換機性能設計的調度策略以及交換機在解碼運算中的工作原理.
1) 交換機調度策略.在實際應用場景中,多用戶并發訪問或者多數據塊重建是非常常見的.以用戶訪問為例,當不同用戶同時引發降級讀時,SDN控制器會根據網絡拓撲選擇出合適的交換機進行解碼運算,這時可能會出現某臺交換機被多個降級讀所共享的情況.為了避免出現交換機熱點問題,對SDN控制器功能進行擴展,實現了3步調度策略:①如圖7所示,首先選擇出各節點到HDFS客戶端的最短路徑,各路徑交點為解碼交換機,從而得到如圖6(a)所示的重建樹結構;②如果選擇出的交換機的連接數(參與降級讀的數量)超過某個閾值,則進行向上調度,即從當前交換機沿數據流方向(圖7中箭頭所指方向)選擇出空閑交換機用于解碼,所得重建樹如圖6(b)所示;③如果最短路徑上所有交換機均不符合,則放棄最短路徑,直接從高層交換機中選擇出空閑交換機.
Fig. 7 Shortest-path strategy圖7 最短路徑策略
2) RS解碼運算的分解.在2.2節的討論中,已經提到了基于網絡計算的重建方案的核心思想,即在交換機上進行部分計算,使得網絡中傳輸的流量減少.考慮到交換機本身的計算能力,為了盡量小地影響其基本的路由轉發功能,在重建方案的設計中,在交換機上只需要進行非常簡單的異或運算.具體的工作原理可通過式(1)來解釋.
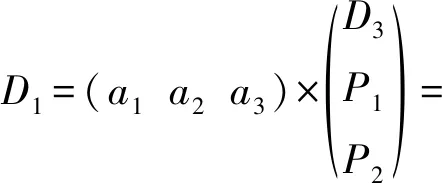
(1)
RS碼的解碼過程可以表示為2個矩陣相乘,其中a1,a2,a3組成了系數矩陣,D3,P1,P2是用于解碼的數據塊和校驗塊.將式(1)左邊的矩陣運算展開,得到式(1)右邊的表達式,可以看到解碼操作的實質就是若干系數各自乘上對應的塊,然后將結果累加.需要注意的是,式(1)中的乘法和加法運算都是伽羅華域中的運算,伽羅華域中的乘法運算非常復雜,涉及到查表等操作,而加法運算非常簡單,就是異或操作,因此在INP的設計中,當從各節點讀取數據時,首先在各節點上對原始數據D3,P1,P2執行乘法運算,即式(1)中的乘法項a1×D3,a2×P1,a3×P2,然后將計算結果發送給對應的交換機,在交換機上只需要將來自不同節點的數據進行異或合并即可.另外通過式(1)也可以分析出降級讀過程中的流量變化,假設需要降級讀取1 GB的數據,按照傳統的數據重建方案,HDFS客戶端所在的網絡將接收到3 GB的數據,而INP方案中,交換機將來自不同節點的數據進行異或合并,大大減少了向后傳輸的網絡流量,理論上HDFS客戶端收到的數據量應該為1 GB,從而解決數據恢復中的瓶頸問題.
2.4 編碼擴展性分析
2.3節中已經詳細說明了RS碼在INP方案下的解碼過程,可以發現INP方案的有效性依賴于交換機上的數據合并過程.在本節中我們將分析一些常見糾刪碼的解碼過程,從而證明INP方案可以運用在多種糾刪碼系統中.
1) LRC碼.LRC(12,2,2)的編碼結構如圖8所示,12個數據塊使用RS編碼的算法產生2個全局校驗塊,另外每6個數據塊通過異或產生1個局部校驗塊.在解碼過程中,如果出現單塊故障,則只需要通過式(2)進行異或計算即可,顯然可以在交換機上進行數據合并減少網絡流量;如果出現多塊故障,則需要用到全局校驗塊,該解碼過程和RS完全一致.
d4=d1+d2+d3+d5+d6+L1.
(2)
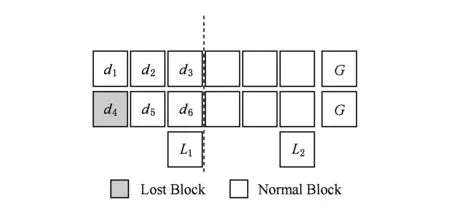
Fig. 8 LRC code圖8 LRC編碼結構
2) PC碼.PC(2,5)的編碼結構如圖9所示,每行5個數據塊通過異或產生1個局部校驗塊,每列2個數據塊通過異或產生1個局部校驗塊,所有的數據塊異或產生1個全局校驗塊.其解碼過程類似于LRC的單塊恢復,每塊數據的恢復都涉及單次異或運算,因此PC碼也可以部署在INP方案中.
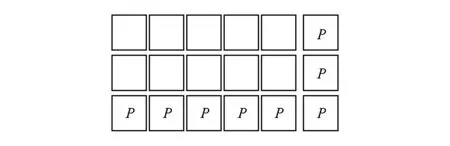
Fig. 9 PC code圖9 PC編碼結構
3) SD(sector-disk)碼[15].SD碼是一種可以修復扇區錯誤的糾刪碼,其結構如圖10所示.與傳統糾刪碼相比,SD碼將扇區作為最小編碼單元,每行采用RS編碼算法產生2個局部校驗塊,所有扇區經過編碼產生2個全局校驗塊,其解碼過程與RS碼相同,區別只在于SD碼重建粒度更小,所以INP方案也可以兼容用于扇區修復的糾刪碼.

Fig. 10 SD code圖10 SD編碼結構
3 實 現
3.1 傳統糾刪碼系統
HDFS-RAID中實現糾刪碼功能的核心模塊主要是DRFS(distributed raid file system)和RaidNode,其中DRFS是在HDFS基礎上實現的RAID方案,而RaidNode進程主要負責數據編碼以及數據重建工作.RaidNode進程會周期性地查詢NameNode,來獲取需要編碼和需要進行重建的文件條目.
DRFS客戶端是在HDFS客戶端的基礎上進行封裝,它的大部分功能其實都是由下層的HDFS客戶端實現的,在讀取數據時,如果出現塊丟失等異常情況,DRFS客戶端將會捕獲到這些異常,并且定位到異常發生的位置,進而檢索同一條帶上的可用塊用于解碼操作,得到請求的數據,這就是傳統的降級讀操作.
3.2 基于網絡計算的糾刪碼系統
在INP方案中, 當客戶端讀取到某個丟失塊時,客戶端同樣會捕獲異常,與傳統降級讀不同的是客戶端之后會采取的措施,即開始執行2.2節所描述的降級讀操作.在整個INP方案的實現中,SDN控制器選擇的是基于Java語言的Floodlight,OpenFlow交換機則采用Open vSwitch虛擬交換機.在客戶端捕獲到讀取異常之后,首先向條帶上的其余數據塊和校驗塊發起訪問,確定有足夠多的可用塊,并獲取這些塊所在節點的IP地址.因為Floodlight采用REST(representational state transfer)風格的編程接口對外提供服務,所以客戶端將節點的IP地址通過HTTP請求的方式發送給Floodlight,Floodlight收到請求后,根據維護的交換機負載信息,對交換機進行調度.當成功選擇出合適的交換機后,更新交換機負載信息,并將交換機和節點的連接方式以重建樹的結構發送回客戶端.然后客戶端開始計算式(1)中的系數矩陣,也稱為解碼矩陣,在與交換機以及各節點建立連接的過程中,將系數矩陣以及文件偏移等信息發送到對應節點.當節點接收到客戶端的連接請求之后,它會去打開指定文件,根據文件偏移定位數據,如果在這個過程中發生異常,會向客戶端發送一個值為false的確認,只要有1個節點不能正常連接,客戶端收到的確認就是false,只有當所有的節點以及交換機都做好數據傳輸準備,客戶端才會收到值為true的確認.
連接成功建立之后,客戶端會采用流水線的方式向節點發出讀取請求.為了提升讀取效率,客戶端上建立了雙緩沖區,在連接建立后客戶端啟動1個子線程向緩沖區中寫數據,寫線程會一直循環檢查2個緩沖區,一旦發現某個緩沖區為空,就會向服務器發出讀取數據請求.采用雙緩沖區這樣的方式,是為了讀線程在讀某個緩沖區時,寫線程可以去填滿另一個緩沖區,當讀線程讀完前一個緩沖區時,可以無等待地切換到另一個緩沖區,而同時寫線程會去填滿之前被讀完的緩沖區.
當寫線程讀取到1個塊的塊尾時,表示已經成功讀取1個丟失的塊,這時客戶端就應該與交換機以及各節點斷開連接,在這個過程中客戶端會向Floodlight發送一個斷開連接的信號,收到此信號的控制器就會更新交換機的負載信息.如果客戶端還需要讀取文件的下一個塊,且該數據塊也發生丟失,則需要重新建立連接,重復整個流程.因為即使是文件中連續的2個塊,也可能編碼在不同的條帶上.
4 測 試
4.1 測試環境
如圖11所示,在1臺配置有2TB磁盤、12 GB內存以及2個4核2.4 GHz Intel Xeon E5620 CPU的物理機上構建了1個由11個Docker容器和1臺虛擬交換機組成的小集群,其中8個容器作為DataNode服務器節點,另外3個容器分別作為NameNode、HDFS客戶端以及交換機的計算節點.容器內運行Ubuntu 14.04.2操作系統,Docker版本為1.7.1,SDN控制器是Floodlight-0.90,交換機使用Open vSwitch 2.0.2來模擬.

Fig. 11 Experimental cluster圖11 測試集群
因為虛擬交換機本身并不具備數據解碼中的計算功能,而修改其源代碼代價太大.因此我們為每個虛擬交換機綁定1個計算節點,如圖11所示,當交換機接收到服務器節點傳來的數據時,首先將數據轉發給對應的計算節點,在計算節點上完成異或合并運算,然后再發送回交換機,并繼續向后傳輸.但是采用這種方式,會給測試引入不必要的開銷,在4.3節我們將分析這種方式對測試結果造成的影響,并合理估計這部分額外開銷.
另外關于糾刪碼的設置,我們采用的編碼是RS(3,2),即每3個數據塊編碼產生2個校驗塊,5個塊一起構成1個條帶,基于這種編碼,每次降級讀取1個塊需要連接另外3個可用塊.另外設置HDFS塊大小為128 MB,使用HDFS-RAID默認的塊分布方案將編碼后的數據塊和校驗塊平均分布在集群中,確保同一糾刪碼條帶上的任意2個塊不在同一節點上.
在4.2~4.4節中,我們將分別從網絡流量、降級讀延遲以及帶寬競爭力這3個方面說明INP方案的有效性.
4.2 流量測試
通過第2節分析可知,影響降級讀性能的一個重要因素是網絡流量,在我們的測試集群中,網絡瓶頸主要出現在交換機與客戶端相連的鏈路上.因為測試過程中客戶端降級讀取1 GB的數據,而編碼方案采用的是RS(3,2)編碼,即每次需要讀取3倍的數據用于解碼操作,所以理論上客戶端的降級讀會從服務器上獲取3 GB的數據,傳統降級讀方式中3 GB的數據將全部流經交換機到達客戶端,在客戶端上進行解碼得到丟失的數據.而基于網絡計算的降級讀方式因為在交換機上已經完成了計算,因此理論上只需要向客戶端傳輸1 GB數據.我們通過調用Floodlight控制器的接口可以獲取到交換機各端口的輸入輸出流量,經過簡單處理后的結果如圖12所示,其中HDFS-RAID表示傳統降級讀,INP表示基于網絡計算的降級讀.
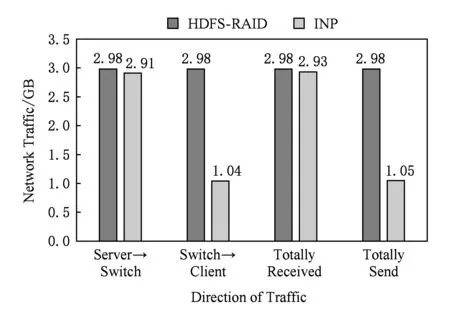
Fig. 12 Comparison of network traffic圖12 網絡流量對比
第1組數據測的是交換機從各服務器節點讀取的數據量,可以看到在傳統降級讀過程中,需要從集群中讀取2.98 GB的數據,與理論分析值3 GB基本相符,另外INP方案中的降級讀從服務器獲取了2.91 GB的數據,略少于傳統降級讀,但認為是在測試誤差范圍內.
我們比較關注的是第2組數據:交換機轉發給客戶端的數據量.圖12中數據顯示INP方案中交換機轉發給客戶端的數據量與傳統降級讀的比例為1:3,基本與理論值相符.
后面2組數據測試的是交換機的總的接收數據量和發送數據量,統計這2組數據主要是為了說明在降級讀中,交換機接收的流量幾乎都來自服務器,而轉發的流量都是送往客戶端.
測試中我們采用的是一種恢復開銷相對較小的編碼,每次恢復1個數據塊只需要讀取3倍的數據量.而在Google ColossusFS中使用的是RS(6,3),Facebook HDFS-RAID使用的是RS(10,4),如果在INP方案中部署這2種編碼,能夠減少的網絡流量會更多.
4.3 降級讀延時
在本節中,我們將分別在不同網絡帶寬下對正常讀、傳統降級讀和INP方案中的降級讀的時間進行比較.測試結果如表1和圖13所示,其中HDFS表示正常讀.
關于網絡帶寬的設置,采用的辦法是在交換機到客戶端的出口端口上創建1個QoS(quality of service)隊列,并設置最大最小速度,以此來限制網絡帶寬.需要注意的是所有的網絡限制都是針對交換機到客戶端的出口帶寬,其余鏈路不做限制,以此來分析網絡流量所引起的瓶頸問題,同時說明INP方案的有效性.
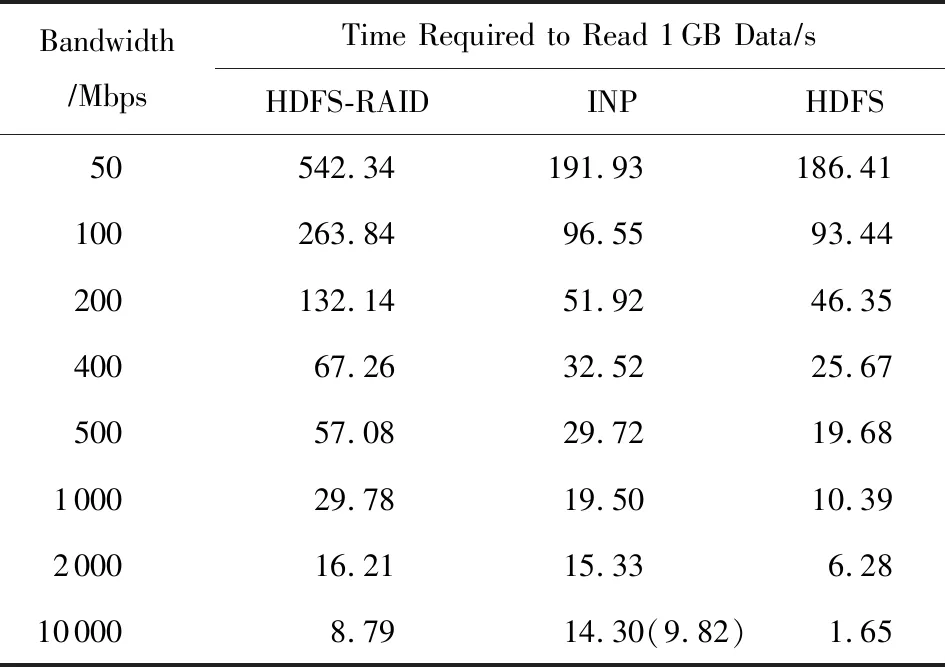
Table 1 Time Required to Read 1 GB Data at DifferentNetwork Bandwidths
Note: The value in parentheses is the correction data, because the simulation method used in our experiments has a large impact on the result at 10 000 Mbps.
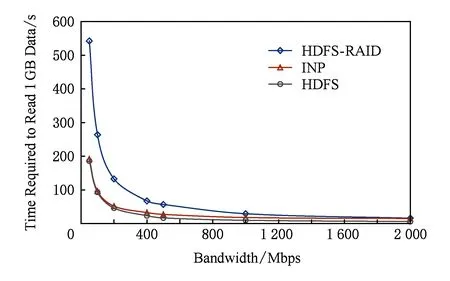
Fig. 13 Time required to read 1 GB data at different network bandwidths圖13 不同帶寬下讀取1 GB數據所需時間對比
在整個測試部分,我們以正常讀取1 GB數據的時間作為基準來分析傳統降級讀和基于INP方案的降級讀的性能.在10 000 Mbps下,測得客戶端正常讀取1 GB的數據需要1.65 s,基于流水線原理,讀取時間取決于瓶頸帶寬和瓶頸鏈路上的網絡流量,在傳統降級讀中,客戶端所在鏈路需要傳輸3倍于正常讀的流量,因此理論上傳統降級讀讀取1 GB的數據需要3倍的正常讀時間,而實際測試結果是8.79 s.這主要是因為降級讀除了網絡傳輸開銷,還存在存儲I/O以及解碼計算開銷.
再觀察10 000 Mbps下INP方案的測試結果.因為4.2節實際測得交換機最后轉發到客戶端的流量和正常讀是一致的,即INP方案中瓶頸鏈路帶寬以及瓶頸鏈路傳輸的網絡流量均與正常讀相同,所以INP方案中的網絡傳輸時間理論上也應該與正常讀一致,不過根據4.1節所述,因為硬件設備受限,所以在仿真測試中為交換機綁定1個計算節點,按照這種方式,在10 000 Mbps下,雖然消除了客戶端的網絡瓶頸,但是計算節點處的鏈路反而成為了瓶頸,而且交換機轉發給計算節點的數據和計算節點回送給交換機的計算結果均在同一鏈路上傳輸,所以該段鏈路上的網絡流量是正常讀的4倍,為了消除這部分開銷,我們測試了3 GB數據在萬兆鏈路下的網絡傳輸時間,以此來近似估計交換機與計算節點之間的額外開銷,如表1所示,我們列出了INP方案的原始測試結果和修正之后的結果,消除開銷之后INP方案讀取時間為9.82 s.但即使是修正之后的數據,也遠遠大于正常讀,甚至要比傳統降級讀時間略長,不僅沒有減少恢復開銷,反而增大.分析INP方案的額外時間開銷,不僅包括存儲I/O和解碼計算,另外在INP方案中,客戶端在讀取數據之前還需要訪問SDN控制器,并等待控制器返回重建樹信息,之后還要與交換機、服務器建立連接,這些操作都存在一定的時間開銷.而且由于客戶端鏈路的網絡帶寬達到10 000 Mbps,數據傳輸速度較快,導致網絡開銷并不是影響恢復性能的主導因素.這就使得INP方案性能反而沒有傳統降級讀性能好.由于集群規模的限制,我們在測試中只能采用條帶較短的編碼方案,但是考慮到實際系統中往往會部署恢復開銷更大的編碼,這時網絡流量將會成倍增加,這些都將有利于INP方案的性能發揮.
當我們將帶寬設置為2 000 Mbps時,交換機與計算節點之間的鏈路不再是網絡瓶頸,因此不用對測試結果進行修正.測試結果顯示INP方案性能優于傳統降級讀,且隨著帶寬資源越來越緊張,INP方案的優勢也越來越明顯,甚至接近正常讀時間.如圖13所示,在1 000 Mbps下,INP方案可以減少50%的降級讀開銷;而在200 Mbps下,INP方案已經達到正常讀的性能.這主要是因為隨著帶寬降低,降級讀的恢復開銷主要取決于網絡傳輸時間,而INP方案大大減少了網絡流量,因此可以獲得非常大的性能提升.而且目前用于測試的INP方案只是一個簡單原型,在性能優化上還有一些工作有待完成.
4.4 網絡競爭力
在4.3節的測試中,評估的都是某種讀取方式獨享整個網絡帶寬時的性能.而在真實應用場景里,往往是既有正常讀,也有降級讀,2種讀取方式并行執行.在這部分,將考量正常讀+正常讀、正常讀+傳統降級讀、正常讀+INP降級讀這3種共享讀取模式下各讀取方式的性能表現.設置這組測試的目的主要是為了評估降級讀與正常讀產生的數據流在網絡中的競爭力表現.
如圖14所示,在1 000 Mbps下,第1組數據顯示的是獨占模式下各讀取方式的性能,即4.3節中測得的數據.第2組數據表示的是當網絡中存在2個客戶端同時讀取數據時正常讀的性能表現.結果符合預期,當網絡中流量成倍增加時,正常讀性能成倍降低,圖14中顯示2個正常讀操作的時間都是原來獨占網絡帶寬時的2倍.再觀察第3組數據,當網絡中同時存在正常讀和傳統降級讀時,正常讀的完成時間接近于獨占網絡帶寬時的3倍,這是因為當網絡中存在降級讀時,網絡流量大大增加,嚴重占用了網絡帶寬,實驗結果顯示在這種共享模式下,正常讀分配有1/3的帶寬,傳統降級讀占用了剩下的2/3,但是考慮到傳統降級讀的流量是正常讀的3倍,所以說明正常讀的網絡競爭力會略強于傳統降級讀.第4組數據測的是正常讀和INP降級讀的共享模式,其中正常讀的時間相比于獨占帶寬增加了1倍,即正常讀在混合模式下占用了一半的帶寬,這與第2組數據情況相同,因此可以認為INP方案在網絡競爭力方面與正常讀表現一致.
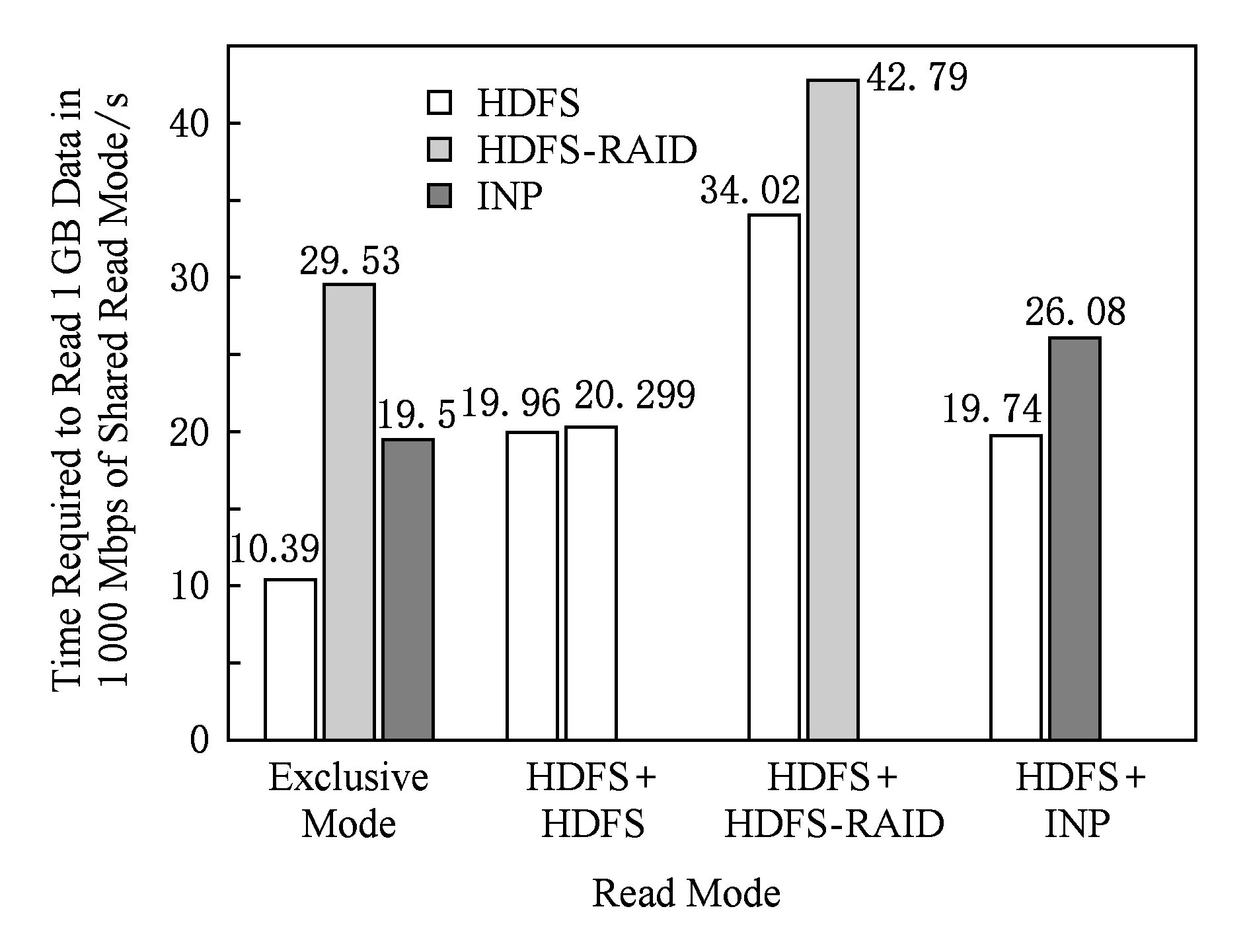
Fig. 14 Shared read mode in 1 000 Mbps圖14 1 000 Mbps下的共享讀取模式
另外我們還分別在500 Mbps下和100 Mbps下對3種混合讀取模式進行了測試,如圖15和圖16所示.在這2種帶寬下,正常讀和INP降級讀的混合模式中,正常讀均占有一半的帶寬,與1 000 Mbps下表現一致.特別是100 Mbps下的測試結果,非常直觀地顯示了INP降級讀具有和正常讀一樣的網絡競爭力.如圖16所示,因為在該帶寬下,INP降級讀已經具有接近正常讀的時間開銷,所以圖16中第4組數據和第2組數據表現完全吻合,這也說明了可以將INP降級讀等價于正常讀來看待.
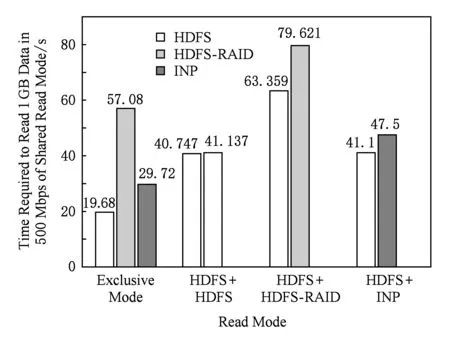
Fig. 15 Shared read mode in 500 Mbps圖15 500 Mbps下的共享讀取模式
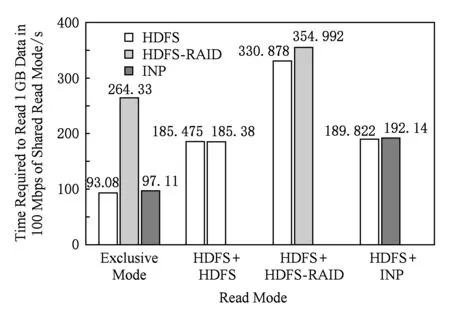
Fig. 16 Shared read mode in 100 Mbps圖16 100 Mbps下的共享讀取模式
4.5 未來工作
在本次測試過程中,我們從網絡流量、降級讀延遲以及網絡競爭力說明了INP方案的有效性,它能夠大大減少降級讀過程中的網絡流量,從而提升恢復性能,甚至可以在一定帶寬下接近正常讀水平,而且我們可以預見到,在恢復開銷更大的編碼系統上,我們的方案會獲得進一步的性能提升.
但是我們在測試環境上還存在一些不足,比如單機性能有限,在單機上模擬集群,對于集群的很多特性無法表現出來,比如存儲I/O操作,這也是一個影響恢復性能的重要因素;另外一個不足是目前沒有在實際的OpenFlow交換機上去實現我們的功能,這也導致實驗過程中引入了一些額外開銷,雖然我們在測試中修正了這部分開銷,但還是不能完全代表真實場景.關于測試部分,在代碼實現上還存在不少優化空間,可以進一步提升INP方案的性能,另外目前INP方案尚未與更多編碼方案進行對比測試.這些問題都將作為我們未來的研究方向.
5 總 結
本文提出一種新型的基于網絡計算的高效故障重建方案INP來解決糾刪碼系統中恢復開銷太大的問題,考慮到影響恢復開銷的3個因素:較高的網絡傳輸開銷、解碼計算復雜以及大量的磁盤讀寫.INP方案選擇從網絡傳輸量這個主要因素上進行優化.
通過分析傳統糾刪碼系統恢復數據時的網絡情況,可以發現客戶端所在鏈路經常需要傳輸大量的數據,這是由RS碼的解碼算法決定的,傳統糾刪碼系統在解碼時總是把所有需要的數據都傳輸到1個節點上進行計算,這就使得該節點所在鏈路成了整個網絡的瓶頸,從而導致恢復開銷增大.
因此我們利用SDN,設計出一種可以在交換機上進行聚合計算的數據重建方案,以此來減少向后傳輸的網絡流量,最終解決客戶端處的網絡瓶頸問題.
實驗結果顯示INP方案能夠大大減少降級讀過程中的網絡流量,從而提升恢復性能,在1 000 Mbps下能夠降低50%的降級讀開銷,而且隨著帶寬資源緊缺,INP方案中的降級讀可以接近正常讀水平.
