基于工作負載感知的固態硬盤陣列系統的架構設計與研究
2019-04-18 05:14:28許胤龍李永坤
計算機研究與發展 2019年4期
關鍵詞:系統
張 強 梁 杰 許胤龍,2 李永坤,2
1(中國科學技術大學計算機科學與技術學院 合肥 230026)2 (安徽省高性能計算重點實驗室(中國科學技術大學) 合肥 230026)
大數據時代,應對海量數據的存儲分析,基于固態硬盤的容錯陣列系統能夠很好地解決海量數據的可靠存儲和高效訪問的困難.原因有2方面:1)容錯陣列系統既能通過多盤I/O提供數據的高并發性,又能通過存儲冗余信息保障數據的可靠性;2)固態硬盤相比機械硬盤,因其具有更高訪問性能、更低能耗和更強抗震性等特點,進一步提升容錯陣列系統的性能.
多塊固態硬盤組成的容錯陣列系統,往往按照輪轉(round-robin)的順序,并行地在各個固態硬盤上讀寫數據(即每塊盤的地位相同).由于數據本身具有時間局部性及空間局部性的特點,易造成局部盤成為熱點盤,進而會造成整個固態硬盤陣列的性能出現瓶頸(極端情況下會出現單盤熱點),又由于固態盤有壽命限制,對某些盤的過多寫易造成固態盤故障等問題,也會對整個陣列可靠性造成影響.本文在由8個固態硬盤(solid state drive, SSD)構成的RAID -0(redundant array of independent disks 0)陣列系統中測試不同企業級工作負載,均發現熱點盤的現象.
如何保證陣列系統級的負載和磨損均衡以及如何區分各個固態硬盤在陣列中的角色,設計合理的固態硬盤陣列系統架構,對提升固態硬盤陣列系統整體性能及可靠性都有很重要的意義.
本文的主要貢獻有2個方面:
1) 利用工作負載感知特性,在RAID -0陣列中設計了一種基于冷熱數據分離存儲的固態硬盤陣列系統架構HA-RAID(hotness aware RAID),并結合滑動窗口技術進行性能優化.實驗結果表明,HA-RAID可將熱數據相對均勻地存儲到各個盤上,很好地實現了陣列系統級的負載和磨損均衡,從而將陣列中熱點盤出現的比例降低到幾乎為0.
2) 在真實的企業級工作負載下,相比傳統RAID -0,HA-RAID可減少12.01%~41.06%的平均響應時間,很好地實現了陣列系統級的I/O性能提升.
1 相關研究工作
近年來,國內外開展了大量針對固態硬盤的相關研究.其中,許多工作關注固態硬盤本身的內部結構,進而分析并設計高效的垃圾回收機制,以提升固態硬盤的讀寫性能、延長使用壽命;另外,還有不少工作關注多塊固態硬盤構成的存儲陣列系統,利用數據冗余提髙數據的可靠性、延長固態硬盤陣列系統壽命并提升陣列系統性能,這些工作可以分別被概括為2方面:
1) 對于單個固態硬盤的研究.關注固態硬盤的內部結構,如文獻[1]探索了固態硬盤的內部組成以及并行化等,同時實現相應的固態硬盤模擬器.關注固態硬盤邏輯地址到物理地址的映射方式,如文獻[2-3]通過探索在不同的應用場景采用不同的地址映射方式來優化固態硬盤的性能.此外,還有關注固態硬盤的垃圾回收過程,如文獻[4]通過建立分析模型探究了不同垃圾回收算法在垃圾回收開銷和擦寫均衡性之間的權衡關系,提出了可以根據需求調整的d-choice垃圾回收算法;文獻[5-6]通過建立理論模型分析了固態硬盤垃圾回收開銷與工作負載之間的關系,證明了將冷熱數據分離存儲在固態硬盤中能夠大大改善垃圾回收性能;文獻[7-8]提出了不同的熱數據識別方法,以部署到固態硬盤中改善其讀寫性能、減少其垃圾回收開銷等.
2) 對于固態硬盤陣列系統的研究.文獻[9]研究了由多塊固態硬盤構成的陣列系統,通過在多塊固態硬盤之間引入冗余數據,進一步提高了系統的可靠性;文獻[10]針對于固態硬盤的特點,構建了新型的適用于固態硬盤的文件系統;文獻[11-12]通過構建可靠性分析模型對基于固態硬盤陣列系統進行了可靠性評估;文獻[13]通過引入彈性條帶機制解決了傳統磁盤校驗塊更新方式不適用于固態硬盤陣列的問題等.
綜合海量存儲的背景和國內外研究現狀可知,將固態硬盤應用于大規模存儲系統(例如陣列系統)已經成為了當前的趨勢和熱點.盡管已經有很多針對于固態硬盤及其陣列系統的性能優化研究,但是其中仍然存在著很多的不足,特別是從感知工作負載的角度來優化固態硬盤及其陣列系統的性能方面,仍有著進一步的改善空間.如在固態硬盤中部署冷熱數據識別方法用于冷熱數據分離存儲,以減少熱點盤出現的概率,實現陣列級負載和磨損均衡,已有的熱數據方法并不能很好地適應工作負載的變化.
2 陣列系統原始架構
在Linux內核的MD模塊,固態硬盤陣列系統以條帶的形式對陣列的存儲空間進行統一編址.每個請求數據的邏輯地址根據陣列系統的編址方式,映射到某塊盤上的固定邏輯地址(固態盤內部閃存轉換層會進一步對該邏輯地址映射為固態盤上真實物理地址,該映射方式限定在單個固態盤內部映射,并不影響數據在陣列級別的分布).由4塊固態盤組成RAID -0陣列系統如圖1所示.圖1中數字0…7, 8…15,分別代表扇區(sector,大小為512 B)0到7以及扇區8到15;1個頁(page,大小為4 KB)包含8個扇區,如圖1中,page 0包含扇區0到7;1個塊(chunk)包含2個頁,圖1中的扇區0到15構成1個塊;1個條帶(stripe)包含4個塊,條帶大小可表示為
stripe_size=4×chunk_size=4×2 page=
4×2×8 sector=64 sector.
如果請求的數據(扇區編號為32~39)為熱數據,根據陣列存儲空間的編址方式,計算得到扇區編號為32~39的數據存放的物理地址:
stripe_num=32/stripe_size=32/64=0,
chunk_num=32/chunk_size=32/16=2,
dd_idx=chunk_num%disk_num=2%4=2,
chunk_offset=32%chunk_size=32%16=0,
sector_num=stripe_num×chunk_size+
chunk_offset=0×16+0=0.
因此,扇區編號為32~39的熱數據存放在2號盤上,并且盤上的起始物理扇區號為0.各應用系統請求的數據具有時間及空間局部性原理,對某些數據的過多訪問會造成對部分盤的過多讀寫,從而導致熱點盤的出現.例如,對扇區編號32~39的熱數據頻繁訪問,將導致對2號盤的過度讀寫,從而使2號盤變為熱點盤.如果大部分I/O請求集中在2號盤,則不能充分發揮RAID陣列高并發的優勢,進而造成整個陣列系統的I/O性能出現瓶頸.固態盤有擦寫次數壽命限制,對某些盤的過多寫,也會對整個陣列可靠性造成影響.
3 數據冷熱區分算法
為避免第2節中提到的熱點盤出現的問題,需對數據進行冷熱區分,并對區分過的數據進行分別處理.設計冷熱數據區分算法,首先要求其識別結果的有效性,否則不能達到冷熱數據分離存儲對存儲系統性能的優化;其次要求算法識別過程的計算開銷要盡可能小,以免降低存儲系統的請求處理吞吐量.
先前的研究者們已經提出了很多有效的冷熱數據區分算法,其中比較典型的冷熱數據區分算法分別是:基于訪問頻次的算法DAMS[14]、基于緩存替換的算法Two-level LRU list[15]、基于訪問頻次和LRU分組的算法GLRU[16]、基于訪問頻率和最近信息的算法MBF[14-17]、基于采樣技術的算法HotDataTrap[17-18].
DAMS假定可用的內存空間無限大,采用直接地址寫次數統計方法,為每個邏輯塊地址(logical block address, LBA)設立一個計數器,記錄其寫統計次數,圖2為其算法流程.一個LBA請求頁被識別為熱數據,當且僅當其寫統計次數大于等于預定義的閾值.
不同的工作負載一般表現出不同的訪問特征,為了能夠精確地捕獲各種工作負載的訪問特征,保證冷熱數據劃分的合理性,采取以下方法:統計最近訪問數據的修改頻率來動態調整熱度閾值,并對每個邏輯地址的計數器值進行定期減半的衰退操作以反映工作負載的動態性.實驗結果證明該方法能準確地識別出熱數據,從而很好地實現了陣列系統的負載均衡.
考慮到計算開銷對存儲系統的請求響應時間的影響,因此本文在設計和實現固態硬盤陣列系統架構時采用最理想的DAMS作為冷熱數據區分算法,DAMS只需很小的計算開銷,但需要較大的內存開銷來記錄訪問頻次,4.3節會進一步討論如何對內存開銷進行優化.
4 基于熱度感知的陣列系統架構設計研究
本節我們利用工作負載感知特性,在RAID -0陣列中設計了一種基于冷熱數據分離存儲和滑動窗口的固態硬盤陣列系統架構,以此來減少熱點盤出現的概率,使陣列系統達到負載和磨損均衡.
4.1 架構設計
利用第3節介紹的冷熱數據識別方案,我們設計了基于冷熱數據分離存儲和滑動窗口的HA-RAID陣列系統架構,如圖3所示.
基于冷熱數據分離存儲和滑動窗口的HA-RAID陣列系統架構由4個模塊組成:
1) 冷熱數據識別模塊.用于對到來的請求數據進行冷熱識別,以用于在固態硬盤陣列系統中進行冷熱數據的分離存儲.該模塊用第3節介紹的典型的冷熱數據區分算法來實現.
2) 滑動窗口模塊.該模塊用來變換各個盤的角色,使每個盤都有機會成為熱點盤,從而達到將熱數據均勻放置在每個盤上的目的,實現陣列水平的磨損均衡.如圖3所示,設定滑動窗口大小為4,初始窗口位置為1~4號盤.當處理一定數量的連續請求后(本文設置的滑動閾值是1 000),窗口以輪轉的方式向右滑動1個位置,移出窗口的盤由普通盤變為熱點盤,移入窗口的盤由熱點盤變為普通盤.對于識別為熱的數據,將其存儲到熱點盤,普通數據存儲到普通盤.
3) 映射表模塊.該模塊用來記錄請求的邏輯地址到陣列中物理地址的映射關系,由于固態硬盤讀寫的最小單位為頁(4 KB),并且本文所用工作負載全部4 KB對齊,因此映射表中只需記錄數據起始地址除以8后的值即可.本文用數據結構(LBA,SSDN,PSN)來實現該映射表,其中LBA表示請求數據塊的起始邏輯地址(起始邏輯扇區號)除以8后的值,SSDN表示請求數據塊在SSD陣列中被存儲的盤號,PSN表示請求數據塊被存儲的起始物理地址(起始物理扇區號) 除以8后的值.
4) 編址模塊.不同于原始架構以條帶的形式對陣列進行地址空間的編排,我們設計的架構中根據冷熱數據識別結果對請求數據的邏輯地址在陣列中亂序編址,數據在每塊盤上順序存放,當有數據需要存儲到盤上時,以順序的方式為其分配物理地址,并更新映射表模塊對應的表項.如圖3所示,下半部分的編址空間中,扇區0…7,存儲于Disk3的2號物理位置,而右上角處的映射表模塊的表項0,
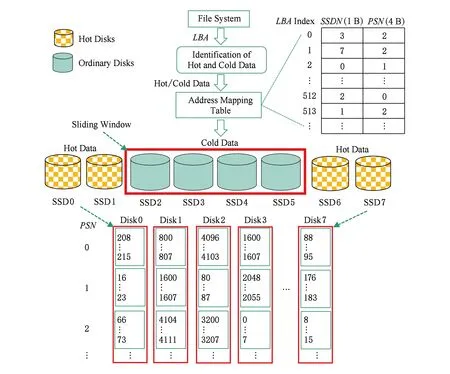
Fig. 3 HA-RAID architecture based on coldhot data separation and sliding window圖3 基于冷熱數據區分和滑動窗口的HA-RAID系統架構
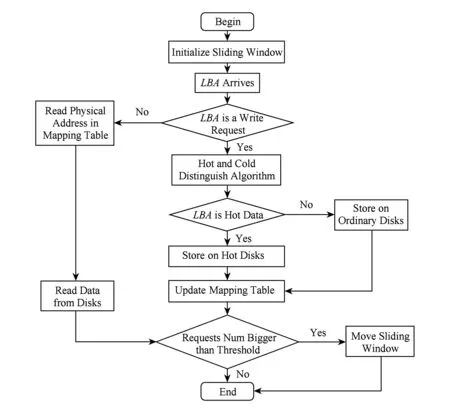
Fig. 4 The I/O flow chat of HA-RAID圖4 HA-RAID的I/O處理流程
即page 0(對應扇區0…7),記錄SSDN為3號盤,且PSN=2.
4.2 處理流程
基于冷熱數據分離存儲和滑動窗口的HA-RAID陣列系統架構,對I/O請求的基本處理流程如圖4所示.首先對陣列中的滑動窗口進行初始化(如滑動窗口大小、滑動窗口初始位置、滑動窗口滑動周期等),然后開始處理文件系統層下發的請求.
對于文件系統層下發的請求LBA,首先判斷它是讀請求還是寫請求,如果為讀請求,則根據維護的地址映射表得到其物理地址(盤號和扇區號),然后在底層盤上讀取數據,完成此次I/O請求;如果為寫請求,則利用冷熱數據識別模塊對其進行冷熱識別:
1) 如果該請求LBA被識別為熱數據,則將其以輪轉的方式存儲到熱點盤中(數據在盤中根據請求先后順序,順序編址并存放),然后更新地址映射表中對應的物理地址,完成此次I/O請求.
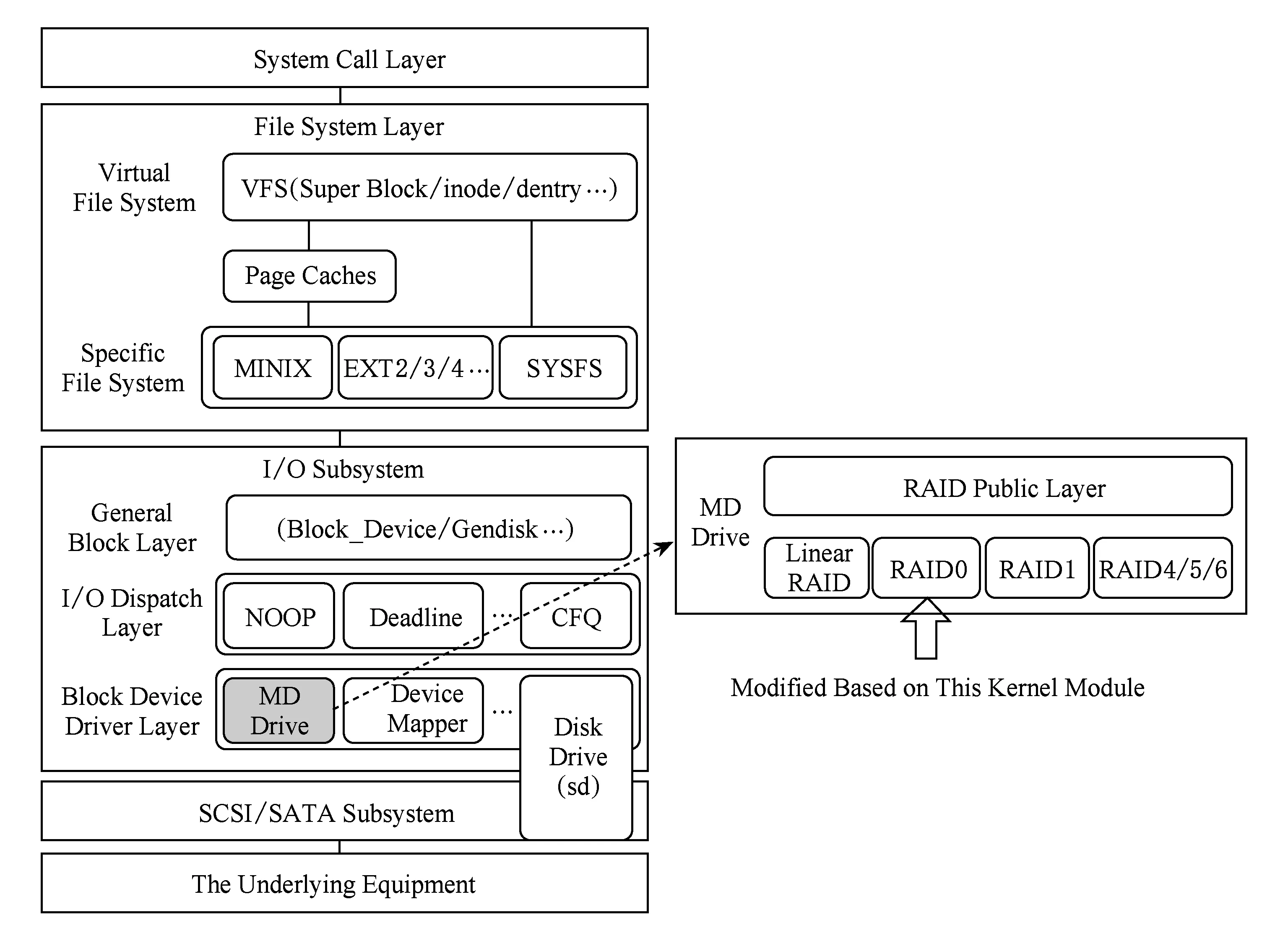
Fig. 5 The hierarchy diagram of Linux kernel block devices for read and write requests圖5 Linux內核塊設備讀寫請求的層次結構圖
2) 如果該請求LBA被識別為冷數據,則將其以輪轉的方式存儲到普通盤中(數據在盤中根據請求先后順序,順序編址并存放),然后更新地址映射表中對應的物理地址,完成此次I/O請求.
最后判斷連續請求的數量是否超過滑動窗口的滑動閾值,如果超過,則將滑動窗口向右滑動1個盤的距離,繼續處理下一個I/O請求;否則,結束此次I/O請求并開始處理下一個I/O請求.
4.3 實現細節
本文在Linux內核MD模塊下的RAID -0中用C語言實現SSD陣列系統架構,這里將詳細介紹SSD陣列系統架構實現過程中的一些實現細節,如Linux內核MD模塊的層次結構圖,實現邏輯地址到物理地址轉換的映射表的構造與管理,處理請求過程中的數據對齊.
1) MD模塊層次結構.Linux內核響應塊設備讀寫請求的層次結構,主要由系統調用層、文件系統層、塊I/O子系統、SCSI(small computer system interface)/SATA(serial advanced technology attach-ment)子系統和底層存儲設備組成.本文通過修改圖5中塊設備驅動層的MD驅動下的RAID -0源碼來實現冷熱數據區分算法和基于冷熱數據分離存儲的SSD陣列系統架構,以實現底層設備陣列中各盤的負載和磨損均衡.
2) 映射表的構造與管理.由于在本文設計的系統架構中,同一個寫請求不是固定寫到一塊盤的固定物理地址上,而是每次都寫到不同盤的不同物理地址上,以實現負載和磨損均衡.因此需要構造與管理一張映射表來實時記錄請求數據塊的邏輯地址到SSD盤號和該盤上物理地址的映射關系.用數據結構 (LBA,SSDN,PSN) 來實現該映射表,如圖6所示,其中LBA表示請求數據塊的起始邏輯地址(起始邏輯扇區號) 除以8后的值,SSDN表示請求數據塊在SSD陣列中被存儲的盤號,PSN表示請求數據塊被存儲的起始物理地址 (起始物理扇區號) 除以8后的值.使用雙數組進行陣列系統中映射表的管理.
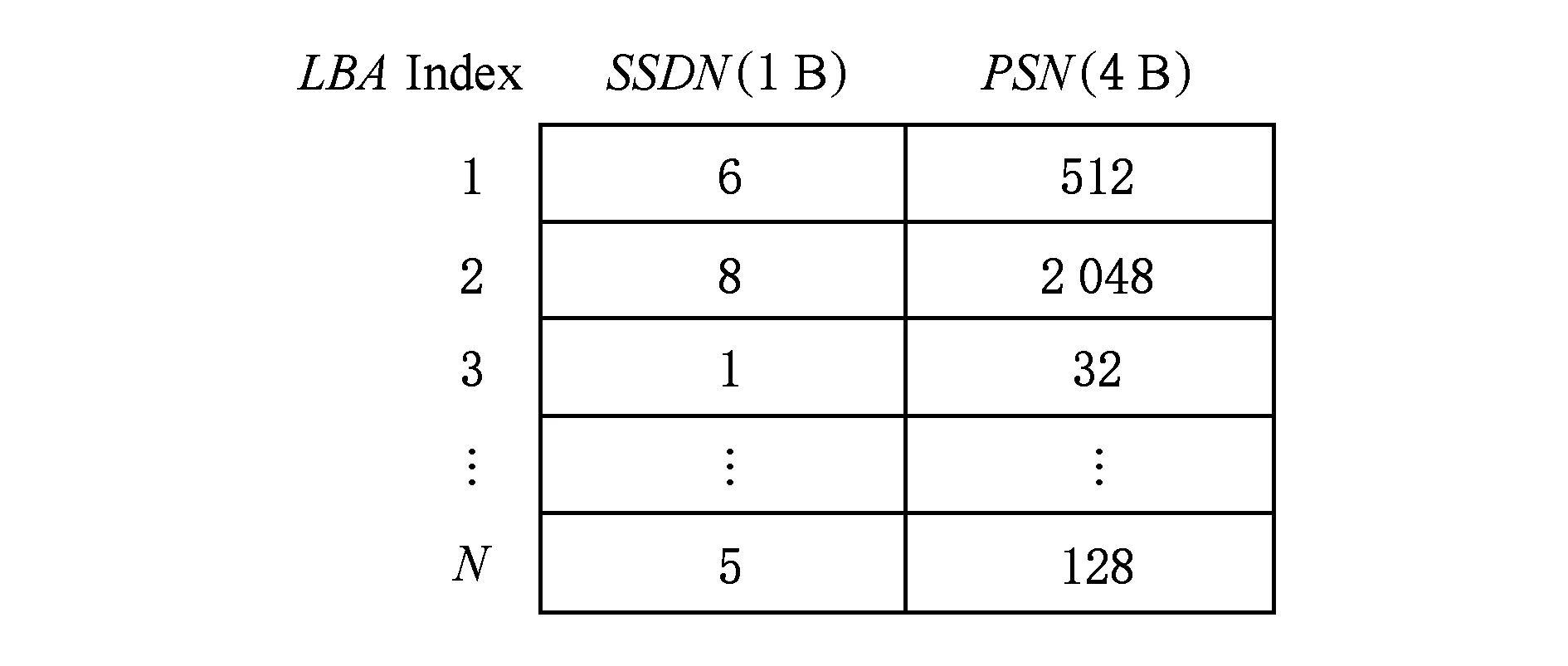
Fig. 6 The mapping table圖6 映射表示意圖
LBA用于雙數組中的索引,無需存儲;SSDN使用1 B存儲,能夠存儲最多256塊盤;PSN使用4 B存儲,能夠存儲的扇區號最多為4 294 967 296,滿足120 GB固態硬盤的容量要求.這樣僅用5 B就足夠記錄1個數據塊的映射關系,對于固態硬盤陣列1 TB的數據空間僅僅需要的映射表空間為1.25 GB.
3) 數據對齊.在系統架構實現中,設定系統的讀寫單位為一個特定大小4 KB的數據塊chunk.為了實現讀寫請求的數據對齊,當一個到來的請求不能與設定的chunk對齊,若小于chunk大小,則將其補充到chunk大小;若大于chunk大小,則將其補充到chunk的整數倍.這樣做是因為固態硬盤的讀寫基本單位為4 KB,并且實驗中設置chunk大小為4 KB,為了讓一次chunk大小的請求集中在1個塊,而不是操作多個塊 (比如未對齊時,1個chunk大小的請求可能會操作2個塊,寫入數據時需要讀-擦-寫,造成性能下降;對齊時,1個chunk大小的請求只會操作1個塊,從而提升固態硬盤性能).
5 實驗與結果
為了進行評估,本文將設計的系統架構部署到由多個商用固態硬盤組成的陣列系統上,并在系統中使用了4個真實的企業級工作負載.由于本文的方案是在原始RAID -0陣列系統上進行的改進,故將原始RAID -0用作本文的實驗基準,并從2個方面對RAID -0和HA-RAID進行對比,即固態硬盤陣列系統的負載均衡以及請求的平均響應時間.
5.1 實驗設置
1) 工作負載.實驗中使用了企業數據中心的塊級traces工作負載,分別為寫占主導的hm_0,src2_0,usr_0和stg_0.其中,hm_0代表硬件監控服務器上的負載,src2_0代表源控制服務器上的負載,usr_0代表用戶主目錄服務器上的負載,stg_0代表Web分段服務器上的負載[19].
我們在實驗中對工作負載進行了預先處理,即數據4 KB對齊.所有工作負載的工作集總大小在10 GB到20 GB之間;與此同時,所有的工作負載具有很強的訪問傾斜性和很高的訪問局部性.例如在后3個工作負載中,大部分寫請求集中在2%~4%的地址空間,而第1個工作負載中,大部分的寫請求集中在10%的地址空間.各工作負載的統計數據如表1所示.
2) 實驗環境.本文將HA-RAID陣列系統架構在物理機器上加以實現.實驗硬件配置為:戴爾PowerEdge T620服務器 (配有4個2.40 GHz Intel Xeon CPU和8 GB物理內存空間) ,1個Intel 530系列固態硬盤用作系統盤,8個Intel 530系列固態硬盤用于構建一個固態硬盤陣列,每個盤的容量120 GB,SATA3接口,MLC(multi-level commission)類型.陣列設置數據塊chunk的大小為4 KB.使用FIO工具測試了固態硬盤的隨機讀寫延時 (50%讀,50%寫,I/O大小4 KB,隊列深度設置為1,單線程,并且繞過磁盤緩存),測試結果如表2所示.
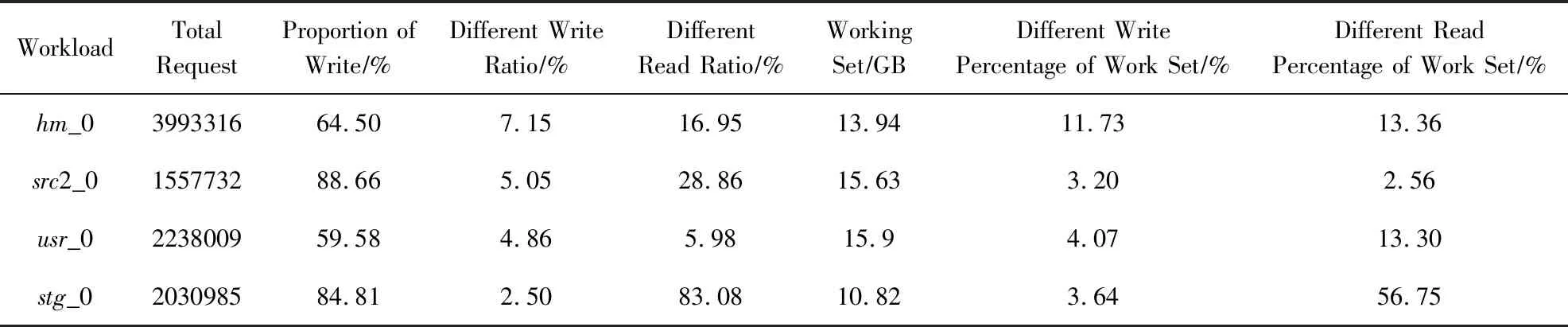
Table 1 Statistical Data of Different Workloads表1 不同工作負載的統計數據
3) 冷熱區分算法參數設置.由于本文重點研究陣列系統的磨損均衡和性能提升,并不對冷熱數據區分算法做深入研究,留在以后再探究.因此在實驗中使用計算時間開銷最少的DAMS作為本文設計的陣列系統架構中的冷熱數據區分算法.不同工作負載下DAMS算法的參數設置如表3所示.
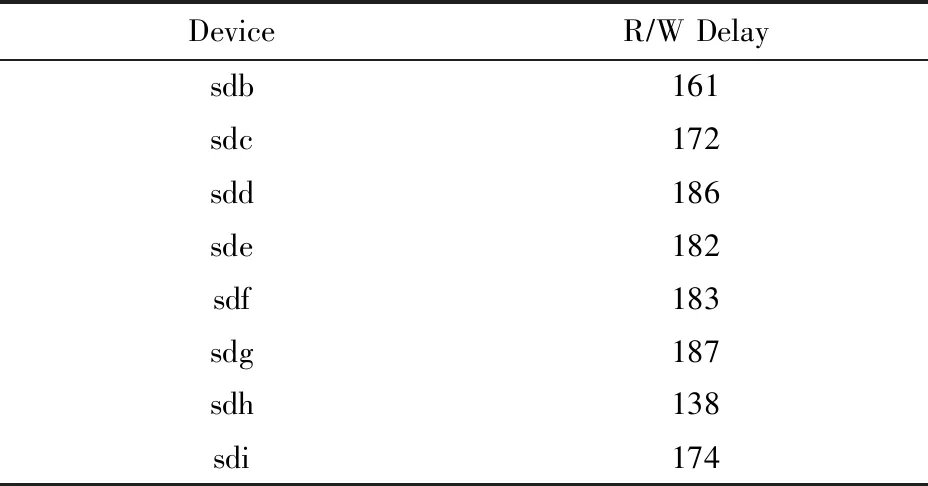
Table 2 Performance Indicators of Intel 530 Series SSD
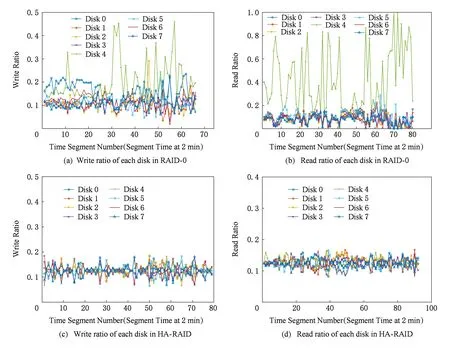
Fig. 8 Read/write ratio of each disk in RAID -0 and HA-RAID under hm_0圖8 負載hm_0下RAID -0與HA-RAID陣列中各盤上的讀寫比例

Table 3 Parameter Setting of DAMS Algorithm Under
Note:Under various workloads, the parameters of DAMS algorithm are experimentally tested and the best value is taken.
5.2 系統請求平均響應時間評估
實驗中,通過記錄每個請求的響應時間和系統處理請求的總個數,計算得到每個請求的平均響應時間,實驗結果展示在圖7中.
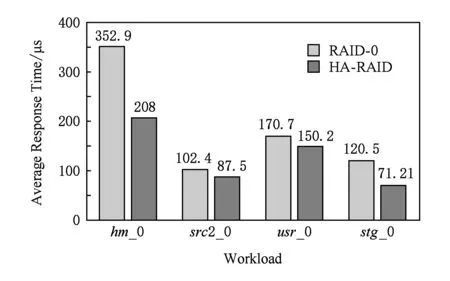
Fig. 7 The average response time of I/O requests圖7 不同工作負載下系統請求的平均響應時間
通過圖7可知,采用陣列系統架構HA-RAID,相比于原始架構RAID -0,部署在實際系統上時,極大地減少了請求的平均響應時間.實驗結果驗證了區分數據冷熱的有效性,因為原始架構會因為冷熱數據的混合存儲而導致熱點盤的出現,從而不能發揮RAID陣列高并發的優勢,進而會一定程度上延遲用戶的訪問請求,造成整個陣列系統的I/O性能出現瓶頸.對比原始架構RAID -0,本文設計的陣列系統架構HA-RAID部署在系統上時,對請求的平均響應時間減少了12.01%~41.06%,有效提高固態硬盤陣列系統的I/O性能.
5.3 系統負載均衡評估
固態硬盤容錯陣列系統的負載和磨損不均衡,都容易降低系統的可靠性,造成數據的遺失.因此,本文實驗統計了各種工作負載下陣列系統中各個盤的負載和磨損情況,統計結果如圖8~11所示.
由圖8所示可知,工作負載為hm_0時,對于原始架構RAID -0,各盤上的讀寫比例在每個時間點都有較大差異,且波動幅度較大;對于熱度感知架構HA-RAID,各盤上的讀寫比例在每個時間點都差異不大,主要集中在0.1~0.15,且波動幅度很小,很好地實現了陣列系統級的負載均衡.
由圖9所示可知,工作負載為src2_0時,對于原始架構RAID -0,各盤上的讀寫比例在每個時間點都有較大差異,且波動幅度較大;對于熱度感知架構HA-RAID,各盤上的讀寫比例在每個時間點都差異不大,主要集中在0.1~0.15,且波動幅度很小,很好地實現了陣列系統級的負載均衡.
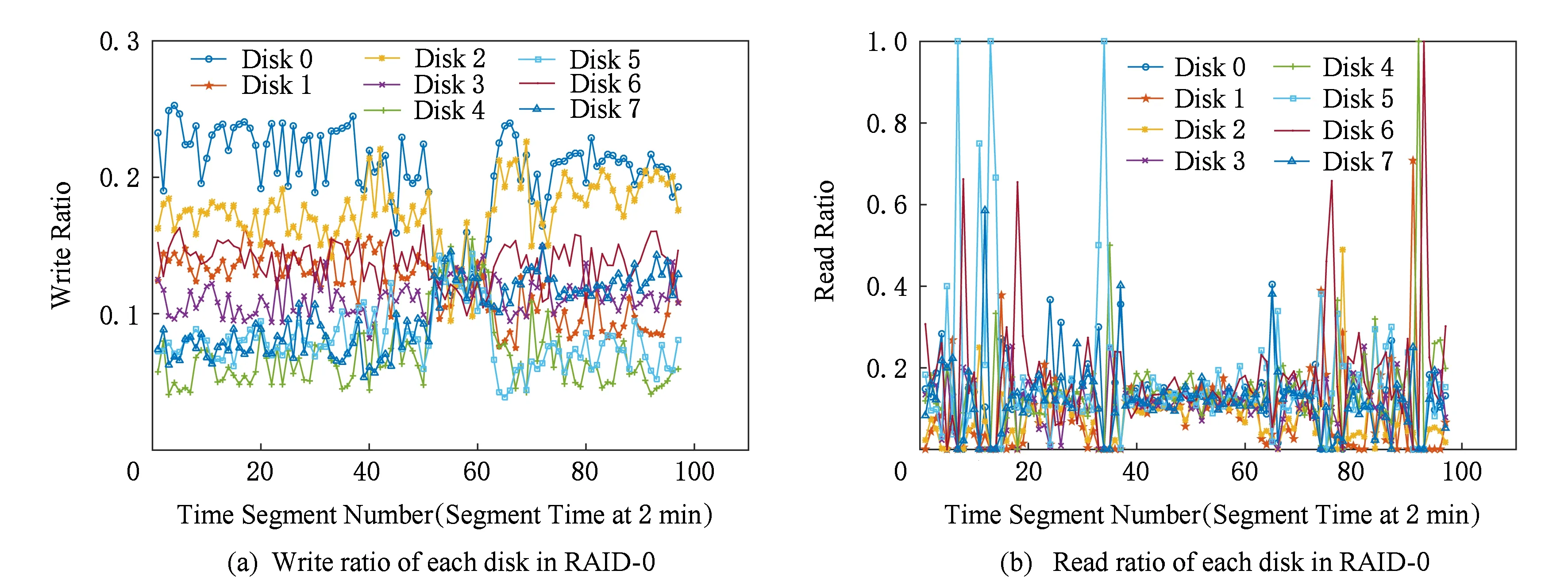
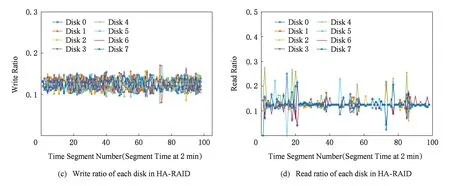
Fig. 9 Read/write ratio of each disk in RAID -0 and HA-RAID under src2_0圖9 負載src2_0下RAID -0與HA-RAID陣列中各盤上的讀寫比例
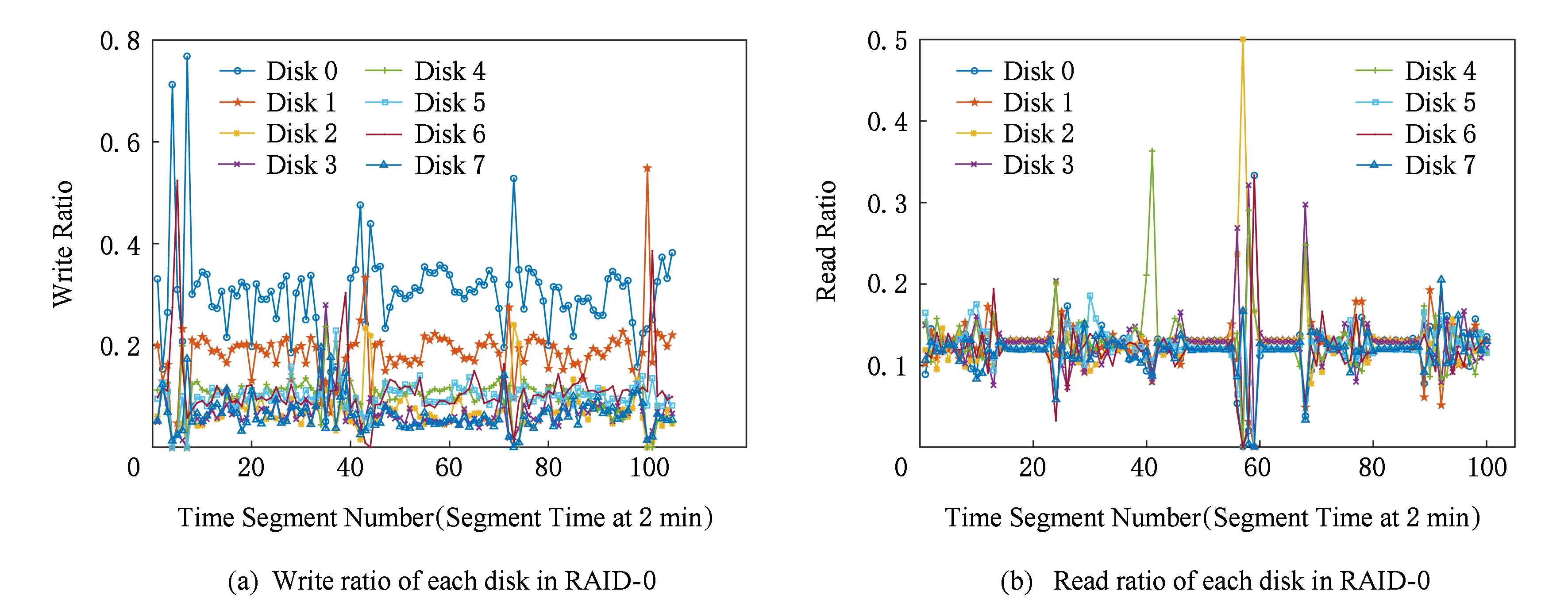
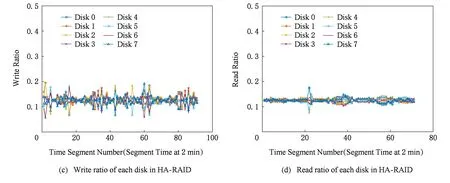
Fig. 10 Read/write ratio of each disk in RAID -0 and HA-RAID under usr_0圖10 負載usr_0下RAID -0與HA-RAID陣列中各盤上的讀寫比例
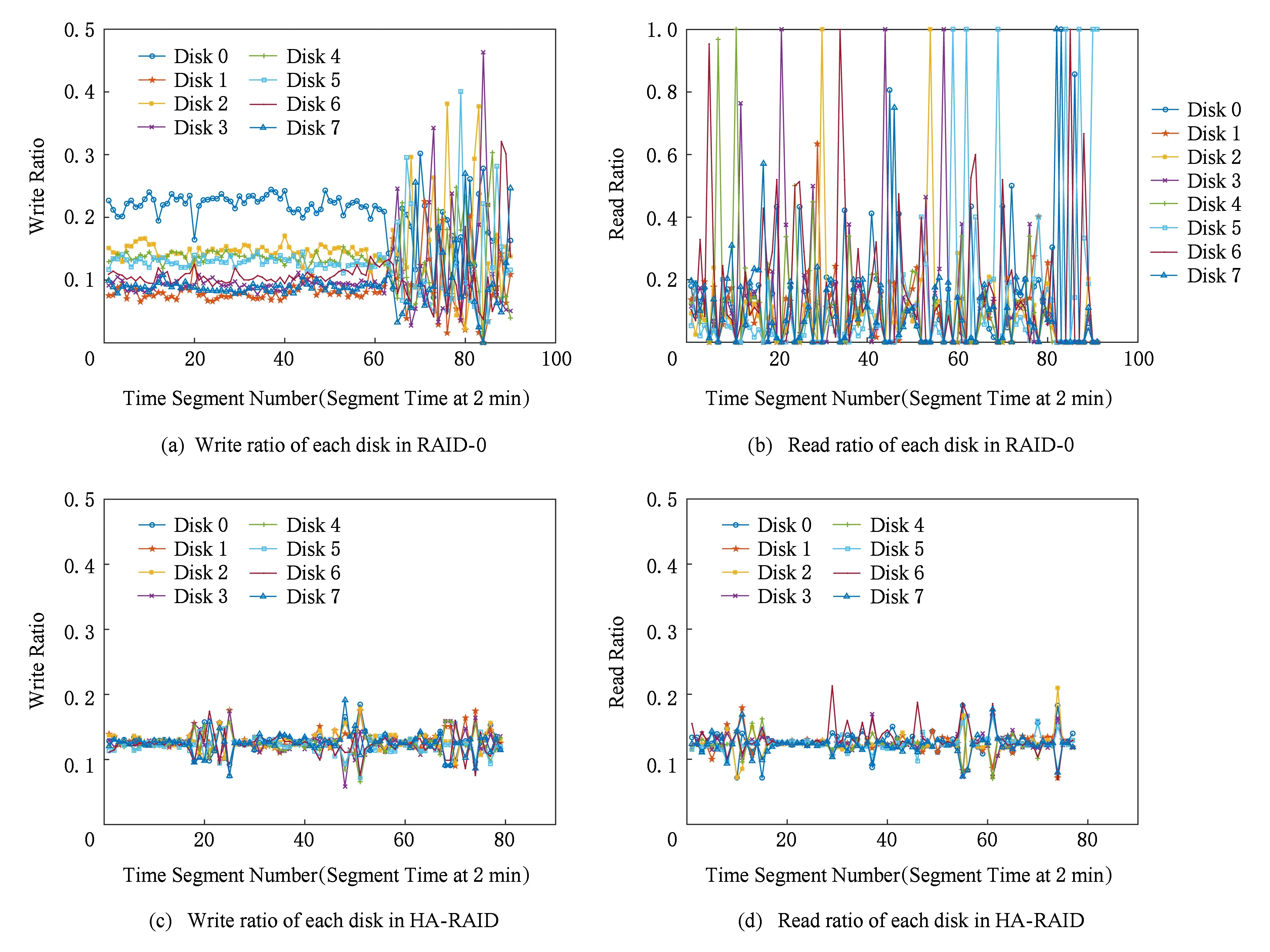
Fig. 11 Read/write ratio of each disk in RAID -0 and HA-RAID under stg_0圖11 負載stg_0下RAID -0與HA-RAID陣列中各盤上的讀寫比例
由圖10所示可知,工作負載為usr_0時,對于原始架構RAID -0,各盤上的讀寫比例在每個時間點都有較大差異,且波動幅度較大;對于熱度感知架構HA-RAID,各盤上的讀寫比例在每個時間點都差異不大,主要集中在0.1~0.15,且波動幅度很小,很好地實現了陣列系統級的負載均衡.
由圖11所示可知,工作負載為stg_0時,對于原始架構RAID -0,各盤上的讀寫比例在每個時間點都有較大差異,且波動幅度較大;對于熱度感知架構HA-RAID,各盤上的讀寫比例在每個時間點都差異不大,主要集中在0.1~0.15,且波動幅度很小,很好地實現了陣列系統級的負載均衡.

Fig. 12 HA-RAID architecture extended to RAID -5 array圖12 擴展至RAID -5陣列上的HA-RAID系統架構
6 HA-RAID擴展至RAID -56
基于RAID -0設計的系統架構HA-RAID 很好地實現了陣列系統級的負載均衡和磨損均衡,從而延長整個陣列的使用壽命并提升I/O性能.但RAID -0陣列沒有引入任何冗余數據,無法保證數據的可靠性.而數據可靠性保證在實際應用中又非常重要,企業的核心數據一旦丟失,損失將是無法估量的.因此,我們將基于RAID -0設計的HA-RAID系統架構擴展至RAID -5陣列,主要設計思路如圖12所示.
對基于RAID -0的HA-RAID系統架構,將其擴展至RAID -5陣列,需要做3個方面的修改:
1) RAID -5陣列需要對寫入內存中的數據以條帶形式組織,并使用與陣列盤上對應的滑動窗口將條帶劃分為熱區域和冷區域,條帶中的熱區域存放識別出的熱數據,冷區域存放普通數據.
2) 對于LBA讀請求,根據地址映射表得到其物理地址(盤號和條帶號),然后在底層盤上讀數據.
3) 對于LBA寫請求,在內存以條帶的組織形式對其進行緩存:①如果該LBA被識別為熱數據,則將其存儲到條帶的熱區域(滑動窗口內); ②如果該LBA被識別為冷數據,則將其存儲到條帶的冷區域(滑動窗口外).當一個條帶上數據存滿,則計算產生該條帶的校驗信息P,然后將條帶數據和校驗數據以條帶形式追加寫入陣列(校驗數據以輪轉的方式存儲到普通盤上),并更新地址映射表中對應的物理地址.
RAID -6陣列上的實現方法與RAID -5陣列類似,只是增加了計算開銷和額外校驗數據的存儲,數據可靠性更高,這里不再贅述.
7 總 結
本文在RAID -0陣列中設計了一種基于冷熱數據分離存儲的固態硬盤陣列系統架構HA-RAID,并結合滑動窗口技術進行優化.相比原始RAID -0陣列架構,HA-RAID可以將熱數據相對均勻地存儲到各個盤上并減少12.01%~41.06%的平均響應時間,很好地實現了陣列系統級的負載和磨損均衡及陣列系統的I/O性能提升.
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(2019年12期)2019-12-25 03:06:46
制造技術與機床(2019年10期)2019-10-26 02:47:06
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
鐵道通信信號(2018年5期)2018-06-28 03:06:24
家庭影院技術(2017年9期)2017-09-26 03:41:45
知識經濟·中國直銷(2017年5期)2017-06-15 20:28:19
通信電源技術(2016年6期)2016-04-20 06:21:32
