全局跳數優化與跳距誤差修正的DV-Hop改進算法
2019-04-10 06:37:34任克強
傳感技術學報 2019年3期
任克強,鄧 浪
(江西理工大學信息工程學院,江西 贛州 341000)
無線傳感器網絡(Wireless sensor Network,WSN)中,采用多個節點隨機分布,自組織一個多跳網絡,部署在需要監測的某些特定區域,采集與處理監測到的信息,同時將處理后的信息發送給監測人員[1]。WSN作為物理世界與數字世界的橋梁,在目標追蹤、環境監測、軍事偵察甚至在能量管理中已被廣泛的應用[2]。在實際的應用中,缺少位置信息的感知數據是沒有意義的[3]。因此,了解目標的位置信息對許多環境感知的應用十分重要,節點定位技術也成為WSN研究的關鍵技術之一。
在WSN現有的定位機制中,根據測量距離方式的不同可以劃分成基于測距(Range-based)算法和非測距(Range-free)算法兩個類別[4]。獲取角度或距離信息對于Range-based算法來說十分重要,所以對整個傳感器網絡的硬件配置要求更為嚴格,同時也具有更好的定位精確度。Range-based算法主要有:AOA(Angle of Arrival)、TOA(Time of Arrival)、TDOA(Time Difference of Arrival)和RSSI(Received Signal Strength Indicator)等[5]。與Range-based算法相比較,從硬件成本和實現復雜度等方面考慮,Range-free算法實現簡單,成本較低,但精度稍有不足。目前,Range-free算法主要有:質心定位(Centroid)、凸規劃定位(Convex Programming)、DV-Hop(Distance-Vector-Hop)、MDS-MAP和APIT(Approximate PIT Test)等算法[6]。
作為Range-free算法的代表之一,DV-Hop算法應用廣泛、易于擴展并且受限制的條件更少,能做到符合大多數應用場景所要求的定位效果,所以得到了廣泛應用與研究[7]。針對DV-Hop自身的一些不足之處,國內外相關學者從諸多方面提出了相應的改進方法。文獻[8]對多種Range-free定位技術進行了評估,采用基于粒子群(PSO)的DV-Hop算法,與傳統DV-Hop算法相比具有更好的定位精度和魯棒性,雖然PSO算法收斂速度快,但是容易陷入局部最優并且不適合用于處理離散的優化問題。文獻[9]針對計算過程中容易產生誤差積累的最小二乘法提出改進方案,并對錨節點跳距進行權值處理,通過改善平均跳距的相對誤差值,提高定位的準確率,但在增加了定位準確率的同時,加大了全網的計算量。文獻[10]采用混合加權定位的方法,通過對質心算法進行兩次加權以獲取更好的定位精度,相較于其他混合算法,該算法在耗能控制和計算量方面具有一定優勢。文獻[11]在對誤差距離權值處理的基礎上,對網絡中節點位置關系進行判斷,利用距離未知節點最近的3個錨節點的跳距信息通過歸一化加權的方式計算未知節點的估算跳距,同時針對節點的坐標估算,采用改進的遺傳算法進行處理,但采用遺傳算法需要考慮到早熟收斂的問題,進化至后期時局部搜索的能力較弱。文獻[12]提出基于PSO-BP傳感器位置確定的改進策略,通過利用改進后的卡爾曼算法對RSSI值進行相關優化,目的是減少噪聲與誤差,最后優化閾值與權值,該算法具備獲取全局最優值同時避免局部最優值出現的能力,有效的改善神經網定位算法的效果。文獻[13]首先對DV-Hop的洪泛機制進行改進,獲取最近錨節點的平均跳距參與估算,然后通過改進的差分校正算法減少跳距的累積誤差,最后對整個預測的區域使用粒子濾波,提升估計節點坐標的準確率且通信開銷相對較低。
針對DV-Hop算法跳數不合理及跳距估算階段誤差累積的問題,本文對DV-Hop算法的跳數及跳距兩個方面進行優化與修正,提出了一種基于全局跳數優化與跳距誤差修正的DV-Hop改進算法,采用通信半徑等相關參數優化跳數的取值,使跳數趨于合理,通信雙方之間估算跳距的誤差進一步減少,以提升定位精度。
1 DV-Hop算法及定位誤差
1.1 DV-Hop算法
DV-Hop算法是基于矢量路由的經典Range-free算法之一,定位過程主要包含3個基本步驟[14]:
①節點間跳數的估算
所有錨節點將位置與跳數數據發送給可通信節點,接收節點收集到該數據后,保留該數據并使跳數加1,繼續轉發至未獲得節點數據的目標,直至整個網絡中相對距離最近的錨節點都能獲取到的對方位置和跳數數據。
②節點間跳距的估算
網絡中全部的錨節點獲得了最近錨節點的最小跳數值與節點位置信息,利用獲得的數據通過式(1)對節點平均每跳距離進行估算:
(1)
式中:(xi,yi)與(xj,yj)為錨節點i、j的實際位置坐標,hij為錨節點i、j之間的最小跳數,Hopsizei為錨節點i平均每跳距離。
通過式(2)計算錨節點i、j之間的估算距離dij:
dij=Hopsizei×hij
(2)
③未知節點坐標的估算
利用節點距離和跳數的估算數據,采取極大似然法估算出未知節點的坐標。
1.2 定位誤差
DV-Hop算法中網絡連通度和錨節點間距離信息對未知節點位置估算十分重要[15],定位過程中產生誤差的原因主要有:
①DV-Hop算法的定位精度很大程度上取決于平均跳距的估算值是否合理,單一的錨節點估算出的平均跳距不能完全代表整個網絡的跳距情況,并且多跳情況下,未知節點與錨節點的估算距離并不是按照直線計算,節點密度低的區域節點的折線率增大,距離誤差將進一步累積,對定位效果產生影響。
②網絡中隨機播撒的WSN節點拓撲結構往往不規則,區域內節點密集程度也就存在差異,不同節點密度估算出的節點間跳數信息以及平均跳距存在一定的誤差。根據DV-Hop算法的特性,錨節點通信范圍內可通信的節點均被視為單跳節點,當大量單跳節點參與距離估算,平均跳距就不能真實的反映網絡中各節點間的距離,導致估算距離與真實距離之間存在差異,降低定位精度。
因此,本文從節點之間的跳數以及節點之間估算距離對DV-Hop算法進行修正。
2 本文算法
2.1 節點間跳數修正
DV-Hop算法估算節點間跳數時,通信區域內的所有鄰居節點都被視作1跳。如圖1所示,B、C、D和E都為節點A的單跳節點,但對應的真實距離卻各不相同,如果這類節點都按照DV-Hop算法處理,會產生較大的定位誤差。針對此類情況,本文引入節點偏差系數、節點相對最佳跳數以及跳數差值修正系數,并與影響跳數的相關參數相結合,提出一種全局節點跳數優化的方法。
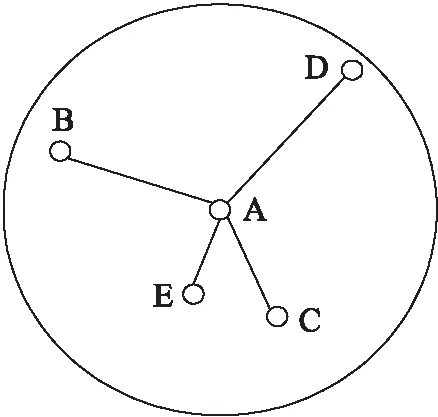
圖1 通信范圍內單跳誤差
對節點的通信區域內單跳的數值進行限制,將節點i、j之間的真實距離dij與通信半徑R之比定義為相對最佳跳數Hij:
Hij=dij/R
(3)
比較估算跳數hij和相對最佳跳數Hij二者的差值,通過式(4)定義偏差系數σij:
σij=(hij-Hij)/hij
(4)
偏差系數σij能夠體現互相通信的錨節點間估算跳數hij與相對最佳跳數Hij存在的差異情況。σij越大,標志著二者之間存在更大的偏差。在通信半徑不變的情況下,估算跳數將大于或等于相對最佳跳數,針對此類情況利用式(5)定義差值修正系數ωij,以優化跳數信息減少誤差的累積。
(5)
此外,跳數數據還受到多個參數的影響,錨節點占比、播撒區域面積和通信半徑都會影響通信過程中的路徑選擇,使跳數數據發生變化。局部區域內錨節點數量增多,將對定位效果產生一定的影響,對于此類區域,錨節點占比增加,網絡連通情況更好,會使一定通信半徑內局部單跳節點增多,將此類節點估算出來的跳數應用于全網,使相對最佳跳數之間誤差進一步加大。于是定義跳數修正系數θij:
(6)
式中:L為正方形播撒區域的邊長,ρ為錨節點占比。
θij隨著整個網絡連通度的增加而減少,當網絡連通情況較差且錨節點比例較低時,利用θij對跳數進行修正,降低單跳節點對整體跳距計算的影響。當網絡連通度較好且錨節點比例較高時,θij值將會變小,對跳數的影響也會降低,避免多跳情況下的誤差累積。
通過差值修正系數ωij與跳數修正系數θij對錨節點跳數進行修正:
(7)

將差值修正系數ωij與跳數修正系數θij共同應用于全網節點的跳數估算:
(8)
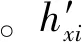
2.2 平均每跳距離修正
DV-hop算法中平均跳距對于節點間距離的估算十分重要。如圖2所示,數據通過節點A發送至節點B共需3跳,DV-Hop算法中折線距離為估算距離,顯然與虛線所示的真實距離存在較大的誤差。因此,本文利用最佳指數下的最小均方誤差準則計算平均跳距并且與依據實際距離得出的單跳平均誤差共同修正平均跳距,以進一步降低平均跳距的誤差,改善定位效果。

圖2 節點間距離誤差
對于錨節點,通過式(2)可估算出錨節點平均每跳距離的估計值,已經獲取錨節點位置信息的前提下,可以利用錨節點i與s的真實距離與估算距離計算出二者的總體差值:
(9)
通過式(9)求出的總差值除以總跳數計算出平均每跳距離誤差εi:
(10)
利用估算距離加上平均每跳的距離誤差,得到校正后的平均跳距Dhopε:
Dhopε=hopsizei+εi
(11)
采用自適應的最小均方誤差準則,目的是使總誤差全局最小,相對于偏差和方差來說應用于跳距的計算更加合理,但需要使代價函數f滿足:
(12)
對代價函數f求hopsizei的偏導并取值為0,得到平均跳距Dhopf:
(13)
通過式(13)計算出的平均跳距,估算距離與實際距離的誤差較小,此外本文將變化的指數值μ引入式(13),根據不同μ值對定位誤差的影響,選取最佳值應用于平均跳距的修正,式(13)改寫為:
(14)
為了避免單一跳距均值不能很好的反映整個網絡中跳距的情況,減少數據不夠準確而帶來誤差累積的風險,將已校正的平均跳距值與使用最佳μ值下的最小均方誤差計算出的平均跳距進行二次平均,得到修正后的平均跳距Dhopave:
(15)
利用式(15)求得修正后的平均跳距,能夠更接近于整個網絡中實際平均跳距,進一步減少跳距誤差累積的影響,從而提升定位精度。
3 仿真結果與分析
為了測試本文算法的性能表現,采用MATLAB R2016b仿真平臺對本文算法、DV-Hop算法和文獻[14]算法從最小均方誤差的不同μ值、差值修正系數的不同n值、網絡內節點總數、節點通信半徑以及錨節點占比對定位誤差的影響進行仿真實驗。仿真實驗環境:100 m×100 m的仿真區域內,隨機安置150個節點,其中錨節點比例為10%,所有節點的通信半徑均為R=30 m。
采用平均定位誤差Errorave作為評價定位效果的標準。
(16)
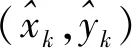
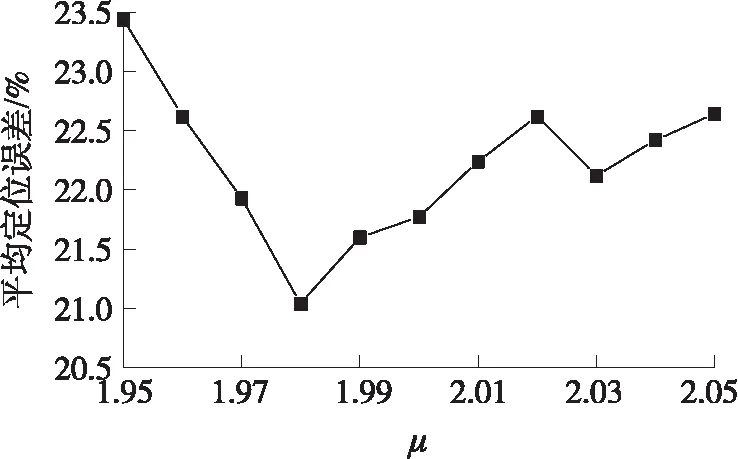
圖3 μ值變化下的平均定位誤差
首先驗證最小均方準則下的指數值的變化對平均跳距修正的影響,在100 m×100 m的仿真區域內,安置150個節點,錨節點占比為10%,通信半徑R=30 m,本文對μ取1.95到2.05,步長為0.01。從圖3中能夠了解到,μ值取1.98時平均定位誤差最小。相較于初始原始取值2,平均定位誤差稍稍降低,與μ值取1.95相比較,平均定位誤差減少約1.7%,表明采用最小均方誤差準則估算平均跳距時,μ的取值將會對平均跳距產生干擾,改變最后的定位效果。本文算法在驗證各參數對平均誤差影響的實驗中,均以1.98為最小均方誤差最佳指數值。
圖4表明了在100 m×100 m的仿真實驗環境下,n值變化下的平均定位誤差的變化情況。本文對n取1.95到2.05,單次增幅為0.01。從圖4中可以看到n取值變化的過程中,平均定位誤差存在些許波動,在1.96取值下定位效果優于其他取值,相較于2.05的取值,效果提升了1.85%。表明n的取值會干擾到跳數值的測定,影響定位誤差。本文算法在驗證各參數對平均誤差影響的實驗中,差值修正系數中n均取1.96。

圖4 n值變化下的平均定位誤差
圖5表明仿真實驗環境下,設置通信半徑由20 m單次遞加4 m最高至40 m條件下,本文算法、文獻[14]算法以及DV-Hop算法平均定位誤差的變化情況。隨著通信半徑的增長,3種算法定位精度均有所提升,但在增至到某一數值時,例如36 m,文獻[14]的平均定位誤差出現了些許波動,表明在某些條件下,半徑的增加對文獻[14]的算法而言,定位精度提升不明顯。總體來說,本文算法平均定位誤差相比于文獻[14]和DV-Hop算法減少約6.58%~9.56%和13.1%~14.5%,且相較于文獻[14]與DV-Hop兩種算法,大通信半徑導致節點路徑選擇減少的情況下,整體性能表現較好。
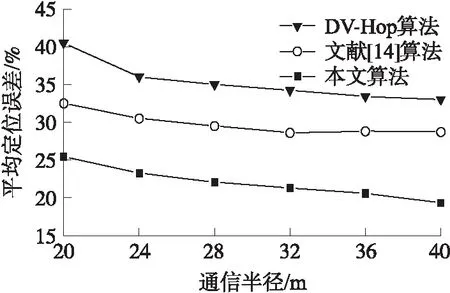
圖5 不同通信半徑的平均定位誤差
圖6表明仿真實驗環境下,錨節點比例單次增長2%,由初始的8%增長至20%的條件下,本文算法和對比算法定位效果。隨著仿真環境中錨節點占比的增長,3種算法的定位效果都不同程度的增長。DV-Hop算法錨節點占比由8%增至10%的過程中,定位精度有明顯的提升,而后錨節點占比的增長對定位效果的影響較小,逐漸趨于平穩。本文算法與文獻[14]算法均能針對DV-Hop算法在錨節點比例較低時節點隨機分布不均影響定位效果的情況進行優化,定位精度提升明顯。控制錨節點占比固定值為12%的條件下,DV-Hop算法平均定位誤差為32.8%,文獻[14]算法為27.6%,而本文算法為22.04%,并且整體效果也優于其他兩種算法圖7表明仿真實驗環境下,節點總數在100~200范圍內,每次增加20的條件下,DV-Hop、文獻[14]以及本文算法在節點數量變化下平均定位誤差的趨勢。DV-Hop算法整體表現較為平穩,誤差最大值與最小值僅相差1.7%,而本文算法與文獻[14]算法整體效果依然優于DV-Hop算法,由于節點總數的增長,單個錨節點覆蓋的未知節點數也一同增長,使整個網絡的連通度更好,提升了定位精度。相較于文獻[14]與DV-Hop算法,本文算法總體定位精度提升約3.39%與9.69%,表明在WSN總節點數增加的情況下,本文改進算法效果好于文獻[14]算法與DV-Hop算法。
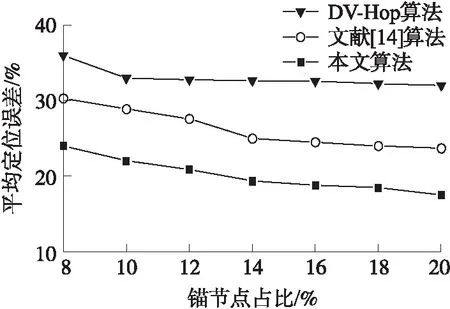
圖6 不同錨節點占比的平均定位誤差

圖7 不同節點總數的平均定位誤差
4 結束語
針對WSN中DV-Hop算法信息轉發時跳數不合理和跳距誤差累積的問題,為了降低累積誤差,以改善定位效果為目的,本文提出了一種跳數優化與跳數修正的DV-Hop改進算法。改進算法通過定義跳數修正系數對跳數信息進行優化,再對指數最佳值下的平均跳距和校正后的平均跳距進行二次優化,并在選取最佳μ值與最佳n值的前提下,對WSN環境中不同通信半徑、不同錨節點比例和不同節點總數的環境下進行定位性能仿真測試。實驗結果表明,在多種仿真環境且不增加額外的硬件開銷和通信成本的條件下,本文算法的定位表現優于DV-Hop算法與相關算法,表明本文對DV-Hop算法的改進能夠有效提升WSN中節點的定位精度。如何進一步降低跳距誤差累積,以使未知節點位置信息更加準確是后續研究的重點方向。
