多特征融合的圖像格貼近度匹配方法
2019-04-04 07:38:38肖滿生肖哲萬爛軍
西安交通大學學報 2019年4期
肖滿生,肖哲,萬爛軍
(湖南工業大學計算機學院,412007,湖南株洲)
圖像檢索通常包含基于標注的圖像檢索(ABIR)與基于內容的圖像檢索(CBIR)[1]。ABIR方法需要手動地進行標記或描述,不但耗時,而且部分圖像很難準確地用簡單關鍵詞進行標注和描述,因此其應用受到限制[2-3]。CBIR方法根據圖像的紋理、灰度或顏色特征進行檢索,因檢索效率比ABIR方法高,近年來已越來越受到學者們的青睞,并出現了很多與CBIR方法相關的具體方法[4-7]。
在有關CBIR方法的研究中,目前基于紋理特征的圖像分析與識別方法在場景圖像、遙感圖像和醫學圖像等領域有著重要的應用,國內外專家提出了許多基于此技術的圖像分析識別方法[1,4,8-13],如Nishant等在圖像特征區域劃分中提出了利用用戶興趣度來選擇區塊,并用區塊的紋理特征來定義區域向量,從而有效地完成圖像內容的匹配和識別[4];Elalami利用色彩共生矩陣(CCM)提取紋理特征來完成圖像檢索[1];Mehta等采用局部多項式逼近技術的尺度自適應變換方法描述紋理特征來識別人臉[9];Martinez-Murcia與Samiee等基于灰度共生矩陣(GLCM)來提取紋理信息,并在醫學病理圖像的識別檢測中進行了應用[10-11];而黃明明則提出一種新的加權中心對稱局部三值模式(WCS-LTP),融合圖像局部形狀和紋理信息來更準確地描述圖像[13]。
上述這些方法都是從紋理的角度對圖像內容進行處理和識別,由于紋理僅反映像素的局部空間分布特征,并未考慮像素本身的灰度、空間的位置情況及組成圖像中各對象的形狀,因此識別效率不高,識別精度普遍不超過80%,個別方法在50%以下。此外,顏色也是圖像最重要的特征,但提取顏色特征時,很多方法只考慮了像素的灰度信息,沒有考慮鄰近像素對視覺的影響,且需要進行顏色量化處理,導致特征維數過高、計算復雜[14-15],盡管如文獻[16]所提出的顏色矩陣方法簡單有效,不需要對顏色量化,特征維數也低,但在實驗中發現,該方法單獨進行圖像檢索時效率較低。
基于此,在文獻[1]與文獻[4]所提方法的基礎上,提出了一種基于多特征融合的格貼近度圖像內容匹配方法,該方法計算簡單、易于實現,具有較好的圖像檢索性能。
1 圖像預處理
由于圖像集中各圖像大小不一,組成圖像的對象多而復雜,因此進行圖像匹配前,應先進行預處理,即利用最鄰近插值圖像縮放算法對原始圖像進行縮放,在尺寸一致的基礎上進行圖像分割,得到圖像中的各對象也即后續圖像匹配的基元。但是,利用該算法處理時所求得的像素點位置存在小數,如按四舍五入處理,則圖像縮放存在嚴重失真。因此,考慮局部性原理,本文采用8-鄰域法來進行圖像縮放,即在處理時以原圖像中源像素點為中心,計算其8-鄰域像素(包含本身共9像素)的平均灰度值,以此作為源像素點所對應的縮放后目標點的像素值。進一步針對不同圖像的組成對象多而復雜的情況,采用FCM算法[17-18]對縮放后的圖像進行聚類分割,得到圖像的各個子對象以便于匹配。
2 圖像特征描述
常見的基于內容的圖像特征有顏色(灰度)特征、紋理特征及像素空間密度特征等。紋理是一種局部特征,是圖像中所對應物體表面特征結構的反應,但紋理不能表達像素固有的灰度信息和密度分布情況;顏色(灰度)是圖像內容的最基本特征,它描述了圖像中各像素的表現,但僅僅考慮像素本身的灰度不能很好地表現圖像中的對象情況,還必須結合它的鄰域像素。為了更好地識別圖像,本文提出了一種灰度特征描述子,結合圖像紋理、像素密度分布提取相關特征。
2.1 灰度特征描述子
圖像中各像素與其鄰域像素存在著聯系。一幅顏色分布均勻的圖像,其鄰域像素間灰度差別小,它們屬于同一類的可能性較大,而像“萬綠叢中一點紅”這樣的圖像,紅色與周圍的像素顏色差別大、聯系小,它們屬于同一類的可能性較小[19]。另外,圖像中的噪聲點與周圍正常像素點的差別也很大。因此,對圖像內容的描述除了要考慮像素本身的灰度外,還要兼顧鄰域像素的關系。設某一像素集X,i和j分別為X中的像素點,即i,j∈X,其灰度分別表示為xi、xj,且j為i的某一鄰域窗口內的像素點,則像素點i的灰度特征表示為
(1)
式中:Ni表示落在像素點i的鄰域窗口內的像素集合;NR是像素集Ni的基數,即鄰域的大小,可取8、16、24等,一般情況下,NR的值為8,即i的8-鄰域像素,Sij表示像素點i與其鄰域像素點j的關系,它由像素間的灰度關系和空間關系合成,表示如下
(2)
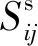
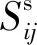
(3)

(4)
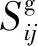
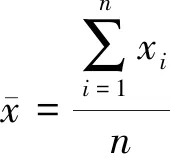
(5)
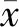
2.2 紋理特征描述子
Haralick等提出灰度共生矩陣(GLCM)來描述圖像的紋理特征,矩陣中的元素md,θ(i,j)表示圖像I中兩像素點i、j的歐氏距離為d、角度為θ的像素對的個數,具體表達式為
md,θ(i,j)=
#{(ix,iy),(jx,jy)∈I|I(ix,iy)=xi,
arctan((jy-iy)/(jx-ix))=θ}
(6)
其中I(ix,iy)表示圖像I中坐標位置為(ix,iy)的像素灰度值。令d=1,θ分別為0°、 45°、 90°、135°,得到4個不同方向的灰度共生矩陣Pd,θ,即P1,0°、P1,45°、P1,90°、P1,135°,并對矩陣中每個元素p(i,j)進行歸一化處理
(7)
式中:R為歸一化常數,常取矩陣中所有滿足給定d,θ的灰度像素對之和,即
(8)
Haralick基于GLCM提出了14個統計特征,本文根據圖像匹配的需要,選取其中4個有代表性的特征,即角二階矩(ASM)、逆差矩(IDM)、相關性(COR)、熵(ENT),分別用f1、f2、f3、f44個特征描述子表示,有關這些特征描述子的表示方法見文獻[8]等。將這4個特征采用高斯歸一化方法對其進行歸一化處理
(9)
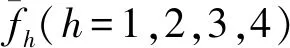
(10)
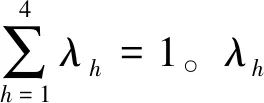
2.3 像素密度特征描述子
像素密度特征主要描述同一灰度級的像素在鄰近區域內分布的密集程度,其分布越多越密集,越能清晰地表現出圖像中的某個對象的形狀[20],鑒于此,本文設計了一個樣本密度分布函數來描述該問題。
設圖像中某對象Qk的中心像素點k(即FCM聚類分割中的聚類中心)與其鄰近像素點j之間的歐氏距離為djk=|xj-xk|(xk、xj分別代表兩像素點灰度值),則以像素點k為中心的密度分布函數可定義為
(11)
式中nk為Qk中像素數。從式(11)可以看出,對象Qk中像素點越多,即nk越大,像素點k周圍的像素灰度值與xk越接近,djk→0,則Zk值越大,由于j是中心像素點k的鄰近像素,不代表k本身,即xk≠xj,從而有djk≠0。因此,Zk表示對象中像素的密度分布特征,它也是圖像相似匹配計算的指標之一。
3 基于多特征融合的格貼近度圖像相似匹配
3.1 格貼近度及多特征融合
格貼近度[21]是模糊集理論中的一種模式識別方法,它按“擇近原則”對相關數據集進行分類,一般用于群體模型的識別,其計算簡單、識別效率高。設對象A、B的特征向量分別為A=(a1,a2,…,an),B=(b1,b2,…,bn),其中ai,bi分別為對象A,B的特征屬性,則A、B的格貼近度定義為
N(A,B)=(A·B)∧(Ac·Bc)
(12)
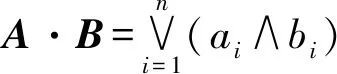
從格貼近度的定義可知,對象間的格貼近度越大,表示對象越接近,因此可以用格貼近度來判斷兩圖像的匹配程度。一幅圖像中包含多個不同對象,將對象的像素灰度特征(式(1))、合成后的紋理特征(式(10))及像素密度特征(式(11))融合組成對象的特征向量集,即對象Qk的特征向量集為Ok={TQk,DQk,ZQk},其中TQk、DQk、ZQk分別代表對象Qk的合成紋理特征、像素灰度特征、像素密度特征,并將該對象作為待匹配的查詢對象。同時從圖像集中提取另一圖像的相應對象Gk的特征向量集設為Gk={TGk,DGk,ZGk},利用式(12)求出兩對象的格貼近度N(Qk,Gk)。同樣,考慮到不同對象的這3種特征在計算中的重要程度不一樣,因此,在融合對象特征向量中設一權重因子,用來標識其重要程度,即Qk={w1TQk,w2DQk,w3ZQk},w1、w2、w3的測定可采用綜合評判方法[21]或由實驗測定給出。
3.2 基于多特征融合的格貼近度圖像匹配實現
基于格貼近度的圖像內容匹配算法實現如下。
輸入圖像Q、格貼近度閾值。
輸出圖像集中按格貼近度排序的圖像。
步驟1圖像縮放,采用2.1節的8-鄰域最鄰近插值縮放算法對圖像進行縮放,得到大小統一的圖像;
步驟2圖像變換,利用Matlab軟件將圖像轉換為灰度圖像;
步驟3圖像分割,采用FCM算法對待匹配的圖像進行分割,得到各個對象;
步驟4提取各對象的紋理特征,即ASM、IDM、COR、ENT在4個方向(0°,45°,90°,135°)、距離為1的紋理特征值,并計算4個方向紋理特征均值,按式(9)進行歸一化處理;
步驟5紋理合成,將步驟4中得到的紋理特征按式(10)進行合成,各權重λi在合成前根據圖像特點提前給定;
步驟6計算像素灰度,根據2.1節中的灰度特征描述子計算各對象的像素灰度gi,在計算灰度前需提前給出或設定λg、λs及σg的值;
步驟7像素分布特征值計算,根據2.3節中的像素密度特征描述子,計算各對象像素的密度特征值Zk并做歸一化處理;
步驟8特征向量合成,采用步驟5~7中所得到的特征值合成加權后各對象的特征向量Qk,其中權值為w1、w2、w3,采用綜合評判方法提前給出;

步驟10將上述得到的格貼近度按大小進行排序,并根據具體要求取一閾值,大于閾值的排序輸出即為圖像匹配結果。
4 實驗結果分析
為了驗證本文所提出的格貼近度匹配算法的有效性,用WANG和Oxford flowers2個圖像數據集進行了具體的實驗。實驗環境采用Matlab2014a軟件編程,實驗評價指標有2個,第一個是平均歸一化修正檢索秩[22](ANMRR,設為Ar),設N(qi)(i=1,2,…,n)表示圖像集中與查詢圖像qi相似的所有圖像數,并設M=max{N(q1),N(q2),…,N(qn)},K=min{4N(qi),2M},則與查詢圖像qi相似的圖像在檢索結果序列中所處的第k個位置的檢索秩為
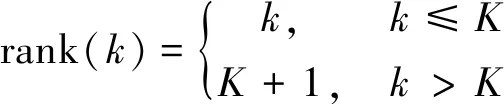
(13)
Ar=
(14)
從Ar的定義可知,Ar值越小,表明該算法的檢索性能越好;第二個是結合查準率P、查全率R的綜合評價指標Pr,在模式識別理論中,查準率和查全率是一對互為抑制的評價指標,為了兼顧查準率和查全率,根據文獻[4]中所描述的P-R關系曲線圖,本文定義了一種結合查準率與查全率的綜合評價方法,即
(15)
式中r為查準率的偏移量,其值決定了P、R的相對重要程度。當r=1時,P、R視為同等重要;r>1時,視為P的重要程度大于R,反之亦然。一般情況下取r=1即可。
另外,為了驗證所提方法的有效性,將文獻[1]中的特征壓縮匹配方法(CMS)、文獻[4]提出的興趣區域匹配方法(MROI)與本文的格貼近度匹配方法(LCD)進行了對比實驗。
4.1 WANG圖像集實驗
WANG圖像集包含1 000幅圖像,共10類,每類100幅。實驗中,將所有圖像縮放成300像素×200像素大小。FCM聚類分割時,在輸入查詢圖像時,聚類類別數根據不同情況自主確定,如Dinosaurs在聚類分割時類別數c=2,聚類最大迭代次數為50,聚類終止條件為兩次迭代時類中心之差不超過0.01,該數據集在灰度特征描述子的計算過程中,λg、λs都取值為1,在8-鄰域灰度化實驗中,經計算σg=49.3,4個紋理特征在表達信息的重要程度上基本一樣,故合成時權重λi的值都為0.25。在求解格貼近度時,采用綜合評判方法取得特征向量中各特征分量(紋理特征、灰度特征、像素密度特征)的權值w1、w2、w3,實驗中,w1=0.25,w2=0.5,w3=0.25,主要考慮圖像紋理不突出,像素密度分布也沒有顏色信息重要。每一類圖像集中隨機抽取20幅圖像作為查詢輸入圖像進行匹配,求取每一次匹配的格貼近度并排序,進而統計Pr、Ar的平均值及總平均值,其他兩種方法MROI、CMS的實驗過程與實驗要求參見文獻[1,4]。3種方法所測得的各項指標數據見表1。
從表1可以看出,比較10類圖像的平均歸一修正檢索秩Ar,本文所提出的LCD方法其Ar最小,表明該方法的檢索性能優于其他兩種方法,CMS方法的Ar次之,MROI方法的Ar最大;LCD方法的Pr比CMS和MROI方法都大,表明其檢索效果總體水平比其他兩種好。個別類的圖像查詢匹配中,LCD方法檢索效果并不都是最優,如Food類圖像查詢匹配,其Ar就不如CMS方法。3種方法進行檢索運行的時間相差不大(LCD方法主要在灰度特征描述計算這一環節所用時間多,而格貼近度計算所用時間相對少),運行時間優勢不明顯,故沒有單獨列出運行的時間效率進行討論。

表1 3種方法對WANG圖像集的Ar、Pr的實驗數據對比
4.2 Oxford flowers圖像集實驗
Oxford flowers圖像集包含17類,如Buttercup、Colts’foot、Daffodil、Daisy等,每類80個圖像。實驗前,先將所有圖像縮放成150像素×150像素。在進行格貼近度匹配計算時,確定紋理、灰度、像素密度3個特征分量的權值w1=0.4,w2=0.4,w3=0.2,這是因為各圖像紋理明顯、顏色突出,其他參數設置同4.1節中的WANG圖像集實驗。選出Buttercup、Colts’Foot、Daffodil、Daisy和Dandelion 5類圖像進行實驗,隨機從每類圖像中選取10個圖像作為輸入查詢對象,計算各類的Ar、Pr及相應平均值,3種方法實驗對比結果見表2。
由表2可以看出,3種方法中本文所提LCD方法得到的5類圖像的Ar最小,Pr平均值最大,說明本文所提LCD方法在圖像內容匹配檢索中有較好的性能。同樣,在3種方法進行檢索的運行時間上,LCD方法的運行時間比CMS及MROI稍短,但相差不大,故也沒有單獨列出其運行的時間效率進行討論。
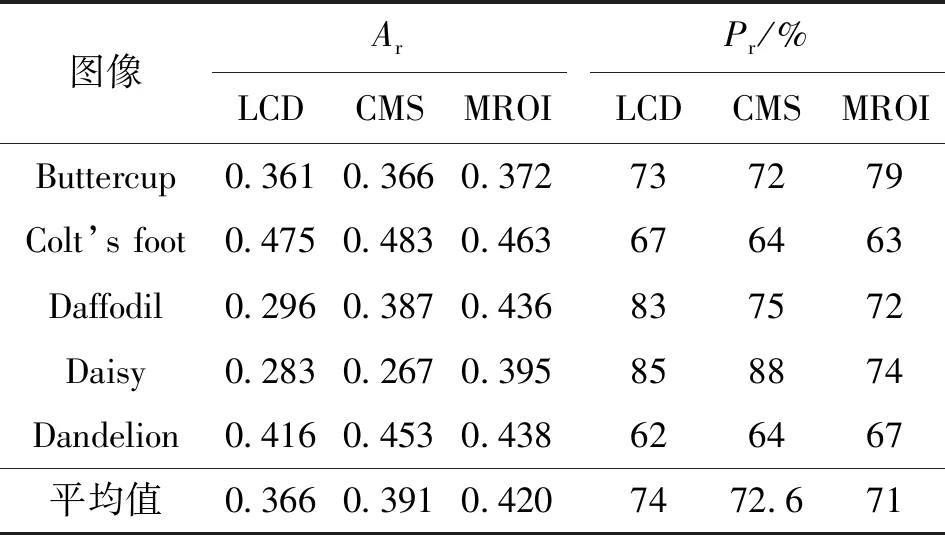
表2 3種方法對Oxford flowers圖像集的Ar、Pr的實驗結果對比
5 結 論
本文通過分析基于內容的圖像檢索技術,提出了一種采用多特征融合的格貼近度的圖像匹配方法,給出了從圖像縮放、分割、特征提取融合及格貼近度計算等完整的圖像匹配計算過程,并通過實驗對比驗證了該方法的有效性。本文的主要優勢有兩個:一是圖像灰度特征描述子的定義與設計,它綜合考慮了組成圖像像素本身的灰度信息及鄰域像素間的相互影響,使得對圖像內容描述更加客觀;二是格貼近度匹配,將格貼近度用于圖像對象匹配,算法簡潔,容易實現,且性能較好。改進了圖像檢索的評價方法,提出了一種結合查準率、查全率的評價指標,但該方法所引入的部分參數,如各紋理特征的合成權重參數λi要在實驗前根據圖像集的具體情況主觀給出,缺少理論依據,可能會導致部分實驗結果不準確,這個問題的解決將是下一步的研究工作。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
兒童故事畫報(2019年5期)2019-05-26 14:26:14
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
