基于SVM的鐵路貨運站裝車數預測
2019-04-03 00:47:36余姣姣
物流技術 2019年3期
關鍵詞:優化
余姣姣
(蘭州交通大學 交通運輸學院,甘肅 蘭州 730070)
1 引言
鐵路貨物運輸是一個受自然條件、經濟發展、社會狀況和自身供給等多方面因素影響的復雜綜合系統,是資源配置和宏觀調控的重要工具。鐵路貨運量作為交通運輸的一個客觀反映,對其的準確預測是制定鐵路發展規劃、開展鐵路市場營銷的重要環節。而鐵路貨運站裝車數作為鐵路貨運量的重要組成部分,對其進行預測對鐵路貨運部門制定裝車計劃等非常重要。
目前,已有多種方法用于鐵路貨運量的預測,并取得較好的成果,主要有分形理論[1]、馬爾可夫鏈[2]、回歸分析[3]、復雜網絡理論[4]、神經網絡理論[5]、支持向量機[6-7]、灰色預測[8]等。然而現有的文獻還沒有對鐵路貨運站裝車數的預測,所以本文將以廣鐵集團的岳陽北和湘潭東等貨運站為例對鐵路貨運站裝車數做出預測。
支持向量機(Support Vector Machine,SVM)是一種新型的神經網絡,是基于結構風險最小化準則的學習方法,該方法以統計學習理論為基礎,在小樣本、高維、非線性預測領域有著很好的應用效果[7、9]。在數據較少的情況下,可以較好地描述鐵路貨運站裝車數的非線性及隨機性特征,提高預測精度。粒子群優化算法(Particle Wwarm Optimization,PSO)是一種基于群體智能的全局隨機搜索算法,可用于非線性及復雜優化問題的求解[10]。
本文以廣鐵(集團)公司2017年3月至2017年7月的裝車數為研究對象,從中選取岳陽北和湘潭東等貨運站為例,采用相空間重構將時間序列數據重構成多維,運用粒子群算法優化支持向量機參數,從而建立預測模型。實例分析的結果驗證了該方法的有效性,為鐵路貨運調度及貨運站對裝車計劃的安排布局提供了依據,并優化資源配置,提高鐵路貨運的效益。
2 鐵路貨運站裝車數預測方法
2.1 相空間重構

式中:m為嵌入維;N為時間序列的數據個數;r為計算中所取的搜索半徑;τ為時間延遲;M=N-(m-1)τ,為m維相空間中嵌入點數目;dij=||xi-xj||∞,為∞范數;θ為Heaviside函數,其表達式為:

相空間重構中有兩個關鍵的參數:嵌入維數m和時間延遲τ。Takens定理中,對于理想的無限長和無噪聲的一維時間序列,嵌入維數m和時間延遲τ可以取任意值,但實際應用中的時間序列都是有限長度且存在噪聲,嵌入維數m和時間延遲τ不能任意取值,須精心確定,否則會極大地影響重構的相空間的質量[11]。確定嵌入維數m和時間延遲τ的方法有多種,本文選用C-C算法進行聯合計算。
考慮混沌時間序列x={xi,i=1,2,...,N},重構相空間X={Xi},Xi為m維相空間中的相點:則嵌入時間序列的關聯積分為

關聯積分為累積分布函數,表示相空間中任意兩點之間距離小于r的概率。另外定義x={xi}的檢驗統計量:

S(m,N,r,τ)反映了時間序列的自相關特性,最優時間延遲τd可取S(m,N,r,τ)第1個零點。
選擇最大和最小的半徑r,定義差量:

ΔS(m,N,r,τ)度量了 S(m,N,r,τ)對所用半徑 r的最大偏差。
綜上所述,最優時間延遲τd可取S(m,N,r,τ)的第1個零點或ΔS(m,N,r,τ)的第1個局部極小點。
根據m和 k(r=kσ/2)的取值設定nm和nk的值,定義指標:

尋找Scor(τ)的全局最小點即可獲得最優延遲時間窗口τw。
本文采用陸振波的工具箱對各車站的數據進行相空間重構,其中采用C-C Method求出各組數據的時間延遲τd和時間窗口τw,然后根據延遲時間、嵌入維數和時間窗口三者之間的關系τw=(m -1) τd求得相應的嵌入維數。
2.2 支持向量機
支持向量機[12-14]是Corinna Cortes和Vapnik等于1995年首先提出的,它在解決小樣本、非線性及高維模式識別中表現出許多特有的優勢,并能推廣應用到函數擬合等其他機器學習問題中。它是建立在統計學習理論的VC維理論和結構風險最小原理基礎上的,根據有限的樣本信息在模型的復雜性(即對特定訓練樣本的學習精度)和學習能力(即無錯誤地識別任意樣本的能力)之間尋求最佳折衷,以期獲得最好的推廣能力。
給定一數據點集G={(xi,di)},其中 xi是輸入向量,di是期望值,n是數據點的總數。SVM使用非線性映射φ:Rn→Rm(m≥n),將輸入空間映射到高維特征空間,再在特征空間中使用式(6)來擬合數據{(φ(xi),di)。

其中w、φ(x)為m維向量;?,? 表示特征空間中的點積;b為閾值。
系數w、b通過最小化式(7)來估計。

不敏感損失函數由式(8)確定。

此時為有限性約束的二次規劃問題。引入拉格朗日乘子,由式(6)給出的決策回歸方程可改寫為:

其中,d>0,σ>0,b>0,δ>0,稱為核參數。本文選取高斯徑向基核函數為本文預測的核函數。
2.3 PSO優化SVM
粒子群優化算法(PSO)[15]是一種進化計算技術,是由Eberhart博士和kennedy博士在1995年提出的一種新的全局優化進化算法,源于對鳥群捕食的行為研究,與遺傳算法類似,是一種基于迭代的優化工具。
支持向量機中懲罰參數c、核參數、不敏感損失參數ε是決定預測性能的三個重要參數,利用PSO對SVM的參數進行優化選擇,對提高預測性能具有重要的意義。相關步驟如下:
Step1 設置PSO初始參數,如種群數、迭代數、變異率、交叉率等,隨機產生一組粒子的初始位置和速度。
Step2 選擇適應度函數,本文選擇均方誤差作為適應度函數來判斷參數選擇的優劣,均方誤差函數的表達式如下:
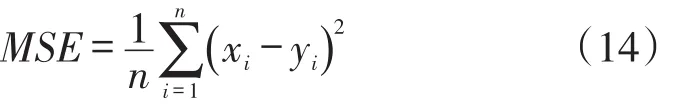
其中,xi為實際值,yi為預測值,n為預測個數。
Step3 根據兩個對比更新粒子的位置。當前適應度值和所經歷過最好位置pbest對比,若當前適應度好,則更換當前適應度值為最好位置;當前適應度值與全局最優位置gbest對比,若當前適應度好,則更換當前適應度值為全局最優位置。
Step4 按照式(11)和(12)對粒子的速度和位置進行更新。

其中,ω表示慣性權重;d=1,2,...,D;i=1,2,...,n;k為迭代次數;Vid為粒子的速度;c1,c2為加速因子;r1,r2是介于0到1之間的隨機數。
Step5 判斷是否到達最優,若滿足,輸出最優參數值;若不滿足,轉Step2。
2.4 貨運站裝車數預測模型
本文通過粒子群算法優化選取SVM的最佳參數,建立預測模型,具體步驟如下:
Step1 采用小波降噪的方法對原始數據進行降噪處理,以提高預測的精度。
Step2 通過陸振波的相空間重構工具箱中C-C方法將一維時間序列數據重構成多維。
Step3 將多維數據分為訓練樣本和測試樣本,并分別進行歸一化處理,將數據歸一化到[0,1]區間,本文采用最大最小法對數據進行歸一化處理,具體公式為:

其中,xmin為序列中最小的數值,xmax為序列中最大的數,xk為實際數值,x為歸一化后的數值。
Step4 參數優化。初始化粒子群,運用PSO對SVM進行參數優化,對比更新粒子的速度和位置,從而得到優化的參數,本文采用林智仁教授的libsvm工具箱中psoSVMcgForRegress函數進行參數優化。
Step5 利用得到的最優參數,并采用libsvm工具箱中SVMcgForRegress函數進行模型的訓練,建立預測模型并對測試樣本進行預測,再將結果反歸一化,得到原始數據的預測值。
3 實例分析
利用所建立的模型對廣鐵(集團)公司的岳陽北、湘潭東等貨運站2017年3月至2017年7月的裝車數在Matlab R2014a進行實例分析,兩個車站的預測結果與真實值的對比如圖1、圖2所示。兩個車站預測值與真實值的誤差量如圖3、圖4所示。
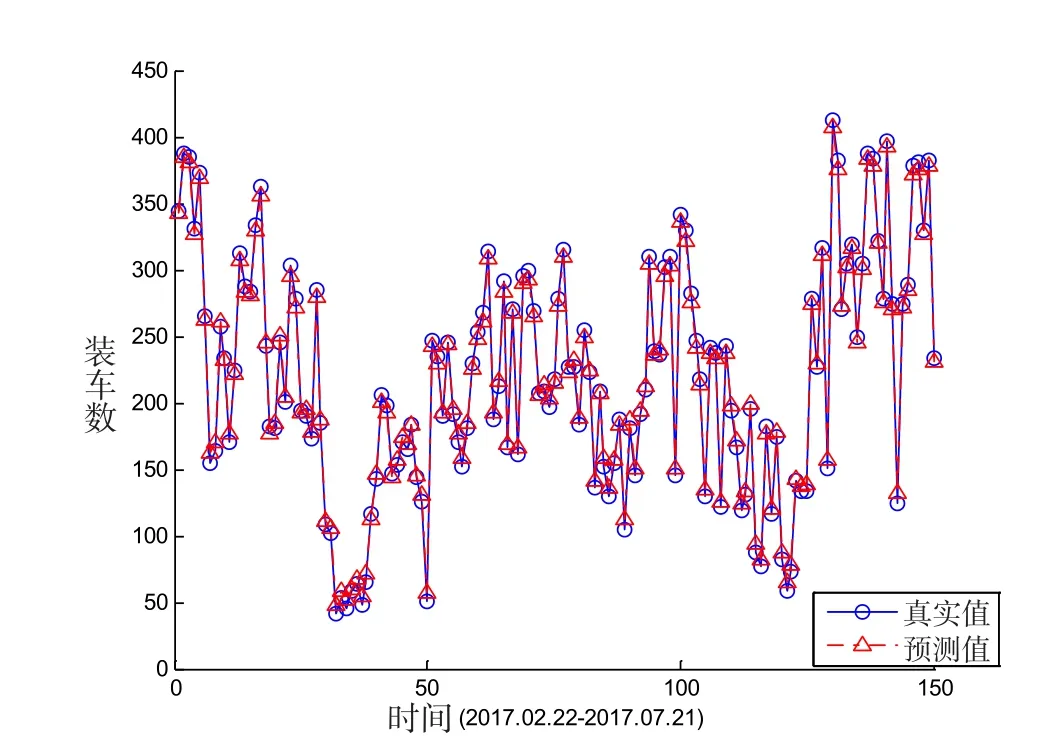
圖1 岳陽北裝車數真實值與預測值
從圖1和圖2可以明顯看出,岳陽北站裝車數擬合效果非常好,預測值和真實值基本重合,結合圖3和圖4可以看出,湘潭東車站的誤差明顯較大。采用本文SVM預測模型和灰色預測的預測性能具體見表1,選用平均誤差ME、平均絕對誤差MAE、平均絕對百分比誤差MAPE、均方誤差MSE和均方根誤差RMSE為評價指標。
從以上圖表可以看出,岳陽北的預測性能明顯比湘潭東好,岳陽北的擬合效果較好,而湘潭東的誤差相對較大。為了比較分析SVM模型的預測性能,另外采用灰色GM(1,1)預測方法對兩個車站進行預測,預測性能見表1,從中明顯可以看出,各項誤差指標SVM模型均比灰色GM(1,1)預測小的多。因此,采用支持向量機的預測效果整體上明顯比灰色預測好。
經分析可知,不同車站采用SVM模型的預測性能不同,主要是因為相空間重構采用C-C方法所確定的時間窗口和時間延遲不同,導致所重構的數據維數相差較大,從而導致了較大的預測誤差。

圖2 湘潭東裝車數真實值與預測值

圖3 岳陽北裝車數誤差量

圖4 湘潭東裝車數誤差量
4 結論
本文采用相空間重構將一維時間序列重構成多維用于SVM的輸入,并用PSO對SVM參數進行優化,建立模型對廣鐵(集團)公司的岳陽北和湘潭東兩個車站裝車數進行預測,有一定的參考價值,但由于不同數據進行相空間重構的嵌入維數和時間延遲不同,導致誤差變化較大,所以在后續研究中,將對此作進一步改進,以提高貨運站裝車數的預測精度。

表1 預測性能
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
能源工程(2022年1期)2022-03-29 01:06:28
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
今日農業(2020年16期)2020-12-14 15:04:59
消費導刊(2018年8期)2018-05-25 13:20:08
家庭影院技術(2018年4期)2018-05-09 07:07:41
電子制作(2017年20期)2017-04-26 06:57:45
