基于自模板重構與NSCT的汽車內飾件表面缺陷檢測方法研究
2019-04-01 09:10:00高興宇李志松潘少慧何卓昆趙凌波
計算機應用與軟件 2019年3期
高興宇 鐘 平,* 李志松 潘少慧 何卓昆 趙凌波
1(東華大學理學院 上海 201620)2(東華大學信息科學與技術學院 上海 201620)
0 引 言
現代汽車工業中,產品質量控制是生產線上最重要的過程之一。汽車內飾件表面缺陷檢測作為質量控制中一個重要的組成部分,其產品質量直接影響汽車最終的價格和分級。到目前為止,汽車內飾件的表面缺陷檢測仍然是通過質檢員的主觀評估來實現的。由于不同質檢員之間的評估標準存在差異、人工成本高、勞動強度大、效率低、無法運用大數據進行統計分析,汽車制造商仍在尋找最佳的解決方案。
將機器視覺技術應用于各種材料表面的缺陷檢測,具有人工檢測無法比擬的優勢。文獻[1]利用神經網絡算法實現了汽車車身表面缺陷的識別和分類,文獻[2]利用光譜殘差的視覺特性實現了鋼帶表面的缺陷檢測;文獻[3]設計的提取器算法實現了鋼軌的缺陷檢測;文獻[4]設計的無監督學習算法實現了混凝土的缺陷檢測。表面缺陷檢測方法大致可以分為特征提取和非特征提取兩類。特征提取在缺陷檢測中起著重要的作用,例如在空間域或頻域中提取缺陷的有效特征,該方法最大的難點就是尋找缺陷的一般特征[5-6]。在非特征提取方法中,Gabor濾波被認為是檢測各種紋理缺陷最成功的方法之一,因為它只需要一組經過優化的濾波器,就可以提取圖像在各個尺度和方向上的紋理信息,同時還可以在一定程度上降低光照和噪聲對圖像的影響。然而,濾波器參數的篩選是一項相當復雜的工作[7-8]。汽車內飾件表面缺陷檢測具有挑戰性的主要原因是缺陷類型的多樣性。在注塑過程中,大部分缺陷都是由于機械故障導致的,這些缺陷是隨機產生的,而且類型是不可預知的。所以很難將所有可能的缺陷類型作為負樣本收集起來進行算法優化,以獲得更好的檢測性能[9-11]。
本文提出了一種基于模板重構與NSCT的汽車內飾件表面缺陷檢測方法。考慮到缺陷的多樣性及其特征描述的困難,首先利用稀疏表示算法對試件圖像進行模板重構,然后利用差影法生成殘差圖像,最后利用NSCT對殘差圖像進行增強,從而實現缺陷的提取。
1 汽車內飾件表面檢測區自模板重構
圖像的稀疏表示是將目標圖像的特征用若干參數來表示,這些參數的組合稱為字典,然后再根據數學模型進行模板重構。利用稀疏表示算法對汽車內飾件表面檢測區進行自模板重構,以生成模板圖像,再與檢測區圖像進行差影,可突顯瑕疵。
用于自模板重構的字典為一系數矩陣,通過系數矩陣中元素的線性組合可以有效地表示檢測區圖像的每一列。由于檢測區圖像的缺陷相對較小,可以直接從檢測區圖像本身進行字典學習。因為自模板圖像來自于檢測區圖像,進行差影時不需要對檢測區圖像進行位置校準,可以靈活地適應各種測試圖像。圖1展示了汽車內飾件表面檢測區自模板重構的具體流程。
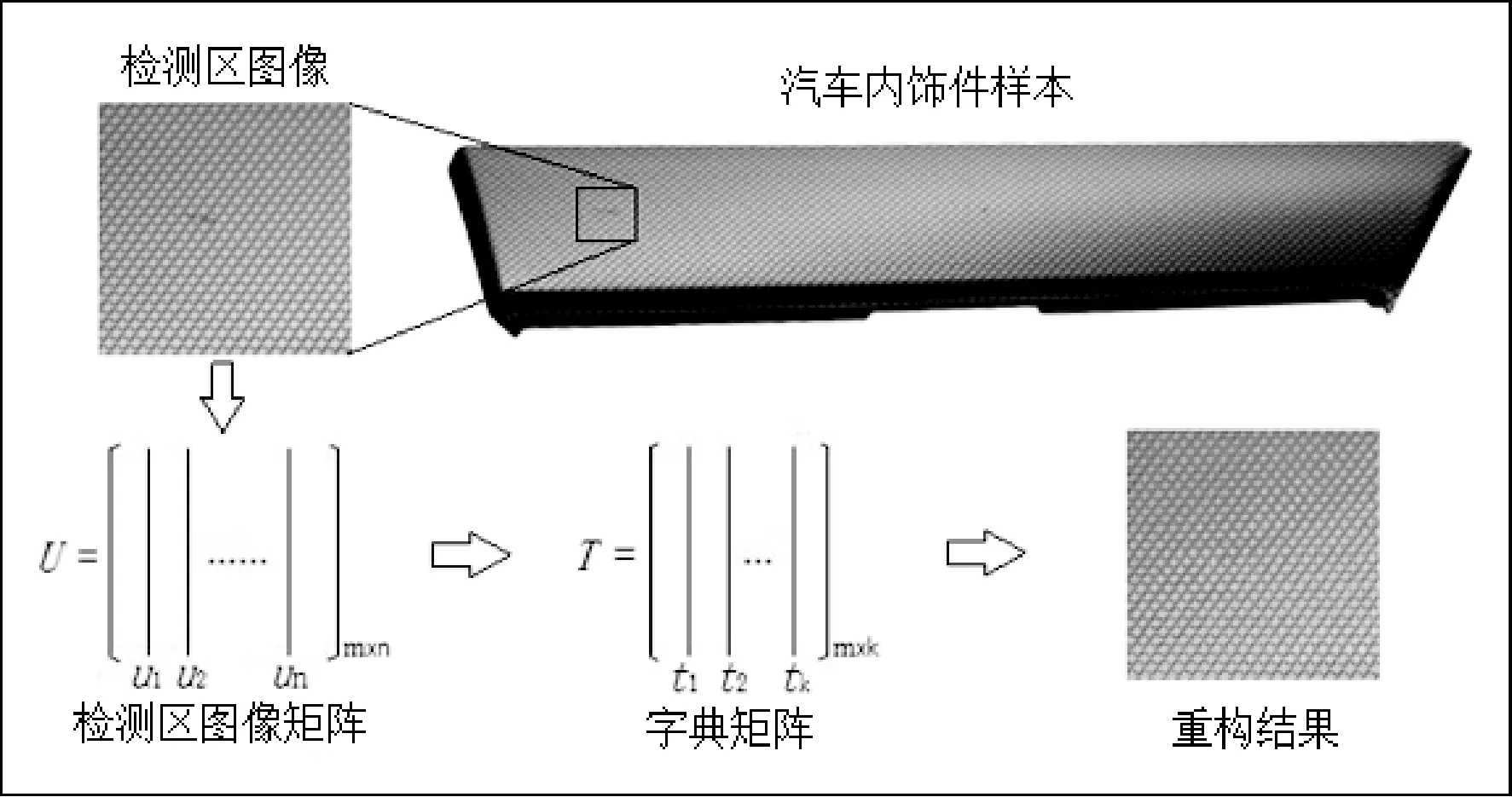
圖1 汽車內飾件表面檢測區自模板重構過程
1.1 字典學習模型
實際上,稀疏表示的目的就是找到一個具有少量基向量的線性組合來近似目標圖像,且滿足生成的字典平方誤差最小[12-14]。假設檢測區圖像矩陣為U=[u1,u2,…,un],ui∈Rm,其中m和n分別為該矩陣的行和列。定義字典D=[d1,d2,…,dk],dj∈Rm,矩陣U中的每一列ui都可以由D中的向量線性表示。該字典D的優化方法如下:
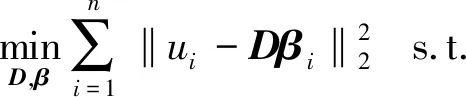
(1)
式中:βj∈Rk為矩陣U中ui的系數向量。由于D和β均未知,如何構造D被稱為字典學習。如果將式(1)中的D或β中的一個變量固定,求解另一個變量,那么式(1)就變成了凸化問題的求解[15],其本質上為最小二乘問題。采用文獻[16]的方法,通過交替最小化實現大型數據集的快速收斂。假設字典D已經確定,則相應的系數矩陣β*可以通過下式求得:
(2)
自模板圖像U′的近似結果為:
U′=Dβ*
(3)
由于自模板圖像U′來源于檢測圖像U, 所以重構誤差會大大減小,稀疏表示算法的詳細流程如下:
Step1生成一個隨機矩陣,記為β0。
Step2對于i=0,1,2,…,n求解Step3。
Step3利用l2范數求解字典D:
(4)
更新系數矩陣β:
(5)
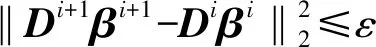
1.2 字典大小k的選取
自模板重構過程中一個關鍵步驟就是字典大小k的選取,k的大小將直接影響圖像的重構精度。本文利用文獻[17]的方法來選取k值,其評價函數G(k)的計算方法如下:
(6)
式中:σk和μk分別為殘差圖像的標準差和均值,殘差圖像由檢測區圖像與自模板圖像相減后獲得。圖2展示了不同k值下檢測區圖像的重構結果。圖3為字典大小k的評價函數曲線。通過式(6)可以計算出最優字典大小k為5。
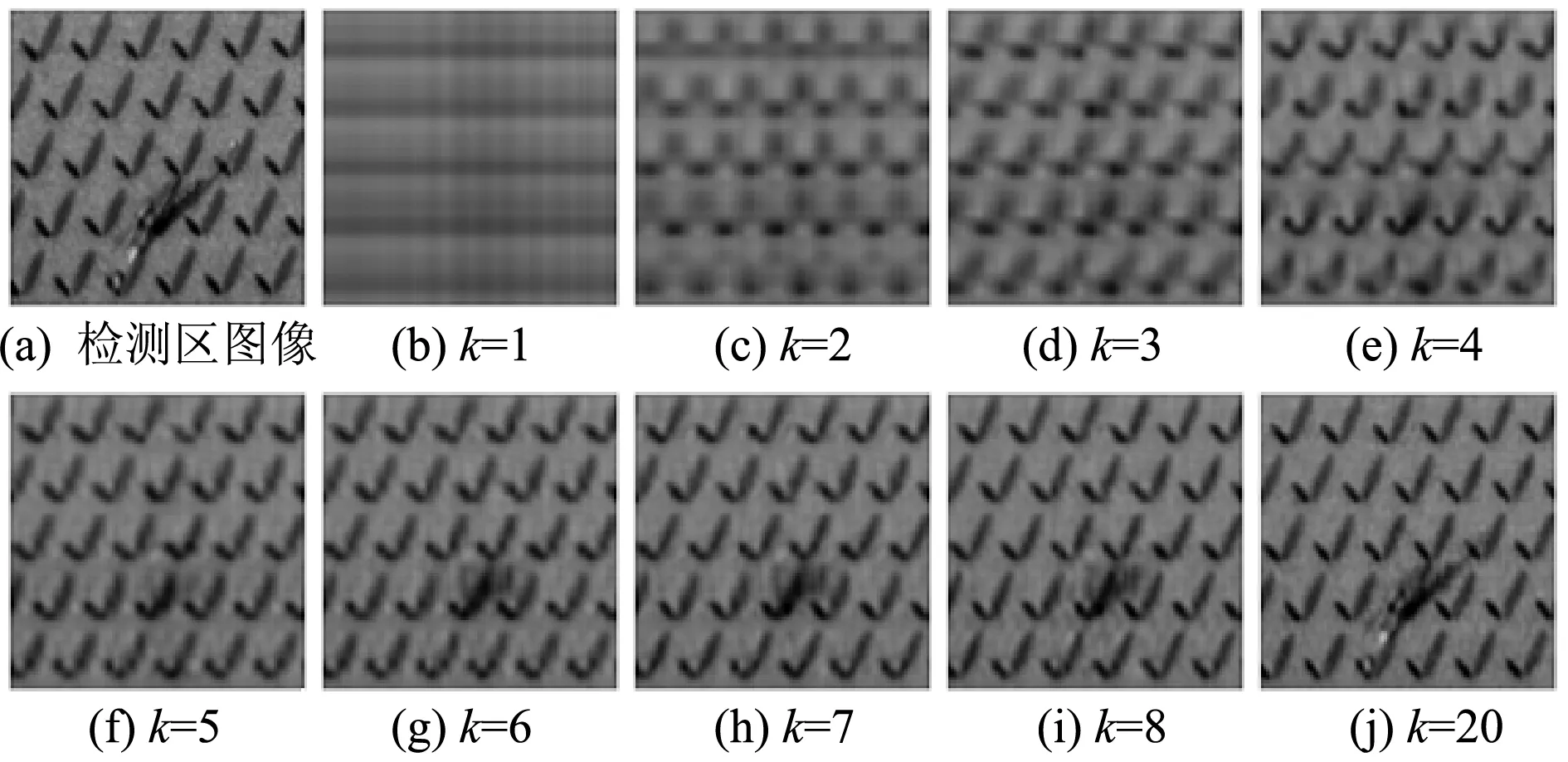
圖2 不同k值對應的重構結果
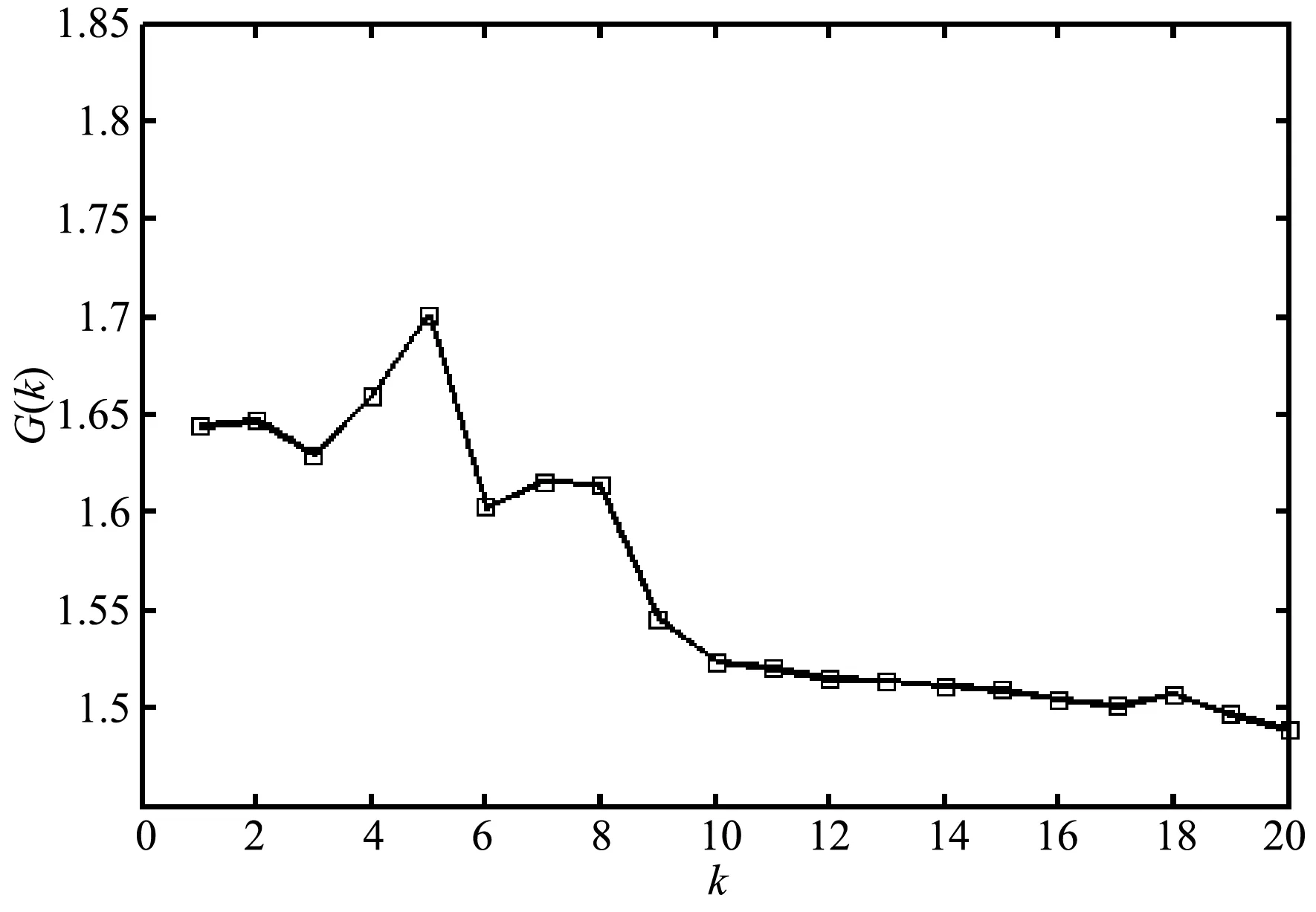
圖3 評價函數曲線G(k)
2 NSCT圖像增強及缺陷提取
針對殘差圖像,文獻[18]設計的自適應閾值方法實現了織物的缺陷檢測。對于高反射物體表面的缺陷檢測,由于檢測區光照不均勻,該方法并不適用,本文提出采用NSCT實現缺陷的增強。
非下采樣Contourlet變換(NSCT)最早由Cunha等提出,該方法繼承了Contourlet變換的各向異性、多方向性和多尺度性,同時還具備Contourlet變換所不具有的平移不變性,消除了子帶中頻譜混疊現象[19]。NSCT由非下采樣金字塔(NSP)進行子帶分解,每一層被分解為一個低通子帶和一個帶通子帶。低通子帶主要包含圖像的低頻信號,可以近似表示原圖像。帶通子帶主要包含圖像的高頻信號,具有豐富的邊緣信息。NSCT對圖像的多方向分解是由非下采樣方向濾波器(NSDFB)來實現的。假設圖像被分解為H層,第H層的帶通子帶包含2H個方向。圖4展示了NSCT的3層NSP分解及NSDFB頻帶劃分示意圖。
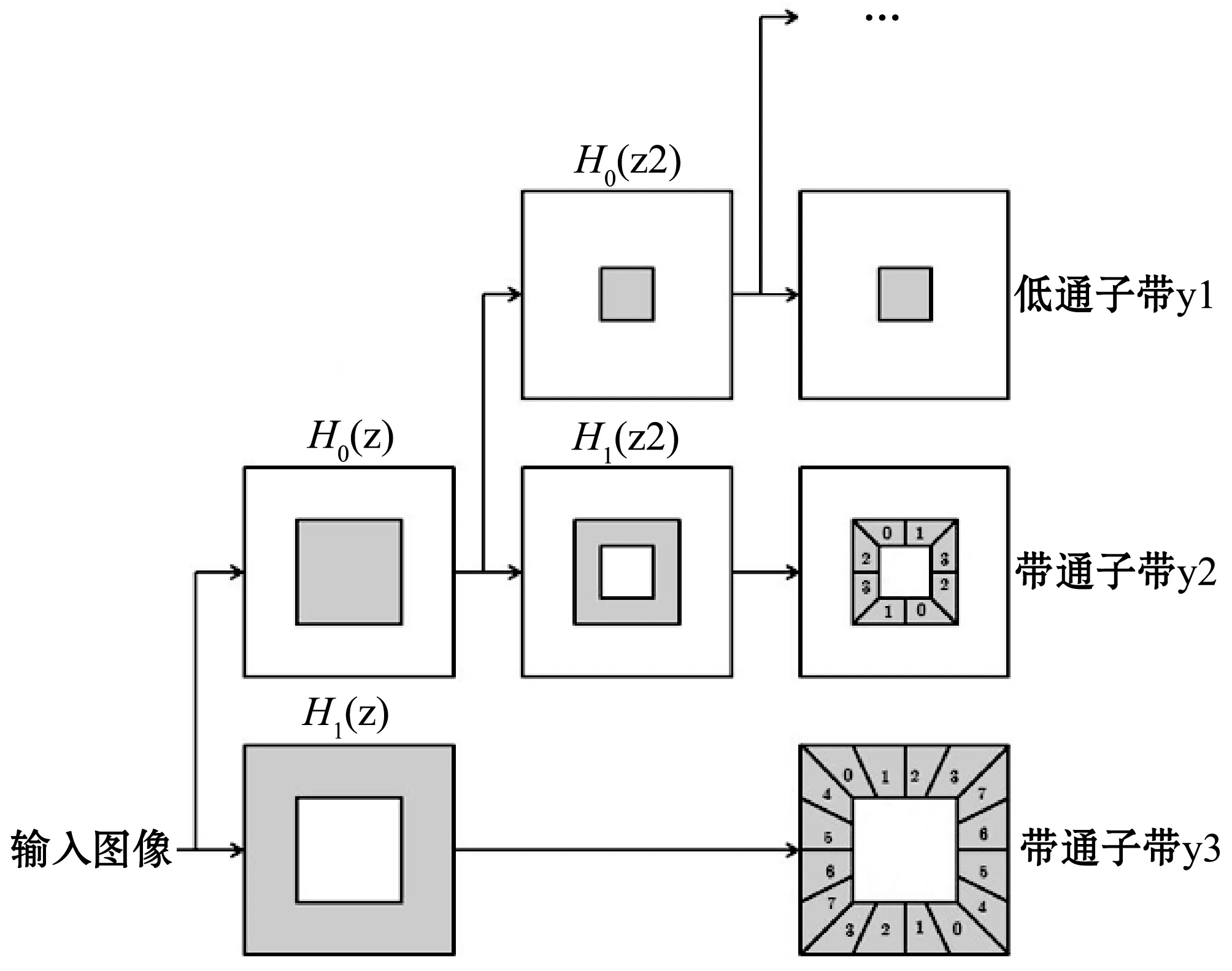
圖4 NSCT的NSP分解與NSDFB頻帶劃分
圖4中H0(z)為低通分解濾波器,H1(z)為高通分解濾波器,H1(z)=1-H0(z),G0(z)和G1(z)分別為對應的低通合成濾波器和高通合成濾波器,它們滿足 Bezout 恒等式:
H0(z)G0(z)+H1(z)G1(z)=1
(7)
考慮到自模板的重構精度與計算速度,本文中檢測區圖像的尺寸設置較小。由于檢測區圖像中缺陷數量有限,其缺陷會在某單一方向上有增強響應,因此無需將所有的子帶都用于瑕疵檢測。為了提高運算速度,本文只選擇第1層子帶和第3層子帶進行圖像融合。第3層子帶被分為8個楔形頻帶,每個楔形頻帶都可以對殘差圖像進行稀疏表示。另外,不同缺陷的響應方向不同,所以不能固定某個方向的頻帶用于缺陷檢測。
因此,需要采用一種算法,能自動地選取合適的頻帶,即選取最優頻帶構建圖像,實現缺陷的增強。本文提出了最優頻帶自適應選取與缺陷增強算法,具體步驟如下:
Step1假設頻帶圖像為ft(i,j),t為頻帶序數,根據評價函數F(t)選取最優頻帶:
(8)
式中:σt和μt分別為ft(i,j)的標準差和均值。σt的值越大說明圖像中缺陷越明顯;μt的值越小說明圖像被近似得越好。
Step2利用標準差法實現缺陷的增強[20]:
f′(i,j)=|f(i,j)-μ|-σ
(9)
Step3缺陷圖像二值化:
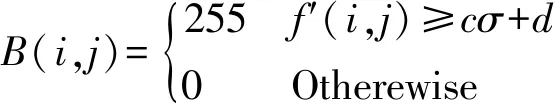
(10)
式中:c和d為閾值常數,不同類型的試件需要調整相應的數值。圖5(a)為劃痕缺陷樣本的殘差圖及對應的二值圖,(b)-(i)為劃痕缺陷樣本8個方向的融合結果及對應的二值圖,可以看出,(e)的檢測結果明顯優于(a)。

圖5 劃痕缺陷8個方向的融合結果及對應的二值圖
3 實驗結果與分析
為了驗證本文所提出方法的穩定性,實驗對大量樣本進行了分析。實驗樣本中缺陷的類別有劃痕、起泡、凹陷、跑料、脫膜和頂印。實驗樣本包含284幅缺陷圖像和147幅正常圖像,圖像大小為121×121,為單通道灰度圖像。檢測系統采用Teledyne DALSA V3-GM-04K018-00-R型單線掃攝像機,分辨率為2 048×1像素,最大幀速率為18 kHz,試件的傳動速度為22.8 mm/s,上位機以Windows XP為操作平臺,利用MATLAB 2013a軟件進行實驗。圖6顯示了幾種缺陷檢測效果。

圖6 幾種樣本的檢測效果
圖6(f)-(j)中第一行圖像為檢測區圖像,第二行圖像為Gabor算法檢測結果,第三行圖像為本文所提出方法的檢測結果,其中,圖6(e)為無缺陷樣本。從檢測結果可以看出,對于(b)、(h)、(j)中的缺陷,Gabor算法具有很好的檢測效果,且具有良好的邊緣信息;對于(a)、(c)、(g)中的缺陷,Gabor算法則不能將缺陷從背景中分離出來。由于(f)、(i)光照不均勻,導致Gabor算法不能實現有效檢測,然而,本文所提出的方法對光照不敏感,具有更好的檢測效果。(d)、(f)為劃痕缺陷樣本圖像,由于其缺陷具有較強的方向性,經非下采樣Contourlet變換后,其缺陷具有良好的邊緣信息。(b)、(i)的缺陷類型分別為跑料和凹痕,其缺陷在多個方向都具有較強的方向性,但是并不影響檢測效果。通過對比,可以看出本文方法具有更好的魯棒性。通過大量實驗數據驗證,本文方法可以實現0.1 mm級精度檢測。
4 結 語
本文通過稀疏表示算法對汽車內飾件表面圖像進行自模板重構,然后利用差影法生成殘差圖像,最后利用非下采樣Contourlet變換實現了缺陷的提取。本文方法作為一種無監督缺陷檢測算法,不需要對待測圖像進行位置校準,也不需要任何先驗信息,對光照不敏感,且魯棒性好。實驗結果表明,本文方法可以有效地檢測因機械故障引起的注塑過程中出現的各種缺陷,其檢測精度可達0.1 mm。下一步的工作將專注于非規則紋理汽車內飾件的缺陷檢測,進一步提高算法的魯棒性與可推廣性。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
兒童故事畫報(2019年5期)2019-05-26 14:26:14
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
