基于注意力機制的循環神經網絡評價對象抽取模型
2019-04-01 09:28:14楊善良
計算機應用與軟件 2019年3期
楊善良 孫 啟
1(山東理工大學計算機科學與技術學院 山東 淄博 255049)2(中國傳媒大學傳媒科學研究所 北京 100024)
0 引 言
評價對象是評論文本中的評價主體,評論文本內容集中反映了對該主體的情感態度。評價對象抽取任務就是從評論文本中抽取出評價對象,但是評價對象在評論文本中的表現形式多樣,抽取過程面臨諸多挑戰。首先,評論文本中通常包含顯式和隱式評價對象,對于顯式評價對象容易從文本中直接抽取,然而隱式評價對象往往不出現在評論文本中,需要通過上下文進行推理,完成抽取任務相對困難。其次,顯式評價對象通常是一個短語,由一個或多個詞語組成,確定評價對象的邊界非常困難。下面以“中美貿易戰”話題的相關評論為例進行說明,評論示例如表1所示。評論1中并沒有評價對象出現,但是在該話題語境下其評價對象是“美國發動貿易戰”這件事;評論2的第二句中有顯式評價對象“美國”,是一個名詞,抽取該評價對象較為容易;評論3中的評價對象是“中美和平發展”,該評價對象是一個名詞短語,可以看作由“中美”、“和平”和“發展”等三個詞語組成。

表1 評論示例表
本文重點研究顯式評價對象抽取任務,解決評價對象由多個詞語組成時所面臨的困難。提出一種端到端的神經網絡模型,減少手動設計特征模板的工作,同時提高網絡評價文本中評價對象抽取準確率。本文把顯式評價對象抽取任務看做序列標注問題,將文本序列映射到評價對象序列,標注的標簽為該字符是否屬于評價對象。采用IOB序列標注模式,B-term代表當前字符是評價對象的開始,I-term代表當前字符包含在評價對象字符串序列中,O-term代表當前字符不屬于評價對象。IOB標注模式在標注出目標字符串的同時也給出了評價對象的邊界,B-Term為起始邊界,最后一個I-term為終止邊界。顯示評價對象的標注示例如下:
評論數據:“中美和平發展才是兩國人民的殷切期望。”
標注數據:“B I I I I I O O O O O O O O O O O O”
隨著網絡評論數據的增多,以及評論數據的可獲取性增強,評價對象抽取任務已經成為情感分析中的研究熱點之一。Liu等[1]將評價詞語和評價對象之間的對應關系作為詞語對齊的依據,使用詞對齊算法從網絡評論中抽取評價對象和評價詞語。Zhou等[2]使用集成算法抽取中文微博評論中的評價對象。首先使用對稱條件概率SCP指標切分微博話題標簽字符串,提取粘性值最高的字符作為候選評價對象;然后根據規則條件和詞語長度限制提取語句中的候選評價對象;最后使用基于圖的標簽傳播算法對候選評價對象排序,選擇排名最高的候選評價對象作為最終抽取結果。Min等[3]首先根據句法和語義特征抽取候選評價對象,然后基于語句間的相似度計算設計出迭代程序對候選評價對象排序并確定抽取結果。Qiu等[4]利用評價對象和情感詞語之間的關聯關系,使用雙向傳播算法抽取評價對象并擴展情感詞語。
隱馬爾科夫模型和條件隨機場模型是解決序列標注問題的常用方法。條件隨機場模型在評價對象抽取任務上已經取得了許多成果。例如,文獻[5]使用條件隨機場CRF抽取評價對象,然后使用線性分類器對評價對象的情感傾向性進行分類。蔣潤等[6]提出一種基于協同訓練機制的評價對象抽取算法,使用支持向量機、最大熵、條件隨機場三種模型組成評價對象候選集分類器。鄭敏潔等[7]提出層疊條件隨機場算法抽取句子中的評價對象,解決復合評價對象和未登錄評價對象的問題。層疊條件隨機場模型首先在底層條件隨機場提取候選評價對象,然后對噪聲進行過濾,補充未登錄評價對象,合并復合評價對象,在高層條件隨機場輸出最終評價對象。Zhou等[8]為解決不同語言之間標注數據不平衡問題,提出跨語言評價對象抽取模型。首先根據英文標注數據集生成漢語訓練數據,然后使用條件隨機場模型抽取評價對象,并通過使用大量未標注漢語評論數據聯合訓練,以提升條件隨機場模型的抽取效果。雖然條件隨機場模型在評價對象抽取上取得了不錯的效果,但是需要手工設計特征模板,抽取結果受特征模板的影響。
深度學習技術已經在圖像處理、語音識別、人臉識別、自然語言處理等多個領域取得了顯著成果。神經網絡模型的特征表示能力和非線性擬合能力在評價對象抽取任務中同樣能夠發揮作用。在這方面已經取得了一些研究成果,例如,文獻[9]使用卷積神經網絡完成評價對象抽取任務。文獻[10]使用循環神經網絡設計評價對象抽取模型。Ding等[11]針對跨領域評價對象抽取問題,使用基于規則的非監督方法生成輔助標簽,然后使用循環神經網絡模型學習隱藏表達形式,以提高跨領域評價對象抽取效果。還有研究者把循環神經網絡和條件隨機場結合在一起,利用神經網絡的特征自動抽取能力和條件隨機場的序列預測能力提高序列標注任務的準確率。目前LSTM、CNN等神經網絡和CRF結合的模型多應用在序列標注、命名實體識別等任務上。例如,文獻[12]結合使用雙向LSTM、CNN和CRF提出新的模型框架,解決序列標注問題。首先使用CNN對單詞字符編碼,形成單詞向量,然后經過雙向LSTM網絡層處理后得到詞語編碼,最后應用CRF標注詞語標簽。本文將評價對象抽取任務作為序列標注問題解決,所以可以結合神經網絡模型和條件概率模型來解決評價對象抽取問題,同時提高評價對象抽取效果。本文提出一種端到端的神經網絡模型LSTM-Attention-CRF,在模型訓練過程中不需要專門設計特征模板,序列預測過程中能夠利用條件隨機場的序列標注能力。
1 序列標注模型框架
評價對象抽取任務的目標是提取評論文本中的評價詞語或短語,可以把評價對象抽取任務轉化為序列標注問題,根據評論文本序列數據標注每個字符對應的IOB標簽。序列標注系統的框架結構如圖1所示,包含模型訓練、模型評估和模型應用三個部分。第一部分是模型訓練階段,在這個階段需要標注訓練數據集,并設計序列標注模型,對模型進行訓練使目標函數最小化;第二部分是模型測試評估階段,把訓練好的模型在測試數據上進行驗證,評價模型效果;第三部分是模型的實際應用階段,將評估結果最優的模型放在實際應用數據集上使用。
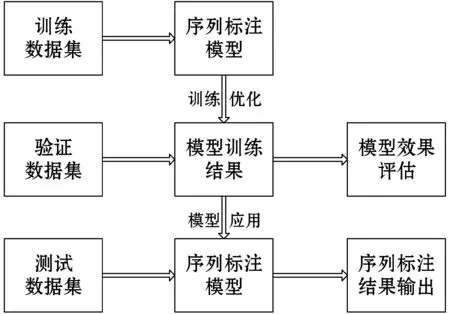
圖1 序列標注系統框架圖
序列標注模型主要包括隱馬爾科夫模型HMM、最大熵馬爾科夫模型MEMM、條件隨機場模型CRF(Conditional Random Field)等。本文主要對序列標注模型進行研究,結合條件隨機場模型和神經網絡模型的優勢,在減少特征模板設計工作的同時提高評價對象抽取的準確率。
2 CRF評價對象抽取模型
2.1 CRF模型
CRF模型是由John D. Lafferty等提出的一種無向圖模型[13],在隱馬爾科夫模型的基礎上發展而來,避免了嚴格的獨立性假設問題。CRF模型經常用于序列數據標注問題,在給定輸入隨機變量序列的情況下計算輸出隨機變量序列的概率分布,在中文命名實體識別、詞性標注等任務上取得了非常好的效果。
條件隨機場的參數化表達形式中定義了狀態特征函數、狀態轉移特征函數和預測序列的條件概率公式。假設輸入觀測序列x,標注序列y的條件概率計算式表示為:
(1)
(2)
式中:Z(x)是歸一化因子;tk為狀態轉移特征函數,計算當前位置和前一個位置的特征;sl是狀態特征函數,計算當前位置特征,特征函數的取值為1或者0,當滿足特征條件時取值為1,當不滿足特征條件時取值為0;λk和ul是對應的特征函數權重。
2.2 特征選擇
特征選擇是使用條件隨機場進行評價對象抽取的第一步,選擇與評價對象相關的特征對CRF模型準確率起到關鍵作用。這里選擇詞語、詞性、依存句法關系等作為模型特征。將這些特征組合起來作為條件隨機場模型的輸入信息。
詞語本身是評論文本的組成部分,能夠直接反映評價對象信息。詞性作為詞語在句子中表達的重要語法信息,對評價對象抽取有重要影響。評價對象多為名詞、名詞短語、動詞等,評價詞語多為形容詞,所以詞性為名詞、動詞、形容詞的詞語對抽取評價對象有參考價值。依存句法分析是分析語句的語法成分以及詞語之間的依存關系,可以用樹形結構進行表示。依存關系包括“主謂關系”、“動賓關系”、“定中關系”等。這里將當前節點與父節點之間的依存關系作為條件隨機場模型的特征。
使用本文引言中的示例:“中美和平發展才是兩國人民的殷切期望。”給出其特征表示,具體信息如表2所示。其中評價對象為“中美和平發展”,是一個名詞短語,包含兩個名詞和一個動詞。

表2 特征表示示例
2.3 模板定義
模板是對特征函數的定義,反映了上下文依賴關系和特征組合形式。模板通過設置窗口大小反映上下文依賴距離,通過定義當前位置特征反映當前位置與前后位置之間的關系。這里使用的特征模板定義如表3所示。
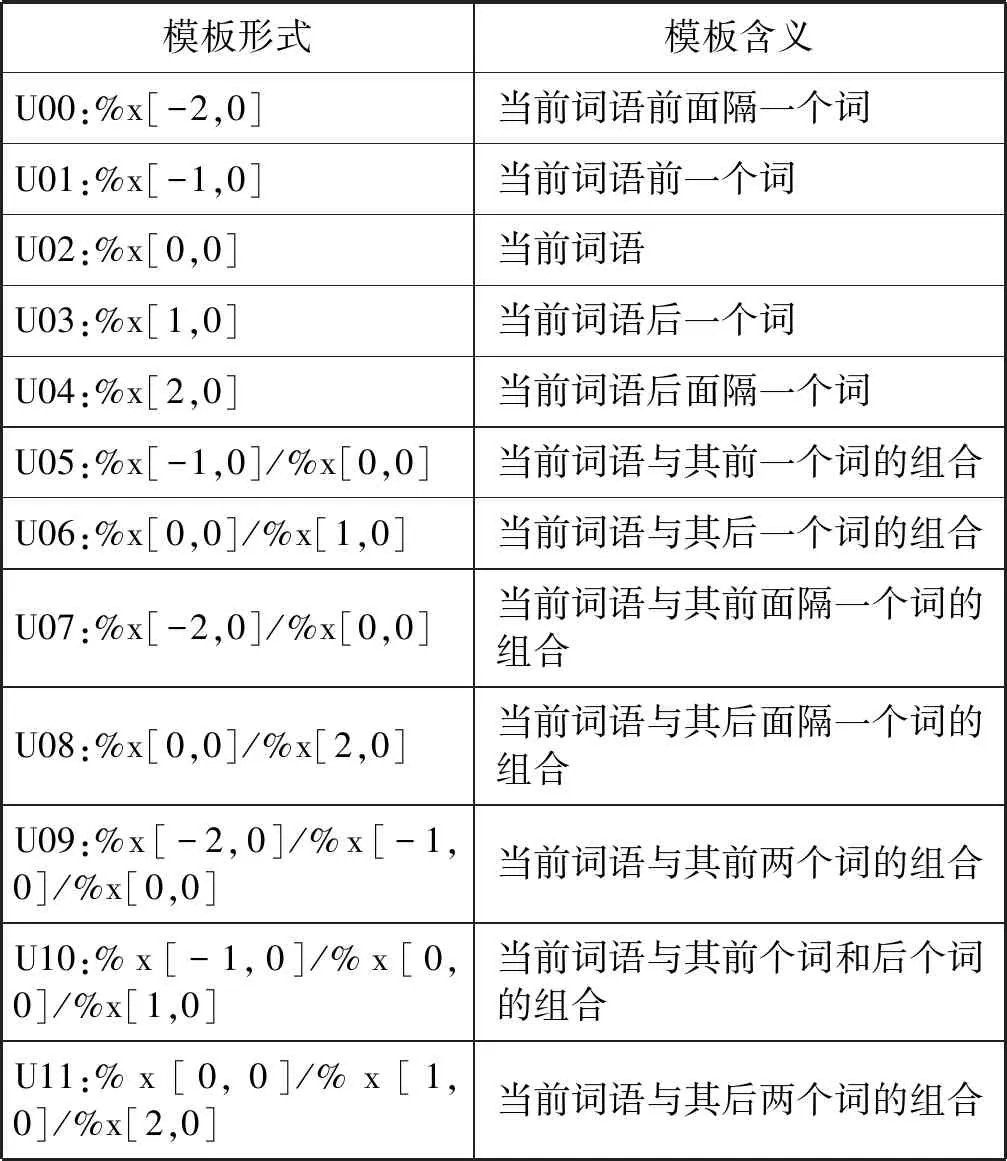
表3 模板形式示例
3 模型設計
3.1 詞向量訓練
CBOW和Skip-gram是最為經典的詞嵌入模型。CBOW通過當前詞語的上下文預測當前詞語,Skip-gram則通過當前詞語預測其上下文詞語。兩者都屬于神經網絡語言模型,通過訓練模型參數得到最優的詞語向量。經過詞嵌入模型得到詞語在語義空間上的表達。
CBOW模型根據詞語的上下文來預測當前詞語,模型結構包括輸入層、投影層和輸出層。
輸入層是詞語wi的上下文,取窗口寬度為c,上下文詞語序列表示為context(wi)=[wi-c,wi-c+1, …,wi+c-1,wi+c],序列長度為2c。這里wi∈Rm,m代表詞向量的維度。
投影層將上下文詞向量累加求和,求和計算如下所示:
(3)
輸出層為一顆二叉樹,根據訓練語料中詞語構建出來的Huffman樹,使用Hierarchical softmax計算最后的概率p(wi|context(wi))。
將對數似然函數作為CBOW模型的目標函數,公式如下所示:
(4)
式中:C為訓練樣本中包含的詞語,在模型訓練中利用Huffman樹結構把最終目標預測轉化成多個二分類概率相乘的形式。
Skip-gram模型根據當前詞語預測其上下文詞語,網絡結構同樣包括輸入層、投影層和輸出層。輸入層為當前詞語的詞向量wi,投影層對wi未作任何改變,輸出層與CBOW模型中相同,同樣是一顆Huffman樹。輸出層計算上下文詞語條件概率值p(context(wi)|wi),該概率值計算式表示為:
(5)
將對數似然函數作為Skip-gram模型的目標函數:
(6)
式中:C為訓練樣本中包含的詞語。模型訓練同樣使用到Huffman樹結構,只是對每個上下文詞語進行層次二分類預測,最后將多個上下文詞語的預測概率相乘。
3.2 注意力機制
神經網絡中的注意力機制是受到人類視覺選擇性注意力機制的啟發而產生的。人類視覺在處理圖像數據時根據需要將注意力集中在圖像的某一部分,篩選出最有價值的信息。同樣在神經網絡模型中,輸入數據的各個部分對模型計算結果的重要程度不同,所以采用注意力機制增加重要數據的權重,同時降低噪聲數據的權重。
注意力機制最早被應用在圖像處理領域,2014年Mnih等[14]基于注意力機制設計了新的循環神經網絡模型結構,能夠自適應地從圖像中選擇區域序列,只處理選中的圖像區域。神經網絡注意力機制在情感分析領域也得到了應用。例如Ma等[15]提出使用外部知識解決評價對象情感傾向判斷問題,首先使用LSTM對輸入語句進行編碼,然后對評價對象使用自注意力機制,最后使用多分類器進行情感傾向性分類。
在神經網絡模型中加入注意力機制的關鍵步驟就是設計合理的權重計算公式。注意力機制的原理可以解釋為計算源數據與目標數據之間的關聯程度,關聯程度越強的源數據權重值越大,反之源數據的權重值越小。這里將源數據記作ms,將目標數據記作mt,權重計算式表示為:
(7)
式中:分母是歸一化因子,所有源數據與目標數據函數值的總和。將式(7)以softmax函數對源數據和目標數據之間的關聯函數值歸一化,求得源數據在對應目標數據上的概率分布。函數f(mt,ms)的計算方法有多種,包括點乘、矩陣相乘、連接和感知器等。以下為源數據和目標數據之間關聯函數的幾個示例:
(8)
自注意力機制(Self Attention Mechanism)是注意力機制的一種特殊情況,其源數據和目標數據相同,計算同一個樣本數據中每個元素的重要程度。在評價對象抽取任務中,則是計算語句中每個詞語與其他所有詞語之間的依賴關系。假設有序列數據mt(mt1,mt2,…,mtn),那么自注意力機制計算式表示為:
(9)
通過softmax公式得到權重值,該權重值反映了數據元素的重要程度,把序列數據mt與對應的權重相乘得到自注意力機制處理結果。
3.3 LSTM-CRF-Attention模型
LSTM循環神經網絡適用于處理序列數據,把對序列標注重要的信息存儲在記憶單元中,但是在標注過程中無法使用上下文依賴信息,會出現大量非法標注問題。例如正確標簽是“OBIIO”的情況下,會給出“OIIIO”的非法標注結果,三個元素都是中間元素,明顯不符合標注規則。條件隨機場模型計算概率最大的標注序列,能夠根據特征函數給出合理的標注結果,包含非法標注的標注序列的特征轉移函數tk(yi-1,yi,x,i)的函數值為0,從而降低了標注序列的條件概率p(y|x),能夠在標注結果中盡可能避免非法標注的出現。但是條件隨機場需要大量特征,以及手動設置特征模板,特征和特征模板對標注結果有較大影響。為了避免非法標注問題和減少手動設置特征模板的工作,將循環神經網絡和條件隨機場模型進行融合,提出LSTM-CRF-Attention評價對象抽取模型,利用循環神經網絡的特征表示能力和條件隨機場的序列標注能力,有效提高模型效果。
LSTM-CRF-Attention的模型結構如圖2所示。模型包括輸入層、循環網絡層、隱藏層、注意力層和標注層。輸入層是詞向量,每個詞語映射到一個詞向量,詞向量初始化方法可以采用隨機方式或者詞嵌入訓練方式;循環網絡層為LSTM循環神經網絡;隱藏層是LSTM網絡中每個處理單元的輸出結果;注意力層采用自注意力機制,自動學習序列元素在評價對象抽取中的權重;標注層采用條件隨機場序列標注模型,輸出每個詞語位置對應的標簽。
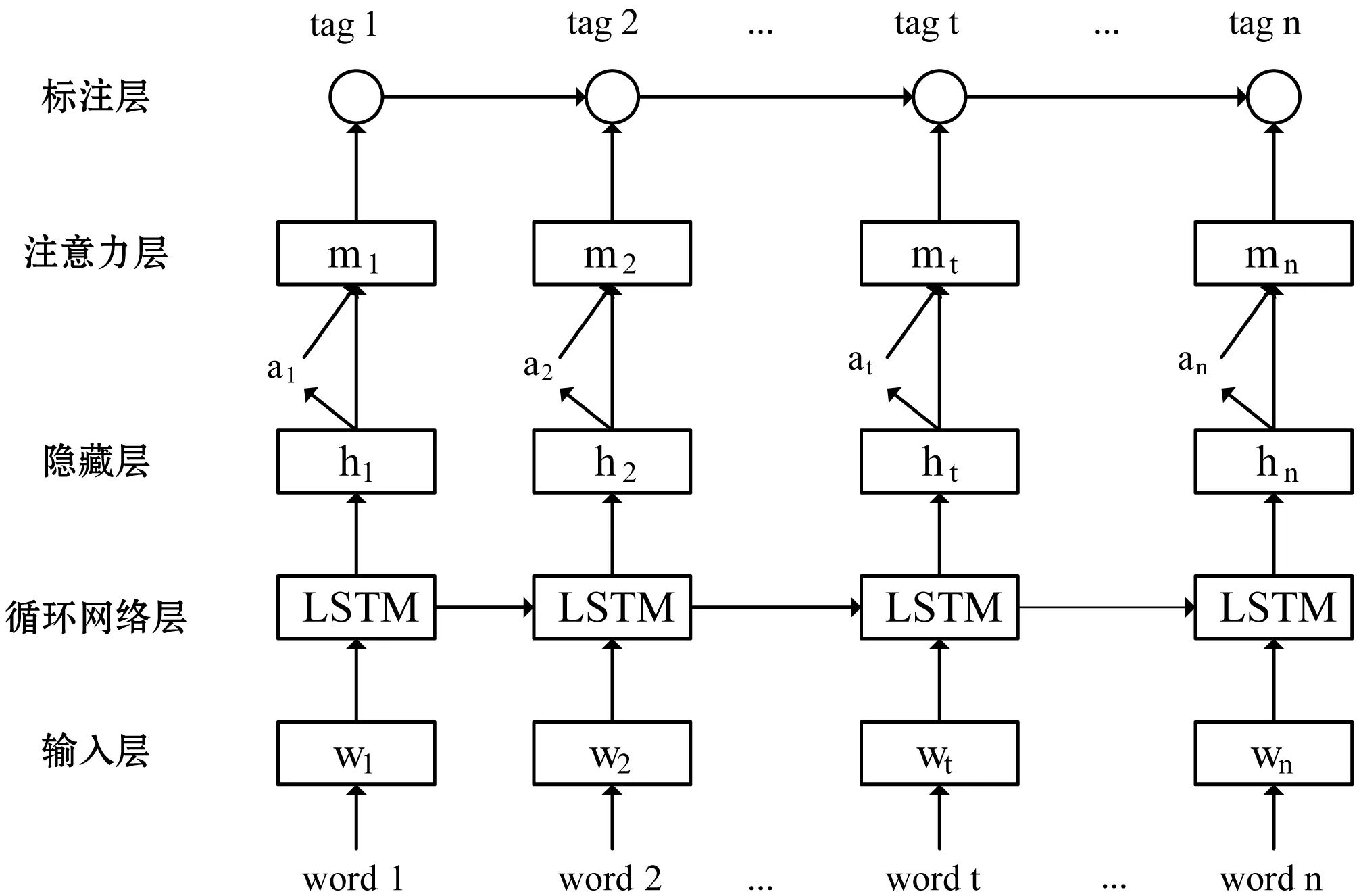
圖2 LSTM-CRF-Attention模型結構圖
循環神經網絡的計算方法如下:
ht=ot·tanh(ct)
(10)
ot=σ(Wo·[ht-1;wt]+bo)
(11)
ct=it·gt+ft·ct-1
(12)
it=σ(Wi·[ht-1;wt]+bi)
(13)
ft=σ(Wf·[ht-1;wt]+bf)
(14)
gt=tanh(Wg·[ht-1;wt]+bg)
(15)
式中:it、ot、ft、ct分別是LSTM網絡的輸入門、輸出門、遺忘門和記憶存儲單元;ht是LSTM神經網絡單元的輸出向量。
注意力層計算評論文本中每個元素的權值,通過增加重要元素的權重來提高評價對象信息的表示能力。這里使用自注意力機制計算注意力層,由隱藏層h計算權重a,然后得到注意力層輸出值m,計算方法如下:
(16)
mi=aihi
(17)
標注層根據注意力層輸出的特征向量進行序列標注。首先根據注意力層計算標簽分值矩陣P(pij),pij表示第i個詞語標記為第j個標簽的分值,分值矩陣計算公式如下:
pij=softmax(mi·wj+bj)
(18)
式中:mi為注意力層輸出向量;wj為權重值;bj為偏置向量。
然后計算標注序列的分值,輸出分值最大的標注序列。假設標注序列為y(y1,y2, …,yn),那么該標注序列的分值為score(y),計算方法如下:
(19)
式中:A為狀態轉移矩陣,其元素值Aij表示從第i個標簽轉移到第j個標簽的概率;pi,yi是第i個詞語標記為標簽yi的分值。此處的狀態轉移矩陣由訓練數據學習得到,由狀態O轉移到狀態I的概率越小越能夠避免出現非法標注序列“OI”,所以可以手動設置AO,I的值為0。
計算每個可能標注序列的概率值p(y),計算方法如下:
(20)
式中:Y表示所有可能標注序列的集合。
訓練LSTM-Attention-CRF模型時使用最大化對數似然函數,即模型的目標函數為:
(21)
使用所提出模型預測標注序列時,選擇概率最大的標注序列為:
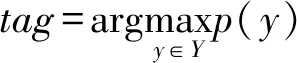
(22)
4 實驗和結果分析
4.1 實驗數據集
本文中使用NLPCC2012和NLPCC2013兩個數據集。NLPCC2012數據集是計算機學會舉辦的第一屆自然語言處理和中文計算會議中的技術評測數據集,數據來自于騰訊微博,包含20個話題,共有2 023條微博數據,使用XML格式文件存儲。NLPCC2013數據集是第二屆自然語言處理和中文計算會議評測數據集,同樣是騰訊微博數據,存儲格式相同,只是數據內容不同,包含10個話題,共有899條微博。
數據集的統計分析結果如表4所示。NLPCC2012數據集中包含3 416個句子,2 353個評價對象,句子平均字數為24.39;NLPCC2013數據集中包含1 873個句子,1 677個評價對象,句子平均字數為32.24。

表4 實驗數據統計表
4.2 評價方法
在評價對象抽取實驗中使用準確率(precision)、召回率(recall)、F值(F-measure)等作為評價指標。準確率反映了抽取信息的準確性,召回率反映了抽取信息的完整性,F值是衡量信息抽取模型的綜合性指標。由于信息抽取任務是對字符串的處理,抽取信息結果在不完全覆蓋正確結果的情況下也具有一定價值。所以這里引用NLPCC評測大綱中的評價方法,將評價指標計算方法分為嚴格評價和寬松評價兩種。
4.2.1 嚴格評價
嚴格評價方法是當抽取出的字符串與正確的字符串完全相同時,信息抽取結果才算正確。在嚴格評價方法下,各指標的計算公式表示為:
(23)
(24)
(25)
式中:system_correct是系統抽取結果中正確的數量;system_proposed是系統抽取結果的總數量;gold_tabel是測試數據中標注出的信息數量。
4.2.2 寬松評價
寬松評價按照抽取信息的覆蓋率計算各項指標。抽取信息結果覆蓋率是指系統給出的結果與測試數據中的字符串重合程度,使用如下公式計算:
(26)
式中:s是標準數據中的信息字符串,s′是系統抽取結果中對應的字符串。計算操作符|*|表示字符串長度,交集運算表示兩個字符串重合的部分。
設定標準數據集合為R,系統輸出結果集合為R′,則測試覆蓋率可以定義為:
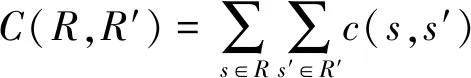
(27)
在寬松評價方法下,各項評價指標的計算式表示為:
(28)
(29)
(30)
式中:|R|和|R′|分別表示標準數據和系統輸出結果集合中的評價對象數量。
4.3 實驗結果
4.3.1 詞向量訓練對實驗結果的影響
經過預訓練得到的詞向量,不僅能夠加快神經網絡模型的收斂速度,而且能夠提高模型預測性能。這里使用CBOW、Skip-gram等詞向量訓練模型,得到語義空間詞向量。然后在NLPCC2012和NLPCC2013數據集上進行實驗,以分析詞向量對神經網絡模型訓練結果的影響,以及不同詞向量預訓練模型的作用。實驗中均使用詞語特征作為模型輸入數據,首先對語料進行分詞,然后根據分詞結果預訓練詞向量,最后使用訓練好的詞向量訓練模型參數并進行模型測試。
LSTM-CRF-Attention模型的詞向量預訓練實驗結果如表5所示。在NLPCC2012數據集的實驗結果中,Skip-gram詞向量嚴格評價F值為55.05%,比隨機詞向量測試結果提高3.72%;CBOW詞向量嚴格評價F值為53.59%,比隨機詞向量測試結果提高2.26%,但是低于Skip-gram詞向量測試結果。在NLPCC2013數據的實驗結果中,Skip-gram詞向量嚴格評價F值為57.05%,比隨機詞向量測試結果提高4.22%;CBOW詞向量嚴格評價F值為54.26%,比隨機詞向量測試結果提高1.24%,但是低于Skip-gram詞向量測試結果。從上述分析可以看出,對于LSTM-CRF-Attention模型,在兩個數據集上,Skip-gram和CBOW詞向量都能提高評價對象抽取效果,但是Skip-gram詞向量訓練模型起到更大的作用,優于CBOW詞向量模型。
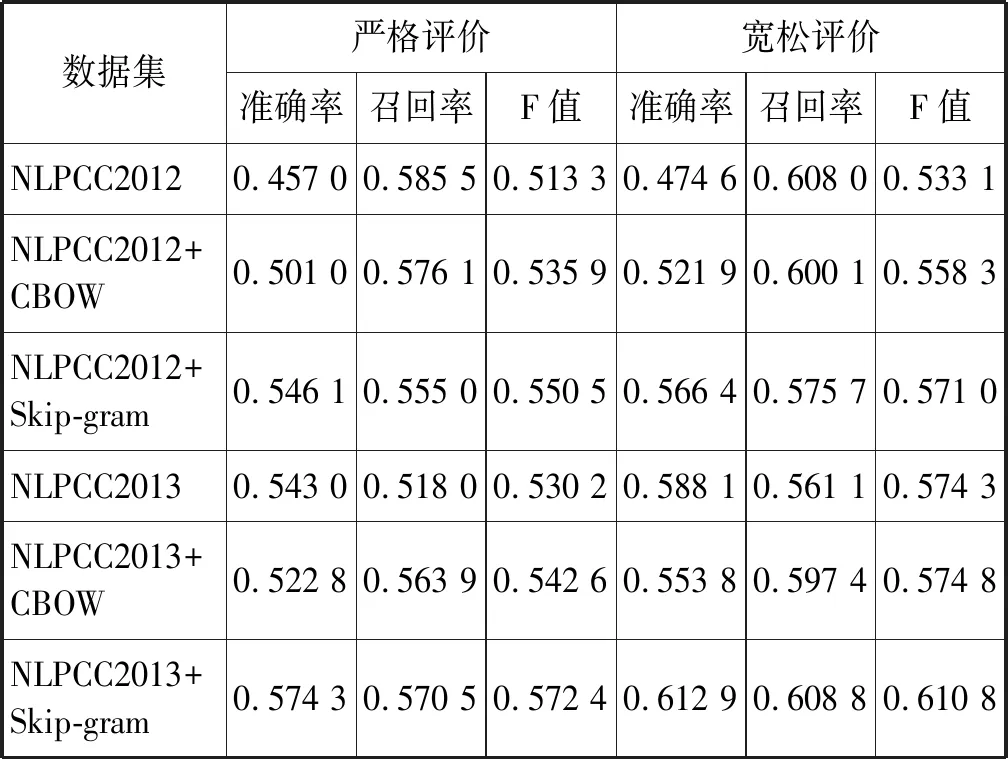
表5 LSTM-CRF-Attention預訓練詞向量實驗結果表
4.3.2 模型對比實驗
使用CRF模型為基準模型,對比分析LSTM-CRF模型、LSTM-CRF-Attention模型的效果,LSTM-CRF模型是去掉注意力機制部分的神經網絡標注模型。LSTM-CRF和LSTM-CRF-Attention模型的結果是采用詞向量預訓練后的實驗結果。CRF實驗結果為“詞語+詞性+依存關系”特征組合的實驗結果。實驗結果評價指標如表6和表7所示。
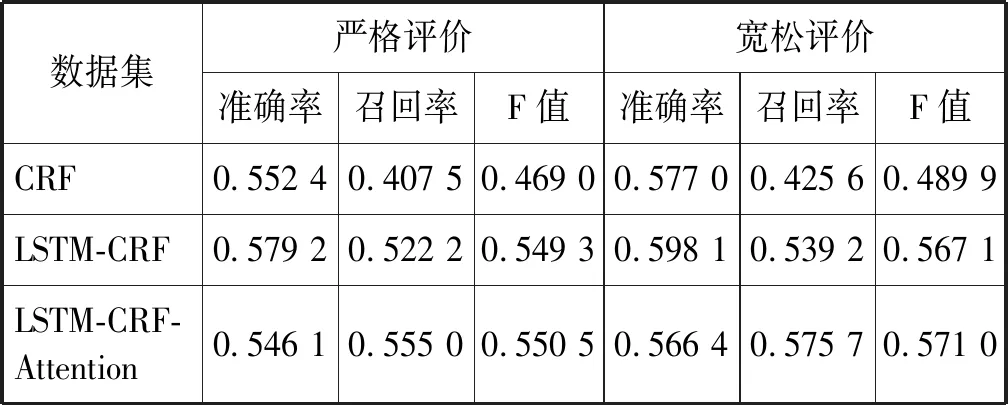
表6 評價對象抽取NLPCC2012數據集對比實驗結果表
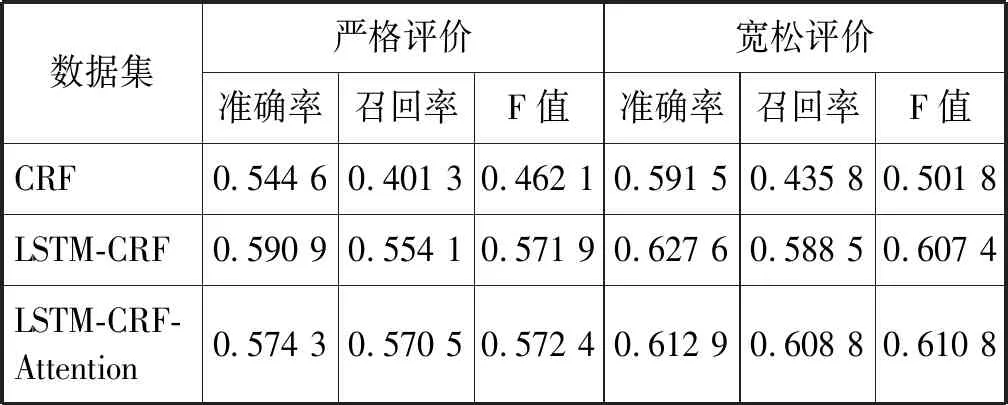
表7 評價對象抽取NLPCC2013數據集對比實驗結果表
可以看出,LSTM-CRF-Attention神經網絡模型在評價對象抽取任務中取得最好結果。在NLPCC2012數據集上,LSTM-CRF-Attention模型的嚴格評價F值達到55.05%,比CRF特征組合模型提高8.15%;寬松評價F值達到57.1%,比CRF特征組合模型提高8.11%。LSTM-CRF模型的評價指標也比CRF特征組合模型有明顯提高,略低于LSTM-CRF-Attention模型。在NLPCC2013數據集上,LSTM-CRF-Attention模型的嚴格評價F值達到57.24%,比CRF特征組合模型提高11.03%;寬松評價指標F值達到61.08%,比CRF特征組合模型提高10.9%。LSTM-CRF模型的評價指標比CRF特征組合模型有明顯提高,略低于LSTM-CRF-Attention模型。
從對比實驗數據來看,條件隨機場與神經網絡模型相融合能夠大幅提高評價對象抽取模型的效果。LSTM-CRF模型的評價指標均高于CRF特征組合模型,同時在神經網絡模型中加入注意力機制后,LSTM-CRF-Attention模型效果得到進一步提高。
5 結 語
本文基于注意力機制提出LSTM-CRF-Attention神經網絡評價對象抽取模型,該模型在評價對象抽取效果上取得了較大提升。使用CBOW和Skip-gram詞向量嵌入模型對語料進行預訓練,有效提高了模型的準確率。注意力機制在神經網絡模型中發揮出了重要作用,增加自注意力權重計算能夠讓模型更準確地提取評價對象信息。在未來的研究中,可以將詞性、依賴關系等語義信息融入到神經網絡模型中,能夠進一步提升模型的信息抽取能力。實驗數據為NLPCC測評數據集,數據規模仍然有限,需要在大規模數據集上進一步驗證模型的適用性,充分發揮神經網絡模型在大數據處理中的優勢。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
石油瀝青(2021年4期)2021-10-14 08:50:44
世界科學技術-中醫藥現代化(2021年10期)2021-03-02 05:52:06
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
中國工程咨詢(2015年2期)2015-02-14 02:59:26
俄羅斯問題研究(2012年1期)2012-03-25 09:54:51
