基于智能手機感知數據的心理壓力評估方法
2019-03-22 04:45:58王亞沙王江濤熊昊一趙俊峰張大慶
計算機研究與發展 2019年3期
王 豐 王亞沙 王江濤 熊昊一 趙俊峰 張大慶
1(高可信軟件技術教育部重點實驗室(北京大學) 北京 100871)2(北京大學信息科學技術學院 北京 100871)3(北京大學軟件工程國家工程研究中心 北京 100871)4(密蘇里科技大學計算機科學系 美國密蘇里州羅拉 65409)5 (計算機網絡和信息集成教育部重點實驗室(東南大學) 南京 210018) (wangfeng2013@pku.edu.cn)
在快節奏的生活中,越來越多的人會受到心理壓力的影響.美國大學健康協會(America College Health Association)在2015年秋季出具的心理學報告[1]中表明有57.7%的學生在過去的12個月中,至少一次感受到“非常焦慮”.同時,有研究表明人感受到的壓力會顯著影響心理和行為習慣,當人們感受到巨大壓力時,往往會顯得焦慮不安、失眠,嚴重的可能會導致心理甚至生理疾病[3].更有調查指出,在中途輟學的大學學生中,有64%是受到了精神方面的疾病的影響[2].這種由壓力帶來的心理疾病,在初期難以被重視,可能會發展成嚴重的問題,進而對一個人造成巨大影響[3].因此,在心理壓力轉化成嚴重的心理問題之前及時檢測心理壓力對大學生心理健康方面有很重要的意義.
近些年來,心理壓力的檢測越來越受到重視.就如何合理檢測人的心理壓力,心理學領域已經做出了很多的研究.最為傳統的方法就是利用依據心理學理論制定的調查問卷,由于其背后的理論支撐,這種方法現在依然是使用最為廣泛的調查方法.其次,人的心理壓力也可以通過專業的儀器進行監控,比如人的皮膚電阻可以和某些心理指標建立聯系[3],監控皮膚電阻即可完成對心理指標的檢測,且結果可信度較高.但是,這些方法并不適用于日常的心理壓力監控.無論是基于問卷還是專業儀器,由于都需要用戶提供額外的時間成本參與測試,對用戶造成了較大的侵擾,導致參與積極性不高;因此,我們希望找到一種自動的、低成本、低侵擾的方法來實現對用戶的實時心理壓力監控.與此同時,智能手機已經成為了人們生活的必需品.為了滿足人們生活中更多的需求,手機中也加入了越來越多的感知設備(比如加速度傳感器、聲傳感器、光傳感器等).在日常生活中,手機可以持續記錄大量和人的日常生活相關的的感知數據,包括運動信息、位置信息、手機使用信息等數據.
與此同時,有研究表明:人的心理壓力狀態會在人的行為習慣上得到反映,比如在壓力較大的狀態下,人們往往呈現出活動積極性降低、頻繁使用手機、睡眠質量較低等狀態[4].手機提供的感知數據可以反映用戶的行為習慣特征,而用戶的行為習慣可能和心理壓力有某種聯系,因此可以嘗試利用手機感知數據,通過機器學習的方法探究手機感知數據和用戶的心理狀態之間的聯系.
建立兩者之間的聯系存在著2項技術挑戰.
1) 如何將基礎的手機感知數據轉變為有意義的分類特征.原始的手機感知數據以日志形式存在,每一個時刻會生成相應的數據,而對心理壓力的評估需要綜合某一段時間內的用戶行為來進行判斷,因此需要將日志數據進行整合,并提取特征.
2) 如何解決帶標記的訓練數據不足的問題.在數據采集階段,智能手機可以低成本、持續采集各類數據并生成特征向量.然而,每個特征向量所對應的標記數據需要用戶主動標注,無法大量獲取,導致帶標記的訓練數據稀少.因此,如何在帶標記的數據不足的情況下進行準確的模型訓練是本文要解決的另一個技術挑戰.
本文針對上述挑戰,利用機器學習的手段,提出了基于智能手機感知數據的心理壓力評估方法.主要貢獻包括3個方面:
1) 對原始的手機感知數據進行分析,提出了特征提取與篩選的方法,基于這些特征生成用于訓練分類模型的樣本.通過特征抽取制定出一系列的方法,將抽象的日志數據轉化為了帶有標記的樣本數據,通過對特征進行篩選得到真正對分類有用的特征,減少了數據維度的冗余.
2) 使用半監督學習模型應對訓練數據不足的問題,本文充分利用大量的沒有標注的數據,使用協同訓練(co-training)對這些數據進行標注,并迭代訓練,提高模型分類精度.
3) 使用了現有的開放數據集(Dartmouth StudentLife)[5]進行驗證,結果證實了本文提出的方法可以對人的心理壓力進行有效地監控,且效果優于其他基線方法.
1 相關工作
1.1 基于專業感知設備感知情緒
由于人的心理變化必然會導致某些生理指標的變化,因此很多研究致力于利用可穿戴設備對人的日常心理壓力進行監控[6-9].通常,這些設備上集成了專門的傳感器,可以感知人的生理指標的變化,例如皮膚的電阻、體溫、心率、血壓等.由于可以直接獲取這些生理數據,所以基于可穿戴設備進行的感知往往很有說服力,但是代價是人們需要佩戴這些專業設備,這就帶來了成本較高,對人打擾程度比較大的問題.而基于手機數據的心理壓力感知可以將人從這些專業設備中解脫出來.
1.2 基于社交網絡感知情緒
隨著互聯網技術的不斷發展,社交網絡也在迅猛發展.基于社交網絡的和壓力相關的研究也越來越多.Lin等人[10]基于微博用戶的數據,利用深度稀疏神經網絡對用戶的心理壓力程度作出判斷;之后,Lin等人[11]基于微博數據,使用卷積神經網絡檢測用戶壓力;在青少年方面,Xue等人[12]從青少年的推特消息出發,提取了一系列特征,利用分類器來了解青少年的潛在壓力類別和壓力水平;Jin等人[13]提出了一種基于協同訓練的方法,結合微博和軌跡信息來完成對青少年的壓力檢測.
這些基于社交網絡的工作通過對人們在社交網絡上的行為和發布的內容,利用自然語言處理以及深度學習可以自動并且在對用戶低侵擾的情況下進行心理壓力的評估.然而,這些工作也有一定的局限性,那就是這些方法只能聚焦于那些頻繁使用社交網絡的用戶,對于不常使用社交網絡的用戶,由于缺乏訓練數據較難對其進行心理壓力的預測.同時,由于人們并不會一直使用社交網絡,因此無法通過社交網絡數據對一個用戶進行不間斷的監控,這些問題也是基于手機感知數據的工作所重視的地方.基于社交網絡對用戶的心理壓力進行評估的方法可以和本文工作形成互補.
1.3 基于智能手機數據感知情緒
近些年來智能手機不斷進步,為了適應各種使用場景,提供了更強大的功能,傳感器種類越來越多,精度也越來越高,它們記錄了用戶使用手機的習慣,提供了大量有價值的數據,陳龍彪等人[14]對智能手機在普適計算領域的應用展開過深入探究.因此也有了越來越多的基于智能手機的感知數據開展的研究,尤其在情感分析領域.這些工作大致上可以分為2種類型:1)探究智能手機數據和用戶情緒的相關性;2)訓練模型利用智能手機感知數據對用戶情緒進行預測.
在第1類的工作中,Wang等人[15]利用Student-Life數據集,從中提取了多維特征,利用線性回歸的方法,分析了用戶在學期中的行為習慣和用戶在學期中的心理壓力,沮喪程度等多種心理指標的關系;Mehrotra等人[15]利用用戶日常生活中的手機通信數據,應用使用習慣等提取了一系列特征,通過線性回歸的方法,分析了多維特征和用戶情緒沮喪程度的相關性;Xiong等人[16]利用大學生的GPS和POI數據,利用線性回歸的方法,分析了不同的行為習慣和用戶社交焦慮的相關性.這些工作對本文的特征提取工作有著很大的指導意義,缺陷是這些工作并沒有完成預測模型,本文在這些工作的啟發下完成,并構建了模型對用戶心理壓力進行預測.
在第2類工作中,Canzian等人[17]通過GPS數據實現了對用戶的沮喪程度(depression)進行預測,(他們)從用戶的GPS數據中提取多維度的特征,從PHQ-9問卷中得到用戶的沮喪程度,利用線性回歸的方法,建立了特征和用戶的沮喪情緒之間的聯系,并使用SVM構建預測模型,達到了80%的準確率.該工作的主要問題在于,其致力于研究用戶一段時間內的沮喪程度,想要達到較好的預測效果,則需要較長時間的GPS數據(通常是2周左右),無法對用戶短時期的心理狀態(以1天為時間窗口)進行實時評估.同時,該工作的事實依據選用的是問卷調查結果,問卷只在實驗結束時進行了一次,所以其無法對用戶的實時心理狀態進行刻畫.Lu等人[18]通過手機感知的聲音數據,可以對用戶在不同場合的緊張程度進行實時預測,該方法中用戶需要佩戴2部手機采集聲音信息,并利用聲學的相關方法提取了一系列特征.使用專業的手環獲取用戶的真實緊張狀態,最后利用高斯混合模型(GMM)對這兩者得到的數據建立聯系,實時預測用戶緊張程度,并討論了如何利用通用模型得到可以更好適配單獨用戶的個性化模型,最后個性化模型達到了約80%的準確率.這個工作雖然能夠實時且精確地預測用戶的緊張程度,可是其數據采集設備對用戶的打擾程度較高,不適用于日常生活中對用戶進行心理壓力的檢測.Bogomolov等人[19]在使用手機收集到的通信數據(包括手機通話數據和短信數據)之外,還使用了天氣數據和用戶的心理學問卷信息,利用決策樹構建模型,在預測用戶是否有壓力的二分類問題中,取得了72%的準確率.但是,和本文工作相比,有2個不同:1)這個工作中也要求用戶完成心理學問卷,并且結果反映心理學問卷對預測準確度有很大的貢獻,而當只使用收集數據的時候,模型很難達到較高的精度,但心理學問卷需要耗費用戶的大量時間,且對用戶的打擾程度較大,本文工作不需要用戶去額外填寫這些問卷,同時也達到了可以接受的模型精確度;2)這個工作中沒有考慮如何利用未標記數據,而在本論文中,本文通過協同訓練使用了大量的沒有標記的數據用于訓練,可以有效提高模型的預測精度.
2 數據集介紹與問題定義
2.1 數據集介紹
為了訓練模型,本文使用了開放數據集Student-Life[5,20].StudentLife數據集是Dartmouth學院的研究團隊于2013年在StudentLife Study中獲取的數據集.在研究中,學生被要求使用安裝有Student-Life程序的手機,手機在后臺記錄了一系列信息.這次研究一共收集了49個學生連續10周的感知數據.這些數據大致分為4個類別:傳感器數據、EMA(ecological momentary assessment)數據、問卷調查數據、學業數據.
本文使用了StudentLife數據集中的傳感器數據和EMA數據,其中,傳感器數據包含了所有利用手機傳感器得到的數據,描述了人在使用手機的過程中活動信息、環境信息、手機使用習慣信息等.EMA數據是即時的生理狀態評估,用戶在使用軟件時會不定期收到簡單的問題,用戶對自己的心理狀態做出評估后,實時反饋給服務器[21].
2.2 問題定義
本文目標是利用手機的感知數據建立模型預測用戶的心理壓力,即通過機器學習算法訓練一個分類器用來完成分類問題.因此需要明確如何形成用以訓練的樣本數據.
訓練數據使用StudentLife數據集中的傳感器數據,原始的文件一共分為10個類別,如表1所示.在試驗中,利用這些數據一共生成了49個學生的2 167個有標記樣本數據,樣本生成的方法在第4節會進行詳細介紹.
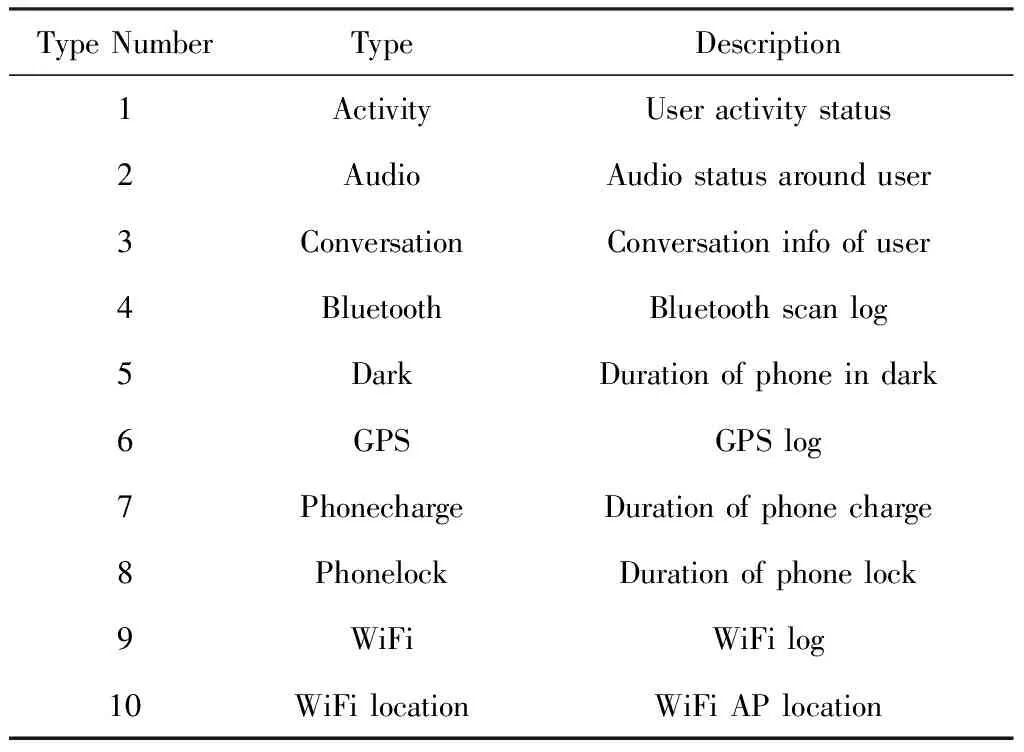
Table 1 StudentLife Sensing Data表1 StudentLife感知數據
不同于以往的工作使用心理學問卷得到的結論作為樣本數據的標注,為了追求預測的實時性,需要使用用戶實時反饋的心理狀態評估,這里利用了EMA數據.
在EMA數據中,真正需要關心的是用戶反饋的心理壓力數據,EMA問卷中關于心理壓力的問題是(figure),用戶有5個選項可供選擇,分別是:
1) 有一點壓力(a little stressed);
2) 確定有壓力(definitely stressed);
3) 壓力很大(stressed out);
4) 感覺較好(felling good);
5) 感覺好極了(felling great).
為了使類目之間的顯著性更大,綜合以往的工作[19],本文將這5類進行融合,將1)~3)合并為有壓力,將4)5)合并為無壓力.從而這個分類問題變為二分類問題.2類的物理意義也更加明確.
問題定義:通過感知數據集D,從D中提取出特征集合F={f1,f2,…,fn},從數據集D中,按照特征抽取規則得到樣本矩陣Xm×n(m行,每一行是一個樣本),從EMA數據中獲取標注集ym(yi對應樣本矩陣第i行的標注),利用Xm×n和ym訓練得到二分類分類器C,使得C能夠在給定輸入后完成二分類任務.
3 方法概覽
本文所設計的方法框架圖如圖1所示,方法共包括在線預測部分和離線訓練部分:
1) 離線訓練部分.將原始數據進行特征提取、特征篩選,得到數據樣本,包括有標記樣本和未標記樣本,然后利用協同訓練得到分類模型.
2) 在線預測部分.從數據源獲取傳感器數據,對數據進行特征提取,通過接口調用預測模型,可以實時完成對用戶心理壓力的評估.
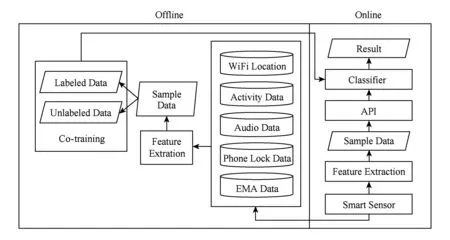
Fig. 1 Mental stress assessment framework圖1 基于移動感知數據的心理壓力檢測框架
整體的工作流程如下.首先,在用戶日常使用過程中,手機會不斷收集感知數據,然后這些感知數據會被傳輸到服務器上,通過特征抽取的方法,從中提取出一系列有意義的特征,繼而通過特征篩選的方法保留有利于分類的特征,將日志數據會被轉化為樣本數據.在生成有標記樣本的同時,也會利用相似的方法得到大量的未標記樣本,這些樣本將被用于協同訓練,從而提升分類模型的分類效果,本文構建的協同訓練分類器基于隨機森林分類器.分類器的訓練工作都是離線完成,從而用戶可以在線調用已經完成的分類器,實現對用戶的心理壓力的實時預測的工作.
4 核心方法
4.1 特征抽取
特征抽取的工作是為了將日志文件轉變為可用于分類的樣本數據.
首先需要引入時間窗口的概念,目的是將批量的日志數據轉化為一個樣本.對于每一個樣本,只使用這個樣本對應的時間窗口內的傳感器數據進行特征提取,生成樣本,并打上對應的標記.
本文選擇了24 h作為時間窗口,對于一個EMA數據,選取用戶反饋該結果的時刻之前的24 h的感知數據用以生成對應這個EMA結果標記的樣本.選定時間窗口為24 h有3個原因:1)人每天的行為是有規律性的,很多指標不會劇烈變化,這樣會更有利于控制變量,進行樣本間的對比,選取其他的時長作為時間窗口,便失去了這個保障;2)以24 h為時間窗口可以采樣到更多有意義的信息,比如用戶的睡眠信息,用戶的睡眠情況和用戶的心理狀態息息相關,以24 h為時間窗口可以很自然地采樣到這個數據;3)以EMA數據作為樣本的標注,根據每一條用戶反饋的EMA數據生成一個樣本,在該數據集中,EMA數據的頻率接近每個用戶每天1次,那么按照天來生成樣本,更符合實際操作中的物理含義.
在特征抽取的過程中,需要對特征進行細化.例如描述用戶周圍人數的特征.用戶在白天周圍人數較多和在晚上周圍人數較多實際上對應著不同的含義.這是因為用戶在白天活動較多,接觸到的人也比較多,而晚上一般都會回到宿舍,周圍接觸到的人比較固定,數量較少.而如果一個用戶晚上接觸到的人也比較多,那么可能會說明這個用戶在參加某種活動,這種發現是有意義的,而如果以天為單位去度量這一特征,則無法得出這個結論.這說明對特征進行細化可以得到更多信息.在特征抽取的過程中,本文使用了2種特征細化方法,分別是按照時間細化和按照POI(point of interest)細化.
1) 按照時間細化.將時間分成白天(8:00—18:00)和夜間(18:00—8:00),在之后的特征提取中,會把每一種維度結合時間進行細化考慮.
2) 按照POI細化.POI描述了用戶所處的位置,和時間類似,用戶的表現按照POI進行劃分也可以得到更多的信息.
同時,將特征分為2個類別,絕對特征和相對特征.絕對特征只描述當前時間窗口內的數據,而相對特征則由當前時間窗口的數據和用戶的歷史數據對比得到.
本節將詳細闡述針對不同數據集提取的特征以及提取這些特征的指導思想.
4.1.1 絕對特征Fa
4.1.1.1 POI相關特征
Jin等人[17]的工作是基于用戶的軌跡對用戶的心理焦慮程度進行預測,提取了POI相關的特征,并證明了用戶訪問不同POI的頻率和用戶的心理焦慮程度是有一定的相關性的.本文從該角度出發,基于StudentLife數據集的WiFi location數據,獲取用戶POI信息.
WiFi location數據是手機的WiFi模塊的掃描結果,每1~2 min會記錄下一次掃描結果,出于對隱私的保護,數據只給出了接入點的位置信息(接入點和學校內POI的關系).本文將POI分為3類:1)教學區,包括教學樓、實驗室、圖書館.2)宿舍區,包括學生公寓、賓館.3)飲食康健區,包括食堂、健身房、藝術館.進而得到每個用戶在每個時間所處的POI類別,這為通過POI信息細化特征提供了幫助,正如通過時間細化是把時間分為了白天和夜間,對各個指標按這2個時間段分別計算;通過POI細化則是把位置分成教學區、宿舍區、飲食康健區,對不同的區域進行計算.
與此同時,我們希望利用一個指標反映用戶每天在各類POI花費的時間.這類信息可以反映一個用戶每天活動的行為習慣,比如熱愛學習的用戶每天會花費更多時間在教學區,而較宅的用戶在宿舍區的時間更多,熱愛健身的人可能在飲食康健區停留更久.基于該思想的指導統計了每名用戶在時間窗口內的POI數據,由于采樣的頻率基本恒定,每一類POI的條目數量正比于用戶在每一類POI停留的時間.
除了考慮用戶在某種類型POI所處的時間長短,這3種類型的數據構成了一個分布,本文引入了熵來表達這個分布的特征.對于一個多類分布X,定義熵為
結合上文,形成的基于POI的特征如表2所示:
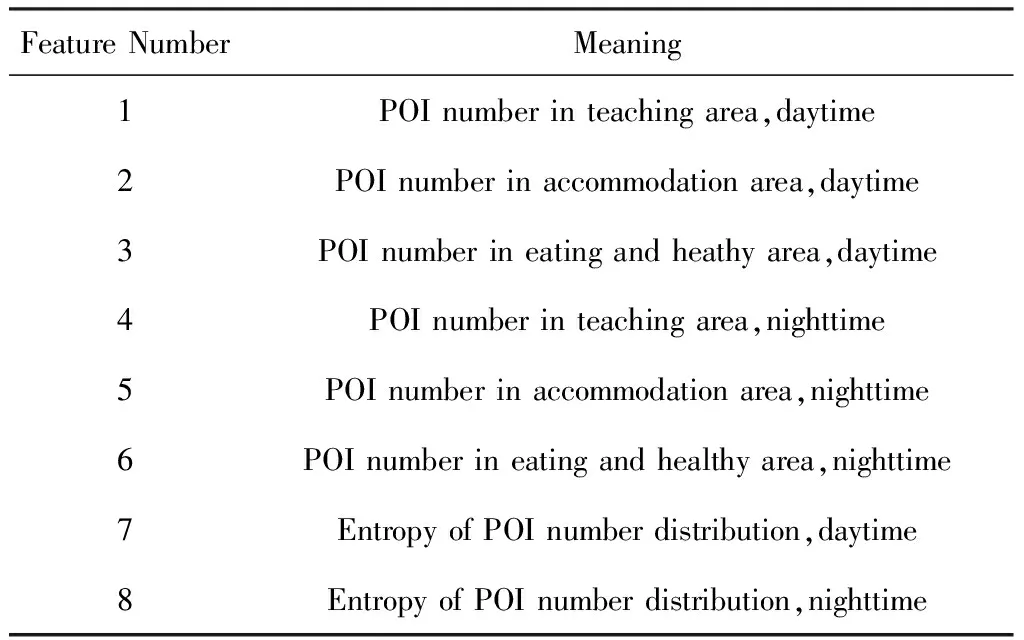
Table 2 POI Based Features表2 基于POI的特征
1) 活動信息相關特征
POI信息可以在一定程度上反映用戶的活動情況,但其粒度較大.StudentLife數據集中通過利用加速度傳感器收集到的數據,使用物理運動分類器[22]對原始數據進行分類,得到用戶在某個時刻的運動狀態:靜止(stationary)、走(walking)或跑(running),還有一類標簽是未知.為了得到更加精細的數據,本文利用了這類數據.傳感器采樣的頻率是恒定的,所以在一個時間窗口內,用戶的某一類標簽數目的多少就對應了用戶處在這種運動狀態下的時間長短.本文對時間窗口內每一類的標簽數量進行統計,并計算熵,同時考慮按照時間進行細化,得到特征如表3所示:
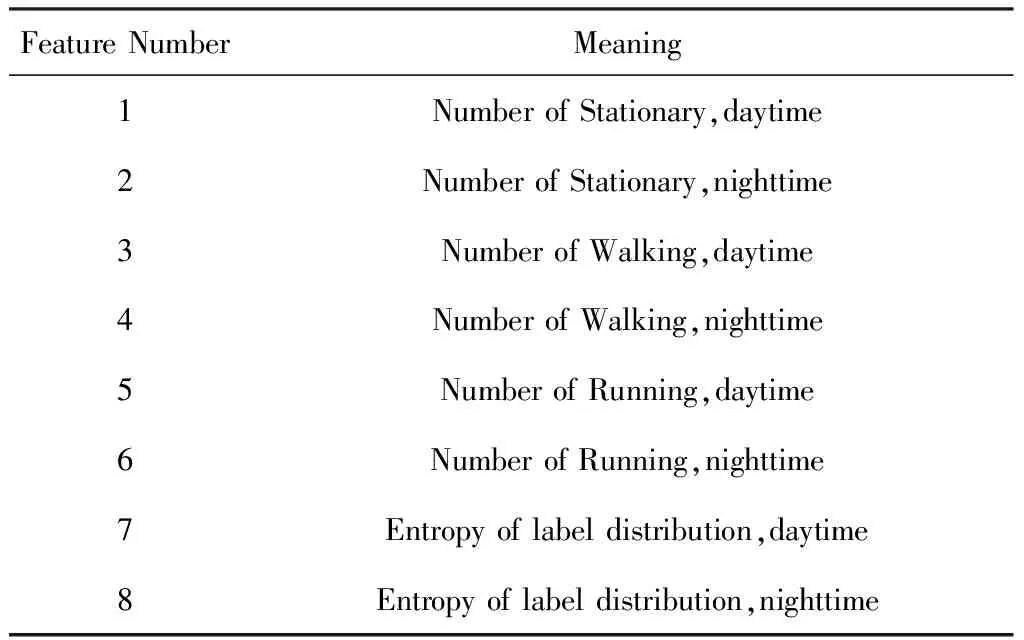
Table 3 Activity Features表3 活動信息相關特征
除此之外,可以反映用戶活動信息的還有GPS信息.GPS傳感器采樣以10 min為間隔,對用戶的經緯度信息進行采樣,在Jin等人[17]的工作中,研究者們探究了用戶的移動距離對用戶的心理焦慮程度的影響,本文利用GPS信息計算出用戶在時間窗口內的白天移動距離和夜間移動距離,移動距離為相鄰的采樣點間的距離的累加,2經緯度點間的距離計算方式為
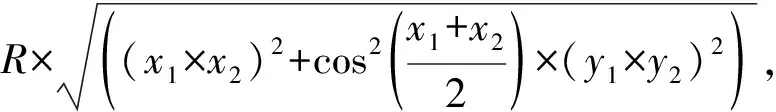
其中(x,y)為一個數據點的經緯度.
2) 聲音相關特征
從Lu等人[13]的工作中已經得知,用戶所處的環境的聲音信息可以用來預測用戶的緊張程度,這說明聲音信息和用戶的心理指標是緊密相關的.利用手機的感知數據可以獲取用戶所處環境的聲音信息.StudentLife數據集利用聲音分類器和對話分類器獲取了一系列的聲音相關信息:其中一個用以感知手機所處環境是否有聲音,另一個用以感知這個聲音是否是人聲.這些信息包括用戶每一時刻所處環境的聲音類型:安靜(silence)、噪音(noise)、人聲(voice).對于這一類的數據,采用類似于處理用戶活動信息的方法,結合時間細化,統計了用戶白天或者夜間3類標簽的數量,即用戶處在相應空間的時長.同時也計算了熵用以描述此分布.
數據集中還包含了用戶所處空間的對話信息,結合心理學角度發現,用戶的心理壓力程度會影響其是否樂于交流,本文據此統計了用戶在不同的時間段以及不同的類別POI所進行的對話次數和時長,聲音相關的特征維度如表4所示.
3) 社交相關特征
有研究表明:當用戶處于較為壓抑的狀態下時,往往表現得更加自閉,不愿與人交流.因此,可以提取特征來刻畫用戶的社交信息.區別于以往的工作,研究者可以通過用戶的電話短信數據獲取用戶的社交相關的信息.手機感知數據中不包含相關信息,但可以使用藍牙掃描數據近似刻畫社交信息.手機會定期進行掃描,并記錄下掃描到的藍牙設備.基于我們的認知,可以被掃描到的藍牙設備大多數為智能手機、電腦等設備.對于孤僻的用戶而言,不會傾向于去人流密集的地方,藍牙掃描記錄的設備數量也就越少;相反,對積極外向的用戶而言,熱衷于參加各種活動,那么記錄中設備數量也就會越多.據此,本文統計了用戶在不同時間段,在不同POI,藍牙掃描到的設備數量,以此來描述用戶所處環境的熱鬧程度,也一定程度上反映了用戶的社交習慣.具體的特征如表5所示.

Table 4 Conversation Features表4 聲音相關特征

Table 5 Bluetooth Features表5 藍牙相關特征
4) 用戶睡眠信息
基于心理學的預知知識,當用戶處在一定的心理壓力下時,會引起焦慮、睡眠質量差等生理反應,因此,為了預測用戶的心理壓力,因此為睡眠質量是很重要的一個特征,刻畫出用戶的睡眠時長以及入睡時間,可以為分類提供幫助.
本文基于手機鎖屏的記錄,獲取用戶的睡眠習慣.每一條記錄了一次手機鎖屏到開啟的起止時間(超過1 h才會被記錄),在探究過程中發現,每24 h都會出現一個較長的記錄,且該記錄都處在深夜,即該記錄對應了用戶夜間的休息(用戶在休息的時候不會使用手機,因此會留下一段長度相當于睡眠時長的記錄).本文使用用戶這條記錄的開始時間作為用戶入睡時間,構造了用戶的睡眠時長以及入睡時間的特征,如表6所示:

Table 6 Sleeping Features表6 用戶睡眠信息
4.1.2 相對特征Fb
絕對特征在描述問題的時候依然有局限性:某些用戶性格比較孤僻,數據顯示他接觸到的人會一直較少,有的用戶相對外向,其接觸到的人較多.因此,對于某一個指標的特定值,對一些用戶來說較高,而對另一些用戶是較少的,相同的值對應了相反的變化,因此本文利用將用戶的數據和自身的歷史數據進行縱向對比的方法來刻畫這種現象.
用于對比的基準是均值.由于時間窗口是24 h,數據一共包括了49名學生超過70 d的感知數據.因此對這49名學生的70 d數據分別按照4.1節提到的特征抽取生成樣本,再對樣本求取平均值,可以得到均值樣本(在前面特征抽取部分提到的維度中,并非所有維度都有對比意義,比如熵的對比值就沒有物理意義,這種值不會進行對比).
之后,對所有可生成相對特征的維度i,計算其相對特征ri:
ri=(vi-avgi)avgi,
將得到的ri作為新的特征維度加入原本的特征向量,對之前得到的樣本矩陣的每一行進行處理,得到增加了相對特征的樣本矩陣.
4.2 特征選擇
按照上面的方法,一共提取了83個維度的特征,但是由于特征都是手工提取,一定會存在很多特征與用戶心理壓力程度在數學上相關性不足.因此,對特征進行降維是有必要的.
為了特征的可解釋性,本文沒有采用PCA一類的方法進行降維,因此特征篩選問題等價于選取最優子集,而最優子集問題是NP難的,從而問題變為利用近似方法選取一個子集,能使分類器達到盡量優的效果,且可以在多項式時間內求解.結合驗證過程中使用的隨機森林分類器,本文提出了一種基于基尼不純度的降維方式.
基尼不純度是用來衡量數據集純凈程度的統計量,在決策樹中使用廣泛.對決策樹而言,隨著樹的節點不斷分裂,目標希望葉子節點中的數據點盡可能屬于同一類別,即希望節點樣本的“純度”越來越高.決策樹選擇節點的劃分方式的時候可以依據基尼不純度來選擇特征維度[23].這里有2個概念:基尼不純度和基尼指數,其中基尼不純度描述了一個數據集的純凈度,而基尼指數則描述了數據集在劃分過程中基尼不純度的變化.
對于數據集D來說,設維度集為F={f1,f2,…,fn},那么基尼不純度可以用IG(D)來表示:
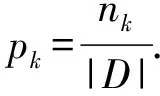
當對D按照某一個數據維度進行劃分的時候,會得到這個基尼不純度的變化,也就是基尼指數,當按照fi進行劃分的時候,基尼指數為
ΔI(D,fi)=IG(D)×(plIG(Dl)+prIG(Dr)).
在決策樹選取特征劃分時,會選擇劃分后基尼不純度變化最大的特征維度fi進行劃分,即:
f*=arg maxfi∈AΔI(D,fi).
基尼不純度變化越大,說明按照這個維度劃分后得到的數據的純度越高,特征篩選時,應盡量保留這些數據維度.基于這個思想:本文所有特征計算基尼指數,將特征按照基尼指數倒排,按照排序增量選取特征,繼而訓練分類器評估,篩選結果在第6節中展示.
4.3 模型訓練與在線識別
4.3.1 分類器選擇
由于數據集中有標記的樣本數量較少,在分類器的選取上,為了避免數據較少引起的分類器過擬合問題,采取了可以有效規避過擬合問題的隨機森林(random forest)來作為本文使用的分類器.
隨機森林是一個包含若干決策樹的分類器,其輸出的類別由個別樹輸出的類別的眾數而定.而森林中的每一棵決策樹只利用一部分特征進行分類,每一棵決策樹使用的樣本也是從原始樣本集合中通過Bootstrap自舉方法生成.
4.3.2 協同訓練
協同訓練(co-training)是一種半監督模型,在有標記的數據量較少的情況下,可以使用大量的未標記數據進行訓練,以提升分類器的精度[24].協同訓練需要從2個不同的“視角”去分析數據,它要求數據集合有2個不同的特征集合,且兩者是相互獨立的,任意一組數據集合可以訓練出預測類別的分類器.協同訓練通過結合著2個從不同視角出發的分類器,構建出更準確的分類模型.
本文采用了2類特征抽取方法,分別得到從原始數據中直接抽取到的絕對特征和基于個人歷史數據的相對特征,這2類特征在數學上也是相互獨立的.對2類特征分別構建分類器,利用協同訓練可以得到2個分類器,具體算法見算法 1:
算法1. Co-training.
輸入:有標記數據集Dlabeled、無標記數據集Dunlabeled、迭代輪數θ、每輪選擇的樣本數n;
輸出:分類器h1,h2.
① 將Dlabeled在2個不同的不相關的特征組合f1,f2上進行投影,分別得到投影后的數據集Df1,Df2;
② 利用Df1訓練出分類器h1,利用Df2訓練出分類器h2;
③ 對每一個Dunlabeled中的未標記數據,利用h1標注,選擇置信度最大的n個樣本,加入Dlabeled;
④ 對每一個Dunlabeled中的未標記數據,利用h1標注,選擇置信度最大的n個樣本,加入Dlabeled;
⑤θ=θ-1;
⑥ ifθ<0‖Dunlabeled=?
⑦ Returnh1,h2;
⑧ else
⑨ 返回算法步驟①繼續執行;
⑩ endif
在每一輪迭代中,從未標記樣本集中選取隨機森林分類器給出的置信度較高的n個樣本加入訓練樣本集,直到未標記樣本集為空.最終可以得到2個隨機森林分類器:h1和h2.
4.3.3 在線評估
通過協同訓練可以得到2個基于不同特征維度的分類器h1,h2,在預測過程中,需要綜合2個分類器給出的結果做出評估.
2個分類器都是基于隨機森林得到的.隨機森林是由很多單獨的決策樹組合得到的復合分類模型,隨機森林的結果是由單獨的決策樹輸出的類別的眾數決定.對二分類{c1,c2}問題來說,設一個包含m棵決策樹的隨機森林,給出分類結果為的決策樹分別為ni棵,那么隨機森林認為樣本屬于ci的概率為
在預測過程中,利用如下的公式得到2個分類器綜合的分類結果,選取概率較大的一個類目作為分類結果:
模型的訓練過程是離線完成的,識別可以在線完成,對給定的用戶數據進行特征提取,特征選擇之后得到樣本,就可以進行在線分類.
5 實驗驗證
5.1 實驗數據
實驗數據采用達特茅斯學院的StudentLife數據集,包括49名學生超過10周的傳感器數據和EMA反饋數據.對數據集采用前文提出的特征提取和特征篩選方法,生成了有標注數據和未標注數據,數量信息如表7所示:

Table 7 Number of Sample表7 樣本數量
5.2 實驗方法
本文在樣本集合上使用不同的方法構建模型,并評估模型的效果.在驗證過程中,對數據采用10折的交叉驗證,將數據隨機分成10份,其中9份用于訓練得到分類模型,最后1份用作驗證.本文使用3種評價指標,分別是精確率(precision,Pr)、召回率(recall,Re)、F值(F-measure,F1).
1)Pr:是正確被分到某一類的樣本數量占所有被分類器標為該類的樣本數量的比例;
2)Re:是正確被分到某一類的樣本數量占實際這一類的樣本數量的比例;
3)F1:是綜合精準率和召回率的一個指標,在認為二者權重相等的時候,是取二者的調和平均,也就是F1值:
本文對模型進行了3個角度的評估,和基線方法進行對比,對特征篩選的效果進行評估,對協同訓練的效果進行評估.
5.3 實驗結果
5.3.1 和基線方法進行對比
本文提出了基于隨機森林的協同訓練模型,在本節中,將此方法和基線方法進行對比,作為對比的基線方法包括:
1) 決策樹(decision tree);
2) 支持向量機(SVM);
3)K近鄰(KNN);
4) 邏輯斯蒂回歸(logistic regression).
對比的實驗結果如圖2所示:
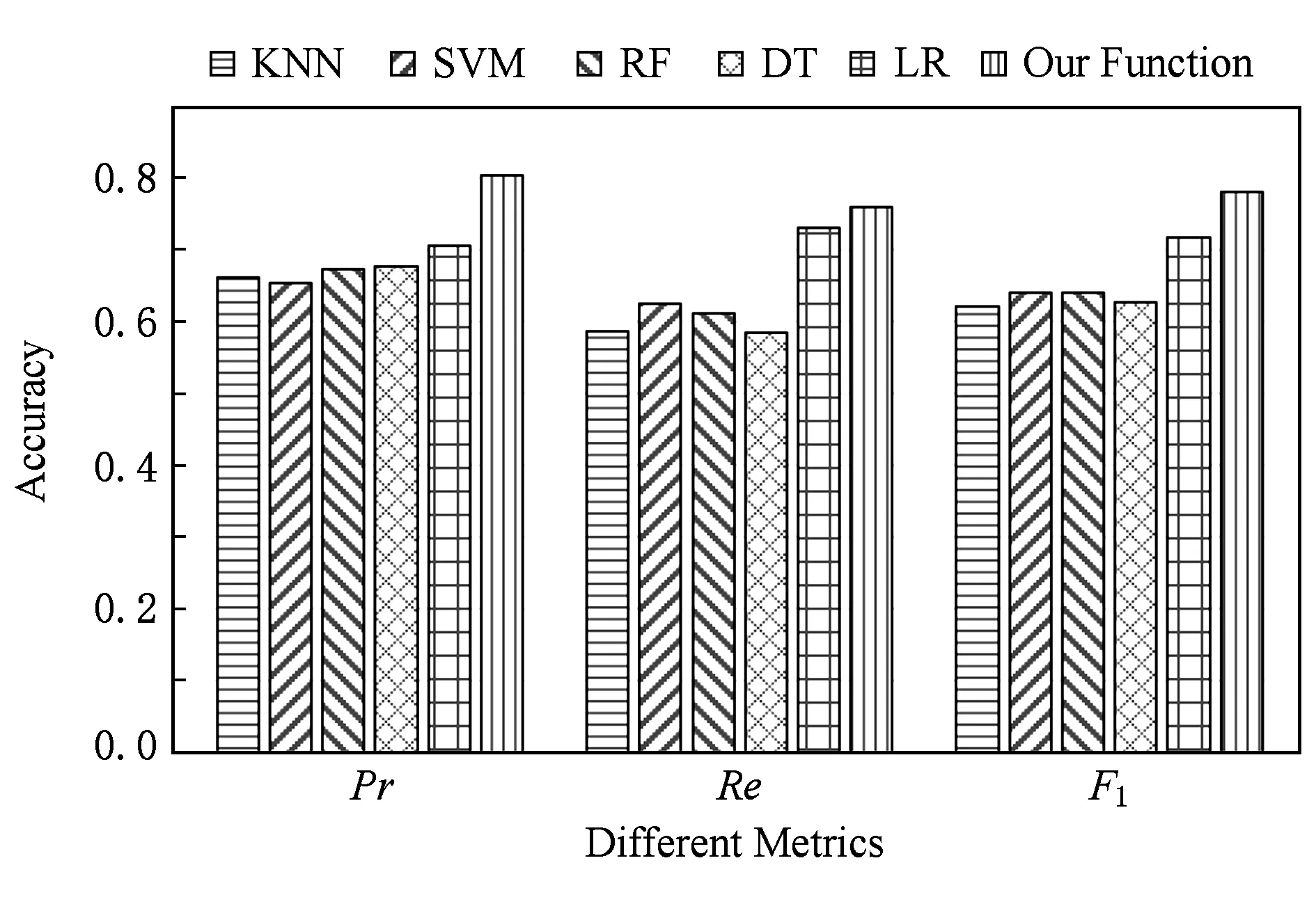
Fig. 2 Compare to other classifier圖2 對比其他分類方法
可以看出本文方法在Pr,Re,F1上的表現都要好于直接使用這些分類器.這得益于協同訓練的方法利用了大量的無標記數據,以及隨機森林分類器在一定程度上克服了數據樣本數量少容易帶來的過擬合問題,本文方法在3種指標上的值如表8所示:

Table 8 Performance of Our Function表8 本篇論文方法效果
5.3.2 對特征篩選的評估
基于手工提取的特征具有一定的冗余性,本文采用基于基尼不純度的特征篩選方法.對每一個特征,計算基尼不純度的變化,并依此倒排.然后從中不斷添加特征進行模型訓練,并進行評估,得到如圖3的曲線.
其中x軸表示訓練使用到的特征數量,y軸表示每輪迭代后模型的各項評估指標.從圖3中可以看出,隨著添加的特征數目不斷增加,各項評估指標的值首先呈上升趨勢,然后趨于平穩.說明在添加了一定量的特征之后,分類器的效果趨于穩定,那么就不需要繼續添加新的特征了.按照這個方法,最終選取了前26個特征用于最后的分類器訓練.
5.3.3 對協同訓練的評估
本文采用協同訓練對未標記的數據進行標記并用于迭代訓練.利用有標記的數據訓練出2個基本的隨機森林分類器,再用2個分類器對無標記數據進行預測,選取預測置信度較高的樣本進入有標記樣本集合,然后基于新的訓練數據集合訓練出2個隨機森林分類器,并對2個分類器的綜合分類結果進行評估,再不斷迭代,直到分類效果趨于穩定.據此得到了圖4所示.
其中x軸為迭代的輪數,y軸為分類器的評價指標值.可以看出,隨著逐漸加入分類器標注的樣本數據,分類器的效果先是逐漸提高,繼而曲線趨于平穩,說明分類器效果達到穩定,此后再加入樣本不再能使分類器效果有顯著提升.
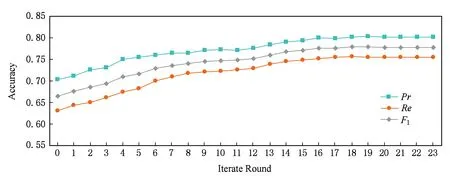
Fig. 4 Performance with number of iteration round圖4 模型評估指標隨協同訓練迭代輪數變化
從實驗中可以看出隨著協同訓練的不斷迭代,訓練模型的效果得到了很好的優化.因此在缺少大量有標記數據的情況下,使用半監督訓練可以有效利用無標記數據,從而改善原本分類器的效果.
6 總 結
本文分析了心理壓力對人的身心的重要性,并針對以往的評估人的心理壓力的方法,提出了基于手機感知數據的自動心理壓力感知方法,在對用戶低侵擾的情況下實現對用戶的心理壓力的評估.針對手機獲取到的日志數據,本文提出了一系列的特征抽取方法,將原始的日志數據轉化為可用于分類的樣本數據.基于基尼不純度提出了特征篩選方法,在多項式時間內篩選出對分類有利的特征.然后提出了基于隨機森林的協同訓練模型,實現了通過手機感知數據對用戶的心理壓力進行感知的任務(Pr=80.4%,Re=75.5%,F1=77.0%),效果好于基線方法.
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
創業家(2015年5期)2015-02-27 07:53:25
