針對層次化名字路由的聚合機制?
2019-03-05 03:45:42許志偉張玉軍
軟件學報 2019年2期
許志偉,陳 波,張玉軍
1(中國科學院大學,北京 100049)
2(中國科學院 計算技術研究所,北京 100190)
3(Department of Computer Science,University of Memphis,Memphis,TN 38152,USA)
現有的互聯網在可擴展性、移動性和安全性等方面面臨嚴峻的挑戰[1-3].互聯網的主流應用形式已經從基本的端到端通信轉變為大規模內容傳輸,現有互聯網端到端的設計原則無法適應這些新興的內容密集型應用形式,加劇了互聯網的內容傳輸壓力.同時,隨著移動互聯網的發展,由移動終端產生的流量占總體網絡流量的比重日益增加,而 TCP/IP體系結構面向常連接設計,IP地址被賦予身份和位置雙重功能,無法有效支撐移動性應用的要求.
為了從根本上解決互聯網面臨的這些問題,需要采用clean-slate方式設計并建設全新的未來互聯網[3-5].命名數據網絡(named data networking,簡稱NDN)[6,7]根據信息名字請求和傳輸數據,不再依賴固定的IP地址傳輸數據,保證了互聯網的可擴展性和移動性;同時,采用網內數據泛在緩存和多路傳輸,有效地保障了這種基于內容名字的傳輸機制的效率.鑒于 NDN網絡的這些優點,命名數據網絡的設計思想已經得到了廣泛的重視和研究,將會應用于包括5G在內的新興網絡體系[8,9].
NDN網絡基于內容名字進行路由,內容名字由不定數量的任意字符串組成.與 IP地址相比,內容名字的結構更為復雜,因此,現有的互聯網路由機制無法直接應用于NDN網絡.同時,當前互聯網擁有海量的在線內容,相應的內容名字數量也極其龐大.綜合考慮NDN網絡路由內容名字的復雜性及其龐大的數量,基于名字的路由技術將是影響NDN網絡效率的最為關鍵的問題,將直接影響NDN網絡的效率和可用性[1].名字是內容的標識,目前常見的內容名字可以分為兩類.
· 一類是以 NDN為代表的層次化名字,采用可讀的文本方式組織,一般由多個“/”隔開的名字段(字符串)組成,名字段的數量和長度都是任意的,類似于現行互聯網中的URL(uniform resource locator)[7].
· 另一類是以數字簽名為代表的扁平化名字.這類名字是經過散列(hash)得到的散列值,具有很好的安全性[2].各類扁平化名字具有其專門的編碼方式,與IP地址類似,配備有完整的命名和路由規則.
當前,關于層次化名字路由的研究還不成熟,尤其是如何優化層次化名字路由,還沒有完善的解決方案.
目前,關于層次化名字路由傳輸的研究主要集中在提升路由表的名字前綴(名字前綴由多個名字段構成)查找速度方面[10-14],例如,通過前綴樹壓縮和GPU并行加速等方法來提高路由查表速度.現有的NDN路由機制為了獲取特定內容,需要針對該內容的名字添加相應的路由表項,利用內容名字標識路由,并關聯可以用于轉發的接口信息(不唯一),因此,NDN的路由表規模與現有 TCP/IP網絡的路由表規模相比將出現巨大的增長.另一方面,NDN網絡中內容來源多樣,信息可以來自多信息源,或者移動信息源,甚至以存儲在網內緩存中的信息副本作為信息來源,導致網絡內容版本變化更加頻繁,進一步加劇了層次化名字路由器的負載.因此,僅靠提升單節點查表速度難以保證海量在線內容的高效路由轉發.針對這些問題,我們需要約減 NDN 網絡整體路由規模,實現層次化路由的聚合和聚合更新,保證高效、準確地轉發內容請求包及相應的內容包,提升NDN網絡整體效率.
路由聚合是降低路由表規模、提升查表效率和優化路由轉發效率的主要措施.路由聚合用一條聚合路由代替大量原始路由,從而減小路由表規模[15].NDN網絡各節點路由聚合過程如圖1所示,聚合前,路由表中存在各個內容對應的表項;聚合后,具有公共前綴和相同轉發接口的表項被聚合為一條聚合路由.不同于現有無類域間路由利用子網號(IP前綴)作為聚合路由標識,NDN網絡聚合路由的標識應包括兩部分:首先是內容名字前綴,其次還需要利用后綴聚合標識區分這一前綴下發往不同接口內容名字.這一聚合路由標識上的差異實際上反映了IP路由和層次化名字路由的本質差異.IP地址路由標識了路由轉發的目的地址,特定子網內IP地址有限,可以用子網號代表這些地址,作為聚合路由標識.NDN網絡中,擁有同一名字前綴的路由的指向不確定,僅利用名字前綴無法代表所有被聚合的路由,形成的聚合路由也無法作為路由轉發的真正依據,需要引入名字后綴的壓縮表示來共同標識被聚合的路由.
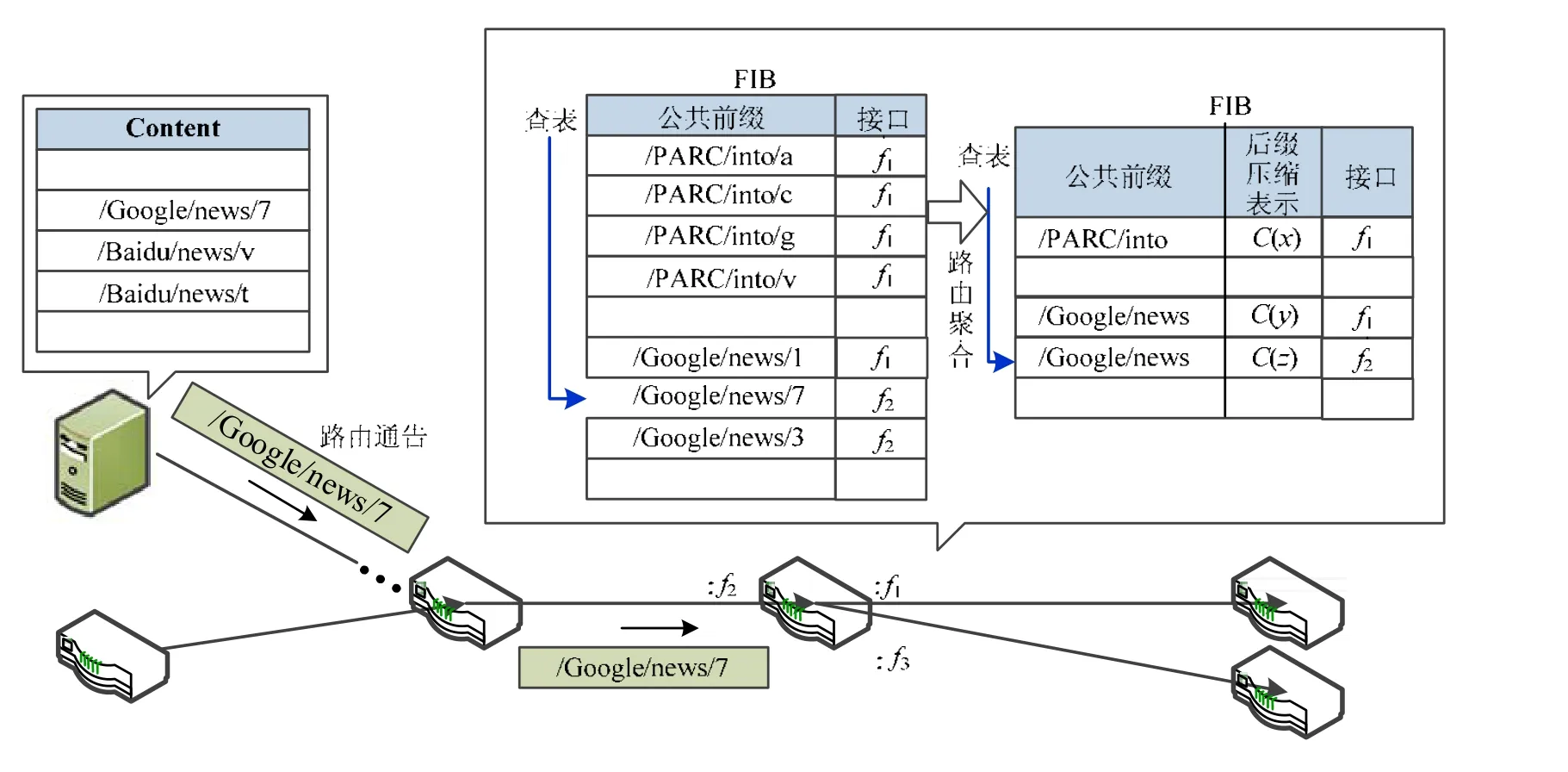
Fig.1 An example for hierarchical name-based route aggregation圖1 層次化名字路由的聚合實例
為了實現全網路由聚合,最大程度地減少名字路由條目數量,在完成特定前綴的名字路由聚合后,需要將被聚合路由通告給其他網絡節點,以便這些節點進一步進行路由聚合,與本地路由表壓縮的效果對比,路由聚合能夠在網絡層面真正大幅度縮減路由規模.
為了約減全網路由規模,提升層次化名字路由查表及轉發效率,本文對層次化名字路由聚合問題進行了系統的分析,采用名字前綴和后綴壓縮表示共同標識路由,提出了支持聚合的后綴壓縮表示機制,并以路由可用性為依據構建了高可用的路由聚合機制,為NDN網絡投入實際部署提供了前提.主要包括如下工作.
(1)對層次化名字路由聚合問題進行了研究,明確了將名字后綴納入聚合后的路由標識的必要性.
(2)為了支持聚合路由在節點間的交換及進一步的聚合,本文提出了一種支持更新及合并操作的后綴壓縮表示機制,堆疊計數布隆過濾器.
(3)為了限制后綴壓縮表示引起的冗余轉發,我們依據聚合路由的可用性構建了一套動態名字路由聚合機制,在保證路由轉發正確性的前提下,最大程度地聚合名字路由,約減全面路由規模,提升了路由轉發效率,保證了海量在線內容的高效路由轉發.
本文首先在第1節對問題背景和相關研究進行系統分析.第2節分析層次化名字路由問題.第3節提出一種可合并計數布隆過濾器,用于名字后綴的壓縮表示,和名字前綴一同標識聚合路由,以便進行本地路由聚合和全網聚合路由通告.在此基礎上,本文給出一套高可用的動態路由聚合機制.最后,本文在真實網絡拓撲的基礎上構建仿真平臺,驗證所提出的層次化名字路由聚合機制.
1 背景及研究現狀
1.1 NDN網絡
NDN根據層次化的名字而不是IP地址路由和轉發數據包.為了從NDN網絡中獲取需要的內容,一個請求節點 Consumer首先發送請求包(interest),其中包括被請求內容的層次化名字.網絡中的路由節點收到該請求包后,分3步進行處理.
(1)首先查找PIT表(pending interest table).PIT表記錄了之前轉發過的所有未被響應的請求包信息,包括被請求內容的名字、收到該請求的時間、接口及轉發接口.如果在 PIT表中找到了特定名字的請求信息,則意味著已經轉發過該請求,將新的請求到達端口加入該表項的接口列表,收到內容后一并處理;如果沒有找到,則建立新的PIT表項.
(2)查找該節點的內容緩存CS(content store),如果緩存了該內容,則直接構建相應的內容包(content),并從收到請求的接口返回內容包.
(3)如果本地未緩存所請求內容,則查找轉發表FIB(forwarding information base),從指定接口將該請求轉發給下一跳的各個鄰居.如果傳輸路徑上的節點都沒有緩存被請求內容,則請求包最終將被轉發到內容發布者 Producer,由內容發布者構建內容包.內容包中將包括內容名字、內容、內容包簽名及簽名信息(發布者公鑰等).然后,同樣由內容發布者從收到請求包的接口返回該內容包.內容包由轉發請求包的路由節點按照其對應 PIT表項中的記錄沿請求到達接口原路徑返回,最終達到內容請求者Consumer.
各節點 FIB中記錄全網所有在線內容的轉發信息,路由條目數量巨大,為了保證正常的基于層次化名字的路由轉發,必須有效地約減路由條目數量,提升路由查表及轉發效率.
1.2 相關研究分析
針對現有的TCP/IP網絡規模不斷增長的問題,大量工作試圖通過IP路由聚合和壓縮加以解決[15,16].其中,基于無類域間路由的TCP/IP網絡路由聚合機制利用子網號(IP前綴)代表被聚合的子網IP地址,有效地約簡了全網路由規模[15],保證了現有 TCP/IP網絡體系結構的互聯網的可用性.其后,為了進一步縮短路由查表時間,提升路由轉發效率,出現了大量本地路由表壓縮方面的研究.Degermark等人通過一種全新的 hash機制實現了路由IP前綴的壓縮[16].文獻[17]首次使用基本的Bloom過濾器實現了路由表查表過程的優化.針對IPv4和IPv6路由查表過程,文獻[18]提出了一種編碼機制,在保證查找效率的同時,降低了查找過程中的誤判率.然而,由于名字路由不再基于 IP實現路由,而是以內容名字為路由標識進行路由,路由標識的數量不可控,且結構更為復雜,這些研究都無法直接應用于層次化名字路由.
在 NDN路由轉發方面,張麗霞等人[7]進行了大量基礎性研究.首先,在文獻[19]中提出了 NDN網絡的自適應多路轉發機制,在轉發路徑選擇方面優化了網絡傳輸效率;其次,文獻[20,21]分別提出了 NDN網絡中基于內容名字的最短路徑優先協議OSPFN和鏈路狀態協議NLSR,實現了基本的層次化名字路由.在所提出的這些關鍵問題的引導下,層次化名字路由機制得到了更為廣泛的研究[22-24],包括分層路由和路由可達性評估等機制被先后引入層次化名字路由過程.為了進一步提升路由查表效率,文獻[10,13,14,25]通過哈希表、名字前綴的前綴樹索引和前綴樹壓縮等方式優化了NDN路由節點路由查表(內容名字查找)效率.文獻[11]通過GPU提升了前綴樹查找效率.為了實現板卡級別的包過濾,進而優化NDN網絡內容獲取效率,文獻[12]利用布隆過濾器實現了網絡節點本地FIB表、PIT表和CS緩存的表項板卡級緩存,提升了轉發效率.然而,當今互聯網已經得到了全方位的應用,在可以預期的互聯網擴大應用的大背景下,網絡信息數量將進一步急劇增長[3],僅僅通過改進本地路由查表過程、提升查表效率,并不能從根本上解決未來層次化名字路由在應用中的路由規模問題,需要通過研究包括路由聚合在內的全網路由規模約減機制來保證正常的路由查表及轉發.
2 針對層次化名字路由的聚合過程分析
構建在現有互聯網層次化網絡拓撲之上的TCP/IP路由聚合機制,通過無類域間路由將子網IP地址聚合成對應的子網網絡號以約減路由表規模,并將聚合后的路由通告給其他網絡節點,以便進行進一步的聚合,最終形成高度聚合的聚合路由,在全網范圍內約減路由規模.NDN的層次化名字路由根據路由名決定從哪幾個接口轉發內容請求.下面通過一個例子分析名字路由聚合過程.注意,為了簡化分析,假設各節點路由的轉發接口均一致,不再特別說明.參照IP地址聚合機制,層次化名字聚合過程如圖2(a)所示.

Fig.2 Potential problems in hierarchical name-based route aggregation圖2 針對層次化名字的路由聚合過程的潛在問題
(1)在路由建立過程中,路由器R1和R2分別向路由器R3發送了針對名字A1/B1/C1和A1/B1/C2的路由通告.
(2)路由器R3收到這兩條路由通告后,聚合成路由表項A1/B1并添入其FIB(fowarding information base)表.
(3)路由器R3繼續向周邊路由器通告聚合后的路由表項,最終路由器R4將收到的路由通告A1/B1與其本地路由A1/B2進一步聚合,得到路由A1并通告給R5.
(4)在數據請求階段,路由器R5向R4發送請求包,請求名字為A1/B1/C1的內容.
(5)路由器R4會根據路由表項A1/B1將請求包轉發給路由器R3.
(6)最終由路由器R3轉發給路由器R1,路由器R1返回相應的數據內容給請求者.
從上述過程可知,采用層次化名字聚合能夠縮小全網路由表規模,進而提升路由查找效率.然而,如果僅僅采取與IP地址類似的聚合方式,那么當請求沒有聚合過的內容時,這種聚合方式將會出現問題.還是在上述例子中,如果在步驟(4′)中,R5請求名字為A1/B1/C3的數據,那么在步驟(5′)中,R4同樣會基于聚合后的路由表項將請求包轉發給路由器R3,但因為路由器R3中并沒有聚合名字為A1/B1/C3的路由信息,將導致數據請求失敗.
從上述實例可以看出,名字聚合不能完全采用IP路由聚合的方式.原因在于,IP路由地址是一種具有固定長度的由0和1組成的比特串,當聚合后的IP地址前綴長度為k時,其可能包含的被聚合后綴的取值最多只有232-k種,IP地址聚合時考慮到了所有可能的后綴取值,聚合后通過IP前綴信息標識路由;與IP地址不同,內容名字的取值可以是任意字符串.層次化名字的一個名字段在理論上有無窮多種取值,如圖2(a)中,名字前綴“A1/B1/”后面可以添加各種字符串(名字后綴),因此,以名字前綴為標識的聚合結果無法囊括所有可能的名字后綴,即使請求名字同路由名字的前綴吻合,也無法保證可以根據該路由轉發請求并獲得對應的內容.因此,在名字路由聚合過程中,不僅需要抽離出待聚合路由的公共前綴來作為新的聚合路由前綴,同時為了準確地將多條路由聚合為一條聚合路由,也需要生成這些待聚合路由名字后綴的壓縮表示,和聚合路由前綴一起標識聚合路由,如圖2(b)所示.為了便于節點間交換聚合路由并進一步聚合這些路由,實現全網路由聚合,后綴壓縮表示不僅需要能夠準確地壓縮表示被聚合路由的名字后綴,還需要支持多個后綴壓縮表示的合并,以便構建新的聚合路由.如圖2(b)中,R3完成對路由A1/B1/C1和A1/B1/C2的聚合后,會將聚合路由A1/B1:C(x)通告周邊節點R4,其中,C(x)為名字后綴C1和C2的壓縮表示,R4可以將收到的聚合路由A1/B1:C(x)和本地路由A1/B2:C(y)進一步聚合,壓縮表示B1,B2的同時,合并C(x),C(y),形成新的聚合路由A1:B(k)/C(x,y),聚合路由標識由名字前綴A1和名字后綴壓縮表示B(k)/C(x,y)共同構成.
考慮到全網海量內容名字聚合后的巨大熵空間,過度的聚合必將帶來路由查表過程中的誤判,因此在名字聚合過程中,需要保證聚合后路由的可用性.在此基礎上,最大程度地聚合路由,縮減全網路由的規模.如何構建準確的后綴壓縮表示機制,并以聚合路由可用性為依據完善層次化名字路由的聚合機制,以更少的路由條目表征正確的路由轉發路徑,這將是一個極具挑戰性的問題,也是層次化名字路由聚合過程中必須解決的一個關鍵問題.
3 針對層次化名字路由的聚合機制
根據上一節的分析,為了構建針對層次化名字路由的聚合機制,主要需要解決兩個問題.
(1)聚合路由標識問題,具體來說就是名字后綴的壓縮表示問題;
(2)以路由可用性為基準的路由聚合問題.
為了解決這些問題,本節首先對聚合過程中的核心問題——名字后綴壓縮表示問題進行分析,并按照分析結論設計支持路由名字后綴壓縮表示的計數布隆過濾器——堆疊計數布隆過濾器,和名字前綴一起構成聚合路由標識;最后,在對NDN路由可達性分析的基礎上構建一套高可用動態路由聚合機制.
3.1 后綴壓縮表示問題分析
網絡內容不斷發生變化,存在內容源失效、內容過期和內容版本更新等情況,為了能夠動態地添加并更新指向相關內容的聚合路由,后綴壓縮表示機制不僅要表示特定內容后綴的存在性,同時還要支持特定內容后綴的刪除和更新.經過多年的發展,布隆過濾器(Bloom filter,簡稱BF)已經成為應用最為廣泛的壓縮表示機制,衍生出了多種不同類型的布隆過濾器,其中,計數布隆過濾器(counting Bloom filter,簡稱 CBF)被設計用來同時支持添加操作和刪除操作[26].CBF通過將 BF的單比特位單元擴展為用于計數的固定長度的多比特位單元,記錄各單元被重復設置為1的次數(所添加名字段的哈希值命中這一單元的次數),以便哈希到這些單元上的已添加元素需要被刪除時,通過減小這些單元上的計數器值來實現元素刪除.除了用l比特的計數器替代基本布隆過濾器的單比特單元外,CBF完全等同于 BF,可以按照基本布隆過濾器的配置方法配置,包括配置過濾器單元(計數器)數、哈希函數數量等.CBF的哈希函數命中特定單元的最大次數c大于特定整數i的概率具有上界[27],可以根據這一上界配置CBF各單元計數器大小(比特位串長度l).通常情況下,4比特長的計數器即可滿足構建CBF的需要,以極大的概率保證任一單元的計數器都不會超出其最大計數范圍.CBF可以滿足路由聚合過程中路由更新引起的動態添加、刪除名字后綴的需要.為了優化CBF的性能,在支持添加操作和刪除操作的同時,降低存儲開銷和假陽性率,多種新型計數布隆過濾器先后被提出來.其中,Cohen等人提出了 Spectral Bloom Filter(SBF)[28],可以確保其任一單元的計數器都不會超出其最大計數值,但是與 CBF相比增加了的存儲開銷.文獻[29]基于d-left哈希提出dlCBF,與CBF相比,在同樣的假陽性率下優化了存儲開銷.MPCBF[30]利用多級比特數組在保證查詢效率的基礎上實現了CBF的功能,其存儲開銷和假陽性率與CBF相比都有所改善.
但是,如果利用現有各類計數布隆過濾器壓縮表示路由名字后綴,在全網路由聚合過程中,來自不同節點的相關路由后綴的壓縮表示將被進一步聚合,這就需要將后綴壓縮表示(計數布隆過濾器)合并,而現有的各類計數布隆過濾器[27-30]都不支持多個計數布隆過濾器的合并操作.現有計數布隆過濾器都通過類似計數器的機制來記錄哈希函數重復命中各個單元的情況,多個計數布隆過濾器合并時可以選擇的合并算子包括加運算、或運算和異或運算.首先,逐個單元進行計數器值的按位或運算和異或的運算結果不能代表不同元素命中各單元的計數總和,因此無法用來支持計數布隆過濾器的合并.而對應單元的計數器相加同樣也存在問題.例如,
(1)將計數布隆過濾器的計數器長度設為4比特,最大計數值為15.
(2)當一個節點R周邊的16個節點中的一個Rj壓縮表示一個后綴名字段nsgx后,nsgx的k個哈希結果指向的計數布隆過濾器CBFj的計數器的值c1j,…,ckj均加 1,得到?cij≥1,i∈{1,2,…,k},j∈{1,2,…,16}.
(3)假設R周邊的16個節點都壓縮表示了nsgx,當R需要進一步聚合這條路由時,需要合并來自16個鄰居的計數布隆過濾器CBF1,…,CBF16.如果采用相加的方式合并這些CBF,則需要將這些計數布隆過濾器各單元計數器的值相加,即ci=ci1+…+ci16.由于?cij≥1,故ci≥16,超出了計數器的最大計數范圍.
注意,這與上述計數器最大值的概率上界并不沖突.文獻[27]中上界的證明條件是計數布隆過濾器用于壓縮表示不重復元素,如果不同路由存在相同的名字后綴,計數布隆過濾器的計數器很快就會溢出.究其原因,現有計數布隆過濾器在壓縮表示被添加的元素的過程中,沒有保留足夠的信息,無法發現兩個壓縮表示結果中相同的元素,合并后壓縮表示結果中會出現重復元素.綜上所述,由于現有計數布隆過濾器不能有效地排除不同路由節點上記錄的相同名字后綴的影響,因此不能支持來自不同路由節點的名字路由的聚合操作.為了實現支持路由聚合的名字后綴壓縮表示機制,并和路由名字前綴一同標識聚合路由,需要構建一種全新的壓縮表示機制,該機制需要同時支持:(1)后綴名字段的動態添加和刪除;(2)多個壓縮表示結果的合并.針對這兩個需求,我們在第3.2節中設計了一種全新的計數布隆過濾器——堆疊計數布隆過濾器(compounded counting Bloom filter,簡稱CCBF),用于被聚合路由名字后綴的壓縮表示.
3.2 堆疊計數布隆過濾器
為了支持名字后綴的動態添加和刪除,同時支持多個壓縮表示的合并,我們在現有計數布隆過濾器思想的基礎上構建的新的后綴壓縮表示機制需要:
(1)歸并重復后綴名字段的添加,支持多個壓縮表示的合并;
(2)記錄后綴名字段哈希結果命中過濾器各個單元的次數,支持后綴名字段的動態添加和刪除.
通過加運算合并現有計數布隆過濾器時,由于無法排除記錄在多個計數布隆過濾器中的重復后綴名字段,造成合并結果中會出現計數器計數溢出的情況.我們注意到,基本布隆過濾器可以通過按位或歸并重復名字段.這是由于在基本布隆過濾器中重復添加和合并重復名字段時,重復的名字段的所有哈希結果都將命中過濾器中同一個單元,即使重復置1,也不會改變BF比特數組的取值,從而屏蔽了重復名字段的影響.例如,將一個布隆過濾器BF1同另外一個布隆過濾器BF2合并的過程中,如果BF1和BF2中都添加了后綴名字段nsgx,nsgx的k個哈希結果分別指向的這兩個布隆過濾器的k個單元(位),b11,…,bk1和b12,…,bk2,全部被置 1.注意到,合并BF1和BF2后,仍有:

合并結果中同樣是這k個單元被置1,可以有效地歸并記錄在不同布隆過濾器中的重復名字段.根據這一觀察,我們利用基本布隆過濾器可以歸并重復元素的特點,通過堆疊多個相同的基本布隆過濾器來構建支持合并的計數布隆過濾器.多個基本布隆過濾器的特定位置的單元可以共同記錄該位置被所添加的后綴名字段的哈希結果命中的次數(每次將其中一個基本布隆過濾器的相應單元置 1),從而構建了一種全新的支持合并的計數布隆過濾器——堆疊計數布隆過濾器.CCBF通過偽隨機發生器使用多個基本布隆過濾器,在有效使用所包含的過濾器的同時,保留了各單元被重復置1時過濾器的使用順序.
CCBF的數據結構如圖3所示.
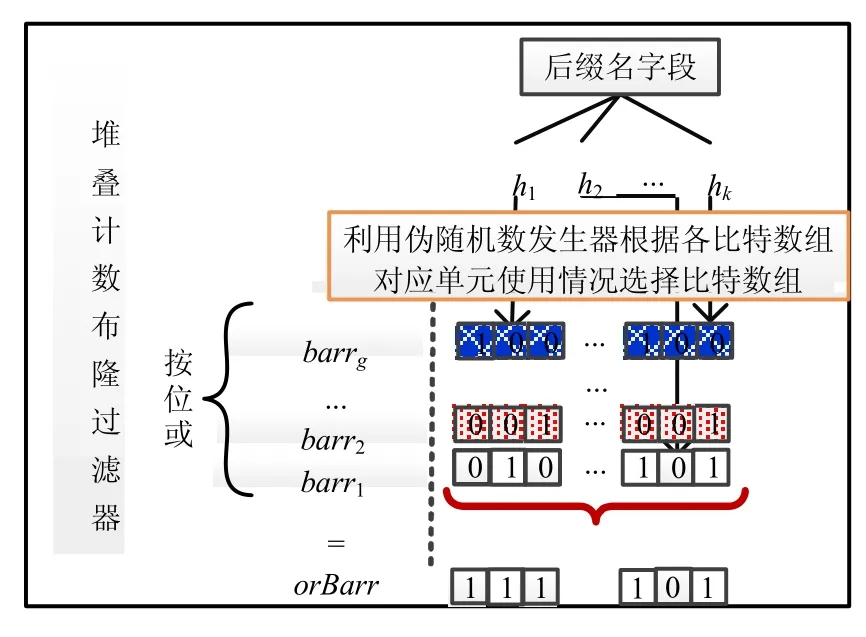
Fig.3 Framework of compounded counting Bloom flitter圖3 堆疊計數布隆過濾器的結構
CCBF由g個比特數組(長度為m)和它們按位或的結果數組orBarr構成.其中,g的大小以能夠滿足計數需要為基準,本節后續將具體說明.orBarr是 CCBF的g個比特數組按位或的結果,用于提升 CCBF的查詢效率.CCBF除了支持名字段的添加、刪除和查詢外,還支持多個CCBF的合并.下面對這些操作逐一加以說明.
(1)添加、刪除和查詢后綴名字段
CCBF在添加一個名字段nsg的過程中,針對k次哈希操作中的第j次哈希操作,利用偽隨機數生成器,根據哈希結果對應位置單元(下標為hashj(nsg)的單元)已經被置1的比特數組的數量,隨機選中g個比特數組中的一個比特數組barri(CCBF的第i個比特數組),將其下標為hashj(nsg)的單元置1.同時,如果為名字段nsg的k個哈希結果選擇的比特數組滿足:

則說明該名字段已經添加過,放棄本次添加.注意,本文采用的偽隨機數發生器根據第hashj(nsg)個單元已經被置 1的比特數組的數量來選擇下一個要使用的比特數組,具體操作就是針對各個單元隨機生成一個數組標號的排列,并以這些排列為列構建矩陣,在產生偽隨機數的過程中,以特定單元已經被置1的數組的數量加1為行號,查找特定單元對應的列上相應行中記錄的數組標號,返回該標號代表的數組.因此,選中的比特數組對應的單元必然還沒有被置 1.這樣既避免了名字段的重復添加,又高效地實現了特定單元被置 1次數的計數,為刪除名字段提供了前提.具體添加操作的計算過程如算法1所示.算法1中,利用偽隨機數發生器隨機選擇比特數組,針對一個特定的哈希結果指向的單元,總能在g個比特數組中找到一個數組,其對應單元為0(證明見定理1),可以持續支持新數據的插入.
算法1.CCBF.add(nsg).
輸入:nsg.//待壓縮表示的后綴名字段


定理1.CCBF過濾器中包含g個比特數組,令這些比特數組第pj個單元被置為1的個數為cj,則cj大于等于g的概率可控,具有概率上界.
證明:令 CCBF能夠插入的名字段的最大值為n,其相應的比特數組長度為m,哈希函數個數為k,比特數組數量為g,則g個比特數組的第pj個單元被置為1的數量cj大于等于g的概率為

根據斯特林公式化簡可得:
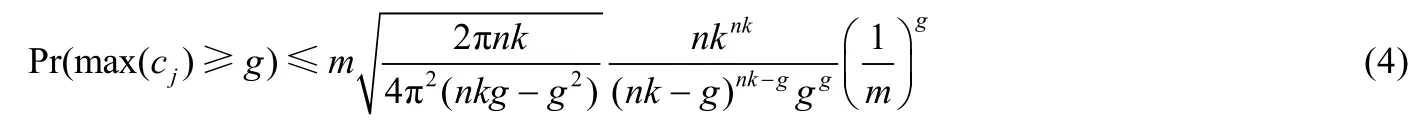
由文獻[26]中的公式:

可知,在布隆過濾器的最優配置中,n×k與m成線性關系,因此,n×k遠大于g,公式(4)中根號內的值小于 1.同時,對第2項放大,得到公式(3)的一個松弛上界:

將公式(5)代入可得:

為g個比特數組特定位pj被置為1的次數cj,得到g的概率上界. □
根據公式(7),當g為16時,CCBF任意一位全部被置1的概率為1.37×10-15×m,在通常網絡應用中,這種情況不會出現,即當向包括16個比特數組的CCBF添加名字段時,總可以為k個哈希結果找到對應單元為0的比特數組,完成添加操作.
下面對添加操作的計算復雜度進行分析和比較.算法1共進行了k次哈希、k次隨機數組選擇及k次數組讀寫操作,最后將g個比特數組按位或得到更新后的orBarr,計算復雜度為O(k×H1+k×H2+k+m×g),其中,H1為布隆過濾器哈希過程的時間開銷,H2為偽隨機數生成器選擇數組的時間開銷,偽隨機數生成器實際上就是在針對各單元的隨機數組標號排列中查找一個元素,其計算復雜度遠低于布隆過濾器的哈希函數,而比特數組按位或操作的復雜度m×g同樣小于布隆過濾器的哈希函數的復雜度,因此,本算法的計算復雜度規約為O(k×H1).現有的計算布隆過濾器,包括CBF、SBF、dlCBF和MPCBF,添加新元素時直接查找并更新對應的計數單元,而本算法還要通過額外的偽隨機生成器選擇計數單元對應的比特數組,雖然計算復雜度均為O(k×H1),但算法1的計算開銷將近似 2倍于上述 4類計數布隆過濾器的添加操作的計算開銷.當然,鑒于現有布隆過濾器哈希函數的高效性[26],CCBF添加操作的總體計算開銷仍較小,不會影響CCBF的應用.
布隆過濾器作為一種壓縮表示機制,除了可以節省存儲空間外,最關鍵的是可以提升后綴名字段存在性查詢的效率.與添加和刪除操作相比,后綴名字段(路由)查詢是路由聚合機制中最常見的操作,為了優化聚合路由(CCBF的名字段)查詢效率,我們在 CCBF中添加了一個記錄 CCBF中g個比特數組按位或的結果的數組orBarr,在進行查詢的過程中,無需逐一查看g個比特數組,判斷哈希結果對應單元是否為 1,而是直接查看orBarr的對應單元是否為 1即可,具體查詢操作如算法 2所示,查詢操作的復雜度完全等價于基本布隆過濾器查詢操作的復雜度,與CBF和MPCBF的查詢過程類似,可以直接定位各個哈希函數對應的單元并進行查詢,具有相同的計算復雜度.由于 SBF在查詢過程中在通過哈希函數定位計數單元后仍需要通過索引最終找到這些計數單元,以完成查找,dlCBF需要在d個分區中逐一定位并查找各個哈希對應的單元,存在重復操作.因此,SBF、dlCBF查詢效率低于CBF、MPCBF以及算法2.
算法2.CCBF.query(nsg).
輸入:nsg.//待查詢的后綴名字段

CCBF刪除操作的計算過程類似于添加操作的計算過程,這里不再贅述,僅就其中的關鍵操作步驟進行說明.首先確認該名字段可以刪除(類似算法 2的查找過程);然后,通過偽隨機數生成器定位上一次添加操作中各個哈希函數操作的單元所在的比特數組,將這些比特數組對應單元清零,并更新orBarr,完成名字段刪除操作.因此,CCBF刪除操作的計算復雜度與添加操作類似,為O(k×H1).與其他計數布隆過濾器相比,CCBF的刪除過程需要通過偽隨機數發生器找到需要進行單元清零操作的比特數組,因此,刪除操作的計算開銷近似 2倍于其他計數布隆過濾器的刪除操作的開銷.
(2)合并操作
不同于其他現有計數布隆過濾器,CCBF支持合并操作,即將多個配置完全相同的CCBF合并為1個,以便應用于類似路由聚合這樣需要歸并已有名字段的場景.多個CCBF的合并操作相當于將這些CCBF壓縮表示的名字段(添加的元素)合并,即等同于在一個CCBF中添加其他CCBF中壓縮表示過的名字段.CCBF中的偽隨機數發生器可以確保哈希結果對應單元置 1時選擇的比特數組有固定的順序,CCBF中添加后綴名字段(元素)的順序不會影響各個比特數組的取值,詳見定理2.因此,按照不同CCBF比特數組的標號,可以按順序合并各個比特數組(按位或,與BF的合并操作相同),實現多個CCBF的合并.
當然,多個CCBF合并后壓縮表示的名字段數量仍然受到其比特數組數量g和長度m的限制.以兩個CCBF的合并過程為例,合并過程主要是將兩個CCBF中的g個比特數組兩兩按位進行或操作,同時將兩者的orBarr也按位或.具體如算法3所示.
算法3.CCBF.combine(other).
輸入:other.//待合并的另外一個CCBF過濾器,兩個CCBF的配置完全相同,且合并后的后綴數沒用超過CCBF的容量n


其中,為了保證合并后不會超過CCBF的配置容量n,CCBF利用estSize函數估計當前已添加的名字段的數量(已添加名字段數量).CCBF每次添加1個名字段時會有k位被置1,因此可以利用g個比特數組中1的總數除以k,得到已經添加的名字段的數量,estSize函數的計算過程如公式(8)所示。

其中,g和k為CCBF配置的比特數組數量和哈希函數數量,比特數組的sum4ones函數可以計算它其中被置1的單元的數量.算法3的計算過程包括估計已添加名字段總數和合并比特數組兩部分,其中,
· 估計已添加名字段的復雜度為Ο(m×g),其中,m為比特數組長度,g為比特數組數量(最大計數范圍);
· 合并比特數組的復雜度也是Ο(m×g).
因此,算法3總的計算復雜度為Ο(m×g).注意,現有其他計數布隆過濾器均無法支持合并操作.
定理2.CCBF中添加元素的順序不會影響CCBF中各個比特數組的取值.
證明:對于一組元素nsg1,…nsgi,…,nsgn,將其按順序添加到一個 CCBF中.不失一般性,假設有兩個名字段——nsgx和nsgy,其哈希結果命中了 CCBF的第j個單元,CCBF中的偽隨機數發生器以確定順序在barr1,…,barrg中選中兩個比特數組,將其第j個單元置1.這一過程中,隨機數發生器選中的下一個比特數組的依據是當前第j個單元被置1的比特數組的個數.因此,如果首先添加nsgx,第j個單元被置1的比特數組的個數為0,隨機數發生器選中barr(1),將barr(1)[j]置 1.當添加nsgy時,選中barr(2),將barr(2)[j]置 1.同樣,如果先添加nsgy,將對barr(1)[j]置1,然后添加nsgx時,將對barr(2)[j]置1.無論nsgx和nsgy的添加順序如何,添加結果都是barr(1)[j]和barr(2)[j]被置1.對特定單元的多次加1操作的順序不影響該單元使用,因此,CCBF中添加名字段的順序不會影響CCBF中各個比特數組的取值. □
綜上所述,堆疊計數布隆過濾器可以高效地完成名字段的添加、刪除和查詢,其計算復雜度基本與現有計數布隆過濾器等同,其中,路由過程中最為頻繁的查詢操作的效率優于或等同于其他計數布隆過濾器.同時,堆疊計數布隆過濾器 CCBF支持高效的多過濾器合并,為聚合路由后綴合并(及其他需要合并多個壓縮表示的場景)奠定了基礎.CCBF空間復雜度為Ο(m×g),與CBF的空間復雜度Ο(m×log2g)相比,使用的存儲空間更多.同樣地,與 dlCBF和 MPCBF相比也需要更多的存儲空間(除 SBF使用的存儲空間隨添加元素增長外,dlCBF和MPCBF都在CBF的基礎上優化了存儲空間開銷[29,30]),但是根據定理1,g的取值在實際應用中具有上界(通常情況下為 16),因此,CCBF空間復雜度可控,在當前網絡設備存儲空間不斷擴大的背景下,完全可以應用于各類互聯網應用場景.在假陽性率方面,CCBF中哈希函數定位數組單元的方式與BF和CBF相同,函數個數k和數組長度m的配置也與BF和CBF相同[26],因此,CCBF中添加一個元素時,k個哈希結果均發生碰撞的概率(假陽性率)與BF和CBF完全相同.雖然CCBF的假陽性率高于優化了假陽性率的SBF、dlCBF和MPCBF,但是路由聚合過程中,假陽性的出現只會增加冗余轉發數量,不會引起轉發錯誤,并非路由聚合過程中的首要因素,不會影響CCBF在聚合路由后綴壓縮表示中的應用.
綜上所述,CCBF的主要設計目標是實現多個CCBF的合并,以便支持路由聚合操作.在此基礎上,CCBF優化了其查詢效率,為構建高效的路由聚合機制提供了前提.在基于CCBF的后綴壓縮表示的基礎上,可以將指向同一接口的多條具有公共名字前綴的路由聚合為 1條聚合路由,用公共名字前綴和后綴壓縮表示共同標識聚合路由(如圖1所示),有效地避免了第2節中指出的僅采用路由名字前綴來標識路由時出現的路由錯誤,構建了準確、高效的路由標識.
3.3 基于路由可達性的動態名字路由聚合機制
在上述層次化名字聚合路由標識的基礎上,本文利用路由可達性度量聚合路由可用性,并作為路由聚合條件,將多條穩定可達的具有公共名字前綴的路由(包括其他節點通告的路由)聚合為一條聚合路由;當可達性下降后,進行解聚合,還原被聚合路由,降低聚合程度,提升路由可達性;聚合和解聚合都需要通告周邊鄰居節點.按照這一動態聚合方式,本文構建了一套基于路由可達性的動態名字路由聚合機制.
本文之所以將路由可達性作為路由聚合的條件,其原因是聚合路由壓縮表示了被聚合路由的名字后綴(或后綴壓縮表示),將不可避免地在路由查找過程中引入假陽性,將沒有聚合過的路由納入聚合路由查找結果,進而在NDN網絡中帶來冗余的轉發.由于NDN網絡采用多路轉發機制,因此假陽性引起的冗余轉發不會影響正常的內容獲取,僅僅會加大網絡負載.當然,過大的網絡負載同樣會影響網絡效率,甚至會抵消路由聚合后路由規模縮減帶來的效率提升.如果假陽性問題引起的網絡負載過大,將會進一步引起網絡擁塞等問題,因此,我們需要最大程度地保證轉發的正確性,同時,通過路由聚合減小路由規模,提升網絡效率.其中,為了回滾聚合路由,需要在低速存儲中備份被聚合路由,在減小路由節點高速內存空間的同時,實現了基于路由可達性的動態聚合過程.本文名字路由聚合記錄如圖4所示.

Fig.4 An example for dynamic route aggregation圖4 動態路由聚合過程實例
NDN網絡節點的不同接口可以獲取不同內容,因此,本文的聚合機制在聚合相關路由的同時,保留了各個接口的獨立記錄.為每條聚合路由針對不同接口設置獨立的后綴壓縮表示單元和相應的可達性統計單元,形成聚合路由的標識二元組結構:〈路由前綴;轉發接口信息〉,其中,轉發接口信息中記錄了接口ID、路由后綴壓縮表示、轉發延遲統計和可達性統計等狀態信息(如圖4所示).可達性統計為RP(faceID),其中,faceID為相應的接口ID.可達性統計值為最近轉發出去的請求的響應比,代表路由可用性的統計結果,如公式(9)所示.

其中,n(t-1)為t-1時刻總共發出的內容請求包數量,ns(t)為t時刻收到的內容響應包數量.其中,通過卷積運算淘汰舊的統計信息,提升當前請求響應情況在統計結果中的比重.針對接口faceID,RP(faceID)準確地反映了依據聚合路由從該接口轉發請求、獲取內容的可能性,可以作為評估聚合路由可用性的標準.根據文獻[31]中的相關定理,當節點間連通概率大于等于lg(N)/N時(N為網絡節點數),網絡為強連通網絡.因此,我們可以將這一條件作為判斷路由可達性的閾值,如果所有RP(faceID)都大于lg(N)/N,則可以獲取分布在任意網絡節點上的內容.
當一組具有公共前綴的聚合路由在所有接口上的可達性都達到了閾值,且持續了從某個時刻t起的兩個時刻時,則這些路由被認為是穩定的路由,可以和其他具有公共前綴的穩定路由一同進一步聚合新的聚合路由.這種延遲決策機制可以避免聚合過程中的抖動現象(頻繁重復聚合和解聚合的循環).同樣地,聚合路由兩個時刻內持續不可用,則需要將其分解為之前被聚合的路由,以提升路由準確性,改善路由可達情況.為了支撐聚合路由回滾,需要在各個節點保留如圖4所示的線索樹結構,在聚合路由的同時保留被聚合路由信息,以便更新和回滾聚合路由.其中,當前路由線索是當前使用的聚合路由的線索,當需要更新和回滾路由時,可以快速找到相應的聚合路由,并回滾或更新相關被聚合路由.本文的動態聚合機制可以在保證路由可用性的前提下最大程度地聚合路由,縮小全網路由規模,提升層次化名字路由效率.
4 實驗評估
4.1 方案部署與實現
我們在NDN網絡的仿真平臺ndnSIM[32]的基礎上實現了本文針對層次化名字路由的聚合機制.
· 首先,我們對ndnSIM的FIB模塊進行了修改.現有的ndnSIM中,每條路由包含路由名字前綴和轉發接口信息.基于本文動態路由聚合機制,我們在轉發接口信息中添加了后綴壓縮表示 C和可達性統計RP(見公式(9)).RP中的統計值n(t-1)是在查表轉發請求時計數,而nr(t)是下一個時刻收到的內容包的數量.根據不同的預定容量n,用于壓縮表示后綴名字段的CCBF按布隆過濾器最優配置設置比特數組長度m及哈希函數個數k[26],同時,根據本文第3.2節的分析,比特數組數量被設置為16.在此基礎上,FIB模塊周期性更新 RP,根據更新過的 RP分析現有路由的可用性,將持續可用的路由進行進一步聚合,得到新的聚合路由,并周期性地通告周邊節點.同時更新在低速外部存儲中的記錄路由聚合過程的數據結構(如圖4所示),以備聚合路由回滾時還原其中備份的路由信息.
· 其次,我們修改了轉發模塊ndn-forwarding-strategy.實現了基于名字前綴和后綴壓縮表示的轉發機制.
仿真平臺在本地計算機上部署,其配置如下:Ubuntu 13.04,內核版本 3.8.8,Intel Core i7 3.4G CPU,DDR3 1866 16G內存,1TB硬盤.為了保證仿真結果真實、可靠,我們采用了一個真實的網絡拓撲——歐洲EBONE網絡拓撲[33],包括279個節點、731條邊,其中包括65個邊界網關節點、45個網關節點和169個邊緣路由節點.在邊緣節點中,我們隨機選擇了10個節點作為內容發布節點producer,實驗中請求的各類內容全部由這10個節點發布.另外,選擇了 30個節點作為內容請求方 consumer,內容請求服從參數α為 0.6的 Zipf-Mandelbrot分布,即被請求的多數內容為熱門內容,其他內容很少被請求.為了全面驗證本文路由聚合機制的有效性,實驗中使用了多個不同規模的數量集,這些數據集的具體信息見表1.

Table 1 Datasets表1 數據集
在此基礎上,通過對這些數據進行組合,我們可以得到各種規模的名字數據集.在其基礎上,我們對本文路由聚合機制的有效性進行了全面的評估.首先比較了路由聚合前后的路由表規模;其次,通過與 NDN原生路由查表機制以及利用CBF壓縮路由表的對比方案比較,給出了路由聚合前后的路由查表效率的比較;最后,通過對比分析了本文路由聚合機制帶來的假陽性問題.
4.2 聚合前后路由表規模對比分析
路由聚合的目標是減少路由條目數量,從而提升路由查表效率,進而優化網絡傳輸效率.同時,路由條目的減少還會減少路由設備內存的使用,降低 NDN網絡部署成本.為了驗證本文路由聚合機制的聚合效果,我們在數據集Alexa top 1M上比較了各個路由節點在同一時刻采用聚合后的路由條目數量和不采用聚合的情況下路由條目數量的比值R,在2 000s內對279個路由器每隔6s記錄一次R值,仿真結果如圖5所示.
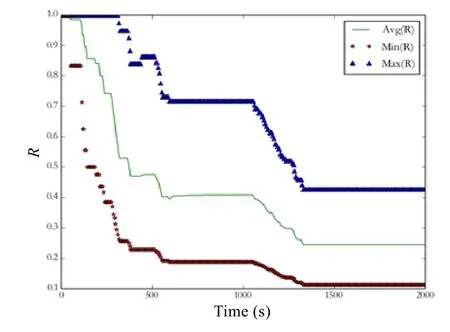
Fig.5 Effection on FIB size reduction of route aggregation圖5 路由聚合對路由表規模的影響
仿真過程中,隨著時間Time的推移,路由聚合程度不斷提升,路由規模不斷縮小,在1 400s附近,全網路由聚合達到穩定狀態.全部 279個節點中,在全網路由聚合完成后,路由條目數量至少壓縮了 60%,平均壓縮了75.47%,路由聚合對路由規模的縮減效果明顯.注意,由于現有數據集中多數名字(URL)只有 2級,如果應用于實際部署的NDN網絡中,路由名字層次變化更多,路由聚合效果也會更為顯著.
4.3 聚合路由效率分析
作為影響網絡傳輸效果的關鍵因素,路由查表效率直接影響網絡數據包轉發延時.路由聚合主要通過減少路由條目數量(路由表規模)來提升路由查表效率,進而縮小網絡數據包轉發延時.利用本文路由聚合機制,可以將多條具有公共前綴的層次化名字路由聚合為單條聚合路由,并利用這些路由的公共名字前綴和后綴壓縮表示來共同標識該聚合路由.因此,與未進行聚合的層次化名字路由相比,本文的路由聚合機制在縮短名字前綴查找時間的同時,也引入了路由后綴的查找過程.為了驗證本文聚合過程對路由查表時間的影響,我們首先針對不同規模Ns的名字路由(1萬、10萬和100萬)進行路由聚合,并比較聚合前后各路由的查表時間總和LTime.實驗結果如圖6(a)所示,圓形點線代表未聚合路由查表時間總和,方形點線為本文聚合路由查表時間總和.可以看出,未被聚合的路由的查表時間與路由規模成正比例關系,隨著路由規模Ns的增長線性增加;而聚合后路由查找基本不受路由規模增長的影響,僅表現出1s的差異,如圖6(a)所示.究其原因,主要是由于聚合后減小了前綴數量及前綴查找時間;同時,本文在后綴壓縮表示查詢方面的優化(為CCBF添加16個比特數組按位或得到的歸并結果orBarr)也避免了大量后綴查詢時延的引入.
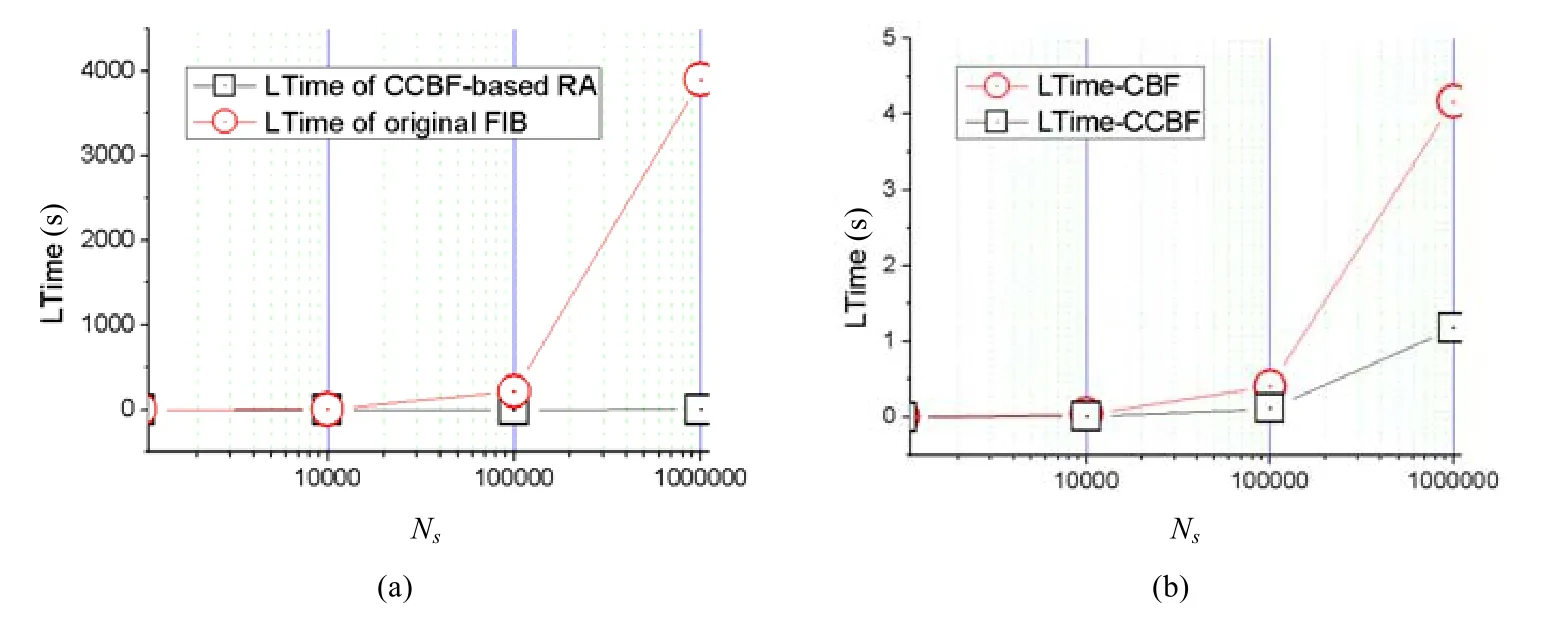
Fig.6 Comparison of route lookup time圖6 路由查找效率對比
為了進一步驗證本文路由聚合機制的查表效率,我們在 CBF的基礎上構建了一套路由壓縮機制作為對比方案,采用與本文的聚合路由相同的前綴和CBF壓縮表示的路由后綴共同標識壓縮后的路由.壓縮后的路由規模與本文路由聚合后的路由規模相同,通過這一方式對比驗證本文聚合路由查表效率.如圖6(b)所示,方形點線為CBF的查詢時間LTime-CBF,圓形點線為本文CCBF的查詢時間LTime-CCBF.在不同規模的路由表上,本文方案的查表時間始終只有對比方案的一半,本文建立在orBarr上的查詢過程的效率要優于CBF的查詢效率.
同時,我們對比了聚合前后路由更新效率(如圖7所示),路由更新時間等于所有路由的查找、刪除和添加操作的總和,用UpTime代表.圖7(a)中,圓形點線為未聚合路由總更新時間,方形點線為本文方案路由總更新時間.未聚合路由的整體更新時間都隨路由規模Ns的增長呈線性增長,本文路由聚合機制的更新時間增加較慢,路由規模對路由更新效率的影響同樣存在.為了進一步評估本文機制的路由更新效率,圖7(b)中,我們對比了本文機制的路由更新時間和基于CBF的對比方案的路由更新時間.圓形點線為本文機制的總路由更新時間,方形點線為對比方案的總路由更新時間.兩個方案的總路由更新時間都隨路由規模Ns的增長呈線性增長,本文路由更新時間略小于對比方案路由更新時間的 2倍,雖然與路由查表時間相比,本文的路由聚合機制的路由更新時間較長,但路由更新不是網絡路由轉發過程中最關鍵的操作,操作頻率較低,且獨立處理,基本不影響路由查表過程.
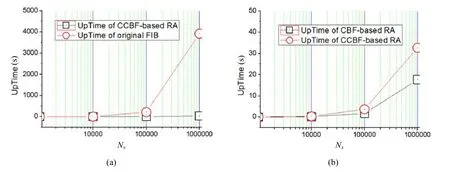
Fig.7 Comparison of route updating time圖7 路由更新時間對比
4.4 假陽性分析
本文的聚合標識在使用路由名字前綴的同時,還引入了基于CCBF的后綴壓縮表示.CCBF本身可能會在查詢過程中引入假陽性,即查詢到未被壓縮表示過的名字段.假陽性在路由聚合問題的背景下,將會引發路由查詢的假陽性誤判,將數據包發往沒有通告過相關路由的接口.注意,假陽性不會影響數據包從通告過該路由的接口正常轉發,僅僅是增加了冗余的路由轉發.本節實驗驗證了本文后綴壓縮表示所采用的 CCBF布隆過濾器的假陽性情況,并與基于CBF的對比方案的假陽性進行了對比.在布隆過濾器的配置過程中,本文為各個過濾器設定的最大假陽性率均為0.01.圖8中,菱形點線為CCBF在不同規模數據集下的查詢假陽性數Fp-CCBF,方形點線為對比方案在不同規模數據集下的查詢假陽性數 FP-CBF.兩種布隆過濾器在不同規模的數據集上的假陽性值相同.
為了進一步分析假陽性的出現情況,分析兩種方案在不同的添加比例Rfill下的假陽性變化情況,本文針對3種不同規模的數據集(1萬、10萬和100萬)進行了實驗.其中,Rfill=nc/n,n為布隆過濾器容量(分別取1萬、10萬和100萬),nc為添加到布隆過濾器的名字段數量.如圖9所示,在不同規模的數據集下,兩種方案的假陽性查詢數量在Rfill達到0.85后出現了假陽性查詢,并在Rfill到達1時達到最大值,兩種方案的假陽性查詢數量始終保持相同.本文方案在查詢假陽性方面等同于基于計數布隆過濾器CBF的對比方案,沒有帶來額外的假陽性查詢.
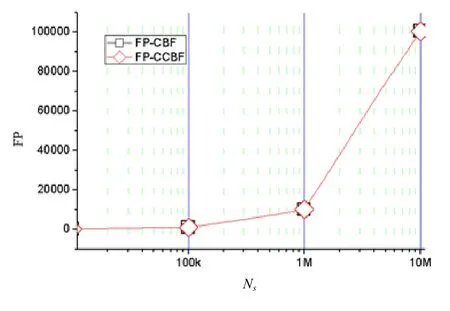
Fig.8 False positive under datasets with different size圖8 不同規模數據集下的假陽性
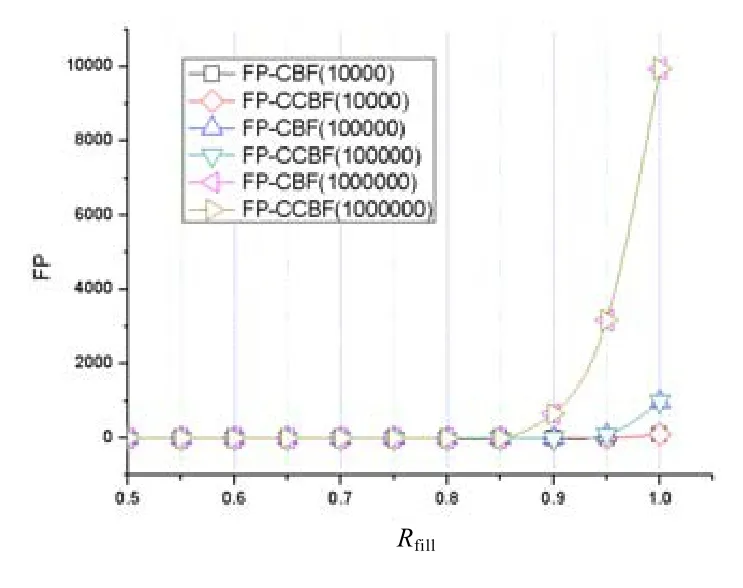
Fig.9 False positive with differentRfill圖9 不同Rfill下的假陽性
5 結 論
為了實現針對層次化名字路由的聚合機制,進而優化NDN等信息中心網絡的傳輸效率,本文首先分析了層次化名字路由的聚合問題,明確了路由聚合過程中需要同時利用路由名字前綴和后綴壓縮表示來共同標識聚合后的路由.為了實現對名字后綴的壓縮標識,同時在路由聚合過程中通告和進一步聚合(合并)這些后綴壓縮標識,本文提出了一種全新的計數布隆過濾器 CCBF.CCBF在支持多過濾器合并的同時,還優化了查詢效率.在此基礎上,本文進一步提出了面向路由可達性的動態路由聚合機制,在保證路由可達性的前提下最大化聚合路由.我們在真實網絡拓撲及數據集上構建了實驗環境,驗證了本文路由聚合機制的有效性,本文路由聚合機制通過有效聚合路由,以較小的冗余路由轉發(假陽性路由查詢)為代價,減小了路由規模,優化了網絡傳輸效率,為NDN等信息中心網絡投入實際應用提供了前提.
本文的路由聚合程度由路由可達性動態決定.作為影響可達性的關鍵因素,如果能夠有效地降低 CCBF的假陽性查詢結果,則不但可以避免過多的冗余轉發,而且可以提升路由可達性,進一步提升路由聚合程度,減少路由條目數量.為此,在下一步的研究工作中,應該將綜合分析現有計數布隆過濾器的優化思路,降低堆疊計數布隆過濾器的查詢假陽性,進一步改進路由后綴壓縮表示機制及相應的路由聚合過程.
