基于對抗學(xué)習(xí)的跨模態(tài)檢索方法研究進展
2019-03-02 02:35:26張璐
現(xiàn)代計算機 2019年2期
張璐
(四川大學(xué)計算機學(xué)院,成都 610065)
0 引言
近年來,由于多媒體數(shù)據(jù)的快速增長,跨模態(tài)檢索這一研究領(lǐng)域吸引了學(xué)者們的廣泛關(guān)注。跨模態(tài)檢索的任務(wù)是用一種模態(tài)數(shù)據(jù)作為查詢條件,檢索相關(guān)語義的另一種模態(tài)的數(shù)據(jù)。該研究領(lǐng)域的核心問題和難點是如何去衡量不同模態(tài)數(shù)據(jù)的內(nèi)容相似度,同時目前的研究致力于提高檢索的精度。2017年,B.Wang等人第一次提出了將生成對抗網(wǎng)絡(luò)(Generative Adversarial Networks)[1]應(yīng)用到跨模態(tài)檢索問題的方法ACMR(Adversarial Cross-Modal Retrieval)[2],該方法中使用對抗學(xué)習(xí)來使得文本和圖像兩種模態(tài)數(shù)據(jù)的特征分布趨于一致,可以有效地尋找不同模態(tài)的共同子空間。2018年,出現(xiàn)了更多使用對抗學(xué)習(xí)進行跨模態(tài)檢索的研究方法,并在公開數(shù)據(jù)集上取得了優(yōu)秀的效果,進一步證明了對抗學(xué)習(xí)在跨模態(tài)檢索問題上的有效性和研究價值。
1 相關(guān)工作
1.1 跨模態(tài)檢索
跨模態(tài)檢索的一般步驟分為三步,如圖1所示。第一步是對不同模態(tài)的數(shù)據(jù)進行特征提取,第二步是進行跨模態(tài)相關(guān)性建模,第三步是對檢索結(jié)果進行排序。跨模態(tài)檢索方法大致分為兩類,一類是基于實值特征學(xué)習(xí)的方法,另一類是基于二值特征學(xué)習(xí)的方法[3]。先進的實值特征學(xué)習(xí)方法包括 CCA[4]、Corr-AE[5]、LCFS[6]、JRL[7],先進的二值特征學(xué)習(xí)方法包括 CMSSH[8]、SCM[9]、SePH[10]、DCMH[11]。雖然二值特征會損失部分信息,但是由于采用位運算,二值特征學(xué)習(xí)方法在檢索速度上優(yōu)于實值特征學(xué)習(xí)方法。
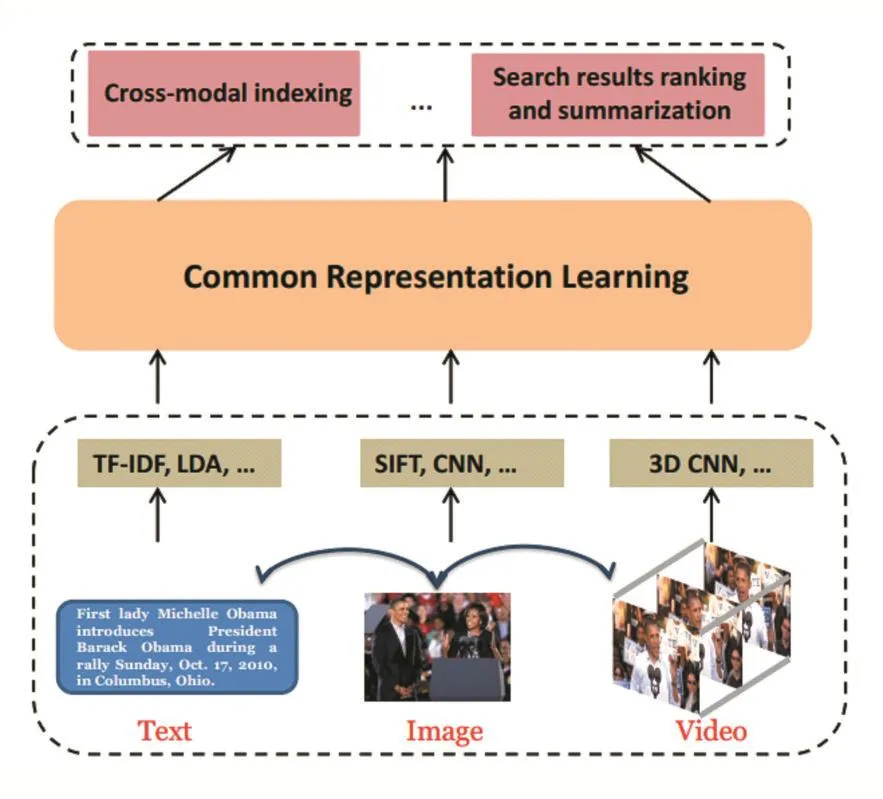
圖1 跨模態(tài)檢索的總體框架[3]
1.2 對抗學(xué)習(xí)
Ian J.Goodfellow等人在2014年提出了生成對抗網(wǎng)絡(luò)(Generative Adversarial Networks),該網(wǎng)絡(luò)的原理是利用零和博弈的思想,讓網(wǎng)絡(luò)結(jié)構(gòu)中負(fù)責(zé)生成偽造數(shù)據(jù)的生成器(Generator)和負(fù)責(zé)鑒別真實數(shù)據(jù)與偽造數(shù)據(jù)的判別器(Discriminator)進行對抗訓(xùn)練,從而讓生成器學(xué)習(xí)到正確的數(shù)據(jù)分布。GAN相比較于傳統(tǒng)的模型,不同點在于它擁有兩個不同的網(wǎng)絡(luò),訓(xùn)練的時候采用的是對抗訓(xùn)練,其中生成器的梯度更新信息來源于判別器而不是真實的數(shù)據(jù)樣本。在跨模態(tài)檢索領(lǐng)域,對抗學(xué)習(xí)中的判別器通常替換為一個進行二分類的分類器,判別生成的數(shù)據(jù)是文本模態(tài)或者圖片模態(tài),來使得生成器生成模態(tài)不變的共同特征。
2 研究進展
2.1 對抗跨模態(tài)檢索
對抗跨模態(tài)檢索是第一個將對抗學(xué)習(xí)應(yīng)用到跨模態(tài)檢索問題的論文。該方法是一個實值特征學(xué)習(xí)方法。該方法使用特征生成器和模態(tài)分類器組成的對抗網(wǎng)絡(luò)生成具有模態(tài)間不變性和模態(tài)內(nèi)判別性的共同特征。特征生成器由標(biāo)簽預(yù)測和結(jié)構(gòu)保存兩個模塊組成。標(biāo)簽預(yù)測模塊以圖片和文本的特征匹配對為輸入,輸出該匹配對的語義類別概率分布,損失函數(shù)表示為:
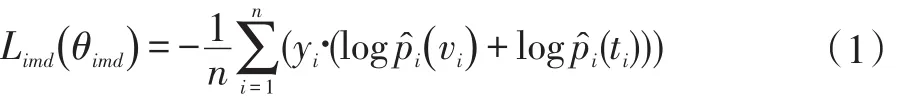
其中yi表示圖片和文本匹配對的真實的類別標(biāo)簽向量,log和log分別表示圖像和文本的多標(biāo)簽分類概率。優(yōu)化該損失函數(shù)的目的是保存特征的模態(tài)內(nèi)判別性。結(jié)構(gòu)保存模塊引入了三元組約束和模態(tài)間不變性損失。損失函數(shù)表示為:


其中mi表示輸入的文本或者圖片特征的模態(tài)標(biāo)簽,是一個one-hot向量。D(vi;θD)和 D(ti;θD)分別表示預(yù)測輸入特征為文本或者圖片模態(tài)的概率。對抗訓(xùn)練的過程是在一次迭代中固定特征生成器或者模態(tài)分類器的參數(shù),最小化正在訓(xùn)練的模塊的損失函數(shù)來進行優(yōu)化的,這兩個子進程可以表示為:

2.2 自監(jiān)督對抗哈希網(wǎng)絡(luò)
自監(jiān)督對抗哈希網(wǎng)絡(luò)跨模態(tài)檢索[12]是一個二值特征學(xué)習(xí)方法。該方法使用自監(jiān)督語義生成網(wǎng)絡(luò)和對抗學(xué)習(xí)來保存生成的統(tǒng)一的哈希碼的語義相關(guān)性和分布一致性。該方法利用自監(jiān)督語義生成網(wǎng)絡(luò)生成保存圖像和文本語義信息的標(biāo)簽的語義特征,并使得圖像和文本的生成網(wǎng)絡(luò)學(xué)習(xí)到的特征對齊語義特征,以此建立文本和圖像特征的語義關(guān)聯(lián)。利用兩個模態(tài)分類器對輸入的語義特征或者文本和圖像特征進行模態(tài)分類,以此在對抗學(xué)習(xí)中學(xué)習(xí)不同模態(tài)特征分布的一致性。自監(jiān)督語義生成網(wǎng)絡(luò)的損失函數(shù)表示為:



該損失函數(shù)表示模態(tài)分類器分類錯誤的個數(shù)。對抗學(xué)習(xí)的損失函數(shù)表示為:

對抗訓(xùn)練時固定生成網(wǎng)絡(luò)或者判別網(wǎng)絡(luò)的參數(shù),優(yōu)化另一個網(wǎng)絡(luò)中的參數(shù)。
2.3 基于注意力機制的深度對抗哈希
基于注意力機制的深度對抗哈希跨模態(tài)檢索[13]是一個二值特征學(xué)習(xí)方法。該方法引入注意力機制去檢測多媒體數(shù)據(jù)中有益于不同模態(tài)數(shù)據(jù)進行相似度比較的信息量大的區(qū)域,即受關(guān)注區(qū)域。使用深度對抗哈希去學(xué)習(xí)有效的注意力掩碼和哈希碼,通過實驗驗證了注意力機制在跨模態(tài)哈希方法中的有效性。該方法包括三個模塊,分別是特征學(xué)習(xí)模塊,注意力模塊和哈希模塊。特征學(xué)習(xí)模塊用于提取圖像和文本的特征,注意力模塊學(xué)習(xí)注意力掩碼用于區(qū)分圖像與文本的受關(guān)注區(qū)域和不受關(guān)注區(qū)域,哈希模塊用于將圖像和文本的受關(guān)注區(qū)域特征和不受關(guān)注區(qū)域特征分別轉(zhuǎn)換成對應(yīng)的哈希碼。特征學(xué)習(xí)模塊和注意力模塊對應(yīng)對抗學(xué)習(xí)中的生成器,哈希模塊對應(yīng)對抗學(xué)習(xí)中的判別器。該方法引入了跨模態(tài)檢索損失和對抗檢索損失對網(wǎng)絡(luò)的參數(shù)進行優(yōu)化。跨模態(tài)檢索損失函數(shù)表示為:

其中A和B表示不同的模態(tài),HiA和HjB是語義相同的不同模態(tài)的哈希碼,HiA和HkB是不同語義不同模態(tài)的哈希碼,優(yōu)化該損失函數(shù)的目的是保存哈希碼的語義相似性。對抗檢索損失表示為:

哈希模塊優(yōu)化該損失函數(shù)的目的是盡量讓同一語義不同模態(tài)的不受關(guān)注區(qū)域保存相似性,而注意力模塊盡量區(qū)分出受關(guān)注區(qū)域和不受關(guān)注區(qū)域,讓不受關(guān)注區(qū)域不保存相似性信息。整個框架的目標(biāo)損失函數(shù)表示為:

訓(xùn)練的時候固定哈希模塊,更新特征生成模塊和注意力模塊的參數(shù):

固定特征生成模塊和注意力模塊的參數(shù),更新哈希模塊的參數(shù):

3 結(jié)語
自監(jiān)督對抗哈希網(wǎng)絡(luò)與對抗跨模態(tài)檢索的區(qū)別在于后者是一個實值特征學(xué)習(xí)方法,而前者是一個二值特征學(xué)習(xí)方法;后者是讓圖像和文本的特征在擬合真實語義標(biāo)簽的過程中進行共同決策來使得圖像和文本預(yù)測標(biāo)簽分類的概率分布趨于一致,而前者是讓圖像和文本的特征對齊真實語義標(biāo)簽的特征分布來使得特征分布趨于一致。基于注意力機制的深度對抗哈希與對抗跨模態(tài)檢索的區(qū)別在于前者是一個二值方法;后者使用對抗學(xué)習(xí)來尋找共同子空間,而前者使用對抗學(xué)習(xí)處理注意力網(wǎng)絡(luò)的參數(shù)學(xué)習(xí)。從以上內(nèi)容的介紹可以看出,基于對抗學(xué)習(xí)的跨模態(tài)檢索方法受到了廣泛的關(guān)注,且在已發(fā)表的文獻中呈現(xiàn)的實驗結(jié)果也充分證明了對抗學(xué)習(xí)應(yīng)用到跨模態(tài)檢索問題上的有效性和進一步的研究價值。
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現(xiàn)代語文(2016年21期)2016-05-25 13:13:44
湖北經(jīng)濟學(xué)院學(xué)報·人文社科版(2015年8期)2015-12-29 05:53:07
上海電機學(xué)院學(xué)報(2015年4期)2015-02-28 14:30:00
大連民族大學(xué)學(xué)報(2015年2期)2015-02-27 08:28:11
計算物理(2014年2期)2014-03-11 17:01:39
河南科技(2014年23期)2014-02-27 14:19:15
