基于協(xié)同過(guò)濾的高校圖書(shū)推薦系統(tǒng)
2019-03-02 02:35:34劉濤
現(xiàn)代計(jì)算機(jī) 2019年2期
劉濤
(南京工程學(xué)院計(jì)算機(jī)工程學(xué)院,南京 211167)
0 引言
近些年來(lái),互聯(lián)網(wǎng)技術(shù)蓬勃發(fā)展,即將進(jìn)入5G時(shí)代的移動(dòng)互聯(lián)網(wǎng)、物聯(lián)網(wǎng)、云計(jì)算等技術(shù)都是各個(gè)國(guó)家和公司的關(guān)注重點(diǎn)。與此同時(shí),全球互聯(lián)網(wǎng)能產(chǎn)生的信息量級(jí)也從TB發(fā)展為PB,甚至ZB。信息量的飛速增長(zhǎng),使人們能獲取更多的信息資源,但也增加了人們獲取所需信息的難度,這被成為“信息超載”。如何解決“信息超載”,節(jié)約人們的時(shí)間和精力,成為研究的重點(diǎn)。
搜索引擎是一種解決方案,但隨著數(shù)據(jù)量的增加,僅僅通過(guò)搜索往往已經(jīng)滿足不了人們的需求,推薦系統(tǒng)成為一種更好的解決方案,相比搜索引擎的“一對(duì)多”,推薦系統(tǒng)實(shí)現(xiàn)了“一對(duì)一”的服務(wù)方式,它能夠根據(jù)每個(gè)用戶的個(gè)人愛(ài)好和習(xí)慣,做出個(gè)性化推薦。同時(shí)還能夠及時(shí)跟蹤用戶需求的變化,做出的推薦也會(huì)跟著需求的變化而變化。
大學(xué)圖書(shū)館擁有著數(shù)十萬(wàn)甚至數(shù)百萬(wàn)的圖書(shū)資源。向喜歡或需要的讀者推薦相應(yīng)的圖書(shū),實(shí)現(xiàn)圖書(shū)的個(gè)性化推薦,具有十分重要的意義。
1 協(xié)同過(guò)濾技術(shù)
目前,推薦系統(tǒng)中的推薦技術(shù)主要有關(guān)聯(lián)規(guī)則、基于內(nèi)容的推薦、協(xié)同過(guò)濾和混合推薦方法。協(xié)同過(guò)濾根據(jù)其他用戶的偏好向目標(biāo)用戶進(jìn)行推薦。它首先找到與目標(biāo)用戶的偏好一致的一組鄰居用戶,然后分析鄰居用戶,并推薦鄰居用戶喜歡的目標(biāo)。協(xié)同過(guò)濾具有以下優(yōu)點(diǎn):①不需要考慮推薦項(xiàng)目的內(nèi)容;②可以為用戶提供新的推薦;③訪問(wèn)網(wǎng)站時(shí)對(duì)用戶的干擾較小;④技術(shù)易于實(shí)現(xiàn)。因此,它已經(jīng)成為一種流行的推薦技術(shù)。
以下為協(xié)同過(guò)濾技術(shù)分類如圖1所示。
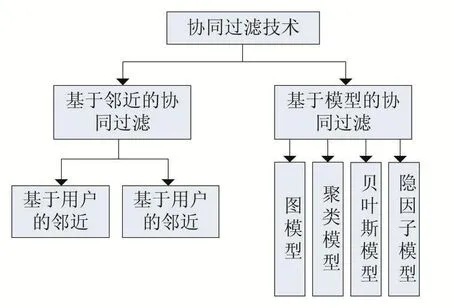
圖1
2 研究?jī)?nèi)容
2.1 模型框架

圖2
算法流程:
輸入:用戶數(shù)據(jù)
輸出:用戶感興趣圖書(shū)
(1)按照規(guī)則對(duì)用戶借閱記錄打分(1為最低,5為最高)。
(2)評(píng)分矩陣構(gòu)建,使用一年的學(xué)生借閱數(shù)據(jù),以用戶集合U為行,以圖書(shū)集合I為列,構(gòu)建評(píng)分矩陣A。Aij為用戶Ui對(duì)圖書(shū)Ij的打分。
(3)特征提取,使用SVD分解評(píng)分矩陣,將稀疏高維度評(píng)分矩陣降維存儲(chǔ)。獲得用戶特征矩陣和物品特征矩陣。
(4)尋找鄰居,使用KNN算法,基于歐氏距離,尋找用戶Ui的2k個(gè)鄰居。
(5)優(yōu)化鄰居,利用修正關(guān)系后的距離公式,重新計(jì)算Ui與2k鄰居的距離,找到最近的k個(gè)鄰居。
(6)輸出推薦結(jié)果,對(duì)k個(gè)鄰居借閱書(shū)目使用SVD預(yù)測(cè)打分,按打分高低輸出前m個(gè)推薦書(shū)目。
2.2 SVD(奇異值分解)
現(xiàn)實(shí)生活中大部分矩陣都不是方陣,方陣可以使用特征值分解來(lái)描述它的重要特征,對(duì)于普通矩陣,我們使用奇異值分解來(lái)描述其重要特征。

我們假設(shè)A是一個(gè)N×M的矩陣,分解后的U就是一個(gè)N×N的方陣(U里面的向量被稱為左奇異向量),Σ是一個(gè)N×M的矩陣(除對(duì)角線元素以外的元素都是0,對(duì)角線上的元素稱為奇異值),VT(V的轉(zhuǎn)置)是一個(gè)N×N的矩陣,V里面的向量稱為右奇異向量。
我們將一個(gè)矩陣A的轉(zhuǎn)置乘A,將會(huì)得到一個(gè)方陣,我們用這個(gè)方陣求特征值可以得到:

Vi就是右奇異向量,此外:
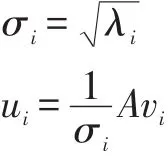
σ是奇異值,u是左奇異向量。奇異值σ跟特征值類似,在矩陣Σ中從大到小排列,而且σ的減少特別的快,在多數(shù)情況下,前10%甚至更少的奇異值的平方和就占了全部奇異值平方和的90%以上了。也就是說(shuō),我們也可以用前r個(gè)奇異值來(lái)近似描述矩陣:

右邊的三個(gè)矩陣相乘的結(jié)果將會(huì)是一個(gè)接近于A的矩陣,r越接近于n,則相乘的結(jié)果越接近于A。而需要保存這三個(gè)矩陣的存儲(chǔ)空間,要遠(yuǎn)遠(yuǎn)小于原始矩陣A的存儲(chǔ)空間。
2.3 KNN回歸算法
KNN算法:對(duì)于任意的n維輸入向量,其對(duì)應(yīng)于特征空間一個(gè)點(diǎn),輸出為該特征向量所對(duì)應(yīng)的類別標(biāo)簽或者預(yù)測(cè)值。它實(shí)際上的工作原理是利用訓(xùn)練數(shù)據(jù)對(duì)特征向量空間進(jìn)行劃分,并將其劃分的結(jié)果作為其最終的算法模型。
對(duì)新來(lái)的預(yù)測(cè)實(shí)例尋找K近鄰,然后對(duì)這K個(gè)樣本的目標(biāo)值去均值即可作為新樣本的預(yù)測(cè)值。

2.4 基于關(guān)系的修正距離
對(duì)于用戶特征矩陣Um*n,m為用戶數(shù)量,n位特征維度。可以使用KNN獲得用戶u和v是相似用戶,但這樣不能很好地挖掘出用戶之間的興趣關(guān)系。向量g=u-v可以表示兩個(gè)用戶之間的興趣差異關(guān)系,g⊥表示g在其余(n-1)個(gè)特征維度上差異向量(為可視化方便,將(n-1)維看做1個(gè)軸,見(jiàn)圖3)。可見(jiàn),兩個(gè)用戶只應(yīng)該在g上存在差異,而與g⊥的距離應(yīng)該相同。通過(guò)以下方程可以變換:

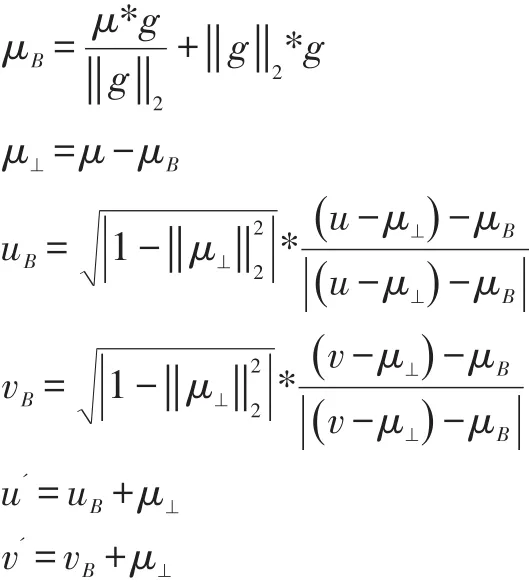

圖3

圖4
經(jīng)過(guò)變化后的u'和v'在g⊥上具有了相同距離(圖4),而只在g上存在差距。使用余弦相似度計(jì)算用戶與關(guān)系g的差距:

3 實(shí)驗(yàn)
隨機(jī)從用戶中抽取一名,編號(hào)為6334。對(duì)其進(jìn)行圖書(shū)推薦。首先使用KNN模型獲得其10個(gè)鄰居,編號(hào)分別為:
[11,104,164,195,228,245,256,291,352,373]
這里設(shè)定關(guān)系為用戶6334與其10個(gè)鄰居差值的平均值,即:

使用關(guān)系距離修正模型重新計(jì)算相鄰用戶,其前5個(gè)鄰居編號(hào)為:
[291,104,164,373,245]
待評(píng)分書(shū)目集合是這5個(gè)鄰居的借閱書(shū)目集合與該用戶借閱書(shū)目集合的差集。
最后使用SVD模型對(duì)待評(píng)分書(shū)目集合打分,按高分排序,如表1所示。

表1
4 結(jié)語(yǔ)
在如今信息超載的時(shí)代里,推薦系統(tǒng)已經(jīng)成為現(xiàn)代信息社會(huì)人們獲取信息的重要技術(shù)手段,可以幫助人們獲取到真正感興趣的信息,本文提出了在奇異值分解和KNN基礎(chǔ)上修正關(guān)系的綜合推薦方法,提高了基于協(xié)同過(guò)濾推薦的推薦精度,能更深挖掘出讀者潛在的閱讀需求。
本文選取了本校1年的借閱數(shù)據(jù),隨著數(shù)據(jù)規(guī)模的擴(kuò)大,推薦準(zhǔn)確率也會(huì)相應(yīng)提高,但對(duì)于更大規(guī)模數(shù)據(jù)的處理,如何增加更多用戶行為,就成為了我們接下去的研究工作。
猜你喜歡
數(shù)學(xué)小靈通·3-4年級(jí)(2024年2期)2024-05-15 02:02:28
世界科學(xué)技術(shù)-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創(chuàng)業(yè)家(2015年10期)2015-02-27 07:55:08
創(chuàng)業(yè)家(2015年10期)2015-02-27 07:54:39
