一種基于合作關系的陌生人推薦系統
2019-03-02 02:35:24李卓華黃翔
現代計算機 2019年2期
關鍵詞:用戶
李卓華,黃翔
(佛山科學技術學院電子信息工程學院,佛山 528225)
0 引言
科技的發展改變了人們的生活方式,一些具有代表性的社交網站已成為影響力巨大的信息平臺。社交網絡上的用戶和信息出現爆炸式增長,要找到感興趣的內容變得越來越困難。為幫助人們快速準確地找到自己想要的資源,推薦系統應運而生[1]。它對于緩解信息過載、重建用戶關系非常有效,因此在社交網絡中得到了廣泛應用,并主要用于向目標用戶推薦好友(相同興趣或愛好的其他用戶)。但目前用來解決陌生人推薦的系統,尤其是應用在一些用戶與用戶之間有明顯的合作需求的社區平臺中(如職場社交、創業社交、購物社區等),推薦系統得出的推薦結果不盡如人意。
1 基于合作關系的社交場景
在此類合作需求的社交場景中,用戶具有較為明確的社交目的,通常需要其他用戶來協助解決某一特定的需求。以創業社交中的組建團隊為例,為了使團隊的工作效率最大化,團隊成員之間需要各司其職,各取所長,從而通過這樣明確的供需互補促成團隊誕生。很明顯,此時特別強調用戶的雙向匹配程度,既要推薦符合該需要的潛在用戶加入團隊并合作,還要被推薦用戶能滿足相應團隊及成員的某一方面需求,雙方的供應與需求能互相匹配。
同樣的,在其他的基于合作的社交場景中,需求都強調合作關系,如職場求職的職位匹配、創業事務的發布與完成,等等。
2 現有研究
傳統的推薦算法比較成熟,但多應用于分析用戶興趣偏好或需求推薦的資源,如商品、電影、音樂等。如文獻[2]提出的協同過濾推薦算法通過計算目標用戶的鄰近用戶集合來預測真實評分,達到推薦目的;文獻[3]提出基于內容的推薦方法嘗試推薦與用戶評分高的項目相似的資源。傳統的推薦算法主要用于對物品的推薦。與傳統算法推薦目標不同的是,社交場景下的推薦算法的目標是用戶集合,傳統推薦技術不能在此類場景下直接應用。
Lo等[4]提出根據互動次數衡量用戶間的親密度,互動次數越多說明關系越好。Chin[5]則根據任意兩個用戶間手機交互的次數來進行推薦。這也是Facebook好友推薦系統“People You May Know”的一種典型算法基礎。它強調,將有緊密社交關系的用戶同社交網絡中沒有聯系的用戶區分開來,但其實驗結果表明,該類推薦算法的推薦結果中陌生人的比重較低。
另外,Shen等[6]根據用戶關注過的Blog分析出用戶的興趣模型,由模型計算興趣相似度進而發現潛在好友。Zheng等[7]則是根據用戶去過的地方構建興趣模型。實驗結果表明,該推薦方法向用戶推薦的好友反映了用戶具有相同或相似的興趣,對于用戶通過社交網絡認識新朋友有較好的效果,常適用于基于興趣社交的社交場景。
通過分析發現,現有的應用于社交場景的推薦策略以用戶的社交行為為依據,提出了多種推薦方法,歸納為:
(1)基于社交關系的推薦
挖掘與被推薦用戶社交行為密切的用戶,核心思想是如果好友推薦結果中有與被推薦用戶有一定聯系的用戶,則推薦的結果更有可能被接受。
(2)基于興趣關系的推薦
致力于尋找社交平臺上興趣愛好相似的用戶。通過用戶的一系列關鍵詞,建立用戶的向量表示,計算每個用戶向量之間的相似度來衡量用戶的相似程度。
此兩類推薦方法在各自特定場景中能取得較好的推薦效果,但在處理基于合作關系的社交場景的推薦問題時有以下的不足:
(1)推薦不準確。現有的推薦方法依據的是相似性度量,然而在基于合作關系的社交場景中,用戶更加關心那些能滿足自己某一特定需求的用戶[8],若只考慮用戶之間的相似性,顯然結果是不理想的。
(2)單向的推薦容易造成垃圾信息。現有的推薦方法只是把被推薦人單向性地推薦給目標用戶,沒有考慮被推薦的用戶是否會對目標用戶感興趣,而合作關系的確立是雙向的[9],單向性的推薦容易造成推薦的不準確。
針對傳統的從社交或興趣單一角度進行好友推薦的方法存在的局限性,本文綜合考慮用戶供應與需求的數據匹配,提出一種相互吸引度來改進社交相似度的新算法。
3 推薦算法的實現
3.1 算法框架
系統實現的框架包括三部分:數據采集、數據分析、結果呈現。其中,數據采集,又分為目標用戶的供應數據和需求數據。供應數據就是目標用戶可以提供的資源,這里的資源可以是具體的物品,也可以是服務或是技能等,這些數據是目標用戶根據自己的實際情況主動去編輯輸入的,這部分功能稱之為供應數據獲取模塊。而目標用戶的需求數據,是指用戶希望在平臺內獲得的資源,要通過用戶的使用來隱性獲取,例如用戶的搜索,瀏覽等記錄[10],這部分功能為需求數據獲取模塊。
綜上所述,整個算法框架概括如圖1所示。
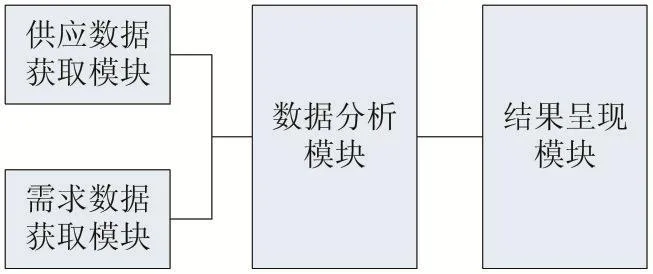
圖1 算法框架圖
3.2 具體實現
本算法采用基于雙向匹配的指數來計算推薦結果,即通過供應數據和需求數據計算用戶與用戶之間的相互吸引程度。具體的技術方案如下:
(1)服務器通過用戶所能提供的資源以及其他用戶對其評價,獲得用戶的供應數據;同時,服務器通過跟蹤分析用戶的搜索和瀏覽歷史記錄,獲得用戶的需求數據,并建立對應的供應矩陣和需求矩陣。獲得的用戶供應數據和需求數據,通過數據庫等存儲引擎進行存儲。
(2)已獲得的供應數據與需求數據,采用了不同的數據獲取規則。如用戶的供應數據中,如果用戶所能提供的資源是通過評分來衡量其權重,其評分是有數值上限的,而用戶的需求數據,如果是通過用戶瀏覽某資源的次數來衡量用戶對該資源的需求權重,其瀏覽次數是沒有數值上限的。所以需要在兩種數據構成的矩陣中進行數值標準化。參考文獻[11]給出數值標準化的公式:
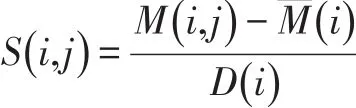
(3)利用數值標準化后的供應矩陣和需求矩陣,設X和Y分別表示用戶u的需求數據構成的矩陣和其他用戶的供應數據構成的矩陣。當其他用戶的供應矩陣與用戶u的需求矩陣相似度高,說明其滿足用戶u的需求的概率就大,對用戶u的吸引度高。計算用戶u的需求數據和其他每個用戶的供應數據的Pearson相關系數,記為其他用戶v對u的吸引度Att(u,v)。其中v泛指其他的任一用戶,且v屬于除目標用戶u的其余用戶集合R。
所述Pearson相關系數的計算公式如下[12]:
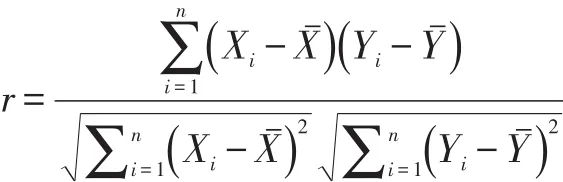
其中,Xi表示用戶對第i個資源的需求指數,Yi表示用戶對第i個資源的供應指數,Xˉ表示需求指數的和的平均值,Yˉ表示供應指數的平均值。
(4)上述v對u的吸引度Att(u,v)范圍為[-1,1],在該范圍內設定閾值k,對u的吸引度大于閾值k的用戶組成u的最近鄰集合設為D。
(5)利用上述供應矩陣和需求矩陣,計算用戶u的供應數據和u的最近鄰集合D中每個用戶的需求數據的Pearson相關系數,記為u對最近鄰中的用戶的吸引度Att(d,u),其中d屬于D且D包含于R。
(6)為了滿足雙向匹配的原則,用戶u與用戶d應滿足供需互補的關系,這樣能在最大程度上促進合作關系的確立。計算用戶u與用戶d的相互吸引度Mat(u,d),計算公式如下:
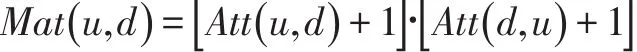
(7)選取相互吸引度最高的N個用戶進行相互推薦。
4 實驗分析
為評估本文提出的基于雙向匹配的推薦算法的性能,本節進行對比實驗。實驗使用的數據集來自2012年國際知識發現與數據挖掘競賽(KDDCup)公開的騰訊微博數據[13],其中包括:用戶關注關系、用戶社交行為、用戶關鍵詞。
實驗中,為進一步模擬社交環境,對原數據集進行了信息過濾,將用戶社交網絡數據中沒有用戶關鍵詞數據的用戶過濾掉,最終留下6095個用戶來模擬一個小型社交網絡,并作為實驗數據集。本節評估推薦列表長度N取值分別為{5,10,15,20}、本文算法的閾值k取值為0.4時不同算法的各指標的平均值。閾值k在實際使用中隨數據集的不同而不同,可通過實驗確定最佳值。從實驗數據集中隨機抽取100名用戶作為待生成推薦列表的用戶。
在實驗數據集中,記錄有每個用戶的關注關系、社交行為和關鍵詞。在item.txt中,以(用戶ID,用戶類別,用戶關鍵詞ID)三元組的形式記錄了從用戶個人資料提取的信息(如圖2),我們將用戶資料中提取的關鍵詞ID作為用戶的供應數據,在供應矩陣中將對應元素置1。

圖2 用戶供應數據
從圖2用戶提取的數據在供應矩陣中,表示如圖3所示。

圖3用戶供應矩陣
在user_key_word.txt中,以(用戶ID,用戶關鍵詞)二元組的形式記錄了從用戶所發微博提取的信息(如圖4),其中用戶關鍵詞的每一項都是“關鍵詞ID:權重”的形式,權重越大,用戶對該關鍵詞的興趣越強。我們將用戶所發微博中提取的關鍵詞作為用戶的需求數據,在需求矩陣中將對應元素置為該關鍵詞的權重。
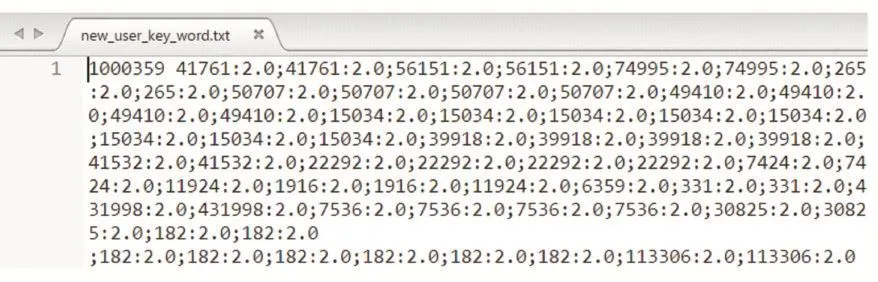
圖4用戶需求數據
從圖4用戶提取的數據在需求矩陣中,表示如下圖5所示:

圖5 用戶需求矩陣
同時,本文采用如下方法來計算用戶間相互吸引度:
(1)在用戶關鍵詞數據中,以用戶個人資料提取的關鍵詞作為用戶的供應數據,在供應矩陣中將對應元素置1;
(2)在用戶關鍵詞數據中,以用戶所發微博提取的關鍵詞作為用戶的需求數據,在需求矩陣中將對應元素置為該關鍵詞的權重;
(3)假設為用戶u生成推薦列表,則用戶u稱為目標用戶,其他每個用戶稱為候選用戶。處理新的候選用戶時,利用供應矩陣和需求矩陣計算候選用戶與目標用戶的相互吸引度;
(4)將相互吸引度最高的N個用戶推薦給目標用戶。
對于本文算法提供Top-N列表的推薦系統,我們通過實驗,主要從查準率、查全率、F指標等三個常用算法指標上進行分析對比。其中:
查準率(Precision):為給某用戶u生成的推薦列表中,用戶u關注的人的數量與推薦中用戶總數的比值[14],本實驗中推薦用戶總數即為推薦列表的長度。
查全率(Recall):為給某用戶u生成的推薦列表中,用戶u關注的人的數量與用戶u實際關注的人的總數之比值[15]。
F指標(Fmeasure):為查準率和查全率的調和平均數[14]。
實驗中,對比基于Jaccard相似度的算法[16]和基于粉絲數的算法[17]這兩種推薦算法,對本文新提出的基于雙向匹配的推薦算法進行綜合評估。圖6-8分別對比了三種推薦算法的各個指標。
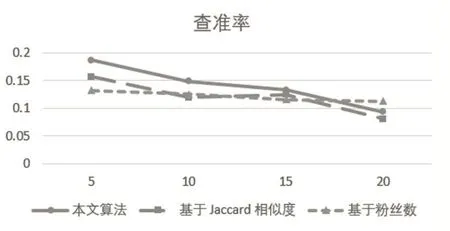
圖6 三種算法查準率對比
從圖6可以看出:①隨著推薦列表長度N的增長,各算法推薦的準確率在下降,查準率曲線整體呈下降趨勢;②本文算法在查準率比基于Jaccard相似度和基于粉絲數的算法要高;③在推薦列表長度N=20時,基于粉絲數的推薦算法查準率高于本文算法,這主要是由于用戶關注列表中熱門用戶的分布較均勻,導致不管推薦列表增長多少,增長的部分總會存在一部分熱門用戶,從而有利于基于粉絲數的推薦算法,這也解釋了為什么該算法的查準率曲線下降較為平緩。
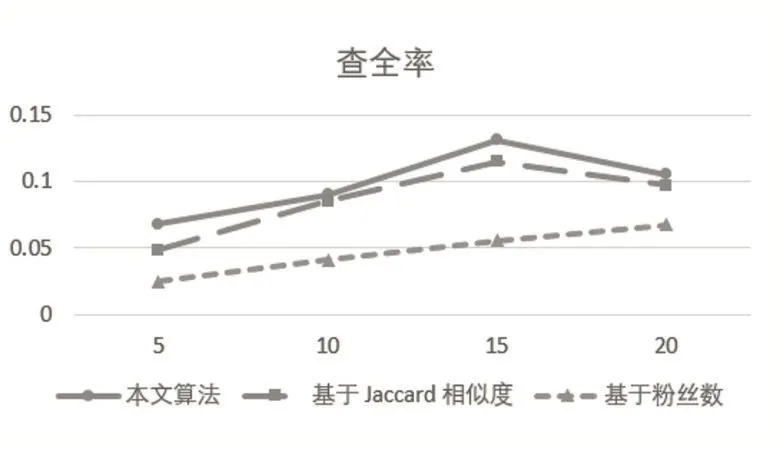
圖7 三種算法查全率對比
從圖7可以看出:①本文算法和基于Jaccard相似度的算法比基于粉絲數的算法查全率要高;②隨著推薦列表長度N的增長,查全率曲線總體呈上升趨勢。
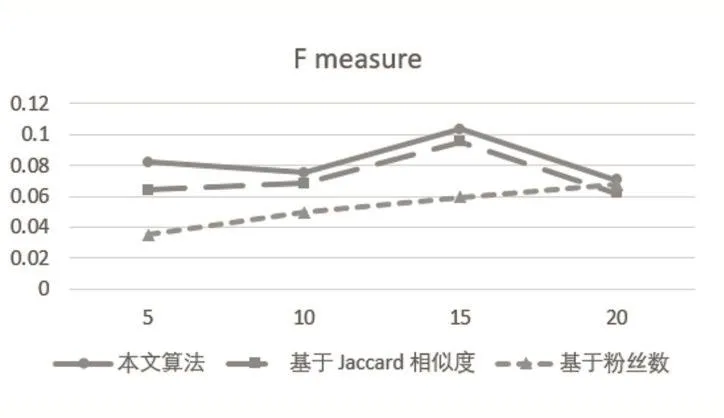
圖8 三種算法F指標對比
從圖8可以看出:①本文算法和基于Jaccard相似度的算法的綜合表現優于基于粉絲數的算法;②在推薦列表長度N=20時,基于粉絲數的算法的綜合表現優于基于Jaccard相似度的算法,但仍劣于本文算法。
5 結語
通過上一節實驗的綜合對比,可以看出:從查準率、查全率、F指標三方面分析,本文提出的新算法均優于基于Jaccard相似度的算法和基于粉絲數的算法。其主要原因是由于本文算法綜合考慮了用戶間的供需關系和興趣參數。此新算法特別適用于用戶供需關系明確的平臺的推薦系統中,通過供需合作關系的參數重構,解決了當前社交網絡的用戶推薦技術主要依據的是用戶之間的相似性的推薦弊端,提高了用戶的社交價值,具有較高的實用性。
猜你喜歡
車主之友(2022年4期)2022-08-27 00:58:26
知音·下半月(2022年5期)2022-05-23 23:17:04
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年5期)2016-11-28 09:55:15
非公有制企業黨建(2016年1期)2016-07-19 13:02:51
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
衛星與網絡(2016年12期)2016-02-05 09:23:23
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
