基于回歸CNN的煙葉近紅外光譜模型研究?
2019-02-27 08:31:00宗倩倩丁香乾宮會麗
計算機與數字工程 2019年2期
宗倩倩 丁香乾 韓 鳳 宮會麗 張 磊
(1.中國海洋大學信息科學與工程學院 青島 266100)(2.山東煙草研究院有限公司信息技術研究中心 濟南 250001)
1 引言
農產品、藥材及煙草等原料主要化學成分含量很大程度上能夠表征其內在品質,對它們的選種、種植及加工過程具有關鍵的指導意義,因此原料化學成分定量預測的準確性至關重要。近紅外光譜分析技術因其快速、樣品非破壞性、無污染等優點得到迅速發展,煙草行業利用此技術實現了對煙葉原料化學成分的定量分析[1~5]。
近紅外定量分析方法主要有主成分回歸(PCR)、多元線性回歸(MLR)、偏最小二乘回歸(PLS)、支持向量機(SVM)、人工神經網絡(ANN)等,采用這些方法進行煙葉化學成分的定量分析,在應用中取得了很好的進展和成就,但是隨著應用的逐漸深入,這些方法也暴露出許多問題,諸如:MLR會遇到共線性問題和輸入變量個數的限制問題、PCR不能辨別噪聲或有效信息且運行速度較慢、PLS不能有效處理非線性問題、ANN模型復雜,容易出現“過擬合”現象等。為了構建煙葉近紅外光譜與化學成分間復雜關系的模型,國內外研究學者提出了將線性與非線性方法混合使用的混合算法。例如,陳達等[6]提出了基于PLS和ANN的混合算法的非線性模型,結果表明該非線性模型得到了較高的預測精度;李世勇等[7]采用最小二乘支持向量回歸(LSSVR)法和PLS,以192個煙葉數據來訓練模型,分別建立了煙葉總糖含量的近紅外預測模型,并用95個煙葉樣品去測試模型性能,結果表明LSSVR具有更好的準確度和穩健性;L.J.Janik等[8]利用PLS與NN相結合來建立定標模型,把相對較少的PLS主成分得分矩陣當做神經網絡的輸入,預測值當做目標函數,結合了PLS定量建模的魯棒性和NN非線性逼近的能力。混合算法中,與PLS相結合的多是諸如SVM,ANN的淺層結構算法,其局限性在于不能完全考慮特征的空間分布,而且不能得到更深層次的特征表示,針對復雜問題其泛化能力受到一定制約。
為了能夠更深層次挖掘出原料近紅外光譜中對化學成分定量分析起關鍵作用的特征信息,本文利用卷積神經網絡能充分考慮特征的空間分布,減少數據維數并能夠在保持光譜數據空間拓撲結構的基礎上學習光譜數據的更深層次的抽象特征的優勢,提出了基于回歸的卷積神經網絡算法。它利用CNN來近似抽象近紅外光譜數據的分布,然后逐層提取、逐漸抽象近紅外光譜對應預測指標的本質特征,更深層次挖掘對應吸收峰表征的信息,并將CNN頂層的分類器改為回歸器,以構建定量回歸預測模型,預測性能得到了進一步提升。
2 基于回歸的卷積神經網絡算法
2.1 卷積神經網絡
CNN在圖像識別領域[9~10]取得輝煌成就的關鍵原因是其在特征提取方面的突出優勢[11],其結構圖如圖1所示,其中卷積層和池化層構成的特征提取器是重要結構。它提取特征并不采用人們的直覺,而僅僅依賴于訓練數據基于反向傳播的訓練過程,該過程旨在自動地學習過濾器的權重,使得它們能夠從輸入數據中提取更加抽象和本質概念,進一步提高預測準確性。
CNN基于三個重要的思想:局部感知、權重共享、空間/時間采樣。卷積層通過由訓練參數組成的不同卷積核與輸入數據做卷積操作來提取不同特征,在該操作過程中參數是共享的,不僅減少了參數的數量,而且提高了網絡的泛化能力。池化層對卷積層的輸出特征數據進行子抽樣,若CNN中池化層卷積核大小為k,池化操作是將卷積層的輸出特征數據縮小(k*k)倍,一般選用max pooling和mean pooling兩種池化方法。

圖1 傳統的卷積神經網絡結構圖
卷積層卷積操作如式(1)所示:

經過一系列卷積和池化操作得到的特征數據將經過全連接層與輸出層相連,全連接層的操作為式(2)所示:
經過一系列卷積和池化操作得到的特征數據將經過全連接層與輸出層相連,全連接層的操作為式(2)所示:
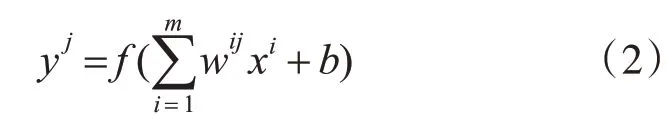
式中:yj和xi分別代表n輸出向量的第j個神經元和m維輸入向量的第i個神經元,w是一個m*n的權重矩陣,b為偏置,f()采用Sigmoid函數。
CNN采用梯度下降法來更新權重的,其核心公式為誤差代價函數對參數的梯度,稱為靈敏度。卷積層的靈敏度為
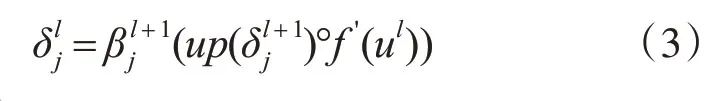
式中:βj為卷積核的值,up為上采樣操作,跟選的池化方法相關,ul=Wlxl-1+bl。
2.2 改進的回歸卷積神經網絡
模式識別中,CNN相對于傳統方法的顯著優勢在于提取特征的同時可以減少數據維數并在網絡結構中分類。CNN的優勢可以用來處理具有高維、高冗余及非線性等特征的光譜數據。通常,在以圖像作為輸入的CNN結構中,由于像素的強度經常是臨近像素的均值,并且接近均值的概率很大,所以在卷積層后邊加了池化層。但對于光譜數據高噪、譜帶歸屬困難等特征,使得光譜數據并無明顯的鄰域特征,所以改進的CNNR算法移除了池化層。
CNN通過在網絡結構中設置池化層卷積核大小壓縮特征數據,若將池化層卷積核設為1,那么經過池化操作對輸入特征數據大小沒改變,但是會使網絡運行時間延長,所以改進的CNNR算法直接創建只有卷積層和全連接層的網絡,并把輸出層函數改為Sigmoid函數。由于池化操作僅使輸入特征數據的維度變小而不改變樣本數量,所以去掉池化層并不影響網絡各層的操作。
CNNR依然采用反向傳播算法來調整參數大小,與傳統的CNN不同的是,反向傳播過程中由于CNN卷積層后邊是池化層,所以會先在池化層的特征數據上進行采樣,使得與前邊卷積層特征圖大小一致,先按式(3)計算靈敏度再調整權重和偏置。但改進的CNNR算法沒有池化層,無需進行上述采樣操作而直接計算靈敏度,據式(3)將卷積層的靈敏度改為式(4),且卷積核的權重以及偏置更新公式為式(5)和式(6):

式中:(pil-1)uv是xli-1做卷積操作時與kilj逐個元素相乘所得值,u、v是位置信息。
傳統CNN算法由于運行時間長以及對內存要求過高的問題在實際應用中存在困難,主要原因是完全連接層占據了90%的權重,卷積層占據了90%以上的運行時間[12],這意味著如果想要最小化運行時間和存儲空間,那就必須將完全連接層和卷積層的數量最小化。受到以上所述的啟發,本文將采用含有兩層卷積層和一層全連接層的網絡架構,考慮到回歸問題具有特殊性,它需要較大的卷積核來提取整體數據的特征,通過多次實驗發現第一、二層卷積層的卷積核大小分別為10和6,卷積核個數分別為20和40時不僅運行時間達到最小,而且擬合效果較好。
傳統的神經網絡采用反向傳播算法作為訓練準則的核心之一,這很容易陷入局部最優[13]。當神經網絡架構變深時,這種缺點變得很明顯,因為在這種情況下存在大量要優化的參數。緩解深架構神經網絡局部最小困境的一種有效的方法是將參數初始化到盡可能高的程度[14],如果參數被初始化非常接近搜索空間中的最優狀態,則找到全局最優的機會大大增加[15]。為使網絡最大可能找到全局最優,開始時使卷積核權重由服從[-0.1,0.1]上的均勻分布函數隨機產生,偏置由Rand(0,1)函數隨機產生,學習率設為1。
改進的回歸卷積神經網絡的訓練過程具體步驟如下:
step 1:建立改進的回歸卷積神經網絡并初始化該網絡涉及的參數,包括網絡層數、卷積核的權重W、偏置b及網絡學習率r,迭代次數等參數;
step 2:取經過預處理的訓練樣本的光譜數據x及其對應的煙葉化學成分的實測值yi輸入到網絡,對X執行操作1,得到卷積層的輸出特征圖;
step 3:經過一系列卷積操作把輸出特征圖即學習到的深層次的特征連接成一個矢量饋送到全連接層執行操作2,然后將輸出值作為回歸函數的輸入,對訓練樣本進行預測并得到它們的預測值
step 4:計算n個訓練樣本的誤差,公式為

step 5:據式(5)和式(6)來調整卷積核的權重和偏置;
step 6:判斷迭代次數是否超過最大迭代次數,如果沒有超過,返回執行step 2~5,若超過,保存權重和偏置并退出訓練過程。
3 實驗仿真分析
為了驗證基于回歸的卷積神經網絡算法在原料化學成分近紅外光譜模型方面的有效性,本文應用國內某煙草企業提供的396個煙葉樣品,采用基于回歸的卷積神經網絡算法構建煙葉近紅外光譜對化學成分的預測模型,并對所建的總糖、總煙堿及氯指標模型進行了測試與分析。
3.1 樣品數據
本研究中的396個煙葉樣品數據來自山東、云南、貴州和廣西四個產區,并盡可能涵蓋企業卷煙配方使用的煙葉原料范圍,各檢測指標值均由連續流動分析法檢測得到,總糖數據分布在15%~38%之間,總煙堿主要分布在0.9%~4%區間內,氯離子分布在0.2%~1.6%之間。以Kennard-Stone方法將樣品數據進行劃分,從中選取300個煙葉樣品來構建CNNR定量預測模型,用其余的96個煙葉樣品作為外部測試集,驗證模型的預測性能。供試樣品情況如表1所示。

表1 供試樣品詳細信息
3.2 實驗儀器與分析軟件
本文實驗采用的儀器是AntarisⅡFT-NIR分析儀(美國ThermoFisher公司分子光譜部),配備積分球漫反射采樣系統,InGaAs檢測器。設置烘箱溫度為40℃,將本研究中的396個樣品放在烘箱中烘干4h,取出樣品直接粉碎研磨,過篩60目,裝入密封袋中密封并在常溫下避光保存24h。在溫度18℃~21℃的條件下,取每份煙末樣品15g于干凈的樣品池中,輕輕放置壓樣器,把每個樣品放置在上述分析儀中采用漫反射方式重復掃描三次,并取三次的平均值當做最后的實驗光譜數據。
Matlab 2010a和Unscrambler9.7為數據分析工具。應用Unscrambler軟件進行光譜解析,基于Matlab 2010a構建CNNR算法和PLSR算法的煙葉化學成分定量預測模型。
3.3 光譜數據預處理方法
由于近紅外光譜中含有許多對光譜信息產生干擾的冗余信息,為了提高模型預測的準確性,模型構建前必須對光譜數據進行預處理,本文采用了平滑,求導,標準歸一化和譜段選擇這幾種技術。
由于近紅外光譜中有很多重疊譜峰,因此建模前需要采用求導處理來消除基線平衡、漂移的干擾,但導數處理也會放大光譜信號,噪聲信號也會被放大,所以對光譜求導后,需要對光譜數據采用平滑處理來減弱乃至消除譜圖噪聲、提高信噪比,本文采用Savitzky-Golay算法[16]。為了消除指標之間的量綱影響與變量自身變異大小和數值大小的影響,需要對光譜數據做標準歸一化處理。將做過上述數學預處理的光譜進行譜段選擇再進行建模,可獲得理想效果。
3.4 模型評價方法
預測模型通過訓練集交叉驗證均方根誤差RMSECV、測試集均方根誤差RMSEP、平均相對誤差MRE以及實際檢測值與模型預測值的相關系數R來定量評價。一個好的模型應該具有較高的R值,較低的RMSECV值、RMSEP值和MRE值。它們計算方法如下所示:

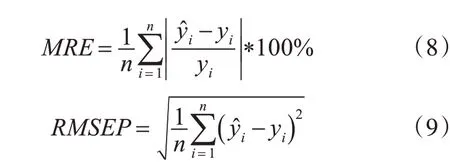
式中:y?i是模型預測值,yi是實際檢測值,n是樣本個數,
3.5 結果與分析
3.5.1 內部交叉驗證
為了從光譜數據中提取充分有效的信息,盡可能消除導數的影響,必須進行預處理。在本文中,一階導數(1st derivative),二階導數(2nd derivative),平滑點數,標準規范化向量(SNV)和不同譜段的選擇來實現CNNR預測模型構建的組合優化過程。以總煙堿為例,以x-loading圖來選取建模譜段。

圖2 總煙堿的x-loading圖
根據圖2選取4400-4200cm-1為總煙堿的建模譜段,選取譜段后對光譜運用各種預處理組合方法進行建模,多次實驗對比結果如表2所示。
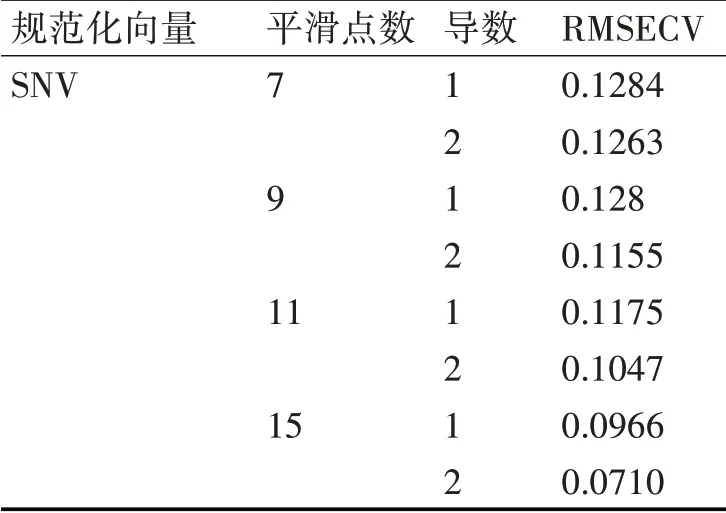
表2 總煙堿的預處理組合實驗對比結果表
從表2可以看出,固定規范化向量和平滑點數不變時,對光譜采用二階導數時,模型的RMSECV值較小,而且當平滑點數為15,RMSECV達到最小。
采用相同的思路分別對總糖和氯離子選擇最佳模型預處理組合方法組合,比較RMSECV的大小得出CNNR最佳模型的不同預處理組合方法結果如表3所示。

表3 CNNR最佳模型的預處理組合方法
采用最佳的預處理組合方法處理光譜數據并用設定好的CNNR各參數構建各指標的定量模型,重復進行實驗并記錄每次實驗對應的總誤差大小,當總誤差達到最小時將其視為最佳模型。在實驗過程中發現運行到5000次后總誤差趨于穩定,修改CNNR模型的迭代次數為5000次,極大程度減少了運行時間。總煙堿最好模型總誤差變化圖如圖3所示。
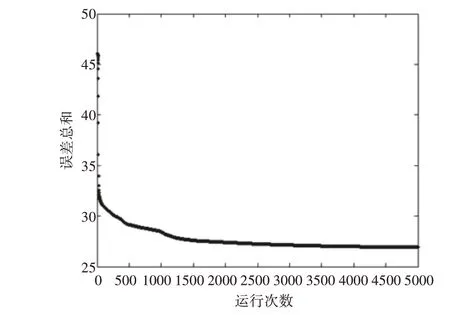
圖3 總煙堿模型總誤差變化圖
圖3顯示了總煙堿模型訓練過程中總誤差的變化趨勢。可以看出,在循環的開始階段,總誤差急劇減少,這是因為反向傳播算法為了達到最大可能性的CNNR模型參數采取了較大的步長。在訓練過程的進一步階段,訓練總誤差變化逐漸平緩,這表明網絡正在趨向收斂,到最后都降低到總誤差值穩定的程度,這時網絡已經完全收斂。
總糖、總煙堿和氯離子三個指標按照最佳參數進行建模,它們最佳模型的交叉驗證性能圖分別如圖4~圖6所示。

圖4 總糖模型交叉驗證性能圖

圖5 總煙堿模型交叉驗證性能圖

圖6 氯離子模型交叉驗證性能圖
圖4~圖6分別給出了總糖、總煙堿和氯離子構建的CNNR內部交叉驗證的真實值與預測值的散點擬合圖,橫坐標是實際檢測值,縱坐標為模型預測值,比較直觀地反映出所建模型的效果。可見,所建模型的擬合效果較理想,大部分樣品均勻分布在擬合線附近,樣品實際檢測值與模型預測值呈較明顯的線性相關。
3.5.2 外部驗證
用CNNR構建的最佳模型進行外部測試集預測,預測集的RMSEP、MRE和R對比表如表3所示。
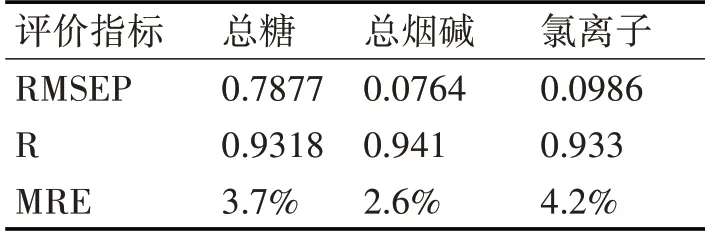
表4 CNN模型評價指標結果
從表4結果看出,CNNR對三個指標的預測結果均較好。各指標的相關系數R均大于0.93,且預測相對平均誤差MRE均小于5%,說明采用CNNR模型預測的化學值與連續流動自動分析儀的測量差異較小。CNNR模型在預測原料化學成分時能夠充分考慮光譜數據本質和抽象的信息,準確地分析原料中不同化學成分,為以后準確進行原料化學成分定量分析提供了全新技術支持,在以后的實踐中有很大的發展前景。但同時CNNR作為一種神經網絡,其計算量大導致運行時間較長,且若訓練數據過少容易出現“過擬合”的問題,所以CNN更適合處理數量多且復雜的數據。
4 結語
本文提出的作為一種深度學習的基于回歸的卷積神經網絡預測原料化學成分研究,與傳統近紅外定量建模方法相比,它在抽取原始數據更加本質和抽象特征上具有得天獨厚的優勢,經過方法有效性論證和實際數據測試均驗證了該方法的有效性,為進行原料化學成分定量分析提供了一種新思路。使用本文提出的回歸卷積神經網絡算法能夠和近紅外光譜數據有效結合,抽取的特征對光譜數據有很強的解釋能力,同時對原料化學成分有最佳綜合表達能力,提升了原料化學成分定量分析的預測精度,為原料化學成分的定量分析提供了穩定和有效的方法支撐。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
