萬有引力搜索算法的Web服務選擇?
2019-02-27 08:31:04袁博馬力
計算機與數字工程 2019年2期
袁 博 馬 力
(西安郵電大學 西安 710061)
1 引言
由于受到自然界群體現象的啟發,在過去的幾十年里,研究人員提出了多種群體智能算法,如人工蟻群算法[1],粒子群算法[2]等,它們一般通過模擬生物種群或者自然物體的客觀規律來達到尋找最優值的目的。
萬有引力搜索算法[3](Gravitational Search Algorithm,GSA)在2009年首次由伊朗克曼大學的教授Esmat Rashedi等提出。萬有引力搜索算法是一種新的啟發式智能優化算法,它是在牛頓萬有引力定律[4]及粒子間的相互作用的基礎上被提出的。
近幾年,有關萬有引力搜索算法一直是人們研究的重點,文獻[5]用萬有引力搜索算法來解決約束優化問題。為防止出現早熟現象,文獻[6]將混沌變異添加到萬有引力搜索算法中。為提高分類問題的精確度,文獻[7]提出了將GSA與SVM相結合的模型。
但GSA算法也一定的缺點:算法停滯、早熟現象以及局部最優問題,因此本文利用萬有引力搜索算法和粒子群算法相結合,并對粒子運動速度方程方程進行改進,結合實驗,所改進的算法具有較好的性能。
2 萬有引力搜索算法
2.1 萬有引力搜索算法原理
在GSA中,慣性質量大的粒子比慣性質量小的粒子運動得慢,所以物質都朝著慣性質量大的粒子運動。粒子的位置就是問題的解,當算法滿足結束的條件時,擁有最大慣性質量的粒子它的位置就代表問題的最優解。
在GSA中,設參與搜索的粒子組成的系統是獨立的,是遵循萬有引力定律及牛頓運動定律的人工制造的世界。萬有引力定律及運動定律的定義分別如下:
1)萬有引力定律:任意兩粒子彼此間均是互相吸引的,兩個粒子間引力的大小和它們慣性質量的積成正比關系,和它們間歐氏距離的平方成反比關系。但在在GSA中,我們用R代替R2,因為大量實驗結果顯示,使用R比使用R2的效果更好。
2)運動定律:任意粒子的速度都等于它此時的速度與其加速度之和。加速度都等于作用在此粒子上的外力除以其慣性質量。
2.2 萬有引力搜索算法簡介
設在一個擁有N個粒子的引力系統中,粒子i的位置是:
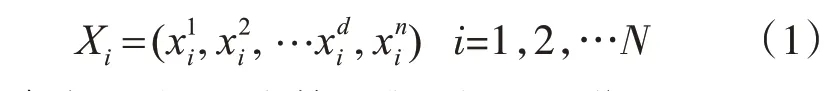
其中,xid表示粒子i在第d維空間上的位置。
由牛頓萬有引力定律可知,t時刻在第d維上粒子i受到粒子j的作用力為

其中,Mi、Mj分別表示粒子i和粒子j的引力質量,ε是一個很小的常量,Rij(t)是粒子i和粒子j在t時刻時它們之間的歐氏距離:
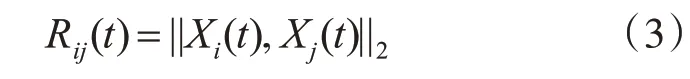
G(t)是t時刻的引力常數,其值由宇宙的真實年齡決定,G(t)的值[8]隨著宇宙年齡的增長反而會變小,它們之間的關系如下式所示:
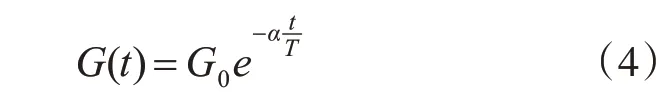
其中,G0代表在宇宙初期的萬有引力常數,一般取值為100;α為20;T為最大迭代次數。
為了讓GSA有隨機性的特點,通常給第d維空間上作用在粒子i上的萬有引力的合力設定一個隨機數,如下定義:

rand為[0,1]內的隨機數。
由運動定律可知,第d維空間上粒子i,t時刻的加速度為

GSA中設定引力質量與慣性質量相等,由適應度函數得出粒子的引力質量的定義:
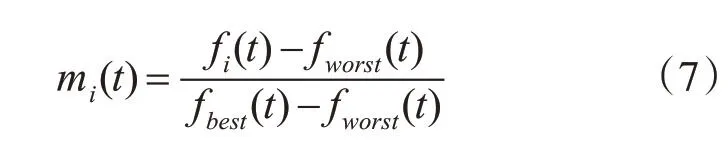
fi(t)為t時刻粒子i的適應度函數值;fworst(t)、fbest(t)分別為t時刻群體最差適應度函數值和群體最好適應度函數值;引力質量一般用單位值表示如下:
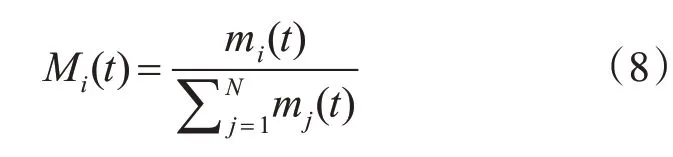
對于求最大值問題:
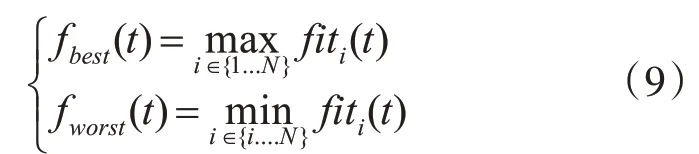
對于求最小值問題:
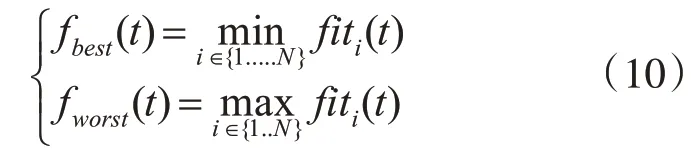
由以上可知粒子的運動速度和位置分別是:
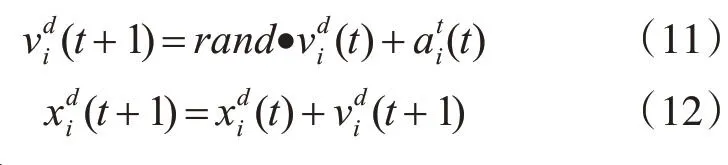
其中,rand是[0,1]上均勻分布的隨機數,GSA使用隨機數來實現其在搜索過程中的隨機性。
3 改進的萬有引力搜索算法
對萬有引力搜索算法中的速度和位置,由式(11)、(12)分析可知,GSA僅有當前的位置信息在迭代過程中起作用,由此可知萬有引力搜索算法是一種缺乏記憶的算法。從式(6)、(11)、(12)可以得知,當粒子運動至最優解或接近最優解之前,由于引力的大小與距離成反比,所以粒子的速度會不斷的增加,當粒子運動至或接近最優解時,粒子的運動速度有可能會非常快(存在隨機性),由運動學的規律可以知道,上面的情況會致使粒子在最優解周圍來回的震蕩,從而降低了算法的搜索精度。因此本文將萬有引力搜索算法和粒子群算法進行了結合并做以改進。
粒子群優化算法(Particle Swarm Optimization,PSO)是1995年由Kennedy博士和Eberhart教授提出的算法。其它的群體智能算法相類似,PSO也是一種隨機搜索的全局優化算法,當對整個群體對解空間中最優解的搜索時,僅需要粒子追隨自己及整個群體當前的最好位置移動。
粒子群算法中的粒子的運動速度和位置方程為如下式(13)和式(14):其中,rand1、rand2為區間[0,1]內的隨機數。c1,c2為正常數是學習因子也稱為加速系數,c1和c2分別是調整粒子的個體經驗和群體經驗并對粒子運動軌跡產生影響的重要參數。若c1=0,則僅有群體經驗在粒子的運動中起作用,對于復雜問題算法很容易出現局部收斂的問題。若c2=0,則僅有個體經驗影響粒子的運動,粒子之間缺乏信息交互的能力。w是慣性權重,w的作用就是為防止算法早熟收斂而產生擾動。pi為粒子i曾經歷過的最好位置即個體極值,代表個體經驗;gbest為所有粒子曾經歷過的最好位置即全局極值,代表群體經驗。
借助粒子群優化算法的優點,為引力搜索算法中的粒子增加記憶性和信息共享能力。則將萬有引力搜索算法與粒子群優化算法相結合后的粒子運動速度的式(15):
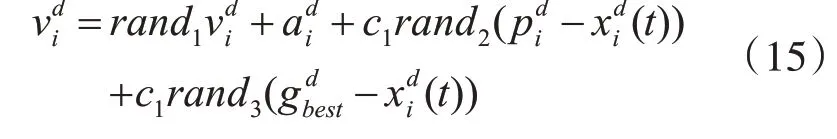
其中,rand1、rand2和rand3均為區間[0,1]內的隨機數;w1和w2均為慣性權重,可以通過調節w1和w2的值來調整粒子在運動的過程中受引力、信息共享的影響程度,顯然,當w1和w2為零時改進后的算法退化為引力搜索算法。PSOGSA的流程圖如圖1。
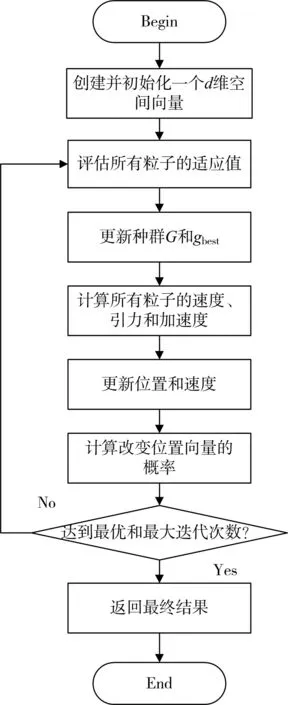
圖1 PSOGSA的流程圖
PSOGSA能緩解GSA出現的算法停滯的缺點。PSOGSA利用目前所獲得的最優解引導慣性質量大的粒子朝全局最優方向移動,而不是所有粒子都朝最優解聚集。顯然,PSOGSA也可以加快群體的整體運動,促使PSOGSA算法的尋優能力增強。
圖2用y=x2函數顯示了GSA在兩次迭代過程中粒子的運動情況。M2是一個較優解周圍的粒子向M2聚攏。如圖3所示,PSOGSA利用目前所獲得的最優解引導慣性質量大的粒子朝全局最優方向gbest移動[9]。(M1代表現在搜索所處位置)

圖2 GSA在兩次迭代過程中粒子的運動情況
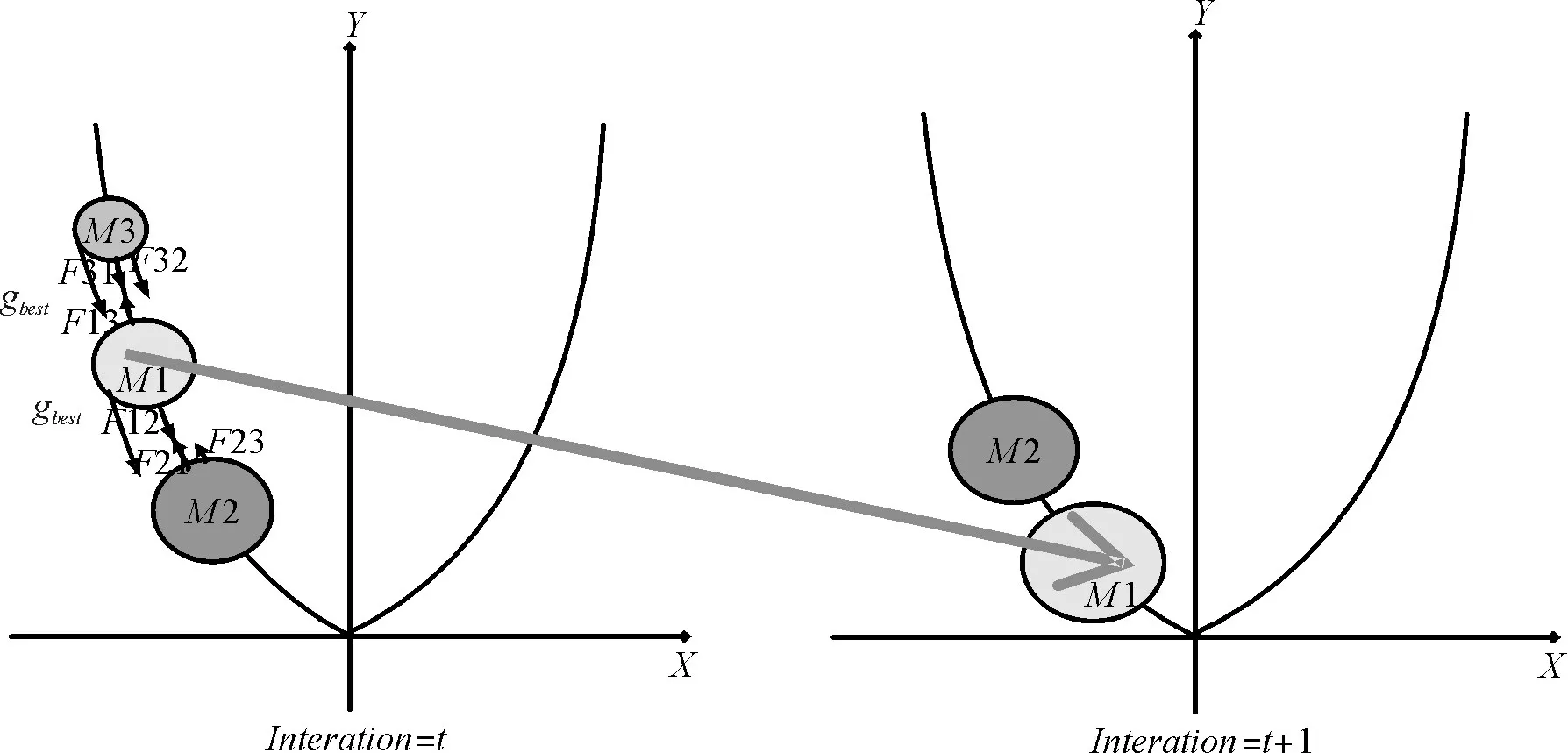
圖3 PSOGSA的兩次迭代過程中粒子的運動情況
文獻[10]通過實驗證明,PSOGSA在解決優化問題上要優于PSO和GSA。然而原始PSOGSA主要解決的是連續優化問題,但是實際中有很多優化問題都是離散的比如Web服務選擇問題和路由選擇問題。為了解決工程實際中眾多的組合優化問題,本文借鑒Mirjalili和Lewis提出的二進制PSO算法的理論對原始PSOGSA做以改進。為了讓搜索可以在離散的搜索空間內進行,需要修改位置更新式(14)。又由文獻[3]和[11]可知,改變搜索代理的位置是需要一個傳遞函數的,這個傳遞函數映射速度的值對位置狀態改變的概率。文獻[12]中例舉了許多標準傳遞函數。根據Mirjalili和Lewis提出的理論可知傳遞函數應該要保證當速度的絕對值大時,改變位置狀態的概率也就大。反之概率小。此外,傳遞函數是在[0,1]范圍內隨著速度的增加而增加的。參考文獻[3]本文將傳遞函數定義如下:

圖4是對式(16)的說明。
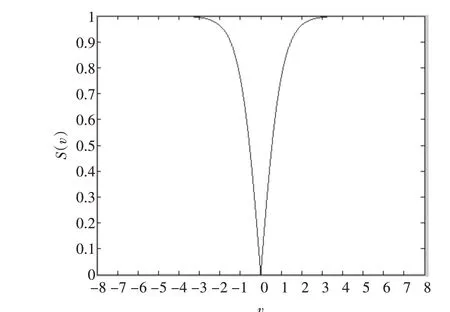
圖4 S(v)與v關系
得到S(vid(t))的結果后,搜索代理就會按照下面的規則更新位置:

由文獻[13]可知,將gbest加入到速度矢量中會減弱算法的尋優能力,為了解決這個問題,本文對c1和c2做如下變化:

由于PSO算法和GSA算法都存在收斂速度慢,容易出現停滯的現象,也就是說,粒子聚集且運動速度幾乎為零,粒子難以逃離局部極值區,從而導致算法早熟。為了避免萬有引力搜索算法與粒子群優化算法相結合后的算法出現以上問題,可以通過在進化過程中動態調整搜索空間的邊界來進行對粒子飛行位置的追蹤,當發現粒子聚集時,通過對邊界進行一定的操作和在新的搜索空間內激活停滯粒子,使粒子跳出局部區域,去尋找最優解[14]。
通過如下公式對搜索空間的左邊界進行擴展:

上面的式子中,Bdl表示d維下搜索間的左邊界,Bdr表示d維下搜索空間的右邊界;Cb代表收縮率,-cb=1-cb;Ob代表擴展率。
rand1~rand6是服從[0,1]上均勻分布的隨機數。從式(19)~(21)可以看出,通過以全局的極值點為核心在一定范圍內進行隨機收縮或擴展從而對搜索空間的邊界進行調整。若在第d維時當前的邊界被重置,則表明在第d維粒子是聚集在一起的,那么,為了增加粒子的多樣性在這時算法會隨機的挑選少量的粒子進行激活,讓其跳出局部極值的區域。
3.1 算法的主要步驟
在每次迭代結束后,算法都會執行下面的3個步驟。
1)標記當前搜索空間的左右邊界。在第d維中,查看是否有粒子跳出當前邊界[Bdl,Bdr],若有粒子跳出,則在第d維將邊界標識置為true,反之置為false。
2)在此步中,我們將分別處理搜索空間在每一維中的左右邊界。如果全局極值點和邊界的距離大于閾值ε,且在該維上邊界的標識為false,那么使用式(19)對邊界進行收縮,否則使用式(20)對邊界進行擴展;如果全局極值點和邊界的距離小于或等于閾值ε,則表示出現了粒子聚集的現象,那么使用式(21)重置邊界。
3)在此步中為了增加粒子的多樣性,我們將激活處于停滯狀態下的粒子,清除粒子的個體經驗。如果在第d維中當前的邊界被重置,那么在此時的邊界內給速度加上一個服從正態分布的隨機數,以便激活粒子。當算法得到最優解或達到最大迭代次數時算法終止。
3.2 服務場景設計與數據組織
采用在Web服務組合領域經常使用的旅游場景,作為驗證本文改進的萬有引力搜索算法在解決基于多目標優化的Web服務組合問題中的可行性和有效性。在應用場景中,服務請求者只需再提供一些非功能需求如出發日期和酒店等級等信息,作為服務提供者選擇最佳方案的依據。服務提供者就會給服務請求者返回一個最優的組合服務。該組合服務按照服務的功能需求需要4個服務類如圖5所示:訂票、訂酒店、租車和找導游服務。為每個服務類選取5個候選服務則共有20個原子服務,從服務日志中讀取這20個原子服務的歷史QoS信息,經過量綱統一和極性一致性處理,然后基于灰色系統理論對其QoS屬性值進行預測,得到各服務類中候選服務的QoS屬性預測值如表1~4所示。

圖5 旅游場景
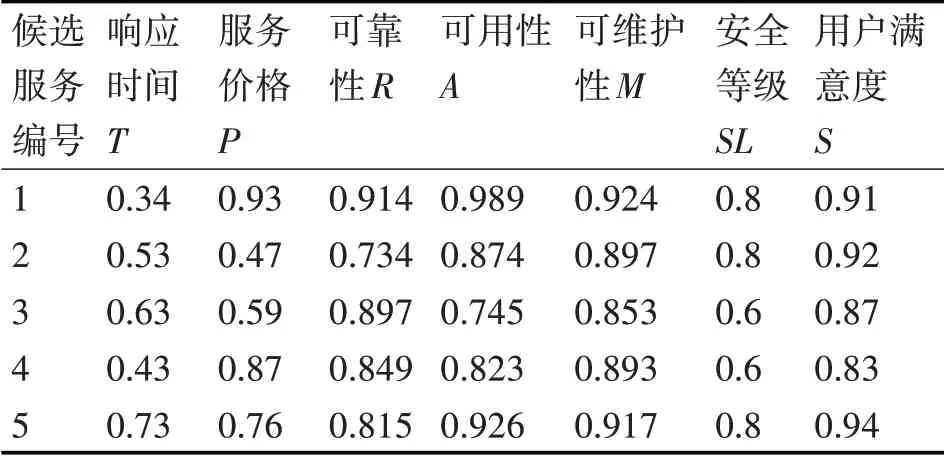
表1 訂票服務的QoS屬性預測值
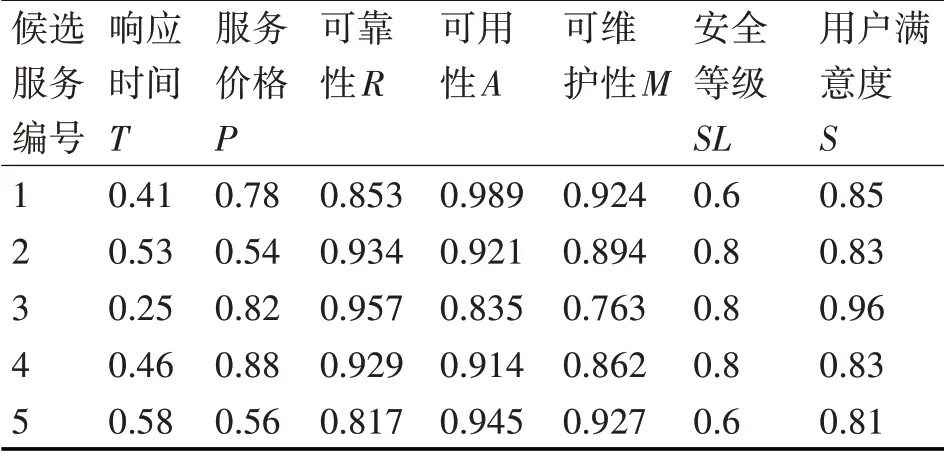
表2 訂酒店服務的QoS屬性預測值
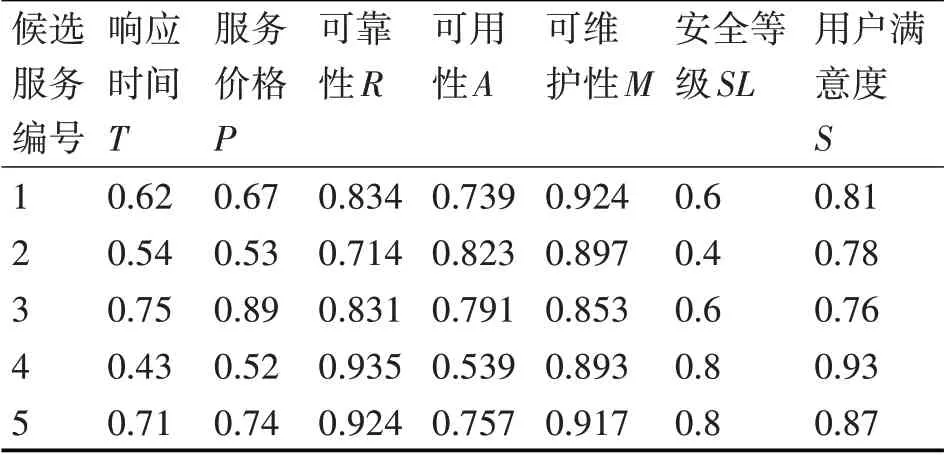
表3 租車服務的QoS屬性預測值
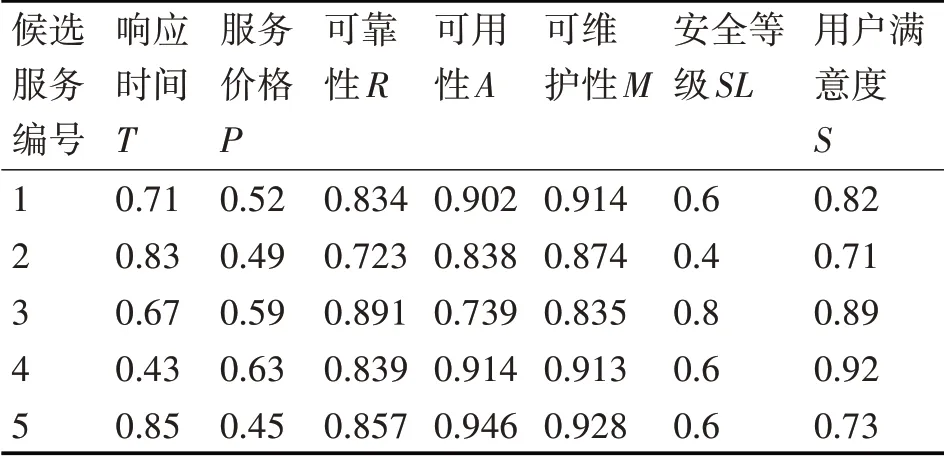
表4 找導游服務的QoS屬性預測值
根據上述表中給出的預測值,使用窮舉法得到的最優服務組合方案的序列是(1,4,5,3),最優值為0.495。得到的最優結果是用于判斷后文中用改進萬有引力搜索算法得到的結果是否優的依據。
3.3 Web服務選擇過程
依據3.2節構造的基于多目標優化問題的Web服務選擇模型,應用非功能屬性參數也就是QoS屬性來評估服務請求中每個服務的適應度函數值。慣性質量按照下面的式(7)更新。fi(t)為t時刻粒子i的適應度函數值,它是由非功能屬性參數和t時刻每個服務的適應值來計算的[15]。
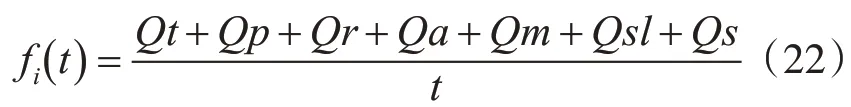
在特殊時刻,
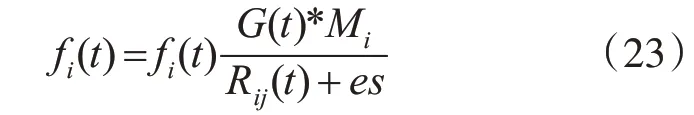
其中,G(t)是t時刻的引力常數,es是一個很小的常數,Rij(t)是t時刻服務i和服務j之間的歐氏距離。
4 實驗與分析
為了證明改進的萬有引力搜索算法在解決基于多目標優化的Web服務組合問題中的可行性和有效性。使用3.2節中建立的旅游場景和測試數據對改進的萬有引力搜索算法進行實驗,同時和標準萬有引力算法進行對比。實驗環境為Windows 7系統,2.27GHz CPU,4G內存,工具為Matlab 7.0,使用語言Matlab。初始參數的設置:種群規模P=80,交叉概率Pc=0.5,變異概率Pm=0.03,最大進化代數T=1000。
表5~7分別代表PSO、GSA和DBPSOGSA算法獨立運行十次的結果。
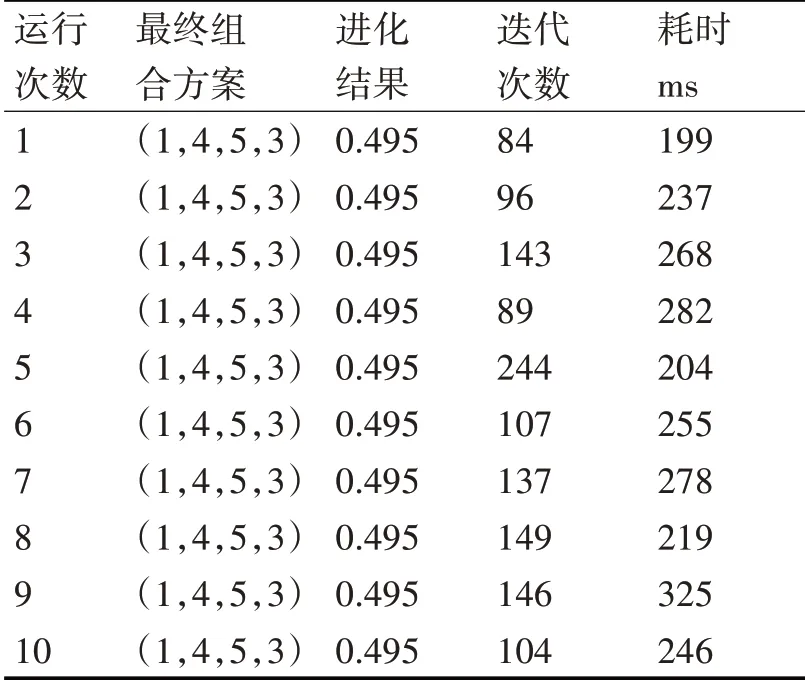
表5 PSO獨立運行10次的結果

表6 GSA獨立運行10次的結果
由表5、表6、表7可知在求解同一規模的問題時,GSA、PSO和本文所提出的DBPSOGSA算法都可以得到最優解,但迭代的次數和耗時是有差異的,圖7是這三種算法在求解同規模問題時運行次數和迭代次數對比圖。
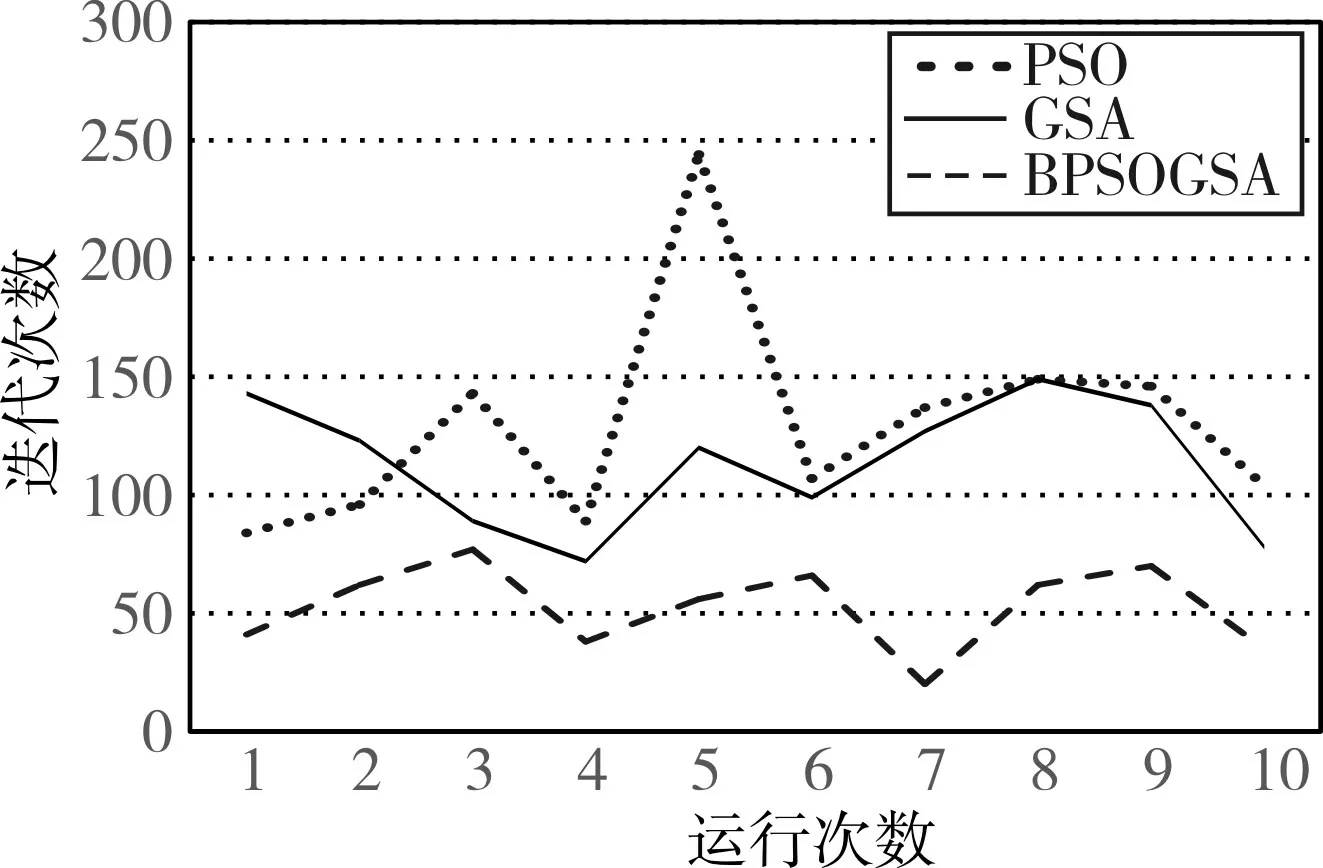
圖6 PSO、GSA和DBPSOGSA求解同規模問題時運行次數和迭代次數對比圖
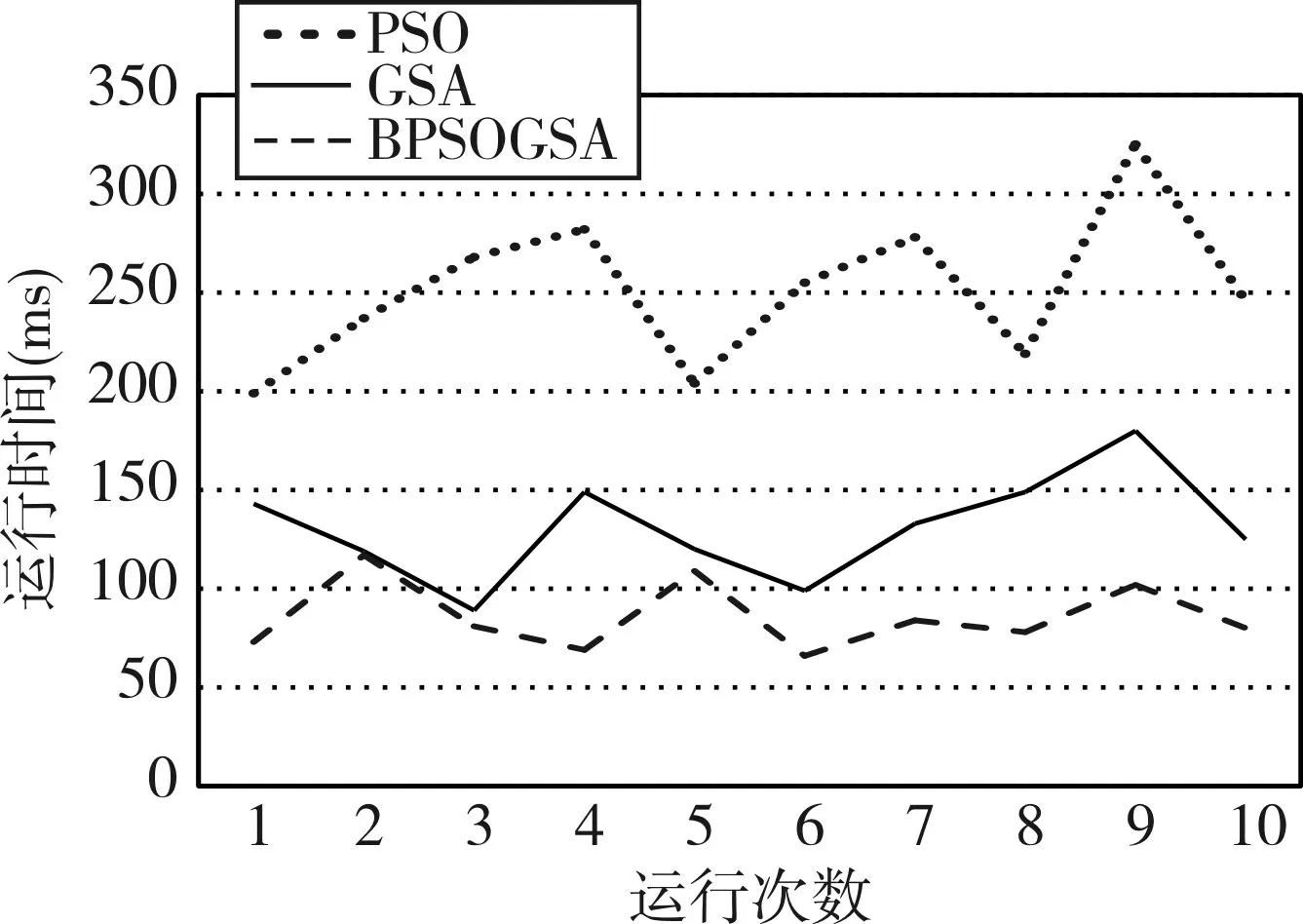
圖7 PSO、GSA和DBPSOGSA求解同規模問題時運行次數和運行時間對比圖
由實驗結果可以看出:PSO算法平均迭代130次左右才可找到最優解,平均耗時251ms,GSA算法平均需要迭代110次可以找到最優解,平均耗時約為130ms,而改進的DBPSOGSA算法平均迭代53次就可以找到最優解,平均耗時約為85ms,該算法在迭代次數和平均耗時上都比PSO和GSA算法有所提升,擁有較好的性能。
引用旅游場景的實驗證明改進的萬有引力搜索算法在解決基于多目標優化的Web服務組合問題上也具有一定的可行性。
5 結語
本文先是對原始萬有引力搜索算法的基本原理和優化過程做以介紹;再通過引入粒子群算法改進GSA中粒子的記憶性,使粒子在優化過程中不但受空間中其他粒子的影響,而且受自身記憶的影響,通過對邊界進行一定的操作和在新的搜索空間內激活停滯粒子,使粒子跳出局部區域,去尋找最優解。最后進行了算法和服務性能的對比,證明了所提出的改進的萬有引力有較好的性能。
接下來的工作就是進一步驗證所提出算法的全局收斂性,以及如何改進萬有引力搜索算法使其具有更廣泛的適用性。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
今日農業(2019年14期)2019-09-18 01:21:54
今日農業(2019年12期)2019-08-15 00:56:32
今日農業(2019年10期)2019-01-04 04:28:15
今日農業(2019年15期)2019-01-03 12:11:33
今日農業(2019年16期)2019-01-03 11:39:20
