基于GA-SVM算法的烤煙香型自動識別研究
2019-02-23 07:15:48邱昌桂孔蘭芬楊式華楊雙艷張建強袁天軍
煙草科技 2019年2期
關鍵詞:分類
邱昌桂,孔蘭芬,楊式華,楊雙艷,劉 靜,張建強,袁天軍,劉 澤
1.云南瑞升煙草技術(集團)有限公司,昆明市高新區海源北路1699號 650106
2.云南同創檢測技術股份有限公司,昆明市高新區海源北路1699號 650106
3.云南中煙工業有限責任公司技術中心,昆明市五華區紅錦路181號 650231
烤煙香型是中式卷煙香氣風格的基礎,也是煙葉風格特色的重要表征以及煙葉品質區域劃分和卷煙配方設計與產品維護的重要依據,對我國煙葉原料種植及工業應用產生了深遠影響[1],因此一直是煙草行業的研究熱點。烤煙香型通常分為清香型、中間香型和濃香型3大類,進而又細分為清香型、清偏中型、中偏清型、中間型、濃香型、濃偏中型和中偏濃型7小類[2-3]。目前,關于不同香型烤煙的差異性和表征研究已有許多報道,例如不同香型烤煙化學成分差異性分析[4-11]、煙葉化學成分與香型風格間的關系[12-13]、采用定量指數法評價烤煙香氣風格[3]、利用聚類和線性判別分析方法對烤煙香型進行表征[14-15]以及利用神經網絡[16]和隨機森林[17]對烤煙香型進行分類等方面。支持向量機(Support Vector Machine,SVM)是Vapnik[18]在統計學 VC(Vapnik-Chervonenkis)維理論和結構風險最小化準則(Structural Risk Minimization,SRM)基礎上,提出的一種用于解決分類和函數逼近問題的新型機器學習方法。與神經網絡等傳統機器學習方法相比,SVM具有嚴格的理論和數學基礎,不存在局部最小問題,且泛化能力強,適合小樣本學習,能夠較好地解決局部極小點、非線性、過學習以及“維數災難”等問題[19],在復雜數據分類、信號處理、文本分類及估計回歸函數等方面得到廣泛應用,在數據挖掘和高維模式識別等領域也表現出應用潛力[20-21]。但在實際應用中,對于SVM最優參數的選擇在理論上尚未得到較好解決。目前常用的SVM參數選擇一般采取窮舉法,但該方法計算量大,耗用時間長,尋優精度低,且不易獲得最優SVM參數。近年來支持向量機在烤煙模式識別方面應用較多,主要有基于交叉驗證優化參數的烤煙煙葉等級分類[22-25]、選擇不同核函數判別煙葉的可用性[26]和煙葉配方的替換[27]、卷煙品牌的判別[28]及不同核函數對烤煙感官質量的評價[29]等。但采用遺傳算法(Genetic Algorithm,GA)優化支持向量機參數在烤煙香型分類的應用研究則鮮見報道。為此,采用遺傳算法優化支持向量機參數的模式分類方法,對3類主要香型風格烤煙的特征差異性進行模式識別,以期建立一種有效識別烤煙香型風格的方法,為烤煙香型準確識別、烤煙產地溯源和煙葉香型風格定位提供依據。
1 材料與方法
1.1 材料
選取2015—2016年濃香型、清香型、中間香型的代表產區河南、云南和貴州的3個等級(B2F、C3F和X2F)煙葉樣品共514個。其中,濃香型煙葉樣品58個,主要來自河南省漯河市、平頂山市、商丘市和許昌市下轄的6個縣;中間香型煙葉樣品110個,主要來自貴州省安順市、貴陽市、銅仁市和遵義市下轄的5個縣;清香型煙葉樣品346個,主要來自云南省昆明市、大理市、紅河州、普洱市、臨滄市、曲靖市、文山市、玉溪市和楚雄州下轄的28個縣。
1.2 儀器
6890N/5975N氣相色譜/質譜聯用儀,配HP-5MS毛細管色譜柱(美國Agilent公司);KBF540恒溫恒濕箱(德國Binder公司);R114旋轉蒸發儀(瑞士Büchi公司);Cyclotec 1093旋風式樣品磨[瑞典FOSS(中國)有限公司];ABS204-S電子天平(感量0.000 1 g,瑞士Mettler-Toledo公司);同時蒸餾萃取裝置(自制)。
1.3 檢測方法
1.3.1 樣品制備
根據烤煙香型定點布置采樣點和落實農戶,于煙葉采收期選取3個等級(B2F、C3F和X2F)的初烤煙葉樣品2.0 kg進行編號、封裝后備用。
1.3.2 樣品預處理
每個樣品將剔除煙梗后的200 g煙葉用粉碎機粉碎,過250 μm分樣篩,充分混勻后的煙末置于恒溫恒濕箱(溫度22℃,相對濕度60%)平衡24 h,準確稱取25 g平衡后的煙末樣品,采用同時蒸餾萃取法對樣品進行前處理,用二氯甲烷作溶劑萃取2 h。所得提取物經無水硫酸鈉干燥后,在水浴45℃、體系壓力56 kPa下旋轉蒸發濃縮至1.0 mL,加入50 μL內標物的無水乙醇溶液(0.1 mol/L),搖勻,裝入樣品瓶中待測。
1.3.3 致香成分含量的測定
致香成分含量的測定按照文獻[30]的方法,使用氣質聯用分析儀對萃取濃縮液進行分析,所得圖譜采用NIST05和Wiley275譜庫進行檢索定性,并以萘為內標物,按照內標校正歸一化法計算各致香成分的含量。
1.4 模式分類方法
1.4.1 支持向量機(SVM)算法原理
支持向量機是基于線性可分情況下的最優分類平面而發展起來的機器學習方法[31],其核心思想是在進行分類時,通過核函數將樣本數據映射到高維特征空間中,在高維特征空間構建一個分類超平面作為決策面,由此可以將樣本正確分類,且使分類間隔距離最大。其中,構建分類超平面就是求函數的全局最優解:

滿足:
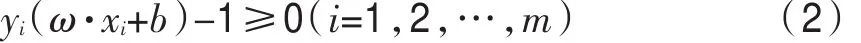
式中:m為樣本個數;xi為訓練樣本;yi為樣本類別;ω為分類超平面的法向量;b為常數。
支持向量機進行多樣本分類時,樣本往往是非線性且不可分的。通過在約束條件中引入正的松弛因子允許存在錯分樣本,在目標函數中加入參數懲罰因子c以及引入核函數將樣本映射到一個高維特征空間,使其在高維特征空間中實現線性可分。其中,懲罰參數c用于控制分類器泛化能力與分類正確率之間的平衡,對于支持向量機分類模型的精度和泛化能力影響顯著。c值越小,訓練誤差越大,分類器泛化能力變差;c值越大,會引起過學習,分類器泛化能力下降。
1.4.2 核函數的選擇
核函數決定了支持向量機特征空間的結構,對于支持向量機的分類性能影響顯著。常用的核函數有線性核函數(Linear)、二次核函數(QKF)、多項式核函數(Poly)、Gauss徑向基核函數(RBF)和多層感知器核函數(Sigmoid)等[32]。本方法中采用了應用較廣泛的徑向基核函數,其形式如下:

式中:g為核函數參數,可以影響SVM算法的復雜程度。
1.4.3 遺傳算法優化參數
遺傳算法(GA)是一種模仿生物界的進化規律演化而來的自適應全局優化搜索方法。與傳統的優化算法相比,遺傳算法不依賴于特定的數學方程和導數表達式,具有全局搜索能力強、不易陷入局部最優解、效率高、尋優速度快等優點[33]。在生產調度、自適應控制、函數優化、機器學習和人工智能等領域得到廣泛應用。利用遺傳算法對支持向量機參數進行優化時,首先對分類器參數(懲罰參數c和核函數參數g)進行編碼,然后以支持向量機分類正確率為適應度函數,在適應度函數的約束下,通過隨機選擇、交叉和變異等步驟尋找最優參數值,從而有效提高支持向量機分類的精度和效率。
2 結果與討論
2.1 不同香型烤煙中致香成分含量的差異性分析
采用多重比較方法對不同香型烤煙中的68種致香成分含量進行分析,結果見表1。
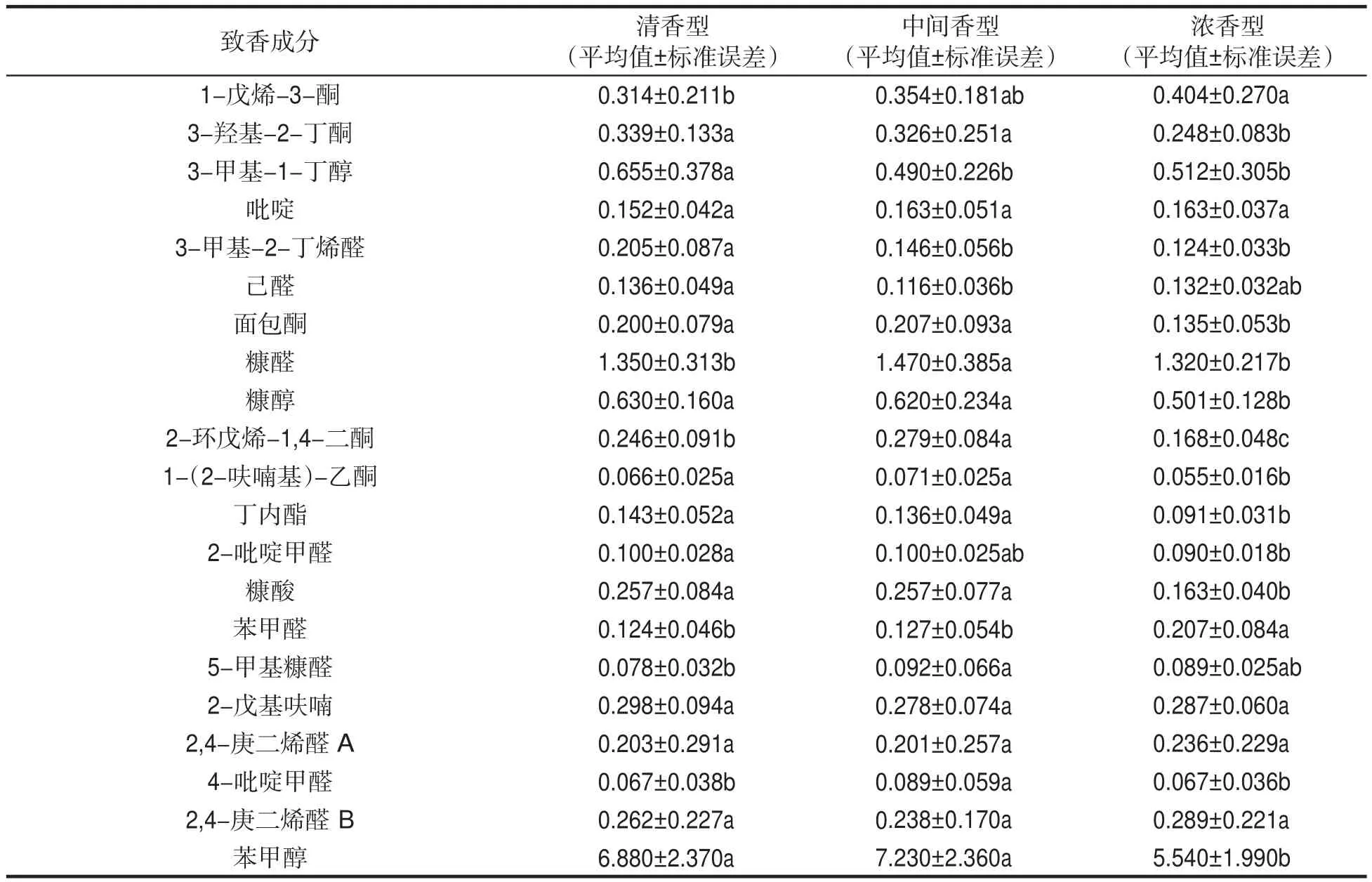
表1 不同香型烤煙中致香成分組間差異性分析結果①Tab.1 Results of differential analysis of aroma components in flue-cured tobacco samples of different flavor types(μg·g-1)
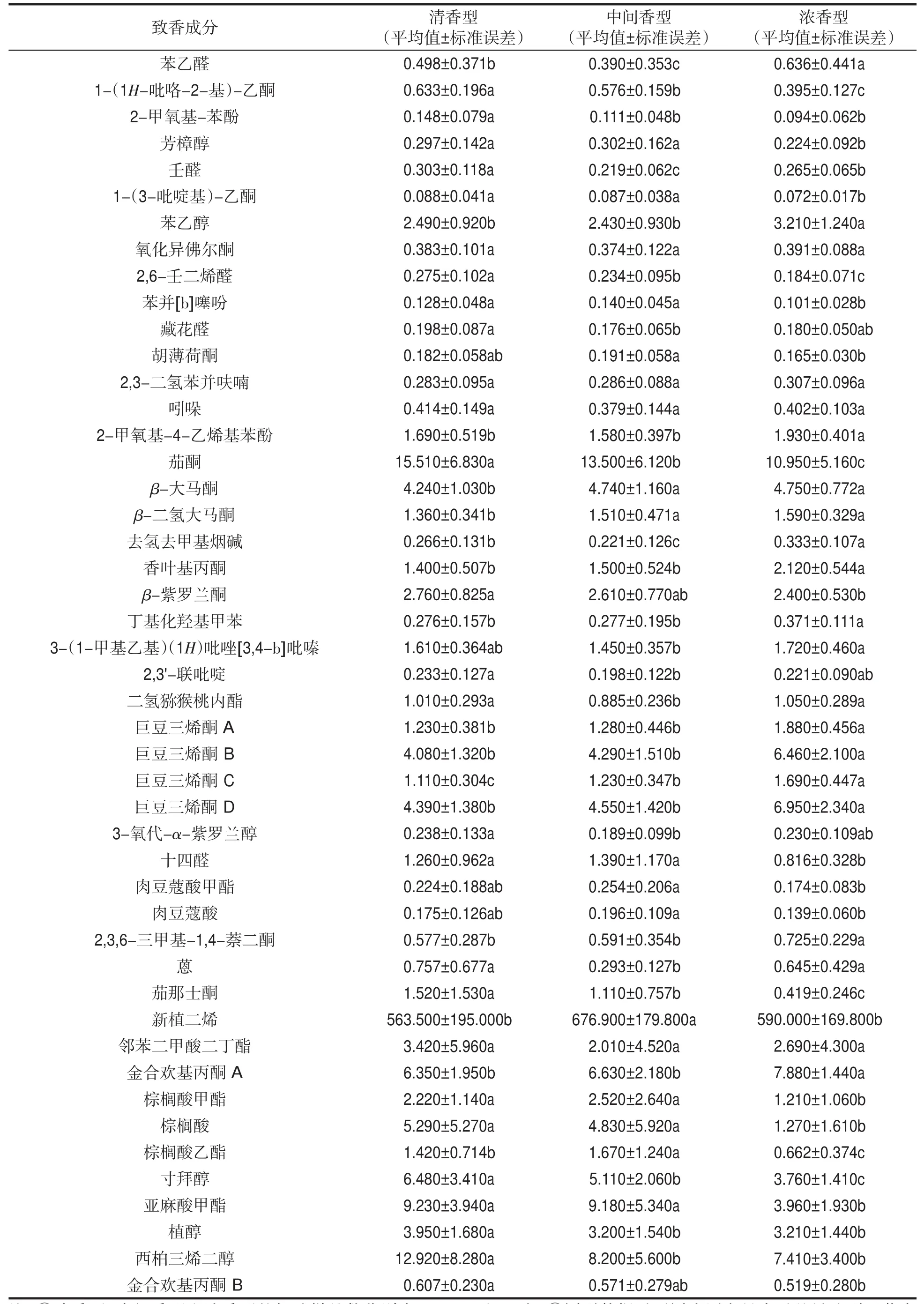
表1(續)
表1可見,不同香型烤煙中吡啶、2-戊基呋喃、2,4-庚二烯醛A、2,4-庚二烯醛B、氧化異佛爾酮、2,3-二氫苯并呋喃、吲哚、鄰苯二甲酸二丁酯等8種致香成分的含量無明顯差異,其他60種致香成分的含量均存在顯著差異。在3類香型煙葉樣品中新植二烯含量均最高,1-(2-呋喃基)-乙酮含量均最低;清香型煙葉樣品中3-甲基-1-丁醇、3-甲基-2-丁烯醛、1-(1H-吡咯-2-基)-乙酮、茄酮、β-紫羅蘭酮、蒽、茄那士酮、鄰苯二甲酸二丁酯、棕櫚酸、寸拜醇、植醇和西柏三烯二醇含量均顯著高于其他香型;中間香型煙葉樣品中糠醛、苯甲醇、十四醛、新植二烯、棕櫚酸甲酯和棕櫚酸乙酯含量均顯著高于其他香型;濃香型煙葉樣品中苯乙醇、丁基化羥基甲苯、3-(1-甲基乙基)(1H)吡唑[3,4-b]吡嗪、巨豆三烯酮B、巨豆三烯酮C、巨豆三烯酮D、2,3,6-三甲基-1,4-萘二酮和金合歡基丙酮A含量均顯著高于其他香型。
由表1可知,同類香型中存在致香成分標準偏差較大的現象,說明這些致香成分含量在相同香型(清香型、中間香型、濃香型)不同生產點間存在差異。總體上,3類香型煙葉樣品中均為苯甲醇、新植二烯、鄰苯二甲酸二丁酯、西柏三烯二醇含量差異最大,但清香型煙葉樣品中茄酮、寸拜醇含量差異顯著高于其他香型,中間香型煙葉樣品中金合歡基丙酮A、棕櫚酸甲酯、棕櫚酸、亞麻酸甲酯含量差異顯著高于其他香型,濃香型煙葉樣品中巨豆三烯酮B、巨豆三烯酮D含量差異顯著高于其他香型,由此導致不同香型烤煙的香型區分度更為明顯,也造成同類香型烤煙在香氣質、香氣量等方面存在一定差異。
2.2 GA-SVM算法的烤煙香型分類
采用GA-SVM算法對清香型、中間香型和濃香型3類香型的514個煙葉樣品進行分類,使用5折交叉驗證,重復測試10次。首先對GA-SVM算法的各控制參數進行設置,其中種群最大數量為20,取值范圍為[20,100];最大進化代數為100,取值范圍為[100,500];支持向量機懲罰參數c取值范圍為[0,100],核函數參數g取值范圍為[0,100]。以第一次對514個煙葉樣品數據使用5折交叉驗證為例,圖1給出了使用GA-SVM算法優化支持向量機c、g參數的迭代運算曲線。
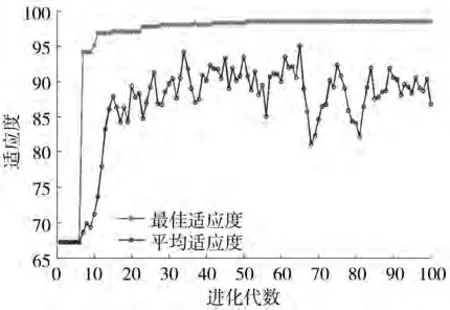
圖1 GA-SVM算法參數優化過程曲線Fig.1 Parameter optimization process curves of GA-SVM algorithm
基于最優保留策略,種群中的最優個體適應度逐漸增加,最后穩定在98.54%,表明此時的懲罰參數c與核函數參數g的組合達到性能最優,即最佳懲罰參數c=72.931,最佳核函數參數g=0.011時,訓練集的分類正確率為100%,測試集的分類正確率為94.12%,結果見表2。可見,重復測試10次,GA-SVM算法的訓練集分類正確率為100%;測試集分類正確率為96.40%,其中清香型煙葉為98.27%,中間香型煙葉為89.55%,濃香型煙葉為98.26%。
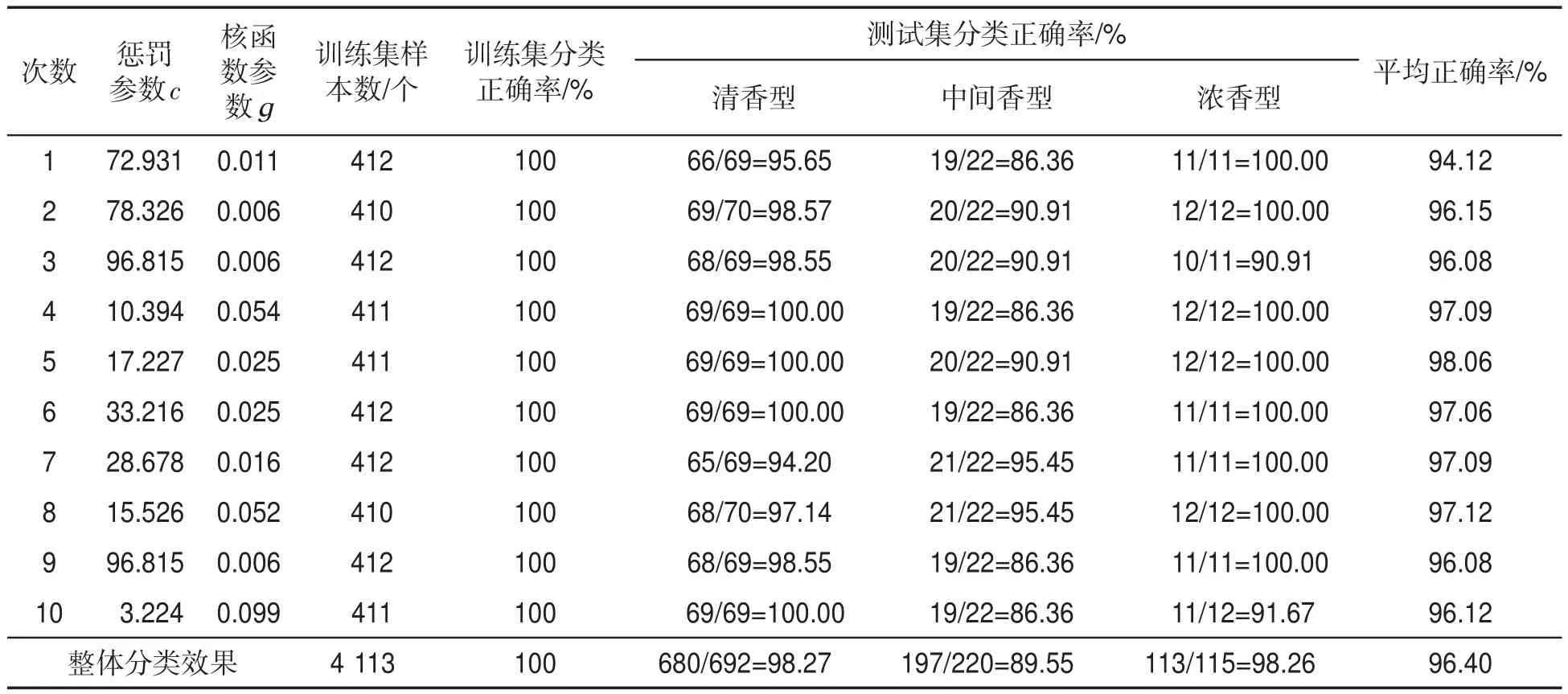
表2 GA-SVM算法對不同香型烤煙的分類結果Tab.2 Classification results of flue-cured tobacco samples of different flavor types by GA-SVM algorithm
2.3 SVM和樸素貝葉斯分類算法的烤煙香型分類
使用SVM算法和樸素貝葉斯算法分別對514個煙葉樣品進行分類,使用5折交叉驗證,重復測試10次,結果見表3。可見,訓練集SVM算法的分類正確率為100%,樸素貝葉斯算法的分類正確率為86.46%;測試集SVM算法的分類正確率為78.58%,樸素貝葉斯算法的分類正確率為84.42%。對比可見,由于GA-SVM算法使用遺傳算法對支持向量機的參數進行優化和調整,獲得最優參數,從而使取得的分類正確率優于SVM以及樸素貝葉斯等傳統分類算法。
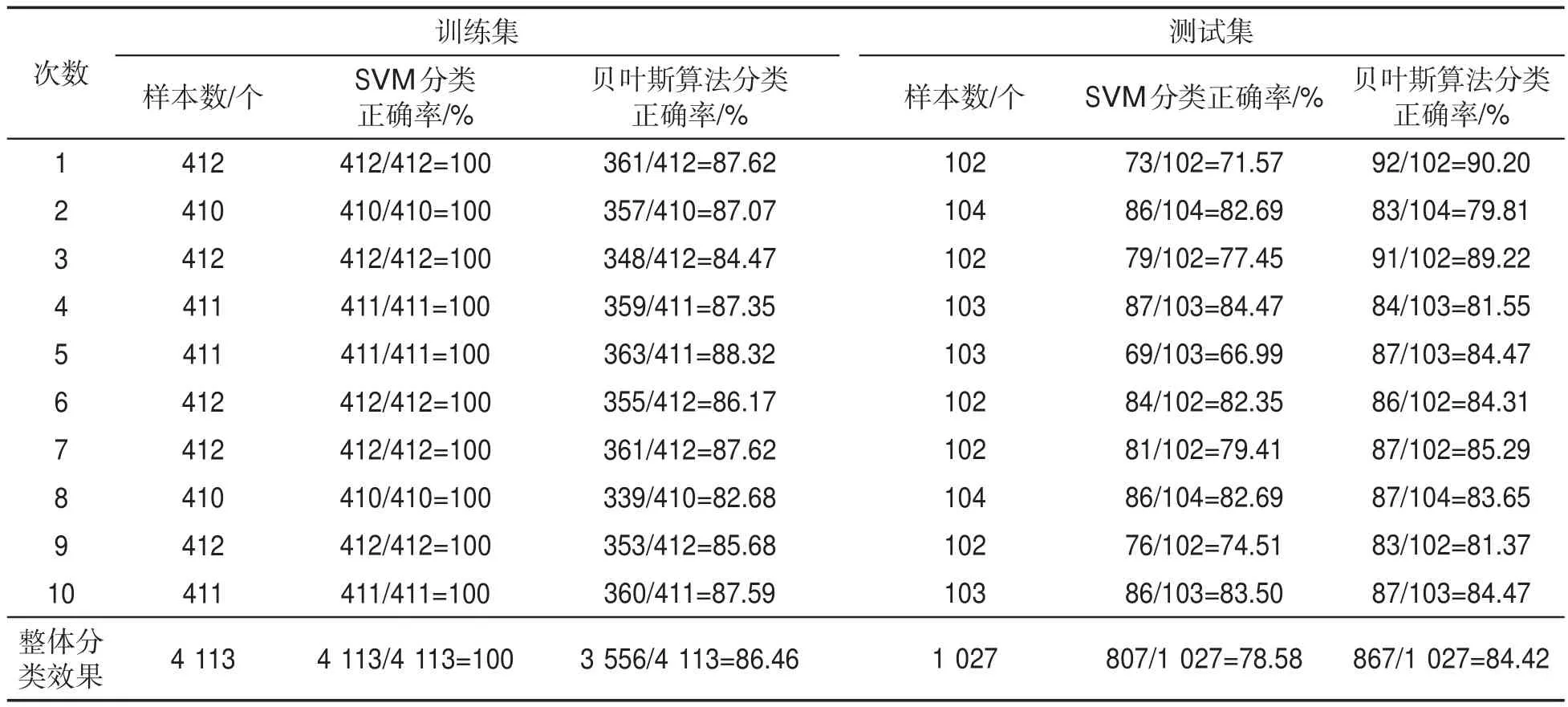
表3 SVM算法和樸素貝葉斯算法對不同香型烤煙的分類結果Tab.3 Classification results of flue-cured tobacco samples of different flavor types by SVM and naive Bayesian algorithms
3 結論
為了尋找一種有效識別烤煙香型風格的方法,以清香型、濃香型和中間香型烤煙為研究對象,提出了一種基于致香成分結合GA-SVM算法的烤煙香型自動識別方法。該方法能夠避免支持向量機算法在分類過程中主要依靠經驗值選取參數的缺陷,通過使用遺傳算法對支持向量機參數進行優化和調整,以獲得最優參數。采用GA-SVM算法、SVM算法和樸素貝葉斯算法分別對清香型、中間香型和濃香型3類香型的514個煙葉樣品進行分類,結果表明:3類香型煙葉的分類正確率分別為96.40%、78.58%和84.42%,GA-SVM算法顯著優于SVM和樸素貝葉斯等傳統分類算法。因此,GA-SVM算法結合煙草致香成分能夠用于對烤煙香型進行分類。
猜你喜歡
西北民族大學學報(自然科學版)(2021年4期)2021-12-29 02:54:24
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小聰仔(科普版)(2020年12期)2021-01-18 09:16:52
東方少年·布老虎畫刊(2020年4期)2020-06-08 15:48:10
學生天地(2019年32期)2019-08-25 08:55:22
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
小天使·一年級語數英綜合(2017年11期)2017-12-05 18:49:56
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
