基于GACA-MKSVM的齒輪箱故障診斷
2019-02-22 05:19:30柳玉超
設備管理與維修 2019年1期
柳玉超
(中車青島四方機車車輛股份有限公司,山東青島 266111)
0 引言
齒輪箱作為牽引系統的重要機械部件,直接影響機車的安全行駛,對齒輪箱故障識別診斷的效率關系到鐵路運輸質量。因此,研究機車齒輪箱故障診斷具有重要意義。
以電力機車的齒輪箱為研究對象,采用遺傳蟻群算法優化的多核支持向量機,對齒輪箱故障進行識別分析,避免了單核支持向量機精度較差的問題,并與神經網絡、單核支持向量機、標準遺傳算法優化的多核支持向量機方法進行比較分析。
1 建模理論分析
1.1 機車齒輪箱故障分析
齒輪箱主要故障類別可分為齒輪與軸承故障、密封不良、保持架故障、箱體故障以及無故障(正常)等5類模式。研究發現齒輪軸承發生故障,如密封不良、齒輪磨損時,較小的粉塵及金屬屑會進入潤滑油中,導致齒面的磨粒磨損、磨粒濃度變化。齒輪磨損發生故障,潤滑油中鐵、鉻和鋅元素的含量明顯增加;保持架磨損故障,銅元素的含量明顯增加;箱箱體磨損故障,鋁元素的含量明顯增加;密封不良故障,硅元素的含量明顯增加。因此,選擇鐵、鉻、鋅、銅、鋁、硅、和磨粒含量作為齒輪箱診斷的輸入。
1.2 支持向量機原理和算法
SVM(Support Vector Machine,支持向量機)是由Vanpik提出的一種基于統計學習理論的智能學習方法。傳統單核支持向量由于單核的局限性,難以適應復雜故障診斷問題,且識別精度低,難以用于實際問題。為此,采用多核函數解決單核的不足,多核支持向量機是2個及以上的單核函數通過線性組合,得到支持向量機的核函數。常見的核函數主要有:
(1)線性核函數 K(X,Y)=(X,Y);
(2)多項式核函數 K(X,Y)=(X·Y+c)d,其中 c為常數,d 為多項式階數;
(4)Sigmoid 核函數 K(X,Y)=tanh(v(X,Y)-c),其中 v 為尺度,c為衰減參數。
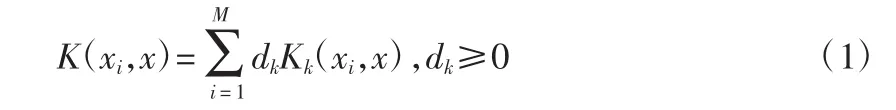
式中:M 為單核數目,dk為第 k 個單核的權值,Kk(xi,x),為基本的核函數。單核支持向量機分類函數的形式見式(2)。
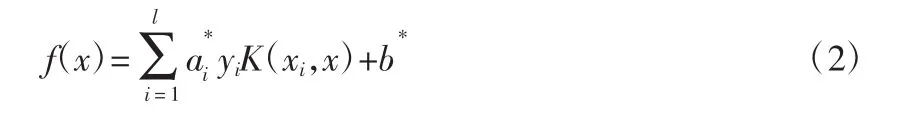
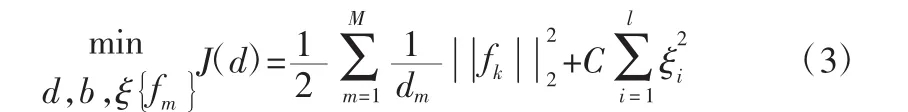
式(3)中的約束條件為式(4)。
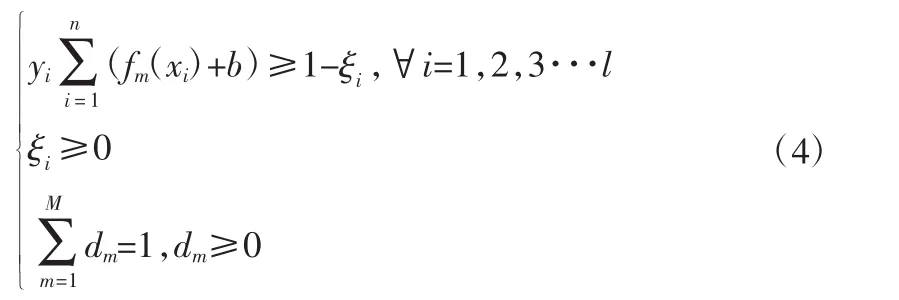
式中:b為偏置量,C為懲罰參數,ξi為訓練誤差。
利用對偶化條件,構建Lagrange函數,結合KKT條件,將約束優化問題轉化為無約束優化問題。見式(5)。
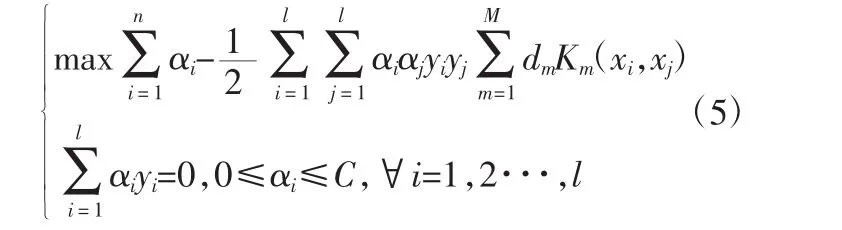
式中:σ為核函數寬度。求解式(5),建立MKSVM模型,形式為式(6)。
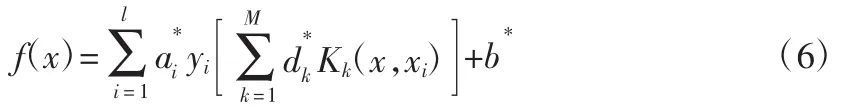
2 基于GACA-MKSVM的齒輪箱故障診斷模型
2.1 遺傳—蟻群算法
遺傳算法在全局尋優方面具有很強能力,但在計算過程中沒有使用反饋信息,后期計算過程中很可能出現大量無用迭代。蟻群算法充分利用了系統的正反饋,具有很強收斂能力,但由于前期計算過程缺乏信息素,導致前期求解速度較慢。為了充分利用兩種算法的優點,避免各自缺點,將遺傳算法和蟻群算法組合,首先利用遺傳算法進行全局尋優,然后再利用蟻群算法快速找出最優解。
2.2 遺傳算法
(1)初始化種群。采用實數編碼,初始化遺傳算法種群規模M,最大迭代次數 Genmax,終止迭代次數,Gen(Gen<Genmax)種群最小進化率Rmin,交叉概率Pc,變異概率Pm。
(2)適應度值函數。見式(7)。式中:l為訓練樣本個數,Ti為訓練樣本的目標輸出值,Yi為訓練樣本實際輸出值。

(3)選擇、交叉和變異操作。輪盤堵轉法選出新的父代。交叉隨機選擇2個個體,單點交叉。隨機選擇一個個體,進行變異操作。
2.3 兩種算法的銜接過度
若遺傳算法連續迭代次數達到Gen,種群進化率都小于Rmin,終止遺傳算法,或者當迭代次數達到最大值Genmax,終止遺傳算法,進入蟻群算法。
2.4 蟻群算法
初始化螞蟻數量m,信息素強度Q,蟻群最大迭代次數Nmax,信息素影響因子α,啟發式影響因子β,信息素殘留系數ρ。
(1)信息素初值設置。見式(8)。利用遺傳算法得到的較優解,根據式(7)初始化信息素,其中τc為根據具體問題設置的信息素常數,τG為遺傳算法求得的優化解轉換值。
(2)選擇概率。對于每只螞蟻根據概率轉移公式(8)得式(9),式中:α為信息素影響因子,β為啟發式影響因子。

(3)信息素跟新。依據式(7)計算適應度值,根據式(9)更新信息素,得式(10),式中:ρ為信息素殘留系數,Q為常數,代表信息素強度。
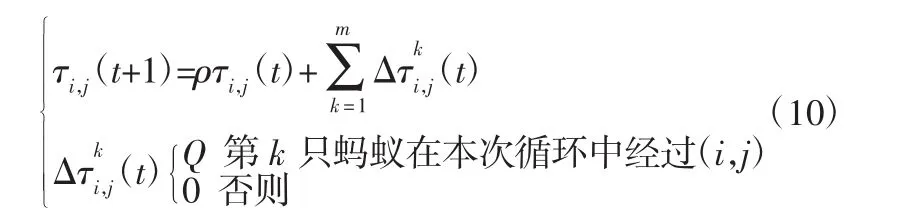
2.5 故障診斷步驟
已知齒輪箱故障的訓練樣本集為(x1,y1),…,(xm,ym),其中xi∈Rd,yqi∈{+1,-1},i=1、…、m,q=1,…,f,m 為電機故障訓練樣本的個數,f為故障模式數目。選擇多項式核函數和高斯徑向基核函數構造多核核函數,多核核函數見式(11),式中:α為權重系數。
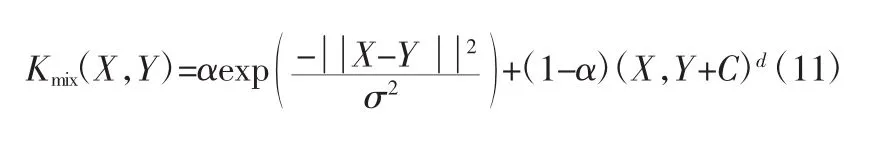
利用改進MKSVM實現齒輪箱故障診斷的步驟:
(1)數據預處理,歸一化處理,消除指標類別差異的影響。
(2)利用遺傳蟻群算法優化支持向量機參數C,σ,d,α。
(3)根據遺傳蟻群算法優化得到的支持向量機參數C,σ,d,α,利用提取得到的主成分數據求解式(11),得到對應的第q類故障的支持向量機故障診斷分類器模型。同理,可得5個基于GACA-MKSVM齒輪箱故障分類器模型。
(4)利用求得的f個齒輪箱故障分類器模型建立故障診斷系統模型,如圖1所示。
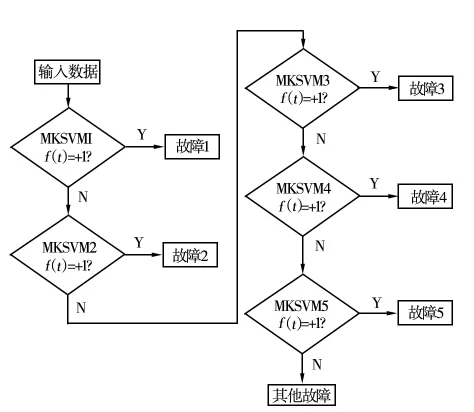
圖1 支持向量機故障診斷分類器模型
(5)利用故障診斷分類器模型進行故障診斷。在仿真研究中,先將輸入數據t輸入支持向量機故障診斷分類器模型MKSVM1,若 f(t)輸出結果為+1,則該故障屬于故障模式 1;否則,將輸入數據作為支持向量機故障診斷分類器模型MKSVM2的輸入,依次計算,直到相應的f(t)輸出結果為+1,得出相應的故障模式。若最終的決策函數沒有出現+1情況時,則該故障屬于其他故障模式。齒輪箱故障診斷流程如圖2所示。
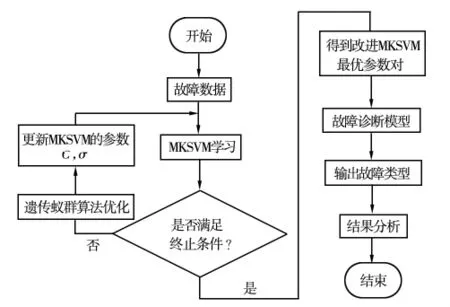
圖2 基于GACA-MKSVM故障診斷流程
3 仿真分析
以電力機車齒輪箱為研究對象,選擇某機務段和諧號電力機車齒輪箱故障資料為樣本。選取300組數據作為樣本數據,200組數據作為網絡訓練樣本數據,100組數據作為網絡測試樣本數據。用F1,F2,F3、F4及F5分別表示齒輪與軸承故障、密封不良、保持架故障、箱體故障以及無故障(正常)等5類故障模式,訓練樣本、測試樣本部分數據如表1所示。
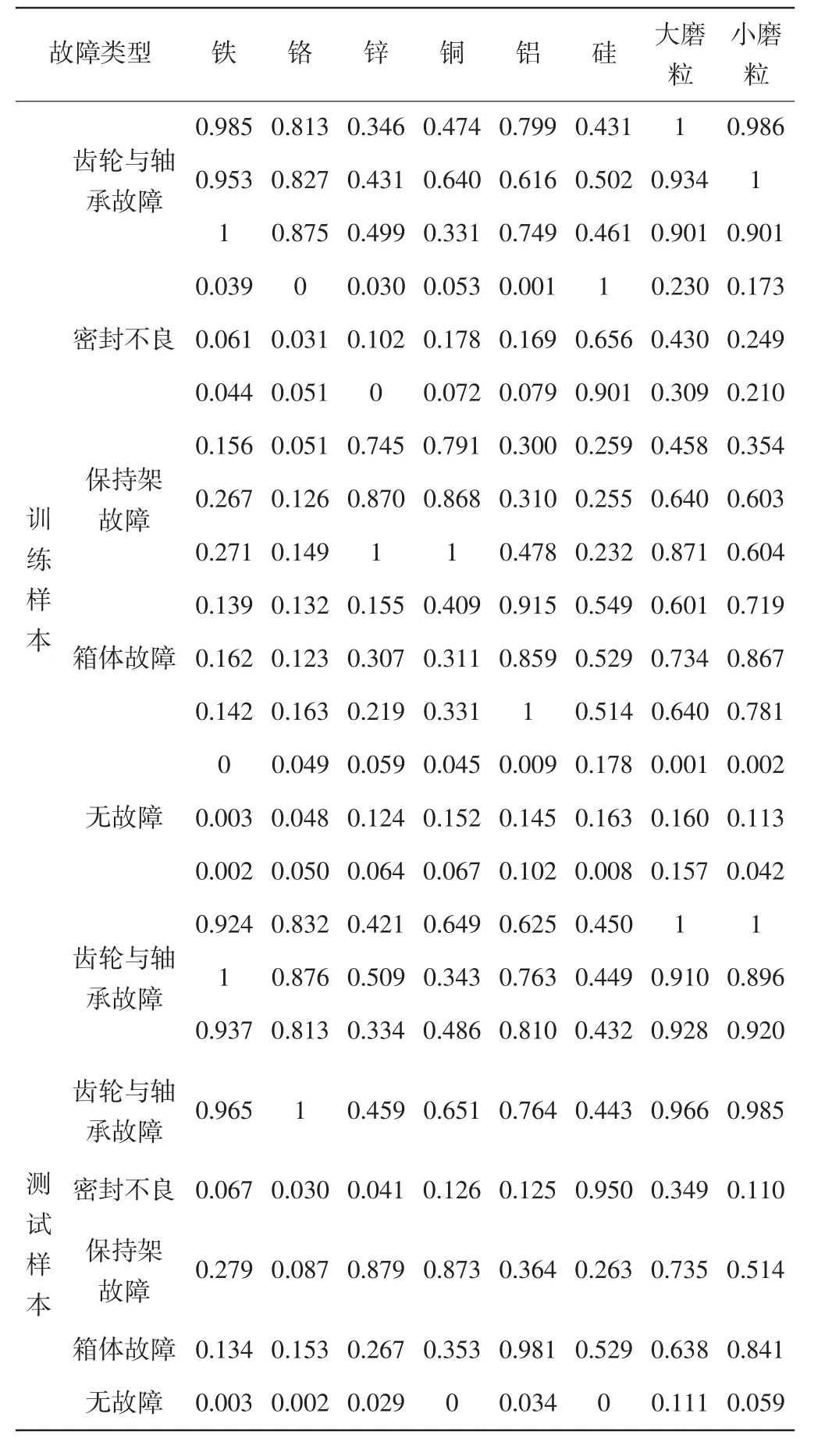
表1 部分樣本數據
經遺傳蟻群算法優化得到的5種故障模式的支持向量機(MKSVMl-MKSVM5)參數。然后,得到對應的5類故障的支持向量機故障診斷分類器模型,隨機選取5組測試樣本,分別為a1=(0.001,0.042,0.058,0.057,0.099,0.011,0.143,0.051),a2=(0.946,1,0.512,0.598,0.751,0.438,0.974,0.979),a3=(0.102,0.029,0.040,0.126,0.202,0.956,0.401,0.099),a4=(1,0.867,0.496,0.434,0.674,0.460,0.911,0.892),a5=(0.002,0.038,0.060,0.051,0.011,0.176,0.002,0.003)輸入故障診斷分類器模型進行故障模式識別。輸入數據維數為8維,診斷結果見表2。

表2 基于GAGA-MKSVM故障診斷模型測試結果
從表2可知,基于GACA-MKSVM故障診斷模型對驗證數據的診斷結果與實際故障完全一致,準確率為100%。進一步研究,每類故障模式中取10組數據作為驗證數據,故障識別準確率仍為100%。可見,基于GACA-MKSVM故障診斷模型對于小樣本仍然具有良好的分類性能。
為了進一步說明該方法的有效性,從每種故障模式樣本中選取共60組為訓練樣本,剩余的樣本為測試數據樣本,與直接使用支持向量機(SVM)、標準遺傳算法優化支持向量機(GASVM)故障診斷方法進行比較分析,4種方法對驗證數據的故障診斷結果對比如表3所示。
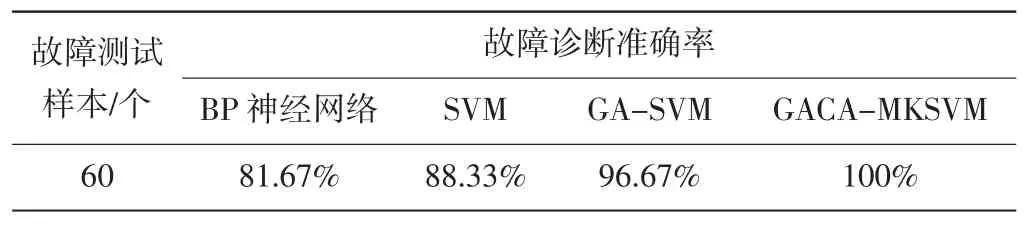
表3 4種診斷模型測試結果
從表3可以看出,基于CGA-LSSVM故障診斷模型對齒輪箱的故障識別準確率明顯高于BP神經網絡、SVM,GA-SVM故障診斷模型。
4 結論
研究基于遺傳蟻群優化多核支持向量機的齒輪箱故障診斷方法,建立高性能的齒輪箱故障診斷模型。遺傳蟻群相比標準遺傳算法搜索效率更高而且很好地解決了過早收斂的問題,優化后的基于多核支持向量機的齒輪箱故障診斷模型故障識別準確率更高。以電力機車的齒輪箱為研究對象,仿真結果表明:遺傳算法優化多核支持向量機的故障診斷方法應用于電力機車齒輪箱故障診斷,故障識別準確率高。該方法為電力機車齒輪箱的故障診斷提供借鑒參考。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
汽車維修與保養(2019年7期)2020-01-06 03:30:42
光學精密工程(2016年6期)2016-11-07 09:07:19
汽車維護與修理(2016年10期)2016-07-10 08:17:41
重慶工商大學學報(自然科學版)(2015年10期)2015-12-28 07:43:58
汽車維修與保養(2015年6期)2015-04-17 03:31:50
汽車維護與修理(2015年2期)2015-02-28 12:15:39
振動、測試與診斷(2014年5期)2014-03-01 01:14:21
