緊湊型深度卷積神經(jīng)網(wǎng)絡(luò)在圖像識(shí)別中的應(yīng)用*
2019-02-13 06:59:14錢雪忠
計(jì)算機(jī)與生活 2019年2期
吳 進(jìn),錢雪忠
江南大學(xué) 物聯(lián)網(wǎng)工程學(xué)院,江蘇 無(wú)錫 214122
1 引言
深度卷積神經(jīng)網(wǎng)絡(luò)在圖像識(shí)別領(lǐng)域取得了突破性的進(jìn)展,但是網(wǎng)絡(luò)的參數(shù)規(guī)模越來越大,參數(shù)量達(dá)到百萬(wàn)級(jí),甚至千萬(wàn)級(jí),不利于應(yīng)用。為了更好地解決這個(gè)問題,一種方式是壓縮現(xiàn)有的網(wǎng)絡(luò)模型,Howard等人[1]提出的基于深度可分離的卷積結(jié)構(gòu)MoblieNet,引入了傳統(tǒng)網(wǎng)絡(luò)中原先采用的group思想,即限制濾波器的卷積計(jì)算只針對(duì)特定的group中的輸入,將標(biāo)準(zhǔn)卷積分離成一個(gè)深度卷積和一個(gè)點(diǎn)卷積,極大程度地降低了卷積計(jì)算,同時(shí)提升了計(jì)算速度。基于MobileNet的group思想,ShuffleNet[2]將輸入的group打散,結(jié)合深度可分離卷積代替類似于ResNet block單元構(gòu)成了ShuffleNet單元,解決了多個(gè)group疊加出現(xiàn)的邊界效應(yīng),減少了計(jì)算量,增強(qiáng)了網(wǎng)絡(luò)的表現(xiàn)力。Theis等人[3]通過使用對(duì)角Fisher信息值在盡量避免訓(xùn)練損失的前提下一次去掉一個(gè)卷積的特征圖的方法來剪枝。
另一種方式是權(quán)值壓縮,Han等人[4]基于權(quán)值聚類的方法將連續(xù)分散的權(quán)值離散化,從而減少需要存儲(chǔ)的權(quán)值數(shù)量,并采用Huffman encoding將平均編碼長(zhǎng)度減少實(shí)現(xiàn)減小模型尺寸的目的,最后采用CSR(compressed sparse row)來存儲(chǔ)。Rastegari等人提出的XNOR-Net[5]輸入和輸出都量化成二值,將輸入數(shù)據(jù)先進(jìn)行BN歸一化處理,接著進(jìn)行二值化的卷積操作,實(shí)現(xiàn)32倍的存儲(chǔ)壓縮,同時(shí)訓(xùn)練速度得到58倍的提升。
本文鑒于卷積神經(jīng)網(wǎng)絡(luò)(convolutional neural network,CNN)結(jié)構(gòu)的壓縮理論,分析了現(xiàn)有的不同的CNN結(jié)構(gòu)模型,設(shè)計(jì)了多分支的Conv-mixed結(jié)構(gòu),并設(shè)計(jì)了新的緊湊型深度卷積神經(jīng)網(wǎng)絡(luò)架構(gòu)Width-MixedNet,分別在 CIFAR-10、CIFAR-100 和 MNIST數(shù)據(jù)集上進(jìn)行實(shí)驗(yàn),結(jié)果表明,Width-MixedNet在參數(shù)規(guī)模遠(yuǎn)低于其他深度神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)的情況下,取得了更好的效果。
2 相關(guān)工作
2.1 Conv-mixed結(jié)構(gòu)
傳統(tǒng)的深度卷積神經(jīng)網(wǎng)絡(luò)都是以convolutionspooling堆疊起來的直線型結(jié)構(gòu),比如2012年Krizhevsky等人[6]提出的由5個(gè)convolution層和3個(gè)fullconnection層堆疊成的AlexNet,2014年Visual Geometry Group和Google DeepMind研發(fā)的由3×3的小型卷積核反復(fù)堆疊的19層VGGNet[7],之后由微軟訓(xùn)練的多達(dá)152層的ResNet[8]。上述深度卷積神經(jīng)網(wǎng)絡(luò)的深度逐漸加深,雖然達(dá)到的精度越來越高,伴隨而來的是網(wǎng)絡(luò)的參數(shù)越來越龐大,容易導(dǎo)致過擬合,計(jì)算量也變得相當(dāng)大,難以應(yīng)用,并且網(wǎng)絡(luò)越深,容易導(dǎo)致梯度消失,模型難以優(yōu)化。為了深度神經(jīng)網(wǎng)絡(luò)能在有硬件條件限制的平臺(tái)上廣泛應(yīng)用(比如自動(dòng)駕駛汽車、無(wú)人機(jī)、VR設(shè)備等),緊湊型的網(wǎng)絡(luò)模型設(shè)計(jì)引起了很多關(guān)注。
為了讓深度卷積神經(jīng)網(wǎng)絡(luò)有更好的提取特征和學(xué)習(xí)能力,最直接有效的方法是增加卷積層的通道,但這會(huì)增加整個(gè)網(wǎng)絡(luò)的計(jì)算量,容易導(dǎo)致過擬合。因?yàn)榫矸e神經(jīng)網(wǎng)絡(luò)中每一個(gè)輸出通道只對(duì)應(yīng)一個(gè)卷積核,同一個(gè)層參數(shù)共享,因此一個(gè)輸出通道只能提取一種特征。在文獻(xiàn)[9]中提出的MLPConv代替?zhèn)鹘y(tǒng)的卷積層,將輸出通道之間信息進(jìn)行組合,相當(dāng)于普通卷積層之后再連接1×1的卷積核ReLU激活函數(shù),因?yàn)閮?nèi)核為1×1的卷積層只有一個(gè)參數(shù),只需要很小的計(jì)算量就可以提取一層特征,增加一層網(wǎng)絡(luò)的非線性化。
在2014年ILSVRC(large scale visual recognition challenge)的比賽中,Google Inception Net[10]以較大的優(yōu)勢(shì)奪冠。值得注意的是,InceptionNet精心設(shè)計(jì)的Inception Module(如圖1所示),先將前一層輸出的特征圖(previous layers)分別作為1×1、3×3和5×5的卷積層和一個(gè)maxpooling層的輸入,然后各個(gè)分支在輸出通道上合并(concatenation),作為下一個(gè)Inception Module的輸入。這種由Inception Module堆疊成的深層網(wǎng)絡(luò)結(jié)構(gòu),對(duì)寬度進(jìn)行了高效的擴(kuò)充和利用,提高了準(zhǔn)確率并且不至于過擬合。
最近的研究開始直接設(shè)計(jì)緊湊型的網(wǎng)絡(luò)架構(gòu):SqueezeNet[11],論文提到的Fire Module如圖2所示,先將前一層的輸出特征圖(previous layers)作為由3個(gè)1×1卷積組成的squeeze層的輸入,在輸出通道上合并之后,再作為由4個(gè)1×1和4個(gè)3×3的卷積組成的expand層的輸入,接著在輸出通道上合并作為下一個(gè)Fire Module的輸入。SqueezeNet達(dá)到了AlexNet相同的精度水平,同時(shí)SqueezeNet的模型大小只有AlexNet的1/50。

Fig.2 Fire module圖2 Fire模塊
受到所述觀察的啟發(fā),提出了一種緊湊的深度卷積神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu),其中包含一種新的基本模塊Conv-mixed。圖3是整個(gè)網(wǎng)絡(luò)模型中的一個(gè)Convmixed結(jié)構(gòu),前一層的輸出(previous layer)作為Convmixed的輸入,輸入共有5個(gè)分支,分別為P-C0-C1-C2、P-C3-C4-C5、P-C6、P-A-C7、P-C8。C8之后又是兩個(gè)分支C8-C9和C8-C9,最后各個(gè)分支在輸出通道上合并。參數(shù)k和s表示內(nèi)核大小和步長(zhǎng),參數(shù)r表示空洞卷積的擴(kuò)張率,在每一次的卷積操作之前,都對(duì)其輸入進(jìn)行Batch Normalization正則化,所有的卷積都采用ReLU激活函數(shù)進(jìn)行非線性化。
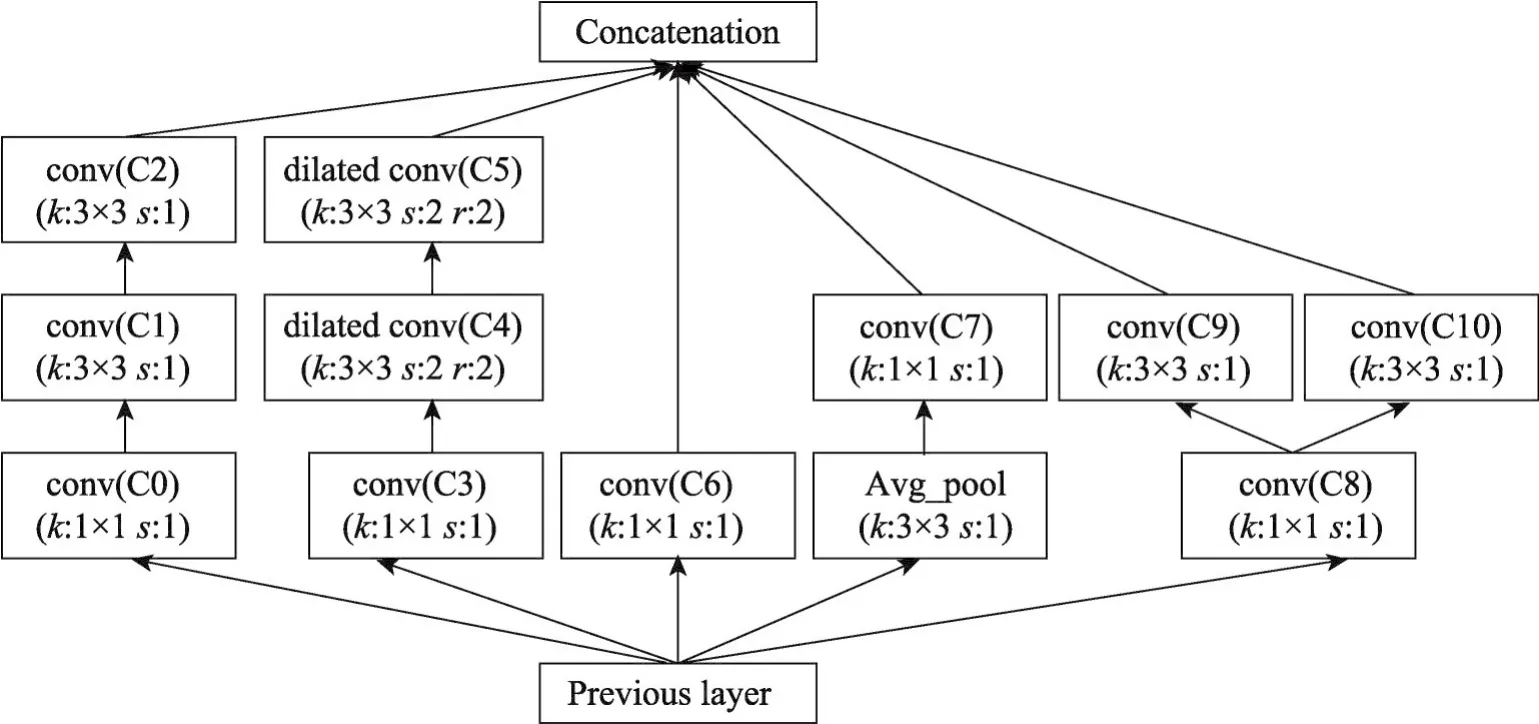
Fig.3 Conv-mixed module圖3 Conv-mixed模塊
在圖像數(shù)據(jù)中,臨近區(qū)域的數(shù)據(jù)相關(guān)性高,卷積神經(jīng)網(wǎng)絡(luò)中每一個(gè)輸出通道對(duì)應(yīng)一個(gè)濾波器,只能提取一類特征,因此使用分支結(jié)構(gòu)使多個(gè)不同的卷積核連接同一位置,這樣可以提取多個(gè)不同的特征。文獻(xiàn)[12]中提出:如果數(shù)據(jù)集的概率分布可以被一個(gè)很大很稀疏的神經(jīng)網(wǎng)絡(luò)所表達(dá),那么構(gòu)筑這個(gè)網(wǎng)絡(luò)的最佳方式就是逐層構(gòu)筑,即將上一層高度相關(guān)(correlated)的節(jié)點(diǎn)聚類,并將聚類出來的每一個(gè)小簇(cluster)連接到一起。設(shè)計(jì)出的Conv-mixed這種多分支結(jié)構(gòu),將相關(guān)性高的節(jié)點(diǎn)連接在一起,構(gòu)建了很高效的符合上述理論的稀疏結(jié)構(gòu)。
為了增加提取特征的多樣性,使用了1×3、3×1和3×3三種不同尺寸的卷積內(nèi)核,相比于大型的卷積比如5×5和7×7,小型卷積的計(jì)算量雖然小,但是感受視野也小。為了彌補(bǔ)這個(gè)缺陷,在分支結(jié)構(gòu)里加入了Dilated Convolutions[13]即空洞卷積。普通卷積和空洞卷積的對(duì)比如圖4所示,左邊是內(nèi)核kernel=3的普通卷積,相當(dāng)于kernel=3、膨脹系數(shù)r=1的空洞卷積;右邊是kernel=3、r=2的空洞卷積,相當(dāng)于kernel=7的普通卷積。膨脹系數(shù)r表示每個(gè)像素之間填充r-1個(gè)0。在通道數(shù)相同的情況下,圖4左邊的普通卷積和右邊的空洞卷積參數(shù)量相同,但是在同一層的感受視野卻不同,感受視野公式如下:
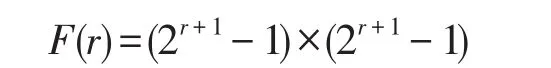
其中,r表示膨脹系數(shù),F(xiàn)(r)表示最終的感受視野,例如圖4中左邊普通卷積在這層的感受視野為F(r=1)=3×3,右邊r=2的空洞卷積感受視野為F(r=2)=7×7。可以推算:經(jīng)過卷積層疊加之后,2層的3×3的普通卷積轉(zhuǎn)換相當(dāng)于1層5×5的卷積,2層3×3、r=2的空洞卷積,相當(dāng)于1層13×13的普通卷積。
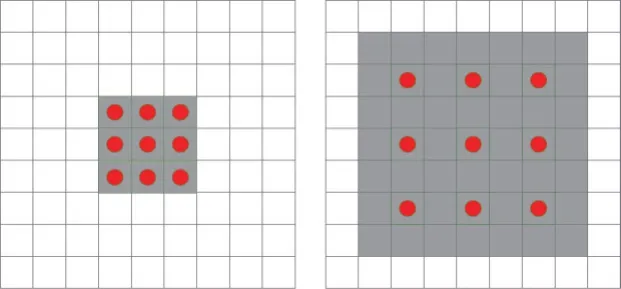
Fig.4 Comparison of ordinary convolution and dilated convolution圖4 模塊普通卷積和空洞卷積的對(duì)比
對(duì)于一個(gè)Conv-mixed結(jié)構(gòu)的參數(shù)數(shù)量F(i,n)和運(yùn)算量Flops(i,n)的計(jì)算方法為:

其中,kl和kd指的是當(dāng)前卷積核的寬度和高度,Ni指的是上一層特征圖的通道數(shù)也就是輸入通道數(shù),Ni+1指的是輸出通道數(shù),b指的是偏置,hl和hd指的是輸出特征圖的寬度和高度。
2.2 逐層卷積代替全連接層
傳統(tǒng)的深度卷積神經(jīng)網(wǎng)絡(luò)在最后一個(gè)卷積之后使用全連接層(full connection,F(xiàn)C)將特征向量化進(jìn)行圖像分類,但是全連接層的參數(shù)量太大,在整個(gè)深度卷積神經(jīng)網(wǎng)絡(luò)中占的比重過多,一方面增加了計(jì)算量,另一方面容易導(dǎo)致過擬合。以用作“ImageNet”[14]分類任務(wù)的AlexNet為例,經(jīng)計(jì)算,整個(gè)網(wǎng)絡(luò)的參數(shù)數(shù)量有6.1×106,后面的3個(gè)全連接層參數(shù)量有5.86×106,可以說全連接層的計(jì)算量幾乎占據(jù)了整個(gè)網(wǎng)絡(luò)。雖然AlexNet之后的深度卷積神經(jīng)網(wǎng)絡(luò)(比如VGGNet、GoogleNet等)中全連接層的參數(shù)量占整個(gè)網(wǎng)絡(luò)的比重沒有這么多,是因?yàn)槎技由盍司W(wǎng)絡(luò)的深度,只增加了卷積層的數(shù)量,后面的全連接層并沒有增加,但是全連接層的參數(shù)量依然可觀。
為了解決這個(gè)問題,一種方法是在文獻(xiàn)《Network in Network》中提出的“GAP,Global Average Pooling”方法,在最后一個(gè)卷積層之后使用1×1的卷積縮小通道數(shù),然后對(duì)每個(gè)feature map求平均,再進(jìn)行softmax,以極小的計(jì)算量達(dá)到全連接層的準(zhǔn)確率。雖然使用了GAP的深度卷積神經(jīng)網(wǎng)絡(luò)計(jì)算量減少了,也減輕了過擬合,但是整個(gè)網(wǎng)絡(luò)的收斂速度減慢了。
另一種方法是Long等人[15]在語(yǔ)義分割的任務(wù)中提出的“全卷積網(wǎng)絡(luò)(fully convolutional networks,F(xiàn)CN)”中將全連接層轉(zhuǎn)換為卷積層,例如圖5所示的全連接層,假設(shè)深度卷積神經(jīng)網(wǎng)絡(luò)的最后一個(gè)卷積層的輸出特征圖的尺寸大小為12×12×96,全連接層的第一個(gè)隱藏層和第二個(gè)隱藏層的節(jié)點(diǎn)數(shù)都為1 000,一共需要分為100個(gè)類。在連接第一個(gè)隱藏層時(shí),需要將特征圖拉伸成一個(gè)長(zhǎng)度為13 824的一維向量,再和隱藏層進(jìn)行全連接,再進(jìn)行最后的分類。但是FCN中將全連接轉(zhuǎn)換為卷積層時(shí),如圖6所示,直接用內(nèi)核為12×12的大型卷積核、通道數(shù)為1 000的卷積層,將輸出的特征圖變?yōu)?×1×1 000,同樣的,在連接第二個(gè)隱藏層時(shí),直接用上一層的輸出特征的寬度×高度的內(nèi)核、通道數(shù)為1 000的卷積層代替,這樣就可以達(dá)到全連接層直接轉(zhuǎn)換為卷積層的效果。

Fig.5 Full connection layers(The number of parameters is 1.5×106)圖5 全連接層(參數(shù)數(shù)量為1.5×106)

Fig.6 Full connection layers is converted to convolutional layer in FCN圖6 FCN中將全連接層轉(zhuǎn)換為卷積層
因?yàn)榫矸e層共享了大量的計(jì)算,權(quán)值和偏置有自己的范圍,所以轉(zhuǎn)換為卷積層后加快了整個(gè)網(wǎng)絡(luò)的運(yùn)算速度。參數(shù)數(shù)量仍為1.5×106。一個(gè)全連接層轉(zhuǎn)換為卷積層的參數(shù)計(jì)算方法如下:

式中,kl和kd指的是卷積核的長(zhǎng)度和寬度,Ni指的是通道數(shù),b指的是偏置。因?yàn)檗D(zhuǎn)換為卷積層的參數(shù)數(shù)量和全連接層的參數(shù)數(shù)量是相等的,雖然整個(gè)網(wǎng)絡(luò)的學(xué)習(xí)能力變強(qiáng)了,但是參數(shù)數(shù)量并沒有減少,因此提出了“多個(gè)小型卷積逐層縮小特征圖代替全連接層”的方法,如圖7所示。
與圖6中的全連接層直接轉(zhuǎn)換為卷積層相比,層數(shù)越深,輸出的特征圖的尺寸越小。在卷積層中,卷積核對(duì)特征圖進(jìn)行局部窗口滑動(dòng)做濾波操作,因?yàn)樯鲜鯢CN中提到的方法是直接使用和輸出特征圖“寬度×高度”一樣尺寸的卷積核,那么就只有一個(gè)窗口作用于全部區(qū)域,但是參數(shù)和運(yùn)算量都沒有變,實(shí)際上效果等效于全連接層,而逐層使用小型卷積層,提取的都是特征圖局部區(qū)域的特征,是所有的濾波器對(duì)局部區(qū)域分別進(jìn)行卷積操作,是真正意義上的“卷積層代替全連接層”,并且計(jì)算量更小,收斂更快,參數(shù)量更少,僅有2.5×105,只有全連接層的1/6。

Fig.7 Multiple small convolution stacks instead of full connections(The number of parameters is 2.5×105)圖7 多個(gè)小型卷積堆疊代替全連接(參數(shù)數(shù)量為2.5×105)
2.3 Width-MixedNet架構(gòu)
經(jīng)過初步實(shí)驗(yàn),圖8是本文設(shè)計(jì)的深度卷積神經(jīng)網(wǎng)絡(luò)架構(gòu)Width-MixedNet。
在Conv-mixed結(jié)構(gòu)之前,先使用了少量的普通卷積和最大池化,這樣做可以用少量的計(jì)算將特征進(jìn)行跨通道的組合,增加輸出通道。為了能使整個(gè)網(wǎng)絡(luò)的參數(shù)盡可能得少,優(yōu)化Width-MixedNet架構(gòu)時(shí),在Conv-mixed合并多通道的特征圖后面使用了多個(gè)1×1的卷積,這樣可以把同一空間位置但是不同通道的特征組合在一起,同時(shí)可以用很小的計(jì)算量增加一層非線性化。在輸出通道數(shù)相同的情況下,1×1卷積的參數(shù)量只有3×3卷積參數(shù)量的1/9、5×5的卷積參數(shù)量的1/25。
在最后的Conv-mixed結(jié)構(gòu)之后是本文設(shè)計(jì)的多個(gè)小型卷積層堆疊代替全連接層,作為最后的特征提取。AlexNet、VGGNet、InceptionNet等大型卷積神經(jīng)網(wǎng)絡(luò)在卷積層的特征提取中,特征圖的寬度和高度都在減小,通道數(shù)增加,設(shè)計(jì)的多個(gè)小型卷積層的目標(biāo)是將特征圖的寬度和高度縮小到1×1、通道數(shù)接近于甚至等于分類類別數(shù)。為了能使網(wǎng)絡(luò)的參數(shù)數(shù)量和計(jì)算量少并且能夠保證分類準(zhǔn)確率的情況下,2×2、1×3和3×1等尺寸的卷積內(nèi)核會(huì)使網(wǎng)絡(luò)的層數(shù)變多,導(dǎo)致計(jì)算量過大,并且過擬合,5×5的卷積內(nèi)核單個(gè)卷積層的參數(shù)數(shù)量大,導(dǎo)致?lián)p失函數(shù)收斂慢,需要更多的訓(xùn)練時(shí)間。初步實(shí)驗(yàn)證明,3×3和4×4的卷積最為合適。
3 實(shí)驗(yàn)與分析
為了驗(yàn)證本文提出的深度卷積神經(jīng)網(wǎng)絡(luò)架構(gòu)的性能,分別在數(shù)據(jù)集MNIST、CIFAR-10和CIFAR-100進(jìn)行測(cè)試,實(shí)驗(yàn)使用GTX1080Ti單個(gè)GPU,實(shí)驗(yàn)環(huán)境TensorFlow1.4.0。采用整個(gè)網(wǎng)絡(luò)的參數(shù)數(shù)量和正確率對(duì)模型進(jìn)行評(píng)價(jià),并驗(yàn)證多個(gè)小型卷積逐層縮小特征圖代替全連接層的性能。
3.1 CIFAR-10數(shù)據(jù)集
CIFAR-10數(shù)據(jù)集共有60 000張彩色圖像,圖像的尺寸為32×32,分為10類,每類由5 000張訓(xùn)練樣本和1 000張測(cè)試樣本組成。在樣本訓(xùn)練時(shí),先對(duì)圖像進(jìn)行預(yù)處理,對(duì)每張圖片進(jìn)行隨機(jī)翻轉(zhuǎn),設(shè)置隨機(jī)的亮度和對(duì)比度,對(duì)圖像隨機(jī)剪切成長(zhǎng)度×寬度為28×28的大小,獲得更多的帶噪聲的樣本,擴(kuò)充樣本容量。
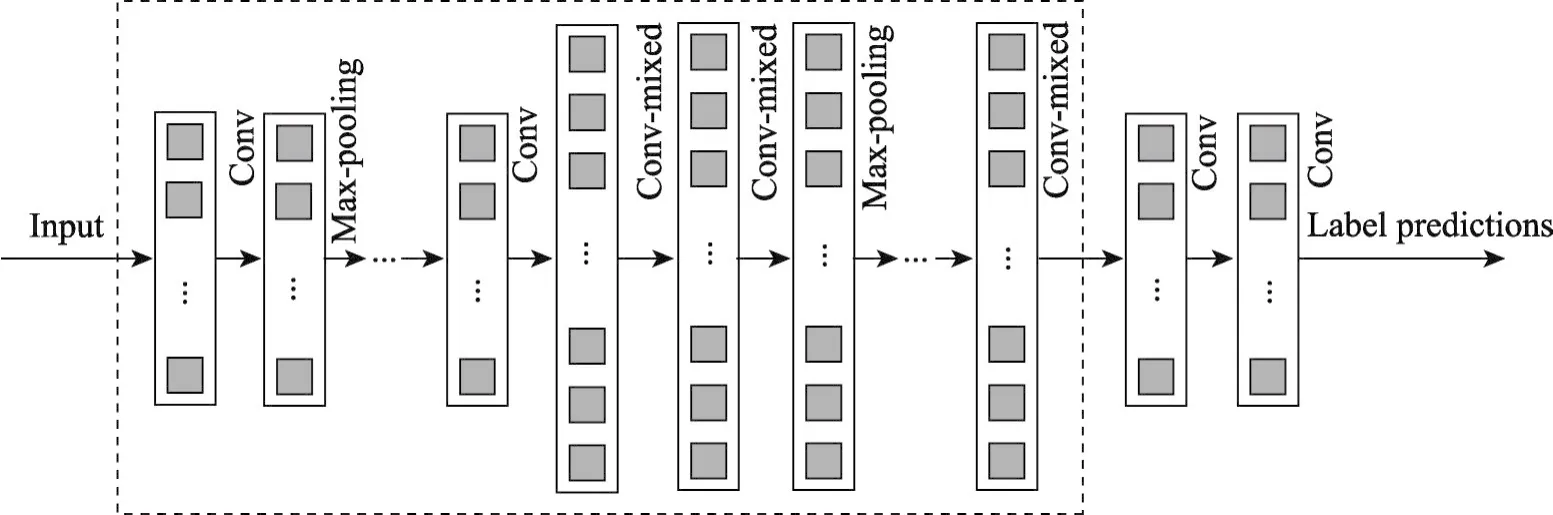
Fig.8 Deep convolutional neural network architecture Width-MixedNet圖8 深度卷積神經(jīng)網(wǎng)絡(luò)架構(gòu)Width-MixedNet

Table 1 Width-MixedNet parameters in CIFAR-10表1 在CIFAR-10中Width-MixedNet的參數(shù)
在CIFAR-10數(shù)據(jù)集中,使用的深度卷積神經(jīng)網(wǎng)絡(luò)框架如表1所示,表1介紹了Width-MixedNet的普通卷積(conv)、最大池化(maxpool)和Conv-mixed的詳細(xì)參數(shù),如第三列是每一層輸出尺寸的寬度、高度和通道數(shù)的乘積;第四列Filter size/Stride表示普通卷積和最大池化的內(nèi)核尺寸和步長(zhǎng);Conv-mixed的基本參數(shù)(參照?qǐng)D3)在第五列Feature maps(Convmixed)中;最后一列Parameters列出了每一層的參數(shù)數(shù)量。初步實(shí)驗(yàn)表明,對(duì)于輸入圖像數(shù)據(jù),在前兩層使用較大的內(nèi)核如7×7和5×5的普通卷積對(duì)圖像處理,會(huì)使分類精度提高0.5%~1%,另外在Conv-mixed中使用較大的內(nèi)核,只能將精度提高0.3%~0.7%,但是會(huì)讓整體參數(shù)量提高1倍。在表1的框架中,整體參數(shù)只有3.4×105,主要參數(shù)集中在最后兩個(gè)Convmixed和代替全連接的第一個(gè)conv中,約占了整個(gè)網(wǎng)絡(luò)參數(shù)數(shù)量的56%。
表2顯示了使用的深度卷積神經(jīng)網(wǎng)絡(luò)Width-MixedNet和其他深度卷積神經(jīng)網(wǎng)絡(luò)在CIFAR-10數(shù)據(jù)集上參數(shù)數(shù)量和準(zhǔn)確率的對(duì)比,實(shí)驗(yàn)表明Width-MixedNet在參數(shù)規(guī)模遠(yuǎn)低于其他深度卷積神經(jīng)網(wǎng)絡(luò)的情況下,準(zhǔn)確率能達(dá)到較高水平。其中與SqueezeNet和FitNet相比,Width-MixedNet在準(zhǔn)確率和參數(shù)規(guī)模上都有較大優(yōu)勢(shì);與WideResNet(d=16,k=8)相比,雖然WideResNet的準(zhǔn)確率高出2.17個(gè)百分點(diǎn),但是本文的參數(shù)規(guī)模僅有WideResNet的1/30。

Table 2 Comparative evaluation results on CIFAR-10表2 CIFAR-10對(duì)比實(shí)驗(yàn)結(jié)果
3.2 CIFAR-100數(shù)據(jù)集
CIFAR-100數(shù)據(jù)集和CIFAR-10數(shù)據(jù)集的組成方式基本一致,圖片的大小和格式相同,但是CIFAR-100有100類,每一類的訓(xùn)練樣本和測(cè)試樣本都只有CIFAR-10的1/10,識(shí)別難度更大。在實(shí)驗(yàn)中,使用的架構(gòu)和參數(shù)與CIFAR-10實(shí)驗(yàn)一致,只是在每個(gè)卷積層之后增加了Batch Normalization[20]正則化處理,并調(diào)整了batch大小和迭代次數(shù)。實(shí)驗(yàn)結(jié)果如表3所示,實(shí)驗(yàn)表明,Width-MixedNet在參數(shù)規(guī)模遠(yuǎn)低于其他網(wǎng)絡(luò)結(jié)構(gòu)的情況下,可以達(dá)到更高的識(shí)別準(zhǔn)確率。
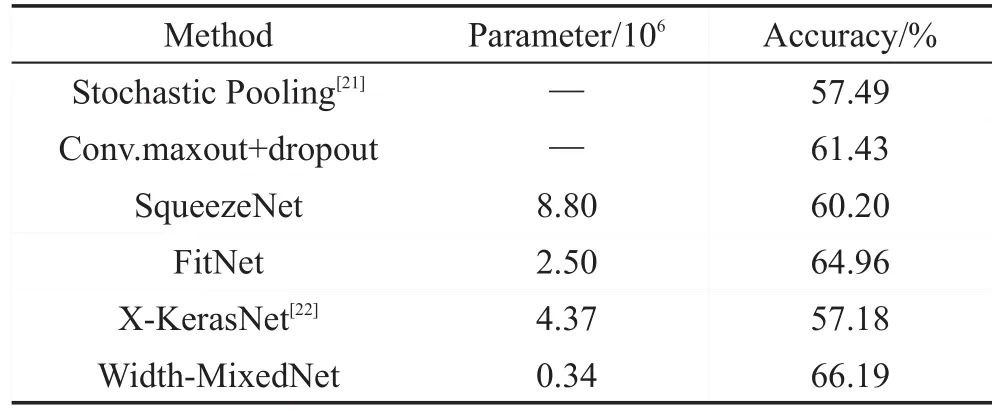
Table 3 Comparative evaluation results on CIFAR-100表3 CIFAR-100對(duì)比實(shí)驗(yàn)結(jié)果
3.3 MNIST數(shù)據(jù)集
MNIST數(shù)據(jù)集是由60 000張訓(xùn)練樣本和10 000張測(cè)試樣本組成的手寫字體圖像數(shù)據(jù)集,每個(gè)樣本為28×28大小的二值圖像,MNIST識(shí)別任務(wù)相對(duì)簡(jiǎn)單,為了使整個(gè)網(wǎng)絡(luò)的參數(shù)數(shù)量盡可能得少,在實(shí)驗(yàn)CIFAR-10的結(jié)構(gòu)基礎(chǔ)上縮減了普通卷積(conv)和Conv-mixed的數(shù)量和卷積核的通道數(shù)。為了能使實(shí)驗(yàn)結(jié)果更直觀,在表4中使用測(cè)試集的錯(cuò)誤率作對(duì)比,實(shí)驗(yàn)表明,Width-MixedNet在參數(shù)數(shù)量較少的情況下,有更好的識(shí)別率。

Table 4 Comparative evaluation results on MNIST表4 MNIST對(duì)比實(shí)驗(yàn)結(jié)果
3.4 卷積層代替全連接層
為了驗(yàn)證多個(gè)小型卷積逐層縮小特征圖代替全連接層的性能,在MNIST和CIFAR-10數(shù)據(jù)集上,分別比較了直接使用全連接層進(jìn)行最后的特征提取的Width-MixedNet-FC、將卷積層直接轉(zhuǎn)換為全連接層的Width-MixedNet-FCN和多個(gè)小型卷積層代替全連接層的Width-MixedNet-CNNs在交叉熵?fù)p失函數(shù)Loss、訓(xùn)練每個(gè)batch的平均耗時(shí)和測(cè)試數(shù)據(jù)集平均每張圖片的耗時(shí)。通過TensorBoard得到TensorFlow的可視化結(jié)果,TensorBoard的效果圖通過Chrome瀏覽器查看,為了使實(shí)驗(yàn)結(jié)果更直觀,折線圖進(jìn)行了相應(yīng)的平滑處理。
該實(shí)驗(yàn)中MNIST數(shù)據(jù)集每個(gè)batch大小為50,迭代1 500次,CIFAR-10數(shù)據(jù)集每個(gè)batch大小為128,迭代5 000次。如圖9和圖10的折線圖所示,Width-MixedNet-CNNs交叉熵?fù)p失Loss下降速度最快,值最小,效果最好;Width-MixedNet-FC交叉熵?fù)p失Loss下降速度最慢,雖然Width-MixedNet-FC和Width-MixedNet-FCN的參數(shù)數(shù)量相同,但是Width-MixedNet-FCN的表現(xiàn)能力和學(xué)習(xí)能力更強(qiáng)。不同的網(wǎng)絡(luò)結(jié)構(gòu)訓(xùn)練每個(gè)batch的時(shí)間、測(cè)試每張圖片的時(shí)間和測(cè)試的準(zhǔn)確率如表5和表6所示,實(shí)驗(yàn)表明,Width-MixedNet-CNNs訓(xùn)練每個(gè)batch的時(shí)間最短,測(cè)試每張圖片的時(shí)間最短,同時(shí)達(dá)到更高的準(zhǔn)確率。

Fig.9 Cross entropy loss function of CIFAR-10圖9 CIFAR-10的交叉熵?fù)p失函數(shù)的折線圖
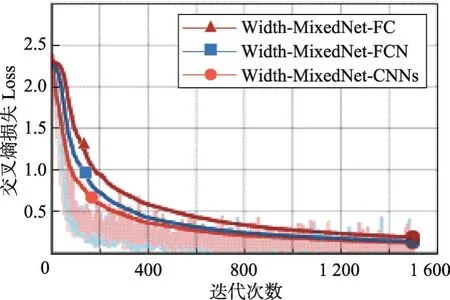
Fig.10 Cross entropy loss function of MNIST圖10 MNIST的交叉熵?fù)p失函數(shù)的折線圖
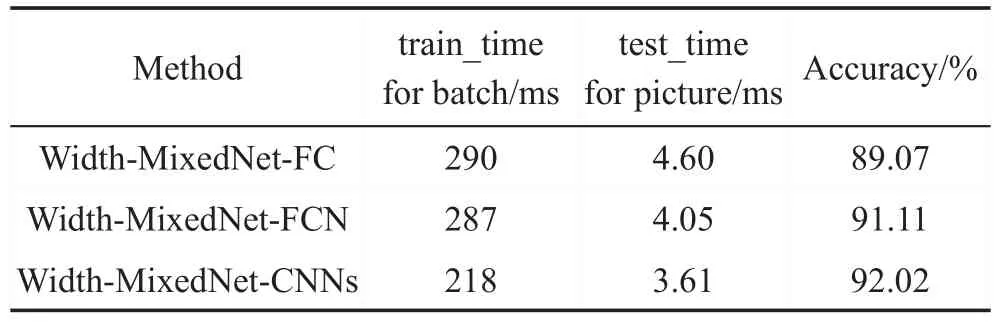
Table 5 Comparison of running time of CIFAR-10表5 CIFAR-10的運(yùn)行時(shí)間對(duì)比

Table 6 Comparison of running time of MNIST表6 MNIST的運(yùn)行時(shí)間對(duì)比
為了驗(yàn)證多個(gè)小型卷積逐層縮小特征圖代替全連接層時(shí)網(wǎng)絡(luò)參數(shù)的減少對(duì)算法的影響,在CIFAR-10數(shù)據(jù)集上,分別比較了將卷積層直接轉(zhuǎn)換為全連接層的Width-MixedNet-FCN和不同尺寸的小型卷積層在交叉熵?fù)p失函數(shù)Loss、訓(xùn)練集的準(zhǔn)確率training accuracy和測(cè)試集的準(zhǔn)確率test accuracy。在實(shí)驗(yàn)中,對(duì)Width-MixedNet的結(jié)構(gòu)進(jìn)行了微調(diào),去掉了最后一個(gè)maxpool層,并且使最后的輸出特征圖變成12×12×96,隨著迭代次數(shù)的增加,在實(shí)驗(yàn)中Loss逐漸穩(wěn)定在一個(gè)極小的區(qū)間內(nèi),不利于觀察,為了使實(shí)驗(yàn)結(jié)果更為直觀,將迭代次數(shù)設(shè)為1 500,并且對(duì)折線圖進(jìn)行了相應(yīng)的平滑處理。實(shí)驗(yàn)結(jié)果Loss折線圖如圖11所示。

Fig.11 Cross entropy loss function of CIFAR-10圖11 CIFAR-10的交叉熵?fù)p失函數(shù)的折線圖
表7顯示了將卷積層直接轉(zhuǎn)換為全連接層的Width-MixedNet-FCN和多個(gè)小型卷積層代替全連接層的Width-MixedNet-1、2、3、4在CIFAR-10數(shù)據(jù)集上的對(duì)比,其中Filter/Stride表示卷積核的寬度和高度的乘積以及步長(zhǎng),F(xiàn)eature maps/Padding表示輸出通道數(shù)和是否填充,Training accuracy和Test accuracy表示訓(xùn)練集和測(cè)試集的準(zhǔn)確率。Width-MixedNet-FCN最后由全連接層直接轉(zhuǎn)換的2個(gè)卷積層的參數(shù)數(shù)量達(dá)到了13.9×106,并且訓(xùn)練集的準(zhǔn)確率高于測(cè)試集的準(zhǔn)確率,說明Width-MixedNet-FCN的學(xué)習(xí)能力較差于其他結(jié)構(gòu),并且有過擬合的傾向。由圖11可以看出,Width-MixedNet-FCN的交叉熵?fù)p失函數(shù)Loss的值較大,下降速度較慢。Width-MixedNet-4最后的特征提取是由一個(gè)內(nèi)核為4×4、步長(zhǎng)為4和一個(gè)內(nèi)核為3×3、步長(zhǎng)為1的卷積層組成,其參數(shù)數(shù)量為1.2×105,效果最好。Width-MixedNet-1、2、3、4的測(cè)試集準(zhǔn)確率都高于訓(xùn)練集準(zhǔn)確率,并且準(zhǔn)確率都高于Width-MixedNet-FCN,說明多個(gè)小型卷積層疊加代替全連接層的方法效果更好。

Table 7 Comparative evaluation results on CIFAR-10表7 CIFAR-10的對(duì)比實(shí)驗(yàn)結(jié)果
4 結(jié)束語(yǔ)
本文針對(duì)現(xiàn)有的深度神經(jīng)網(wǎng)絡(luò)參數(shù)數(shù)量過于龐大的問題,分析了現(xiàn)有的深度神經(jīng)網(wǎng)絡(luò)的不同結(jié)構(gòu),設(shè)計(jì)了一種緊湊型的高效深度卷積神經(jīng)網(wǎng)絡(luò)架構(gòu)Width-MixedNet,其多種不同卷積層組成多分支的基本模塊Conv-mixed,在卷積神經(jīng)網(wǎng)絡(luò)的寬度上進(jìn)行擴(kuò)充,提高了網(wǎng)絡(luò)在同一層中提取不同特征的能力,并且在深度神經(jīng)網(wǎng)絡(luò)的最后分類任務(wù)中,改進(jìn)了FCN中將全連接層直接轉(zhuǎn)換為卷積層的方法,使用多個(gè)小型卷積層逐層縮小特征圖的規(guī)模的方法代替全連接層,進(jìn)一步減少了網(wǎng)絡(luò)的參數(shù)數(shù)量,提高了網(wǎng)絡(luò)的表現(xiàn)能力和學(xué)習(xí)能力。實(shí)驗(yàn)結(jié)果表明,Width-MixedNet在參數(shù)規(guī)模遠(yuǎn)低于其他深度卷積神經(jīng)網(wǎng)絡(luò)的情況下,可以達(dá)到更好的效果。
本文提出的緊湊型結(jié)構(gòu)Width-MixedNet,其學(xué)習(xí)能力強(qiáng)、參數(shù)規(guī)模小的特點(diǎn)適合部署移動(dòng)平臺(tái),例如可穿戴設(shè)備、智能家具和無(wú)人機(jī)上。之后的工作中,將進(jìn)一步研究Width-MixedNet在目標(biāo)檢測(cè)、圖像分割等領(lǐng)域中的表現(xiàn)和Width-MixedNet部署在移動(dòng)設(shè)備上的可行性。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年11期)2020-12-14 06:59:52
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學(xué))(2019年6期)2019-10-10 01:01:50
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
藝術(shù)品鑒證.中國(guó)藝術(shù)金融(2018年8期)2019-01-14 01:14:28
藝術(shù)品鑒證.中國(guó)藝術(shù)金融(2018年10期)2019-01-08 02:44:26
藝術(shù)品鑒證.中國(guó)藝術(shù)金融(2018年12期)2018-08-26 06:03:48
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
