基于混合采樣的非平衡數(shù)據(jù)分類算法*
2019-02-13 06:59:32吳藝凡梁吉業(yè)王俊紅
計(jì)算機(jī)與生活 2019年2期
吳藝凡,梁吉業(yè)+,王俊紅
1.山西大學(xué) 計(jì)算機(jī)與信息技術(shù)學(xué)院,太原 030006
2.山西大學(xué) 計(jì)算智能與中文信息處理教育部重點(diǎn)實(shí)驗(yàn)室,太原 030006
1 引言
大數(shù)據(jù)時(shí)代的到來(lái)使得基于數(shù)據(jù)的知識(shí)獲取成為可能,促進(jìn)了數(shù)據(jù)密集型科學(xué)的發(fā)展。分類是機(jī)器學(xué)習(xí)和數(shù)據(jù)挖掘中重要的信息獲取手段之一,但傳統(tǒng)的分類算法沒(méi)有考慮數(shù)據(jù)的平衡性,在非平衡分類問(wèn)題上仍面臨著巨大挑戰(zhàn)。例如在醫(yī)療診斷[1]、網(wǎng)絡(luò)入侵檢測(cè)[2]等問(wèn)題中,關(guān)注的事件在所有數(shù)據(jù)記錄中占比都極小,但是將其錯(cuò)誤分類卻會(huì)帶來(lái)無(wú)法估量的代價(jià)。將數(shù)量占多數(shù)的類稱為多數(shù)類,占少數(shù)的類稱為少數(shù)類,在非平衡數(shù)據(jù)中對(duì)少數(shù)類的正確分類往往比多數(shù)類更有價(jià)值。例如在癌癥檢測(cè)領(lǐng)域中,健康人的數(shù)量遠(yuǎn)大于患病人的數(shù)量,但更注重對(duì)真正患病人的識(shí)別率。因此如何對(duì)非平衡數(shù)據(jù)集進(jìn)行正確分類,提高少數(shù)類的分類精度成為分類問(wèn)題中的一個(gè)難點(diǎn)[3]。并且多類問(wèn)題通常可以簡(jiǎn)化為兩類問(wèn)題來(lái)解決,因此非平衡數(shù)據(jù)集分類問(wèn)題的研究重點(diǎn)也就轉(zhuǎn)化為提高兩類問(wèn)題中的少數(shù)類的分類性能[4]。
目前,國(guó)內(nèi)外學(xué)者對(duì)非平衡數(shù)據(jù)分類問(wèn)題的常用策略大致分為算法層面的方法和數(shù)據(jù)層面的方法。算法層面主要有代價(jià)敏感學(xué)習(xí)[5]、集成學(xué)習(xí)[6-7]、特征選擇[8]、單類別學(xué)習(xí)[9]等方法。數(shù)據(jù)層面最常用的方法是數(shù)據(jù)采樣技術(shù),主要包括三種:過(guò)采樣、欠采樣和混合采樣。本文重點(diǎn)關(guān)注數(shù)據(jù)層面的研究進(jìn)展。
過(guò)采樣中比較經(jīng)典的算法是Chawla等人[10]提出的 SMOTE(synthetic minority over-sampling technique)算法,其基本思想是:距離較近的少數(shù)類之間的樣本仍然是少數(shù)類,在距離較近的兩個(gè)少數(shù)類樣本之間通過(guò)線性插值的方式產(chǎn)生一個(gè)新的少數(shù)類樣本,使得少數(shù)類樣本增加,達(dá)到平衡數(shù)據(jù)集的目的。實(shí)驗(yàn)結(jié)果表明SMOTE算法顯著提高了少數(shù)類的分類精度,但是SMOTE算法是對(duì)所有少數(shù)類樣本盲目地進(jìn)行過(guò)采樣,容易生成很多不重要的少數(shù)類樣本。Han等人提出的Borderline-SMOTE[11]算法,認(rèn)為處在邊界上的少數(shù)類更容易被錯(cuò)分,對(duì)分類器的性能起到更重要的作用,因此對(duì)樣本周圍多數(shù)類較多的少數(shù)類樣本用SMOTE過(guò)采樣。
欠采樣中較為簡(jiǎn)單的方法是隨機(jī)欠采樣,指隨機(jī)刪掉一些多數(shù)類樣本以平衡數(shù)據(jù)集,該方法操作簡(jiǎn)單,但容易刪去一些有用的多數(shù)類樣本造成信息丟失。Tomeklinks[12]方法認(rèn)為能構(gòu)成Tomeklinks對(duì)的樣本中,某個(gè)樣本可能為噪聲樣本或在兩類樣本的邊界上,將其中的多數(shù)類樣本刪去,從而達(dá)到欠采樣的目的。
使用單一的采樣算法如只使用過(guò)采樣容易造成分類器過(guò)擬合,只使用欠采樣容易導(dǎo)致樣本信息丟失。混合采樣同時(shí)采用過(guò)采樣和欠采樣技術(shù),在解決上述問(wèn)題的同時(shí)提高了少數(shù)類的分類精度。傳統(tǒng)的混合采樣中表現(xiàn)較為出色的有SMOTE+Tomek links方法[13],在使用SMOTE對(duì)少數(shù)類樣本上采樣的同時(shí),刪除多數(shù)類樣本中的Tomek links對(duì),還有SMOTE+ENN(edit nearest neighbor)方法等。這些方法都是基于樣本之間的距離的,Song等人[14]提出基于聚類的混合采樣算法(bi-directional sampling based onK-means,BDSK),該算法將SMOTE過(guò)采樣算法與基于K-means的欠采樣算法相結(jié)合,在增加少數(shù)類樣本的同時(shí)有效地刪去噪聲樣本。上述混合采樣的方法都是基于距離或者聚類的,沒(méi)有考慮到?jīng)Q策邊界對(duì)樣本的影響。Veropoulos等人提出了代價(jià)敏感訓(xùn)練算法[15],通過(guò)賦予錯(cuò)分的正負(fù)類樣本不同的懲罰系數(shù)來(lái)降低分類超平面的偏移度,此方法簡(jiǎn)單易行并且具有一定效果。然而,當(dāng)少數(shù)類樣本過(guò)分稀疏時(shí),采用此方法會(huì)因分類超平面過(guò)分?jǐn)M合少數(shù)類樣本而影響分類效果。Jian等人[16]提出的基于不同貢獻(xiàn)度的采樣算法(different contribution sampling,DCS),認(rèn)為支持向量是更靠近決策邊界的樣本,貢獻(xiàn)度更高,因此針對(duì)支持向量和非支持向量采用混合采樣方法,即使用SMOTE和隨機(jī)欠采樣技術(shù)來(lái)分別對(duì)少數(shù)類樣本中的支持向量和多數(shù)類樣本中的非支持向量進(jìn)行重新采樣。該方法雖然考慮到?jīng)Q策邊界的影響,但沒(méi)有考慮到被錯(cuò)分的少數(shù)類樣本更靠近真實(shí)類邊界,對(duì)分類器的性能起到重要作用,并且對(duì)多數(shù)類樣本進(jìn)行隨機(jī)欠采樣有可能會(huì)刪去一些重要的樣本。
為了克服采樣算法的盲目性以及支持向量機(jī)算法(support vector machine,SVM)在處理非平衡數(shù)據(jù)時(shí)分類超平面容易偏向少數(shù)類樣本的問(wèn)題,本文提出了一種基于SVM分類超平面的混合采樣算法(hybrid sampling algorithm based on SVM,SVM_HS),旨在利用SVM分類超平面找出較為重要的少數(shù)類樣本和不重要的多數(shù)類樣本,對(duì)這些樣本進(jìn)行過(guò)采樣和欠采樣,達(dá)到平衡數(shù)據(jù)集的目的。在UCI數(shù)據(jù)集上進(jìn)行實(shí)驗(yàn)并與其他重采樣算法進(jìn)行比較,實(shí)驗(yàn)結(jié)果顯示SVM_HS算法的F-value和G-mean值均有較大提高,在處理非平衡數(shù)據(jù)分類問(wèn)題上具有一定優(yōu)勢(shì)。
2 相關(guān)工作
本文算法是基于SVM分類超平面的混合采樣算法,因此首先將從SVM算法思想和超平面偏移問(wèn)題以及混合采樣中用到的采樣算法兩方面進(jìn)行介紹。
2.1 SVM算法
20世紀(jì)90年代Vapnik提出了SVM支持向量機(jī)算法[17],以結(jié)構(gòu)風(fēng)險(xiǎn)最小化為原則,同時(shí)考慮到置信范圍和經(jīng)驗(yàn)風(fēng)險(xiǎn),克服了分類器過(guò)學(xué)習(xí)、高維數(shù)、非線性和局部極值點(diǎn)等一系列問(wèn)題。目前在機(jī)器學(xué)習(xí)領(lǐng)域中成為一個(gè)新的研究熱點(diǎn)。
SVM的基本原理是尋找一個(gè)最優(yōu)分類超平面,使得該超平面在保證分類精度的同時(shí)能夠使超平面兩側(cè)的空白區(qū)域最大化。設(shè)訓(xùn)練樣本集為T={(xi,yi),i=1,2,…,l},xi∈Rm,yi∈{-1,1},超平面記作ωT?φ(x)+b=0,求解最優(yōu)分類超平面可轉(zhuǎn)化為二次優(yōu)化問(wèn)題:

約束條件為:
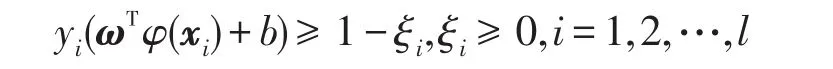
其中,ξi為松弛因子,C>0為誤分樣本的懲罰系數(shù)。用Lagrange乘子法可獲得式(2)的對(duì)偶問(wèn)題:
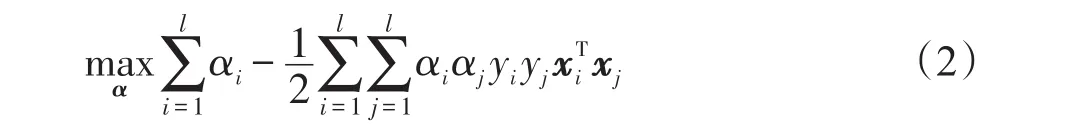
約束條件為:

其中,αi為L(zhǎng)agrange乘子。設(shè)k(xi,xj)為核函數(shù),它對(duì)應(yīng)非線性映射φ。那么SVM訓(xùn)練出來(lái)的分類判別式為:

但在利用SVM算法進(jìn)行分類時(shí),是建立在正負(fù)類數(shù)據(jù)樣本數(shù)量大致持平的情況下,當(dāng)樣本數(shù)量不平衡時(shí),分類超平面會(huì)偏向少數(shù)類。下面分別通過(guò)兩組實(shí)驗(yàn)數(shù)據(jù)進(jìn)行分析驗(yàn)證,兩組數(shù)據(jù)樣本正負(fù)比分別為1∶1和1∶10,其他參數(shù)包括高斯核寬度為10,懲罰系數(shù)C為100,實(shí)驗(yàn)結(jié)果分別如圖1和圖2所示。
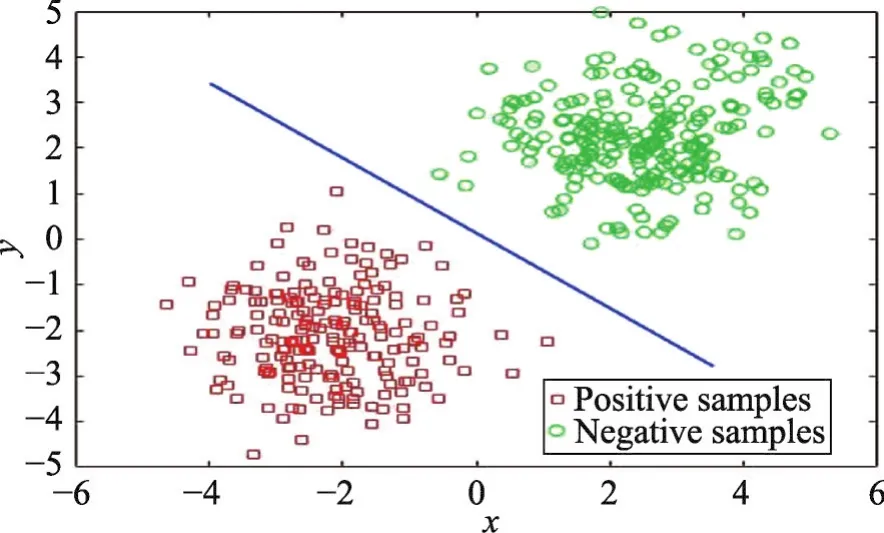
Fig.1 Hyperplane of balanced dataset圖1 平衡數(shù)據(jù)集的分類超平面
可以發(fā)現(xiàn),當(dāng)數(shù)據(jù)平衡時(shí),SVM分類超平面完美地位于正負(fù)樣本中間,當(dāng)正負(fù)樣本出現(xiàn)嚴(yán)重失衡時(shí),分類器的分類性能就會(huì)下降,為了使超平面兩側(cè)的空白區(qū)域最大化且獲得較高的分類精度,分類超平面會(huì)偏向少數(shù)類。因此為了使超平面向真實(shí)類邊界靠近,需要改變非平衡數(shù)據(jù)集的分布情況。

Fig.2 Hyperplane of unbalanced dataset圖2 非平衡數(shù)據(jù)集的分類超平面
2.2 SMOTE算法
SMOTE算法基本思想是:在距離較近的兩個(gè)少數(shù)類樣本之間通過(guò)線性插值的方式產(chǎn)生一個(gè)新的少數(shù)類樣本,使得少數(shù)類樣本增加,達(dá)到平衡數(shù)據(jù)集的目的。整體算法如算法1所示。
算法1SMOTE算法

3 基于混合采樣的非平衡數(shù)據(jù)分類算法
從相關(guān)研究中可以知道[15-17],傳統(tǒng)的SVM算法對(duì)非平衡數(shù)據(jù)集進(jìn)行分類時(shí),訓(xùn)練所得的分類超平面會(huì)偏向少數(shù)類,被錯(cuò)分的少數(shù)類比分對(duì)的更靠近真實(shí)類邊界,對(duì)分類器的性能起到更重要的作用,因此對(duì)這些樣本進(jìn)行過(guò)采樣;而對(duì)于多數(shù)類來(lái)說(shuō),離分類超平面越遠(yuǎn),則對(duì)分類性能的影響越小,因此對(duì)離超平面較遠(yuǎn)的多數(shù)類樣本進(jìn)行欠采樣,進(jìn)而使SVM分類超平面向著真實(shí)類邊界方向偏移。
3.1 SVM_HS算法基本思想
給定一個(gè)樣本集,使用該集合訓(xùn)練出一個(gè)SVM分類器,被錯(cuò)誤分類的少數(shù)類樣本更為重要,是要進(jìn)行過(guò)采樣的集合對(duì)象;離分類超平面較遠(yuǎn)的多數(shù)類樣本相較于離超平面近的多數(shù)類樣本更為不重要,是要進(jìn)行欠采樣的集合對(duì)象。
設(shè)初始訓(xùn)練樣本集合為T,T=P?Q,其中P表示少數(shù)類樣本集合,Q表示多數(shù)類樣本集合。利用SVM對(duì)集合T進(jìn)行訓(xùn)練得到分類器為:
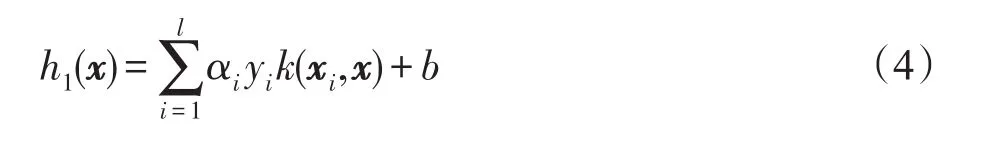
分類超平面為:

利用分類超平面可將少數(shù)類集合分為分對(duì)的集合P1和分錯(cuò)的集合P2。P2即為要進(jìn)行過(guò)采樣的對(duì)象,即:

對(duì)于集合Q,根據(jù)公式:

計(jì)算出所有多數(shù)類樣本點(diǎn)到超平面的距離r,然后根據(jù)采樣率得到較遠(yuǎn)的多數(shù)類樣本即為集合Q′。
在算法中,找到集合P2和集合Q′后,直接刪掉集合Q′,然后對(duì)集合P2使用SMOTE算法迭代進(jìn)行合成,將每次合成的新樣本加入到訓(xùn)練集中,在每次迭代后測(cè)試分類器的分類性能并使用G-mean值進(jìn)行比較,當(dāng)G-mean開始減小時(shí),迭代結(jié)束,即得到優(yōu)化后的分類器。根據(jù)算法思想可以看出,訓(xùn)練集將逐漸趨于平衡,使得SVM分類超平面慢慢向真實(shí)類邊界方向偏移直至最靠近真實(shí)類邊界。
3.2 迭代停止準(zhǔn)則
將一個(gè)原始數(shù)據(jù)集分為訓(xùn)練集和測(cè)試集,測(cè)試集不進(jìn)行任何操作,設(shè)訓(xùn)練集為T,集合T將訓(xùn)練SVM分類器并對(duì)T進(jìn)行混合采樣,重復(fù)此步驟。假設(shè)第t次迭代后得到的訓(xùn)練集合為X,使用集合X訓(xùn)練出新的分類器h(x)后,再使用集合X測(cè)試分類器h(x),并使用非平衡問(wèn)題中常用的評(píng)價(jià)標(biāo)準(zhǔn)幾何平均正確率G-mean值評(píng)價(jià)分類器的性能,若G-mean值逐漸增加,則說(shuō)明所訓(xùn)練出的分類器性能變好,迭代繼續(xù);若G-mean值減小,則結(jié)束迭代,選擇當(dāng)前訓(xùn)練出的分類器作為最優(yōu)分類器。
3.3 SVM_HS算法描述
SVM_HS的整體算法如算法2所示。
算法2SVM_HS算法

4 實(shí)驗(yàn)過(guò)程及結(jié)果分析
4.1 評(píng)價(jià)標(biāo)準(zhǔn)
對(duì)于分類問(wèn)題,一般使用分類精度作為標(biāo)準(zhǔn)來(lái)評(píng)價(jià)一個(gè)分類器的性能。但對(duì)于非平衡數(shù)據(jù)來(lái)說(shuō),由于傳統(tǒng)的分類算法更傾向于多數(shù)類樣本,僅僅使用準(zhǔn)確率評(píng)價(jià)非平衡數(shù)據(jù)分類算法是不合適的,反映不出對(duì)少數(shù)類樣本的分類性能。因此,非平衡數(shù)據(jù)的評(píng)價(jià)標(biāo)準(zhǔn)也是數(shù)據(jù)挖掘領(lǐng)域中一項(xiàng)重要的研究?jī)?nèi)容。目前常用的評(píng)價(jià)標(biāo)準(zhǔn)主要有F-value、G-mean等。
在二分類問(wèn)題中,常用的混淆矩陣[18-19]如表1所示。其中,TP表示少數(shù)類樣本被正確分類的數(shù)量,F(xiàn)N表示少數(shù)類樣本被錯(cuò)誤分類的數(shù)量,TN表示多數(shù)類樣本被正確分類的數(shù)量,F(xiàn)P表示多數(shù)類樣本被錯(cuò)誤分類的數(shù)量[20]。

Table 1 Confusion matrix of 2-class problem表1 二分類問(wèn)題中的混淆矩陣
由此可以得到:
(1)分類準(zhǔn)確率
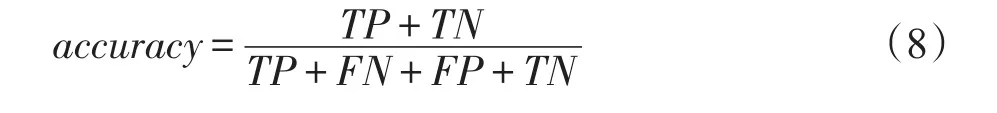
(2)查準(zhǔn)率

(3)查全率

(4)少數(shù)類的F-value[21]
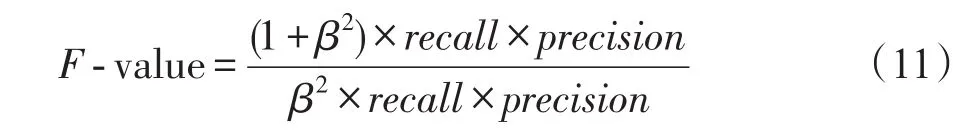
式中,β是調(diào)整查準(zhǔn)率和查全率所占比重的參數(shù),通常取β=1。
(5)幾何平均正確率G-mean[22]

本文選用accuracy、F-value、G-mean作為評(píng)價(jià)算法性能的標(biāo)準(zhǔn)。
4.2 數(shù)據(jù)集描述
為了評(píng)價(jià)本文提出的SVM_HS算法的有效性并與同類方法進(jìn)行對(duì)比,選用標(biāo)準(zhǔn)數(shù)據(jù)庫(kù)UCI中的8組非平衡數(shù)據(jù)集進(jìn)行實(shí)驗(yàn)和分析,選擇了不同平衡程度、不同樣本數(shù)量、不同領(lǐng)域的數(shù)據(jù)集進(jìn)行實(shí)驗(yàn),使得數(shù)據(jù)集更具代表性。由于UCI中二類不平衡數(shù)據(jù)集較少,這里可以將部分?jǐn)?shù)據(jù)集中的某些類別合并,形成二類不平衡數(shù)據(jù)集,例如,Segment數(shù)據(jù)集包含2 310個(gè)樣本,共有7個(gè)類別,可以將其中的第五類“window”作為少數(shù)類,而其余的所有類別進(jìn)行合并形成多數(shù)類,這樣就可以形成一個(gè)二類的不平衡數(shù)據(jù)集。通過(guò)此方式,對(duì)UCI中的部分其他數(shù)據(jù)集也進(jìn)行類似的修改,從而形成了需要的數(shù)據(jù)集。修改后的數(shù)據(jù)集詳細(xì)信息描述如表2所示。
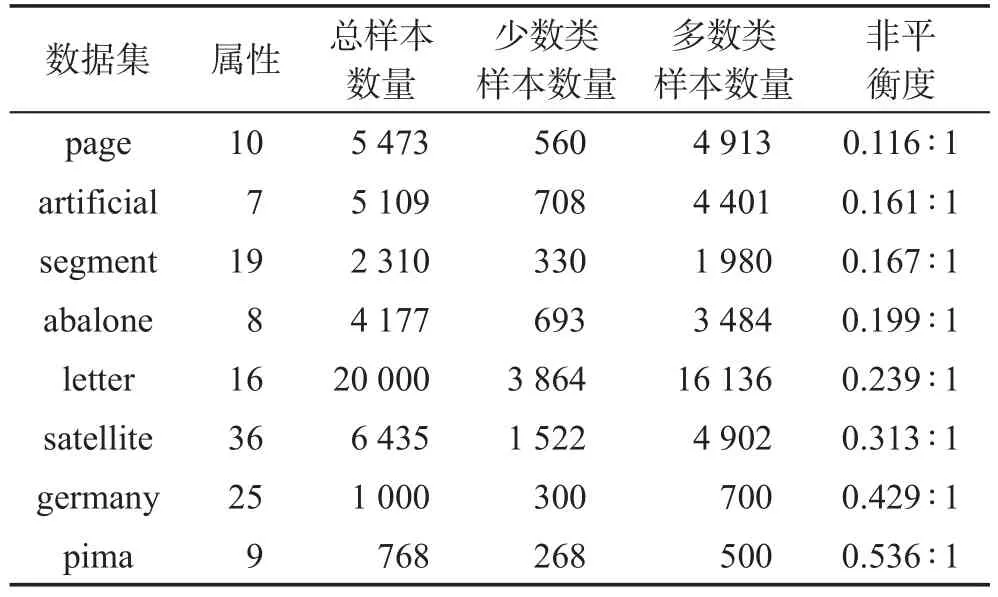
Table 2 Experimental datasets description表2 實(shí)驗(yàn)數(shù)據(jù)集描述
4.3 實(shí)驗(yàn)設(shè)計(jì)與結(jié)果分析
本實(shí)驗(yàn)采用十折交叉驗(yàn)證方法,使用Matlab作為仿真環(huán)境并將LIBSVM工具箱作為實(shí)現(xiàn)工具。
在SVM_HS算法中,需要輸入訓(xùn)練樣本集合T和每次迭代的采樣率δ,即少數(shù)類增加的百分比和多數(shù)類減少的百分比。由于需要迭代使得分類超平面逐漸趨于真實(shí)類邊界,因此每次采樣的樣本個(gè)數(shù)不宜太多,但為了排除人工的方法,為實(shí)驗(yàn)設(shè)置恰當(dāng)?shù)牟蓸勇剩疚倪x取了幾個(gè)采樣率的值即10%、20%、30%、40%進(jìn)行了實(shí)驗(yàn),使用3個(gè)數(shù)據(jù)集進(jìn)行測(cè)試,并利用非平衡分類問(wèn)題中的一般性評(píng)價(jià)標(biāo)準(zhǔn)F-value、G-mean進(jìn)行評(píng)估。如表3和表4所示,可以看出,當(dāng)采樣率為20%時(shí)F-value和G-mean的值普遍較高,因此本文將選取20%作為每次迭代實(shí)驗(yàn)中的采樣率。
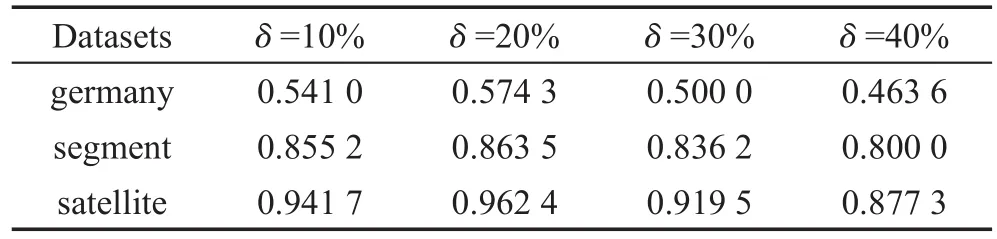
Table 3 F-value at different sampling rates表3 不同采樣率下的F-value

Table 4 G-mean at different sampling rates表4 不同采樣率下的G-mean
采樣率確定后,將本文算法SVM_HS與SVM算法、SMOTE+SVM算法和Borderline_SMOTE+SVM算法進(jìn)行比較,并對(duì)accuracy、F-value、G-mean等評(píng)價(jià)指標(biāo)進(jìn)行分析。算法參數(shù)設(shè)置如下:支持向量機(jī)分類器選擇高斯核函數(shù),核寬度為10,懲罰因子C為1 000,算法中SMOTE最近鄰參數(shù)k選取為6,采樣率為20%。實(shí)驗(yàn)結(jié)果如表5所示。
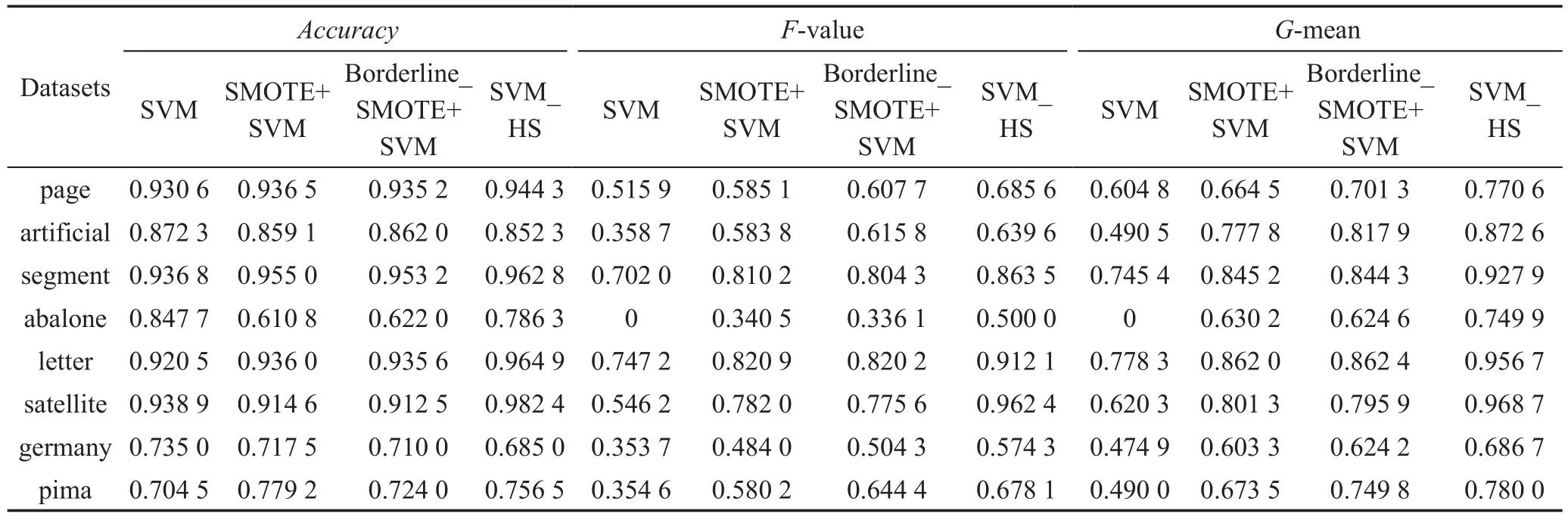
Table 5 Accuracy,F-value,G-mean表5 分類準(zhǔn)確率、F-value、G-mean
在表5中,相比較傳統(tǒng)的SVM算法,本文算法的準(zhǔn)確率在多數(shù)數(shù)據(jù)集上只有小幅度的提高,且在個(gè)別數(shù)據(jù)集上有所降低。這說(shuō)明在提高少數(shù)類的分類準(zhǔn)確率的同時(shí)多數(shù)類的分類準(zhǔn)確率可能會(huì)減小,但與兩種改進(jìn)的算法相比,本文的準(zhǔn)確率都有明顯提高。相比于準(zhǔn)確率,F(xiàn)-value和G-mean更能作為非平衡數(shù)據(jù)整體分類性能的評(píng)價(jià)指標(biāo),往往能夠指示一個(gè)方法在非平衡數(shù)據(jù)集的分類性能好壞。表5顯示出,SVM_HS算法明顯優(yōu)于SMOTE+SVM算法和Borderline_SMOTE+SVM算法,在數(shù)據(jù)集上得到了較好的實(shí)驗(yàn)結(jié)果,有效提高了少數(shù)類和多數(shù)類的分類精度,說(shuō)明本文算法有一定的優(yōu)勢(shì)和可行性。
為了對(duì)比算法的優(yōu)勢(shì),圖3~圖5分別繪制了4種算法在8個(gè)數(shù)據(jù)集上的測(cè)試結(jié)果趨勢(shì)曲線。其中,橫坐標(biāo)為4種算法策略,縱坐標(biāo)為實(shí)驗(yàn)取值范圍。通過(guò)這3個(gè)圖可以看出,使用SVM_HS方法進(jìn)行混合采樣,少數(shù)類的分類性能有所上升。
實(shí)驗(yàn)結(jié)果表明本文算法在少數(shù)類的數(shù)量有明顯劣勢(shì)的情況下,分類效果有較大的提高,能夠顯著提高少數(shù)類的分類精度,并具有良好的適應(yīng)性。
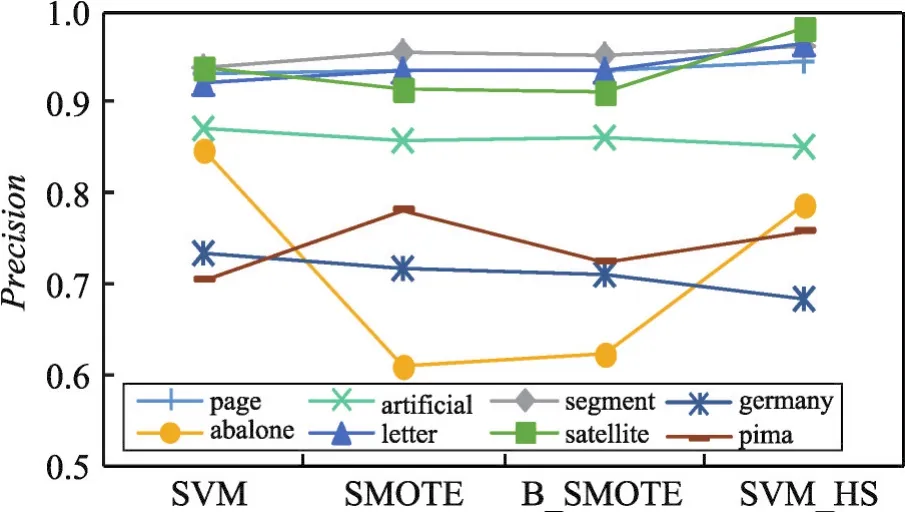
Fig.3 Variation curve of precision圖3 準(zhǔn)確率變化曲線圖
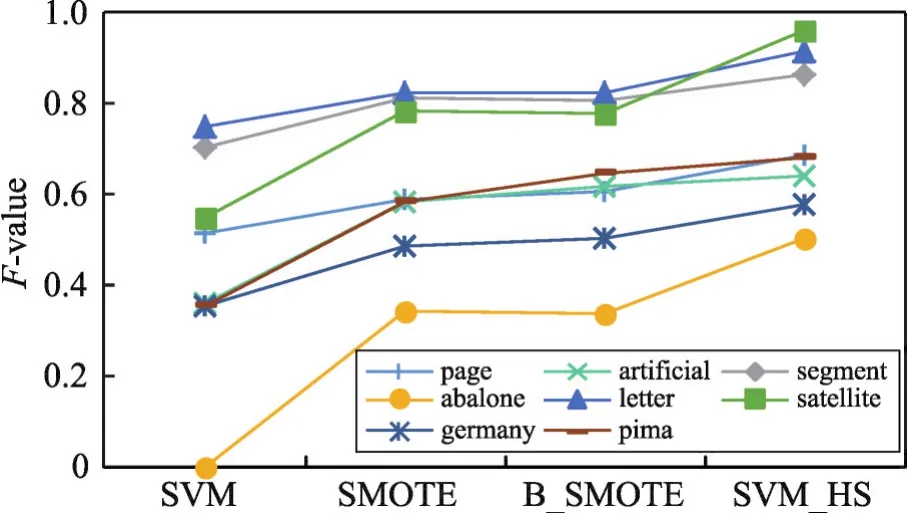
Fig.4 Variation curve of F-value圖4 F-value變化曲線圖
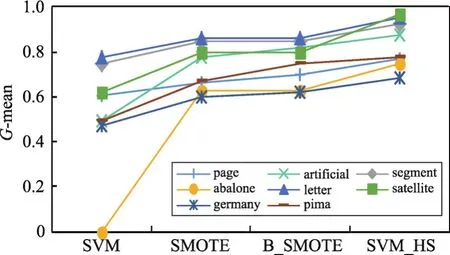
Fig.5 Variation curve of G-mean圖5 G-mean變化曲線圖
5 結(jié)束語(yǔ)
本文針對(duì)SVM算法在處理非平衡數(shù)據(jù)時(shí)分類超平面容易偏向少數(shù)類樣本的問(wèn)題進(jìn)行研究。首先利用SVM算法得到分類超平面;然后迭代進(jìn)行混合采樣,主要包括刪除離分類超平面較遠(yuǎn)的多數(shù)類樣本和對(duì)靠近真實(shí)類邊界的少數(shù)類樣本用SMOTE算法過(guò)采樣兩部分;使分類超平面逐漸靠近真實(shí)類邊界。本文算法通過(guò)在數(shù)據(jù)層面的改進(jìn),少數(shù)類的分類精度得到顯著提高。然而,本文僅在數(shù)據(jù)層面進(jìn)行了改進(jìn),如何在算法層面進(jìn)行改進(jìn),將是未來(lái)重點(diǎn)研究方向。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
小哥白尼(趣味科學(xué))(2019年6期)2019-10-10 01:01:50
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
