深度神經網絡在森林步道視覺識別中的應用*
2019-02-13 06:59:12侯永宏呂曉冬陳艷芳李器宇
計算機與生活 2019年2期
侯永宏,呂曉冬+,陳艷芳,趙 健,李器宇,陳 浩
1.天津大學 電氣自動化與信息工程學院,天津 300072
2.天津航天中為數據系統科技有限公司,天津 300458
1 引言
無人機以其體積小、成本低、適應性強、機動性好等特點在軍用和民用領域展現出巨大的應用潛力,在搜索救援、森林監測、地貌重建等[1-3]方面具有廣闊的應用前景。然而,傳統無人機的飛行需要全球定位系統(global positioning system,GPS)或人為操控,無法在復雜環境下自主完成任務。近年來,學術界和工業界研究重點逐漸轉向無人機自主導航技術,無人機代替人類在野外環境下執行任務成為可能[4]。無人機在森林環境下的自主導航具有廣泛的應用前景,主要體現在搜索救援方面:無人機的大量部署是對救援人員的有效補充,能夠有效減少救援的反應時間以及失蹤人員的受傷風險。但由于森林環境的復雜性和多樣性,無人機在森林環境下的自主導航仍是一個亟待解決的問題。
自主導航的關鍵在于環境感知,無人機需要在森林環境中探索可飛行路徑。森林步道是人們為了穿過森林而走出來的林中小路,因此,無人機沿著森林步道飛行是相對安全有效的行進方式。然而,相比于規范、邊界明顯的人行道,森林步道多樣且邊界模糊,形狀和寬度不受限制,沒有可用于導航跟蹤的規律性,因此,森林環境下的路徑識別更具有挑戰性[5-6]。過去的幾十年中,路徑識別的相關算法得到廣泛研究,在該領域有了長足的發展。現有的道路識別算法主要可分為三類:基于特征的、基于參數模型的以及基于機器學習的方法。基于特征的算法通常提取圖像中重要且穩定的特征,如強度[7]、顏色[8-9]或紋理特征[10-11]將道路從背景中分割出來。然而,基于單個特征的分割方法魯棒性和兼容性差,容易受到天氣、光照變化以及陰影的影響,并且對道路形狀不敏感,不適用于森林步道這類的復雜場景。因此,后續提出的算法通常將圖像分割處理與其他方法相結合,以獲得適當的特征。Alon等人[12]將基于Adaboost算法的區域分割與基于幾何投影的邊界檢測相結合,來尋找自然地貌下的可行駛區域。然而該算法計算量過大,實用性不高。文獻[13-14]采用了圖像顯著性檢測算法,利用顏色、亮度和方向對比來尋找視覺焦點,通過視覺差異來突出路徑。但當路徑與周圍環境對比度小時,很難根據強度變化進行區分。文獻[15]提出了一種基于自頂向下的混合算法,將圖像的區域和邊緣信息相結合,通過離線分類器學習低階和高階圖像信號以檢測道路區域。Zhang等人[16]提出修改特征編碼器并增加特征選擇的過程,使用樹形結構來表示分割區域多閾值的層次關系,再結合K-means進行無監督特征學習,從而提高路徑識別的魯棒性。Santos等人[17]利用邊緣密度估計進行超像素檢測,從灰度、紋理、交通等特征中提取先驗信息,結合支持向量機對圖像中的路徑進行分割。這類基于特征的方法需要根據具體的環境選擇合適的分割算法,因此有著一定的局限性和應用范圍。基于參數模型的方法需要根據少量先驗信息匹配數學模型,如道路邊緣、形狀、分布等,從而估計模型參數完成道路檢測。Hu等人[18]提出一種多模態道路檢測與分割系統,利用單目圖像和高清多層激光雷達獲取反映環境結構的三維點云數據進行高斯模型的參數估計,從而確定道路的中心線區域。文獻[19]基于隨機抽樣一致性(random sample consensus,RANSAC)算法,利用頂視圖圖像匹配曲線道路模型,不易受圖像中物體遮擋或覆蓋等情況影響。但這類算法的有效性取決于模型的精確度,因此對道路形狀有著嚴格要求,適應性較差。
隨著人工智能的發展,路徑感知逐漸向機器學習過渡,基于機器學習的相關算法相繼提出[20-21]。文獻[22]從輸入圖像中提取每個像素的特征向量,利用支持向量機在線進行自監督學習,通過訓練后的分類器進行道路/非道路分類。文獻[23]通過距離歸一化和水平圖像金字塔泛化遠近場的限制,利用深度神經網絡訓練分類器將道路與其他背景區別開,具有良好的自適應效果。Laddha等人[24]提出一種基于單目圖像的道路識別算法,利用車輛姿態估計傳感器(GPS和慣性測量單元)對訓練道路圖像進行自動標注,再利用卷積神經網絡對其訓練完成路徑識別。這些算法雖然能夠達到較高精度,但預處理手段復雜,需要大量的前期工作和計算。蘇黎世大學Scaramuzza教授帶領學生Giusti等在文獻[25]中首次提出將無人機的路徑導航問題轉為神經網絡分類問題的思想,即根據識別路徑位置來調整無人機航向。研究員使用三個不同朝向的頭戴式相機收集在森林中行走時的數據,組成數據集IDSIA。利用神經網絡判斷圖像中的路徑位置(右側/中間/左側),進而完成飛行方向(右轉/直行/左轉)修正。這是第一個利用深度神經網絡來實現無人機在森林中自主飛行的文獻,但當無人機在飛行中遇到樹木稀疏的低密度場景時,往往會導致飛行方向的誤判,從而偏離正確的森林路徑。NVIDIA作為全球領先的視覺計算公司,在自動駕駛汽車、醫療影像分析和機器人自主學習等方面成果斐然,引領人工智能計算領域的前進與發展。由Smolyanskiy[26]領導的NVIDIA公司研究團隊在IDSIA數據集的基礎上利用安裝了三個攝像頭的寬基線裝置來增加水平邊路的數據,從而估計無人機的飛行方向(右轉/直行/左轉)和橫向偏移(左偏/中間/右偏)。該方法雖然一定程度上提高了準確率,但依舊忽略了低密度場景下的誤判情況,準確率仍有一定的提升空間。
以往的相關工作大都集中在城市道路、高速公路等場景,主要應用于地面車輛的自動駕駛領域。用于無人機復雜環境下搜救應用場景的路徑識別技術研究較為少見。基于神經網絡的路徑識別算法[25-26]是少有的針對該應用場景下的技術研究,能夠通過簡單的端對端網絡實現路徑跟蹤,并且相較于傳統方法具有魯棒性高,適用范圍廣的優點。但在森林環境中,路徑邊緣模糊,樹木分布不勻,不可避免地會出現低密度的森林場景。上述兩種方法在此類場景下會出現嚴重誤判,大大降低無人機路徑跟蹤的安全性和穩定性。針對這個問題,本文提出一種基于多列深度神經網絡的方法,該方法通過建立一個雙列深度神經網絡模型(two-column deep neural networks,2CDNN),將相機獲取的RGB圖及其邊緣與紋理特征作為輸入,利用網絡自主學習預測三種飛行方向(左轉/直行/右轉)的概率,在保證高密度場景中路徑識別準確率的前提下,大大提高在低密度場景下的識別準確率,從而提高無人機在森林環境下進行搜索救援的安全性和可靠性。實驗表明在IDSIA數據集中取得了良好的效果,準確率高達91.31%,比現有的方法提高了4.41%。
2 基于單路深度神經網絡的路徑感知方法
2.1 IDSIA數據集
目前,針對森林環境的路徑感知技術研究,業界普遍采用蘇黎世大學Scaramuzza教授發布的數據集IDSIA。該數據集采集方法如下:徒步者配備三個頭戴式相機,沿著森林路徑迅速行走并始終直視前方。三個相機并行排列但朝向不同:中間相機指向正前方,與徒步者視角一致;兩邊相機分別朝左、朝右偏轉30°,如圖1所示。IDSIA數據集由這三個相機采集到的圖像序列組成。圖像的標簽為無人機的三類飛行轉向指令:左轉、右轉和直行,由獲取圖像的相機位置決定。左側相機采集的圖像中路徑在右側,則圖像標簽為右轉。同理,右側相機的圖像標簽為左轉,中間相機的圖像標簽為直行,如圖2所示。
2.2 基于單個神經網絡的路徑感知方法介紹及分析
文獻[25]采用深度神經網絡(deep neural network,DNN)作為圖像分類器,網絡包含4個卷積層、4個池化層以及1個全連接層。網絡輸入為裁剪成101×101大小的RGB圖,對于給定的輸入圖像,深度神經網絡給出3個值,分別表示輸入標簽為左轉、直行和右轉的概率。該方法在IDSIA數據集上取得了85.2%的準確率。

Fig.1 Top view of acquisition setup圖1 頭戴式相機配備俯視圖

Fig.2 Images taken by cameras facing different view directions圖2 不同朝向相機獲取的圖像
本文針對該方法在數據集下發生誤判的概率做出統計,具體情況如圖3所示。
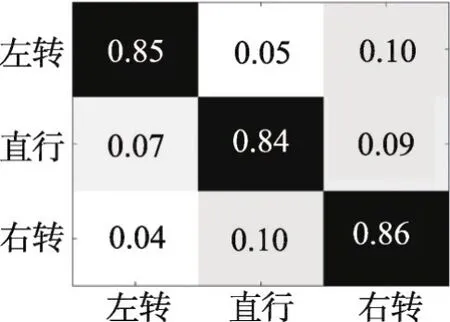
Fig.3 Confusion matrix for DNN on IDSIAdataset圖3 DNN在IDSIA數據集上的混淆矩陣
圖3中縱坐標為標簽,橫坐標為網絡判斷結果,表格內容為統計概率。統計結果顯示,網絡將左轉誤判為右轉以及右轉誤判為直行的概率很高。結合圖像分析,網絡在樹木稀疏的低密度場景下的誤判概率要遠遠高于樹林茂密的高密度場景。高密度場景下,高大的樹木與平坦的小路界限較為分明;而低密度場景的路徑周圍多為平坦的草叢,兩者的分界線較為模糊,如圖4(a)和圖4(b)所示。

Fig.4 High-density and low-density scenes in forests圖4 高密度場景圖與低密度場景圖
解決此類問題的關鍵在于如何在低密度場景下將森林路徑與其周圍環境很好地區分開。低密度場景的路徑周圍由于存在堆積的枝條和草葉,故含有更多的紋理特征;而路徑除兩旁輪廓線外基本沒有多余線條,紋理更少。因此,本文提出2CDNN網絡模型,一列網絡輸入為經過預處理的特征圖來突出輸入圖像的邊緣紋理特征,另一列網絡輸入RGB圖突出輸入圖像的顏色特征,最終將兩個網絡結果融合進一步提高路徑識別性能。
3 2CDNN模型
2CDNN模型本質上是基于多列深度神經網絡[27]的網絡模型。多列深度神經網絡是一個簡單的集成模型,由多個神經網絡并行組成。各網絡輸入為不同方法預處理后的圖像,通過將各網絡的輸出向量融合作為最終判斷結果。本文提出的2CDNN模型主要由三部分組成:圖像預處理、網絡結構以及結果融合,如圖5所示。
(1)圖像預處理:首先將相機獲得的RGB圖進行直方圖均衡結合邊緣提取的方法獲得特征圖,并將原RGB圖和特征圖分別作為兩列網絡的輸入。
(2)網絡結構:采用兩列深度殘差網絡分別對輸入進行監督訓練,預測三個飛行方向的概率。
(3)結果融合:將兩個網絡的概率向量進行點乘融合,最大概率值的標簽即為識別結果。
3.1 圖像預處理
針對上文對低密度場景下的誤判分析,紋理信息是區分路徑與周圍環境的重要特征,因此為了更好地提取圖像中的紋理信息,本文采用了直方圖均衡和邊緣提取的方法對圖像進行預處理,從而獲得突出局部細節和結構紋理信息的特征圖。

Fig.5 2CDNN model圖5 2 CDNN模型
直方圖均衡化處理是一種簡單有效的圖像增強算法,常常用來壓縮圖像的動態范圍使得高動態范圍的場景呈現出更多的細節,提高整體對比度。因此,在進行邊緣提取前采用直方圖均衡處理可以有效地提取出圖像的局部紋理細節[28-29]。為了達到均衡化的效果,算法需要利用累積分布函數將原圖的直方圖映射為均勻分布的直方圖。設一幅圖像像素總數為n,灰度級為L,nk為灰度級為rk的像素個數,則映射函數T(r)公式如下:
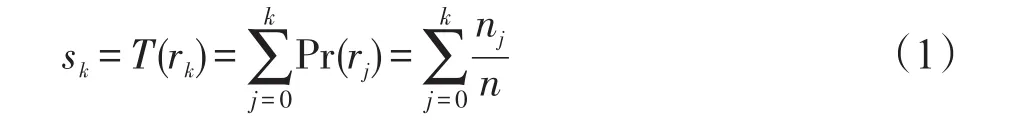
式中,rk為歸一化后的灰度級,Pr(rk)為rk灰度級出現的概率。
邊緣檢測采用經典的Laplacian算子,它是一個二階微分算子,具有各向同性的特點,可有效提取圖像的邊緣紋理等細節信息,定位精度高。但因其對噪音較為敏感,因此檢測前需進行低通濾波。Laplacian算子及其變體已經成為提高各種應用性能的有效方法[30-32]。本文主要通過該方法來突出圖像中的紋理和結構特征。假設圖像像素點為f(x,y),Laplacian算子可以定義為下式:

圖6(a)、圖6(b)分別為圖4(a)和圖4(b)經過直方圖均衡和邊緣提取預處理后的特征圖,由圖可知,高密度場景特征圖和低密度場景特征圖都能很好地突出局部細節,并且森林路徑相較于周邊環境的紋理信息更少。因此,該預處理方法適用于這兩類場景中。

Fig.6 Feature maps of Fig.4(a)and Fig.4(b)圖6 圖4(a)和圖4(b)對應特征圖
大多數現有的深度學習算法只考慮顏色或深度特征,無法從多角度學習和分辨目標。因此,本文應用深度學習模型從兩方面——顏色和紋理特征發現和學習有意義的圖像信息,這有助于提高復雜森林環境下路徑識別的準確性。如圖5所示,RGB圖和特征圖分別為2CDNN模型中兩個網絡通道的輸入。
3.2 網絡結構
傳統的卷積層在信息傳遞中或多或少會存在信息的丟失和損耗,而深度殘差網絡的越層連接可以直接將輸入信息跨越中間層傳輸到后層,一定程度上保證了信息的完整性。深度殘差網絡的另一個特點是能夠解決網絡變深后的性能退化問題。本文提出的網絡結構由兩列相同的深度殘差網絡構成,如圖5所示。單個網絡主要基于深度殘差網絡TrailNet[26],并在TrailNet的每個卷積層后額外添批歸一化操作(batch normalization,BN)。批歸一化操作使輸入數據服從均值為0、方差為1的分布,公式如下:

其中,x(k)為輸入數據的第k維,E[x(k)]、分別表示該維的均值和標準差,表示批歸一化變換后的值。之后利用式(4)對上式結果施加一個反變換,還原出上層需要學習的數據分布:

式中,γ和β為可學習變量,y(k)為批歸一化最終值。批歸一化操作保證每層的輸入數據分布穩定,從而達到加速訓練的目的。
以一列通道為例,其具體結構如圖7所示。網絡輸入為裁剪成320×180大小的RGB圖像。網絡由4個殘差模塊組成,每個殘差模塊包括兩個卷積層和一個恒等映射。整個網絡加權層總數為18。除了第一個卷積核為7×7,其余均為3×3大小。部分層利用步長為2的卷積層進行下采樣,卷積核數量增加一倍但特征映射大小減半,從而能保持時間的復雜度不變。每個卷積層后都進行批歸一化操作,使數據分布穩定。池化層選用平均操作,最后輸出通道為3,分別表示無人機飛行方向為左轉、直走和右轉三類的概率。
3.3 結果融合
為了進一步提高模型的判斷準確率,本文嘗試了多種方法,最終采用點乘方式將兩路網絡結果進行融合。模型中兩個網絡的輸出結果都是一個概率向量,里面包含三個概率值,分別表示飛行方向為右轉、直行和左轉的概率。點乘融合是將兩個網絡輸出的概率向量逐個元素相乘,結果向量中的最大值為該測試圖像的識別結果,其索引對應的標簽即為最終預測的飛行方向。表達式如下所示:

其中,label表示圖像標簽,v1、v2代表概率向量,°為點乘運算,Fin()表示為尋找最大值索引的函數。若兩個網絡的輸出向量分別為[0.012 3,0.152 6,0.835 1]和[0.002 5,0.341 8,0.655 7],三個概率值從左到右的標簽為右轉、直行和左轉,因此兩個網絡判斷的飛行方向均為左轉。將兩個向量進行點乘得到最終輸出向量為[3.075E-05,0.052 2,0.547 6],取其最大值對應的標簽,則網絡判斷飛行為左轉。這是兩個網絡輸出標簽一致的情況。當圖像中路徑定位較難判斷時,往往會導致兩個網絡輸出標簽不一致。如向量[0.458 3,0.431 2,0.110 5]和[0.263 5,0.701 4,0.035 1],前一個向量中右轉和直行概率接近,而另一個向量中直行概率明顯高于左轉。利用點乘融合可以得到的向量為[0.120 8,0.302 4,0.003 9],即直行。因此,點乘融合可以糾正大部分因路徑定位模糊導致的單個網絡誤判。
4 性能評估
為了驗證提出的2CDNN模型性能,本文實驗主要從以下兩方面進行:

Fig.7 Network architecture used in 2CDNN圖7 2 CDNN中的網絡結構
(1)比較不同的預處理方法、融合方法,前期融合與后期融合的差異以及該模型與其他網絡架構的對比。所有對比實驗均在IDSIA數據集上進行。
(2)在仿真環境AirSim下的森林場景利用該模型判斷無人機的飛行方向,畫出其飛行軌跡。
4.1 實驗配置
4.1.1 數據集處理
本文采用針對森林環境下路徑跟蹤的數據集IDSIA作為網絡的訓練和測試數據集。該數據集在多樣的道路類型和環境下從3種不同角度(朝左30°、正面以及朝右30°)拍攝森林路徑,道路類型包括從傾斜狹窄的高山小路到寬闊的森林小路,環境有晴天、陰天和下雪等。根據文獻[26]進行訓練和測試數據集的劃分,路徑001、002、004、007和009為訓練集,005、006為驗證集,003、008和010為測試集。此外,本文采用多種經典方法進行數據增強,包括輕度的仿射變形、隨機翻轉和旋轉等,從而進一步增加樣本數量,提高識別率和網絡泛性能力。
4.1.2 實驗平臺
(1)所有的實驗均在一臺工作站上完成,工作站配置了主頻3.6 GHz的Intel?CoreTMi7-4790 CPU,8 GB內存。該工作站還配置了英偉達的TITAN X顯卡,用于完成神經網絡的訓練。軟件平臺為業界廣泛采用的深度學習框架Caffe(convolutional architecture for fast feature embedding)。
(2)該模型的仿真實驗主要在AirSim環境下進行。該環境是微軟推出的用于模擬無人機飛行的開源工具,通過人工智能(artificial intelligence,AI)技術提供詳細的三維街景,包括交通燈、公園、湖泊等。本文采用該環境提供的森林場景,利用2CDNN模型判斷無人機的飛行路線。
4.2 2CDNN模型在IDSIA數據集上的評估
本文針對2CDNN模型在IDSIA數據集下的訓練和測試進行了多種對比實驗。網絡訓練采用Xavier初始化權重,一次迭代128張訓練圖片(batch size),一共訓練了20個循環(epoch)。網絡采用牛頓加速梯度(Nesterov accelerated gradient,NAG)優化器,初始學習率(base learning rate)設置為0.001,該學習率經過20個循環后下降為0.000 01。實驗主要步驟如下:
(1)利用訓練集中的RGB圖對單網絡(如圖7)進行訓練,訓練后的網絡在測試集上測試,獲得飛行方向的識別正確率。
(2)對數據集中的圖像利用4種預處理方法獲取特征圖,分別為邊緣提取、直方圖均衡、CIELab色彩域轉換結合邊緣提取以及直方圖均衡結合邊緣提取。訓練和測試按照(1)中步驟進行,獲得測試集的正確率。
(3)分別采用平均融合和點乘融合的方法將(2)中4種預處理方法獲取的識別正確率與(1)中RGB圖的識別結果相融合。
(4)將RGB圖與文中3.1節預處理方法得到的特征圖進行疊加,獲得與前期融合相同效果的疊加圖,訓練和測試按照(1)中步驟進行,獲得測試集正確率。
(5)選取幾個目前較為主流的網絡架構在數據集上按照(1)中步驟進行訓練與測試。
表1給出了各預處理方法在單網絡通道以及與RGB圖測試結果平均融合、點乘融合下的識別率。由表可得出以下結論:(1)相較于其他三種方法,直方圖均衡結合邊緣提取的方法在單網絡通道下的識別率最高,達到87.94%。這表明,增強局部細節并突出邊緣紋理信息能更好地提高路徑感知性能。(2)雙網絡通道結果融合明顯提高了識別率。這是由于結果融合能夠很好地綜合兩路信息優點,達到信息互補的目的。(3)點乘融合方法明顯優于文獻[27]中的平均融合,能夠進一步提高識別準確率。

Table 1 Comparison of various preprocessing methods表1 預處理方法比較
1)該部分只用RGB圖作為網絡輸入,為了與有預處理方法的網絡結果進行比較,因此沒有融合的結果。
此外,輸入為直方圖均衡結合邊緣提取的特征圖比輸入為RGB圖在單網絡通道下的判斷準確率有所提升,主要體現在對低密度場景中路徑位置的正確判斷,如圖8所示。其中,圖8(a)為網絡誤判的RGB圖,圖8(b)中為其判斷正確的對應特征圖。圖8(a)中兩張圖的標簽分別為直行和左轉,但由于該場景下樹木稀疏,路徑周圍較為空曠,導致網絡在這兩張RGB圖下誤判飛行方向為左轉和右轉。而通過本文方法獲得圖8(a)的特征圖,如圖8(b)所示,能夠很好地顯示圖中的局部細節。可以看出,圖中路徑部分的紋理細節明顯少于周邊環境,因此可以很清楚地表示出路徑位置。網絡對特征圖的正確判斷使2CDNN模型在結果融合時能夠大概率地糾正網絡對RGB圖的誤判,從而提高測試集的整體識別率。此外,圖9顯示了網絡判斷正確的RGB圖及其誤判的特征圖,此情況多出現于光照對比強烈的場景中。這類兩路網絡判斷有偏差的情況絕大部分在融合后得到解決,兩個結果向量通過點乘融合能夠獲得正確的判斷結果。由此可見,采用兩路網絡融合的2CDNN模型才能達到信息相互彌補的目的,取得更優效果。

Fig.8 Success cases fusing results of RGB images(detected wrong)and their feature maps(detected right)圖8 融合RGB圖(誤判)和其特征圖(判斷正確)結果后判斷正確的場景
為了展示2CDNN模型在提高識別率上的出色表現,本文對單路網絡通道和2CDNN模型進行了對比。單路網絡通道輸入為RGB圖與特征圖相加獲得的疊加圖,等同于圖像信息的前期融合;2CDNN模型的兩路輸入分別為RGB圖和特征圖,測試結果如表2所示。可以看出,2CDNN的識別率比單路網絡對于疊加圖測試識別率要高出3.48%。這表明信息的后期融合在識別性能上的效果要優于前期融合。

Fig.9 Success cases fusing results of RGB images(detected right)and their feature maps(detected wrong)圖9 融合RGB圖(判斷正確)和其特征圖(誤判)結果后判斷正確的場景

Table 2 Accuracy comparison between DNN and 2CDNN表2 單路網絡通道和2CDNN準確率對比
圖10給出了單網絡通道輸入分別為RGB圖、特征圖的混淆矩陣以及2CDNN模型的混淆矩陣。圖中縱坐標為標簽,橫坐標為網絡判斷結果,表格內容為統計概率。從圖中可以看出,2CDNN顯著提高了標簽為左轉和右轉的準確率,特別是右轉方向提升到了95%。此外,相比于文獻[25]方法,2CDNN不僅提高了整體的判斷準確率,而且針對上文提到的左轉誤判為右轉以及右轉誤判為直行的問題也得到了較大的改善,誤判率分別從10%、10%降低到5%和2%。
另外,本文使用不同網絡架構在IDSIA數據集上進行測試,將其識別結果與2CDNN模型進行比較。本文選用了 DNN[25]、Trailnet[26]、VGGNet-16[33]和 Resnet-18[34]與本文方法進行對比,結果如表3所示。DNN、Trailnet、VGGNet-16和Resnet-18網絡輸入同為RGB圖。表3結果顯示,2CDNN網絡顯著提高了識別性能,這說明了殘差網絡的越層學習結合直方圖均衡和邊緣提取的預處理有助于提取路徑更本質和抽象的特征,有效提高路徑位置判斷準確性。

Fig.10 Confusion matrices for DNN and 2CDNN on IDSIAdataset圖10 DNN和2CDNN在IDSIA數據集上的混淆矩陣
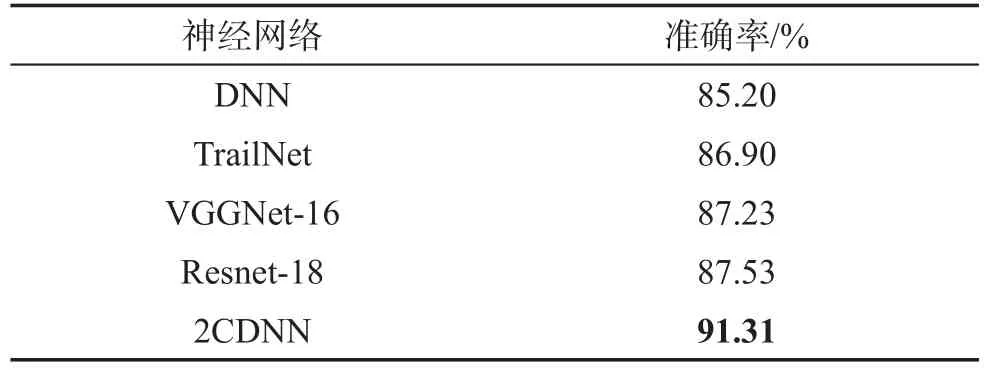
Table 3 Comparison of proposed method with different network architectures on IDSIAdataset表3 不同網絡架構在IDSIA數據集的識別率
4.3 2CDNN模型在AirSim環境下仿真實驗
為了體現2CDNN模型在無人機自主飛行應用中的可行性,本文利用AirSim下的3D森林場景對2CDNN模型進行測試。
4.3.1 仿真實驗方案
森林環境中囊括多種不同情況,例如光照角度不同、森林密度不同、路徑彎曲程度不同等。本文選取一段環境較為復雜的森林步道,這段步道俯視圖如圖11所示,紅色曲線為正確的森林步道,起點為坐標軸位置。利用遙控器人為控制場景中的模擬無人機沿著森林步道飛行,通過無人機上搭載的一個正面朝前的相機來收集飛行過程中的圖像,形成一個數據集做2CDNN模型在該森林步道下的飛行測試集。通過2CDNN模型對飛行測試集中的圖像進行方向判斷,根據判斷結果按照采集圖像的順序在圖11中畫出該模型判斷的飛行軌跡,由圖中紫色虛線表示。
4.3.2 仿真實驗結果及分析
從圖11中可以看出,飛行軌跡基本上與人為控制的選擇結果相符,表明所提出的2CDNN模型能夠識別路徑位置并判斷正確的飛行方向,從而安全穿過森林。此外,飛行軌跡有幾處偏離正確路徑,大多為岔路口或光線太暗導致的失誤,之后在飛行過程中會逐漸回歸正確步道,具體情況如圖12。圖12(a)中為判斷正確的場景圖,可以看出,光照造成的部分陰影對模型的判斷沒有影響,在彎曲步道處也適應良好。而圖12(b)中誤判的場景顯示,由于樹冠過于茂密導致整個路面處于黑暗中,使得模型無法判斷路徑位置。另外,在多條道路交叉的路口處飛行方向的判斷具有隨機性。

Fig.11 Top view of flight trajectory in forest圖11 森林場景下無人機的飛行軌跡俯視圖

Fig.12 Success and failure cases inAirSim圖12 AirSim環境下判斷正確和錯誤的場景
5 總結
本文提出了一種深度學習模型——2CDNN,使得無人機能夠根據一張圖像判斷在森林環境下沿著森林路徑的飛行方向。2CDNN利用兩個相同的殘差網絡構建一個簡單的融合模型,殘差網絡利用越層連接實現較深網絡的訓練,提高識別準確率的同時能夠加快網絡收斂速度。模型包括兩個輸入通道,在獲取RGB圖突出顏色信息的同時,采用直方圖均衡結合邊緣提取獲得特征圖以突出路徑局部細節和邊緣紋理信息。最終將兩個結果向量通過點乘方法進行融合,以提高2CDNN的識別性能。在IDSIA數據集上的實驗表明,本文提出的網絡模型在準確性方面優于現有模型,提高了無人機在森林環境中路徑感知和方向判斷的準確率。因此,本文方法在無人機自主導航方面具有較高的實際應用價值。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
