基于Python的天貓商品爬蟲技術
2019-01-30 12:53:10侯潔茹呂繼續
科技資訊 2019年32期
關鍵詞:數據采集
侯潔茹 呂繼續
摘? 要:信息技術的跨越式發展,尤其是人工智能新潮浪起的時代,不論身處哪個領域,數據已經成為一種重要的資源,而數據的采集很大程度上依賴于爬蟲技術。該文結合對天貓出售的商品信息的抓取,闡述數據采集的基本流程。
關鍵詞:網絡爬蟲技術? 天貓網站爬取? 數據采集
中圖分類號:TP391.1;TP393.092 ? ?文獻標識碼:A 文章編號:1672-3791(2019)11(b)-0010-02
隨著互聯網科技的飛速發展,網上購物成為人們的生活中的一部分。天貓網站是網購中具有代表性的大型電子商務平臺。它的商品信息數據十分龐大,包含了生活、學習、工作等多個領域的商品信息。該文以抓取天貓網站中的口紅商品信息為例,詳細介紹了使用網絡爬蟲實現從數據獲取到數據分析,再到數據結構化存儲的過程。
1? 相關技術
該文涉及的主要技術為網絡爬蟲技術與python編程語言的應用技術。
1.1 網絡爬蟲
網絡爬蟲(又稱網頁蜘蛛、網絡機器人或網頁追逐者)是[1]一種能自動采集互聯網信息的程序。為了提高效率,節省時間,往往采用爬蟲框架來實現抓取。目前爬蟲技術已經較為完善,有很多優質的爬蟲框架,如基于Java的webmgaic框架、Apache Nutch2框架;基于python的scrapy框架、pySpider框架;基于C語言的DotnetSpider框架、NwebCrawler框架,等等。能夠很好地實現分布式,以及多線程的網絡數據爬取。
1.2 Python語言
Python是目前較為流行的計算機程序設計語言,是一種面向對象的動態類型語言。基于python的網路爬蟲技術十分完備,對于大型的爬取任務,可以分布式、多線程的抓取,對于規模較小的網頁爬取,python提供了能夠實現http請求的功能模塊,如urllib庫、resquests庫;以及能夠解析網頁的功能模塊,如BeautifulSoup庫、lxml庫、pyquery庫。可以很好地實現靜態網頁、動態網頁,以及多頁抓取等數據采集的任務。該文基于resquests庫與BeautifulSoup庫實現天貓網站的商品信息的采集。
2? 爬取天貓商品信息
天貓商品信息的爬取過程可以概括為4個部分,即URL請求、頁面數據解析、多頁爬取、數據的存儲。
2.1 URL請求
如同使用瀏覽器瀏覽網頁一般,網絡爬蟲需要通過URL向服務器發送請求。服務器在接收到請求后,傳回相應的頁面。此次抓取的初始URL是在天貓官網搜索口紅后的頁面的URL。具體網址如下。
https://list.tmall.com/search_product.htm?q=%BF%DA%BA%EC&type=p
2.2 頁面數據解析
Python的requests庫可以模擬瀏覽器過URL發送Http請求,此次爬取任務不需要提取表單,只是信息的獲取,采用get函數實現。由于天貓網站具有一定的反扒機制,所以采用了get函數中的headers參數模擬瀏覽器信息,該參數為字典格式。此次模仿的是Google瀏覽器,具體參數如下。
{‘User-Agent:Mozilla/5.0(Windows NT 10.0; Win64;x64)AppleWebKit/537.36(KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36}
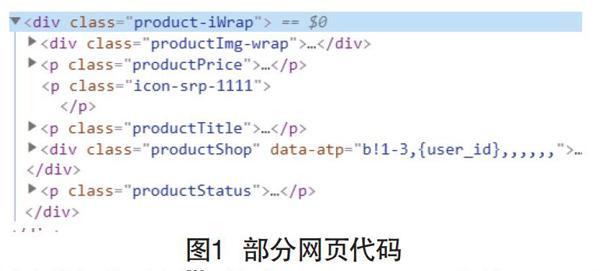
成功獲得網頁頁面信息后,采用BeautifulSoup庫從爬取到的網頁中解析出此次爬取需要獲取的商品名稱、價格、店鋪名稱以及月銷等信息,首先通過Google瀏覽器的開發者工具查看網頁結構,我們想要的信息在屬性class的值為“product-iWrap”的div標簽下,如圖1所示。
利用遞歸的思想[3],結合BeautifulSoup中的find()函數,解析出商品名稱、價格、店鋪名稱以及月銷等信息,并以列表的格式存儲。
2.3 多頁的爬取
通過上述的操作,可以很好地實現目標網頁的信息抓取,但我們需要大量抓取數據,所以要對口紅商品進行多頁爬取。通過對不同頁[2]的URL的觀察,發現口紅商品改變頁碼以后,網址URL中只有參數s會發生變化,并且s與頁碼的關系為s=60×頁碼。依據發現的規律使用遞歸構造不同頁的URL。
2.4 數據的存儲
將解析完的數據以csv格式存儲[4],使用python的文件處理語句,使其自動實現。以寫入的方式創建并打開一個csv文件,制定文件的路徑為相對路徑,命名為“lipstick.csv”。在數據爬取到以后,使用write()函數,將數據寫入到csv文件中,并保存。
3? 存儲結果展示及結語
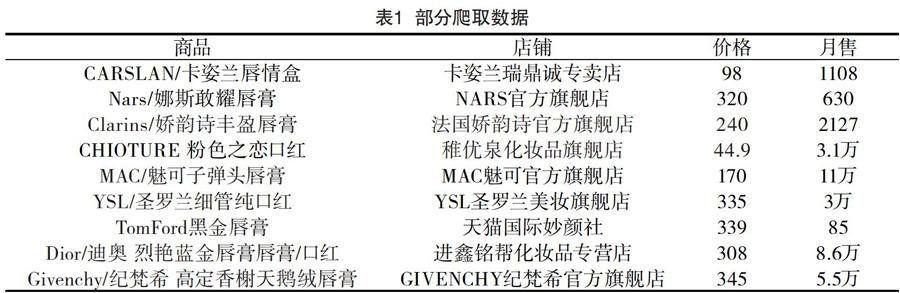
由于得到的數據較大,只對部分數據進行展示,具體情況見表1。
從我們獲得的數據來看即使是同一品牌的口紅,由于出售店鋪、款式、型號等因素的影響,在價格上也會有很大差別。這使得數據具有很大的價值,對數據進行聚類、排序、篩選或者其他算法分析可以挖掘到很多有利的價值為大眾購物提供參考。
參考文獻
[1] 陳方,譚愛平,成亞玲,等.主題爬蟲技術研究綜述[J].湖南工業職業技術學院學報,2008(5):13-16.
[2] 楊帆,董俊,唐宏亮,等.基于Python的淘寶評論爬取技術研究[J].中國管理信息化,2019,22(4):162-163.
[3] 廖勇毅,丁怡心.基于Python的股票定向爬蟲實現[J].電腦編程技巧與維護,2019(5):45-46.
[4] 裴麗麗.基于Python對豆瓣電影數據爬蟲的設計與實現[J].電子技術與軟件工程,2019(13):176-177.
猜你喜歡
現代電子技術(2016年22期)2016-12-26 12:36:15
電子技術與軟件工程(2016年22期)2016-12-26 11:11:30
現代電子技術(2016年22期)2016-12-26 09:44:35
電子技術與軟件工程(2016年19期)2016-12-19 19:59:14
電腦知識與技術(2016年27期)2016-12-15 20:42:01
農業與技術(2016年15期)2016-11-09 17:43:03
科技視界(2016年18期)2016-11-03 22:51:40
中國科技博覽(2016年22期)2016-11-01 16:58:26
軟件工程(2016年8期)2016-10-25 15:54:18
軟件工程(2016年8期)2016-10-25 15:52:53
