PU場景下的生物醫(yī)學(xué)命名實(shí)體識別算法研究
2019-01-24 06:01:08高冰濤翟振剛
智能物聯(lián)技術(shù) 2019年1期
高冰濤 ,翟振剛 ,劉 斌
(1.中國電子科技集團(tuán)公司第三十六研究所,浙江 嘉興 314000;2.西北農(nóng)林科技大學(xué) 信息工程學(xué)院,陜西 楊凌 712100)
0 引言
近年來,由于生物醫(yī)學(xué)領(lǐng)域命名實(shí)體識別研究的潛在應(yīng)用價值和問題的復(fù)雜性,這項(xiàng)研究已經(jīng)吸引了很多感興趣的研究者。目前大部分生物醫(yī)學(xué)命名實(shí)體的識別主要集中在識別Medline文本中的基因和蛋白質(zhì)的名稱,識別分子生物醫(yī)學(xué)中的命名實(shí)體成為生物信息學(xué)中知識發(fā)現(xiàn)的最基本任務(wù)。例如Merry K P和Modi M在文本中提取蛋白質(zhì)互作信息,第一步就是蛋白質(zhì)名稱的識別[1]。準(zhǔn)確高效的生物醫(yī)學(xué)命名實(shí)體識別系統(tǒng)對生物醫(yī)學(xué)和生物信息學(xué)工作者的研究具有重要的作用和意義[2]。
在傳統(tǒng)的生物醫(yī)學(xué)命名實(shí)體識別中工作中,由于維特比算法在序列數(shù)據(jù)中的優(yōu)良表現(xiàn)和生物醫(yī)學(xué)命名實(shí)體的特性,多采用隱馬爾可夫模型(Hidden Markov Models,HMM)[3]作為主要算法進(jìn)行研究和應(yīng)用[4]。例如:基于單詞相似度平滑技術(shù)的HMM命名實(shí)體識別分類器[5]、PowerBioNE生物命名實(shí)體識別系統(tǒng)[6]、BioTrHMM生物醫(yī)學(xué)命名實(shí)體識別系統(tǒng)[7],Jie Zhang等人也指出HMM在生物醫(yī)學(xué)領(lǐng)域中進(jìn)行命名實(shí)體識別的有效性[8-9]等。
在生物醫(yī)學(xué)命名實(shí)體識別領(lǐng)域中,傳統(tǒng)的識別算法為了獲得良好的預(yù)測性能和保證模型的健壯性,通常要使用大量的標(biāo)注數(shù)據(jù)對模型進(jìn)行訓(xùn)練。但是,在實(shí)際應(yīng)用當(dāng)中,我們能夠直接獲得的全標(biāo)注數(shù)據(jù)往往很少,并且人工標(biāo)注數(shù)據(jù)的成本高昂。PU學(xué)習(xí)作為一種半監(jiān)督學(xué)習(xí)方法,具有比傳統(tǒng)的有監(jiān)督學(xué)習(xí)方法更大的靈活性。與有監(jiān)督學(xué)習(xí)方法相比,半監(jiān)督學(xué)習(xí)方法需要的標(biāo)注數(shù)據(jù)樣本數(shù)量少,降低了分類模型對目標(biāo)領(lǐng)域標(biāo)注樣本的需求量,克服了模型學(xué)習(xí)過程中由于目標(biāo)領(lǐng)域標(biāo)注數(shù)據(jù)樣本不足造成的局限。半監(jiān)督學(xué)習(xí)方法,在標(biāo)注數(shù)據(jù)不足的情況下,不僅可以保證算法的性能,還有效地節(jié)約了資源。
正例未標(biāo)注學(xué)習(xí)[10],即PU學(xué)習(xí)(Positive and Unlabeled Learning),是一種半監(jiān)督學(xué)習(xí)方法。PU學(xué)習(xí)在疾病基因的識別[11]、與時間有關(guān)的數(shù)據(jù)流問題的處理[12]和構(gòu)建AUC優(yōu)化方法[13]等方面應(yīng)用廣泛,并且在不確定數(shù)據(jù)和風(fēng)險評估方面都取得了非常好的效果[14-17]。
研究至今,暫沒有發(fā)現(xiàn)研究者在生物醫(yī)學(xué)命名實(shí)體識別領(lǐng)域中通過使用PU學(xué)習(xí)進(jìn)行研究的相關(guān)內(nèi)容。本文將PU學(xué)習(xí)有效地應(yīng)用到生物醫(yī)學(xué)命名實(shí)體識別當(dāng)中,在少量標(biāo)注數(shù)據(jù)和大量未標(biāo)注數(shù)據(jù)的情況下構(gòu)建模型,實(shí)現(xiàn)命名實(shí)體識別。本文主要是從PU學(xué)習(xí)中的兩步法和隱馬爾可夫模型的角度展開研究,將生物醫(yī)學(xué)領(lǐng)域中的命名實(shí)體識別問題轉(zhuǎn)化為PU場景下的命名實(shí)體識別問題,在PU場景下建立隱馬爾可夫模型,對命名實(shí)體進(jìn)行識別。
1 問題定義
給定目標(biāo)領(lǐng)域數(shù)據(jù)集為D=P∪U,其中P表示數(shù)據(jù)集中的正例樣本的集合,U表示數(shù)據(jù)集中未標(biāo)注數(shù)據(jù)樣本的集合,U中同時含有正例樣本數(shù)據(jù)和負(fù)例樣本數(shù)據(jù)。每個數(shù)據(jù)樣本可以表示為〈x,f(x),y〉,其中,x 表示觀測樣本數(shù)據(jù);f(x)表示樣本 x 對應(yīng)的詞性狀態(tài)屬性,當(dāng)樣本是未標(biāo)注樣本時f(x)取值為?;y∈{0,1},表示樣本是否為蛋白質(zhì)命名實(shí)體,y取值為0時表示該樣本不是蛋白質(zhì)命名實(shí)體,y取值為1時表示該樣本是蛋白質(zhì)命名實(shí)體。本研究目標(biāo)是使用少量的標(biāo)注正例樣本,對大量未標(biāo)注的數(shù)據(jù)分類出強(qiáng)負(fù)例樣本RN,最后在強(qiáng)負(fù)例樣本RN和正例數(shù)據(jù)樣本P的基礎(chǔ)上學(xué)習(xí)構(gòu)建隱馬爾可夫模型f,對目標(biāo)數(shù)據(jù)集Dt中的樣本x有:
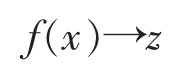
即得到樣本對應(yīng)的詞性狀態(tài),從而得到特征的取值,進(jìn)而實(shí)現(xiàn)命名實(shí)體識別。
2 算法構(gòu)建
本文將通過使用PU學(xué)習(xí)兩步法構(gòu)建模型:在使用少量標(biāo)注數(shù)據(jù)樣本的情況下,通過PU學(xué)習(xí)構(gòu)建模型,對待測樣本進(jìn)行預(yù)測;通過算法分類未標(biāo)注數(shù)據(jù)中的強(qiáng)負(fù)例,使用強(qiáng)負(fù)例樣本和正例樣本構(gòu)建PU場景下的隱馬爾可夫模型。技術(shù)路線可分為4個主要步驟:數(shù)據(jù)集收集與預(yù)處理、分類出強(qiáng)負(fù)例構(gòu)建分類模型訓(xùn)練數(shù)據(jù)集、構(gòu)建分類模型和預(yù)測與評估,算法模塊的關(guān)系如圖1所示。
2.1 分類強(qiáng)負(fù)例
本文主要使用了Rocchio算法、樸素貝葉斯算法、Spy算法和1-DNF算法等4種方法對未標(biāo)注數(shù)據(jù)中的強(qiáng)負(fù)例樣本進(jìn)行分類。
(1)Rocchio 算法
在Rocchio分類算法中,每一個文本d用一個特征向量表示,=(q1,q2,…,qn)。 其中,向量中的每一個元素q1表示一個單詞wi。Rocchio算法構(gòu)建模型是通過構(gòu)建算法中的正例標(biāo)準(zhǔn)向量和負(fù)例標(biāo)準(zhǔn)向量實(shí)現(xiàn)的,正例標(biāo)準(zhǔn)向量和負(fù)例標(biāo)準(zhǔn)向量的計(jì)算方式如下:
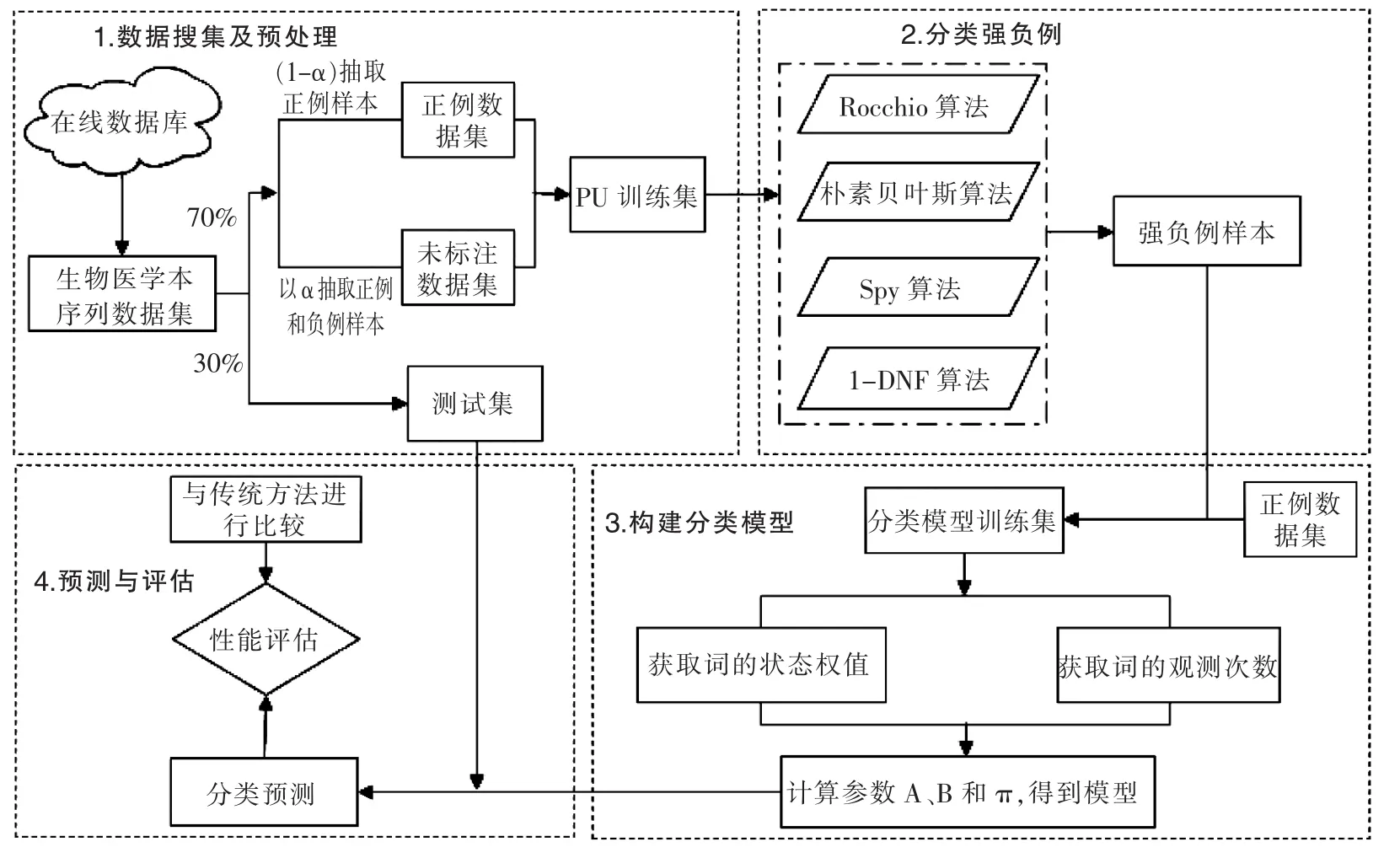
圖1 算法模塊關(guān)系圖
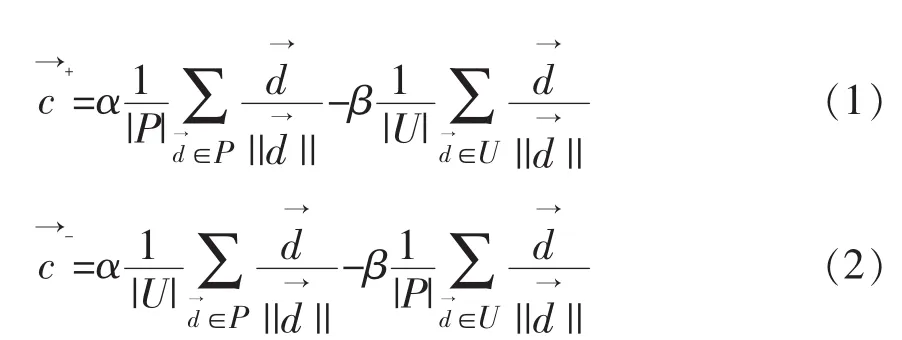
其中,參數(shù)α和β是用來對正例訓(xùn)練樣本和負(fù)例訓(xùn)練樣本的相關(guān)影響進(jìn)行調(diào)整的,推薦使用α=16,β=4[18]。
Rocchio算法具體如下:

(2)樸素貝葉斯算法
樸素貝葉斯算法在分類問題當(dāng)中應(yīng)用非常普遍。對于想要分類的文本集D中的樣本數(shù)據(jù),C=(c1,c2,…,cn)是預(yù)先定義的文本序列數(shù)據(jù)類別,V=(x1,x2,…,x|v|)表示詞匯表,其中 xi表示一個單詞。樸素貝葉斯(NB)分類器對給定的文本數(shù)據(jù)計(jì)算條件概率,計(jì)算得到的最大概率的那個類別被認(rèn)為是文本數(shù)據(jù)的類別。
N(xt,di)表示單詞 xt在文本摘要 di中出現(xiàn)的次數(shù),在給定一個類別cj的情況下通過公式(3)計(jì)算單詞xt出現(xiàn)的概率P(xt|cj),本文中所需要的先驗(yàn)概率P(cj)通過統(tǒng)計(jì)得到。
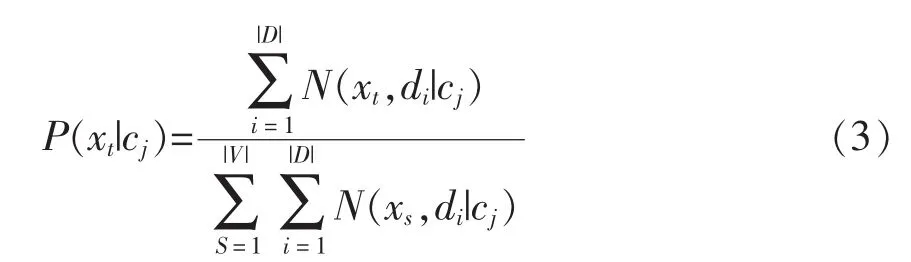
為了防止詞匯表V中的某些單詞在某些類別的文本當(dāng)中沒有出現(xiàn),使用拉普拉斯平滑技術(shù)進(jìn)行處理,如公式(4)所示:
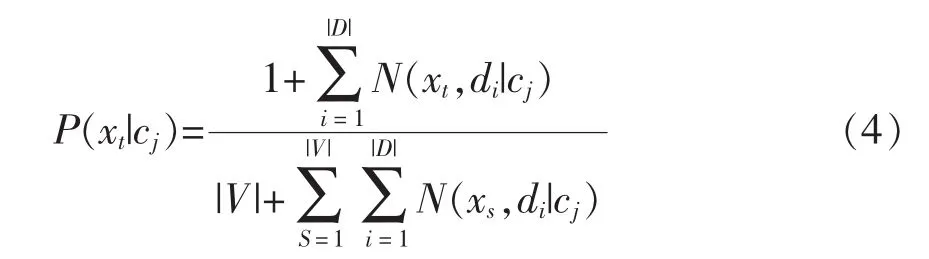
最后,假設(shè)給定類別的文本中單詞出現(xiàn)的概率相互獨(dú)立,本文使用式(5)所示的樸素貝葉斯分類器:
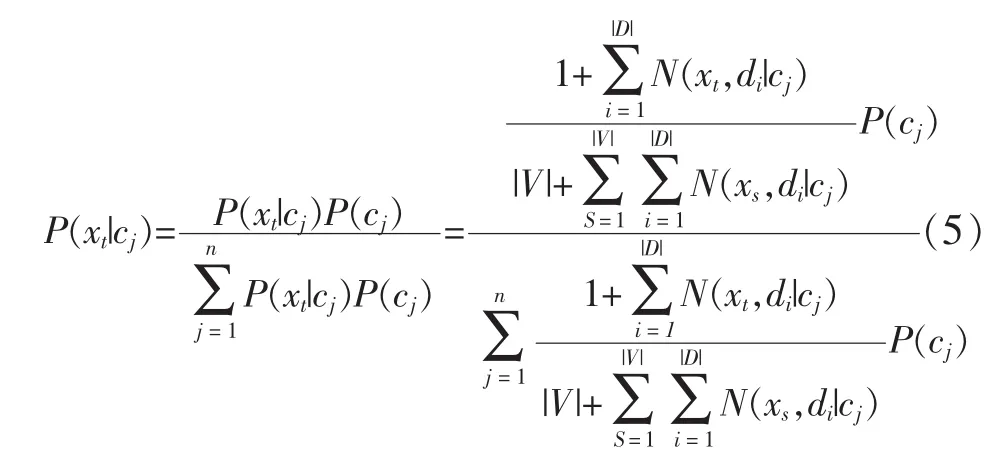
對于給定的文本序列di,通過上述公式計(jì)算條件概率P(xt|cj),概率最大的類別作為單詞xt的類別。為了從未標(biāo)注數(shù)據(jù)U中識別出強(qiáng)負(fù)例數(shù)據(jù)集RN,本文在正例數(shù)據(jù)集P和未標(biāo)注數(shù)據(jù)集U上訓(xùn)練一個樸素貝葉斯分類器,并且用該分類器對未標(biāo)注數(shù)據(jù)U進(jìn)行分類。對于給定的文本數(shù)據(jù),如果是正例的概率小于是未標(biāo)注數(shù)據(jù)的概率,則把文本數(shù)據(jù)看做是一個強(qiáng)負(fù)例樣本。
樸素貝葉斯分類器的算法框架如下:

(3) Spy 算法
Spy算法見算法3。對在Spy算法中使用的概率閾值t進(jìn)行簡單說明:計(jì)算“Spy”數(shù)據(jù)S中每一個樣本分布為正例的概率,取其中的概率最小值作為概率閾值t。
Spy算法的具體過程如下:

(4)1-DNF 算法
1-DNF算法是通過對正例樣本數(shù)據(jù)P和未標(biāo)注樣本數(shù)據(jù)U中的數(shù)據(jù)特征進(jìn)行對比,找到一些正例樣本所具有的的特征,構(gòu)建一個正例特征集PF。該方法計(jì)算在正例樣本數(shù)據(jù)P和未標(biāo)注樣本數(shù)據(jù)U中單詞出現(xiàn)的頻率,然后使用在正例樣本數(shù)據(jù)P中出現(xiàn)頻率比在未標(biāo)注樣本數(shù)據(jù)U中出現(xiàn)頻率高的單詞構(gòu)建正例特征集PF。該方法是通過對未標(biāo)注數(shù)據(jù)U中的所有數(shù)據(jù)樣本進(jìn)行核查,將其中可能是正例數(shù)據(jù)的樣本篩選出來,這樣未標(biāo)注數(shù)據(jù)U中的不含任何正例特征的樣本就被分類為強(qiáng)負(fù)例樣本。
1-DNF算法的具體過程如下:

2.2 構(gòu)建分類模型
通過上述4種方法可以有效地從未標(biāo)注數(shù)據(jù)中將強(qiáng)負(fù)例樣本分類出來,進(jìn)而與正例樣本形成訓(xùn)練集,這樣就可以進(jìn)行有監(jiān)督學(xué)習(xí)。由于HMM在命名實(shí)體識別研究中的有效性,本文同樣選擇HMM作為基礎(chǔ)模型。HMM的三個主要參數(shù)分別是初始狀態(tài)概率向量π、狀態(tài)轉(zhuǎn)移概率矩陣A和觀測概率矩陣B。
轉(zhuǎn)移概率aij的估計(jì)。設(shè)文本序列樣本中時刻t處于狀態(tài)i,在時刻t+1轉(zhuǎn)移到狀態(tài)j的頻數(shù)為Na,ij,則狀態(tài)轉(zhuǎn)移概率 aij的計(jì)算公式如下:
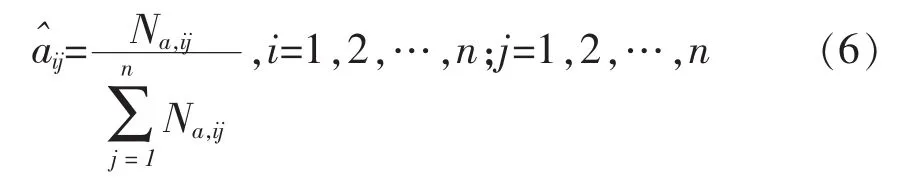
觀測概率bj(k)的估計(jì)。設(shè)樣本中狀態(tài)為j并且觀測為k的頻數(shù)為Nb,jk,則狀態(tài)為j觀測為k的概率 bj(k)的計(jì)算公式如下:
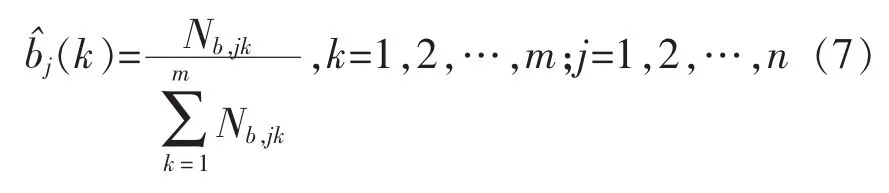
初始狀態(tài)概率πi的估計(jì)。i為S個樣本中初始狀態(tài)為qi的頻率,計(jì)算公式如下:
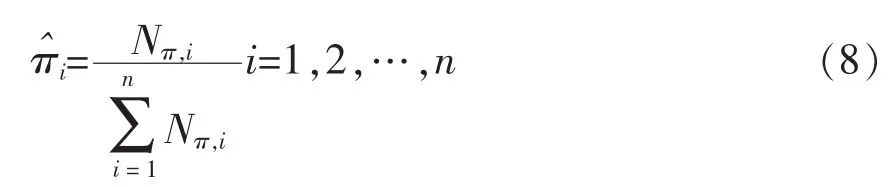
由于可能出現(xiàn)的數(shù)據(jù)稀疏問題,本文使用拉普拉斯平滑的方法進(jìn)行處理,具體如下:
初始狀態(tài)概率計(jì)算為:
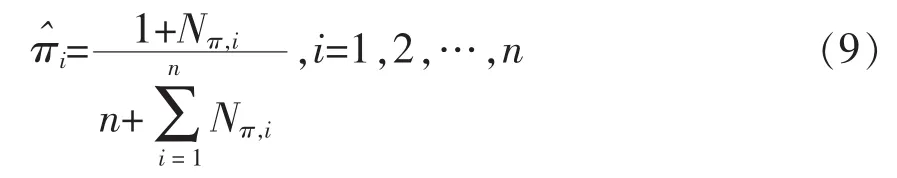
轉(zhuǎn)移概率aij的計(jì)算為:

觀測概率 bj(k)的計(jì)算為:
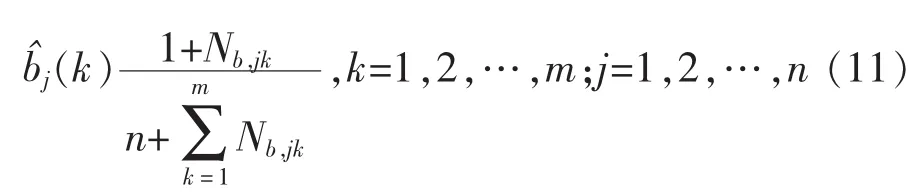
至此得到分類預(yù)測模型,并使用維特比算法對待測數(shù)據(jù)進(jìn)行標(biāo)注,從而對命名實(shí)體進(jìn)行識別。
3 實(shí)驗(yàn)及結(jié)果分析
為了驗(yàn)證本文提出算法的性能,本文在GENIA V3.02語料庫上進(jìn)行了實(shí)驗(yàn)。
3.1 實(shí)驗(yàn)設(shè)置
為了驗(yàn)證本文提出的算法在生物醫(yī)學(xué)領(lǐng)域中命名實(shí)體識別的性能,選取傳統(tǒng)的HMM算法與本文提出的PU場景下的兩步法算法進(jìn)行比較。目前,最常用的生物醫(yī)學(xué)標(biāo)注語料庫是GENIA V3.02語料庫,該語料庫包含了來自MEDLINE的2000個摘要標(biāo)注文本(約360000個單詞),并且包含36個詞性類別,其中包含5個生物醫(yī)學(xué)實(shí)體類型。本文識別的是蛋白質(zhì)命名實(shí)體,采用了精確率、召回率和F值[19]作為評價指標(biāo)。GENIA V3.02語料庫中實(shí)體標(biāo)簽分布說明見表1。

表1 GENIA V3.02語料庫中實(shí)體標(biāo)簽分布
本文中Dt是含有蛋白質(zhì)命名實(shí)體標(biāo)簽和其他詞性標(biāo)簽的目標(biāo)集,Ds是把蛋白質(zhì)命名實(shí)體標(biāo)簽處理為NN類型的輔助集,輔助集中標(biāo)簽分布見表2。

表2 輔助集中實(shí)體標(biāo)簽分布
本文采用PU學(xué)習(xí)中一種普遍使用的方法[20]構(gòu)造PU數(shù)據(jù)集。對一個數(shù)據(jù)集,正例樣本以概率(1-α)隨機(jī)選擇標(biāo)記為正例,這部分樣本構(gòu)成正例樣本集,剩下的正例樣本作為未標(biāo)注樣本,這部分樣本和所有的負(fù)例樣本構(gòu)成未標(biāo)注樣本集。
根據(jù)He J[21]等提出的實(shí)驗(yàn)方法,為了測試在不同PU場景下算法的預(yù)測性能,本文設(shè)置了兩個參數(shù)α和Unlevel來模擬不同的PU場景。α表示正例樣本占源數(shù)據(jù)集的比例;Unlevel表示未標(biāo)注樣本占源數(shù)據(jù)集的比例。

本文通過對每組實(shí)驗(yàn)進(jìn)行十折交叉驗(yàn)證的方法,確保結(jié)果的有效性。
3.2 實(shí)驗(yàn)結(jié)果
為了驗(yàn)證PU場景下兩步法算法的性能,本文分別從不同角度進(jìn)行了實(shí)驗(yàn)。實(shí)驗(yàn)如下:
(1)針對 α的實(shí)驗(yàn)
本文分別設(shè)置參數(shù)α為0.2,0.4,0.6,對PU情況下通過兩步法訓(xùn)練構(gòu)建的HMM與直接使用現(xiàn)有的少量標(biāo)注數(shù)據(jù)構(gòu)建的HMM的分類性能進(jìn)行了對比,實(shí)驗(yàn)結(jié)果如表3至表5所示。
實(shí)驗(yàn)結(jié)果顯示,標(biāo)注數(shù)據(jù)較少的情況下,使用兩步法構(gòu)建的分類模型比直接使用現(xiàn)有標(biāo)注數(shù)據(jù)構(gòu)建的分類模型性能更優(yōu)。當(dāng)參數(shù)α為0.2,0.4和0.6時,通過PU學(xué)習(xí)方法構(gòu)建的分類模型比直接使用現(xiàn)有的少量標(biāo)注數(shù)據(jù)構(gòu)建的模型在準(zhǔn)確率和召回率方面具有顯著的優(yōu)勢。同時,通過PU學(xué)習(xí)得到的分類模型的準(zhǔn)確率和召回率雖然隨著參數(shù)的變化有所起伏,但是總體變化不大,比直接使用現(xiàn)有的少量標(biāo)注數(shù)據(jù)構(gòu)建的分類模型更加穩(wěn)定。
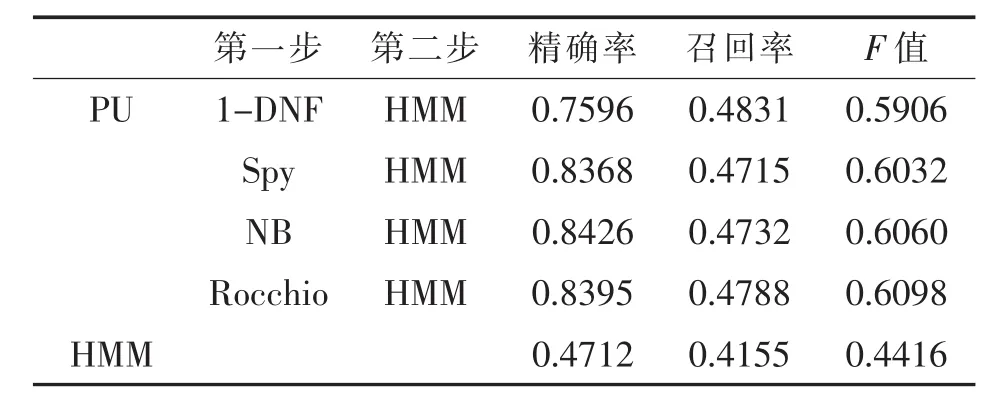
表3 α=0.2時分類性能對比
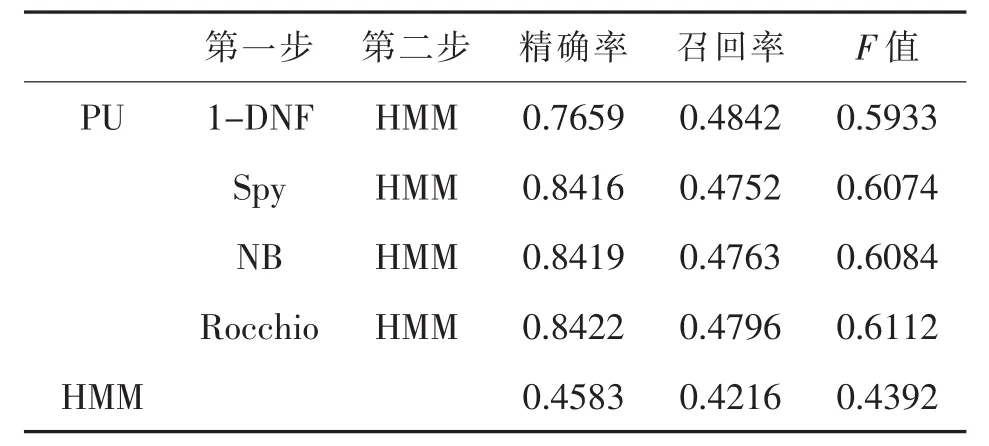
表4 α=0.4時分類性能對比
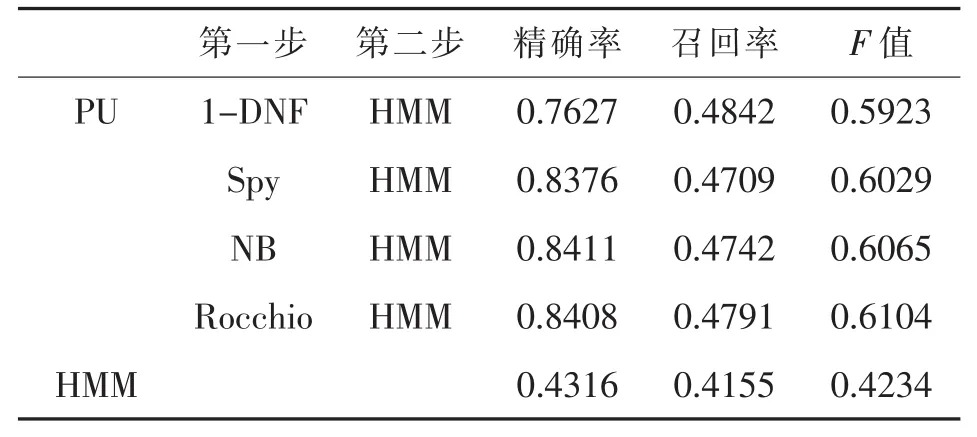
表5 α=0.6時分類性能對比
(2)針對 Unlevel的實(shí)驗(yàn)
本文將Unlevel分別設(shè)置為50%,60%,70%,80%,90%。對在PU情況下通過兩步法訓(xùn)練構(gòu)建的HMM與直接使用現(xiàn)有少量標(biāo)注數(shù)據(jù)構(gòu)建的HMM的分類性能進(jìn)行了對比。表6至表10是模型在不同的Unlevel情況下的實(shí)驗(yàn)結(jié)果對比。
本文在不同的PU學(xué)習(xí)情況下,分別使用1-DNF、Spy、NB和 Rocchio算法作為兩步法的第一步,然后在第二步中使用已有正例數(shù)據(jù)和分類出的強(qiáng)負(fù)例數(shù)據(jù)訓(xùn)練HMM。實(shí)驗(yàn)結(jié)果顯示,在標(biāo)注數(shù)據(jù)較少的情況下,本文通過兩步法得到的模型比直接使用已有標(biāo)注數(shù)據(jù)訓(xùn)練得到的分類模型具有更好的分類性能。并且在模型實(shí)驗(yàn)結(jié)果的準(zhǔn)確率和召回率方面,與直接學(xué)習(xí)得到的分類模型相比優(yōu)勢明顯,特別是在未標(biāo)注樣本比例逐漸增大的情況下,優(yōu)勢越加顯著。
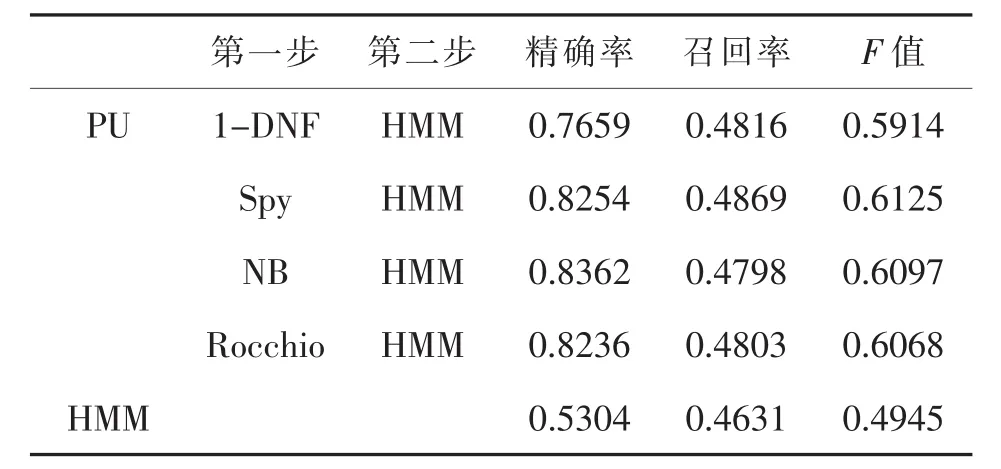
表6 Unlevel=50%時分類性能對比
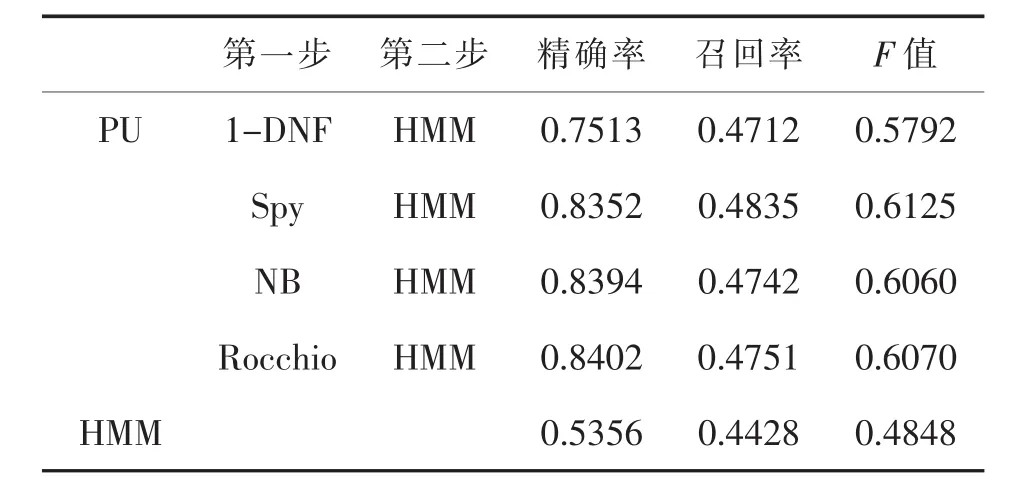
表7 Unlevel=60%時分類性能對比
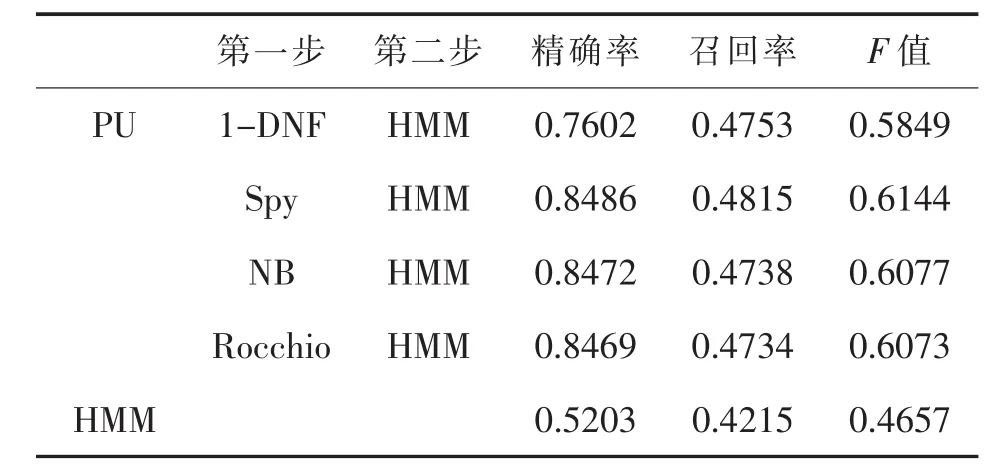
表8 Unlevel=70%時分類性能對比
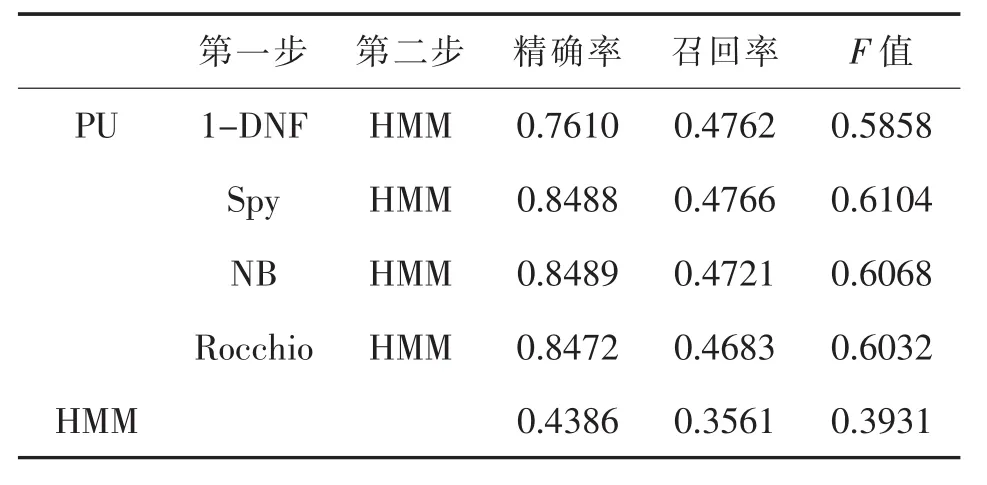
表9 Unlevel=80%時分類性能對比
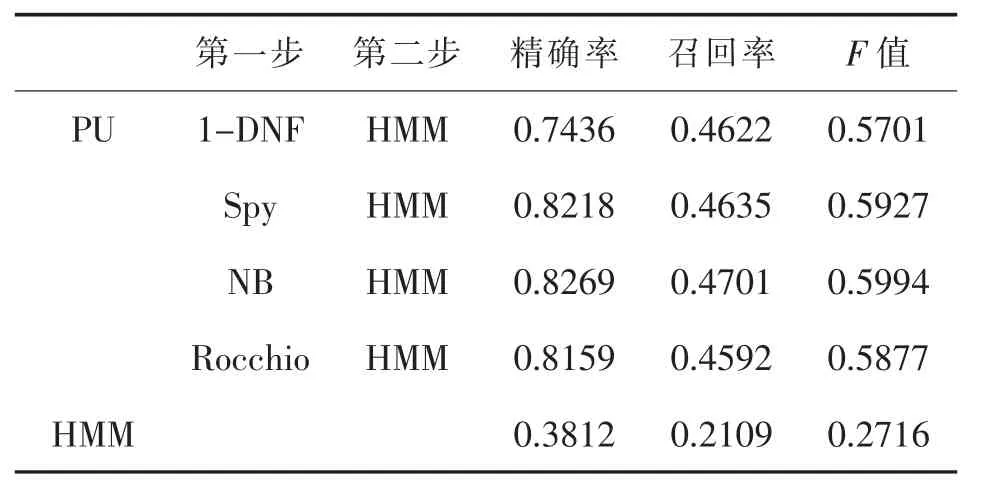
表10 Unlevel=90%時分類性能對比
通過設(shè)置不同的參數(shù)α和Unlevel值,模擬不同PU場景下的生物醫(yī)學(xué)領(lǐng)域的蛋白質(zhì)命名實(shí)體識別問題。以上的實(shí)驗(yàn)結(jié)果表明,在不額外增加人工標(biāo)注目標(biāo)數(shù)據(jù)的情況下,通過兩步法構(gòu)建的分類模型比直接使用現(xiàn)有的少量標(biāo)注數(shù)據(jù)構(gòu)建的分類模型具有更好的分類性能。
4 結(jié)語
針對傳統(tǒng)生物醫(yī)學(xué)命名實(shí)體識別方法需要大量標(biāo)注數(shù)據(jù),而人工標(biāo)注數(shù)據(jù)困難、能獲取標(biāo)注數(shù)據(jù)比較少的問題,本文提出PU情況下通過兩步法構(gòu)建分類模型的生物醫(yī)學(xué)命名實(shí)體識別方法。通過PU學(xué)習(xí)方法中的兩步法在未標(biāo)注數(shù)據(jù)中分類出強(qiáng)負(fù)例樣本,在已有的正例樣本和分類出的強(qiáng)負(fù)例樣本的基礎(chǔ)上對模型進(jìn)行訓(xùn)練,構(gòu)建出分類模型,對目標(biāo)數(shù)據(jù)進(jìn)行命名實(shí)體識別。實(shí)驗(yàn)顯示,在只有少量標(biāo)注數(shù)據(jù)的情況下,通過PU學(xué)習(xí)中的兩步法構(gòu)建的分類模型比直接使用現(xiàn)有少量標(biāo)注數(shù)據(jù)的監(jiān)督學(xué)習(xí)方法構(gòu)建分類模型具有顯著優(yōu)勢。此外,通過PU學(xué)習(xí)方法構(gòu)建分類模型不僅識別性能有所提升,同時大大節(jié)省了人工標(biāo)注數(shù)據(jù)的成本。
在本文中主要通過PU學(xué)習(xí)方法構(gòu)建分類模型,降低模型對標(biāo)注數(shù)據(jù)的需求。現(xiàn)在深度學(xué)習(xí)方法的研究越來越熱,逐漸涉及到多個領(lǐng)域,未來工作考慮在生物醫(yī)學(xué)命名實(shí)體領(lǐng)域?qū)ι疃葘W(xué)習(xí)方法進(jìn)行研究。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
