基于功率譜的蛋白質(zhì)序列特征提取新方法
2019-01-11 02:13:28梁啟浩唐旭清
食品與生物技術(shù)學(xué)報 2018年11期
梁啟浩, 李 陽, 唐旭清
(江南大學(xué) 理學(xué)院,江蘇 無錫 214122)
蛋白質(zhì)序列特征提取是指依據(jù)研究的目的提取序列信息,并使用數(shù)學(xué)方法描述,建立可以反映序列結(jié)構(gòu)和空間信息的特征向量,進而表達其功能[1]。如何從復(fù)雜的序列中挖掘有用的信息是生物信息學(xué)的研究方向之一,信號頻譜分析技術(shù)基于自動信息處理,廣泛應(yīng)用于特征提取的各個領(lǐng)域,比如周期性分析、蛋白質(zhì)編碼區(qū)預(yù)測和基因識別等方面[2-3]。Yin等[2]將信號處理與分析方法引入DNA序列相似性分析中。Hota等[4]基于快速離散傅里葉變換(Fast discrete Fourier transform,DFT)和小波變換(Wavelet transform,WT),從功率譜等信號處理方法的角度對基因識別進行了研究。王其強等[5]基于功率譜將信號處理與分析方法應(yīng)用于P53家族基因的三周期性特征分析。這些研究對于大數(shù)據(jù)中DNA序列處理過程中的特征提取有重要的意義。
蛋白質(zhì)存在于所有的生物細胞中,是生命的物質(zhì)基礎(chǔ)之一,蛋白質(zhì)序列的研究具有極其重要的意義。蛋白質(zhì)空間結(jié)構(gòu)的所有信息均隱藏在氨基酸序列中,因此研究蛋白質(zhì)的氨基酸序列組成已經(jīng)成為生物信息學(xué)研究領(lǐng)域的關(guān)鍵問題之一[6]。聚類分析技術(shù)已廣泛應(yīng)用于蛋白質(zhì)序列信息處理的各個方面,如分析蛋白質(zhì)間的親緣關(guān)系,提取蛋白質(zhì)結(jié)構(gòu)信息、功能信息等[7-8],其目的是簡約數(shù)據(jù)信息系統(tǒng)、降低系統(tǒng)復(fù)雜度。文獻[9]通過Voss映射將DNA序列轉(zhuǎn)換為數(shù)字序列,采用功率譜方法提取DNA序列的特征信息從而進行DNA序列聚類分析,其中特征信息提取的核心是由離散傅里葉變換的序列特征頻譜的j(j=1,2,3)階矩構(gòu)造的一個12維的特征向量,并采用傳統(tǒng)的非加權(quán)組平均法(UPGMA)得到不同物種基于這種相似關(guān)系的系統(tǒng)發(fā)生樹。在此基礎(chǔ)上,本文結(jié)合基于信號頻譜分析技術(shù)與層次聚類方法,將DNA序列數(shù)據(jù)推廣到蛋白質(zhì)序列數(shù)據(jù),進行蛋白質(zhì)序列的特征提取與物種的系統(tǒng)發(fā)生樹(或分層結(jié)構(gòu))研究。
1 材料與方法
1.1 數(shù)據(jù)來源
本文從NCBI網(wǎng)站中下載了文獻[10]中19種動物 的 ND1、ND4 的 蛋 白 質(zhì) 序 列 (NADH dehydrogenase subunit1是線粒體NADH脫氫酶亞基1的簡寫、NADH dehydrogenase subnits4是線粒體NADH脫氫酶亞基4的簡寫,分別表示為數(shù)據(jù)1與數(shù)據(jù)2)進行研究,具體的數(shù)據(jù)有Gibbon(NC_002082.1),Gorilla(NC_011120.1),Human(NC_012920.1),Chimp(NC_001643.1),Pygmy Chimp(NC_001644.1),Sumatran Orang (NC_002083.1),Bornean Orang(NC_001646.1),Hedgehog(NC_002080.2),Rat(AC_000022.2),Mouse(NC_005089.1),Donkey(NC_001788.1),Horse(NC_001640.1),Cow (NC_006853.1),Baleen whale (NC_001601.1),F(xiàn)in whale (NC_001321.1),Cat(NC_001700.1),Grayseal(NC_001602.1),Harbor seal (NC_001325.1),Rhino(NC_001779.1)。同時下載了文獻[11]中11種β珠蛋白蛋白質(zhì)序列(表示為數(shù)據(jù) 3), 分別為 Human(AAA16334),Gorilla(CAA43421),Chimpanzee(CAA26204),Lemur(AAA 36822),Rabbit(CAA24251),Goat(AAA30913),Bovine(CAA25111),Mouse(CAA24101),Rat(CAA29887),Opossum (AAA30976),Gallus(CAA23700) 進 行 研究。并同時找到3種數(shù)據(jù)所對應(yīng)的DNA序列與文獻[9]做比較。
1.2 符號序列的數(shù)字表達HP模型
隨著生物信息學(xué)的發(fā)展,對于DNA序列中堿基進行數(shù)值化的映射有很多,如Voss映射、實數(shù)映射、Z-curve 映射及朱平等[12]建立的映射 φ∶GF(73)→C343等。
本文考慮氨基酸的物理和化學(xué)性質(zhì),在詳細的HP模型中將20種氨基酸分成4大類,分別為極性親水性(PQ),極性疏水性(PR),非極性親水性(SQ)和非極性疏水性 (SR), 且 PQ={G},PR={A,V,L,I,P,F},SQ={S,T,C,N,Q,K,R,H,D,E},SR={W,M,Y}, 由此就將一條給定長度的蛋白質(zhì)序列轉(zhuǎn)化為一條由4類氨基酸構(gòu)成的4元序列。
對含有n個氨基酸的蛋白質(zhì)序列s=s1s2…sn,其中為組成此蛋白質(zhì)序列的氨基酸,進行數(shù)據(jù)化定義
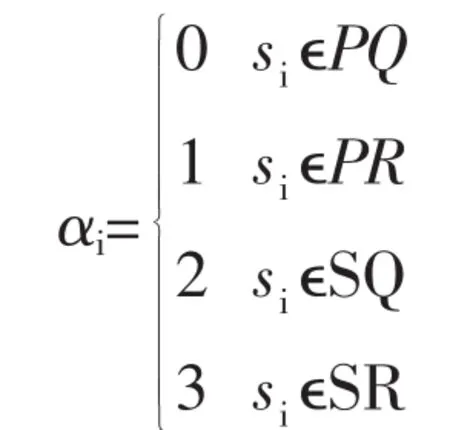
由此即可將任意一條蛋白質(zhì)序列轉(zhuǎn)化為一條由 0、1、2、3 構(gòu)成的 4 元序列,記作:X(s)=α1α2…αn。這樣產(chǎn)生的序列為基因序列的指示序列。
1.3 基于功率譜的蛋白質(zhì)特征向量提取
里葉變換能將滿足一定條件的某個函數(shù)表示成三角函數(shù)(正弦和/或余弦函數(shù))或者它們的積分的線性組合。使用離散傅里葉變換,其顯著的優(yōu)點是使隱藏或潛伏在原始數(shù)據(jù)中的信息經(jīng)周期性變換之后變得清晰。下文的研究以極性親水性(PQ)為例說明,極性疏水性(PR),非極性親水性(SQ)和非極性疏水性(SR)相似。
利用離散的傅里葉變換及上述的指示序列,可以將基因序列數(shù)據(jù)進行離散化
這樣就能得到復(fù)數(shù)序列{UPQ(k)},k=0,1,…,N-1。對這個復(fù)數(shù)序列取模的平方,以定義序列的功率譜
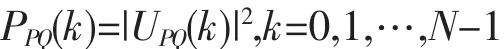
類似地,可得 PPR(k)、PSR(k)和 PSQ(k),且原氨基酸序列的功率譜為這4個子序列的功率譜之和。即
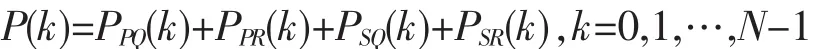
生物序列數(shù)學(xué)表示的目的之一就是分析生物序列的相似性[13],但是不同的蛋白質(zhì)序列長度不同,因此僅通過功率譜不能進行相似性分析,進而去聚類。解決這種問題需要通過功率譜構(gòu)造向量,而相似性則可以通過計算兩向量之間的歐式距離得到。一般認為距離越小,兩序列就越相似。對于極性且親水性(PQ)類氨基酸,在文獻[9]中定義j階矩為
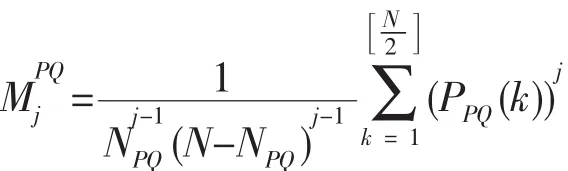
可以構(gòu)建12維向量,也稱為基于矩的
這樣每一條蛋白質(zhì)序列都會得到一個12維的特征向量。特征向量間的距離按歐式距離進行計算,即給定蛋白質(zhì)序列i和j的特征向量分別為Mi和Mj,則兩條序列之間的歐氏距離記為
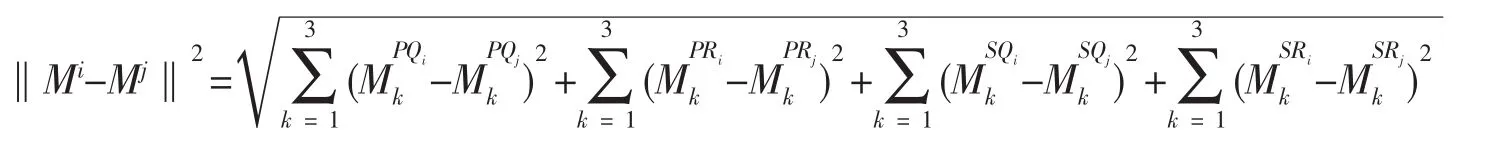
以下將在上面特征向量的基礎(chǔ)上開展研究。
1.4 聚類
聚類分析是進行數(shù)據(jù)分析的一個基本方法,在數(shù)據(jù)挖掘、模式識別、生物信息學(xué)和統(tǒng)計學(xué)等領(lǐng)域都有廣泛的研究與應(yīng)用[14]。它是探索或提取隱含在數(shù)據(jù)中的新規(guī)律和新知識的重要手段。本文將采用基于文獻[15]得到的層次聚類方法,在有限集X={x1,x2,…,xn}上定義一個標準化的度量矩陣d,令
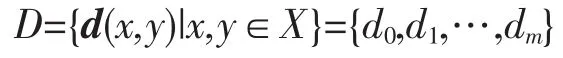
其中 d0=0<d1<…<dm。其算法如下:
算法A
S1 輸入n個樣本,i?0;
S2 構(gòu)造n個類,每個類中只含有一個樣本,記為 X(di)=C={c1,c2,…,cn};
S3 A?C,i?i+1,C??;
S4 B??;
S5 對于任意的 cj∈A,令 B?B∪{cj},A?A/cj;
S6 ?ck∈A,如果存在 xj∈cj,yk∈ck,使得 d(xj,xk)≤di,則 B?B∪{cj},A?A/ck;
S7 C?{B}∪C;
S8 若A≠φ,則轉(zhuǎn)S4;
S9 X(di)=C,輸出 X(di);
S10 直到C≠{X},否則轉(zhuǎn)S3;
S11 結(jié)束。
通過算法A,可獲得數(shù)據(jù)系統(tǒng)的分層(或?qū)哟危┙Y(jié)構(gòu)。
1.5 聚類結(jié)果評價
本文采用熵作為聚類效果的度量標準,熵值表示同一類對象在聚類簇集中的分散程度。處于同一類中的對象熵值越高越分散,相應(yīng)的聚類效果就越差。用標準公式計算簇i的熵,其計算公式為
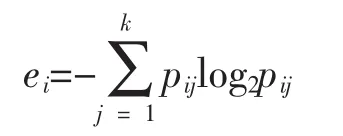
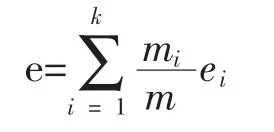
其中,k為簇的個數(shù),m為數(shù)據(jù)集中對象的總數(shù)。熵值的含義是:熵值越小相應(yīng)的聚類效果就越好。在理想情況下,每一類的所有對象應(yīng)分布于不同的簇中,此時e=0。
2 實驗結(jié)果比較與分析
將本文的方法用于ND1、ND4與β珠蛋白序列的相似性分析。選取這3種蛋白質(zhì)序列來檢驗本文方法的好壞,一是因為這3種數(shù)據(jù)在生物上具有重要意義,研究的結(jié)果有實際應(yīng)用價值,ND1與ND4參與線粒體氧化磷酸化的電子傳遞[10],β珠蛋白是位于紅細胞內(nèi)的一種更大的蛋白質(zhì) (血紅蛋白)的一個組件(亞基)[11],對所有的生物體都是至關(guān)重要的。二是由于這3種數(shù)據(jù)已被廣泛研究。將本文結(jié)果與文獻[9]構(gòu)建的結(jié)果進行比較,使本文的方法更具有說服力。
本文將數(shù)據(jù)分為3類時兩種方法的錯分率和熵值進行比較研究。圖1~3為采用3種數(shù)據(jù)構(gòu)造12維特征向量進行聚類分3類時的分層結(jié)構(gòu)。表1,2是采用本文方法與文獻[9]中的方法對實驗數(shù)據(jù)進行聚類所得到的結(jié)果的對錯統(tǒng)計情況,表3為采用兩種方法將3種數(shù)據(jù)分3類時的熵值對比。
將數(shù)據(jù)1分為3類時,文獻[10]中標準的分為3類時的層次結(jié)構(gòu)為(Hedgehog,Donkey,Horse,Cow,Baleen whale,F(xiàn)in whale,Cat,Gray seal,Harbor seal,Rhino), (Rat,Mouse), (Gorilla,Gibbon,Human,Chimp,Pygmy Chimp,Sumatran Orang,Bornean Orang),從圖1和2可以看出,將本文的方法應(yīng)用到數(shù)據(jù)1和數(shù)據(jù)2所得到的結(jié)果與文獻[10]中的結(jié)果是基本一致。人(Human),蘇門答臘猩猩(Sumatran Orang), 婆 羅 洲 猩 猩 (Bornean Orang), 長 臂 猿(Gibbon), 大猩猩 (Gorilla), 侏儒黑猩猩(Pygmy Chimp),黑猩猩(Chimp)彼此之間的線粒體 NADH脫氫酶很相似不是一種偶然,都屬于靈長目。與其他哺乳類的動物進化關(guān)系最遠的物種Mouse和Rat的線粒體NADH脫氫酶與其他物種最不相似,為嚙齒目。19種數(shù)據(jù)中除(Rat,Mouse)屬于脊索動物門以外,Hedgehog與另外16種都屬于脊椎動物門,所以本文將數(shù)據(jù)中的Hedgehog先與靈長目聚為一類是可行的。而文獻[9]的方法將數(shù)據(jù)1中本該屬于鯨目、偶蹄目的Cow與嚙齒目Mouse聚為1類,數(shù)據(jù)2中文獻[9]的方法將嚙齒目Rat和其他兩類混在一起,而Mouse單獨分為1類,這與進化事實相悖。因此,采用本文的方法得到的結(jié)果更好一些。

圖1 數(shù)據(jù)1分3類時的分層結(jié)構(gòu)Fig.1 Hierarchical structure of Data 1

圖2 數(shù)據(jù)2分3類時的分層結(jié)構(gòu)Fig.2 Hierarchical structure of Data 2
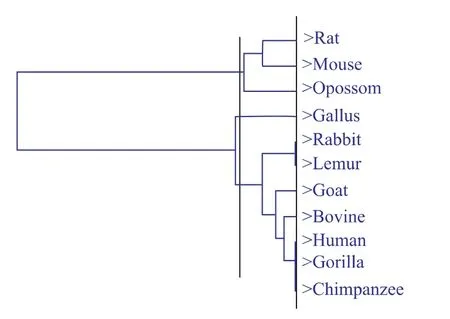
圖3 數(shù)據(jù)3分3類時的分層結(jié)構(gòu)Fig.3 Hierarchical structure of Data 3
將數(shù)據(jù)3分為3類時,文獻[11]中標準的分為3類時的結(jié)果為(Human,Gorilla,Chimpanzee,Lemur,Rabbit,Goat,Bovine,Mouse,Rat), (Opossum),(Gallus)。從圖3可以看出,將本文所得結(jié)果與文獻[11]中的結(jié)果相比: 哺乳動物中的 (Mouse,Rat),(Human,Gorilla,Chimpanzee)和(Lemur,Rabbit)分別是聚類過程中距離最近的物種,它們處于同一分支上,即親緣關(guān)系最近;Gallus作為11個物種中唯一的非哺乳動物和其他的哺乳動物之間的進化距離很遠;本文將(Mouse,Rat)先與負鼠目Opossum聚為一類,文獻[11]后將(Mouse,Rat)與 Opossum 聚為一類,有一定的差別。而采用文獻[9]方法的聚類過程中,將Chimpanzee與Gorilla這兩個物種單獨分為一類,此與文獻[11]差別較大,同時與進化事實不一致。因此,采用本文的方法研究β珠蛋白的結(jié)果好于文獻[9]的方法。

表1 數(shù)據(jù)1和數(shù)據(jù)2分3類時聚類結(jié)果對錯統(tǒng)計Table 1 Error statistics of Clustering result for Data 1 and Data 2

表2 數(shù)據(jù)3分3類時聚類結(jié)果對錯統(tǒng)計Table 2 Error statistics of Clustering result for Data 3
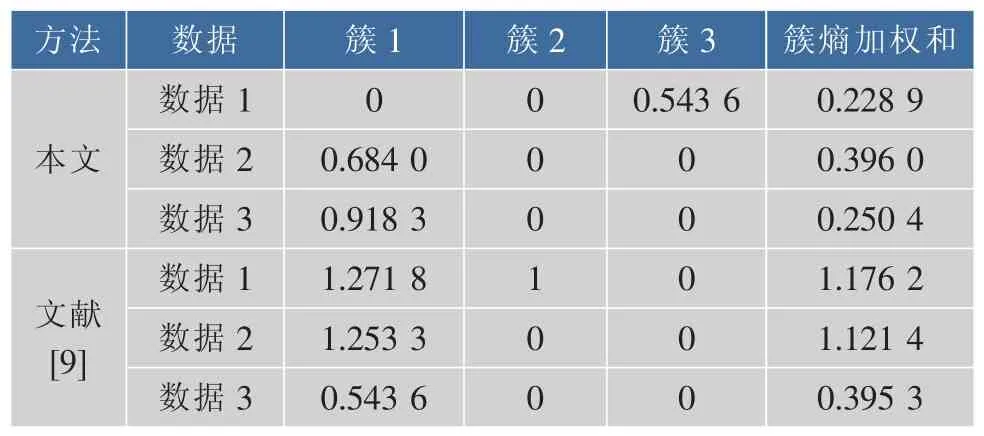
表3 本文方法與文獻[9]的3類數(shù)據(jù)熵值比較Table 3 Compare the entropy values of our method with literature[9]on 3 Data sets
由表1,2可以看出將3種數(shù)據(jù)分別分為3類時,采用本文方法樣本被分錯類的數(shù)目分別為1個、3個、2個,錯分率分別為 1/19=5.3%、3/19=15.8%、2/19=10.5%。與采用文獻[9]的方法相比(樣本被分錯類的數(shù)目分別為10個、9個、3個,錯分率分別為10/19=52.6%、9/19=47.4%、3/19=15.8%), 準確率分別提高了47.3%、31.6%、5.3%。可見將本文的方法應(yīng)用于這3種數(shù)據(jù)的特征提取時能夠提高聚類質(zhì)量。
由表3可看出將3種數(shù)據(jù)分別分為3類時,采用本文方法簇熵加權(quán)和分別為0.228 9、0.396 0、0.250 4。與采用文獻[9]的方法相比(簇熵加權(quán)和分別為 1.176 2、1.121 4、0.395 3),用本文方法產(chǎn)生的結(jié)果簇集具有最小的熵值,說明本文方法聚類結(jié)果較優(yōu)。
因此,對于經(jīng)常用于蛋白質(zhì)氨基酸序列分析的小批量數(shù)據(jù),由圖1~3與表1~3可以看出用本文方法計算出的錯分率與熵值都遠低于文獻[9]中的方法,即頻率域上蛋白質(zhì)序列的特征提取得到的相似度遠遠大于基于DNA序列的特征提取的相似度,本文的方法是有效的,之所以在蛋白質(zhì)序列水平上得到的層次結(jié)構(gòu)要比DNA序列更好,是因為對蛋白質(zhì)序列的相似性進行分析,本質(zhì)上是對組成蛋白質(zhì)氨基酸序列的差異性比較,同一種蛋白質(zhì)DNA序列比氨基酸序列長3倍,隨著序列長度的增加,計算越來越復(fù)雜,并且序列到數(shù)字的映射以及對特征信息處理過程的信息缺失都會影響方法的準確率[2]。
通過本文方法來提取蛋白質(zhì)序列的特征信息有3個優(yōu)點:一是不用直接比較蛋白質(zhì)序列而是去考慮經(jīng)過離散傅里葉變換后這些蛋白質(zhì)序列所對應(yīng)的12維特征向量,特征向量是從組成蛋白質(zhì)序列的氨基酸中提取出來的信息,這樣蛋白質(zhì)序列的比較就轉(zhuǎn)化成了向量之間的比較;二是因為氨基酸序列的親疏水特性、極性非極性跟蛋白質(zhì)的結(jié)構(gòu)有一定的關(guān)系,所以基于氨基酸的這一特性對其分類進而簡化蛋白質(zhì)序列,再提取特征向量可以包含了更多的生物信息;三是基于層次聚類構(gòu)建的分層結(jié)構(gòu)能非常直觀地反映蛋白質(zhì)之間的進化關(guān)系。盡管如此,在提取序列的特征向量時仍然會不可避免地伴隨著某些蛋白質(zhì)序列結(jié)構(gòu)方面的信息丟失。這也正是目前在蛋白質(zhì)的研究中面臨的一大挑戰(zhàn)。
3 結(jié)語
本文將基于DNA序列在頻率域上的表示和離散傅里葉變換構(gòu)造特征向量方法相結(jié)合以表征物種的特征方法進行推廣,提出基于功率譜的蛋白質(zhì)序列特征提取新方法。在研究的過程中采用經(jīng)典HP模型對蛋白質(zhì)的氨基酸序列數(shù)值化;由離散傅里葉變換將序列離散化,根據(jù)定義計算序列的功率譜構(gòu)造蛋白質(zhì)序列的特征向量距離;采用基于距離的層次聚類算法獲取分層結(jié)構(gòu)以考察蛋白質(zhì)序列的相似性。選取3種不同的物種數(shù)據(jù)進行了新方法實驗,以及與文獻[9]中方法的比較研究。實驗結(jié)果表明新方法是可行、有效的,且基于蛋白質(zhì)的氨基酸序列在頻率域上的特征提取方法優(yōu)于基于DNA序列。這些研究結(jié)果對確定未知基因的結(jié)構(gòu)與功能有重要的生物意義,對大規(guī)模的生物數(shù)據(jù)的自動信息處理具有應(yīng)用價值。
猜你喜歡
艦船科學(xué)技術(shù)(2022年15期)2022-09-14 09:21:50
電子制作(2019年15期)2019-08-27 01:12:00
兒童故事畫報(2019年5期)2019-05-26 14:26:14
電子制作(2018年19期)2018-11-14 02:37:08
自動化學(xué)報(2017年11期)2017-04-04 02:52:58
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
