面向事件的中文指代語料庫的構建
2019-01-08 02:13:46張亞軍劉宗田
上海大學學報(自然科學版) 2018年6期
張亞軍, 劉宗田, 李 強, 周 文
(1.上海大學計算機工程與科學學院,上海200444;2.上海精密計量測試研究所,上海201109)
指代是自然語言中一種常見的語言現象,在篇章和對話中大量出現,它使得語言表達簡潔連貫,但在篇章中大量使用指代會增加計算機對篇章的理解難度.指代消解的主要任務就是識別篇章中對現實世界同一實體的不同表達過程[1].以往大量的研究工作都是集中在非事件的文本中[2],取得了一定的成果.隨著“事件”這一概念的興起,越來越多的學者開始著手面向事件的研究.事件關系到多方面的靜態概念,是比靜態概念粒度更大的知識表示單元,以事件作為人類知識的基本單元,更接近人類的認知過程,更符合客觀實際,受到了越來越多領域研究者的關注,并逐漸被計算機語言學、人工智能、信息檢索、信息抽取、自動文摘等知識處理領域所采用.
自20世紀80年代末,一些信息抽取的國際測評會議開始興起,如信息理解會議(Message Understanding Conference,MUC)、自動內容抽取(automatic content extraction,ACE)會議等,這些會議為信息抽取以及指代消解等自然語言處理技術提供了統一的測試語料和測評方法.這些會議的召開在很大程度上推動了指代消解的發展,特別是會議提供的測試語料,使得指代消解系統從基于啟發性規則的消解方法轉向了基于數據驅動的消解方法.例如,MUC語料采用的是標準通用標記語言(standard generalized markup language,SGML)標注方法[3],用<COREF ID= “x”>,<COREF ID= “x”REF=“y”>分別表示實體、參照表達式的左邊邊界,用</COREF>表示實體、參照表達式的右邊邊界.x從1開始嚴格單調遞增,表示實體在文本中的順序標號,REF表示該實體的先行語信息,如果y等于某一個x的值,則這個參照表達式的先行語就是ID號為x的實體,若無REF值,則這個實體不存在先行語.而ACE語料與MUC語料不同,以ACE 2005[4]為例,是通過指代鏈描述文本中的指代關系,將指向同一實體的表達都放在一條具有相同編號的指代鏈中.值得一提的是,ACE語料從ACE 2003開始加入中文語料,目前已達到30萬字的訓練語料、5萬字的測試語料,而且加入了對事件提及的評測,這是最早針對中文指代消解的國際測評語料資源,對于中文指代消解的發展起到了很大的推動作用.2011年,CoNLL提供了針對英文的OntoNotes 4.0[5]語料庫,而且對事件名詞與動詞的共指關系進行了標注,并在2012年推出OntoNotes 5.0[6]語料庫,提供英文、中文以及阿拉伯文的語料進行多語言的共指消解評測.近年來,國內對指代消解的研究也逐漸增多,相關語料庫的構建也有很多.例如,趙知緯等[7]在ACE 2005中文語料庫的基礎上構建了一個面向信息抽取的中文跨文本指代語料庫,舒佳根等[8]在ACE 2005中文語料和中文維基百科的基礎上構建了一個實體鏈接語料庫.
然而,上述語料庫大多不是基于事件的標注,雖然ACE語料庫定義了8類事件,并對事件提及進行了評測,但其對事件的理解還停留在篇章層次,沒有細化到具體的句子,并不能覆蓋所有事件,而且對事件提及的評測并沒有涉及共指消解的問題.OntoNotes語料庫提供的關于事件的共指關系僅僅涉及英文,不適合中文的語句分析.國內大多數語料庫也是建立在類似ACE中文語料的基礎上,并沒有以事件作為知識表示單元進行標注.事件中涉及多方面的實體,稱為要素,與傳統文本中的靜態概念一樣,同樣存在大量的指代現象,同時事件本身也存在不少指代,對于面向事件的應用來說,這些指代帶來了很多不確定性,需要對它們進行處理和研究,這就需要語料庫的幫助.然而到目前為止,還沒有面向事件的中文指代語料庫.
本工作就是為了彌補這一方面的缺陷,在中文突發事件語料庫(Chinese emergency corpus,CEC)的基礎上,構建了一個面向事件的中文指代語料庫,其中包括了對已存在要素、缺省要素和事件的指代標注.與傳統的中文指代語料庫相比,面向事件的中文指代語料庫有其自身的優點:①面向事件的中文指代語料庫是建立在事件的基礎上,以事件作為知識表示單元,反映了事物的動態性,更符合客觀實際,便于計算機模擬大腦工作;②傳統的指代標注進行了過多實體類別的劃分,而面向事件的指代標注是依托事件和事件要素進行的標注,分類少,而且結構清晰;③面向事件的指代標注不僅對指向同一實體的要素進行標注,而且對基準類型的指代進行了標注,通過這種指代關系,可以將抽象要素具體化;④基于事件的標注使傳統指代中的零指代消解[9]轉變為缺省要素[10]的指代消解,使實體要素化,結合事件的語言表現規則,更利于缺省要素的識別和消解;⑤傳統的指代消解因缺少必要的篇章知識用于消解,容易受到限制,而面向事件的指代標注可以通過與事件關系[11-12]的結合,挖掘出更多的篇章知識,提高指代消解系統的性能.雖然受CEC語料的限制,語料庫規模較小,但本工作的初步研究可以為面向事件的中文指代消解提供一個有效的資源支持,對于面向事件的應用來說有十分重要的意義.
1 相關定義
定義1 事件(Event)[13]指在某個特定的時間和環境下發生的、由若干角色參與、表現出若干動作特征的一件事.形式上,事件可以表示為e,定義為一個六元組:
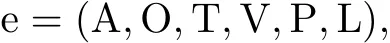
式中,事件六元組元素稱為事件要素,分別表示動作、對象、時間、環境、斷言、語言表現.本工作僅對對象、時間、環境三個要素進行指代消解的標注研究.
O(對象),指事件的參與對象,包括參與事件的所有角色,這些角色的類型數目稱為對象序列長度.對象可分別是動作的施動者(主體)和受動者(客體).主體是主導者,是事件的主角,有時是事件的制造者或期望事件的發生者.客體是事件中的被動者.
T(時間),事件發生的時間段,從事件發生的起點到事件結束的終點,分為絕對時間段和相對時間段兩類.
V(環境),事件發生的場所及其特征等.例如,在小池塘里游泳,場所為小池塘,場所特征為水中,其中場所特征是現實世界中隱藏的無形環境,是人們通過常識在頭腦中經過簡單推理得出,并沒有顯示在文本中.
定義2 事件類(Event Class)[13]指具有共同特征的事件的集合,用EC表示,定義如下.
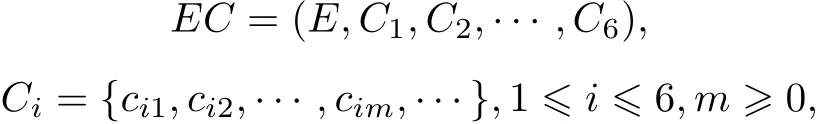
式中:E是事件的集合,稱為事件類的外延;Ci為事件類的內涵,表示每個事件在第i個要素上具有的共同特性的集合;cim是事件類中每個事件在第i個要素上具有的一個共同特性.
定義3 事件觸發詞(Trigger)[14]又稱事件指示詞或事件核心詞,是指文本中可以用來清晰表示所發生事件的詞.一般情況下,觸發詞是句子中的主要動詞(也可能是名詞),觸發詞直接描述了事件.
定義4 先行要素和照應要素 面向事件的中文文本中如果存在要素間的指代關系,表達較為具體的要素稱為先行要素,表達較為抽象的要素稱為照應要素.
定義5 先行事件和照應事件 面向事件的中文文本中如果存在事件間的指代關系,表達較為具體的事件稱為先行事件,表達較為抽象的事件稱為照應事件.事件的具體和抽象的判別與事件所包含的要素是否齊全有關,即事件的對象、環境和時間要素是否缺省.
定義6 面向事件的指代消解 在面向事件的文本中尋找先行要素(或先行事件)和照應要素(或照應事件)之間的關系,并明確給出照應要素(或照應事件)所指向的先行要素(或先行事件)的過程.
2 語料庫的標注
面向事件的中文指代語料庫是在CEC的基礎上進行的標注,共有兩大類指代關系的標注,分別為事件要素(對象、環境和時間)的指代標注和事件的指代標注,其中事件要素的指代標注又分為已存在要素的指代標注和缺省要素的指代標注.
2.1 CEC
CEC是上海大學語義智能實驗室以從互聯網上收集的關于地震、火災、交通事故、恐怖襲擊以及食物中毒五類突發事件的新聞報道作為生語料,經過事件和事件要素等人工標注,并經過統計和分析構建的面向事件的中文語料庫,目前共有332篇,具體的統計情況如表1所示.

表1 CEC統計概況Table 1 CEC statistics
2.2 指代標注方式
為方便計算機處理,CEC語料采用的是XML語言進行的標注,而且事件要素分為已存在要素的指代標注和缺省要素的指代標注,所以指代的標注有兩種標注形式:第一種形式為屬性(Attribute)標注,這種標注只針對要素的指代,與事件的標注無關,目的是進行事件中缺省要素的標注;第二種形式為標識(Tag)標注,即單獨用一個標識進行指代標注,目的是進行已存在要素的標注和事件的標注.
2.2.1 屬性標注
屬性標注的標注位置是在各個要素標識的表示順序編號的屬性里:對象要素是在標識Participant或Object的屬性sid(主體編號)或oid(客體編號)中進行標注;環境要素是在標識Location的屬性lid中進行標注;時間要素是在標識Time的屬性tid中進行標注,下面分別舉例說明.
對于對象要素(見圖1),事件e3與事件e4的主體對象缺失,它們的對象都為事件e2的對象,所以在事件e2的對象屬性sid中同時標出事件e3與事件e4的對象標號s3,s4,以此表示此對象在事件e3與e4中也充當主體對象.有時一個事件的主體也可能在另一個事件中充當客體,這時就要用oid進行標注,比如事件e2的對象在e3中作為客體,則標注為<Participant sid=“s2”oid=“s3”>,或者是一個事件的客體在另一個事件中充當客體或主體,也是按以上形式標注.Object類型的對象也是如此.
對于環境要素(見圖1),事件e2的發生地點同時也是事件e3和事件e4的發生地點,這時就要在事件e2的環境要素屬性lid中進行標注.
對于時間要素(見圖2),事件e19和事件e20都是在時間編號為t19的時間段內發生的,這時就在事件e19的屬性tid中同時標注出t20.

圖1 對象和環境要素的屬性標注Fig.1 Attribute labels of object and environment elements

圖2 時間要素的屬性標注Fig.2 Attribute labels of time elements
2.2.2 標識標注
為了區別缺省要素的屬性標注,加入eAnaphora標識用以進行事件中已存在要素以及事件的指代標注,詳細表示為<eAnaphora anaType=“”aid=“”antecedent=“”rid=“”anaphor=“”/>.
(1)屬性anaType表示指代類型,即哪種要素的指代,或是事件的指代.若是對象要素的指代,屬性值為Object;若是時間要素的指代,屬性值為Time;若是環境要素的指代,屬性值為Location;若是事件的指代,屬性值為Event.
(2)屬性aid表示指代中的先行要素(或先行事件)的順序編號,屬性antecedent表示指代中的先行要素(事件指代標注沒有這個屬性).
(3)屬性rid表示指代中的照應要素(或照應事件)的順序編號,屬性anaphor表示指代中的照應要素(事件指代標注沒有這個屬性).
所以,標識標注共有4種類型表示各要素及事件的指代,如圖3所示.
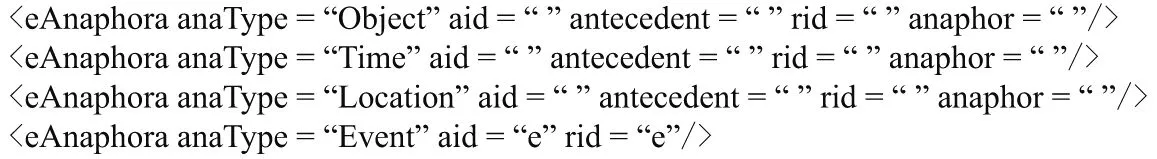
圖3 標識標注Fig.3 Identification labels
2.3 標注過程
基于CEC的指代標注分為語料庫的預處理、自動標注和人工標注三個過程,下面對標注規范進行說明.
2.3.1 標注規范說明
標注規范的制定,可以在一定程度上縮小不同標注者在標注時的差異,減少語料標注過程中的錯誤和不一致性,提高標注的效率.面向事件的中文文本指代標注與傳統文本的指代標注是有差別的,對于缺省要素的標注在2.2節已作了說明,這里僅對已存在要素和事件的標注作簡要說明.
(1)對象要素:事件中對象要素有兩種語義類別,在語料庫中分別以Participant和Object這兩個標識進行標注,前者與人有關,后者與物有關,所以它們不屬于一個語義類別,是不能相互指代的.
(2)環境要素:對于環境要素的標注,除了標注指向同一地理位置的要素,還要進行基準類型的標注,即通過先行環境要素,可以將照應環境要素的地理位置具體化.例如,“香溪洞景區”←“附近山體”,通過這種指代,可以將照應要素的地理位置具體化,可得知具體是在什么地點附近.
(3)時間要素:時間要素與環境要素類似,除了標注指向同一時間的要素,也要進行基準類型的標注.例如,“27日傍晚6時左右”←“隨后”,通過這種指代可以確定隨后是以哪個時間為基準.
以上是針對要素的標注規范說明,事件的指代標注與事件要素的指代標注是有區別的,事件包含對象、時間、環境等各個要素,即事件是由要素組成的.而事件要素的指代沒有考慮事件之間的關系,只將兩個要素單獨進行指代關聯.事件之間的指代,需要將各要素綜合起來考慮,有時還需要聯系上下文,根據上下文來判斷兩個事件是否表示同一個事件.
規定兩個事件具有指代關系的標準如下.
(1)因為事件的觸發詞直接描述了事件,所以首先比較兩個事件的觸發詞是否相同或同義,若是,則進行下一步,否則兩事件無指代關系.
(2)比較兩個事件各要素,因為每個事件必須包含觸發詞,而其他要素可能缺省,不會出現,所以要根據上下文補全缺省要素,然后判斷兩事件是否具有指代關系.具有指代關系的兩事件的各要素必須一致,即指向現實中的同一實體.
通過上述兩步就可以確定事件間的指代關系.
2.3.2 語料庫的預處理
CEC中沒有對標識為ReportTime的報道時間進行編號,由于ReportTime在時間要素的指代標注中可以作為基準時間,因此在標識中加入屬性tid,屬性值為t0.另外,CEC語料在最初標注時,沒有考慮到指代消解的研究,所以對于對象要素的標注粒度沒有作一定的規范限定.這里規定為粗粒度標注,即將修飾對象的一些修飾語連同對象一起標注,因為這些修飾信息往往包含了對象的職業、身份等有價值的信息,在以后的對象要素指代消解中,可以將抽象的對象要素具體化.例如,“中國地震局新聞發言人張宏衛”←“張宏衛”,這種指代的識別就可以得到照應要素的具體身份,對基于事件的推理提供幫助.
2.3.3 自動標注
在自動標注階段,基于缺省要素標注的復雜性,僅對已存在要素和事件進行標注.對于已存在要素,通過簡單的字符串匹配規則,采用標識標注形式進行標注;對于事件,通過對觸發詞進行同義詞的檢測方法,采用標識標注形式進行標注.
2.3.4 人工標注
在人工標注階段,要安排3個人工作.首先,安排兩位標注者對自動標注階段生成的指代鏈進行校正;然后通過文本進行補全,包括自動標注階段沒有識別出的指代,以及缺省要素的指代標注;兩位標注者在標注期間不準商量,兩位標注者完成標注后,由第三個人進行仲裁.仲裁者首先找出兩位標注者之間的差異,針對這些差異,通過外部知識來解決分歧,確定最終的指代鏈.
2.3.5 指代鏈輸出
經過上述步驟后,就會得到最終的標注結果.缺省要素的標注結果已在圖1和2中展示,圖4是已存在要素和事件的標注結果.

圖4 指代鏈Fig.4 Coreference chains
2.4 標注工具
標注規范的制定可以減少語料的不一致,而方便、高效的標注系統可以大幅度提高標注的效率和準確性,防止標注者出現誤操作.圖5是面向事件的中文指代語料標注工具界面,左邊的空白處是對生語料進行事件要素、指代關系等標注的文本框,右邊是添加XML標識以及各標識的屬性,頂欄是工具欄.為了減輕標注者的負擔,該標注軟件提供了自動檢查的功能,可以防止文檔中出現不合法的標識,在一定程度上防止錯誤的語料進入語料庫.
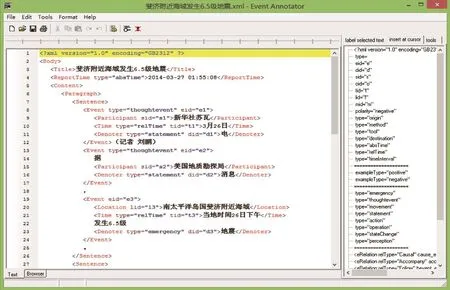
圖5 標注工具Fig.5 Annotation tool
3 語料庫的統計與分析
3.1 一致性檢驗
為了保證語料標注的質量,兩位標注者同時對語料庫進行標注,目的是進行標注結果的一致性檢測.本工作采用Passoneau[15]提出的語料庫指代標注可靠性計算方法,并根據Krippendorff[16]的alpha系數來表示兩位標注者標注結果之間的一致性.該方法通過一個距離度量來表示指代鏈之間的相似度,然后通過alpha系數計算指代鏈之間的相似度距離來表示不同標注者標注結果之間的一致性.
Passoneau相似度距離度量原則如下.
(1)當兩條指代鏈完全吻合時,距離為0;
(2)當一條指代鏈是另一條指代鏈的子集時,距離為0.33;
(3)當兩條指代鏈不互相包含且有公共的非空子集時,距離為0.67;
(4)當兩條指代鏈交集為空集時,距離為1.
按照以上原則,根據兩位標注者的標注結果,計算得到alpha系數為94.6%.Krippendorff認為,低于67%的alpha系數表明標注結果不可靠,因此認為兩位標注者的標注結果高度一致.
3.2 語料庫分析
目前已經標注完的語料共有100篇,其中地震、火災、交通事故、恐怖襲擊和食物中毒各20篇.這是第一期的標注,旨在確定標注流程和規范,對其中的指代進行了統計分析,在以后的工作中,會進一步基于CEC的剩余部分進行標注,并繼續擴大.
3.2.1 指代分類
通過對已標注語料進行統計,對已存在要素的指代可以進行如下分類.
對于對象要素,可以分為如下4類.
(1)表述相同,即存在指代的兩個要素的字符串完全匹配,例如“中國地震局新聞發言人張宏衛”←“中國地震局新聞發言人張宏衛”;
(2)縮略指代,即存在指代的兩個要素中,照應要素是先行要素的一部分,例如“滾滾濃煙”←“濃煙”;
(3)表述不同,即存在指代的兩個要素在文字表達上不同,兩個要素間可能一個是另一個的別名,或者根據上下文,兩個要素都指向同一個實體,例如“中華人民共和國”←“中國”,“修理巷道的20名礦工”←“被困人員”;
(4)代詞類指代,即存在指代的兩個要素間,一個要素為代詞,例如“李女士”←“她”.
對于環境要素,可以分為5類,其中前4類與環境要素相同,下面只舉例說明.
(1)表述相同,例如“醫院”←“醫院”;
(2)縮略指代,例如“四川省汶川縣”←“四川汶川”;(3)表述不同,例如“四川省汶川縣”←“災區”;
(4)代詞類指代,例如“750~850米處巷道”←“該段”;
(5)基準指代,此類指代與前4類是不同的,也是面向事件的指代與傳統指代的不同點,前4類中存在指代的兩個要素都是指向同一實體,而此類指代并非指向同一實體,而是以先行要素為基準,來確定照應要素的具體位置,例如“香溪洞景區”←“附近山體”.
對于時間要素,可以分為如下2類.
(1)同一時間,即存在指代的兩個時間要素指向同一時間,例如“昨晚8時30分許”←“此時”;
(2)基準指代,與環境要素中的基準指代相似,是以先行要素為基準時間來確定照應要素的具體時間,例如“27日傍晚6時左右”←“隨后”.
3.2.2 指代統計
在已標注的100篇語料中,共有1 767個事件,1 623個對象要素,522個環境要素,539個時間要素,其中對于已存在要素的指代數據如表2所示,缺省要素的指代數據如表3所示,各類事件的指代數據如表4所示.
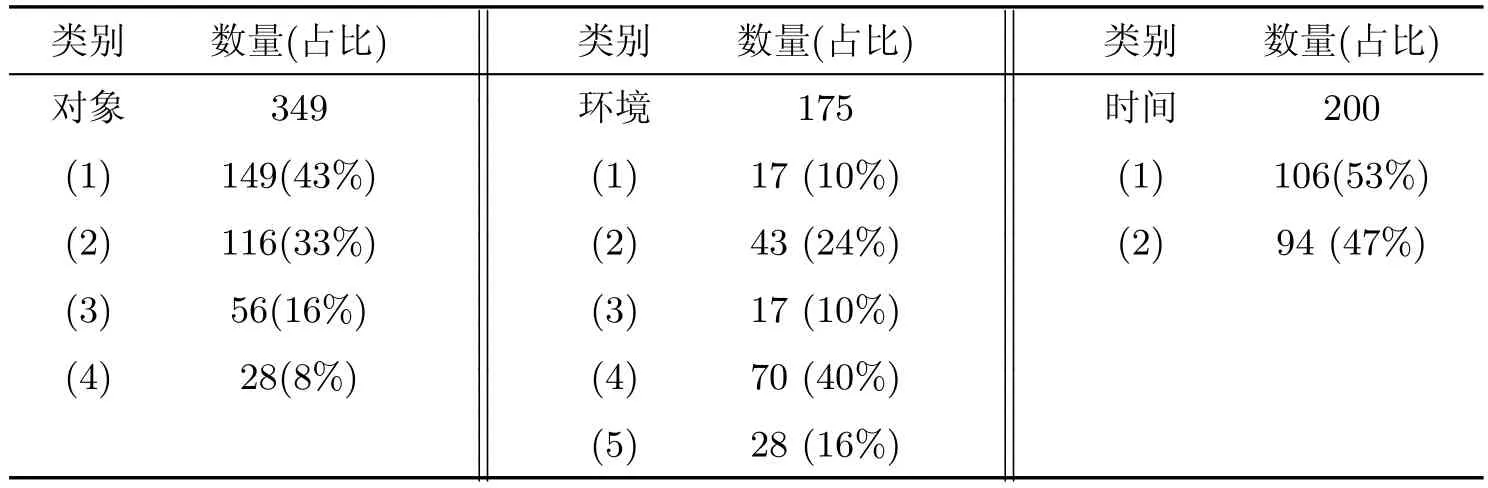
表2 已存在要素的指代統計Table 2 Coreference statistics of existing elements 個

表3 缺省要素的指代統計Table 3 Coreference statistics of default elements 個
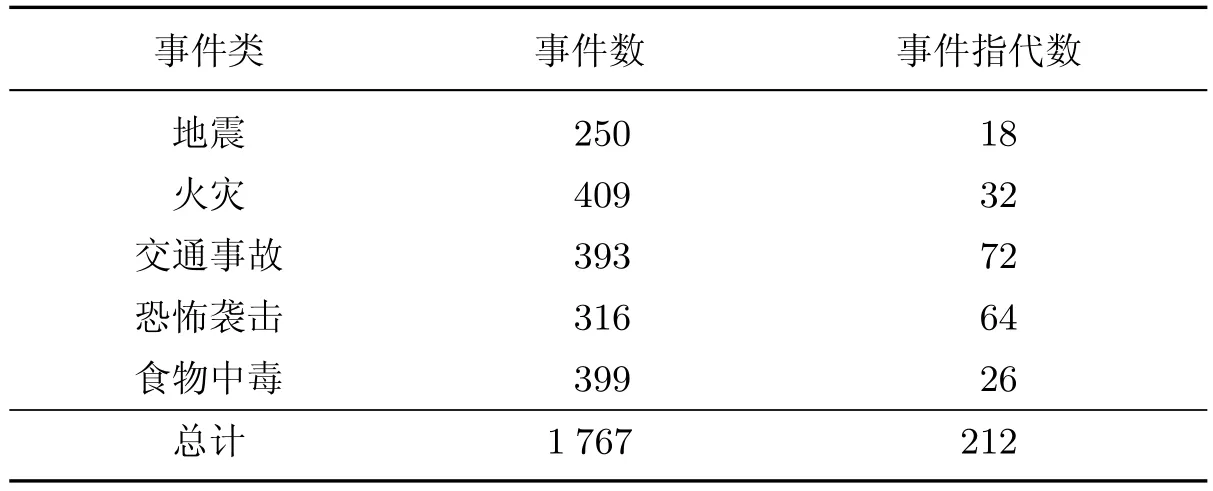
表4 各類事件的指代統計Table 4 Coreference statistics of several kinds of events 個
3.3 語料庫分析
3.3.1 已存在要素指代分析
對于事件中對象、環境和時間的已存在要素的指代,表2已詳細統計了每個要素的指代數量,以及每個要素的不同類別的指代數量.對每種要素中的指代進行分類,可以對后續研究中實現各個要素指代的自動識別提供幫助,也可以幫助設計者思考如何設計算法來達到更優異的系統性能.
對象要素和環境要素的前4類與傳統文本中的指代消解有許多共性,其指代的都是同一實體,這里不再分析,只進行環境要素的基準指代和時間要素的分析.
環境要素中的基準指代與傳統意義上的指代有所不同,存在指代關系的兩個要素并不是指向同一實體,而是一種關聯關系,即通過先行環境要素來確定照應環境要素的具體位置.從表2中可看出,這種類型的指代占整個環境要素指代的16%,所以其識別與否對于指代消解系統的性能有顯著的影響.在已標注的語料中,對這種指代關系進行統計得出,照應環境要素基本上都是以“周圍”“附近”“外面”這種抽象的地理位置詞開頭,可以通過構建一個抽象環境要素的詞典進行識別,然后再找出其對應的先行要素.這僅僅是初步的構想,具體實現還要綜合各種因素進行考慮.
時間要素中的基準指代與環境要素是類似的,有別于傳統意義上的指代,并且對其識別也與環境要素類似.在已標注語料中,具有此類指代關系的兩個時間要素,其照應要素大多是“昨天”“今天”等抽象時間詞,可通過構建一個抽象時間要素詞典進行識別,再找出其對應的先行要素.對于同一時間的指代,在標注中發現,具有此類指代關系的兩個時間要素,照應要素也是一些抽象的時間詞,比如“現”“當時”等,因為語料都是新聞題材類的文本,所以“目前”和“現”大多指代的是新聞的報道時間,而對于“當時”,其先行時間一般出現在前一個事件中或與其最近的且包含時間要素的事件中.
3.3.2 缺省要素指代分析
在語料庫中,一個完整的事件應該包含對象要素、環境要素、時間要素和觸發詞,其中對象要素又包含主體和客體,也就是說,一個完整的事件應包含6個部分,而觸發詞是每個事件必須含有的,其他3個要素可以省略.為了描述各個要素的缺省程度,這里用“缺省度”來衡量:

已標注語料中各要素的缺省量如表5所示.

表5 事件中各要素缺省量Table 5 Default number of each elements in events 個
通過計算得到對象要素的缺省度為51%,環境要素的缺省度為73%,時間要素的缺省度為75%,由此可看出,環境要素和時間要素的缺省程度較大.但這里對對象要素的統計沒有區分主體與客體,不能準確表示對象要素的缺省度,所以又對主體與客體的數量進行了統計,如表6所示.

表6 事件中主體與客體缺省量Table 6 Default number of subject and object in events 個
這里假設每個事件都應存在主體與客體,從表6中可以得到對象要素中主體的缺省度為57.2%,客體的缺省度為88.5%,客體缺省度遠遠大于主體缺省度.
缺省要素的指代消解分為兩個步驟:缺省要素的指代識別和缺省要素的指代消解.對于缺省對象要素的指代識別,其難度要比環境要素和時間要素要大,因為一個事件肯定發生在某個時間的某個地點,也就是說一個事件中環境要素和時間要素只要不存在就可判斷為缺省.而對象要素在一些事件中是可以不存在的,即要對對象要素是否缺省進行識別,而且對象要素又分為主體對象和客體對象,這就進一步加大了識別的難度,要判斷是缺省客體還是缺省主體,還是主體與客體都缺省.從語料庫中發現,對于一些事件,主體和客體的缺省與觸發詞有關,包含某些特定觸發詞的事件往往不包含對象要素,有的只缺省主體或者缺省客體,有的主體和客體都缺省,不過這只是初步構想,對于對象要素缺省指代識別,還需進一步研究.
將表3和5進行比較發現,各要素標注出的缺省指代數與各要素的缺省量不一致,那是因為缺省要素的標注只能根據篇章中已經存在的要素進行缺省要素補全,而一些事件的缺省要素在文中是沒有描述的,這時是不能進行補全的,也就是說缺省指代只能根據已存在要素在一定程度上補全缺省要素.
3.3.3 事件指代分析
從表4的統計結果來看,事件的指代數量還是比缺省要素少,在5個事件類中,交通事故和恐怖襲擊中指代的比例較高,這說明在這兩個題材的新聞報道中,同一事件被重復提及的概率較大.事件指代的目的與缺省要素的指代一致,是將缺失若干要素的事件通過一篇文章上下文中的具體事件進行補全.只不過事件指代針對的是同一事件,而缺省要素的指代既可以針對同一事件,也可以針對不同事件.
對于事件的指代,從3.3.1節中提及的關于事件指代的標準可以看出,事件的指代有兩個關鍵點:事件觸發詞和事件要素的組成.對于具有指代關系的兩個事件,其觸發詞肯定同義或相同,因為觸發詞直接描述了事件.只有觸發詞相同還無法判定,觸發詞相同只能說明事件間屬于同一個事件類,而不是同一個事件,還要通過判斷兩個事件各自的事件要素的組成,才能最終判定.
4 結束語
面向事件的中文指代語料庫是在CEC的基礎上,采用自動標注和人工標注的方法構建而成,以此進行事件中指代消解的研究.目前已標注完成100篇,第一期標注的語料已基本完成.本工作在已標注語料的基礎上,通過對已存在要素指代、缺省要素指代和事件指代的統計,進行了初步分析,為今后的研究打下基礎.
任何語料庫的構建都不可能是完美無缺的,肯定會存在一些問題和不足,由于本工作所構建的語料庫是基于CEC的,所以規模較小,在今后還要利用自動或手工的方法進一步擴充,循序漸進地改進,在今后的研究中不斷完善.
