基于深度強化學習的追逃博弈算法*
2019-01-07 07:13:28鞏慶海王會霞
航天控制 2018年6期
譚 浪 鞏慶海 王會霞
1.北京航天自動控制研究所,北京100854 2.宇航智能控制技術國家級重點實驗室,北京 100854
遠距離非接觸式的精確打擊已成為現代軍事作戰的主要手段,為提高導彈作戰效能,導彈攻防對抗已成為現代軍事研究的主要問題。在導彈攻防對抗中,進攻彈和攔截器具有相反的作戰目的:進攻彈為逃逸者,為達成作戰目的需要盡量躲避攔截器,而攔截器為追捕者,需要使目標處于殺傷或捕獲范圍之內,雙方構成追逃博弈[1]。
目前,導彈攻防對抗的大多研究都是從經典控制方法出發,通過建立攻防雙方微分對策模型,設計制導律來提高導彈武器的作戰效能。例如,文獻[2]通過對比例導引進行改進,使用卡爾曼濾波算法估計地方飛行信息,并使用姿態搜索算法以確定彈頭的機動方向;文獻[3]通過建立追逃對策模型,使用配點法對其進行求解,得到機動策略。文獻[4]將導彈抽象為智能體,從多智能體系統的角度研究攻防對抗問題,但僅用以解決仿真中時空不一致的問題,并沒有從智能算法的角度研究導彈攻防對抗過程。
隨著人工智能技術的飛速發展,各國正致力于研究智能化程度更高的導彈和武器系統來替代現有的設計方案[5]。當AlphaGo在圍棋領域擊敗人類頂尖選手時,深度強化學習已經成為備受學者們關注的研究熱點[6-7]。深度強化學習技術被認為是最有可能實現通用人工智能計算的重要途徑之一,具有很強的通用性。目前深度強化學習在經典控制領域的應用是OpenAI公司使用深度Q網絡(Deep Q Network, DQN)算法在模擬環境gym下對倒立擺進行了穩定控制[8]。此外,在真實場景下的應用是使用近端策略優化(Proximal Policy Optimization, PPO)算法對機械臂控制,使其完成抓取木塊的操作[9]。
用三維空間中的導彈攻防問題抽象為二維平面中智能小車的追逃問題,在DDPG算法[10]的基礎上提出一種追逃博弈算法。該算法的回報函數采用PID控制的思想進行設計,并在Epuck小型移動機器人上進行了追逃博弈實驗驗證。算法以定位系統獲得的位置信息作為輸入,通過對神經網絡進行訓練,輸出追捕者的控制指令,控制其最終成功地完成追捕任務。
1 追逃博弈模型
一對一追逃博弈場景分為一個逃跑者和一個追捕者,它們具有相反的目的:逃跑者要躲避追蹤,而追捕者要捕獲逃跑者。
一對一追逃博弈模型如圖1所示:
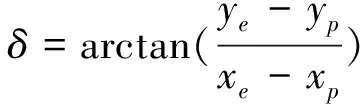
追捕者與逃跑者的運動學模型為:
(1)
式中:i是指追捕者P和逃跑者E;(xi,yi)是智能小車的位置;θi是方向;ui是轉向角,ui∈[-uimax,uimax];vi是由轉向角控制的智能小車的速度;φi表示速度方向與視線角的偏差。
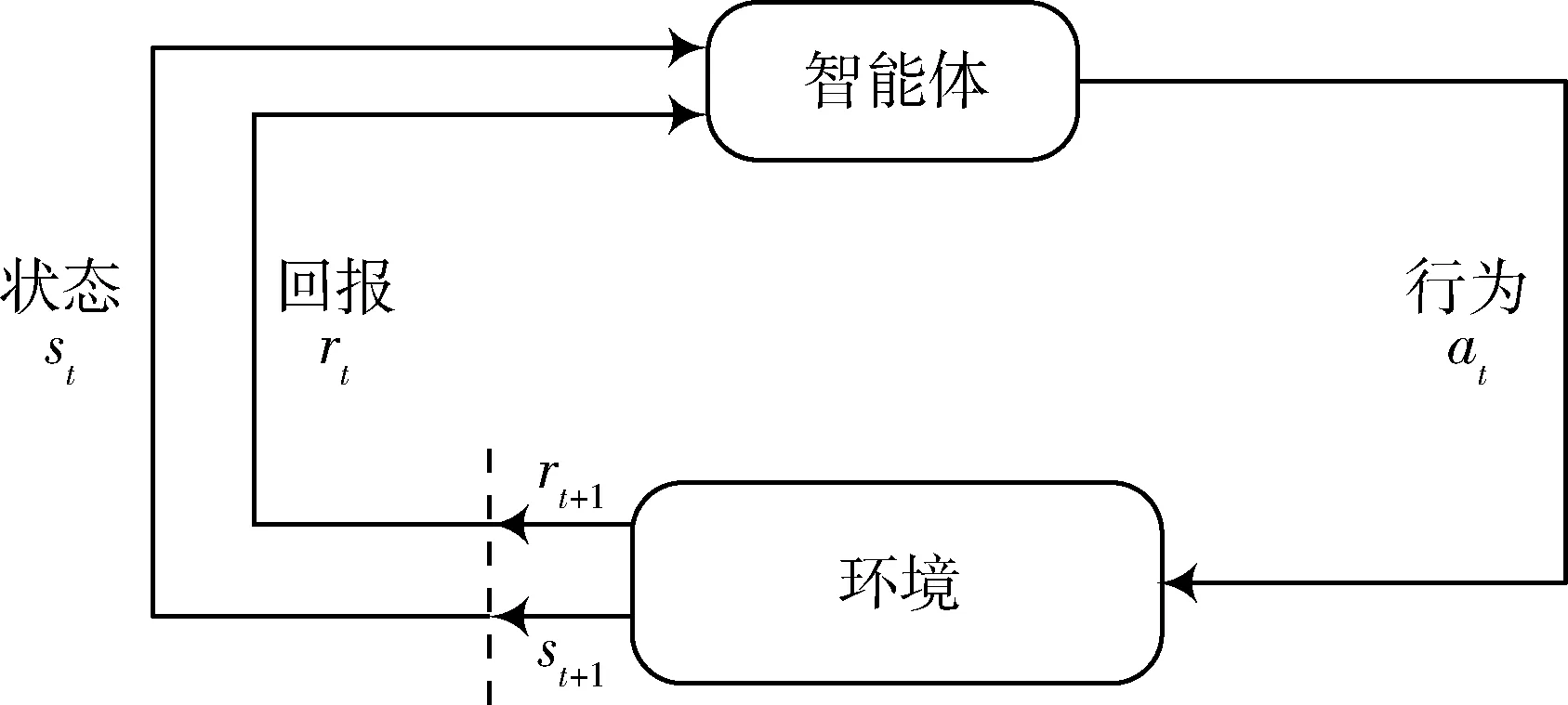
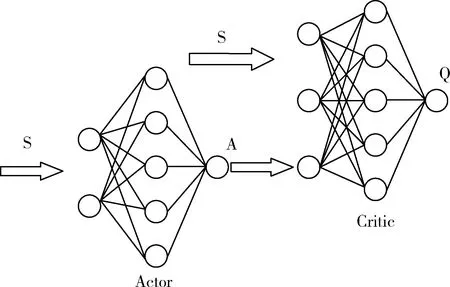
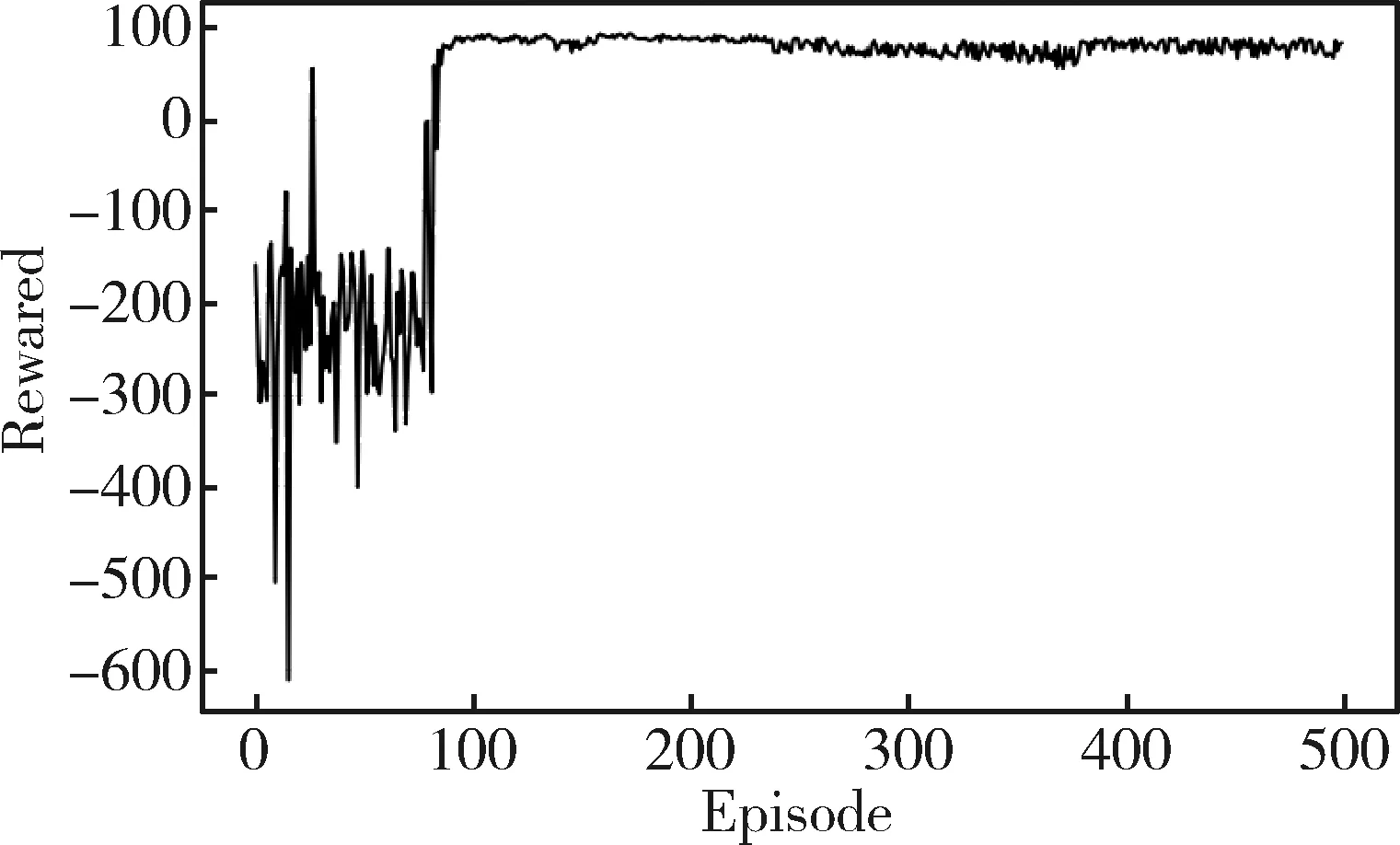
在圖1所示的追逃博弈模型中,設定追捕者應快于逃跑者,即vpmax>vemax,但同時追捕者的機動能力比逃跑者差,即upmax 馬爾科夫決策過程(Markov Decision Process , MDP)由一個五元組(S,A,T,R,γ)描述[11],其中:S為有限的狀態空間;A為有限的行為空間;T為狀態轉移函數;R為回報函數;γ為折扣因子。轉移函數表示在給定當前狀態和行為下,轉移到下一狀態的概率分布: (2) 式中:s′表示下一時刻的可能狀態。 回報函數表示給定當前行為和狀態下,在下一狀態得到的回報。馬爾科夫決策過程具有如下的馬爾科夫特性:智能體的下一時刻的狀態和回報僅取決于智能體在當前時刻的狀態和行為。 在任一馬爾科夫決策過程中,智能體都存在一個確定的最優策略,強化學習的目標就是尋找給定的馬爾科夫決策過程中的最優策略。 強化學習是智能體自主探索環境狀態,采取行為作用于環境并從環境中獲得回報的過程。一般而言,強化學習問題是建立在馬爾科夫決策過程模型的基礎上。 圖2 強化學習框架 強化學習框架如圖2所示。智能體在當前狀態s下,采取行為a,根據狀態轉移函數T,環境會轉移到下一狀態s′,同時環境會對智能體反饋一個獎勵信號,即回報r。智能體在下一狀態按照上述過程依次進行。智能體的目標是通過不斷地訓練,獲得最大化的長期回報。為評估智能體策略,定義狀態值函數Vπ(s)為:當智能體從狀態s開始并隨后執行策略π時,在該策略下狀態的值。因此: (3) 式中:T為最終時刻;t為當前時刻;rt+1為在t+1時刻得到的回報。 由圖2可知,環境反饋給智能體的回報r與狀態s和動作a有關,可用價值函數來描述之間的關系。定義行為值函數Qπ(s,a)為:當智能體從狀態s選擇特定行為a并隨后執行策略π而得到的預期回報。一個最優策略π*將使得智能體在所有狀態下可獲得最大化的折扣未來回報。則在最優策略下的行為值函數Q*(s,a)可重寫為一個貝爾曼最優方程: (4) 對于圖1所示的智能小車追逃博弈場景而言,環境的狀態及智能體的動作都是連續量。因此,使用深度學習中的神經網絡構造函數逼近器,得到近似的行為值函數。Q值神經網絡定義為: Q(s,a)≈f(s,a,w) (5) 式中:w是指神經網絡的參數。 以深度強化學習中的DDPG算法為基礎,定義MDP狀態空間與行為空間,設計回報函數,從而實現智能小車的控制算法,用以對追捕者進行導航與控制,使其盡可能快地追上逃跑者。 通過使用定位系統實時獲得各智能小車的位置信息,以此為基礎構造輸入神經網絡的狀態量。對于圖1所示的追逃博弈場景,本文算法的目的是最小化追捕者和逃跑者之間的相對距離。因此,給出MDP狀態空間如下: S=[L,δ]T (6) 在本文第1節所設定的追逃博弈場景中,逃跑者的狀態可以是靜止、勻速直線運動或帶有機動的運動(即角速度不為0)。追捕者的策略是由神經網絡的輸出給定。因此,給出MDP動作空間為up。更近一步,由式(1)可知,追捕者轉向角影響的是追捕者的角速度,因此,動作空間為: (7) 對于追逃博弈場景而言,MDP轉移函數即為各智能小車的運動學方程,即式(1)。 追捕者的目的是成功捕獲逃跑者,由于實驗場地的限制,追捕者不能越過邊界,否則認為追捕任務失敗。因此,在最終時刻,如果追捕任務成功,則給予一個較大的正回報,否則給予一個較大的負回報。對于在追捕任務過程中的回報函數的設計,借鑒PID控制思想,即:如果追捕者的速度方向與視線相同,則追捕者一定能成功追捕逃跑者(因為追捕者速度大于逃跑者)。因此,追捕任務過程中的回報定義為:kφp。綜上所述,MDP回報函數設計如下: (8) 式中:k是比例因子。 本文采取強化學習中的異策略(off-policy)學習方法,神經網絡的架構采用AC(Actor-Critic Algorithm)的方法,即使用Actor網絡得到行為策略,使用Critic網絡得到評估策略。Actor-Critic 網絡結構如圖3所示。 由于定位系統得到的智能小車的位置信息是一個在時間上連續的序列,因此由狀態構成的樣本之間并不具備獨立性。為解決這個問題,本文算法使用了經驗回放和獨立的目標網絡。經驗回放即將樣本存儲在經驗池中,并在經驗池達到一定程度后隨機從中選取若干樣本進行訓練。使用獨立的目標網絡即再使用一個與策略網絡結構一樣的AC網絡。 圖3 Actor-Critic網絡結構 神經網絡的訓練過程實質上是通過構造一個代價函數,對其進行梯度下降,從而可得到最優的神經網絡參數。Actor網絡輸出的是智能體的行為策略,Critic網絡輸出該行為的評估。因此,Critic網絡的代價函數如下: Li=E[(yi-Q(si,ai|θQ))2] (9) 式中:yi=E[ri+γQ′(si+1,μ′(si+1|θμ′)|θQ′)]。 Actor網絡的策略梯度為: (10) 目標網絡采用延遲更新的方式,即一定時間后將目標網絡參數替換為策略網絡的參數。 智能小車追逃博弈算法如表1所示。 本文采用的智能小車是由瑞士聯合科技院研制的Epuck小型移動機器人,具體構造如圖4所示。Epuck智能小車由DSPIC處理器驅動,車身一周覆蓋有8個紅外距離傳感器,可測量傳感器前方6cm的物體,并且集成了VGA彩色攝像頭和8個LED。此外,智能小車可配備擴展板,通過WiFi與計算機和其他智能小車間通訊。本文對于智能小車的具體型號并不做嚴格要求,其僅作為本文算法驗證的執行機構。 表1 追逃博弈算法 圖4 Epuck移動機器人 小車的室內定位系統采用的是運動捕捉系統,定位精度不低于1mm。定位系統實時獲取智能小車的位置并傳輸到上位機,上位機通過計算得到狀態量,并將其輸入到神經網絡,經訓練得到追捕者小車的控制策略,然后將指令通過無線傳輸到追捕者小車以控制其進行追捕任務。 本文算法程序基于Python語言進行編程,以深度學習框架TensorFlow為基礎,算法中的神經網絡均采用全連接網絡的架構,網絡采用2個隱含層,分別有150和50個節點,訓練算法的minibach設置為16,經驗池大小為10000,學習率為0.0001,折扣因子為0.9,回報函數中的比例因子設置為2。其它實驗參數如表2所示: 表2 實驗參數 訓練時,逃跑者做勻速直線運動,算法訓練500次,記錄每次的累積回報,結果如圖5所示。由圖5可知算法在訓練約100次時開始收斂。圖6分別顯示了兩智能小車在訓練前和算法收斂時的運行軌跡圖,可以看出訓練前追捕者小車處于沒有策略的運動狀態,最終超出邊界而導致任務失敗;當算法收斂后,追捕者小車能夠做出正確的決策,最終成功地捕獲逃跑者。 圖5 算法收斂趨勢 圖6 智能小車運行軌跡 為了驗證本文算法的適應性,在評估時將小車的初始位姿進行修改,使其在一定的范圍內隨機分布,并進行100次測試評估。圖7(a)顯示了這100次評估對的累積回報值,圖7(b)顯示了最后一次的智能小車運行軌跡。由圖7(a)可以看出,這100次評估實驗中,追捕者小車均能成功捕獲逃跑者小車。 此外,將逃跑者的運動狀態分別更改為靜止和隨機運動,再次對算法進行評估,實驗結果分別如圖8和9所示。在這2種狀態的評估實驗中,追捕者小車均能成功完成任務,表明本文算法具有較強的適應性。 圖7 算法評估結果 圖8 逃跑者靜止時小車運行軌跡 圖9 逃跑者隨機機動時小車運行軌跡 使用訓練好的模型對追捕者小車進行控制,在室內場地進行實驗,實驗中分別將逃跑者小車的狀態設置為靜止、勻速直線運動和隨機運動,模型輸入追捕者小車的狀態,輸出控制指令,經WiFi傳輸給追捕者,控制追捕者運動。在這3種狀態的Epuck小車追逃博弈實驗中,追捕者均能夠成功地捕獲逃跑者,與上文對算法評估中的3種仿真實驗結果一致,表明算法能夠實際地用在對智能小車的導航控制中。 立足于三維空間中導彈的攻防對抗問題,將其抽象成二維平面的小車追逃博弈,提出了基于深度強化學習的追逃博弈算法。算法以DDPG算法為原型,設計針對智能體追逃的馬爾科夫決策過程中的狀態空間、動作空間和回報函數,并對算法進行訓練,收斂后的模型在數學仿真和實物實驗中均成功地實現追捕任務。實驗結果表明本文所提出的深度強化學習算法可以有效地實現對智能小車的導航與控制,具有較強的適應性。后續,可將智能小車的運動模型替換為導彈的運動學和動力學模型,用以研究和仿真三維空間的導彈攻防對抗過程。2 馬爾科夫決策過程與強化學習
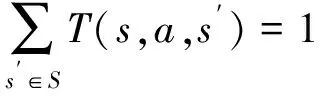
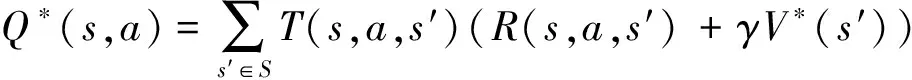
3 追逃博弈算法設計
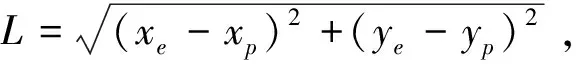
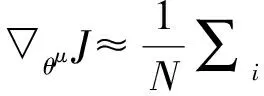
4 實驗驗證
4.1 實驗平臺


4.2 實驗參數設置

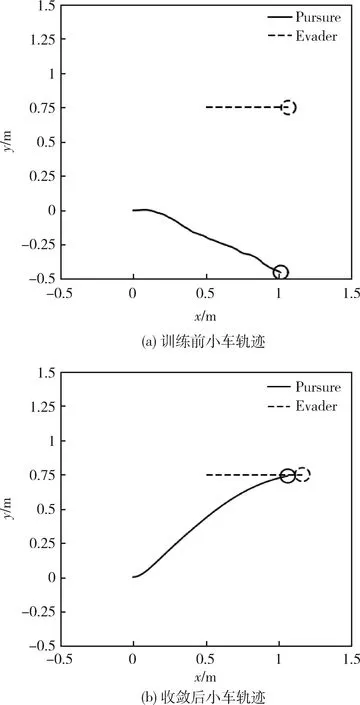
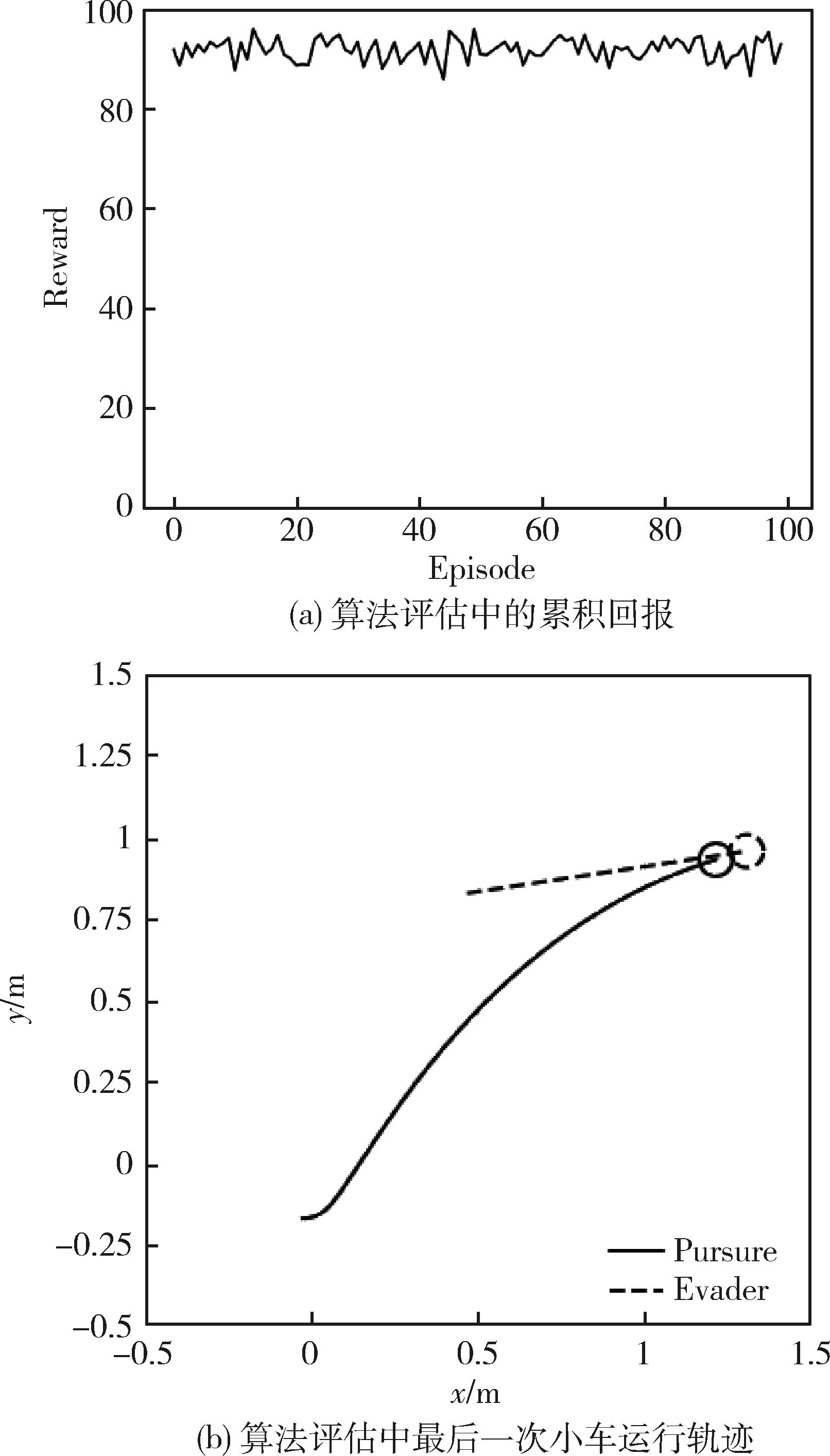
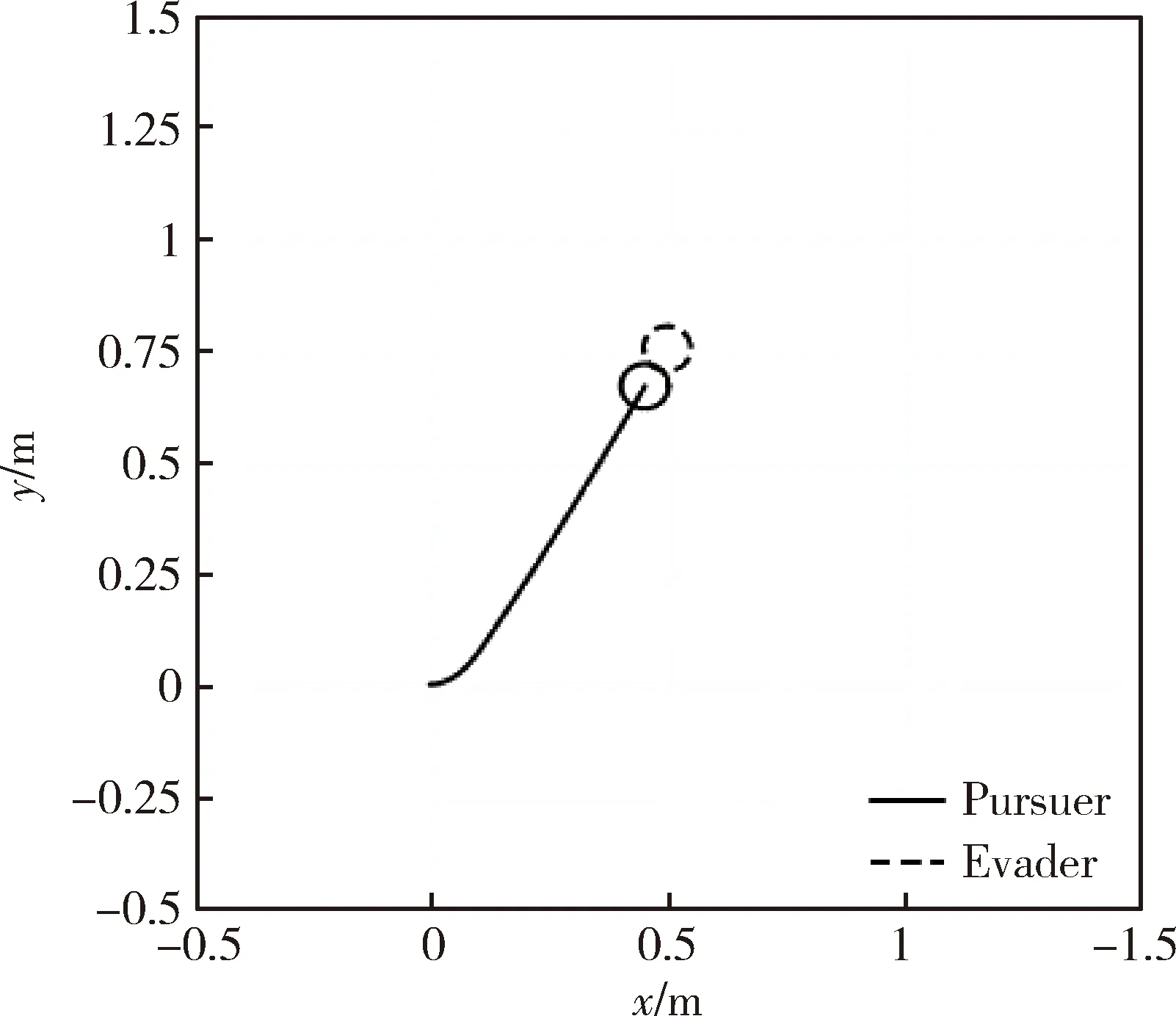
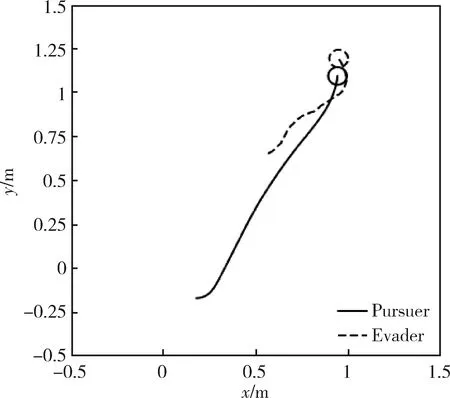
4.3 實驗結果分析
5 結論
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
數學大世界(2018年1期)2018-04-12 05:39:14
發明與創新(2016年38期)2016-08-22 03:02:52
