油氣行業垂直搜索引擎關鍵問題解決方案①
2019-01-07 02:40:38蔡永香李博涵劉遠剛
計算機系統應用 2018年12期
關鍵詞:搜索引擎
王 督,蔡永香,李博涵,劉遠剛
(長江大學 地球科學學院,武漢 430100)
隨著互聯網普及率的不斷提高,網絡信息呈現出數量大、種類多、來源復雜,具有不一致性和不完整性等特點[1].垂直搜索引擎是為了幫助用戶從海量信息庫中快速而準確地獲取所需的內容.
目前建立垂直搜索引擎方面的研究主要包括網頁數據爬取、網頁結構化數據抽取、網頁主題性判斷和分詞和索引策略等方面.國外對垂直搜索引擎的研究起步較早,經典的Fish-search算法[2]根據potentialscore值動態地改變抓取隊列中URL項的順序,實現相關網頁的快速抓取.文獻[3]在網頁采集的過程中,通過URL的MD5摘要計算,避免對相同的URL執行多次網頁抓取過程.Ricardo[4]等利用分布式的查詢代理技術,開發了一個高性能的查詢模塊的搜索系統.Marin[5]通過對網頁中的信進行抽取過濾后,通過構建垂直搜索工具,幫助用戶查找某個特定領域的相關信息.近年來,垂直搜索技術應用相結合在國內也獲得了較快的發展.劉全志等人[6]利用開源的Heritrix和Jsoup設計了一個網絡商品信息抽取系統,實現了Web信息的抽取、存儲、檢索;張亞鳳[7]通過擴展Hertrix框架并添加自定義詞庫實現了體育用品信息類的垂直搜索引擎,其添加自定義詞庫的方法,對本文擴展完整性詞庫的研究起到了借鑒作用;吳潔明等[8]在對Hertrix拓展優化的基礎上,通過倒排索引提高了搜索的效率.張敏等[9]基于Heritrix框架實現了通過IP地址限制爬蟲只抓取某一地區主機上的網頁,采用拓展Heritrix爬蟲的Postprocessing chain 進行限定性采集,有較強的實用性.吳偉等[10]運用ELFHash算法對Heritrix進行多線程的優化,增加爬取線程數,提高了網頁抓取的速度.上述研究總的來說,對爬蟲的抓取效率、正文的抽取精度和搜索精度方面起到一定提升作用,但也存在有待進一步完善的問題:(1)信息獲取階段,多數研究選取ELFHash作為Heritrix的散列函數,但我們在實際應用中發現,ELFHash函數的散列效果并不是很好,且這些研究大多沒有實現增量抓取,導致大量URL的重復抓取,降低了抓取的效率;(2)結構化信息處理階段,這些研究主要通過對不同網站手工配置不同模版的方式進行正文抽取,沒有實現網站自動化抽取;(3)建立索引階段,一般都是利用基礎詞庫進行分詞建立索引,所提供的信息檢索服務精度有待進一步提高;(4)大多研究只是對構建搜索引擎的某一個或幾個過程進行優化,而非對其各階段進行整體優化、一體化的實現垂直搜索引擎的自動化構建.
針對上述問題,本文針對搜索引擎構建的三個階段(信息獲取階段、結構化信息抽取階段和信息存儲檢索階段)進行研究與優化,并將各過程進行有效連接,實現了垂直搜索引擎的自動化構建.
1 自動化垂直搜索引擎構建方法
自動化垂直搜索引擎構建流程主要包含四步,如圖1所示.
1)優化爬蟲,優化抓取任務隊列分配策略,采用增量爬取,提高爬取效率.
2)使用經過優化后的文本標簽路徑比算法抽取網頁正文,標題和時間按其分布規律進行抽取,最后將所有抽取出的部分按字段存儲到數據庫中.
3)使用優化后的C-value方法抽取油氣資源新聞中的完整性詞,建立油氣行業專業詞庫;使用專業詞庫進行分詞,創建索引,提高搜索的精度.
4)實時獲取最新入庫文檔、抽取領域詞、更新詞庫、實現Solr的近實時搜索功能來不斷更新索引,為用戶提供最新的搜索服務.
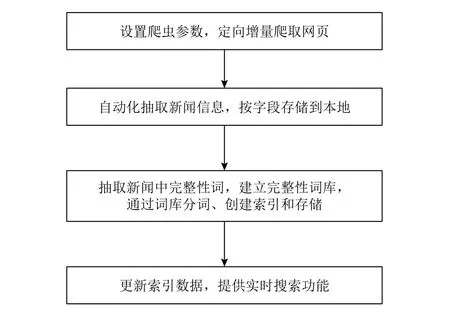
圖1 自動化的垂直搜索引擎構建流程
2 關鍵問題及解決方案
決定垂直搜索引擎自動化效能的幾個關鍵性問題包括:1)爬蟲是否高效;2)爬取信息能否自動存儲在數據庫;3)是否能建立高效的索引,為用戶提供準確的信息檢索服務.本文對這幾方面展開了研究如下:
2.1 Heritrix爬蟲優化
爬取模塊使用開源爬蟲Heritrix,并對其抓取任務的URL隊列分配策略進行優化,采用增量爬取方式,提高爬取效率.
2.1.1 抓取任務中定制 URL 隊列分配策略
默認情況下,Heritrix使用域名分配策略(Hostname Queue Assignment Policy)將爬取的 URL 分配到不同的隊列抓取.該策略的特點是:根據域名作為分組依據,即同一域名下的URL將被分配進同一個抓取隊列.這樣在抓取時會單線程抓取.所以需要將要爬取的多個URL分散至多個隊列中并行處理,以提高爬取速度.大部分解決該問題的方法都是使用ELFHash散列函數,但通過實際測試,發現效果并不理想[11].ELFHash函數將URL的絕對長度作為輸入,并與字符的十進制值結合起來計算hash值,這種方式對長字符串和短字符串都有效,能夠比較均勻地把字符串分布在散列表中.但采用該函數沒有考慮負載均衡,當種子URL較少時,使用該函數會使得多個線程一起去抓取少量種子,造成線程阻塞,無法抽取出新的URL.實踐中發現,使用該函數,爬蟲經常會在散列30個DNS就自動結束.
本文采用的是Hflp散列函數[11].Hflp函數將不定長的URL地址分割成位數相同的幾部分,然后取這幾部分的疊加之和(去除進位)作為散列地址.實驗證明,使用Hflp散列函數可以提高Heritrix的抓取效率,實現負載均衡.
2.1.2 增量爬蟲
增量式爬蟲是指對已下載網頁進行增量式更新,只抓取新產生的網頁內容,提高抓取速度[12].在互聯網信息快速增長的今天,增量式網絡爬蟲能夠顯著的提高網絡信息獲取效率,這是因為增量式爬蟲具有以下優點:
(1)因只爬取新產生的或者己經發生變化網頁,對以前曾經爬取過的網頁不再抓取,可有效減少爬取時數據的下載量;
(2)減小時間和空間上的耗費;
URI (Universal Resource Identifier)是通用資源標識符的縮寫,唯一標識一個網絡資源.URL (Universal Resource Locator)是統一資源定位符的縮寫,URL 是URI的子集,是獲取網絡資源的唯一標識,可以通過URL來區分不同的網頁資源.通常,爬蟲會將已抓取和待抓取的URL分別存放在不同爬取隊列中,并從已抓取的URL中發現新的URL,經過一系列判斷、去重規則過濾后,將符合規則的URL加入待抓取URL隊列中等待抓取.
Heritrix爬蟲會自動記錄每次爬取的URL,在爬取結果文件夾log文件中的recover.gz文件記錄了上一次已抓取的URL信息.所以可以對該文件中記錄的URL不斷過濾累加,每次爬取時,將這些URL寫入到已抓取隊列,避免重復信息的二次爬取.具體改進方法如下:

算法1.增量抓取算法1)建立 recoverAll.txt文件,記錄所有已爬取 URL.當一次爬取完成后,首先讀取recoverAll中記錄的歷史URL信息(首次爬取為空),并使用指紋算法,將URL壓縮后存入Bloom Filter中,生成所有歷史URL信息的Bloom Filter;2)讀取Heritrix爬取結果log文件夾下的recover.gz文件,該文件記錄本次爬取結果,同樣使用指紋算法對有效的URL進行壓縮處理;

3)使用步驟1)中建立的Bloom Filter[13]對步驟2)中讀取的URL過濾去重;4)將去重后的 URL,追加至 recoverAll文件中,并壓縮為recover.gz文件;.5)將Heritrix的配置文件order.xml中的<string name="recoverpath">屬性值更新為新生成的recover.gz文件地址,從而實現對網站長時間監測過程中的增量爬取.
2.2 結構化信息自動抽取方法優化
基于改進的文本標簽路徑比算法抽取出新聞中的正文,同時根據新聞標題和時間的分布規律,實現對標題和時間的精確抽取.
2.2.1 正文的抽取
文本標簽路徑比算法[14]是一種抽取新聞正文比較有效的方法,其核心是通過比較正文內容與噪音內容在標簽路徑和文本內容等特征上的一些顯著區別,抽取出網頁中的正文信息.
該算法在處理大多數網頁時,都具有較好的抽取效果.但對一些短文本新聞會出現抽取錯誤.例如在“中國石油新聞中心”網站中,許多圖片新聞只含有一張圖片以及對圖片的簡短描述,這時算法會將網站“底部版權區”的信息抽取出來作為結果.錯誤原因在于,短新聞的“底部版權區”中的標簽數量和“正文”中修飾部分的標簽數量相差不大,但 “底部版權區”中的文字甚至比正文的還多,而該算法是依據文本長度和標簽的數量來計算文本塊的分值,導致最終“底部版權區”的分值高于“正文”部分.
針對這類問題,本文對該算法進行優化.我們對中石油新聞中心、中石化新聞網、中海油新聞網三個主要油氣信息網站首頁共計306條新聞的正文部分進行統計,發現三個網站中的新聞的正文主要可分為三類:(1)文字類新聞,這類新聞只包含文字,不包含圖片;(2)圖文交替類新聞,這類新聞以文字為主,也包含有部分圖片;(3)圖片類新聞,這類新聞以圖片為主,文字說明很少.這三類新聞都具有以下特征:(1)正文中一般都含有標點符號;(2)正文中一般都不含有超鏈接;(3)<p>標簽和<strong>標簽一般用于修飾正文中的內容.對我們監測的其他油氣相關網站進行檢查,發現這些網站也具有上述特征.
根據上述特征,對該算法做出如下改進:

算法2.文本標簽路徑比算法改進1)對第一次抽取出的新聞內容進行統計.2)確定標點個數是否大于某個閾值α,超鏈接中字符數量是否小于

閾值β;3)若滿足上述兩個條件,則認為新聞正文抽取正確,將第一次抽取的內容作為最終結果.若上述條件有一個不滿足,則按照新規則進行二次抽取.4)在二次抽取中,統計 DOM 中<p>和<strong>標簽的個數,將其作為參數添加至特征值計算公式中,進行二次計算.5)對結果進行排序,抽取高于閾值的結果,并按分數高低遍歷.判斷:① 結果中的標點個數是否大于閾值;② 超鏈接中的字符數量是否小于閾值.取出滿足①②條件且分數最高的作為最終結果.
2.2.2 標題和時間的抽取
一般來說,新聞標題在網頁中的分布位置,按優先級排序為:(1)頁面中被<h>標簽修飾且和<head>標簽中<title>標簽內容相似部分;(2)網頁<head>標簽中<title>標簽的內容;(3)頁面 id或 class屬性值為title的標簽的內容.
根據以上規律,抽取新聞標題方法可分為兩種情況處理:
(1)頁面<head>里的<title>標簽中有字符;
(2)頁面<head>里的<title>標簽中沒有字符.
具體抽取算法如下:

算法3.正文標題抽取算法1)對于情況(1),遍歷DOM到正文元素,獲取<h>標簽修飾的字符,計算字符和<head>里的<title>標簽中字符的相似度[15],若某個<h>標簽中的字符和<title>中字符相似,則將其作為標題.若頁面中所有<h>標簽中的字符和<head>里的<title>標簽中字符都不相似,則將<head>里的<title>標簽中字符作為標題;2)對于情況(2)遍歷DOM,找出id或class屬性的值為title的標簽,將第一個找到的字符作為標題內容.
對時間信息的處理方法如下:由于Heritrix會以其爬取的URL地址作為路徑建立文件夾,將爬取下來的內容存儲在該文件夾中.例如,http://news.cnpc.com.cn/system/2016/05/09/001591599.shtml頁面下載到本地的存儲路徑為:項目根目錄/jobs/爬取任務名稱/mirror/news.cnpc.com.cn/system/2016/09/001591599.shtml.而“項目根目錄/jobs/爬取任務名稱”部分路徑可由用戶自定義.根據該特點,正文的時間抽取算法如下:

算法4.正文時間抽取算法.1)利用正則表達式將該地址下mirror文件夾后面部分內容截取出來;2)在截取的部分前面加上爬取網站的網絡協議即為爬取的URL;3)在使用正則表達式,將URL中的年月時間信息提取出來,即為新聞的發布時間.
2.3 基于C-Value改進的油氣行業詞庫建立方法
索引的建立是以詞為基礎的,分詞的準確性是衡量一個垂直搜索引擎搜索精度的重要指標.基礎分詞器通常會根據基本詞典切分,往往將有完整意義的詞分開,例如:“中石油”會被分為“中”和“石油”、“國際能源產業”會被分為“國際”、“能源”和“產業”等.分割開的詞無法反映原詞本身含義,通過這樣的方式分詞建立索引,只能檢索出割裂詞的索引信息.本文通過抽取大量新聞中的具有完整意義的詞,建立完整性詞庫,并利用詞庫進行分詞、建立索引,提高搜索準確度.
2.3.1 C-value 方法
C-value[16]方法是 Frantzi K(1999)提出的.該方法基于統計學與語言學規則,是一種領域獨立的多字詞語自動抽取方法.
統計部分計算公式如下:

公式(1)中a表示某候選術語,|a|指候選術語a的長度,其值為a的字數,f(a)為a出現的詞頻,b表示包含a的候選術語,f(b)表示其出現的頻率,Ta表示包含詞串a的集合.P(Ta)表示Ta的個數.通過實驗發現,在實際應用中使用C-value方法抽取的效果不好.原因如下:
(1)C-value的詞性過濾規則較為寬松,雖然一定程度上增加了召回率,但極大地降低了抽取精度;
(2)C-value是基于英文環境的,并不完全適用于中文領域詞的抽取.
2.3.2 總結行業詞典過濾規則
不同行業的詞庫可能具有不同的規律,因此需要根據涉及的領域,總結出該行業常用詞典的一些規律來指導建庫.下面以油氣行業為例說明.
搜集騰訊、搜狗等公開的詞庫、常用分詞器的詞庫以及互聯網上常用油氣行業詞庫,對其進行文本轉化,過濾,去重后得到油氣行業的常用詞,共30882條.對其結構成分進行分析發現:
(1)油氣行業常用詞的字數長度變化范圍在1–10之間.其中,長度在 2–5 間的詞最多,有 25 629 條,占總數的 83%.長度為 1 的詞有 4614 條,占總數的 15%.長度6–10的只有639條,占2%.這與一般來說英語術語多由 2–3 個單詞組成,而漢語術語多由 2–6 個字組成[17]相符合.
(2)通過對30 882條詞語的結構進行統計分析,總結出長度在2–5之間的排名前20的詞性列表如下:
2.3.3 抽取行業完整性領域詞建庫的方法
根據得到的詞性規則,采用以下算法抽取行業完整性領域詞:

算法5.行業完整詞抽取算法1)使用ICTCLAS分詞器對爬取下來的新聞進行詞性標注,并利用表1中20組語言學規則進行過濾,匹配滿足上述20組規則的詞;2)對所有滿足規則的詞過濾噪聲,去除單字動詞、特殊符號等,將剩下的詞作為語言學規則處理后的候選詞;3)使用公式(1)計算語言學規則候選詞的C-value;4)使用通用詞庫,對計算結果中的常用詞進行過濾并排序,將高于閾值的部分作為最終結果詞.
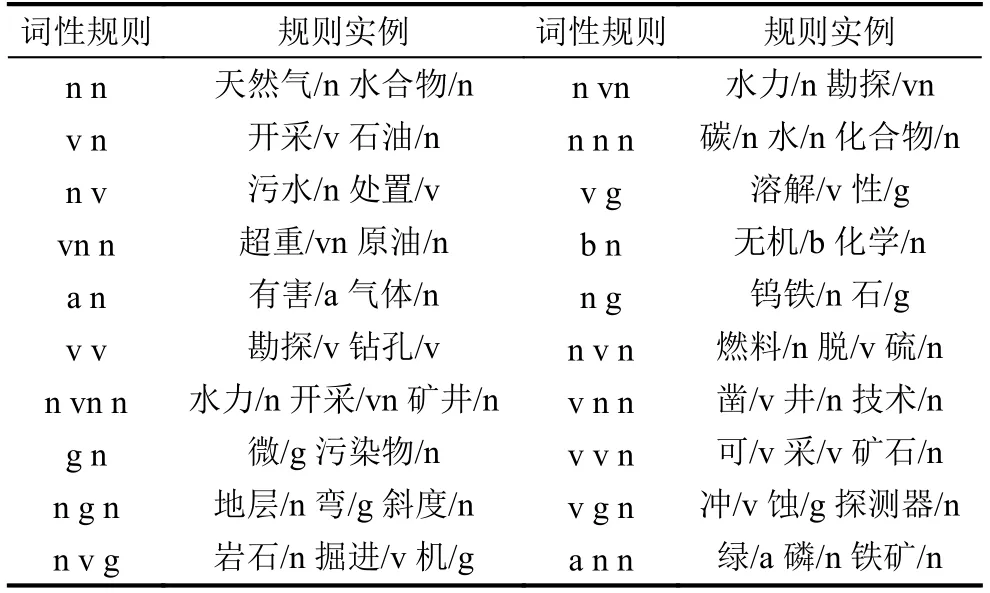
表1 語言學規則
經過多次實驗,C-value的閾值在大于3.0抽取效果最好.
3 實驗分析
本文以油氣行業垂直搜索引擎的構建為例,實現上述方法,并對各過程的結果進行記錄分析.實驗的硬件環境為:服務器 CPU 為 Intel Celeron E3300,雙核主頻為 2.5 GHz;Heritrix 采用 1.14.4 版本;爬取最大線程設置為50,最大深度設置為3,最大爬取時間為60 min,其他為Heritrix1.14.4默認設置.
3.1 URL散列效果對比
使用Heritrix對中國石油新聞中心(http://news.cnpc.com.cn/)進行爬取,分別采用ELFHash函數和Hflp函數進行爬取對比.對60分鐘內URL散列數進行統計,結果如圖2所示.
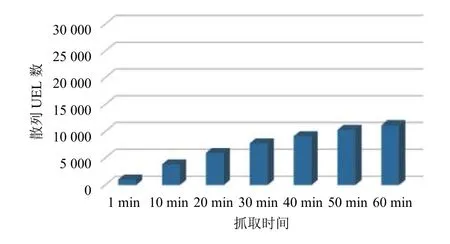
圖2 ELFHash 函數散列 URL 數
從圖2、3的對比中可以看出,在60分鐘內的對各個時間點統計,可見Hflp 較ELFHash 具有更好的散列效果.
3.2 增量爬取
采用Heritrix對中國石油新聞中心進行增量抓取和普通(非增量)抓取,監測時間為一周(網站周末不更新),每天抓取一次,抓取結果如圖3所示.
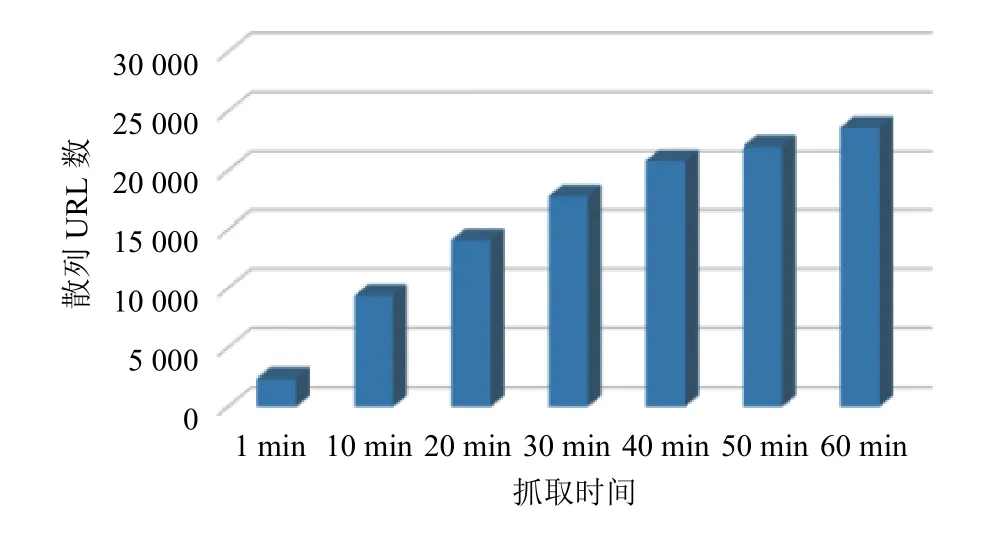
圖3 Hflp 函數散列 URL 數
從圖4、5對比中可以看出,在進行普通(非增量)爬取時,由于爬取時間都設置為1小時,所以爬取URL 數波動范圍不大,維持在 37 000 條左右,但這些爬取的新聞中包含了網站每天新發布的新聞和前面已爬取過的重復新聞.而采用增量爬取后,由于增量的作用每天只爬取新入庫的新聞.雖然爬取時間仍然設置為1小時,但除了第一天爬取了1小時外,隨后幾天爬取的時間和URL都呈現明顯下降的趨勢,最后基本趨于穩定.進一步表明增量抓取能有效提高爬蟲的抓取效率.
3.3 結構化信息抽取部分
對中國石油新聞中心、中石化新聞網和中海油集團新聞網爬取的1000個網頁進行結構化信息抽取,使用基于文本標簽路徑比算法和優化后的文本標簽路徑比算法進行抽取,并進行效果對比.采用人工判讀的方式統計數據庫中新聞結構化信息抽取正確與否,結果如表2所示.
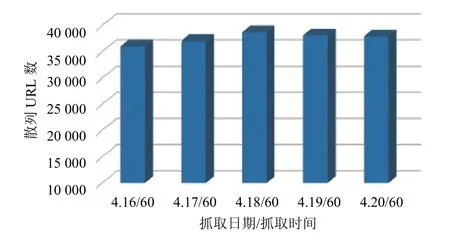
圖4 普通抓取方式抓取的 URL數 (min)
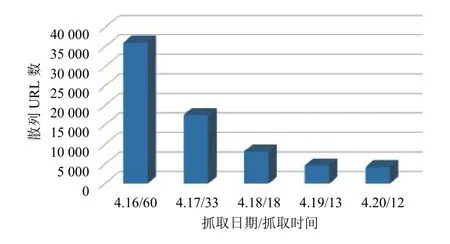
圖5 增量方式抓取 URL 數 (min)
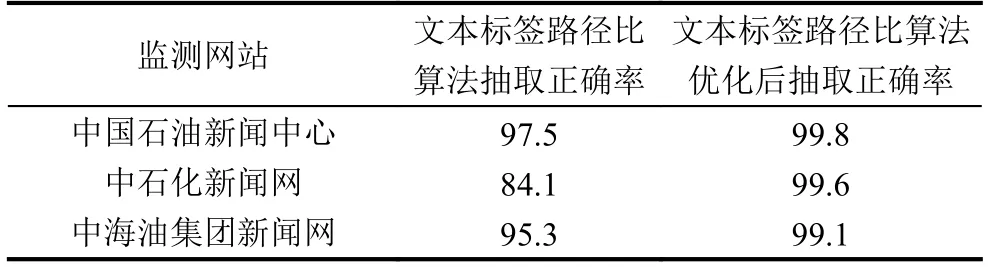
表2 文本標簽路徑比算法優化前后結果對比 (單位:%)
從表中可以看出,在對中國石油新聞中心、中石化新聞網和中海油集團新聞網的抽取中,優化后的文本標簽路徑比正文抽取算法準確率較優化前有了明顯的提升.
3.4 完整詞抽取算法
評價抽取效果一般采用精度和召回率兩個指標[18].本文采用精度、召回率和F-score三個指標評價完整詞的抽取效果.精度用抽取算法抽取出的完整性詞占人工判讀標記的完整性詞的百分比表示,而召回率用抽取算法抽取出的正確完整性詞數占人工判讀標記正確完整性詞數的百分比表示.為綜合評價抽取效果,采用F-score評價指標,計算公式如下:

對中國石油新聞中心爬取的網頁清洗后,選取其中的50篇文章,通過分詞、停用詞過濾等處理后,得到8263個候選詞,通過精度、召回率和F-score對傳統和優化后C-Value方法進行評估,結果如表3所示.

表3 基于傳統 C-value和行業詞典過濾規則改進的CValue方法抽取結果對比(單位:%)
從結果可知,油氣行業詞典總結出的詞性規則較C-value的過濾規則更適合提取油氣行業完整性詞.
3.5 搜索結果比較
本文利用上述垂直搜索引擎自動化構建方法對中國石油新聞中心進行處理,最后輸入關鍵詞進行搜索,并將搜索結果與未使用專業詞庫只基于基礎詞庫分詞建立索引的搜索結果進行對比.
圖6是未使用專業詞庫搜索的結果,當輸入檢索詞“世界石油大會”后,檢索出的是按照基礎詞庫分詞建立索引獲取的結果,檢索出的主要是這個詞被分詞后的子詞相關信息,而包含有完整的“世界石油大會”詞的文檔并沒有優先排在前面,結果不能讓用戶滿意.圖7是使用專業詞庫后搜索的結果,這里 “世界石油大會”是作為一個完整意義的詞被檢索,并沒有被分割為“世界”、“石油”、“大會”三個詞分別檢索,檢索結果能更好的滿足用戶對搜索精度的需求.
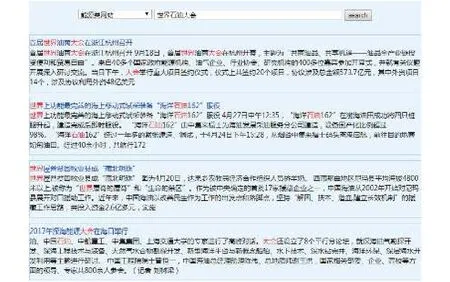
圖6 未使用專業詞庫搜索結果
4 結論
垂直搜索引擎技術研究的目的在于讓特定搜索領域和搜索需求的用戶有更好的用戶體驗.本文對垂直搜索引擎構建中各個階段的關鍵問題進行了深入研究,提出一套自動化構建垂直搜索引擎的方法.與已有的方法相比,該方法能夠提高爬蟲的爬取效率,能夠進行結構化信息的自動化提取,能夠抽取完整性領域詞建立油氣行業詞庫,優化分詞方式,提高搜索的精度.該方法已經成功應用于國土資源部油氣資源戰略研究中心的油氣資源行業信息網,為油氣及相關從業人員提供快捷、準確和有效的信息檢索服務.
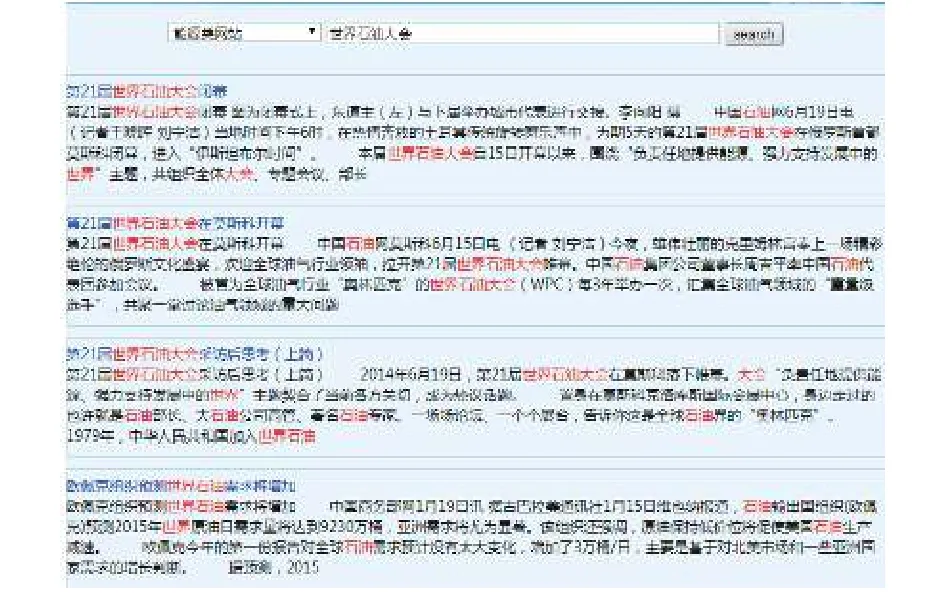
圖7 使用專業詞庫搜索結果
猜你喜歡
計算機與網絡(2022年2期)2022-03-17 22:48:16
中國衛生(2015年12期)2015-11-10 05:13:38
警察技術(2015年3期)2015-02-27 15:37:09
新疆大學學報(自然科學版)(中英文)(2014年2期)2014-11-06 07:49:12
技術經濟與管理研究(2014年11期)2014-03-11 17:02:44
科學導報·學術論壇(2013年5期)2013-06-26 05:41:54
百科知識(2012年11期)2012-04-29 08:30:15
中原工學院學報(2011年4期)2011-12-27 09:19:14
微型計算機·Geek(2009年1期)2009-12-15 05:37:32
計算機應用文摘(2009年17期)2009-04-29 00:44:03
