基于改進雙適應度遺傳算法的碎紙片拼接
2018-12-30 01:43:30韓家寧
新一代信息技術 2018年4期
張 巖,申 鵬,韓家寧,韓 超*
(1. 華北理工大學 化學工程學院,河北 唐山 063000;2. 哈爾濱商業大學 計算機與信息工程學院,黑龍江 哈爾濱 150000)
0 前言
文物修復、虛擬考古、司法物證鑒定等領域廣泛存在著碎片拼接問題,大都可以近似歸結為二維碎片的拼接問題[1],將其抽象,可以近似看作輪廓曲線的匹配的一種特殊形式,而且目前大部分對碎片拼接復原方法的研究也主要集中輪廓曲線匹配上[2],如,賈海燕等[3]人研究了碎紙片輪廓提取技術,通過碎紙片評分的大小來實現對碎紙片的拼接。朱延娟等[4]人提出基于 Hausdorffig 距離的多尺度輪廓匹配算法來解決碎片拼接問題。周豐等[5]人提出了基于角序列的與多尺度空間相結合的輪廓曲線匹配算法,也能很好的實現碎片的拼接問題。從理論上講在物體拼接中,應用輪廓曲線的匹配關系,能夠實現二維破碎物體的拼接[6-8],其原理就是對邊緣特征的識別與匹配[9],但由于碎紙機的發明,碎片邊緣正整齊,很難通過邊緣識別技術對文件進行修復,所以形狀在碎紙機粉碎的碎紙片的拼接中不能發揮作用。因此許多學者針對文檔特征提取了不同的文本特征來進行拼接,王玉霞等[10]人根據碎紙片的左右邊緣像素的相關性來實現碎紙片的拼接,羅智中等[9]人則利用多數文檔的文字行方向和表格線方向平行且單一的特征來進行拼接,但由于采用的特征單一,匹配規則單一,匹配精度較低,人工干預幾率大,而且單頁文檔經碎紙機破碎后其碎片都是成百上千個,計算量大、人工干預次數多且極易產生錯誤的匹配[11],為此有必要進一步選擇匹配特征和優化匹配原則。由于碎紙片大多來自同一頁印刷文字文件被橫切縱切為若干數量,形狀均為相同的矩形,且兩個碎紙片對象邊界之間的破碎字符具有一定的相似性[12]。為此引入圖像的灰度矩陣,灰度矩陣的每個元素對應到圖像上的每個像素點,每個碎片均可以確定一個同型的灰度矩陣,灰度矩陣的特征反映了圖像的特征。用matlab 的imread 函數讀取圖片的灰度信息,顏色越深,灰度值越大。為保證灰度匹配模型中絕對值的和不受這個約束的影響,同時簡便計算,需將灰度值矩陣進行轉化為0-1 矩陣,若灰度值矩陣中某個元素灰度值小于255,則0-1 矩陣中相同位置的元素值記為0,否則記為1。
1 碎紙片特征
1.1 碎紙片行高
由于英文按照四線三格的書寫規則書寫,因此行高可分占中間一格、上中兩格和中下兩格三類,如圖1 所示。

圖1 碎紙片的英文字母行高特征 Fig.1 The character of the letter height of a scrap of paper in English
經過對英文碎片和英文文檔統計發現,只有每句開頭和人名地名等是大寫,其余均為小寫,而在小寫字母中,中間一格的使用率遠遠高于上下兩格的使用率,故行高定義為中間一格豎直方向像素點之和,不同字母占格與使用率情況如表1 所示。由于中間一格的每行黑色像素點之和要遠大于上下兩格中每行黑色像素點之和,故可通過碎紙片上每行黑色像素點之和定位四線三格的位置。
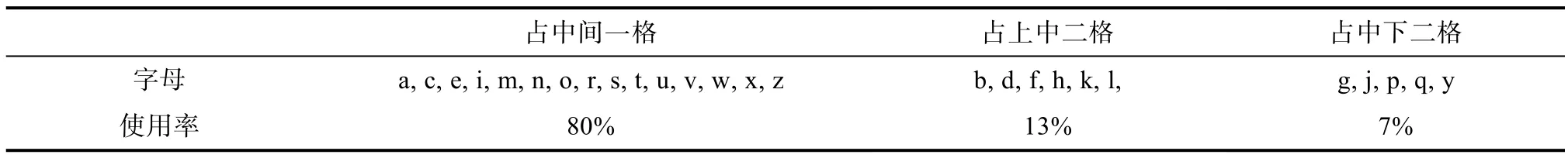
表1 不同字母占格與使用率 Table 1 The occupancy and usage of different letters
觀察統計碎紙片上文字的字體及大小,找到某一臨界值x(一行黑色像素點的和),假設碎紙片共有m行像素點,每行黑色像素點之和為,若,則i,j 為上中下三格的分界線,為行高。
1.2 行間留白
碎紙片確定行高之后,行與行之間的空白即為行間留白,行間留白高度為豎直方向像素點之和。
1.3 兩側留白
由于文檔的書寫規則,都會留有頁邊距,而文檔的內部相對緊湊,故可通過左右兩個方向的留白找出文檔的最左和最右兩側的碎紙片,且相同一側的留白大小應該相同。
2 碎紙片行間距類
將行及行間留白向右側投影,如圖2 所示,若遇到空白行超過行間留白高度時應按相應規則將其填補,如圖3 所示。
本來介于碎紙片最上端和最下端之間的行高或行間留白的高度是固定的,但由于一些碎紙片的上下兩格中的某些行黑色像素點之和大于臨界值x,導致部分介于碎紙片最上端和最下端之間的行高或行間留白的高度有偏差,為解決這個問題,可先確定行高p 和行間留白高度q,并在每一個碎紙片中找到符合的最優行高(或最優行間留白高度),以此為據向上和向下的q個像素點為行間留白(或p個像素點為行高),以次劃分行和行間留白的位置。

圖2 文字行及行間留白的右側投影 Fig.2 Right side projection of text line and space between lines
圖3 規則填補 Fig.3 Replenish regularly
由投影可得出碎紙片的特征行向量,通過對特征行向量的相關性分析,可將碎紙片分成n 類,每一類即為文檔的一大行。
3 邊緣匹配度
3.1 分段最優邊緣匹配度的計算
基于最小距離的邊緣匹配度:
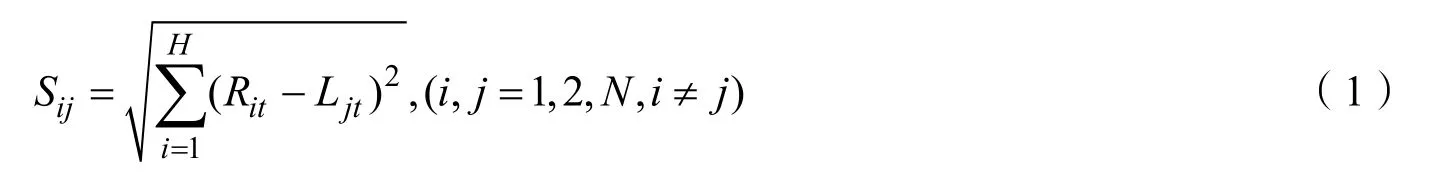
(1)由于文檔的書寫習慣,每段的最后一行通常會出現一部分空白行,若恰巧在此處被切割開,很難匹配到一起;
(2)由于兩個字母(單詞)之間有空白,恰巧挨著一個字母的結尾或另一個字母的開始切開,一側有黑色像素點,一側沒有,也很難匹配到一起;
(3)由于某些文字的書寫特征,如h,兩豎和一橫相連,若在相連的結點切開,也很難匹配在一起,如圖4,此類英文字母還b,d,f,h,k,l,m,n,p,q,t,w,B,D,E,F,G,H,J,K,M,N,P,R,T,W,Y 等。
為此我們把基于最小距離的邊緣匹配度進行優化,由于每類的行間留白的位置相同,故將每類中的碎紙片從行間留白的中線處切開,分成m 段,在計算匹配度時,分別計算兩個碎紙片的每一段的邊緣匹配度。并取其中最優值作為兩個碎紙片的分段最優邊緣匹配度。
第ij 碎紙片的第k 段邊緣匹配度:
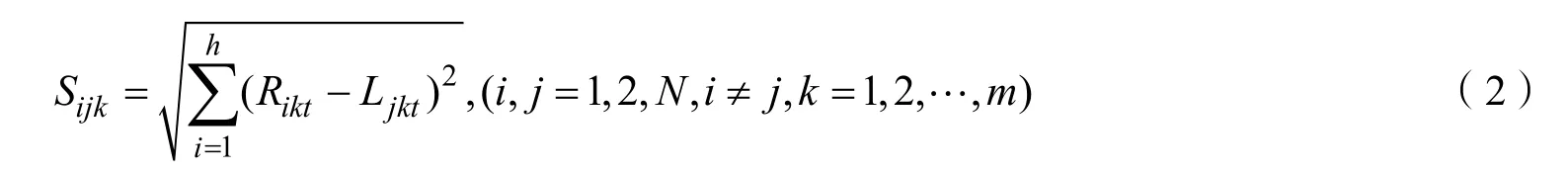
但應注意,若進行匹配的兩個邊緣皆為空白,應剔除,不并入計算。
3.2 分段空白列寬匹配度計算
在計算邊緣匹配度時發現出兩側留白外,經常有左或右邊緣沒有黑色像素點的情況,如圖5 所示。
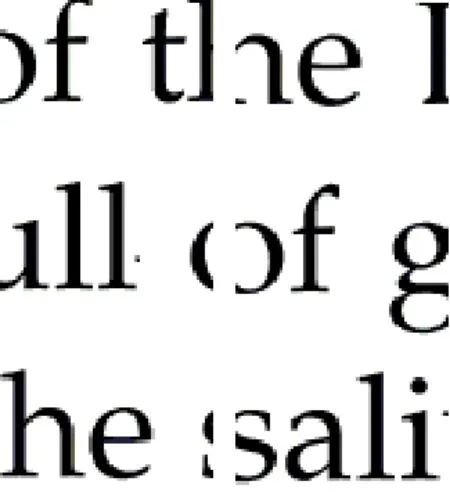
圖4 匹配效果 Fig.4 The matching effect
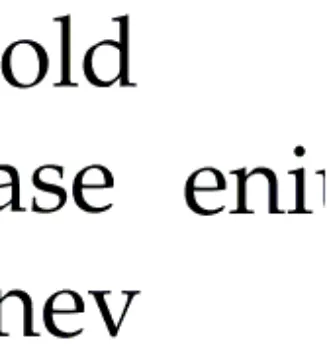
圖5 段落左側或右側邊緣無黑色像素點情況 Fig.5 No black pixels on the left or right edge of the paragraph
此時邊緣匹配度為0,但出現匹配錯誤,為解決此類問題引入分段空白列寬匹配度,即兩個單詞之間的空白像素點之和Vk 是固定的,以此來推斷空白列的匹配問題。同樣將每類中的碎紙片從行間留白的中線處切開,分成m 段,分別計算兩個碎紙片的每一段的空白列寬匹配度,并取最差值作為兩個碎紙片的分段空白列寬匹配度。
則ij 碎紙片第k 段空白列寬匹配度:
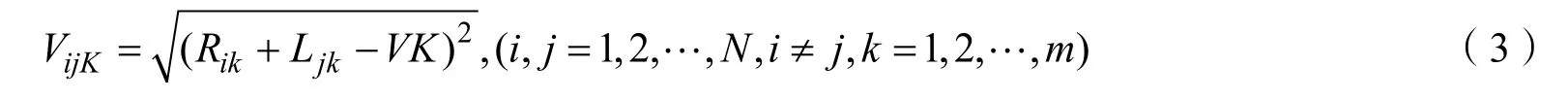
4 基于雙適應度遺傳算法的碎紙片拼接復原模型的建立
本模型采用雙適應度遺傳算法來解決多目標優化,其中拼接方案的兩個適應度Fs和Fv分別依據分段最優邊緣匹配度和分段空白列寬匹配度設計,具體流程如下圖6。
初始種群p0的生成:根據分段最優邊緣匹配度生成初始種群p0,大小為50。
交叉:將父代與適應度函數值相近的父代進行配對,再采用單點交叉,交叉率為1。
變異:本模型采用的變異率為0.05,隨機地取兩個在0到17之間的整數,對這兩個數對應位置的基因進行變異,得到新的染色體。
具體計算步驟如下:
Step1:計算行高和行間留白;
Step2:通過規則填補后的投影進行字符定位及碎紙片的聚類;
Step3:計算分段最優邊緣匹配度和分段空白列寬匹配度;
Step4:找出兩側留白,確定每一大行的開頭結尾;
Step5:將所有類按碎紙片數量進行排序,根據分段最優邊緣匹配度和分段空白列寬匹配度調用雙適應度遺傳算法并由從多到少的順序對每類進行拼接,多余的碎紙片并入下一類;
Step6:每類拼接完后,進行橫向拼接,方法同上。
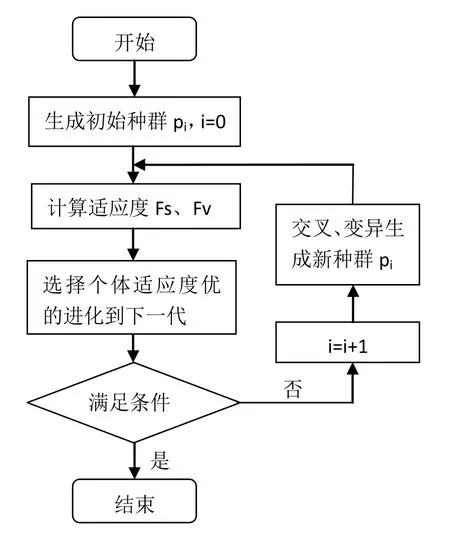
圖6 雙適應度遺傳算法流程圖 Fig.6 Flow chart of dual fitness genetic algorithm
5 實驗過程
(1)計算行高和行間留白,通過規則填補后的投影進行字符定位及碎紙片的聚類,共分12 類,其中19 個碎紙片占10 組,18 個占1 組,1 個占1 組。
(2)找出兩側留白,確定每一大行的開頭結尾,開頭碎紙片編號為19,20,70,81,86,132,159,171,191,201,208,結尾碎紙片編號為31,44,82,109,112,115,127,143,146,147,178。
(3)將只含1 個碎紙片的那類并入碎紙片少的一類,調用雙適應度遺傳算法對每類碎紙片進行拼接,人工干預后,進行橫向拼接,結果如表2 所示。
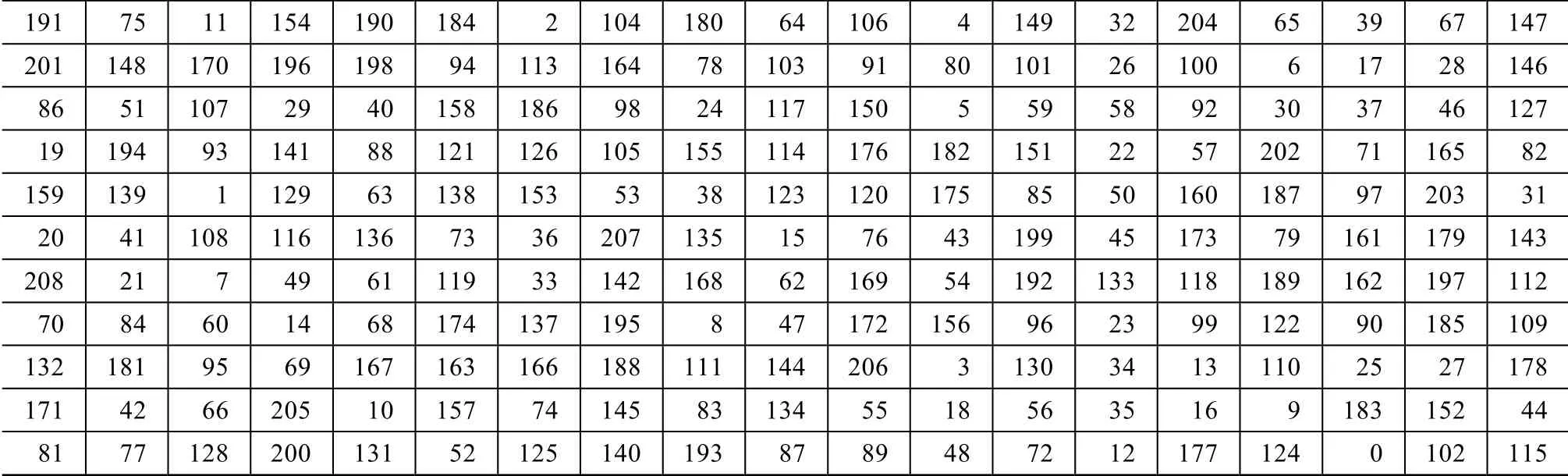
表2 拼接結果 Table 2 Stitching result
在進行人工干預之前,共有4 個碎紙片拼接錯誤,準確率達到98.1%,人工干預后準確率達到100%。其中拼接錯誤主要出現在一個碎紙片上文字信息過少或者一行中四線三格的上下兩格使用率過高,導致字符定位不準確,為后續拼接帶來了麻煩。
也應注意,在碎片拼接后,需要字符識別技術的支持,通過光學字符識別模型,將碎片拼接圖像中的文字處理成可編輯的文本格式[12],才能進一步提高碎片拼接的高效性。
6 結論
(1)通過對英文碎紙片的行高、行間和兩側留白分析,得到了對碎紙片字母利用率和占格分布情況統計的一般方法;
(2)通過設計規則填補而進一步定位字符位置,并通過最有行高(最優行間留白)優化字符位置,使得準確率達到了98%;
(3)設計并優化了分段最優邊緣匹配度,避免了由于切割線兩側部分位置匹配度過低而導致的整體匹配度下降問題;
(4)設計了分段空白列寬匹配度,解決了由于進行邊緣匹配計算的兩個碎片邊緣皆為空白而引起的分段最優邊緣匹配度失靈的問題,建立了基于雙適應度遺傳算法的碎紙片拼接模型,得到了一般規則碎片的拼接方法;
(5)基于本文的研究,碎紙機可進行升級優化,以避免碎紙片拼接帶來的不良影響,可變換切割矩形的大小,也可盡可能多的從空白處切開等。
