基于線性脈動陣列的卷積神經網絡計算優化與性能分析
2018-12-26 10:04:14劉勤讓劉崇陽周俊王孝龍
網絡與信息安全學報 2018年12期
劉勤讓,劉崇陽,周俊,王孝龍
?
基于線性脈動陣列的卷積神經網絡計算優化與性能分析
劉勤讓,劉崇陽,周俊,王孝龍
(國家數字交換系統工程技術研究中心,河南 鄭州 450002)
針對大部分FPGA端上的卷積神經網絡(CNN, convolutional neural network)加速器設計未能有效利用稀疏性的問題,從帶寬和能量消耗方面考慮,提出了基于線性脈動陣列的2種改進的CNN計算優化方案。首先,卷積轉化為矩陣相乘形式以利用稀疏性;其次,為解決傳統的并行矩陣乘法器存在較大I/O需求的問題,采用線性脈動陣列改進設計;最后,對比分析了傳統的并行矩陣乘法器和2種改進的線性脈動陣列用于CNN加速的利弊。理論證明及分析表明,與并行矩陣乘法器相比,2種改進的線性脈動陣列都充分利用了稀疏性,具有能量消耗少、I/O帶寬占用少的優勢。
線性脈動陣列;卷積神經網絡;稀疏性;I/O帶寬;性能分析
1 引言
CNN是一種前饋神經網絡,隨著人工智能的發展,深度學習中的CNN已成為物體識別的主要方法,廣泛用于計算機視覺領域。但CNN是一個計算密集型和存儲密集型的網絡[1-2],為了面向更復雜的任務,CNN的規模正向更深、更復雜方向發展。例如,文獻[3]指出:“標準”的CNN結構層次太少,只有神經元、神經網絡層,要把每一層的神經元組合起來形成組并裝到“艙”(capsule)中完成大量的內部計算。
CNN規模大和計算量大的特點導致移動端上部署變得很困難,規模太大可以壓縮[4-5],計算量太大就須進行加速。如今,CNN嵌入式端加速主要集中于FPGA[6]。例如,文獻[7]結合卷積計算特點用多個二維卷積器實現三維卷積操作,充分利用FPGA上資源實現高速計算。文獻[8]首先考慮FPGA資源限制(如片上存儲、寄存器、計算資源和外部存儲帶寬),之后為給定的CNN模型探索出基于OpenCL的最大化吞吐量的FPGA加速器。文獻[9]在FPGA上部署Winograd算法進行卷積加速。但以上利用FPGA的加速方法都未能利用卷積計算中的稀疏性。利用卷積計算中稀疏性的加速方法有文獻[10],采用行固定的處理數據方式來利用稀疏性,當數據通道的輸入為0值時直接不做處理。文獻[11]利用并行矩陣乘法器完成卷積計算并充分利用了參數稀疏性。文獻[12]把 Winograd算法和稀疏性進行結合減少卷積操作,改變Winograd作用域來利用稀疏性,Winograd算法計算快但對數據輸入輸出要求高,運用到FPGA上時存取速度成了限制因素。
本文以文獻[13-14]中的線性脈動陣列為基礎,對處理單元(PE)做細微的“不傳不運算操作”控制,以實現對卷積計算稀疏性的利用。本文采用的線性脈動陣列主要有3個改進:①針對稀疏性的不傳不運算操作;②針對卷積核矩陣的部分傳輸操作;③針對輸出結果時的緩存減少策略(針對單輸出線性脈動陣列)。本文主要從計算循環周期、存取操作類別和存取操作次數以及資源耗費情況來對比分析和證明,分析表明:改進后的2種線性脈動陣列不僅充分利用了稀疏性,而且不同程度地減少了I/O能耗需求。
2 問題描述
2.1 CNN稀疏性特點
CNN卷積層的卷積計算有一個激活函數,常用的激活函數Relu示意如圖1所示。
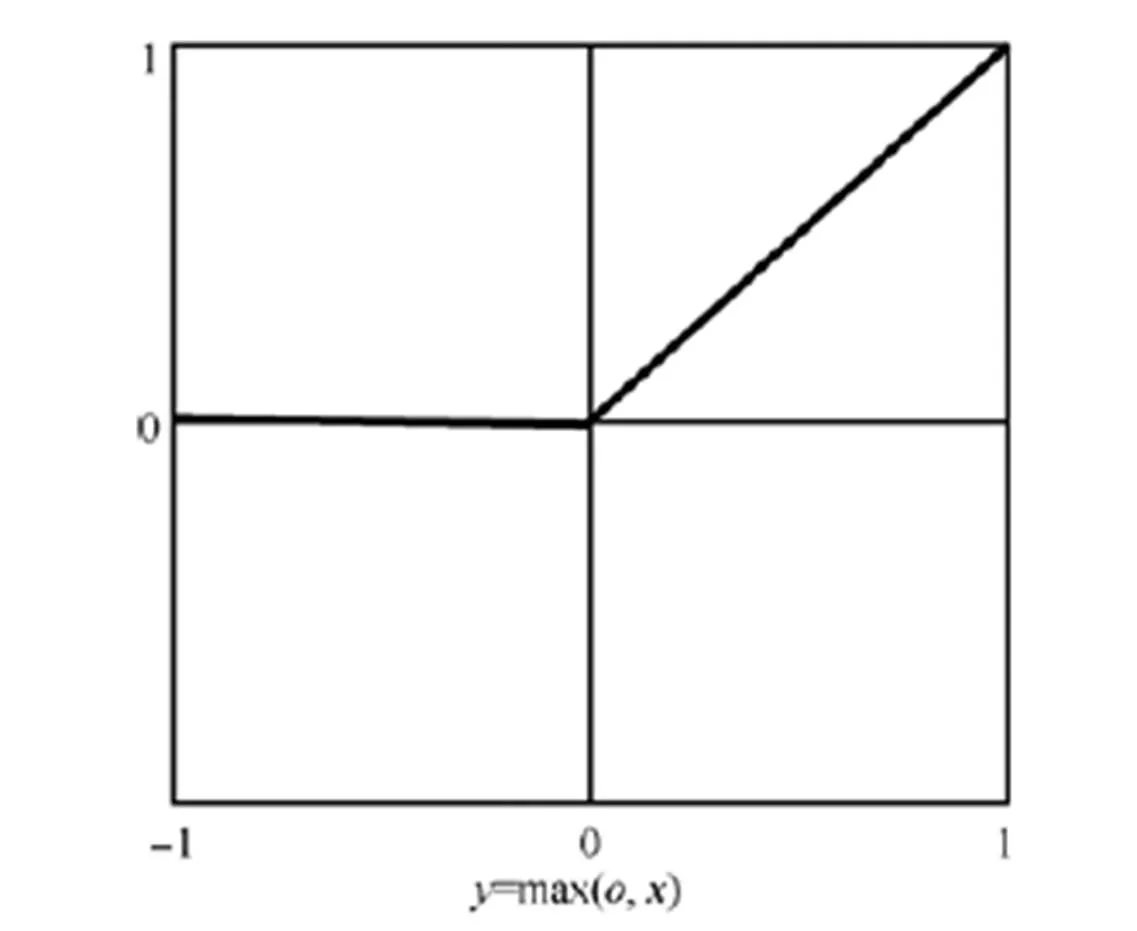
圖1 Relu示意
經過Relu激活函數作用后,小于等于0的都變為0值,所以輸出的特征圖有很多0值存在。本文基于Caffe深度學習框架[15]進行實驗,發現Alexnet、Googlenet、Caffenet和Vgg等卷積神經網絡中都存在較大程度的稀疏性,如Alexnet各個卷積層的0值比例如圖2所示。
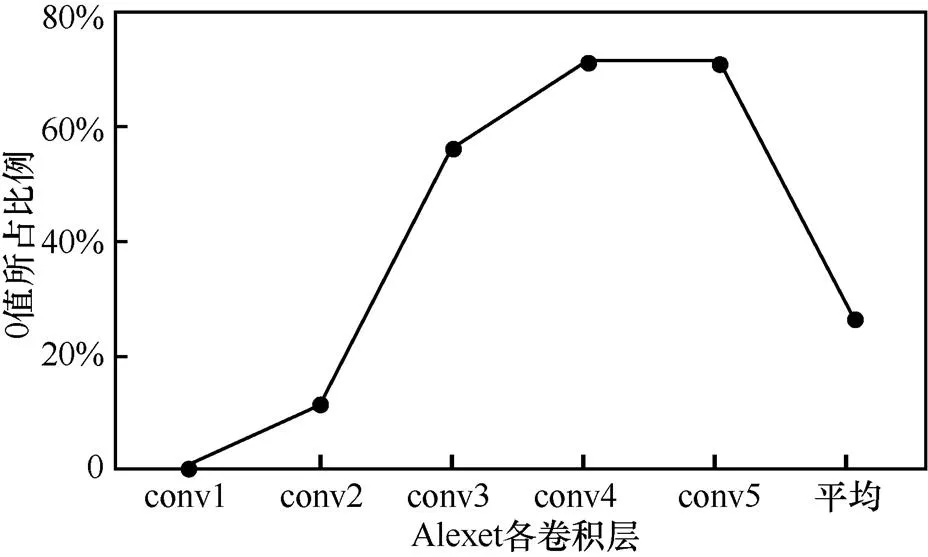
圖2 Alexnet卷積層0值比例
為了利用稀疏性進行加速,本文把卷積過程轉化為矩陣相乘,轉化的方法是文獻[16]中所用的Im2col,如圖3所示。該方法存儲空間要求增大但計算量(乘法和加法操作)沒有變化,若能有效利用稀疏性使0值不參與運算,可以在速度上明顯改進[17]。
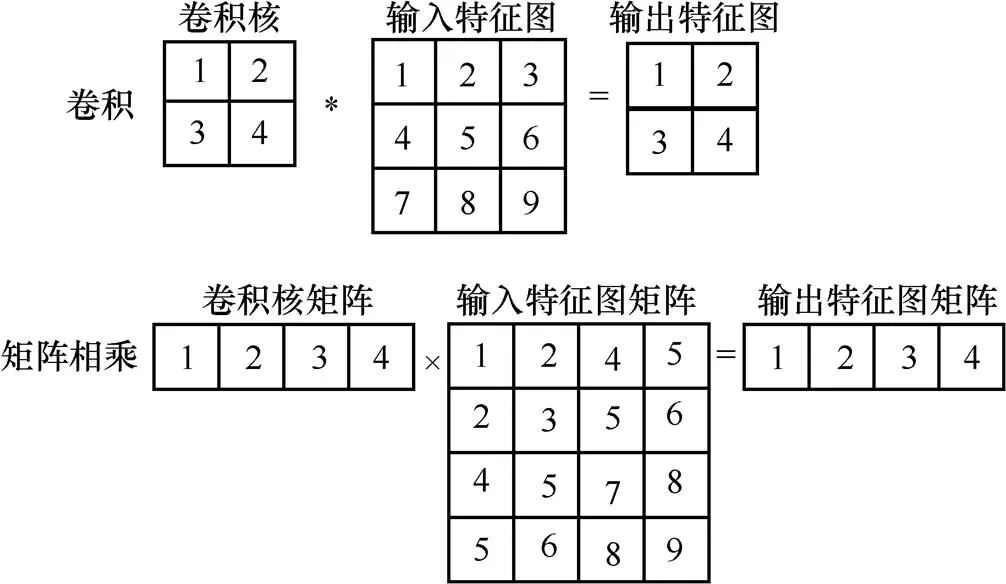
圖3 卷積轉換為矩陣相乘
2.2 并行矩陣乘法器用于CNN加速
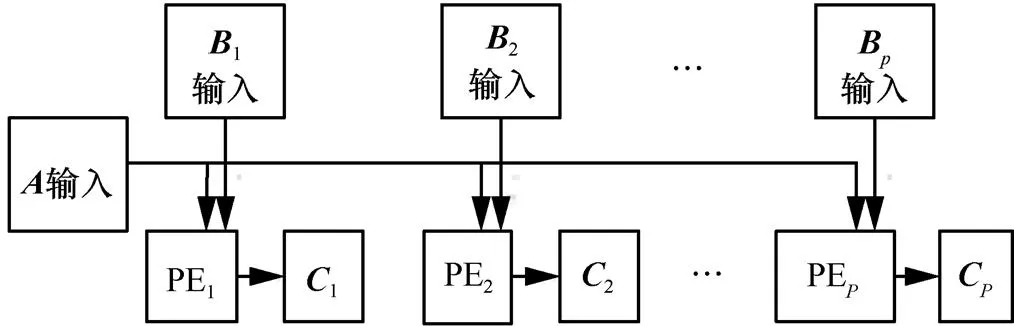
圖4 文獻[11]的并行矩陣乘法器單列結構
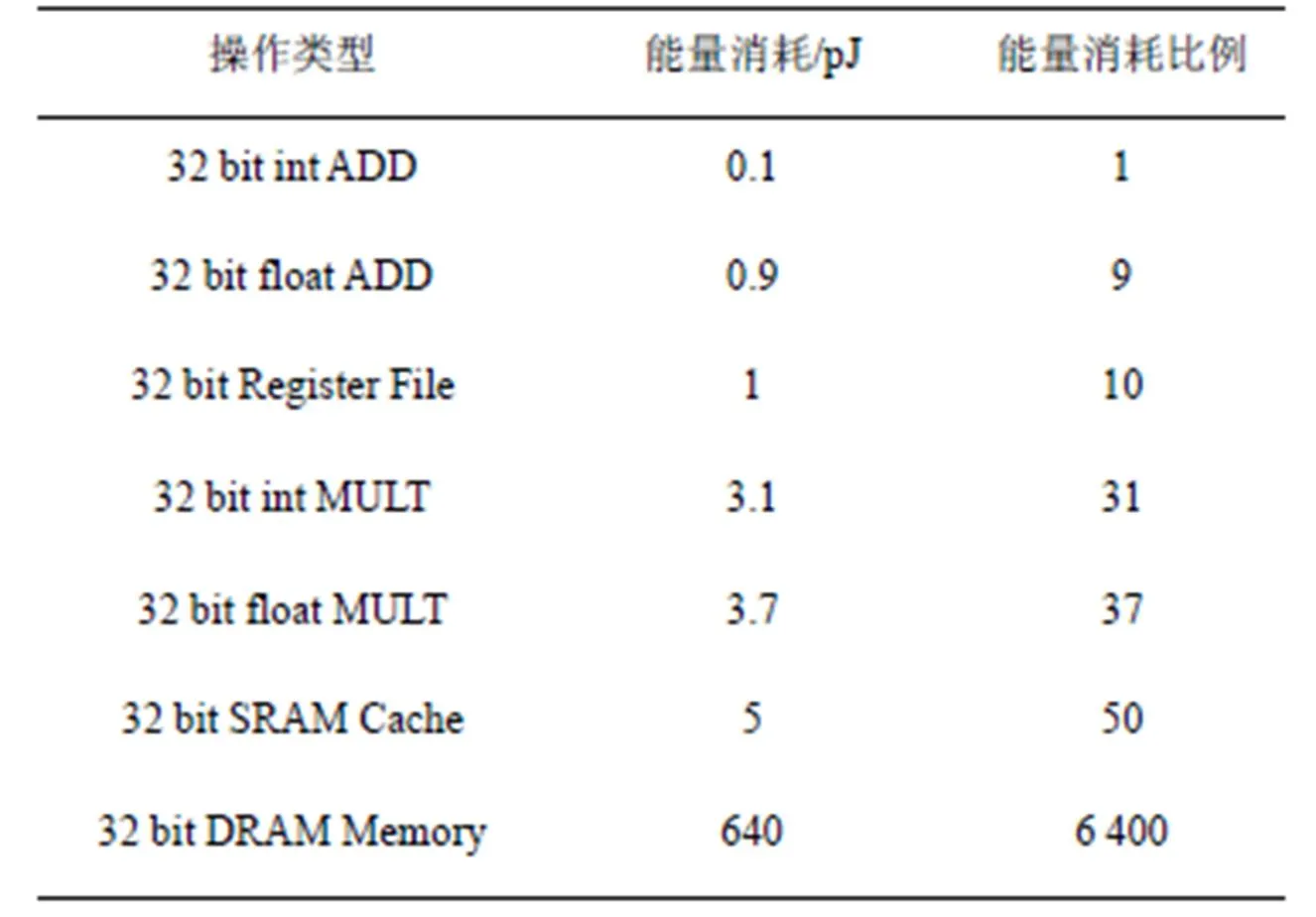
表1 45nm CMOS相關操作能量消耗
3 改進的線性脈動陣列
為了彌補傳統并行矩陣乘法器的缺點,并充分利用CNN計算中的稀疏性特點進行加速,本文基于文獻[13-14]提出的線性脈動陣列進行了兩方面改進,分別是單輸出線性脈動陣列和多輸出線性脈動陣列,具體如圖5~圖8所示。

圖5 單輸出線性脈動陣列
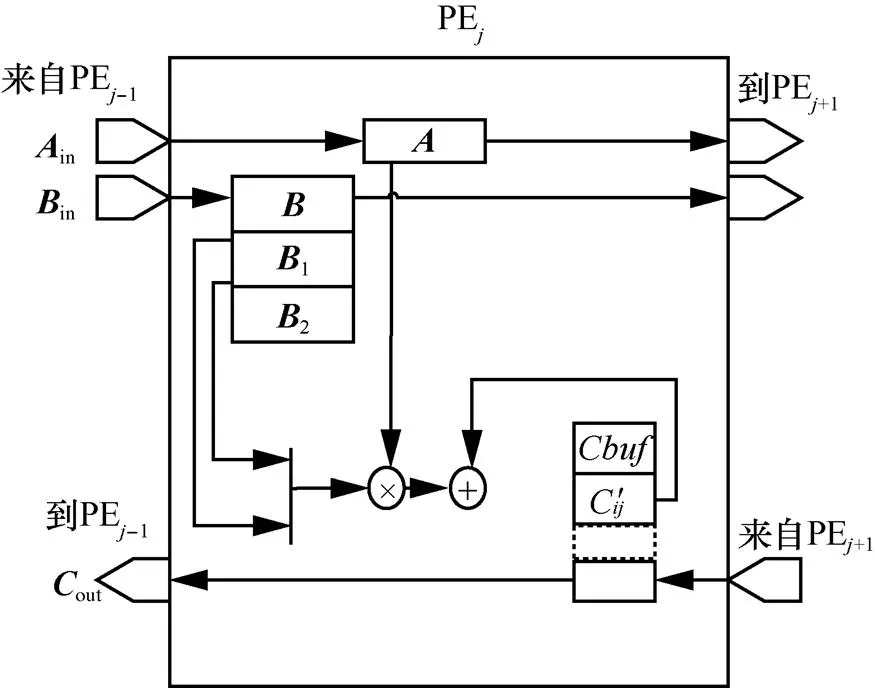
圖6 PE內部結構示意
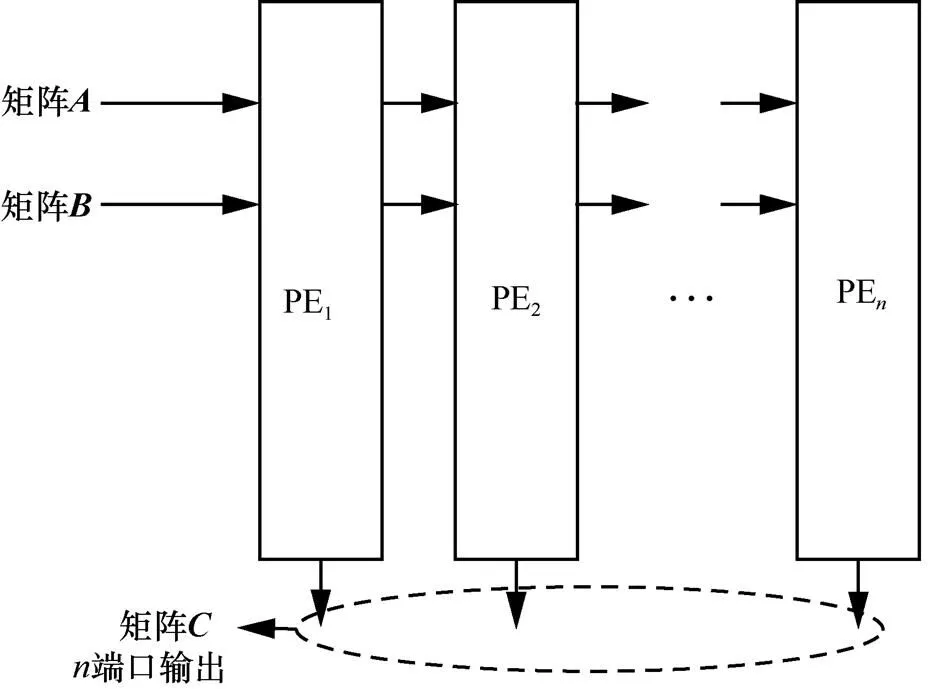
圖7 多輸出線性脈動陣列
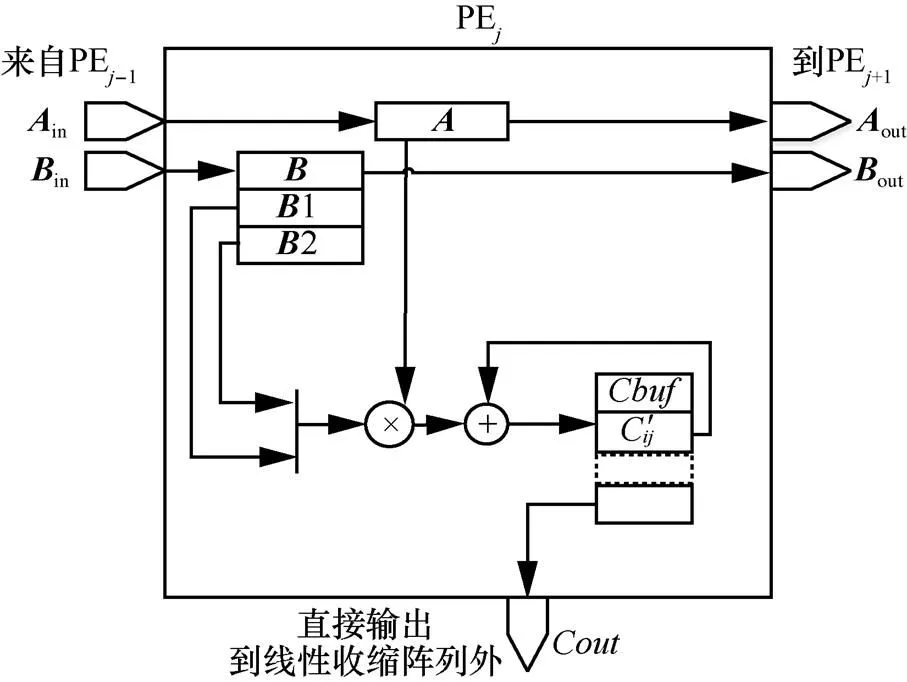
圖8 PE內部結構示意
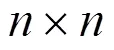
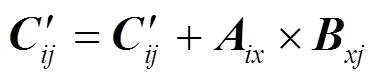
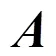
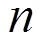
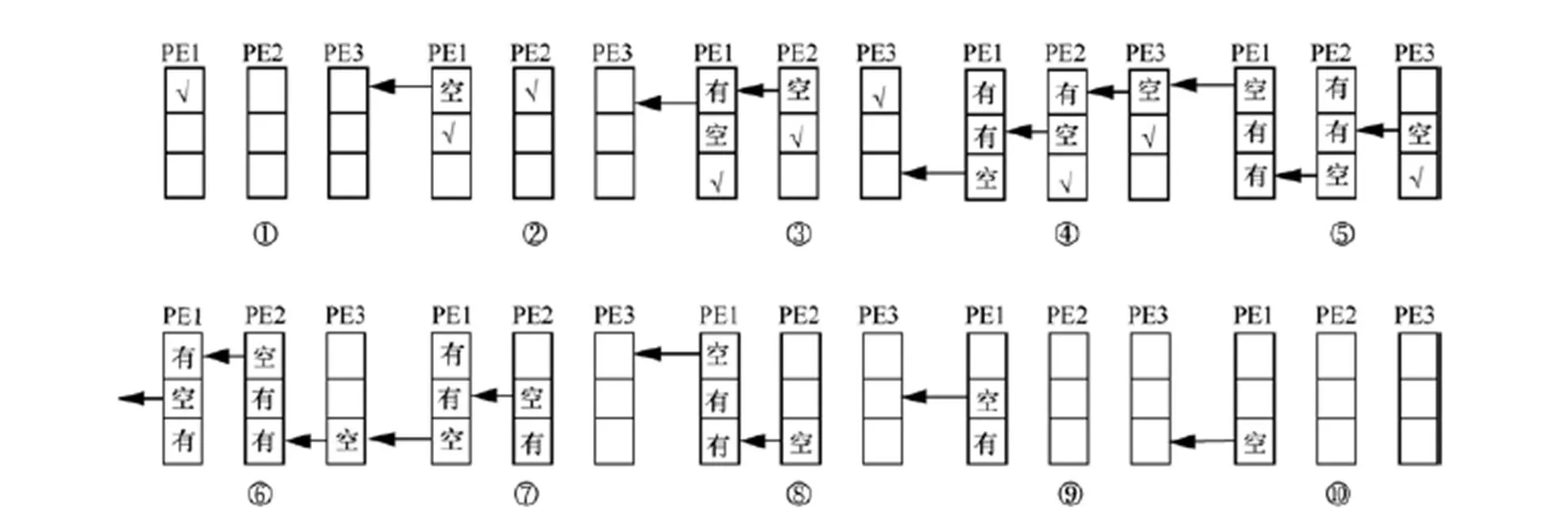
圖9 單Cache傳輸情況
4 單輸出線性脈動陣列性能分析
本文所用的單輸出線性脈動陣列和文獻[11]的并行矩陣乘法器的對比從3個方面進行:計算循環周期、存取操作類別和存取操作次數以及資源耗費情況。下面依次進行說明(接下來分析針對沒有0值的情況,為0值時對應線性脈動陣列的第一個方面改進)。
4.1 計算循環周期
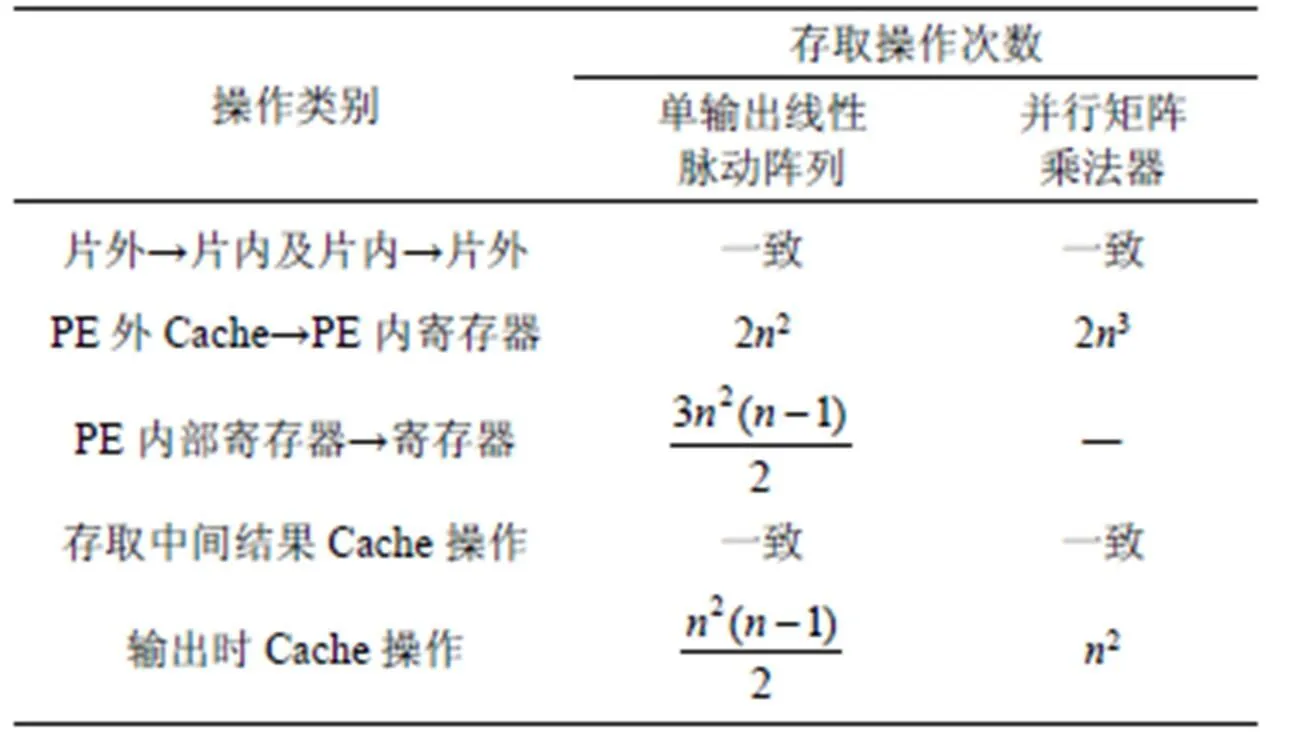
4.2 存取操作類別和存取操作次數
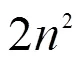
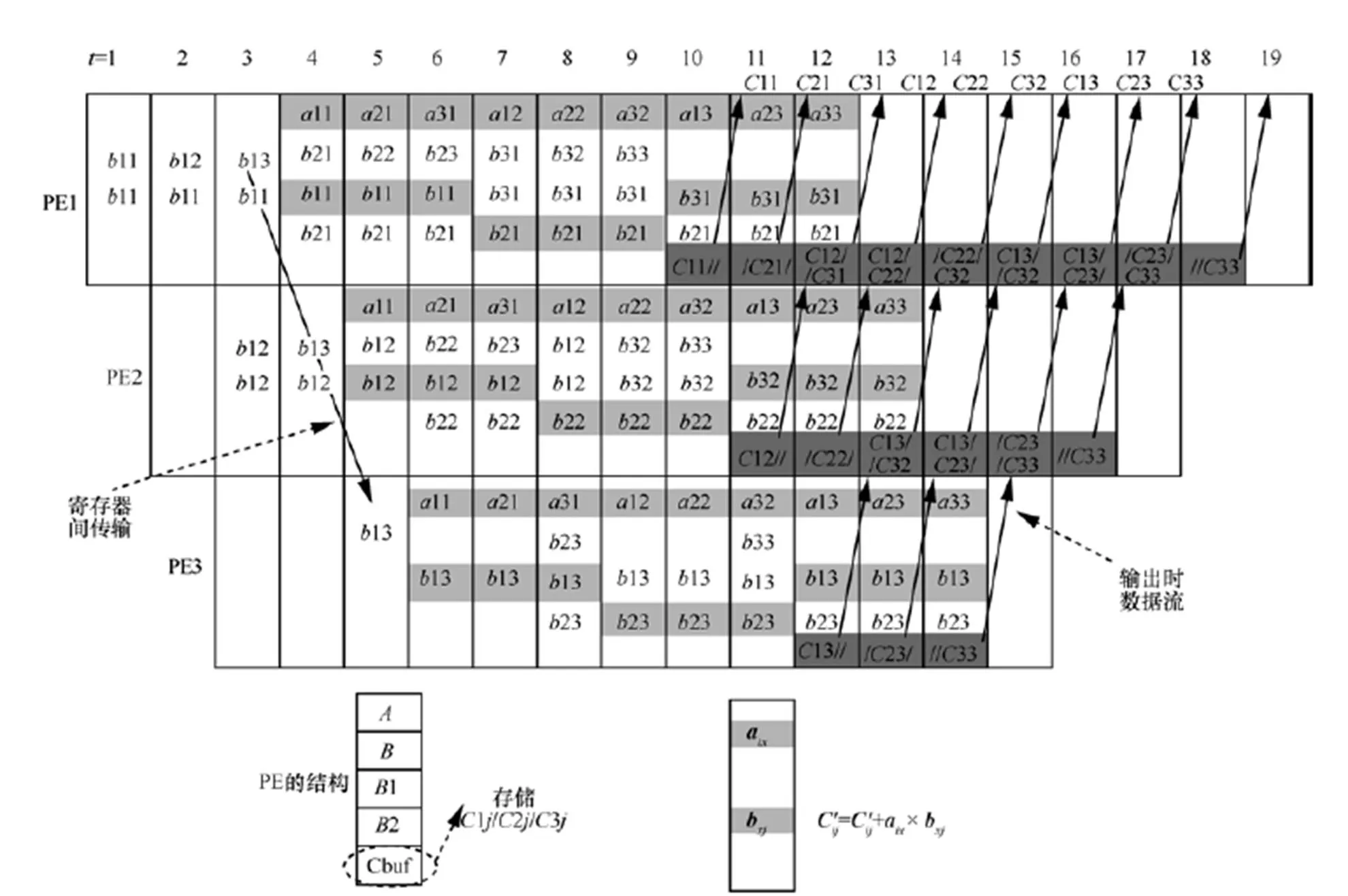
圖10 單輸出線性脈動陣列實現矩陣乘法操作過程
表2 單輸出線性脈動陣列和并行矩陣乘法器存取操作類別和存取操作次數對比
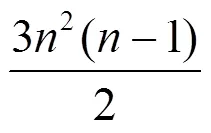
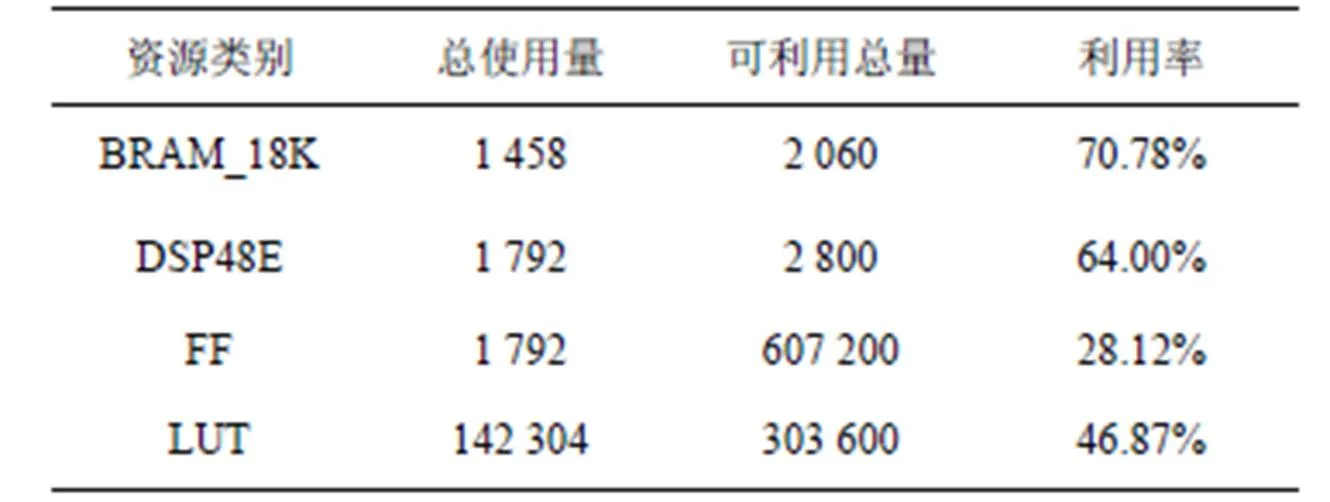
4.3 資源耗費情況
表3 并行矩陣乘法器用于Alexnet卷積加速時的FPGA內部資源使用情況
4.4 與并行矩陣乘法器對比
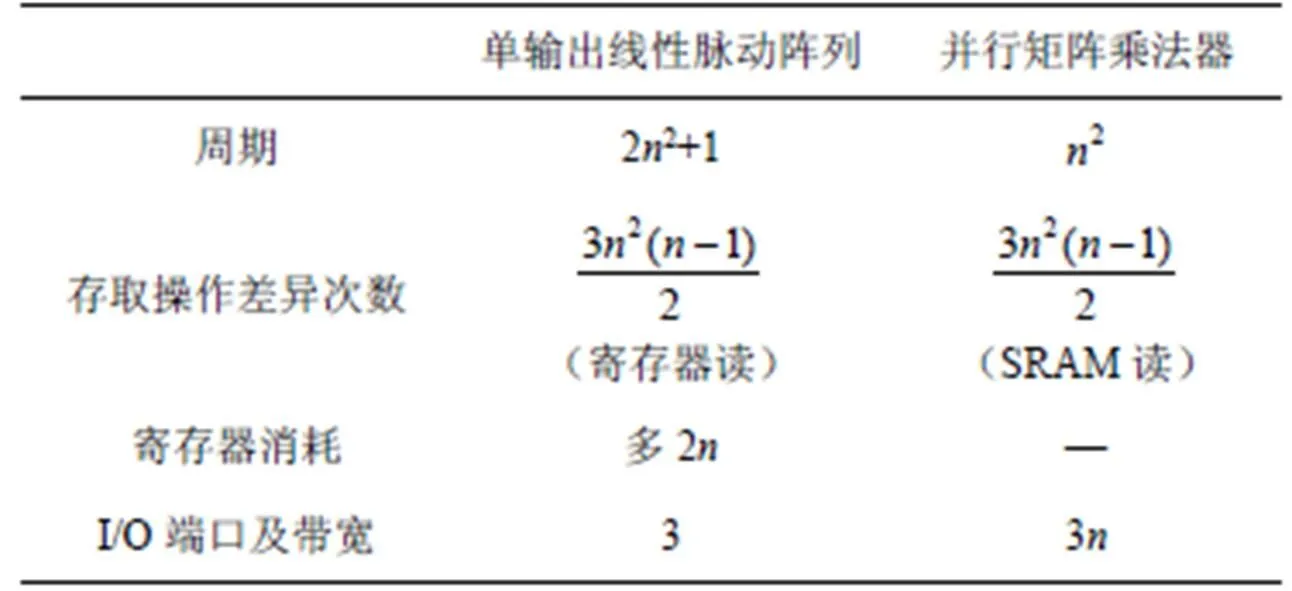
單輸出線性脈動陣列和并行矩陣乘法器各有優缺點,具體的對比分析如表4所示。從表4可以看出,雖然時間耗費增多,但本文單輸出的線性脈動陣列很好地彌補了傳統的并行矩陣乘法器帶寬要求太大的問題。
表4 單輸出線性脈動陣列和并行矩陣乘法器對比
5 多輸出線性脈動陣列性能分析
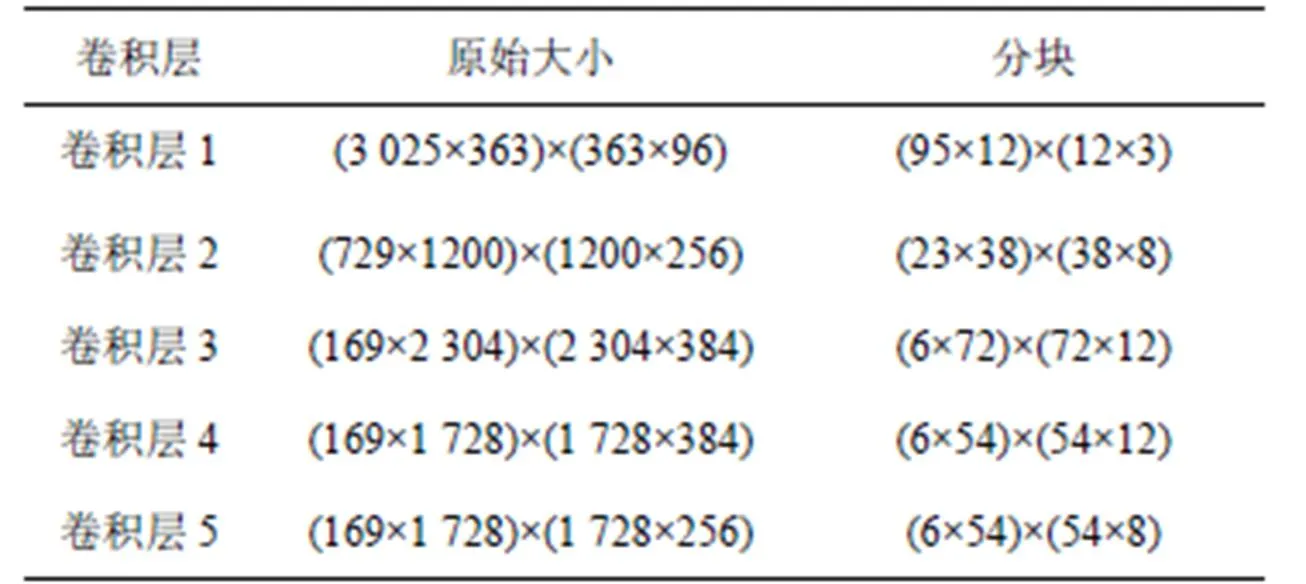
當結合具體CNN模型(如Alexnet)進行分析時,卷積核矩陣以及輸入特征圖矩陣太大,需要進行分塊操作。文獻[11]的單列并行矩陣乘法器用于Alexnet卷積加速時采用了448(14×32)個PE,為更好地進行理論上的對比,本文也采用14個并行的線性收縮陣列,每個有32個PE。為了有直觀上的認識,把Alexnet各卷積層矩陣分塊為大小為32×32的小矩陣后的情況列舉出來以方便后面的分析,具體如表5所示。
表5 Alexnet各卷積層矩陣分塊
分塊后一個很重要的想法是進一步復用和并行流水線。14個并行的線性脈動陣列可以同時進行矩陣乘法計算,分塊矩陣乘法有以下2種(如圖11所示):第一種是為了在乘法完成后方便進行相加;第二種是為了實現對分塊矩陣的復用,設置多級緩存可以進一步減少數據搬移量。
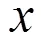
表6 多輸出線性脈動陣列和并行矩陣乘法器存取操作類別和存取操作次數對比
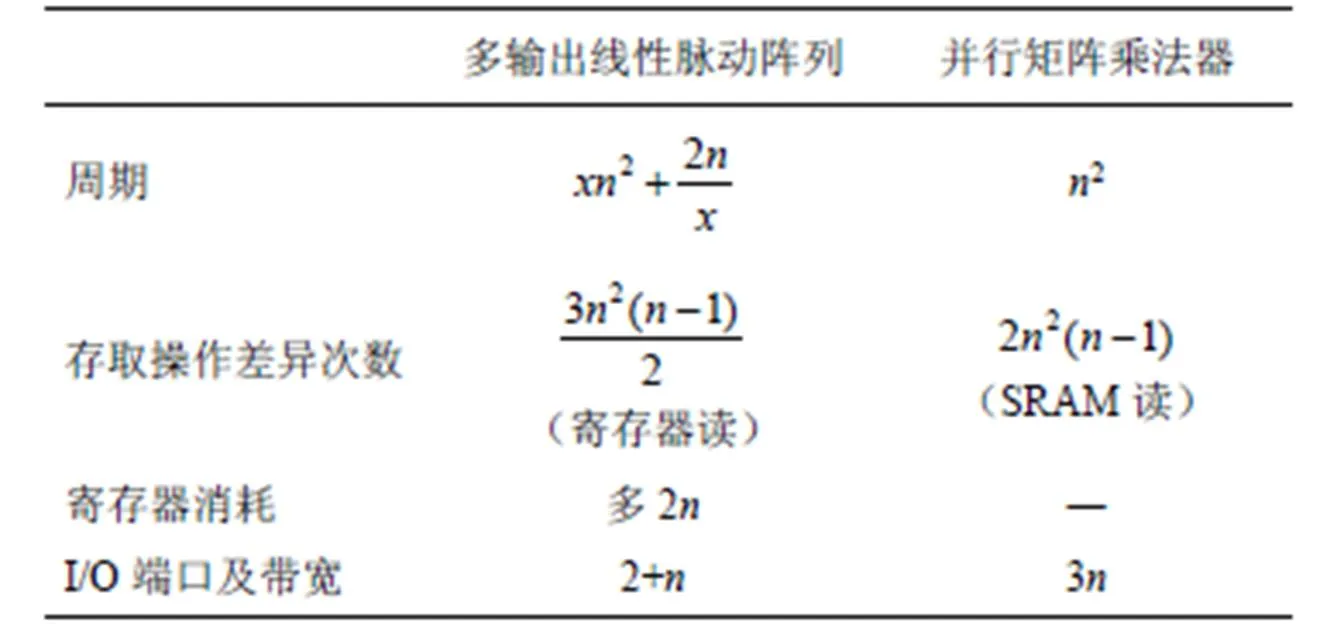
表7 改進的線性脈動陣列和并行矩陣乘法器特點
相比單輸出線性脈動陣列,多輸出線性脈動陣列的最大優點是周期數大幅減少。相比并行矩陣乘法器,該方式仍然具有帶寬的優勢。具體應用場景方面,由于線性脈動陣列能利用輸入中全部稀疏性(、中任意一者的稀疏性都能利用),對于像文獻[19]中剪枝技術應用后帶來的卷積核稀疏性,此時線性脈沖陣列的優勢明顯大于并行矩陣乘法器(并行矩陣乘法器只能利用某一方輸入中稀疏性)。
6 結束語
本文針對CNN計算稀疏性的特點以及文獻[11]所述的傳統并行矩陣乘法器用于CNN加速的局限性,對文獻[13-14]的線性脈動陣列提出了2種改進——單輸出以及多輸出線性脈動陣列,用于CNN嵌入式端的加速。文獻[11]提出的并行矩陣乘法器直接作用于CNN加速時所需帶寬太大,而線性脈動陣列正好能彌補該缺陷。單輸出線性脈動陣列和并行矩陣乘法器對比有耗能以及I/O端口少的優勢,但計算周期卻是2倍的關系,所以本文進一步改進線性脈動陣列,提出了多輸出線性脈動陣列。對比來看,多輸出方式的周期及I/O需求介于兩者之間,很好地解決了前兩者的突出缺陷問題,可行性最高。本文所進行的對比分析只是理論上說明,如何最佳組合以及最充分利用資源并實現是下一步的工作。
[1] HAN S, MAO H, DALLY W J. Deep compression: compressing deep neural networks with pruning, trained quantization and huffman coding[J]. Fiber, 2015, 56(4): 3-7.
[2] QIU J, WANG J, YAO S, et al. Going deeper with embedded FPGA platform for convolutional neural network[C]// International Symposium on Field-Programmable Gate Arrays. 2016: 26-35.
[3] SABOUR S, FROSST N, HINTON G E. Dynamic routing between capsules[C]//Annual Conference on Neural Information Processing Systems. 2017.
[4] HAN S, LIU X, MAO H, et al. EIE: efficient inference engine on compressed deep neural network[J]. ACM Sigarch Computer Architecture News, 2016, 44(3): 243-254.
[5] CHEN W, WILSON J, TYREE S, et al. Compressing neural networks with the hashing trick[C]//International Conference on Machine Learning. 2015: 2285-2294.
[6] MA Y, CAO Y, VRUDHULA S, et al. Optimizing loop operation and dataflow in FPGA acceleration of deep convolutional neural networks[C]//International Symposium on Field-Programmable Gate Arrays. 2017:45-54.
[7] LI N, TAKAKI S, TOMIOKAY Y, et al. A multistage dataflow implementation of a deep convolutional neural network based on FPGA for high-speed object recognition[C]//2016 IEEE Southwest Symposium on Image Analysis and Interpretation. 2016: 165-168.
[8] SUDA N, CHANDRA V, DASIKA G, et al. Throughput-optimized openCL-based FPGA accelerator for large-scale convolutional neural networks[C]// International Symposium on Field-Programmable Gate Arrays. 2016: 16-25.
[9] XIAO Q, LIANG Y, LU L, et al. Exploring heterogeneous algorithms for accelerating deep convolutional neural networks on FPGAs[C]//The 54th Annual Design Automation Conference. 2017: 62-67.
[10] CHEN Y H, KRISHNA T, EMER J S, et al. Eyeriss: an energy-efficient reconfigurable accelerator for deep convolutional neural networks[J]. IEEE Journal of Solid-State Circuits, 2017, 52(1): 127-138.
[11] 劉勤讓, 劉崇陽. 利用參數稀疏性的卷積神經網絡計算優化及其FPGA加速器設計[J]. 電子與信息學報, 2018, 40(6): 1368-1374.LIU Q R, LIU C Y. Calculation optimization for convolutional neural networks and FPGA-based accelerator design using the parameters sparsity[J]. JEIT, 2018, 40(6): 1368-1374.
[12] LIU X, HAN S, MAO H, et al. Efficient sparse-winograd convolutional neural networks[C]//International Conference on Learning Representations. 2017.
[13] JANG J W, CHOI S B, PRASANNA V K. Energy-and time-efficient matrix multiplication on FPGAs[J]. IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 2005, 13(11): 1305-1319.
[14] MATAM K K, LE H, PRASANNA V K. Energy efficient architecture for matrix multiplication on FPGAs[C]//International Conference on Field Programmable Logic and Applications. 2013:1-4.
[15] JIA Y, SHELHAMER E, DONAHUE J, et al. Caffe: convolutional architecture for fast feature embedding[C]//The 22nd ACM International Conference on Multimedia. 2014: 675-678.
[16] JIA Y Q. Optimzing conv in caffe[R].
[17] MOONS B, DE BRABANDERE B, VAN GOOL L, et al. Energy-efficient convnets through approximate computing[C]// Applications of Computer Vision. 2016: 1-8.
[18] 田翔, 周凡, 陳耀武, 等. 基于FPGA的實時雙精度浮點矩陣乘法器設計[J]. 浙江大學學報(工學版), 2008, 42(9):1611-1615. TIAN X, ZHOU F, CHEN Y W, et al. Design of field programmable gate array based real-time double-precision floating-point matrix multiplier[J]. Journal of Zhejiang University (Engineering Science), 2008, 42(9):1611-1615.
[19] HAN S, POOL J, TRAN J, et al. Learning both weights and connections for efficient neural network[C]//Annual Conference on Neural Information Processing Systems. 2015: 1135-1143.
[20] LAI B C C, LIN J L. Efficient designs of multi-ported memory on FPGA[J]. IEEE Transactions on Very Large Scale Integration (VLSI) Systems, 2017, 25(1): 139-150.
[21] CHEN J, LI J. The research of peer-to-peer network security[C]//The International Conference on Information Computing and Automation. 2015: 590-592.
Based on linear systolic array for convolutional neural network’s calculation optimization and performance analysis
LIU Qinrang, LIU Chongyang, ZHOU Jun, WANG Xiaolong
(National Digital Switching System Engineering and Technological R&D Center, Zhengzhou 450002, China)
Concerning the issue that the convolutional neural network (CNN) accelerator design on most FPGA ends fails to effectively use the sparsity and considering both bandwidth and energy consumption, two improved CNN calculation optimization strategies based on linear systolic array architecture are proposed. Firstly, convolution is transformed into matrix multiplication to take advantage of sparsity. Secondly, in order to solve the problem of large I/O demand in traditional parallel matrix multiplier, linear systolic array is used to improve the design. Finally, a CNN acceleration comparative analysis of the advantages and disadvantages between parallel matrix multiplier and two improved linear systolic arrays is presented. Theoretical proof and analysis show that compared with the parallel matrix multiplier, the two improved linear systolic arrays make full use of sparsity, and have the advantages of less energy consumption and less I/O bandwidth occupation.
linear systolic array, convolutional neural network, sparsity, I/O bandwidth, performance analysis
TP183
A
10.11959/j.issn.2096-109x.2018100
2018-08-10;
2018-10-29
劉崇陽,zmylmh1@163.com
國家科技重大專項基金資助項目(No.2016ZX01012101);國家自然科學基金資助項目(No.61572520);國家自然科學基金創新研究群體資助項目(No.61521003)
The National Science Technology Major Project of China (No.2016ZX01012101), The National Natural Science Foundation of China (No.61572520), The National Natural Science Foundation Innovation Group Project of China (No.61521003)
劉勤讓(1975-),男,河南睢縣人,國家數字交換系統工程技術研究中心研究員,主要研究方向為寬帶信息網絡、片上網絡設計。

劉崇陽(1994-),男,湖北宜昌人,國家數字交換系統工程技術研究中心碩士生,主要研究方向為人工智能、深度學習。
周俊(1979-),男,湖北黃岡人,國家數字交換系統工程技術研究中心講師,主要研究方向為芯片設計、寬帶信息處理。
王孝龍(1993-),男,河南民權人,國家數字交換系統工程技術研究中心碩士生,主要研究方向為寬帶信息網絡、協議解析。
猜你喜歡
中等數學(2022年2期)2022-06-05 07:10:50
中學生數理化·七年級數學人教版(2021年11期)2021-12-06 05:38:48
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
小學生學習指導(低年級)(2020年6期)2020-07-25 02:31:36
電子制作(2018年18期)2018-11-14 01:48:24
小學生學習指導(低年級)(2018年9期)2018-09-26 05:59:44
瘋狂英語·新讀寫(2018年2期)2018-09-07 09:32:10
數學小靈通·3-4年級(2017年6期)2017-06-22 11:28:50
山東工業技術(2016年15期)2016-12-01 05:31:22
中國中醫藥現代遠程教育(2014年11期)2014-08-08 13:23:44
