基于拖曳線列陣聲納與ARPA雷達的目標分選
2018-12-20 07:54:38高楓顏明重朱大奇
電子設計工程 2018年24期
關鍵詞:關聯
高楓,顏明重,朱大奇
(上海海事大學信息工程學院,上海201306)
拖曳線列陣聲納是一種拖曳距船尾部一定距離的聲波接收系統,用于探測水上與水下目標。它通過接收航行目標自身輻射噪聲來進行探測,標定,跟蹤以及類型識別[1]。
拖曳線列陣聲納技術雖能用于測量目標的方向,但其在水上與水下的目標分選工作中仍存在不小的局限性。目前,利用拖曳線列陣聲納進行目標分選的研究中,通常采用對探測目標的輻射噪聲進行特征提取的方法,獲得探測目標輻射噪聲的功率譜、頻譜,并與現有船艇噪聲庫和信息庫進行對照分析,從而實現目標分選[2]。但由于水聲目標本身種類繁多、目標輻射噪聲隨海情、航速、工況的不同而變化及各種客觀因素的影響,即使是同一目標輻射噪聲的差異也很大,并且水聲樣本是各個國家的機密,因此,擁有完備的信號庫是十分困難且代價很高的[3-4]。所以,對于信息庫中未記錄輻射噪聲頻譜的目標,無法用此方法對目標進行識別或分選。
為解決這種拖曳線列陣聲納目標分選工作的局限性,本文充分利用拖曳線列陣聲納與其他傳感器,如船載的ARPA雷達,采用信息融合的方法,來實現水上與水下目標的分選。由于ARPA雷達只能探測到水上目標[5-7],而拖曳線列陣聲納可同時探測到水上和水下的目標,因此,將拖曳線列陣聲納與ARPA雷達的多目標數據進行時空配準和航跡關聯,可有效地分選出水下目標。
本文主要工作如下:通過構建實際運動仿真模型,對同時載有拖曳線列陣聲納與ARPA雷達的艦船基于分布式結構模型進行具體目標分選分析。主要步驟包括:時間配準、空間配準及航跡關聯。其中,本文使用自適應α-β算法進行ARPA雷達與拖曳線列陣聲納數據的時間配準,采用基于統計的最近領域法進行航跡關聯。
1 運動目標建模
拖曳線列陣聲納探測系統與ARPA雷達系統所探測到的方位是目標相對于本船的角度,設原點為本船,目標與本船的相對位置如圖1所示。
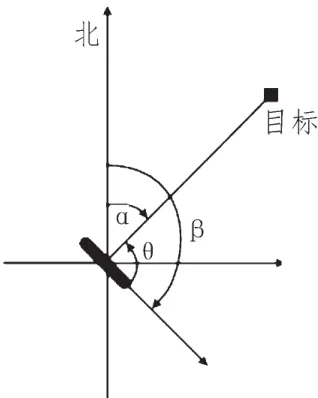
圖1 探測目標角度示意圖
以正北方向為零度方向,進行順時針旋轉,α表示目標相對本船的絕對方位,β表示本船的航向角,則聲納基陣探測到的目標方位θ可以表示為:

即,考慮的方位就是對θ的計算,當本船保持類直線運動或停滯不動時,本船航向β是一個常數。θ與α是線性關系,對探測方位的計算可以轉化為對絕對方位的計算。
不同的目標運動模型在聲納圖上顯示的航跡是不同的。設想一個目標圍繞著本船做類圓周運動(曲線運動),如圖2所示:
目標相對拖曳陣聲納基陣的方位角表示為:
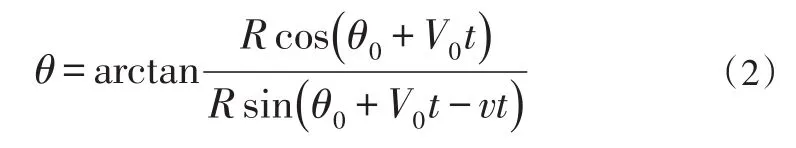
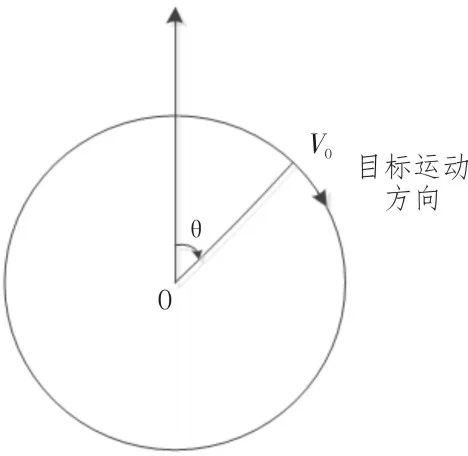
圖2 類圓周運動模型圖
其中:θ0為目標初始方位,R為目標做類圓周運動的半徑,V0是目標轉向角速度,V為本船速度。當速度V較小時,探測方位θ與時間t的關系近似為線性關系。若目標保持類直線運動,如圖3:
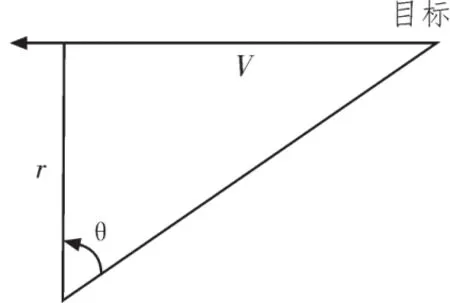
圖3 類直線運動模型圖
目標相對探測基陣的方位角可表示為:
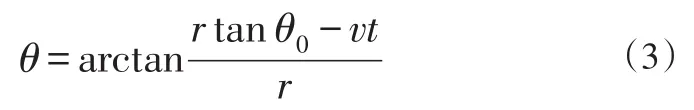
若它不是t的線性函數,目標方位軌跡會顯示為一條正切曲線,根據已有的目標方位記錄值進行正切函數計算是非常困難的,會消耗大量的時間。最有效的辦法是假設目標的方位角在短時間服從線性變化,根據已知的目標航跡(t,θ)利用最小二乘方法擬合出一條直線,計算某個時刻的θ值,設:

求a,b使得J極小,再對J求微商:
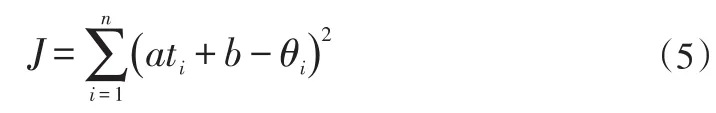
可解得:
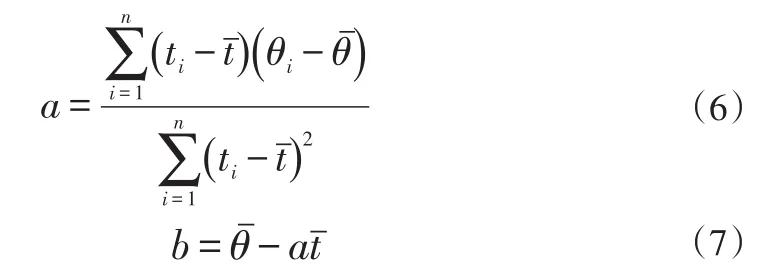
其中:

把a,b代入公式,可求得:

在短時間內,水上與水下運動目標的方位角可看作呈線性變化的。這種類直線擬合的方式,時間越短效果越好。因此,在短時間內探測海上運動目標時,可將目標方位角看作呈線性變化。
2 目標數據預處理
2.1 目標數據空間配準
由于聲納基陣中心與母船雷達的坐標中心位置不同,因此,在航跡關聯之前,需對空間坐標進行統一。一般將拖曳線列陣聲納測得的目標方位,經視差修正,轉換到母船雷達坐標系中[8],如圖4所示。
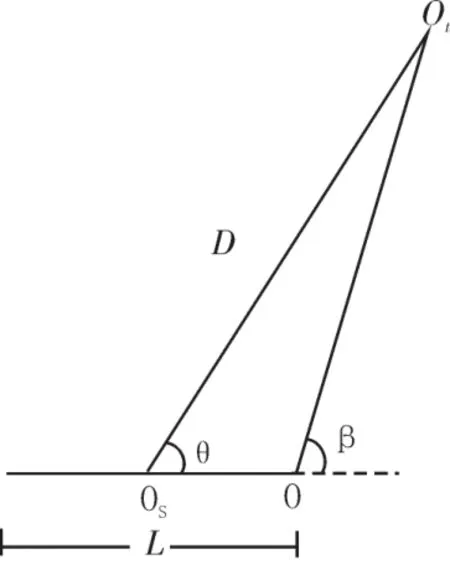
圖4 拖曳線列陣聲納探測目標示意圖
假設本船拖曳線列陣聲納長L米,本船雷達的位置為O,目標位置為Ot,目標距離聲納中心θs的距離為D,拖曳線列陣聲納探測的舷角為θ,則修正后的舷角為:
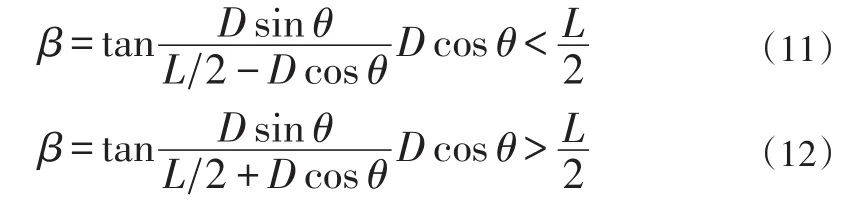
2.2 目標數據時間配準
拖曳線列陣聲納與ARPA雷達的目標數據傳輸率通常不一致,在航跡關聯前,必須對其在時間上進行同步。常見時間同步方法有:最小二乘法、內插外推、基于神經網絡的一系列算法和濾波算法等[9-13]。本文采用一種在時間復雜度和空間復雜度都較小,更加滿足實際應用的自適應α-β濾波算法。
一般的α-β濾波算法精度不夠高,并且往往隨著目標運動的變化誤差會越來越大,不能滿足信息融合要求,本研究使用的自適α-β算法,用殘差累積的方法來不斷更α,β值,從而將其精確度提高[14],下面給出公式說明:
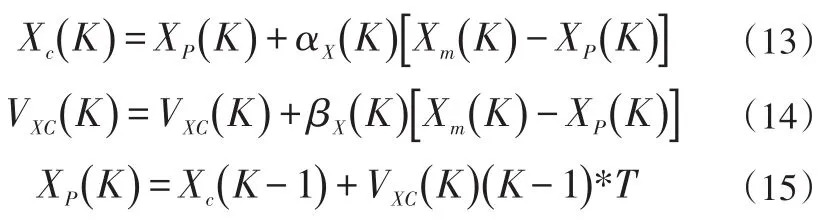
其中:XP(K)是通過前一個周期即第K-1個周期,來預測的目標信號在第K周期的橫坐標測量值,Xc(K) 是目標在第K周期的橫坐標計算值;αX(K)是第K周期X方向的距離平滑系數,βX(K)是第K周期X方向速度分量的平滑系數。
加入修正系數是因為預測值或計算值存在誤差。若將α,β設為固定值,當目標船發生運動狀態變化時,很容易造成軌跡預測錯誤。此處采用殘差積累算法不停更新α,β值,殘差用來表示,傳感器的測量誤差的方差用來表示,該誤差是固定值。而預測的誤差需要一個過程去積累,因此我們需要一個滑動窗口來不停更新。對于數據的處理我們僅需考慮一個方向即可。下面以X方向的α,β計算為例。
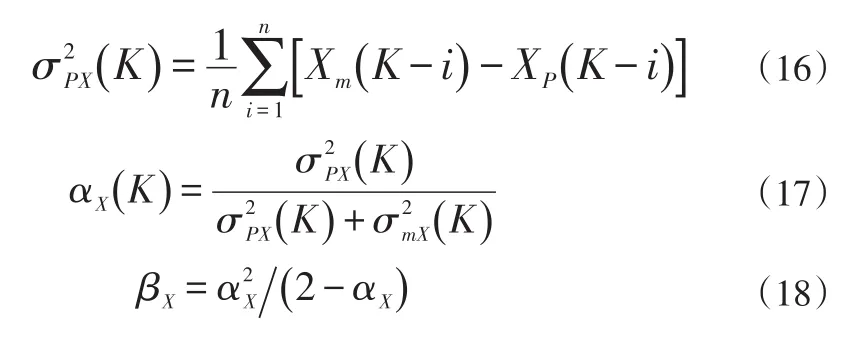
3 目標航跡關聯
航跡關聯的主要工作可以描述為:預處理過后的ARPA雷達目標數據和拖曳線列陣聲納目標數據是否源于相同目標,同源目標即為水上目標,非同源目標則為水下目標。
多傳感器多目標的航跡關聯算法通常分為基于統計算法的和基于模糊數學的算法[15-16]。理論上,基于模糊數學的關聯算法具有精度高,關聯誤差小的優點,尤其是在目標數量大且目標數據分布密集的情況下。但這是以犧牲時間、空間復雜度為前提的。基于統計的關聯算法雖然在目標數量大且目標數據分布極為密集的情況下,精度不如基于模糊數學的關聯算法,但在效率上要遠遠高于前者。本文考慮在實際應用中目標的分布不會過于密集,而且實際往往要求時間和空間復雜度更小的算法,因此采用基于統計的算法。先不妨假設節點數為M=2,對于M>2的情況可以類推,設兩個傳感器的航跡節點集合分別為:
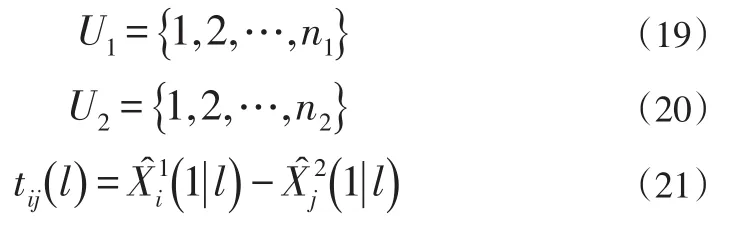
可定義H0和H1為下列事件:是對于相同 目標的航跡估計;H1:是對于不同目標的航跡估計。這樣目標關聯問題就轉化為了假設檢驗問題,這里我們使用最近鄰域法。
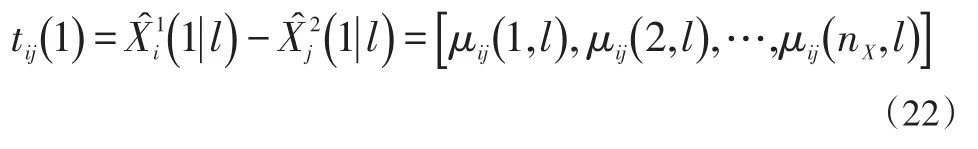
式中:i∈U1,j∈U2,nX是狀態估計的維數,表示l時刻的各航跡的狀態估計誤差。若假設閾值矢量為,那么,最近領域關聯的標準為:
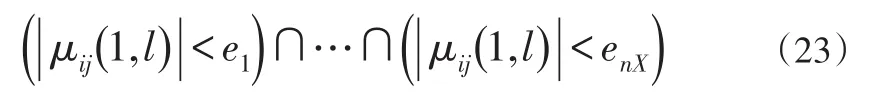
若公式(23)成立,那么我們就可認為兩條航跡相關聯,且只要成功關聯,就無需對該航跡進行后續關聯檢測。也有學者提出了基于統計的其它算法,這里不再贅述。
4 仿真與實現
4.1 時間配準算法仿真
針對上述兩種時間配準算法,本節采用MATLAB軟件對其進行仿真與分析,模擬目標的運動軌跡與ARPA雷達獲得的數據測量值。再用兩種時間配準算法對該數據進行處理,比較二者的配準精度。誤差取時間點為5到50秒的配準數據與真實數據的差值絕對值,如圖5~7所示。
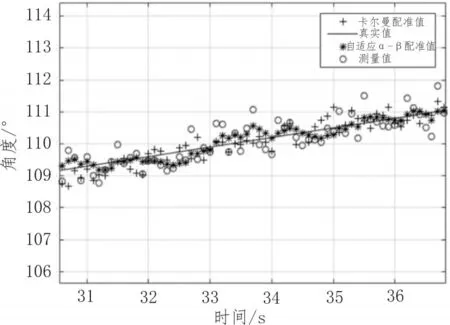
圖5 時間配準局部放大圖
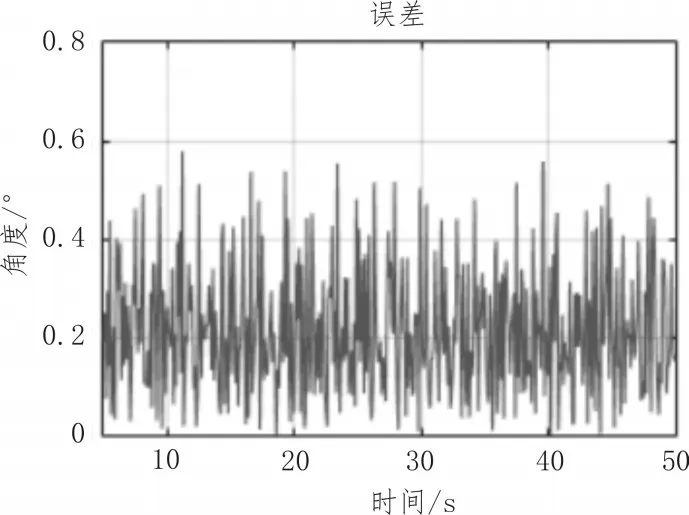
圖6 卡爾曼濾波算法誤差分析圖
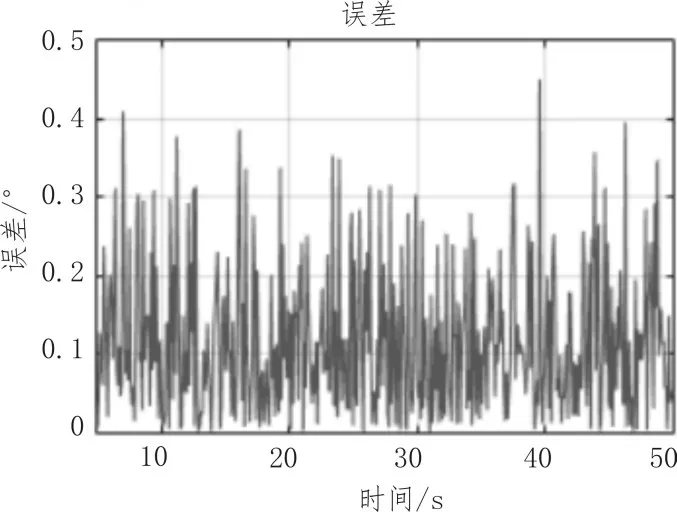
圖7 自適應α-β濾波算法誤差分析圖
通過分析可知,一方面,在精度上,自適應的α-β濾波算法能夠將誤差范圍控制在0.4度以內,而常用的卡爾曼濾波算法只能將誤差范圍控制在0.6度以內。由此可見在實際應用中,自適應的α-β濾波算法與目標實際運動軌跡的匹配度更高,且計算量更小,時間和空間復雜度更低,因此,運行所占內存小,速度更快,能夠在盡可能短的時間內對目標進行分選。另一方面,自適應α-β濾波算法能夠根據經驗設置初始α,β值,使軌跡盡快趨于收斂,而卡爾曼濾波算法的初始誤差極大,需一段時間后才趨于收斂。因此在實際應用中,自適應α-β濾波算法更滿足實際需求。
4.2 時間配準算法的實際應用
將自適應的α-β濾波算法應用到一組真實數據中,本文選取了一段從100s到500s的時間范圍內,目標真實運動軌跡的方位角數據,如圖8所示。
由分析可知,雖然真實數據會隨著測量誤差上下浮動,但浮動幅度極小,可在大體上保持穩定。對比ARPA雷達數據與拖曳線列陣聲納數據的時間序列,按缺少的時間的值在濾波之后的函數上取值,即可達到時間配準的目的。
4.3 航跡關聯算法仿真
針對上述的關聯方法,利用MATLAB進行仿真驗證,模擬了3個目標,兩個水上目標,一個水下目標,用時間配準后的ARPA雷達數據和拖曳線列陣聲納數據進行關聯,見表1~3,從而判斷目標位置,完成分選。
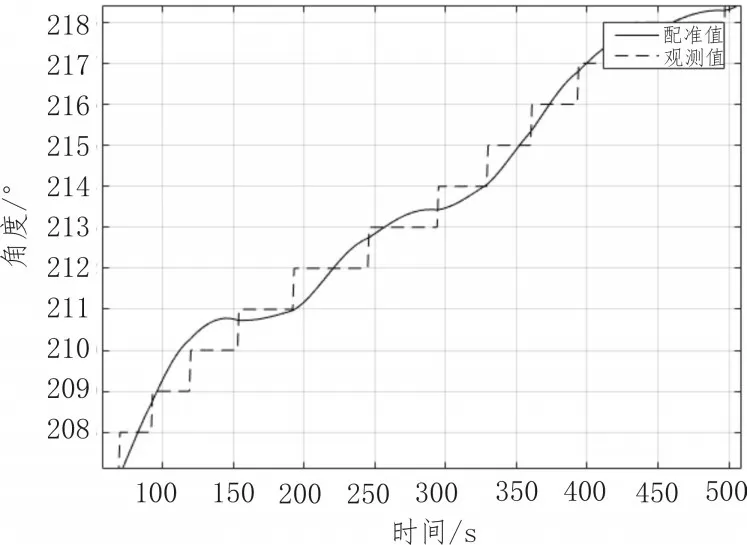
圖8 真實數據配準圖
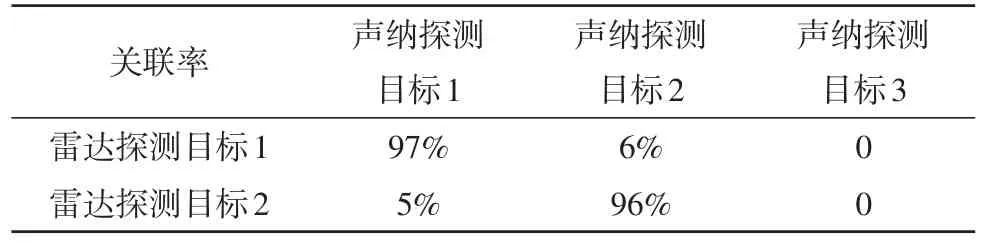
表1 閾值e=1°時的關聯率
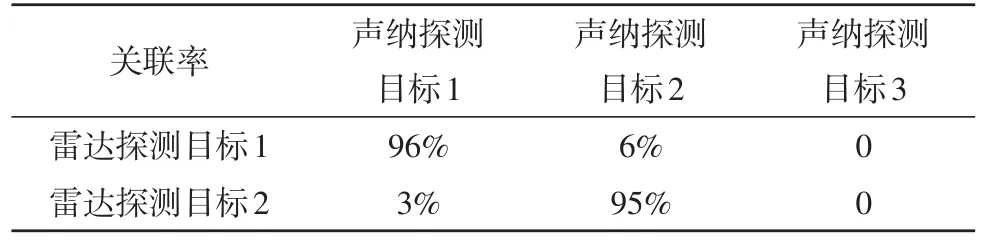
表2 閾值e=0.75°時的關聯率
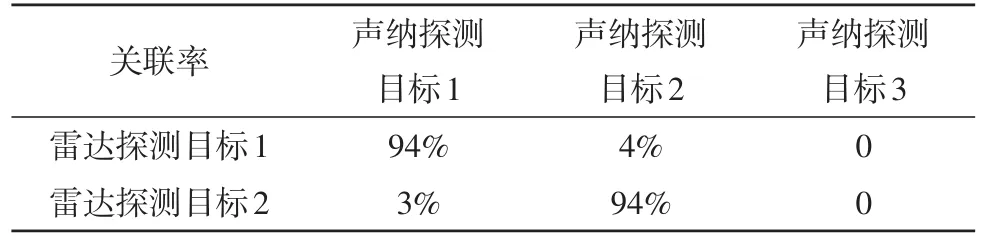
表3 閾值e=0.6°時的關聯率
由表1~3可知,拖曳線列陣聲納探測到的目標1和ARPA雷達的目標1是同一目標,拖曳線列陣聲納探測到的目標2和ARPA雷達的目標2是同一目標,而目標3則是水下目標。且由表中數據可知,關聯率對于閾值的取值并不敏感,可通過經驗取閾值。由于個別探測點的測量誤差較大,還存在兩船探測軌跡交叉的情形,在交叉點附近易發生誤關聯,但對于關聯率90%以上的兩個目標,可認為這兩個目標為同一目標,聲納數據圖與雷達數據圖分別如圖9與圖10所示。
5 結論

圖9 聲納數據圖
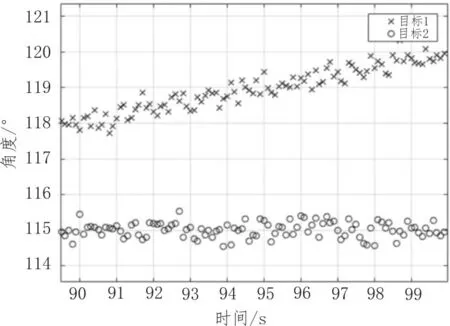
圖10 雷達數據圖
鑒于我國現階段水上與水下目標的分選研究具有依賴已有噪聲庫這一局限性,本文設計了基于拖曳線列陣聲納和ARPA雷達的目標分選系統,使其不必依賴于信息庫中的數據。該系統使用分布式融合模型對運動模型進行分析,模擬了真實船舶的拖曳線列陣聲納數據與ARPA雷達數據,采用了優化的時間配準、空間配準和航跡關聯算法,具有更小的時間復雜度與空間復雜度以及更高的精度,因此,其所占內存小、運行速度快,更加滿足實際應用要求。通過MATLAB軟件進行的仿真實現和測試驗證表明,本文提出的方法能夠快速且可靠的對未知目標進行初步分選,在實際應用中,可借此方法分選陌生船只或潛水器,這對于我國的國防建設有著十分重要的實際意義。本文研究不僅局限于拖曳列陣聲納與ARPA雷達這兩個傳感器,也可加入AIS等探測設備,即本文后續研究可拓展至多傳感器。
猜你喜歡
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:30
當代陜西(2021年17期)2021-11-06 03:21:36
原道(2020年2期)2020-12-21 05:47:06
當代陜西(2019年15期)2019-09-02 01:52:00
中國非營利評論(2018年2期)2018-06-18 10:48:50
學苑創造·A版(2018年11期)2018-02-01 06:29:20
自動化學報(2017年1期)2017-03-11 17:31:17
讀者(2017年5期)2017-02-15 18:04:18
西藏科技(2016年5期)2016-09-26 12:16:39
振動工程學報(2015年1期)2015-03-01 01:15:42
