基于關(guān)聯(lián)規(guī)則的標(biāo)簽推薦
2018-12-20 01:56:52陳雙雙王曉軍
計算機(jī)技術(shù)與發(fā)展 2018年12期
陳雙雙,王曉軍
(南京郵電大學(xué) 計算機(jī)學(xué)院,江蘇 南京 210003)
0 引 言
標(biāo)簽系統(tǒng)在實際生活中應(yīng)用廣泛,用戶通過標(biāo)簽可以標(biāo)注或者搜索自己感興趣的資源,反映該用戶的偏好,表達(dá)對事物的看法,因此標(biāo)簽是連接用戶和事物的紐帶。目前常見的標(biāo)簽推薦方法大都基于FolkRank算法[1],這種方法主要是基于用戶、標(biāo)簽、資源三者之間的關(guān)系,并且以這種關(guān)系為基礎(chǔ)構(gòu)建一個無向圖進(jìn)行標(biāo)簽推薦,但是現(xiàn)有的方法沒有考慮到標(biāo)簽與標(biāo)簽之間的關(guān)系,并且也不能有效地緩解數(shù)據(jù)稀疏問題。針對這些問題,引入了標(biāo)簽與標(biāo)簽的關(guān)系,并且利用標(biāo)簽之間的關(guān)系進(jìn)行推薦。
1 相關(guān)研究
Kim等[2]強(qiáng)調(diào)標(biāo)簽數(shù)據(jù)可以描述用戶潛在的興趣和特征,并認(rèn)為結(jié)合不同的算法(協(xié)同過濾、隨機(jī)游走模型等等)可以得到顯著的優(yōu)勢,提高個性化推薦的質(zhì)量。Mahboob等[3]在推薦過程中應(yīng)用熱擴(kuò)散算法,在提取數(shù)據(jù),如用戶、標(biāo)簽、資源以及它們之間的關(guān)系之后,從系統(tǒng)日志文件創(chuàng)建基于圖的模式;根據(jù)用戶的活動路徑并觀察所創(chuàng)建的模式的熱傳導(dǎo),將預(yù)期進(jìn)一步的目標(biāo)推薦給該用戶。Mao等[4]通過記錄各個用戶使用共同標(biāo)簽的情況,建立一個帶有權(quán)重節(jié)點的網(wǎng)絡(luò),然后在標(biāo)簽-資源兩偶圖上執(zhí)行一個擴(kuò)散過程,將標(biāo)簽的權(quán)值轉(zhuǎn)換成推薦項的分?jǐn)?shù),進(jìn)行個性化推薦。Ma等[5]為了提高推薦的精確度,改進(jìn)了基于用戶的協(xié)同過濾方法,提出融合用戶標(biāo)簽與用戶關(guān)系網(wǎng)的方法。Li等[6]針對在線用戶構(gòu)建了一種新的LDA(latent Dirichlet allocation)模型,以學(xué)習(xí)用戶的動態(tài)興趣,并且結(jié)合LDA模型和增長Biterm主題模型(incremental biterm topic model,IBTM)設(shè)計了一種新的自動標(biāo)簽推薦方法。Rawashdeh等[7]為了提高標(biāo)簽推薦的準(zhǔn)確度,提出了基于用戶-標(biāo)簽-項目關(guān)系的鄰接矩陣,并結(jié)合卡茨模型(Katz model)構(gòu)建出一個關(guān)于用戶、標(biāo)簽、項目的卡茨矩陣。Mashal等[8]利用近鄰法(K-nearest neighbors,KNN)進(jìn)行標(biāo)簽推薦,KNN方法從文檔集合中選擇出與新文檔最相關(guān)的K個文檔,將這K個文檔標(biāo)簽推薦給新文檔,相似度越大的文檔,其標(biāo)簽推薦的位置越靠前。Belem等[9]提出了一種有監(jiān)督的主題模型,是針對主題模型LDA的一種改進(jìn),它增加了一個連續(xù)變量代表標(biāo)簽,并利用標(biāo)簽訓(xùn)練出最優(yōu)的參數(shù)。Si等[10]也是在LDA模型的基礎(chǔ)上,提出了主題模型Tag-LDA,此方法基于文檔內(nèi)容和標(biāo)簽聯(lián)合建模。
以上研究雖然在一定程度上提高了精確度,卻忽略了標(biāo)簽與標(biāo)簽之間的關(guān)系,并且沒能考慮到標(biāo)簽數(shù)據(jù)稀疏問題。在實際應(yīng)用中,用戶的標(biāo)簽數(shù)據(jù)往往會一直處于稀疏的狀態(tài),系統(tǒng)無法準(zhǔn)確捕捉其興趣偏好,從而影響了推薦的質(zhì)量。針對標(biāo)簽數(shù)據(jù)稀疏問題,提出一種基于重疊的時間窗口模型(based on overlapping time window model,OTWM)標(biāo)簽數(shù)據(jù)采集方法;此方法按照時間窗口順序去采集標(biāo)簽數(shù)據(jù),每兩個相鄰的時間窗口有重疊的時間區(qū)間,這使得重疊時間區(qū)間內(nèi)的標(biāo)簽重復(fù)利用,緩解了數(shù)據(jù)稀疏問題。為了提高標(biāo)簽推薦的精確度,提出了一種基于關(guān)聯(lián)規(guī)則的標(biāo)簽推薦方法(based on association rules tag recommendation,ATRecom)。首先,構(gòu)建一種基于重疊的時間窗口模型用來采集用戶的標(biāo)簽數(shù)據(jù);然后,對這些標(biāo)簽數(shù)據(jù)進(jìn)行挖掘分析,找到標(biāo)簽與標(biāo)簽之間的關(guān)系;最后,利用挖掘出來的關(guān)聯(lián)規(guī)則為用戶進(jìn)行標(biāo)簽推薦。
2 標(biāo)簽的關(guān)聯(lián)規(guī)則挖掘
2.1 關(guān)聯(lián)規(guī)則概念
關(guān)聯(lián)規(guī)則可反映一個事務(wù)與其他事務(wù)之間的關(guān)聯(lián)性[11]。若兩個或者多個事務(wù)之間存在關(guān)聯(lián)關(guān)系,那么就能通過已經(jīng)發(fā)生的事務(wù)預(yù)測與其關(guān)聯(lián)的事務(wù),例如廣為人知的啤酒與尿布案例。
關(guān)聯(lián)規(guī)則定義為形如X→Y的蘊涵式,描述了頻繁共現(xiàn)的事務(wù)X,Y同時出現(xiàn)的規(guī)律和模式,表示規(guī)則前件事務(wù)X和后件事務(wù)Y中的項目頻繁地同時出現(xiàn)。例如{tag1,tag2}→{tag3}的蘊涵式,描述了標(biāo)簽集{tag1,tag2}出現(xiàn)時,標(biāo)簽集{tag3}也很有可能出現(xiàn)。
關(guān)聯(lián)規(guī)則挖掘過程主要包含3個階段[12]:
第一階段是采集數(shù)據(jù)事務(wù)庫。
第二階段從數(shù)據(jù)事務(wù)庫發(fā)現(xiàn)頻繁項集集合。
第三階段利用挖掘獲得的頻繁項集集合,產(chǎn)生關(guān)聯(lián)規(guī)則(association rules)。
2.2 相關(guān)定義
定義1:時間窗口TW。
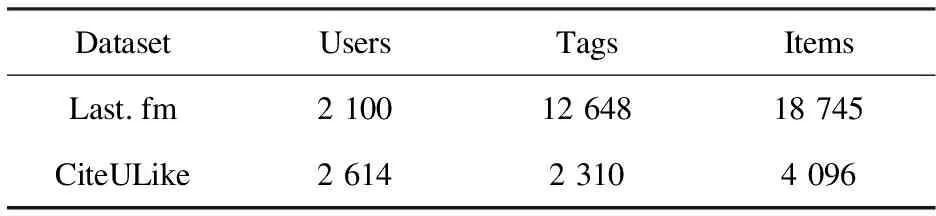
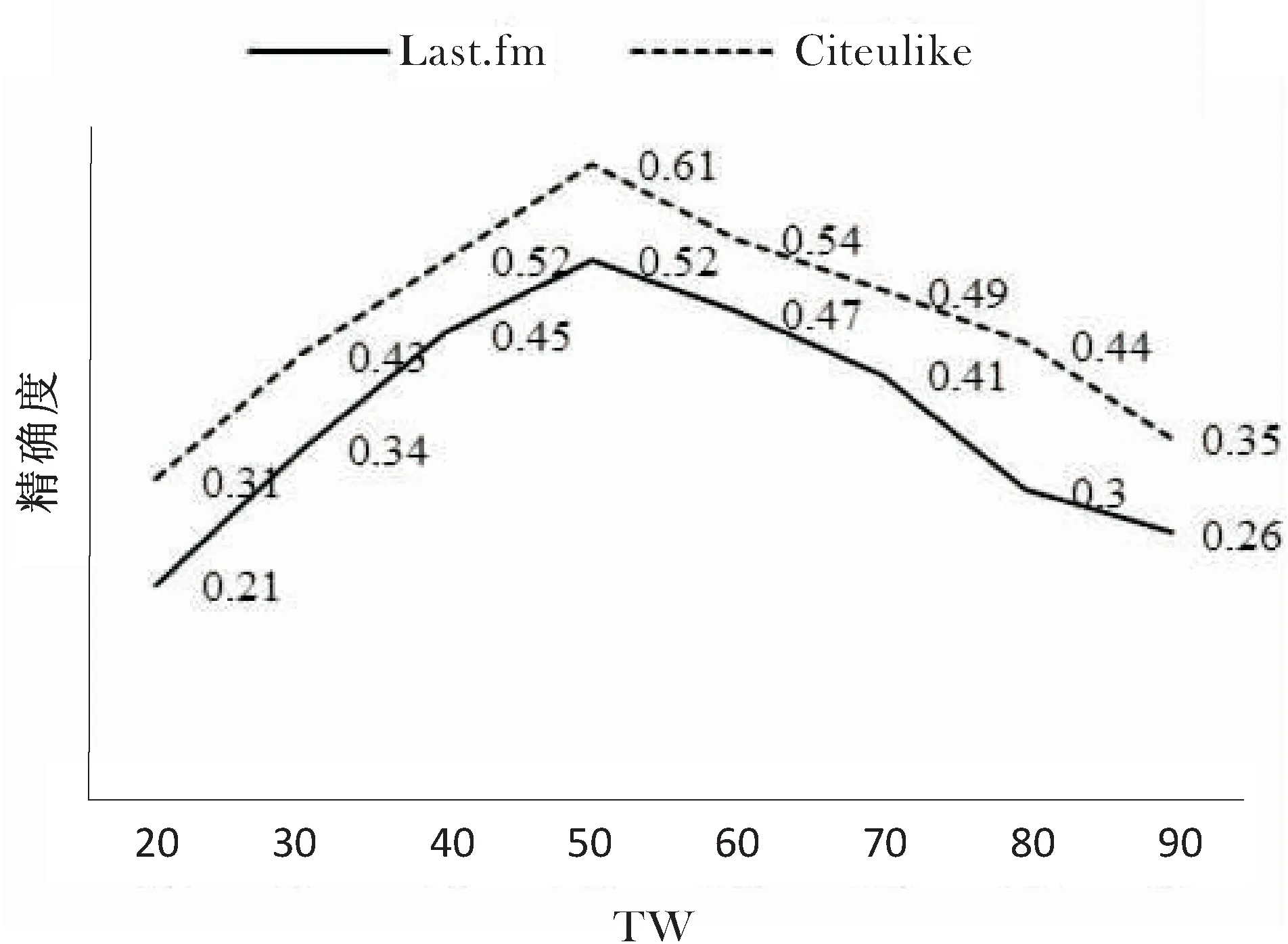
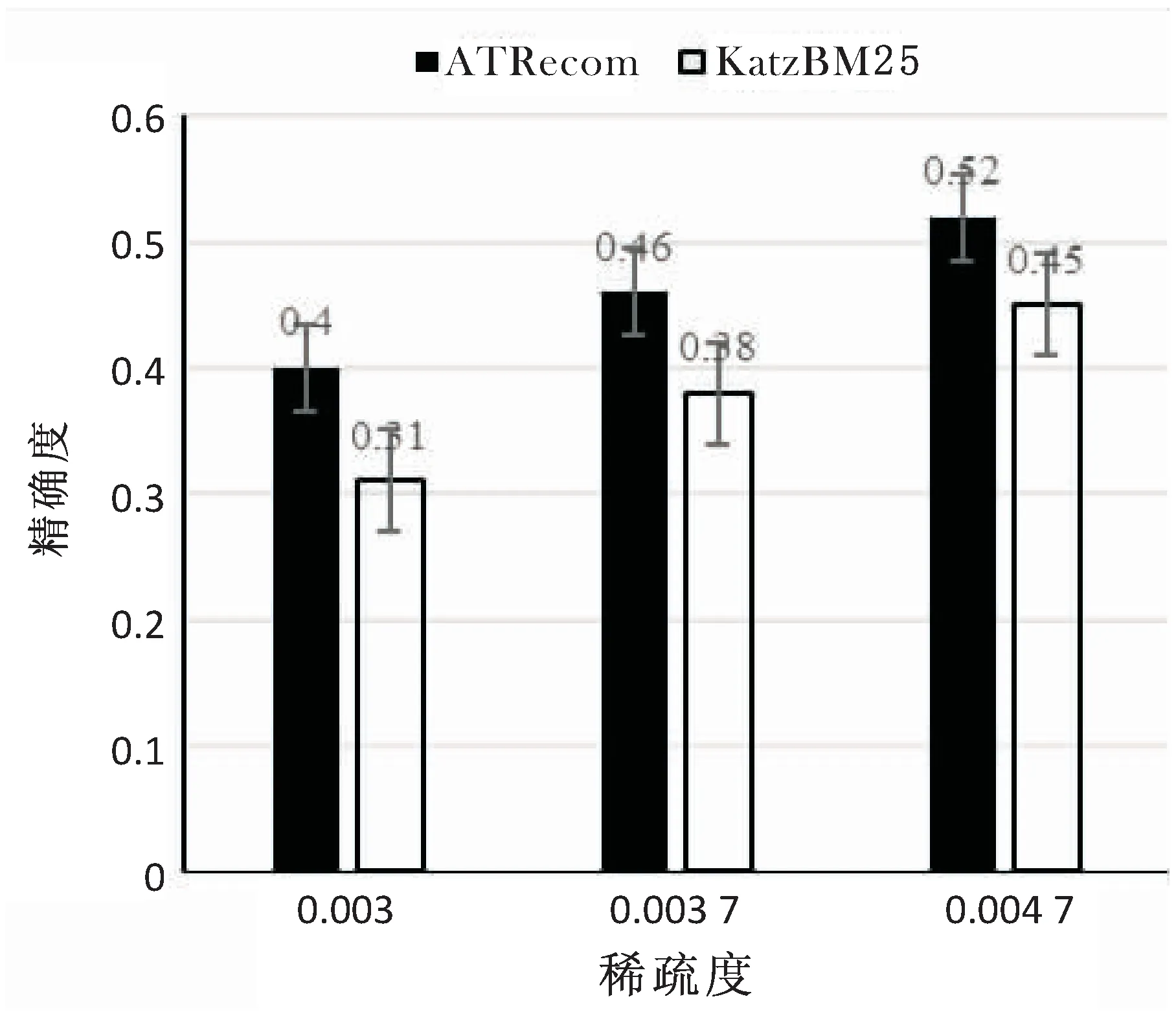
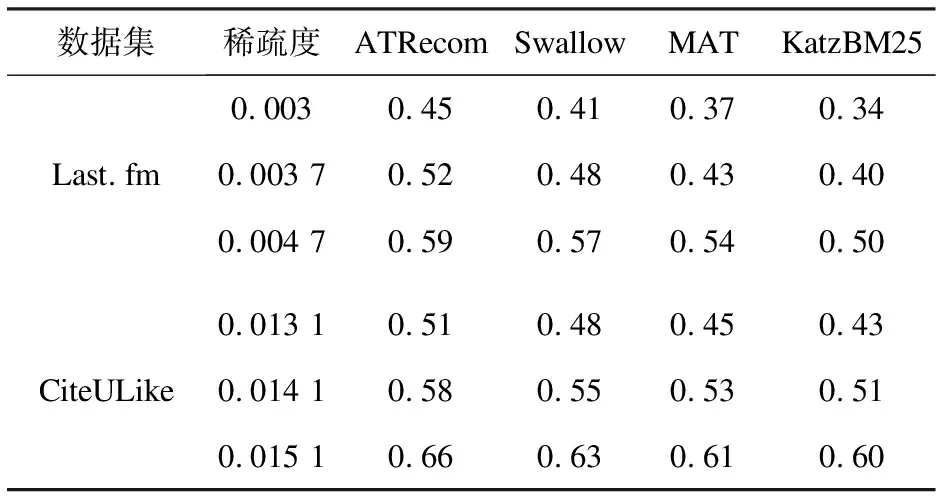
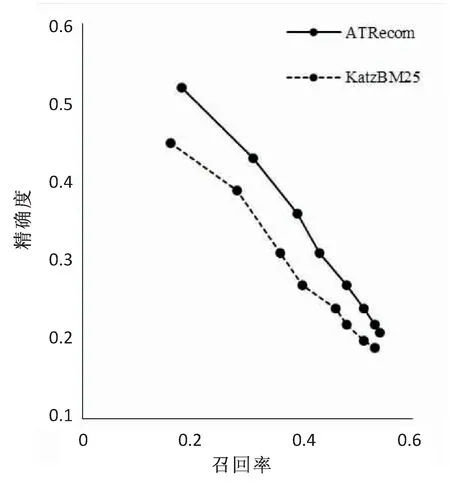
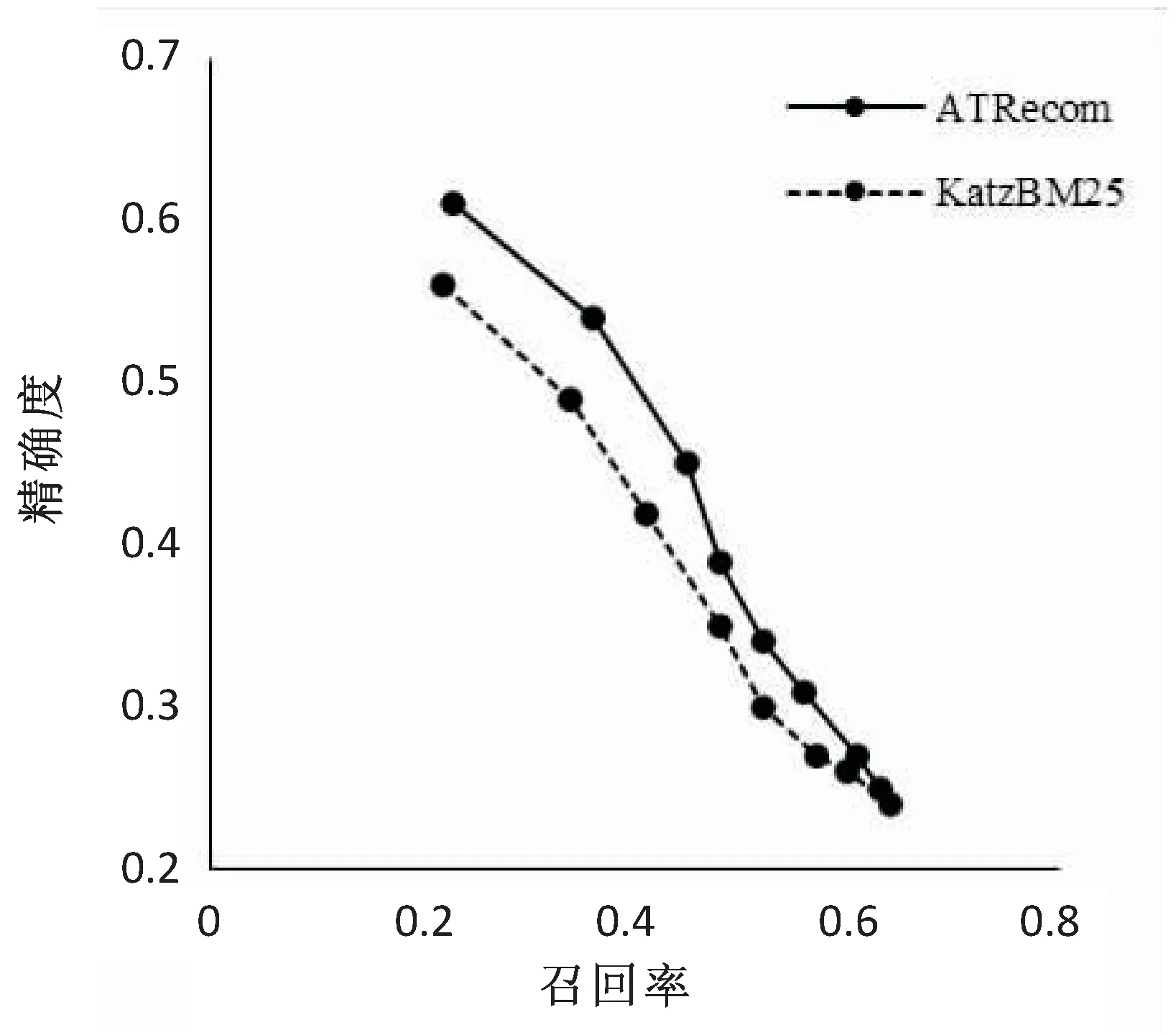
假設(shè)S={tag1, tag2, …, tagn}是一個在時間區(qū)域[TS,TE]內(nèi)出現(xiàn)的標(biāo)簽序列;Sw={tagw+1, tagw+2,… ,tagw+m}是一個在時間區(qū)域[ts,te]內(nèi)的標(biāo)簽序列,即Sw?S,其中ts>TS,te 定義2:滑動步長ST。 假設(shè)在兩個相鄰時間窗TWi= [ti,tj]和TWi+1= [ti+1,tj+1]中,ti 定義3:標(biāo)簽事務(wù)和標(biāo)簽事務(wù)庫。 L(uid,TW) = {tag1,tag2,…, tagh}是用戶uid在時間窗口TW內(nèi)使用過的標(biāo)簽序列,它定義為一條標(biāo)簽事務(wù)(tag transaction)。多條標(biāo)簽事務(wù)組成的集合就是標(biāo)簽事務(wù)庫T。 定義4:頻繁共現(xiàn)標(biāo)簽集。 設(shè)P為一個由多個標(biāo)簽組成的集合,P={tag1,tag2,…,tagk},P中所有標(biāo)簽在標(biāo)簽事務(wù)集合T中同時出現(xiàn)的次數(shù)為sup(P),稱為P的支持度。給定一個最支持度minSup,當(dāng)sup(P)> minSup時,稱P為頻繁共現(xiàn)標(biāo)簽集,且頻繁共現(xiàn)標(biāo)簽集有一個特征,如果P是頻繁共現(xiàn)的,那么P的子集也是頻繁共現(xiàn)的。 圖1是基于關(guān)聯(lián)規(guī)則的標(biāo)簽推薦(ATRecom)過程。 圖1 基于關(guān)聯(lián)規(guī)則的標(biāo)簽推薦過程 系統(tǒng)在采集用戶的標(biāo)簽數(shù)據(jù)時,首先在第一個時間窗口TW1內(nèi)采集每個用戶所使的標(biāo)簽序列L(uid,TW1),即用戶標(biāo)識為uid的標(biāo)簽事務(wù),并且將這條標(biāo)簽事務(wù)添加到標(biāo)簽事務(wù)庫T中;當(dāng)采集完該窗口內(nèi)所有用戶的標(biāo)簽數(shù)據(jù)后,時間窗口向前滑動ST步長,到達(dá)第二時間窗口TW2,同樣采集第二時間窗口TW2內(nèi)所有用戶的標(biāo)簽數(shù)據(jù),針對每個用戶都會生成一條關(guān)于該用戶的標(biāo)簽事務(wù),添加到標(biāo)簽數(shù)據(jù)庫T中。依次類推,OTWM模型會把所有時間窗口內(nèi)的用戶標(biāo)簽數(shù)據(jù)采集完成,得到標(biāo)簽事務(wù)庫T,標(biāo)簽數(shù)據(jù)采集完成。其過程如下: 步驟1:定義時間窗口TW的大小t,滑動步長ST。 步驟2:采集當(dāng)前時間窗口TWi(代表第i個時間窗口)內(nèi)的每個用戶對應(yīng)的標(biāo)簽事務(wù),直到所有用戶在該窗口內(nèi)的標(biāo)簽數(shù)據(jù)采集完畢,得到該窗口內(nèi)所有用戶的標(biāo)簽事務(wù),加入標(biāo)簽事務(wù)庫T中。 步驟3:判斷當(dāng)前窗口TWi是否為最后一個時間窗口。 步驟4:如果當(dāng)前窗口不是最后一個時間窗口,滑動時間窗口ST步長,到達(dá)下一個時間窗口TWi+1,重復(fù)步驟2,采集此窗口內(nèi)每個用戶的標(biāo)簽數(shù)據(jù),生成關(guān)于該用戶的標(biāo)簽事務(wù),將其加入標(biāo)簽事務(wù)庫T中;如果當(dāng)前窗口是最后一個時間窗口,那么用戶標(biāo)簽數(shù)據(jù)采集完畢。得到最終的標(biāo)簽事務(wù)庫T。 頻繁項集合挖掘的方法有許多,但是實際應(yīng)用中常見的有兩種:(1)Apriori及其改進(jìn)算法,其基本思想是[13]由k項頻繁項集產(chǎn)生k+1項頻繁項集,直到滿足條件的頻繁項集發(fā)現(xiàn)為止。Apriori算法通過不斷地構(gòu)造候選集、篩選候選集挖掘出頻繁項集,需要多次掃描原始數(shù)據(jù),當(dāng)原始數(shù)據(jù)較大時,磁盤I/O次數(shù)太多,效率比較低下。(2)FP-Growth算法處理數(shù)據(jù)的效率比較高,其基本思想是將原始數(shù)據(jù)壓縮到一個FP-Tree,在該樹上進(jìn)行頻繁項集的挖掘,只需要掃描兩邊數(shù)據(jù)庫[14]。 ATRecom采用FP-Growth算法。利用FP-Growth算法對標(biāo)簽事務(wù)庫T[15]進(jìn)行頻繁項[16]挖掘,得到頻繁共現(xiàn)的標(biāo)簽集集合,記F={P1,P2,…,Pm},其中Pi是頻繁共現(xiàn)的標(biāo)簽組成的集合,即頻繁共現(xiàn)標(biāo)簽集。 對上述得到的頻繁共現(xiàn)的標(biāo)簽集集合F進(jìn)行挖掘,找出標(biāo)簽之間的關(guān)聯(lián)規(guī)則庫R。其過程主要分為以下幾步: 步驟1:讀取頻繁共現(xiàn)標(biāo)簽集集合F,其中F={F1,F2,…,Fi,…,Fn}。 步驟2:對頻繁共現(xiàn)標(biāo)簽集集合F中每個頻繁共現(xiàn)標(biāo)簽集Fi,產(chǎn)生其所有非空子集,并存放在集合Sub中,其中Sub={sub1,sub2,sub3…}。 步驟3:對于非空子集集合Sub中的每個元素Subi都計算其在F中的支持度;如果為最小支持度minSup,則認(rèn)為關(guān)聯(lián)規(guī)則“subi→(Fi-subi)”是可靠的,并且保存到關(guān)聯(lián)規(guī)則庫R中。 針對要進(jìn)行推薦的目標(biāo)用戶uid收集其標(biāo)簽事務(wù),得到關(guān)于該用戶的標(biāo)簽事務(wù)庫Tu,然后利用上一小節(jié)中挖掘獲得的標(biāo)簽之間的關(guān)聯(lián)規(guī)則庫R尋找用戶uid潛在感興趣的標(biāo)簽列表。其過程主要分為以下幾步: (1)收集待推薦用戶uid使用過的所有標(biāo)簽,得到關(guān)于該用戶標(biāo)簽集合tuid= {tag(uid,1), tag(uid,2),…, tag(uid,k)}; (2)依次讀取上述標(biāo)簽關(guān)聯(lián)規(guī)則庫R中形如X→Y的關(guān)聯(lián)規(guī)則,并且判斷該規(guī)則中的先導(dǎo)標(biāo)簽集X是否存在于關(guān)于該用戶的標(biāo)簽集合tuid中; (3)當(dāng)判斷為存在時,即X?tuid,并且該條規(guī)則X→Y中先導(dǎo)標(biāo)簽集X關(guān)聯(lián)的后繼標(biāo)簽集Y?tuid,將標(biāo)簽集Y推薦給對應(yīng)用戶。 實驗選取了在標(biāo)簽推薦系統(tǒng)中常用的兩個數(shù)據(jù)集,分別是Last.fm[17]和CiteULike[18],它們的數(shù)據(jù)特征如表1所示。Last.fm是一家著名的音樂網(wǎng)站,它通過分析用戶的聽歌行為來預(yù)測用戶對音樂的興趣,數(shù)據(jù)集包含用戶2 100個,標(biāo)簽12 648個,項目(歌手)18 745個,用戶給項目貼標(biāo)簽的信息186 479條。CiteULike是一個著名的論文書簽網(wǎng)站,它允許研究人員提交或者收藏他們感興趣的論文,給論文打標(biāo)簽,從而幫助用戶更好地發(fā)現(xiàn)和自己研究領(lǐng)域相關(guān)的優(yōu)秀論文,數(shù)據(jù)集包含用戶2 614個,項目4 096個,標(biāo)簽2 310個,用戶給資源打標(biāo)簽信息161 395條。 表1 數(shù)據(jù)特征 評估標(biāo)簽推薦系統(tǒng)的性能度量主要采用精確度(precision)和召回率(recall)[19]。 實驗采用了基于關(guān)聯(lián)規(guī)則的標(biāo)簽推薦和基于卡茨(Katz)模型的標(biāo)簽推薦[7]兩種方法。其中,基于Katz模型的標(biāo)簽推薦方法主要根據(jù)用戶-標(biāo)簽-項目的關(guān)系構(gòu)建出一個關(guān)于用戶、項目、標(biāo)簽的三元鄰接矩陣,通過最佳匹配文本相似度公式(Best Match25,BM25)計算出這個鄰接矩陣上的各個權(quán)值,然后結(jié)合Katz模型,對該矩陣進(jìn)行矩陣處理,得到Katz矩陣。最后根據(jù)Katz矩陣計算用戶、項目、標(biāo)簽的Katz評分,從而進(jìn)行推薦。ATRecom是利用標(biāo)簽與標(biāo)簽之間的關(guān)系進(jìn)行推薦,而KatzBM25則是根據(jù)用戶、標(biāo)簽、項目之間的關(guān)系。 利用ATRecom方法的標(biāo)簽推薦涉及到時間窗口TW這個不確定參數(shù)。為了找出最為合適的時間窗口值TW,驗證了TW取值在20到90之間的均勻分布的實驗結(jié)果。圖2顯示了時間窗口TW的變化對標(biāo)簽推薦結(jié)果精確度的影響,當(dāng)時間窗口TW的取值為50時,推薦的精確度是最高的。 圖2 時間窗口對精確度的影響 數(shù)據(jù)稀疏度是影響推薦精確度重要因素。數(shù)據(jù)集Last.fm和CiteULike的數(shù)據(jù)稀疏度計算如下: 其中,sparsity是數(shù)據(jù)的稀疏度;users是用戶個數(shù);items是項目個數(shù);tagassinments是用戶給項目打標(biāo)簽的記錄條數(shù)。 為了觀察數(shù)據(jù)稀疏度對ATRecom、KatzBM25方法推薦精確度的影響,驗證了這兩種方法在Last.fm、CiteULike數(shù)據(jù)集,3種不同稀疏度下的實驗結(jié)果。圖3、表2顯示了各數(shù)據(jù)集在時間窗口TW為50時,在不同的稀疏度下獲得的實驗結(jié)果。 (a)Last.fm 數(shù)據(jù)集稀疏度ATRecomSwallowMATKatzBM25Last.fm0.0030.450.410.370.340.003 70.520.480.430.400.004 70.590.570.540.50CiteULike0.013 10.510.480.450.430.014 10.580.550.530.510.015 10.660.630.610.60 結(jié)果表明,ATRecom獲得的精確度比KatzBM25高,并且當(dāng)數(shù)據(jù)的稀疏程度發(fā)生變化時,ATRecom的精確度變化幅度低于KatzBM25。這表明ATRecom推薦方法在一定程度上緩解了數(shù)據(jù)稀疏造成的推薦不準(zhǔn)確的問題,其主要原因是在數(shù)據(jù)采集過程中,ATRecom采用了有重疊的時間窗口,這使稀疏的標(biāo)簽數(shù)據(jù)可以二次利用。 (a)Last.fm (b)CiteULike 圖4顯示了ATRecom和KatzBM25在Last.fm和CiteULike兩種數(shù)據(jù)集推薦的準(zhǔn)確度和召回率的關(guān)系,在此,Last.fm數(shù)據(jù)集的稀疏度為0.004 7,CiteULike數(shù)據(jù)集的稀疏度為0.015 1,ATRecom中的時間窗口TW為50。可知,推薦的精確度越高召回率就會越低。但是ATRecom推薦結(jié)果精確度、召回率都明顯高于KatzBM25。 基于關(guān)聯(lián)規(guī)則的標(biāo)簽推薦方法不同于傳統(tǒng)的標(biāo)簽推薦,該方法中采用基于重疊的時間窗口模型的標(biāo)簽數(shù)據(jù)采集方法能夠使重疊時間區(qū)間內(nèi)的標(biāo)簽數(shù)據(jù)多次合理利用,緩解了數(shù)據(jù)稀疏問題;同時避免了當(dāng)標(biāo)簽信息的時間跨度過大時,本來無關(guān)的標(biāo)簽之間的相互影響造成的規(guī)則挖掘的不準(zhǔn)確性。此外,這種標(biāo)簽推薦方法也考慮到了標(biāo)簽-標(biāo)簽的關(guān)系,而不在拘泥于傳統(tǒng)的用戶-標(biāo)簽,資源-標(biāo)簽這種關(guān)系。2.3 基于OTWM的數(shù)據(jù)采集
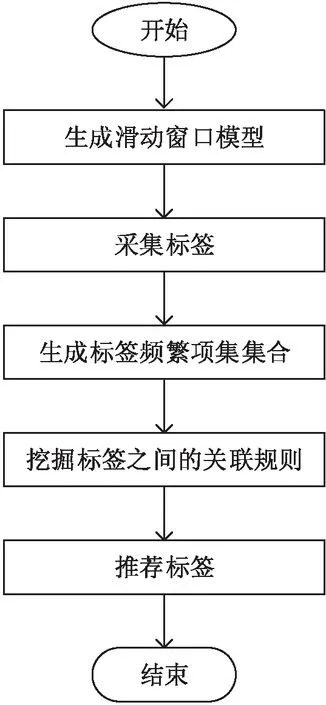
2.4 標(biāo)簽關(guān)聯(lián)規(guī)則挖掘
2.5 標(biāo)簽推薦
3 實驗與結(jié)果分析
3.1 數(shù)據(jù)集與評估標(biāo)準(zhǔn)
3.2 實驗結(jié)果
4 結(jié)束語
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42當(dāng)代陜西(2021年17期)2021-11-06 03:21:36數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14山東煤炭科技(2020年1期)2020-03-06 06:43:28學(xué)苑創(chuàng)造·A版(2018年11期)2018-02-01 06:29:20Coco薇(2017年11期)2018-01-03 20:59:57讀者(2017年5期)2017-02-15 18:04:18暨南學(xué)報(哲學(xué)社會科學(xué)版)(2016年9期)2017-01-15 13:52:02高考金刊·理科版(2012年3期)2012-01-01 00:00:00當(dāng)代修辭學(xué)(2011年2期)2011-01-23 06:39:12
