陶瓷行業博客文本矩陣的建立方法
2018-12-05 09:08:50胡小麗
電腦與電信 2018年9期
胡小麗
(景德鎮陶瓷大學信息工程學院,江西 景德鎮 333403)
1 引言
在有著幾千年歷史且名揚海外的中國陶瓷行業,網絡中有大量關于陶瓷藝術、陶瓷文獻、陶瓷企業、陶瓷產品、陶瓷技術、陶瓷原料、燃料以及行業資訊等陶瓷方面的有價值的博客信息資源。為了提高陶瓷行業聚類的精度,陶瓷信息詞典的建立與博客文本矩陣建立方法尤為重要,對提取陶瓷行業博客文本特征有著重大意義。
2 陶瓷信息詞典建立
本文從各知名陶瓷網站中收集信息,進行預處理,再進行人工分類,創建了以下11個類別,分別是:陶瓷藝術、日用陶瓷、建筑陶瓷、衛浴陶瓷、功能陶瓷、工業陶瓷、陶瓷燃料、陶瓷原料、陶瓷商貿、陶瓷文獻和陶瓷技術。收集的信息主要來自全國陶瓷行業排名前十位的陶瓷網站服務商,如中國陶瓷信息資源網http://www.ccisn.com.cn、中國陶瓷網http://www.taoci163.com/、中華陶瓷網 http://www.chinaceram.cn/、中陶網http://www.ccenn.com/等等。這些網站相對來說是比較權威的,其信息內容比較全面,信息來源也都是可靠的,能夠很好地滿足創建陶瓷信息語料庫的要求。創建的陶瓷信息詞典以文本格式保存到相應的文件中。
3 陶瓷信息詞獲取方法
陶瓷行業的博客文本的特征詞與陶瓷信息密切相關。提取陶瓷信息的方法有多種,例如,基于陶瓷信息詞典的方法、基于語料庫的方法等等。本文選用的是基于陶瓷信息詞典的方法。
提取一篇文章中的陶瓷信息詞的方法:先為選用的陶瓷信息詞典建立一個表,然后通過查表的方式判斷進行過分詞處理的文章(詞串)中的詞是不是陶瓷信息詞。如果能在表中查找到,則是陶瓷信息詞,將其輸出;否則,不是陶瓷信息詞,判斷下一個。這樣,最后得到一個陶瓷信息詞串(該串可以是空串)。考慮到陶瓷信息詞表的長度較長,加之需要頻繁查找,為降低開銷,我們采用了索引技術。先對無序的陶瓷信息詞語表排序,按字長由短到長,然后對排好序的陶瓷信息詞表,根據詞的字長建立了一個索引表。因此,查找陶瓷信息詞時,可以先查索引表,然后查陶瓷信息詞表。具體算法如下所示:
提取陶瓷信息詞的算法:
輸入:陶瓷信息詞典CIC,詞串S1
輸出:陶瓷信息詞串S2
方法:
1)創建一個表存放陶瓷信息詞典CIC;
2)將CIC按陶瓷信息詞字長以升序排列;
3)根據詞的字長在CIC上創建一個方便查找的索引表Index;
4)Loop1
5)判斷S1是否為空,如果是,執行第(13)步,否則,繼續;
6)取S1中的第一個單詞視為當前單詞W;
7)Loop2
8)判斷W是否標點符號,如否,繼續執行判斷;否則,讀串S1的下一個單詞作為當前單詞W,并執行第(4)步;
9)計算W的字長;
10)在索引表Index中查詢單詞W,如果查找到,繼續執行;否則,讀串S1的下一個單詞視為當前單詞W,并執行第(4)步;
11)在CIC中查詢單詞W,如果查找到,執行第(8)步;否則,讀串S1的下一個單詞視為當前單詞W,并執行第(4)步;
12)W進入串S2,并從S1中去掉W,執行第(4)步;
13)輸出詞串S2。
在具體實現程序過程中,我們可以隊列的形式存儲詞串S1和S2,采用二維數組存儲陶瓷信息詞。
4 陶瓷博客文本矩陣建立
從Web獲取到的博客文本經預處理后仍然屬于半結構化數據,需要將數據結構化,即轉換為數據庫中的結構化數據形式,才能用于后續的聚類分析處理。從Web頁面中獲取的文本必須表示成計算機可讀取的形式,常用的表示形式:向量空間、布爾模型、基于圖的文本表示、概率模型和潛在語意索引等。本文采用向量空間模型的建立方法。
向量空間模型是將一篇文檔表示成一個特征值向量。同樣一個文檔數據集合中所有不重復出現的詞(除了停用詞)組成該向量的各分量,每一個不同的特征項對應向量的一個維度,維數和詞的數目相同。也就是說,在向量空間模型中,每一個文本都被轉換為一個n維的向量,n為特征項的個數,形式為V(T1,W1;T2,W2;…;TV,WV),Tk為特征項,Wk為特征項權重。向量中的Wk的值表示Tk在此文檔中的中的權值,即Tk對于描述此文檔所起作用的程度。Wk越大,則Tk對于描述V(T1,W1;T2,W2;…;TV,WV)也越重要;Wk越小,Tk就越不能反映V(T1,W1;T2,W2;…;TV,WV)的內容。
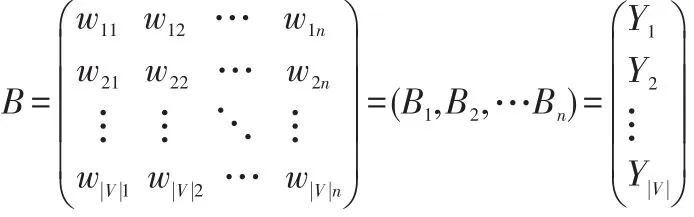
本文選取的文本表示方法是基于向量空間模型的方法,該方法是將文本映射成為一個特征向量,把博客看作一個文本,每個博客都有對應的特征項(也叫索引詞),V={T1,T2,…,TV}表示相關博客的一組特征項,每一個Tk都是一個索引詞,集合V稱為詞匯表,v表示它的大小,代表V中所包含的特征項個數,對于博客Bj中的每個特征項Tk,都有一個權值Wkj,這樣對于每個博客Bj都可以被表示成一個詞向量Wj={W1j,W2j,…,Wvj},這個詞向量就是該博客的特征向量。從而對于一個有M個博客的博客集,可以構造相應的文本特征項矩陣:
5 結束語
基于向量空間模型的矩陣建立方法是目前較為常用的文本表示方法。該方法較布爾模型包含了更多的信息,對陶瓷行業博客文本的聚類研究非常有幫助。
猜你喜歡
閱讀(快樂英語高年級)(2020年8期)2020-01-08 02:21:16
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
智慧少年·故事叮當(2018年11期)2018-05-14 11:48:18
中華手工(2017年2期)2017-06-06 23:00:31
小學教學參考(2015年20期)2016-01-15 08:44:38
中外會展(2014年4期)2014-11-27 07:46:46
語文知識(2014年1期)2014-02-28 21:59:13
七彩語文·低年級(2011年19期)2011-04-12 00:00:00
海外英語(2006年8期)2006-09-28 08:49:00
