基于回歸模型的公司營銷活動用戶群挖掘
2018-11-30 01:47:40葉敏
商情 2018年49期
葉敏


【摘要】某銷售公司想通過用戶的歷史數據,預剛下次營銷活動最有可能參與營銷活動的人群。本文通過構建Logistic模型,基于用戶的歷史購買數據和用戶基本信息,使用R語言進行計算,預瀏用戶是否會參與營銷活動。
【關鍵詞】Logistic模型 營銷活動 R語言
一、引言
某零售公司目前有約3000萬的活躍用戶,市場部門有30萬美元的預算,其希望挖掘出最有可能在30天內購買該公司產品的用戶群,本文討論用邏輯回歸建模對產品的購買預測,得到優化模型,并進行了模型評估。
二、基于Logisstic回歸方法的營銷用戶群的挖掘建模
(一)Logistic回歸模型原理介紹
Logistic回歸模型是研究因變量非連續型變量情況的分析模型。其中,解決這個問題的核心方法稱為極大似然估計法:
(1)引入參數e。
(2)引入Logisic函數的激活函數,也叫做越階函數,例如:sogfllod激活函數hθ(x)=g(θTx)=1/(1+e-θTx)
(3)計算P(y=1|x:θ)和P(y=0|x:θ),一般來說激活函數計算得到p=1和。兩類,需要計算他們的聯合概率函數P(y|x:θ)。
(4)最大似然函數,求出合適的參數8。
(5)計算hθ(X),根據該值對樣本進行分類。
(二)構建Logistic模型
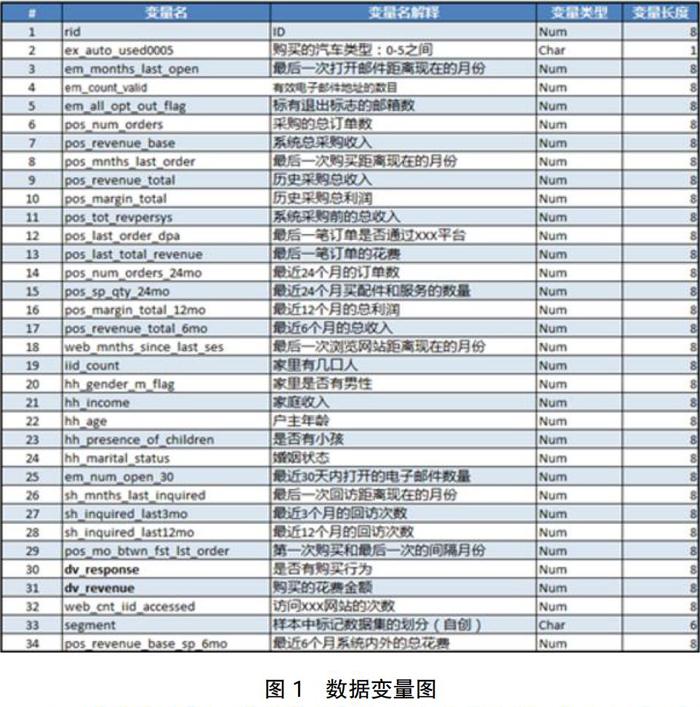
(1)候選變量。候選變量包括用戶的基本情況和一些購物信息。本項目一共包括如下26個自變量和1個因變量(是否有購買行為)。如下圖1所示:
(2)相關性分析。相關性分析包括自變量之間,和自變量和因變量之間的相關性分析。通常而言,自變量與因變量越強,說明該自變量對因變量越重要,而自變量之間的相關性越強,改善兩者之間的共線性強,多重共線性會影響模型的準確度,需要優化模型的變量。
(3)初步建模,變量篩選。該項目的特征值有26個,根據前面的相關性分析和數據缺失情況,去掉11個特質變量(變量與被解釋變量相關程度非常低和缺失率過高),然后用逐步回歸法自動篩選剩下的變量,選出的特征變量先進行顯著性檢驗,再使用VIF進行多重共線性分析,一般來說VIF值小于2,另外計算R^2的值,如R^2<0.5,說明這些變量解釋模型不夠,需要引入更多變量。最終篩選的變量如下:
(4)模型評估。該模型采用ROC Curce圖和AUC值進行模型評估。下圖2是ROC Curce圖:
從圖中可以看到該ROC曲線是往左上角凸的,而AUC值(ROC曲線下方的面積)為0.7613,說明該模型的預測結果的分類效果是不錯的。
三、結論及建議
本文通過構建Logistic模型,基于用戶的歷史購買數據和用戶基本信息,使用R語言進行計算分析,預測用戶是否會參與營銷活動。先進行變量之間的相關性分析,然后初步建模,使用逐步回歸法,篩選變量,最終得到符合模型要求的變量,最后進行模型評估。Logistic模型的優點在于可解釋性強,但是相對于其他機器學習模型來說,準確率不是很高。該項目的主要是為了得到最有可能在30天內購買該公司產品的用戶群,我認為分析完是否購買該產生的用戶后,可以用其他預測模型判斷購買用戶可能會消費多少金額,這樣可以得到更加優質的用戶群。
