基于多目標遺傳算法的云數據安全存儲方法
2018-11-22 12:02:34何利文唐澄澄侯小宇
計算機技術與發展 2018年11期
吳 超,何利文,唐澄澄,侯小宇,周 睿
(南京郵電大學,江蘇 南京 210003)
1 概 述
隨著物聯網的出現,數據的獲取方式變得多樣化,只要是接入網絡的事物,通過傳感器、控制器等硬件就能收集人類或者接入網絡的任意事物的定位數據、反饋數據、個性數據等[1]。IDC Digital Universe study在2011年指出,未來全世界的數據每兩年增加一倍,2020年的數據總量將達到當前的50倍[2]。由于物聯網技術諸如無人駕駛、智能交通、虛擬現實對于網絡質量的要求相當苛刻,目前還處于相對不成熟的時期。未來隨著5G網絡的商用普及之后,5G網絡的高速度、低功耗、低時延、多互聯等特點將支撐物聯網進入井噴式的發展[3]。屆時,物聯網所獲取的巨量數據將會給數據存儲帶來巨大的壓力。目前來說,云存儲系統是最成熟的大數據存儲模型。
云存儲將大量不同類型的存儲設備通過軟件集合起來協同工作,共同對外提供數據存儲服務。云存儲服務對傳統存儲技術在數據安全性、可靠性、易管理性等方面提出了新的挑戰[4]。云存儲的一個核心問題就是數據放置。對用戶來說,云存儲檢索速度以及對于隱私數據的保護是評判云存儲系統質量的兩個重要因素[5]。旨在以最小的時間和空間代價為目的,文中提出一種數據放置方法來解決檢索速度和數據安全問題。在云存儲中,分布式的存儲方式需要考慮到網絡拓撲中一些實際問題,例如不同節點的不同容量、節點間的寬帶、鏈路的長短等,因此數據放置問題需要考慮大量的參數去得到一個最優的數據放置方法。
當前,對于信息安全的研究主要集中在應對網絡層攻擊和對數據本身進行安全性處理兩個方面[6]。對于數據放置安全性能的研究主要集中在數據加密技術。Liu J K等在對云存儲系統的數據安全保護機制[7]的研究中提出了一種方法,即服務端僅提供加密數據而無法解密數據,用戶則需要兩個媒介才能解密文件,一個是解密密鑰,另外一個是連接電腦的個人安全設備,只有同時具有兩項才能解密。余琦等[8]在基于HDFS分布式存儲的安全技術研究中提出了一種復合型加密方法,首先對存入HDFS的文件進行AES加密,然后再用RSA算法保障AES密鑰安全。而一些云存儲供應商比如Amazon S3和Google Cloud Platform提供了服務器端加密服務[9],根據安全級別用不同長度的密鑰加密用戶數據。薛矛等[10]在云存儲系統之上添加一層安全系統架構Corslet,應用安全證書來提供端到端的數據私密性保護、完整性保護以及訪問權限控制等功能。綜上,對于加密算法或者安全架構的應用無疑在數據檢索方面增加了計算的步驟,從而加大了時間開銷。
而對于云存儲系統的檢索優化也進行了大量研究。袁野等[11]在其云環境下的虛擬機放置策略中,采取WFPSO算法優化節點部署策略,解決了復雜網絡拓撲中的網絡通信時延問題。Boru D等[12]在云系統數據中心復制算法的節能優化研究中,著力解決了云系統能耗問題,從而降低了I/O帶寬負荷以及計算中的延遲。而在Su M等[13]的研究中,提出了一種北斗七星模型,將數據放置問題定義為一個最優化的非線性規劃模型,在這一模型中,以量化的因素建立了不等式約束的目標函數,測量抽象空間的歐幾里得距離,從而得到最優化的檢索結果。然而,以上研究均未考慮云系統的安全性問題。
對于數據安全和檢索優化的研究也相對成熟。黃永峰等[14]在云存儲加密及其檢索技術中提出了基于全同態加密的檢索方法,采用信息檢索中的向量空間模型,計算檢索出的文檔與待查詢信息之間的相關度,對檢索詞詞頻和倒排文檔頻率進行統計,然后采用全同態方法對文檔進行加密并建立索引方法,檢索后將加密文檔與索引項密文一起上傳到服務器端。在Tu M等[15]提出的安全數據的最優化放置方法中,也解決了優化檢索和數據安全的問題。但以上研究仍然采用加密的方式保護數據,從而存在額外的開銷。Kang S等[16]在IEEE網絡會議中提出了一種全新的云存儲數據放置策略。在不使用加密的方式保護數據的前提下優化了檢索速度。其思想是將隱私文件拆分為多個存儲,而不同的數據塊存放在不同的節點中,并且這些節點不會直接連接,保證在某一節點被入侵的情況下不會得到整個文件的有效信息,并且攻擊者無法猜出剩下的數據塊在哪一位置。其實現是將數據放置問題作為一個最小化檢索時間的線性規劃模型,并由節點的容量、節點間的帶寬以及節點間的距離作為約束條件,以達到在保證數據安全的同時得到一個檢索最優解。但其在算法上由兩步構成,先用T-coloring算法選出符合安全需求的節點集,再對最短路徑求解。這一方法在較復雜的網絡拓撲中效率較低。
文中提出的方法在不使用數據加密的前提下解決了數據的安全需求和檢索效率問題。并且在仿真試驗中與傳統的數據放置方法進行了對比。
2 云存儲安全放置方法
2.1 系統模型
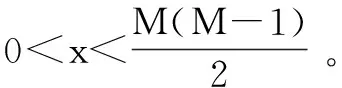

由于該模型中數據是采用分布式的方式將原始數據切分為多個數據塊存放在不同的數據節點中,當系統的某個或者某些數據節點被惡意攻擊以后,黑客無法猜出整體數據中所有的敏感信息。因此,對于惡意攻擊者而言,單個數據節點的敏感信息是沒有具體意義的,除非絕大部分包含有敏感信息的數據塊被存放在了鏈路關系比較密切的幾個數據節點當中。例如,數據節點被存放在了相鄰的數據節點當中,黑客可以很容易地通過逐項遍歷的方式檢索到其他的敏感信息。另一方面,如果為了保證數據的安全性,將切分后的數據塊放置得過于偏遠,會增加用戶正常的數據檢索時間。文中要解決的問題便是在保證即使在某個單一數據節點被黑客攻擊的前提下,也無法猜測出其他數據節點的具體位置。并且在此基礎上需要滿足最小化數據的檢索時間。
保障數據存放安全的前提下最小化數據檢索時間,首先是要保障所存儲數據的安全性。因此,引入一種分布式相關性來定義系統的安全水平。具體為當原始數據被切分成多個數據塊放置在不同的數據節點后,各存放有數據塊的數據節點中可能會包含原始數據中的部分敏感信息。此時,存放在各數據節點中的數據塊之間可能存在有相關度比較高的特征。
可以根據數據節點中數據含有的特征信息來描述相關數據節點之間的相關性。文中定義兩個數據節點Si和Sj之間的相關性為其Pearson相關系數[17]:
(1)
其中,cov(DiDj)表示數據節點Si和Sj中存放的數據塊Di和Dj的協方差。
根據概率論的相關理論可以得到[18]:
ρij=
(2)
其中,E[X]表示數據序列X的期望;0≤|ρij|≤1。當ρij>0時,表示數據塊Di和Dj正相關,當ρij<0時,表示數據塊Di和Dj負相關,并且|ρij|的值越接近于1時,數據塊Di和Dj之間的相關性越大,|ρij|的值越接近于0,數據塊Di和Dj之間的相關性越小。從數據存儲的角度來說,為保證數據存儲的安全,當數據塊Di和Dj之間的相關性越大時,如果兩個數據塊存放在了兩個邏輯距離比較近的數據節點中,若其中一個數據節點被惡意攻擊后,黑客獲取另外一個數據節點中的數據塊信息的概率將會大大增加。因此,在這種情況下,設計數據的放置策略時應該盡量考慮將兩個相關性較高的數據塊存放在邏輯距離較遠的兩個數據節點當中。由此,可以定義系統中數據節點Si和Sj之間的安全水平為:

(3)
其中,Dij為數據節點Si和Sj之間的歐氏距離。
(4)
當數據節點Si和Sj之間不存在數據鏈路時,定義Dij=+。另外,式3表明系統的安全水平與數據塊之間的相關性成反比,與數據節點之間的邏輯距離成正比。Ωij的值越大,表明數據的存放越安全。

(5)
2.2 約束多目標優化模型
假設用戶從數據節點Si發出數據查詢請求,存儲在數據節點Sj處的數據塊Dn將會按照指令要求傳輸到數據節點Si中。則需要解決的一個基本問題是將數據塊Dn從數據節點Sj傳輸到數據節點Si中的時間最小化。一個基本思路是找到數據節點Si和Sj之間的最短路徑。文中定義數據節點Si和Sj之間的最短路徑為Pij,則將數據塊Dn在數據節點Si和Sj之間的最短傳輸時間定義為:
(6)
其中,e表示路徑Pij上相鄰數據節點之間的一段鏈路,e∈Pij;Bexy表示鏈路exy上的帶寬;鏈路exy上的兩個端點分別為網絡的頂點vx和vy,即數據節點Sx和Sy。
文中要解決的根本問題是在保障存儲數據安全的前提下最小化用戶對數據的檢索時間。實際上,該問題是一個多目標優化問題(multi-objective optimization problem,MOP),包括最小化數據的檢索時間T和最大化系統的安全水平Ω。因此,結合式5和式6,可以得到最小化檢索時間的目標函數為:
(7)
文中系統設計的目標是在保證系統數據安全的前提下最小化數據的最小時間,即:
Minimize:F(S)
(8)
Subject to
(9)
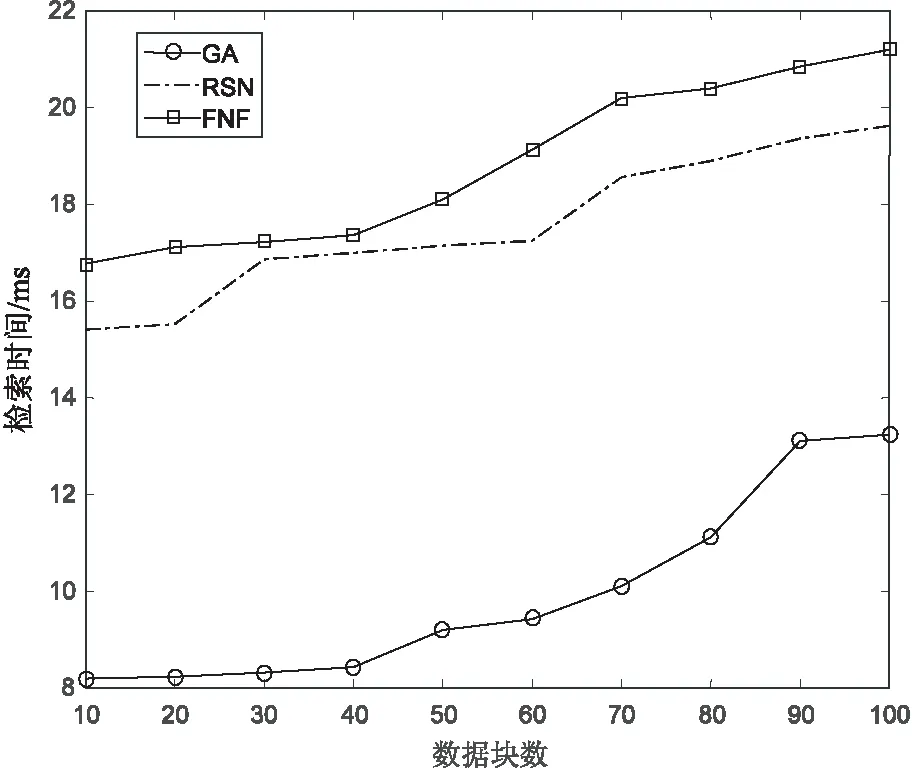
0 (10) 式9表示所有數據塊的尺寸總和是等于原始數據的尺寸的;式10表示存放在數據節點Sn處數據塊的尺寸是小于數據節點Sn的最大容量Cn的。 通過以上最優化模型在一個分布式的存儲系統中獲取最優化的數據放置策略是一個NP難題,傳統的數值計算方法往往不能有效計算其全局最優解。對于此類問題,采取約束優化問題的方法進行求解。約束優化問題(constrained optimization problems,COPs)是指在一系列參數的約束條件下,針對問題求出最優化目標的問題。目前,求解該問題的算法大致有兩類:確定性算法和不確定性算法。前者包括投影梯度法、填充函數法、懲罰函數法、序列二次規劃法等,這些方法的求解大多依賴函數的初始值以及梯度信息,對于最優解的收斂較慢,易陷入局部最優解,且對于連通性差,不可導以及沒有函數表達式的問題沒有很好的解決方法。后者不依賴問題本身的嚴格數學性質,在解決全局最優解的問題中比較有優勢。運行時間相對較短且描述簡單,容易實現。不確定算法主要是一些啟發式算法,包括模擬退火法、蟻群算法、遺傳算法等。文中將重點研究遺傳算法。 2.3.1 遺傳算法 早在20世紀40年代,就有學者開始模擬生物活動研究計算機技術。其中部分學者提出了類似生物進化規律的隨機搜索算法。Holland教授于1975年在其著作《自然系統和人工系統的自適應》中正式定義了遺傳算法。遺傳算法是基于達爾文進化論的啟發以模擬生物界物種進化而形成的啟發式算法,其目的是求取全局最優解,具有隨機性的特征。其不依賴梯度信息的特點被廣泛應用于無約束優化問題,一旦初始參數確定后,遺傳算法將以與問題本身無關的方式進行求解。在不斷的優化過程中使其同樣可以處理約束優化問題。 遺傳算法的基本思想是模仿一個種群的繁殖行為,由父代的染色體通過交叉、變異得到后代的過程。在該過程中根據達爾文的進化理論淘汰掉比較差的后代(不符合線性收斂的個體),存活下來的個體不僅繼承了父代的優點,并且更加適應環境、更加優秀。子代中優秀的個體再不斷繁殖進化。每一次迭代都能夠得到比前一代更好的個體。并最終實現了全局最優解。 遺傳算法的核心操作是選擇、交叉和變異。其過程是將解轉換為可以進行交叉變異的染色體結構,給定滿足約束條件的初始解進行繁殖操作,并遵循適者生存、優勝劣汰的自然選擇法則剔除相對較差的后代,保存比父代更好的近似解。進行多次迭代直到產生滿足條件的最優解時終止算法。其具體步驟如下: (1)編碼:每個問題的解都看作是一個可以進行交配的染色體,所以先將問題的解轉化為染色體結構。染色體上的DNA可以進行自由組合。 (7)迭代:判斷種群是否達到閾值φ,如不達到繼續執行步驟5、6,如達到則中止迭代并得到最優解。 整個遺傳算法流程中先后需要確定遺傳算法的參數選取、編碼方案、適應度函數、算法終止準則(確定閾值)、遺傳算子的設計(包括選擇算子、交叉算子以及變異算子)。并且還要考慮算法能夠支持并行運算,以確保算法的運行效率。 2.3.2 基于多目標遺傳算法的云數據安全放置算法 首先將式7~10中的最優化問題轉化為標準化的遺傳算法求解問題: Maximization:-F(S) (11) subject to: (12) 0 (13) 式12中,δ為等式約束條件的容忍值,一般取一個較小的正值。將式8中的等式約束條件轉換為不等式約束條件后,式8中的等式約束將轉化成一個不等式約束問題。 針對最小化檢索時間問題的特點,構建了該問題的遺傳算法。 (1)編碼方法的確定。 由于文中設計的系統數據是被切分為N個長短不一的數據塊分別存放在不同的數據節點中,因此采用自然數編碼的方式對所要求解的問題進行編碼。用0表示數據的查詢節點,用1,2,…,M-1分別表示其他的各數據節點。這里的數據節點可能存有數據塊,也可能沒有存儲數據塊。當Sm=0時,表明數據節點m中沒有存儲數據塊;當Sm≠0時,表明數據節點m中存儲有數據塊。由于原始數據是被切分成長度不一的N份存放在N個數據節點中,則網絡中將會存在N-1條數據傳輸路徑,以便將各數據節點中存儲的數據塊傳輸到查詢節點0處。數據在傳輸路徑上進行傳輸,必然經過路徑上的多個數據節點,也有可能不經過某些數據節點。由此可知,還剩下M-N+1個數據節點沒有存儲數據塊信息。為了在編碼中反映這N-1條數據傳輸路徑,設定1,2,…,M-N+1個互不重復的自然數隨機排列構成一個個體,對應一種數據放置策略。例如,數據節點的個數為10,數據塊的個數為5(假定其中有一個數據塊0存放在數據節點0處,數據節點0處為用戶查詢節點),則可以用1,2,…,9(其中5,6,7,8,9這幾個數表示沒有存放數據塊)這9個數隨機排列,將其存放到9個數據節點中。如個體1,2,4,7,3,6,8,5,9表示數據塊存放在數據節點0,1,2,4,7這5個數據節點當中。 (2)初始群體的確定。 隨機產生一種1~M-1這M-1個互不重復的自然數排列,即形成一個個體。設群體的規模為N,則通過隨機產生N個這樣的個體,形成初始群體。 (3)適應度評估。 對某個個體所對應的數據放置方案的優劣進行判定,一是要看其是否滿足網絡系統的約束條件,而且要計算其代價函數值。根據基于數據安全約束最小化檢索時間的特征要求所確定的編碼方法,隱含了存放在各數據節點中數據的尺寸之和等于原始數據的尺寸,并且各數據節點中所存儲的數據塊的尺寸一定是小于該數據節點的容量的信息。另外,存放數據塊的數據節點之間一定滿足式3的要求。因此,在設計數據的放置策略時需要同時考慮這幾個約束條件,若不滿足則判定該方案不可行,最后計算其代價函數值。對于某個個體k,設其對應的數據放置方案的不可行個數為φk,其代價函數值為Zk,則該個體的適應度Fk表示為: (14) 其中,w對每個不可行放置策略的懲罰權重,可以根據代價函數(式11)的取值范圍取一個相對較大的數值。 (4)選擇操作。 (5)交叉操作。 除排在第一位的最優個體外,對另外N-1個新產生的個體按照概率pi進行交叉重組。 (6)變異操作。 在選擇機制中,采用了保留最優個體的方式。為保障群體內個體的多樣性,采用連續多次變換的變異技術。變異的概率為pj,一旦發生變異,則變異交換的次數通過隨機的方式產生。 文中通過計算機實驗仿真來驗證提出的基于多目標遺傳算法的云數據安全放置方法。 假設整個云存儲系統中的M個數據節點S是一個隨機的拓撲網絡,并且每一個數據節點在網絡系統中都具有一個固定的位置坐標Sm,其位置坐標具體為其在網絡中的MAC地址。數據節點的存儲容量隨機設定為(256,1 024)GB;需要存儲的原始數據的尺寸設定為(0.5,2)GB;網絡中數據節點之間的帶寬隨機設定在(100,500)MB之間,并由此構成網絡鏈路的帶寬矩陣B。 為了對基于多目標遺傳算法的云數據安全放置方法的可用性和有效性進行系統化的評估,利用檢索時間、數據節點的利用率、安全水平三個評估標準來對其進行衡量,具體為: (1)檢索時間:基于多次查詢,對于檢索操作的實際檢索時間(所有數據塊傳輸到查詢節點的時間)求平均值。 (2)數據節點利用率:數據放置策略中存在對于N個數據塊的選取。在多個文件存入時,查看M個數據節點中實際被使用的節點占比(最小為N/M)。 (3)安全水平:根據文中安全水平的定義,計算出當前數據塊間的安全水平。 為對比分析實驗的結果,參考文獻[16]中的方法對數據節點的選擇策略進行了設計,該策略用以從M個數據節點中選出符合整體安全水平的N個節點存入N個數據塊。其思想是設定一個節點集,初始包括隨機選擇的一個數據節點,根據不同的選擇策略選出一個節點插入當前節點集并確保節點集中兩兩節點間的安全水平不低于最小安全閾值,且平均安全水平不低于平均安全閾值。以下為2種節點選擇策略:隨機選取節點(random selection of nodes,RSN),按照節點選擇策略隨機選擇包含N個節點的節點集;最遠節點優先(furthest node first,FNF),選擇離當前節點集中節點平均距離最遠的并且符合節點選擇策略的包含N個節點的節點集。 實驗首先需要對遺傳算法中所涉及的編碼、選擇、交叉、變異等操作過程進行設計,其具體設計方法可以參見文中的算法描述。 仿真實驗1驗證、比較了提出的基于多目標遺傳算法的云數據安全放置方法中數據檢索次數和原始數據量對數據檢索時間、數據節點利用率以及安全水平的影響程度。其中原始數據被切分為數據塊的數量為30。圖1中設定數據節點數為100。從圖1的結果可見,文中算法的平均檢索時間小于其他算法。 圖1 檢索次數的影響 圖2描述了隨著存儲原始數據量的增加,數據節點的利用率的變化情況。圖中數據節點的數量設定為200。可以看出,隨著原始數據量的增加,數據節點的利用率顯著提高,表現為數據的分散程度比較高,即原始數據切分后的數據塊是分散存儲在存儲系統中的,驗證了系統的安全性。 圖2 數據量與節點利用率的關系 圖3描述了隨著存儲原始數據量的增加,數據安全性的變化情況。圖中數據節點設定為200。如圖所示,隨著原始數據量的增加,GA算法和RSN算法的安全水平也有相應提高,這是因為當原始數據量較少時,算法傾向于選擇離檢索點相對比較近的節點,隨著原始數據量的增加,數據塊需要存儲在距離較遠的數據節點中。這與式3中提出的安全水平理論一致。而FNF由于是選擇最遠節點,故開始時安全性能最高,但后期呈下降趨勢。 圖3 數據量與安全水平的關系 仿真實驗2驗證、比較了在不同的安全水平、數據節點數、數據塊數量下,檢索時間的變化情況。圖4中設定數據節點數為100,數據塊數為30。結果顯示,隨著安全性能要求的提高,各算法的檢索時間均有所增加,這是由于安全性能的提高直接增大了數據塊之間的距離,所以檢索路徑長度增加。 圖4 安全水平的影響 圖5 節點數的影響 圖5中設定數據塊為30,結果顯示,隨著數據節點數的增加,檢索時間呈現增加的態勢,這是由于在更大的網絡拓撲下,數據塊的物理距離的增大所引起。 圖6中,原始數據的尺寸大小設定為2 GB,該原始數據被切分為不同數據量的數據塊,比較分析其數據檢索時間的大小。數據節點的個數設定為200。結果顯示,隨著數據塊數量的增加,檢索時間增加。這是由于在N條檢索路徑上傳輸的總數據不變,N的增加必然會增加檢索路徑的長度。 圖6 數據塊數的影響 該節通過多次仿真實驗,將不同的參數設為變參,均顯示出GA算法在檢索時間開銷上優于FNF和RSN算法。同時在安全性能方面,FNF和RSN算法均優于GA算法,這是由遺傳算法自身特性所決定的,GA算法中的安全性能與安全閾值緊密相關。并沒有對安全水平進行最優化,但可以通過調整閾值,定義GA算法的整體安全性能,已達到實際中所需要的安全需求。 為解決當前云存儲系統的兩個核心問題即數據安全和檢索效率,提出了基于多目標遺傳算法的數據安全放置方法。該方法以數據安全性和檢索效率為目標,建立了多目標優化模型,采用遺傳算法來解決問題。并且在隨機網絡拓撲環境中進行了仿真實驗以驗證其效率。仿真結果表明,該算法在保證數據安全的前提下,優化了檢索效率。同時鑒于遺傳算法具有較低的時間復雜度,在該算法中拋棄了傳統的加密模式,能夠保證較高的運算效率。2.3 多目標遺傳算法






3 實驗仿真與分析





4 結束語
