ETL任務集群調度方法
2018-11-22 12:02:06李磊
計算機技術與發展 2018年11期
關鍵詞:分配
李 磊
(北方工業大學 計算機學院,北京 100144)
0 引 言
ETL(transformation and loading,extraction)技術是構建數據倉庫的基礎技術,也是批量數據交換的基礎技術[1]。ETL是將數據從源抽取、轉換、整合、清洗并加載到目標的過程。ETL過程是構建數據倉庫的重要環節,甚至占到了整個構建過程的80%[2]。隨著時間變化,數據倉庫中ETL任務增多,數據量也不斷增多。若在單機上運行,任務執行花費大量時間,數據的時效性、可用性將嚴重受限。因此,研究ETL任務集群調度算法十分必要。如何將大量的ETL任務分配給集群中每個節點來獲得數據倉庫構建的最小執行代價,是ETL任務集群調度方法中主要研究的問題。數據倉庫中的任務由于受到多種因素的影響,導致ETL任務執行時間不一,所以設計算法保障每個作業都能獲取到執行的機會也是必要的。
文中基于貪婪調度算法[3]的思想,根據ETL任務數據源數據量的大小來合理分配任務,讓集群中工作節點的負載達到均衡,使得總的任務執行時間最短。使用高響應比優先調度算法[4]動態調整任務的優先級,保障任務在節點上公平執行。
1 問題描述
1.1 傳統ETL流程分析
首先,數據從數據源(例如:文本文件、關系數據庫、XML文件、非結構文檔等)抽取出來。其次,合適的轉換、清洗、交集或并集等活動處理抽取的數據,使它們滿足目標結構的需求。最后,加載處理過的數據到數據倉庫[5]。
Kettle工具把ETL工作流實現為一個可以在Java虛擬機上執行的文件,也即是Kettle把上述工作流映射為相應的操作組件,組合為一個完整的ETL任務,由Kettle引擎調度工作流中的各活動。文中ETL調度不再考慮各個活動之間如何調度執行。通常由Kettle工具生成的作業文件依賴于操作系統的調度工具調度,例如Windows的任務計劃、Linux的crontab,調度必須手動配置,無法滿足工程需求。
1.2 ETL任務集群調度約束條件
ETL任務定義:ETL就是一個或多個數據源輸出,經過加工處理,再輸出到一個或多個數據源構成的流程[6],文中要調度的ETL任務就是Kettle工具生成的以上流程。
ETL任務集群調度定義:中心調度節點負責分配ETL任務到集群中的執行節點執行。
每個Kettle作業包含若干作業或者轉換,它們之間具有指定的先后次序關系,Kettle轉換包含的操作組件遵循的是并行執行的原則,Kettle引擎負責每個操作組件之間的調度[7]。集群中所要調度的就是能夠并行執行的Kettle作業。
每個Kettle作業同一時刻只能有一個運行在集群中。不同的Kettle作業可以同時運行在同一臺機器或不同機器。
集群中每個Kettle工作節點執行能力相同。
文中選取影響任務執行時間最重要的源數據的數據量大小,作為ETL任務分配的依據。
1.3 ETL任務集群調度目標函數
通常ETL任務執行考慮執行時間的代價、占用資源的代價以及兩者相結合的代價[8]。文中選擇執行時間代價。
T(kij):表示i任務在j機器上的執行時間代價,1≤i≤n,1≤j≤N。
T(mk):表示機器mk的執行時間代價,1≤k≤N。
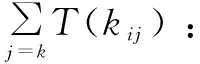
T(task):ETL任務在所有機器上執行的最長時間。
T(task)=max(T(mk))
ETL任務集群調度的目標函數可以定義為:
2 ETL任務集群調度方法
ETL調度系統由調度模塊與執行模塊組成。調度模塊(調度中心)負責管理調度信息,把所有的調度任務抽象為一個任務,按照調度配置發出調度請求,自身不承擔業務代碼。調度系統與具體任務解耦,提高了系統的可用性和穩定性。執行模塊(執行器)負責接收調度請求并執行任務邏輯。
調度流程如圖1所示。批量ETL任務,使用基于貪婪調度算法把ETL任務分配到執行器,把任務添加到Quartz調度器[9]定時執行,抽象的Quartz任務調用遠程的執行器接口,當此執行器接收到新任務的執行調用時,會啟動本地線程運行ETL任務。使用高響應比優先調度算法計算任務優先級,分配到執行器上的任務按照優先級獲取線程資源運行ETL任務。

圖1 集群調度總體設計
貪婪算法是一種解決最優解的近似算法。在對問題求解時,總是做出在當前看來是最好的選擇。也就是說,不從整體最優上加以考慮,所做出的是在某種意義上的局部最優解[10]。假設有一個任務集合S={s1,s2,…,sn},S中每個任務所對應源數據量的大小W={w1,w2,…,wn},m臺工作節點U={u1,u2,…,um}。該算法把S中的任務依據源數據量的大小平均分配到工作節點U中,求解總的任務執行時間最短的分配方法。假設每臺機器分配到所有任務的源數據量總和越平均,硬件資源的負載越均衡,總任務執行時間代價越小。
貪婪分配算法具體步驟如下:
(1)對任務集合S按數據量從大到小排序,存入隊列A。A={(si,wi)…(sj,wj)},其中wi≥wj,1≤i,j≤n。
(2)從隊列A中取出隊首的任務,計算各個節點任務數據量的總量,把該任務分配到ui,1≤i≤m。ui為當前工作節點中數據量總量最少的節點。
(3)重復步驟2直到隊列空,算法結束。
高響應比優先調度用在ETL調度系統中來動態調整ETL任務的優先級。ETL作業的特點也即運行時間長短不一,如果動態調整ETL任務的優先級,有利于任務都能有機會獲得資源運行。
將該算法應用到調度框架的執行器模塊,主要設計如圖2所示。執行器不斷從調度中心接收到調度請求,然后緩存到優先級隊列,在線程組資源充足的情況下,優先級隊列的任務都能獲得線程執行。當線程組資源不能滿足需求時,一些ETL任務由于等待時間變長而優先級變高,如果有空閑資源,這些高優先級的任務將優先獲取到執行機會。為避免有些任務占用時間過長,導致其他任務獲取不到執行的機會,設計任務動態優先級調整任務的執行順序,使用典型的消費生產者模型,優先級隊列為生產者的緩沖區,任務監控線程為消費者代理(負責任務分配),線程組的線程為消費者。
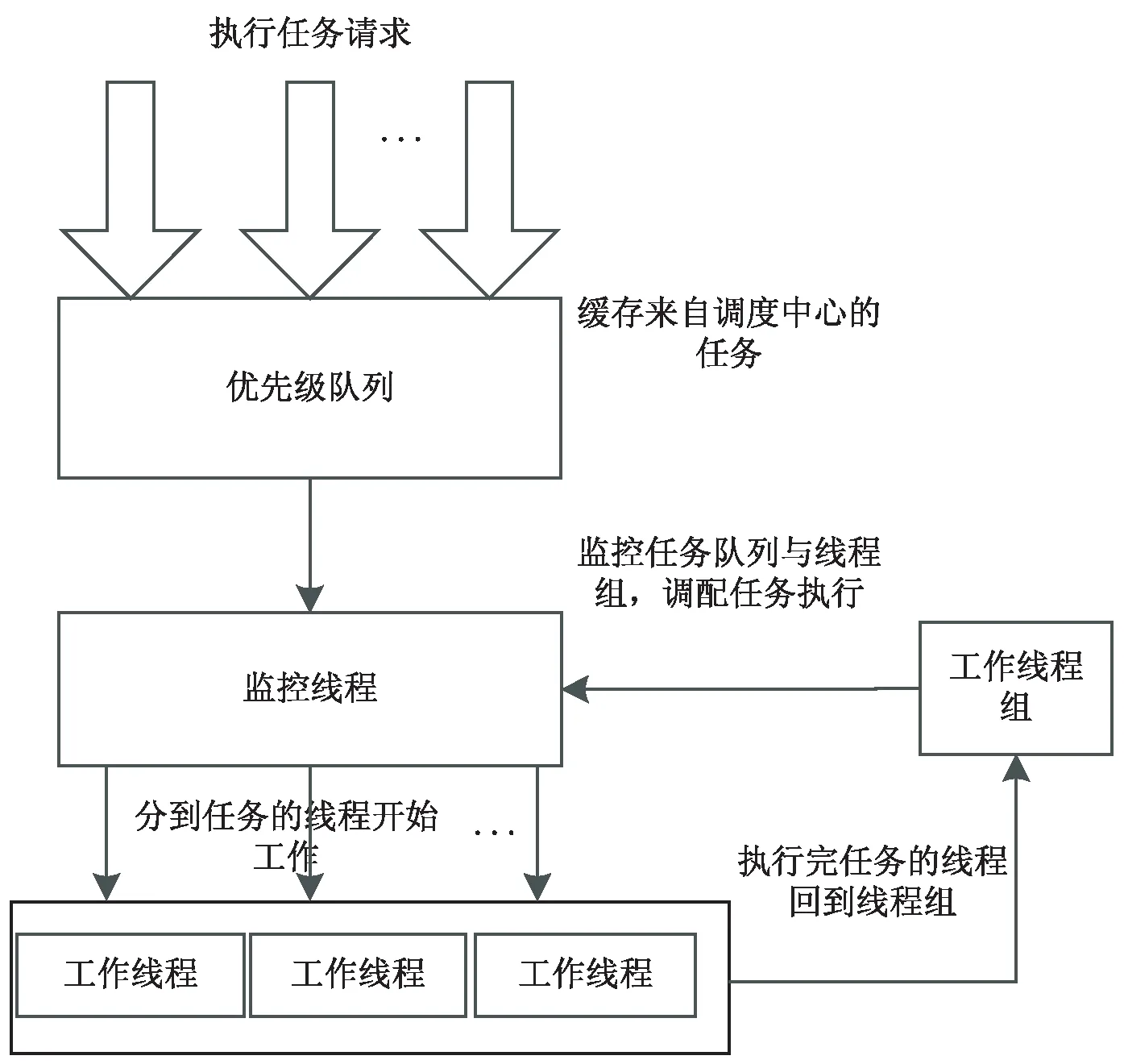
圖2 執行器任務執行策略
3 實驗結果與分析
3.1 實驗描述
實驗中模擬35個ETL任務,其中10個10萬,10個20萬,10個50萬,5個100萬條源表記錄全量抽取任務,定時時間設置為每16分各個任務運行一次,記錄10次全部任務運行完成各工作節點所需時間,求每臺工作節點全部執行完的平均時間作為本節點的執行時間記錄。實驗使用4臺虛擬機,1臺調度中心,3臺工作節點。配置見表1。
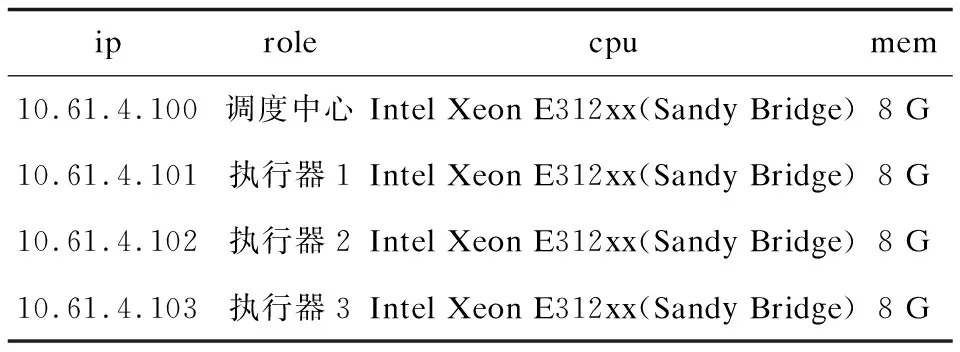
表1 集群配置表
3.2 實驗結果
這35個任務按照貪婪分配原則分配之后的結果是:執行器一分到3個10萬,3個20萬,3個50萬,2個100萬數據量的任務,執行器二少分配一個20萬,多分配一個10,相比于執行器一,執行器三分配到3個10萬,5個20萬,4個50萬與1個百萬數據量的任務。其他幾次測試分配情況就不一一列舉。使用ETL中基于貪婪算法的任務調度方法研究中,基于任務的平均時間分配得到的分組結果為:5個100萬與10個50萬與10個10萬結果同上,30萬101多一個,102多一個,103少2個。分組結果基本上與按源表數據量大小分配相同。任務為35個時,各個執行器使用貪婪算法與輪轉算法的資源利用率如圖3、圖4所示。任務分別為10、35、45個時,使用貪婪、輪轉分配算法執行完所有任務消耗的時間如圖5所示。

圖3 各執行器CPU使用率

圖4 各執行器內存使用率
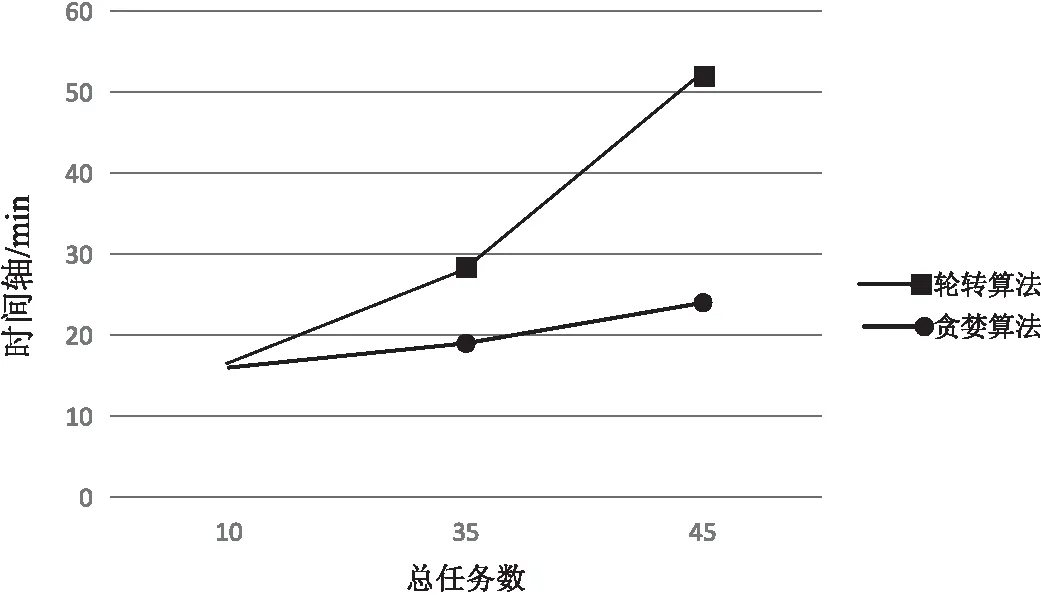
圖5 執行任務的總時間
3.3 實驗分析
輪轉調度算法是以輪詢的方式依次將作業分配到不同的服務器,即將所有服務器組成一個循環隊列,每次取頭服務器分配。從任務數量上看是平均分配到各個服務器,但是由于任務執行時間的大小不等,很大可能造成服務器負載的不均衡[11]。實驗中通過比較輪轉與貪婪調度算法所使用資源的情況,可以看出貪婪調度算法要優于輪轉調度算法。比較相同任務條件下,輪轉算法總耗時多于貪婪算法。輪轉只考慮了任務的數量,并未考慮任務的其他特性,造成負載的不均衡[12]。而貪婪算法考慮ETL任務中關鍵因素任務數據量的大小,以達到負載相對均衡的目的。對于ETL中基于貪婪算法的任務調度方法,文中按任務平均時間作為分組憑據,同樣使用相同數量任務的測試,得到的分組結果基本相同,但是分別測試每個任務的執行時間增加更復雜的步驟。同時為了保證所測試時間的準確性,還需要連續測試多天的數據,選擇同一任務時間相近的數據作為最終分組的憑據。
4 相關工作
現有的ETL調度算法主要集中在ETL工作流邏輯轉換的過程優化,通過減少處理過程數量或改變過程執行順序來減少ETL工作流的執行代價[13],或者根據ETL活動的分配和調度而建立數據倉庫ETL任務調度模型。如基于粒子群算法分布式ETL任務調度[14],設計ETL任務調度模型,將連續空間域映射為離散整數域解決工作調度問題,利用啟發式算法找到最佳調度策略;基于遺傳算法的ETL任務調度[15],采用同層劃分的思想進行模型化求解。這些ETL任務調度算法,不適合現有成熟ETL工具生成的任務調度。
5 結束語
分析了ETL任務的特點,設計與優化ETL集群調度框架,加入批量ETL任務分配算法和動態優先級算法。貪婪調度算法依據ETL任務特點實現集群負載均衡,優點是把ETL中任務數據總量均勻分配到各個執行節點,減少任務執行時間。高響應比算法,優點是在任務執行時動態調整任務的優先級,以避免ETL任務獲取不到運行資源。結合兩種算法,文中設計的ETL集群任務調度系統具有高效穩定的特點。同時也存在不足:由于ETL任務執行涉及到數據量、網絡帶寬、數據轉換復雜度等諸多不確定因素[16],實現負載均衡任務分配只從數據量單方面考慮,做不到準確,所以設計一種能衡量一個完整ETL任務權重的算法十分必要;由于貪婪調度算法是一種靜態的分配算法,在分配任務完之后,如果有工作節點的資源使用率過高,不能做到動態調整,所以下一步設計動態調整任務的工作節點,以達到資源使用率的均衡,從而達到所有任務執行總時間最短的目的。
猜你喜歡
天水行政學院學報(2022年4期)2022-11-18 09:02:36
艦船科學技術(2022年13期)2022-08-11 09:30:02
鐵道通信信號(2020年9期)2020-02-06 09:15:22
漢語世界(The World of Chinese)(2019年3期)2019-07-01 02:37:48
數學大王·趣味邏輯(2019年5期)2019-06-13 20:27:43
小學科學(學生版)(2019年5期)2019-05-21 01:00:18
中學生數理化·中考版(2018年10期)2018-12-07 00:44:52
經濟技術協作信息(2018年30期)2018-11-22 06:20:24
中央社會主義學院學報(2017年1期)2017-04-16 05:34:07
中國衛生(2014年12期)2014-11-12 13:12:40
