信用評分系統的研究
2018-11-20 07:47:20彭妍陳宣霖
消費導刊 2018年6期
彭妍 陳宣霖


摘要:消費者在金融機構進行借貸的歷史數據的記錄非常多,指標龐大。然而并非所有的數據都能夠對借貸判斷起到作用。為了使得金融機構能夠對用戶有正確的借貸選擇,本文利用分箱和特征篩選法得到具有50個指標的評分體系,最終利用決策樹模型對數據進行精確度檢驗,結果表明:決策樹模型在信用評分系統應用精確度非常高。
關鍵詞:信用評分系統 分箱 特征選擇 決策樹模型
引言
隨著日益增長的物質文化需求,消費信貸業務有著迅速發展的趨勢,而長期以來,如何規避信用風險是各金融機構面臨的主要問題,因此構建完整有效的信用評分體系十分關鍵和迫切。其基本原理是基于對消費者的利用信用歷史記錄和人口特征等大量數據進行詳盡的分析,建立出最佳的信用評估模型,預測違約情況,值得在實踐中推廣,本文將對此進行探索。(數據來源于2018年東證期貨杯建模競賽)
一、指標選取
指標太多會導致模型結果偏差較大,因此需要對指標做降維處理,篩選更為重要的指標,使得數據更為簡化,本文首先使用分箱法對連續型指標進行處理。
(一)分箱處理
分箱法是指通過考察“鄰居”(周圍的值)來平滑存儲數據的值,用“箱的深度”表示不同的箱里有相同個數的數據,用“箱的寬度”來表示每個箱值的取值區間,將連續變量離散化將多狀態的離散變量合并成少狀態。假設要將某個自變量的觀測值分為k個分箱,一些常用的分箱方法有:等寬分箱、k均值聚類分箱、Best-KS法等。本文使用最優分箱法對將需要離散化的連續性變量進行處理,避免了數據中無意義的波動,也避免了極端值的影響,增強了數據的穩定性和健壯性,這里展示其中一個指標的分箱結果:
(二)特征選擇
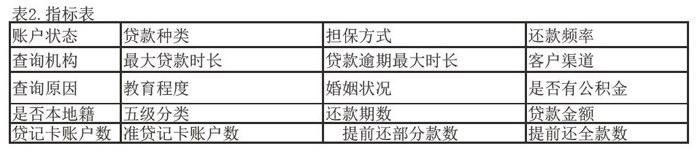
在將連續型變量進行分箱處理后,仍含有較多的指標,鑒于此進一步對數據進行特征選擇處理,特征選擇基本思想是從原始特征中選擇出一些最有效特征以降低數據集維度。導致分類器下降的原因往往是因為這些高緯度特征中含有無關特征和冗余特征,因此特征選擇的主要目的是去除特征中的無關特征和冗余特征。本文通過Fllter法衡量變量之間的相關性,采用皮爾遜相關系數來評估,最終選擇了最重要的指標共504-用于建模。(這里只展示前20個指標)
二、非平衡樣本的處理
由數據原始數據Y頻數表可知,數據集存在嚴重的非平衡性。由于正常用于大于違約用戶;留存客戶大于流失客戶。即Y=0(正樣本)和Y=1(負樣本)的數據量相差很大,對于最終的預測結果會嚴重傾向于多數的正樣本類,導致對負的分類錯誤率很高,本文采用過采樣法解決非平衡樣本的問題,在Y=1中的數據隨機抽取95%,在Y=0中的數據隨機抽取5%后建立新的數據集進一步做后續模型的分析。
三、決策樹模型
決策樹是在各種情況發生的概率已知的基礎上,通過構成決策樹來對項目風險進行評估,并對其可行性進行判斷。其基本思想是根據一些分割原則,將大量的訓練集數據劃分類。基本步驟是對于給定訓練集數據先按一定的分割原則一分為二,得到的兩個子集再按另一種分割原則一分為二,如此重復,直到合適的程度。基于此,將決策樹模型應用于上文中含有50個指標的信用評分系統,得出其判斷精確度結果表明,決策樹模型精準度高達96%。
四、建議
根據本文選擇的指標和模型結果對貸款人提出以下建議:
1.對于信用卡累計逾期月份較多的,建議以后在于使用信用卡時盡量提前還款,來降低累計逾期月份數和累計逾期金額數。
2.由于不良還款記錄一般不易消除,所以在以后建議還款記錄保持良好,從而再下次銀行貸款期可以通過模型識別。
3.對于銀行貸款,如果要貸大筆金額,可以先從小額貸款開始,然后按時還款,或者提前還款。
