基于Spark的腫瘤基因混合特征選擇方法
2018-11-20 06:08:36汪麗麗費敏銳
計算機工程 2018年11期
汪麗麗,鄧 麗,余 玥,費敏銳
(1.上海大學 機電工程與自動化學院,上海 200072; 2.上海市電站自動化技術重點實驗室,上海 200072)
0 概述
基因芯片技術可快速檢測成千上萬基因的表達水平,對了解基因功能、開展生物學研究等具有重要意義。文獻[1]通過檢測一組特異基因的表達水平進行腫瘤亞型的診斷。隨后大量研究人員展開將基因數據用于腫瘤診斷及亞型分類的研究。腫瘤基因數據往往樣本數量少而基因數量非常龐大。數據中的大量無關基因及冗余基因會對分類產生一定影響。有研究表明[2],在腫瘤基因數據處理過程中,選擇特征基因子集往往比選擇高效分類器更為重要。
傳統特征選擇分為過濾式(filter)與封裝式(wrapper)。過濾式依據某一標準給特征賦予一定的權重,具有收斂快、計算復雜度低等優勢,如F-score[3]、互信息等。封裝式將后續學習器的性能作為特征子集的評價準則,學習器包括擴展的線性模型(回歸模型[4]、線性支持向量機[5-8])、基于樹的方法(隨機森林[9-11])等。混合特征選擇結合過濾式和封裝式,比過濾式分類效果更優,比封裝式計算更快[12-13]。近年來,集成特征選擇算法受到研究學者們的廣泛關注。集成特征選擇方法通過數據擾動或功能擾動方法,獨立構造不同學習器進行特征選擇,集成各個結果獲得最終特征子集[14]。一些學者結合混合特征選擇和集成特征選擇實現更優化的特征選擇,如:基于FCBF及ABACO、IBGSA 2種啟發式算法的集成方法[15];基于Relief、IG、FCBF集成方法及ABACO算法[16];基于信噪比和條件信息相關系數(CCC)集成方法[17]。
F-score[3]算法簡單、運行速度快,有助于理解數據但主要對線性關系敏感。SVM遞歸特征消除(SVM-RFE)[5]算法穩定能夠反映出數據的內在結果。針對多標簽問題可拓展為多分類SVM-RFE(MSVM-RFE)[6-8],但往往不能全面地考慮特征與每個類別的關系。基于隨機森林的特征選擇準確性高,適合多分類問題,但對于關聯特征的打分不穩定[9-11]。隨機森林特征選擇和MSVM-RFE對于挖掘非線性關系有較好的效果。集成特征算法如要得到較好的集成效果,集成學習器之間必須呈現差異性[18],所以采用功能擾動方法集成這3種差異性較大的特征選擇方法可實現優缺點相互補充,提取出包含最多類別信息的特征子集,以便開展后續的生物學研究。
目前,基因數據的處理分析大多都是在單臺機器上實現的。然而隨著基因數據規模逐步擴大,單機處理運算能力不足的缺陷逐步顯現。分布式計算框架的出現使存儲及處理海量數據成為可能。Spark立足于彈性數據集,數據緩存在節點內存,適合基因數據處理過程中存在的大量迭代運算。
綜上所述,本文提出一種基于Spark分布式計算框架的混合特征選擇方法。該方法利用F-score去除無關基因,通過集成F-score、MSVM-RFE、基于隨機森林的特征選擇3種方法得到特征子集,最終實現SVM分類預測。
1 腫瘤基因數據的混合特征選擇
1.1 Spark分布式框架
Hadoop框架一直是首選的大數據處理方案,但從Map任務到Reduce任務,數據被寫入磁盤從而產生大量信息通信,并不適合處理迭代任務。Spark分布式框架基于彈性分布式數據集(RDD),數據被緩存在工作節點的內存中,適合進行機器學習及智能優化算法中的迭代運算。數據集操作不僅包括Map和Reduce操作,還提供很多函數轉換(transform)、數據執行(action)等操作。
本文將Spark運行在現有的Hadoop集群基礎上,通過讀取HDFS上文件創建彈性分布式數據集RDD,在RDD分區的工作節點上分別執行腫瘤基因數據的特征選擇操作,執行后結果被發送到驅動程序進行聚合,最后將結果返回到HDFS平臺上。
1.2 分布式混合特征選擇實現
分布式混合特征選擇的主要思路是首先用過濾式特征選擇,在不影響分類正確率的基礎上,去除無關基因,然后分別進行3種不同的特征選擇,集成不同的選擇結果作為最終的特征子集,最后用支持向量機進行分類檢驗,混合特征實現框圖如圖1所示。
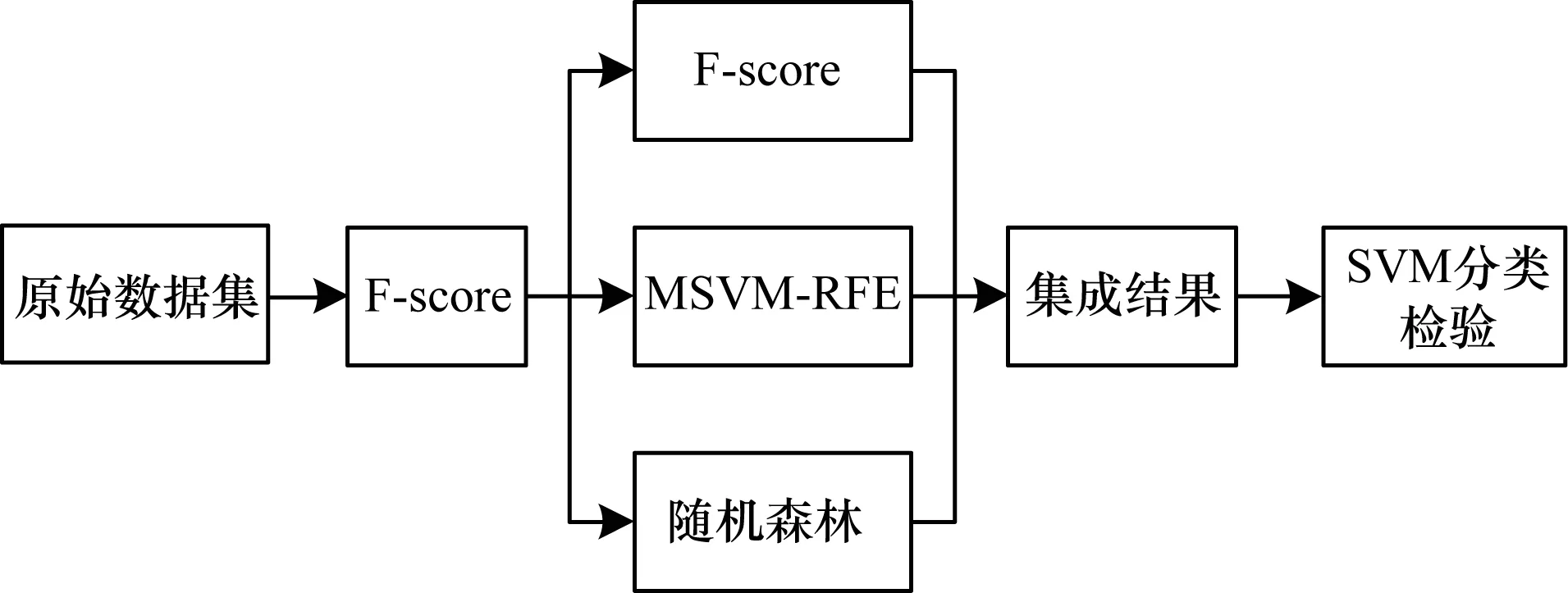
圖1 混合特征選擇實現框圖
分布式混合特征選擇實現步驟如下:
步驟1從HDFS上讀取腫瘤數據集,創建一個彈性分布式數據集。
步驟2通過Map操作將文件每行的數據用“,”隔開,通過LabeledPoint來存儲標簽列和特征列。
步驟3采用F-score特征選擇方法去除無關基因,并用支持向量機進行分類檢驗。
步驟4對上一步得到的初選特征子集分別采用F-score、MSVM-REF、基于隨機森林的特征選擇3種方法,每種方法輸出選擇的特征子集,選擇出現最多次數的特征為最終特征選擇子集。
步驟5利用最終的特征選擇子集運行在支持向量機上,采用十折交叉驗證計算子集的分類正確率。
1.3 F-score及支持向量機分類檢驗
腫瘤數據成千上萬的基因中有90%以上的基因都是與分類無關的,所以可以通過F-score粗略地計算每個基因與類別之間的關系,在不降低分類準確率的條件下,去除這些無關基因。通常有2種方法來確定初選特征子集的基因數方法:按照經驗選擇或根據某些準則自動確定。本文首先依據相關的文獻資料,確定基因數為100~200之間,然后逐漸減少基因數進行若干次實驗并記錄分類結果,直到基因數下降而特征子集的分類正確率基本保持不變則停止。確定選擇基因數的初選過程如下:
1)F-score特征初選
初始數據集RDD1={(x1,y1),(x2,y2),…,(xN,yN)},其中,xi=〈xi1,xi2,…,xin〉為n維向量,n為總基因數,yi取0,1,…,m中某一值,m為標簽類別數,N為樣本數。通過F-score計算每個特征與標簽類別之間的關系,計算公式為:
(1)
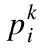
2)對上述階段得到的初選特征子集進行SVM分類檢驗
本文采用的支持向量機是在基本型的基礎上引入“軟間隔”概念,并采用hinge損失,SVM目標函數為:
(2)
傳統的SVM求解是引入拉格朗日乘子得到對偶問題,通過SMO算法求解對偶問題。在分布式計算框架下,不需要轉換成對偶問題,而是直接針對目標函數利用隨機梯度下降(SGD)優化技術求解,在每次迭代中計算梯度和、損失和以及更新權重,直至收斂或達到指定次數。其中,隨機梯度下降更新公式為:
(3)
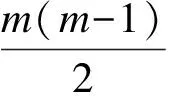
1.4 集成特征選擇
對初選特征子集RDD2分別進行F-score、MSVM-REF、基于隨機森林的特征選擇,每個特征選擇方法都將特征子集作為輸出,得到RDD3、RDD4、RDD5。結合3個特征子集計算出現次數最多的特征,將放入最終特征子集RDD6中。
1.4.1 F-score特征選擇
F-score在Map階段根據式(1)逐個計算RDD2中每個特征與標簽類別之間的相關性,在Reduce階段依據得分按降序排列,選擇q個相關性最大的特征,保存為彈性數據集RDD3。
1.4.2 MSVM-REF特征選擇
SVM-REF特征選擇過程是基于SVM最大間隔原理的迭代選擇方法。從原始特征集開始,每一次迭代通過訓練模型生成權向量,得到每個特征的得分,去掉得分最低的特征,當剩余特征數達到預先設定值時,則停止迭代。由于腫瘤亞型診斷中常出現多分類問題,因此采用多分類支持向量機遞歸消除(MSVM-RFE)。最早的MSVM-RFE(OVA-RFE)采用OvR策略將多分類問題拆分成多個二分類任務,分別計算特征重要性,將多個得分相加后得到排序總分以此作為特征剔除的依據。OVA-RFE并不能保證最后的特征子集能同時最小化評價函數,所以采用對OVA-RFE擴展的MSVM-RFE。首先利用線性加權法將問題轉換為以下形式:
(4)
利用OBD算法解決該最優化問題得到:
(5)
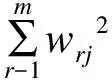
算法1多分類支持向量機遞歸消除
輸入初選特征子集RDD2,設定的特征選擇數q
輸出被選擇的特征子集RDD4
1.初始化
1.1.讀入初選特征子集RDD2為集合S;
1.2.設置k為特征集S中特征數;
2.重復以下步驟,直到k=q:
2.1.用集合S訓練多分類支持向量機模型,得到m個權重向量w1,w2,…,wm,其中wr=[wr1,wr2,…,wrk]T;
2.2.計算評價指標,得到特征i對應的得分ci=∑rwri2;
2.3.找出得分最小的特征z=argminici,將此特征z從集合S中除去;
2.4.設置k為集合S的特征數;
3.返回集合S為RDD4。
1.4.3 基于隨機森林的特征選擇
隨機森林的特征重要性度量方法是通過計算平均值的方法,來收集底層樹的特征重要性并將其整合。由于一棵決策樹頂部的特征對大部分輸入樣本的最終預測決策有一定貢獻,因此某一特征作用的部分樣本可以用來作為對該特征相對重要性的估計。通過在多棵隨機樹中取這些相對重要性的平均值,可以減少這種估計的方差。特征的重要性被認為是該特征帶來的某一標準的總減少量,在本文中此標準為Gini不純度。
初選特征子集RDD2包含m個類別和N個樣本,最初的Gini不純度為:
(6)
其中,pj表示第j類樣本出現的概率。若經過一次分割,樣本集被分為k個部分R1,R2,…,Rk,樣本數分別為m1,m2,…,mk,此時的Gini不純度為:
(7)
分割前后Gini減少量為Gini特征重要性(Gini Important),即:
GiniImportant=Gini-Ginisplit
(8)
Gini特征重要性越大,代表該特征越重要,所以將其作為算法2中衡量特征重要性的一大指標。
根據不純度減少原則來選擇基因存在一個問題,即相關的多個特征選擇一個特征后,其他特征的重要性就會急劇下降,不利于了解每個特征的重要性,容易造成誤解。每次訓練學習器選擇的特征子集差異性較大,不利于下一步選擇結果的集成,所以采用一種貪心算法-序列后向搜索算法來改善。每次迭代從特征集合中去掉重要性得分最低的特征,通過多次迭代最終得到特征數目少且分類效果優的最優特征子集。具體步驟如算法2所示。
算法2基于隨機森林的序列后向特征算法
輸入初選特征子集RDD2,設定的特征選擇數q
輸出被選擇的特征子集RDD5
1.初始化
1.1.讀入初選特征子集RDD2為集合S;
1.2.設置k為特征集S中特征數;
2.重復以下步驟,直到k=q:
2.1.對數據集S有放回地抽樣分成n個子集,分配到各個計算節點;
2.2.創建多個map任務,利用n個訓練子集構建n棵對應的決策樹,計算每棵決策樹分裂過程中的每一個特征變量的特征重要性GiniImportanti;
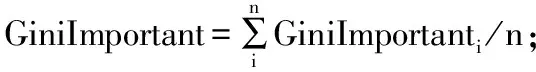
2.4.找出重要性得分最小的特征,將其從集合S中除去;
2.5.設置k為集合S的特征數;
3.返回集合S為RDD5。
1.5 支持向量機參數調整
在利用隨機梯度下降求解SVM超平面參數時,有3個主要參數需要設置:迭代次數,步長以及正則化參數C。在SGD中,一開始增加迭代次數可以提高分類器性能,一旦完成特定次數迭代后,再增大迭代次數對結果的影響較小,所以希望選擇一個與該特定次數相接近的值。步長是決定算法在最陡的梯度方向上前進的距離。步長越大,SGD收斂速率越快,但會導致收斂到局部最優解。正則化可通過控制模型的復雜度防止模型出現過擬合。當正則化參數選取過小,對模型性能的改變隨之減少;當參數過大又會導致欠擬合降低模型性能。
為了進行這3個參數的調優,創建2個輔助函數:trainParams函數與trainMetric函數。trainParams函數給定輸出參數然后訓練SVM模型,trainMetric函數計算該模型對應的分類正確率。首先給定參考序列,執行Map數據轉換操作,對序列元素逐一進行trainParams、trainMetric函數操作,然后再執行數據執行操作,輸出不同參數及其對應分類結果,選擇分類效果最優對應的參數即為最優參數。
2 實驗結果與分析
2.1 運行環境的搭建與設置
本文的計算機集群包括2臺計算機,其中一臺計算機同時作為主節點與工作節點(Intel Core i3-6100 CPU @3.70 GHz),另外一臺作為工作節點(Intel Core 2 Duo CPU E8200 @2.66 GHz)。內存分別為8 GB、4 GB。Spark分布式環境是部署在Ubuntu系統上,依次安裝JDK、Hadoop、Spark以及Python,并設置SSH(Secure Shell)免密碼登錄,便于操作工作節點。計算機集群硬件及軟件版本配置情況如表1所示。

表1 集群軟硬件信息
2.2 腫瘤基因數據集及預處理
本文使用結腸癌(Colon)、乳腺癌(Breast)、兒童小型圓形藍細胞腫瘤(SRBCT)、白血病(Leukemia)數據。數據集可從UCI、GEMS網站下載,4個數據集的基因數、樣本數、標簽類別如表2所示。其中,Colon、Breast數據集標簽為患病樣本或正常樣本,SRBCT、Leukemia數據集標簽為不同亞型。
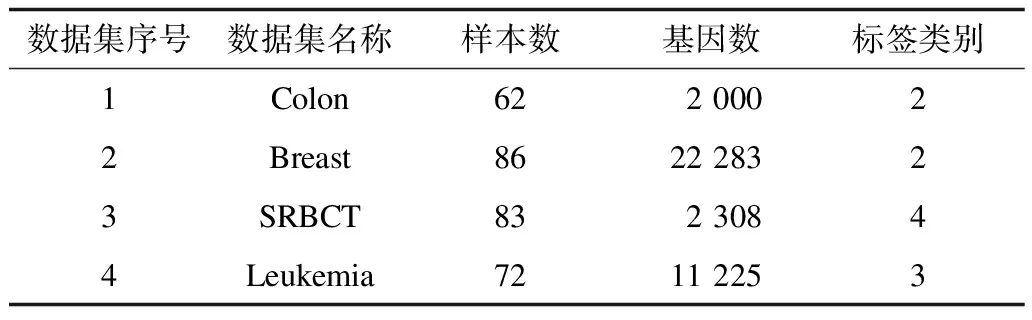
表2 腫瘤數據集
2.3 結果分析
2.3.1 F-score實驗分析
F-score作為初步的特征選擇,要求在不降低分類正確率的前提下去除無關基因及相關性較低的基因。本文分別對3個數據集進行F-score特征選擇,選擇基因數為100,用支持向量機進行檢驗,其分類正確率與不加特征選擇情況對比如表3所示。
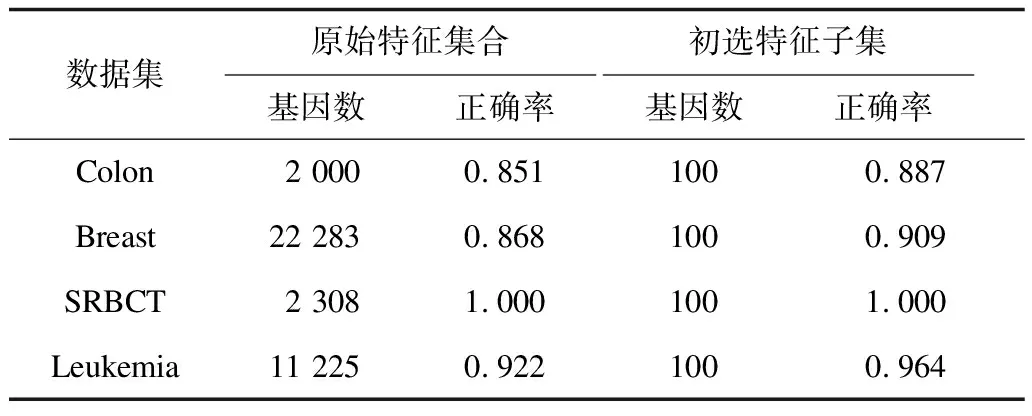
表3 F-score特征選擇前后結果比較
由于樣本數量的限制,因此本文采用十折交叉驗證,將10次結果平均值作為最終分類正確率。對比實驗結果可知,F-score選擇特征基因子集后,分類正確率不僅沒有下降,反而由于去除了無關基因,分類正確率在一定程度上有所上升。實驗結果表明,利用F-score選擇100個特征基因能很好地保留與分類密切相關的特征基因。
2.3.2 集成特征選擇算法實驗分析
集成特征選擇算法分析方法如下:
1)各種方法的參數選擇
在求解支持向量機時,有3個參數需要設置:即迭代次數、步長和正則化參數。3個參數的參考序列分別為Seq(1,5,10,30,50,100)、Seq(0.001,0.01,0.1,1.0)、Seq(0.001,0.01,0.1,1.0,10.0)。當單獨使用SVM計算特征子集的分類正確率時,通過多次訓練模型,在序列中搜索最佳參數。當使用SVM用于特征選擇時,SVM迭代次數、步長、正則化參數取固定值,分別為50、0.01、0.01。
在隨機森林中,選擇決策樹個數為100,原始的序列后向算法每次迭代消除一個特征,但由于隨機森林模型本身計算成本較高,訓練消耗時間較大。因此,希望通過在每次迭代中消除幾個特征來降低計算復雜度,但是增加迭代消除特征數可能會導致算法性能的下降。因此,在Colon、Breast、SRBCT、Leukemia數據集上分別設定特征消除數為1、2、3,訓練隨機森林模型進行特征選擇,對不同特征子集皆采用十折交叉驗證計算分類正確率,記錄數據如圖2所示。由圖2可知,當迭代消除數為1和2時,分類準確率相差不大,當迭代消除數為3時,會下降多一些,所以選擇迭代消除特征數為2。
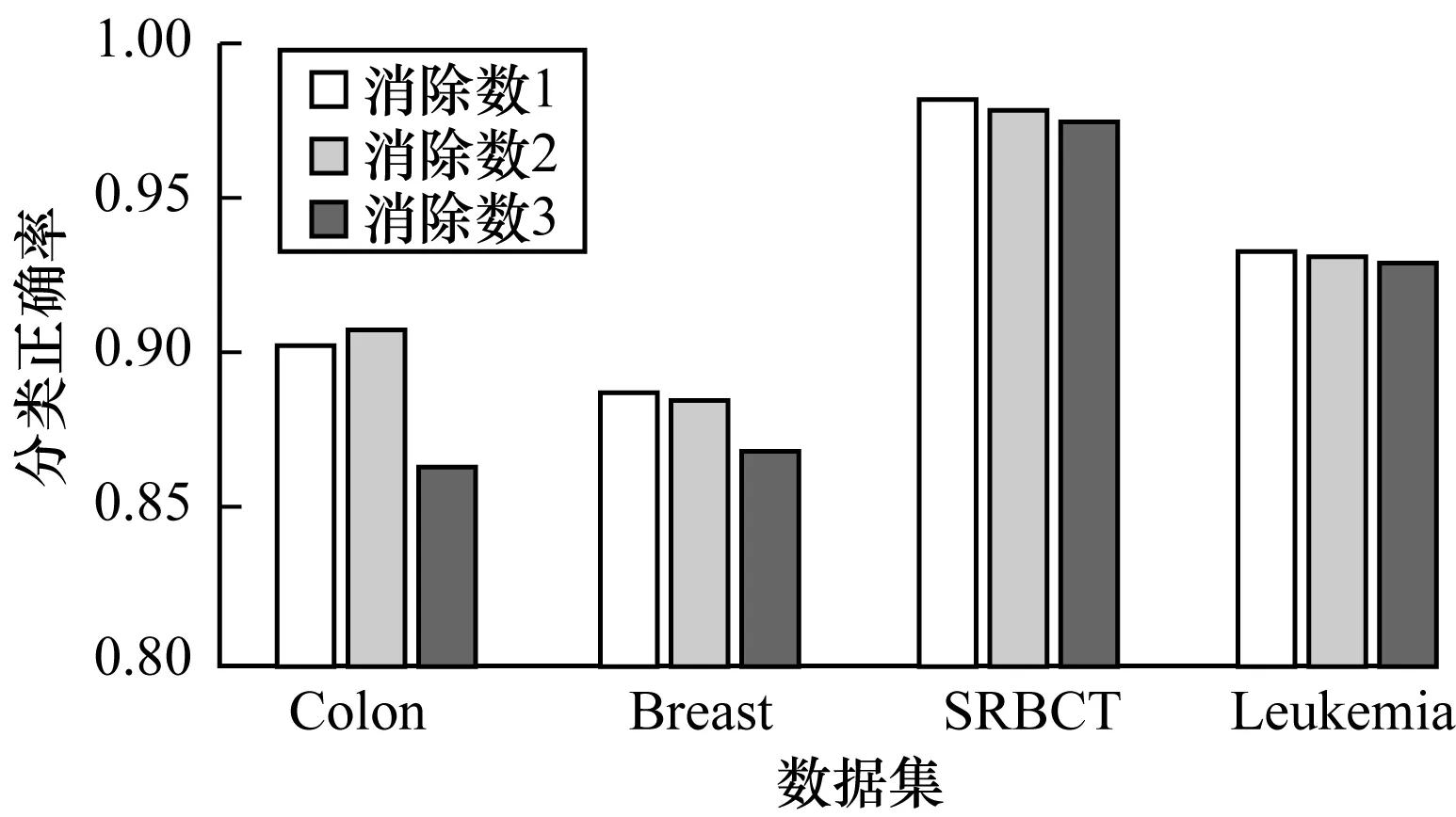
圖2 隨機森林參數選擇
2)集成特征選擇與子特征選擇對比
在初選特征子集基礎上,分別進行F-score、MSVM-RFE、基于隨機森林的特征選擇以及集成特征選擇算法4種特征選擇方法,記錄選擇不同特征數時對應的分類正確率,繪制折線圖如圖3所示。折線圖橫軸為選擇的特征數,縱軸為支持向量機分類正確率。預期的特征選擇效果是隨著選擇的特征數增加,分類正確率隨之上升,達到一定值后保持不變,或者一定程度下降。實驗結果與預期大致相符,在達到某一最大值之后,特征數的增加不能帶來正確率的上升,正確率會在一定值上下浮動。
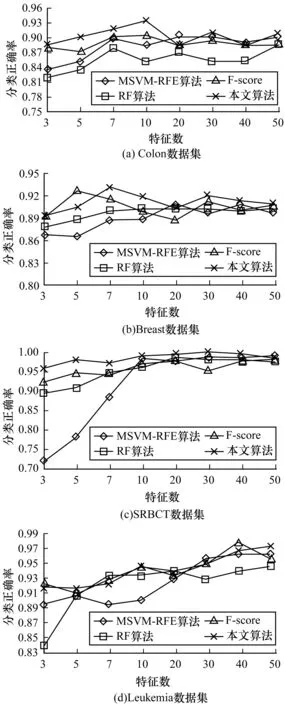
圖3 特征選擇對比折線圖
從圖3可以看出,在Colon、Breast、SRBCT數據上,集成特征選擇效果相比F-score、MSVM-RFE、基于隨機森林的特征選擇效果有一定程度提升,尤其是在基因個數較少的時候有較好的分類正確率。在Leukemia數據上,集成特征選擇算法與基于隨機森林的特征選擇方法效果相差不大,但仍優于F-score、MSVM-RFE運算效果。出現這樣的原因主要是因為在微陣列技術中會對微陣列數據進行歸一化,矩陣文件每個值為2個信號的差值,可能為負值或極小值。Colon、Breast、SRBCT數據皆為正值,而Leukemia數據存在一些負值,這些負值不僅不具有生物學意義,還在一定程度上會影響實驗的結果。由于引入隨機性隨機森林的抗噪能力較好,因此在Leukemia數據上基于隨機森林的特征選擇效果較好,另外2種特征選擇效果并不佳,那么集成3種特征選擇方法并不能產生更好的效果,只能維持與相較最好的特征選擇方法相似的效果。對于這些數據點,應該在特征選擇前置為缺失或賦予統一的數值。大體上,集成特征選擇方法能充分考慮特征與標簽之間線性與非線性關系,特征子集的分類效果在整體上優于子特征選擇方法,實驗表明,集成特征選擇能提取出一組數量更少、更具有結果分類能力的特征基因子集。
3 結束語
為解決腫瘤數據急劇增長導致的單機運算能力不足的問題,本文基于Spark分布式計算框架提出一種混合特征選擇方法。首先利用F-score特征選擇方法去除無關基因,保留與分類密切相關的基因。然后集成F-score、MSVM-REF、基于隨機決策樹的特征選擇3種方法,得到最優的特征子集。最后采用支持向量機分類器對特征子集進行分類預測。實驗結果表明,本文算法能提取特征數量少、分類效果好的特征子集。由于最優的特征選擇和分類要建立在有效的數據預處理的基礎上,因此下一步將從以下2個方面進行改進:融合多個相關數據集生成一個信息量更大的數據集,得到更為可靠的分析結果;增加集群節點數減少算法運行時間。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
