基于維基百科的中文嵌套命名實體識別語料庫自動構(gòu)建
2018-11-20 06:42:56李雁群何云琪錢龍華周國棟
計算機工程 2018年11期
李雁群,何云琪,錢龍華,周國棟
(蘇州大學(xué) 計算機科學(xué)與技術(shù)學(xué)院 自然語言處理實驗室,江蘇 蘇州 215006)
0 概述
信息抽取的目的是從無結(jié)構(gòu)的自由文本中抽取出實體及其相互關(guān)系并轉(zhuǎn)化為結(jié)構(gòu)化表達形式,從而為知識庫的構(gòu)造提供數(shù)據(jù)基礎(chǔ)[1-2]。嵌套命名實體是一種特殊形式的實體,其內(nèi)部包含其他實體,嵌套在里面的實體稱為內(nèi)部實體,最外層的實體稱為外部實體。如外部實體“[[[中共]nt [北京]ns 市委]nt 宣傳部]nt”包含“[中共]nt”“[北京]ns”和“[中共北京市委]nt”3個內(nèi)部實體。其中,嵌套實體的類型標注采用《人民日報》語料的格式,即nr表示人名,ns表示地名,nt表示組織名。由于嵌套命名實體含有豐富的實體信息以及實體之間的相互關(guān)系,且其結(jié)構(gòu)復(fù)雜多變,因此嵌套命名實體的識別成為信息抽取中值得研究的任務(wù)之一。
目前的嵌套命名實體識別都采用有監(jiān)督的機器學(xué)習(xí)方法,因而需要一定規(guī)模的語料庫。GENIA V3.02[3]是生物醫(yī)學(xué)領(lǐng)域內(nèi)的命名實體語料庫,其中包含了嵌套命名實體,被廣泛應(yīng)用于生物醫(yī)學(xué)領(lǐng)域的命名實體識別研究。該語料庫包含2 000條MEDLLINE摘要和94 014個實體引用,其中約有17%的實體嵌套在其他實體中。EPPI[4]是生物醫(yī)學(xué)領(lǐng)域內(nèi)另一個標注了蛋白質(zhì)及其相互作用關(guān)系的語料庫,它包含217個從PubMed和PubMedCentral選出來的摘要和全文文獻,總共有134 059個實體引用。RCAHMS[5]是一個標注實體及其語義關(guān)系的歷史檔案語料庫,包含1 546個文本和28 272個實體引用,其中18.7%的實體嵌套在其他實體中。
中文方面的命名實體語料有來源廣泛的MSRA語料和新聞領(lǐng)域的1998年1月份的 《人民日報》語料,兩者都標注了最外層實體,但后者還標出了嵌套在內(nèi)層的命名實體,因此中文嵌套命名實體識別研究大都基于《人民日報》語料[6-7]。該語料庫總共有61 922個實體引用,其中,13.8%的實體嵌套在其他實體中。不過,由于《人民日報》語料是1998年的新聞?wù)Z料,因而其局限性較大,難于拓展到其他領(lǐng)域的嵌套命名實體識別。本文提出基于中文維基百科的方法來自動構(gòu)建面向?qū)挿侯I(lǐng)域的中文嵌套命名實體識別語料庫。該方法對中文維基百科的條目進行實體分類,并從這些實體條目中自動構(gòu)造出中文嵌套命名實體。
1 相關(guān)工作
嵌套命名實體識別方法主要分為基于規(guī)則的方法和基于機器學(xué)習(xí)的方法。早期的方法是在基本實體識別的基礎(chǔ)上采用基于規(guī)則的后處理方法來識別嵌套命名實體[8-9],其不足之處是規(guī)則的靈活性較差。基于機器學(xué)習(xí)的方法大都采用層次模型,即將嵌套命名實體的識別轉(zhuǎn)換成多個層次的序列標注問題。層次模型可以從3個層面展開:1)標簽層次化[4],即擴充一個詞的標記使它反映出該詞所參與的所有實體類型,然后用一個序列化標注模型來識別,其不足之處是標記集龐大,從而導(dǎo)致訓(xùn)練語料稀疏,訓(xùn)練時間較長;2)模型層次化[4,10],即采用多個疊加的序列化標注模型,第1個序列化模型首先識別出基本實體,然后再用第2個模型識別出第2層嵌套命名實體,以此類推,其特點是模型數(shù)量較多;3)語料層次化[5],即將一定范圍內(nèi)的單詞從左到右連成長度不一的詞串作為實例,然后用序列化標注模型來識別,其缺點是數(shù)據(jù)復(fù)雜度較高。
與序列化標注方法不同,文獻[11]采用判別式成分句法分析器來訓(xùn)練嵌套命名實體識別模型。該方法把每個嵌套命名實體轉(zhuǎn)換成一棵句法分析樹,其中每一個詞作為該樹的葉子節(jié)點,而每個內(nèi)部實體作為該樹的子樹,其優(yōu)點是樹的表示法可以清晰地表示任意層數(shù)的嵌套命名實體。
中文嵌套命名實體識別的研究都是在《人民日報》語料上進行的,大都采用層次化模型。文獻[6]將人名和地名作為基本實體在第1層進行識別,然后將識別結(jié)果傳遞到第2層模型進行嵌套組織機構(gòu)名的識別。文獻[12]用相似的方法,差別在于第1層識別基本實體,第2層再識別3層實體,如果要識別更高層的嵌套命名實體還要采用啟發(fā)式規(guī)則進行后處理。與上述研究工作不同的是,文獻[7]提出一種聯(lián)合學(xué)習(xí)模型,將中文嵌套命名實體識別看作是一種聯(lián)合切分和標注任務(wù),采用平均感知器算法進行在線訓(xùn)練,運用集束搜索算法進行解碼。該方法獲得了較快的收斂速度和較好的識別效果,缺點是只能識別兩層嵌套命名實體。
2 嵌套命名實體識別語料庫的構(gòu)建
本文的核心思想是利用中文維基百科來自動構(gòu)建一個高質(zhì)量的中文嵌套命名實體語料庫。一方面,中文維基百科含有大量的條目,其中包含大量的各種類型的命名實體,如人物、組織和機構(gòu)等,可以采用機器學(xué)習(xí)的方法從這些維基條目中以較高的性能識別出命名實體及其類型[13]。另一方面,這些維基百科條目之間本身就蘊含著上下級關(guān)系,如條目“上海市虹口區(qū)足球場”為地名實體,而其中的“上海市”和“虹口區(qū)”又分別都是維基條目中的地名實體。因此,可以利用這樣的包含關(guān)系來自動構(gòu)建一個嵌套命名實體“[[上海市]ns [虹口區(qū)]ns 足球場]ns”。具體而言,從維基百科構(gòu)建嵌套命名實體語料庫包含以下2個步驟:
1)中文維基條目實體分類。利用機器學(xué)習(xí)的方法對所有的維基百科條目進行分類,從中識別出命名實體條目。
2)嵌套命名實體自動生成。利用維基條目實體分類結(jié)果以及維基頁面中的相關(guān)信息進行嵌套命名實體自動標注。
2.1 中文維基條目實體分類
對英文維基百科條目進行分類主要有2種方法:基于啟發(fā)式規(guī)則的方法[14]和基于機器學(xué)習(xí)的方法[15-17]。在中文維基百科上,文獻[13]采用機器學(xué)習(xí)的方法進行維基條目的實體分類,從中文維基百科條目的半結(jié)構(gòu)化信息及維基頁面的文本中提取各類特征,并根據(jù)中文的特點加入更多額外特征,構(gòu)造相應(yīng)的特征向量,然后使用SVM分類器進行條目實體分類,獲得了較高的分類性能。本文使用該方法進行中文維基條目的實體分類,其主要特征包括以下4個方面:
1)信息框?qū)傩悦m撁嫘畔⒖虻膬?nèi)容是關(guān)于該條目的基本屬性,每一個屬性包含屬性名和屬性值,將其中所有的屬性名以詞包形式提取出來作為一個特征。例如,在一個人物條目的信息框中可能有屬性對<“國籍”“中華人民共和國”><“姓名”“XXX”>和<“出生日期”“XXXX年XX月XX日”>等,分別提取“國籍”“姓名”和“出生日期”等作為詞包特征。
2)分類框中心詞。每個條目所對應(yīng)頁面的分類框為當前條目所屬的各個類別。例如,一個人物的分類框中可能有“XXXX年出生”“在世人物”和“中國人民大學(xué)校友”等類別信息,分別提取每個類別的中心詞“出生”“人物”和“校友”等作為特征。
3)定義句中心詞。每個維基頁面文本的第一段通常為該條目的摘要,而第一句則是定義句,介紹當前條目的基本概念。通過對定義句進行分詞和詞性標注,找出其最右邊的名詞作為定義句的中心詞。此外,當定義句的句式結(jié)構(gòu)為 “……是(為)……”時,還能通過正則匹配獲得該句中心詞。例如,從“馬云”維基條目的摘要中提取到的特征為“企業(yè)家”。
4)中文相關(guān)特征。與中文有關(guān)的4個額外特征,具體如下:
(1)條目標題的首字是否為中國人名的姓氏且標題長度為2個到4個字。
(2)條目標題中是否包含外國人譯名中使用的分隔符“·”。
(3)標題的最后一個字和詞,詞可以通過分詞工具獲得。
(4)維基百科分類框中心詞在同義詞詞林[18]中的語義編碼。
在人工標注的條目實體類型語料上的實驗結(jié)果表明,該方法的總體性能較高,準確率達到97%,召回率達到95%,平均性能F1指數(shù)達到了96%,這樣的性能滿足了后續(xù)要求。
2.2 嵌套命名實體自動生成
通過上述的維基條目實體分類得到了一個大規(guī)模的實體字典,其中有大量的實體條目包含了其他實體條目,很多情況下一個實體中甚至包含了3個到4個內(nèi)部實體,這為自動構(gòu)建嵌套命名實體語料庫提供了大量的數(shù)據(jù)基礎(chǔ)。雖然該實體字典規(guī)模很大,但也存在下列問題:
1)字典匹配的假正例問題。在實體文本中進行單純的字典匹配經(jīng)常會產(chǎn)生假的嵌套命名實體,這種情況尤其會發(fā)生在外國實體名稱中。如“奧雷爾韋爾拉克”是法國阿韋龍省的一個市鎮(zhèn),而“奧雷”則是法國利穆贊大區(qū)上維埃納省的一個市鎮(zhèn),兩者沒有任何的嵌套關(guān)系。簡單的名稱匹配很容易使后者成為前者的內(nèi)部實體,但這是一個假正例。
2)實體歧義問題。如“中國”這個詞在當今語境下(包括《人民日報》語料庫和微軟語料庫)沒有任何歧義,就是指“中華人民共和國”,但由于中文維基百科是一個綜合性的知識庫,其中“中國”還可以指向1931年由中國共產(chǎn)黨所創(chuàng)建的“中華蘇維埃共和國”,1927年建立的以南京為首都的“中華民國”,袁世凱在1915年稱帝成立的“中華帝國”等,甚至還可以指向日本九州的“中國”地區(qū),這種實體的歧義給的構(gòu)建工作帶來了困難。
為了解決上述問題,本文提出了自動構(gòu)造中文嵌套命名實體的算法。
算法嵌套命名實體自動生成
輸入CWE[],中文維基實體名稱列表
WID{},中文維基實體名稱到維基條目id的映射表
WLK{},維基條目id到該維基頁面中的內(nèi)鏈接列表的映射表
輸出CNE[],中文嵌套命名實體列表
初始化:CNE=[]
1.對每一個中文維基實體名稱CWE[i]:
2. 如果WID{CWE[i]}有多個元素,則跳過該實體
3. 以CWE為字典,使用最長匹配原則從左到右識別出其中所包含的內(nèi)部實體,匹配后的嵌套實體為ne
4. 將ne加入到CNE數(shù)組
5.對每一個中文嵌套命名實體CNE[i]:
6. 對CNE[i]的每一個內(nèi)部實體e:
7. 若WID{e}中存在一個id等于WID{CNE[i]},則在CNE[i]中刪除e的標注
8. 若WID{e}中沒有一個id在WLK{WID{CNE[i]}}中,則刪除CNE[i]
9.對每一個中文嵌套命名實體CNE[i]:
10. 對每一個中文嵌套命名實體CNE[i]:
11. 若CNE[i]以內(nèi)部實體e出現(xiàn)在CNE[i]中,則用CNE[i]的標注代替CNE[i]中e的標注
在算法中,CWE為從上節(jié)獲得的中文維基實體名稱列表,WID將實體名稱映射到維基id,當id有多個時,表明實體名稱具有多個含義,即岐義性,WLK可根據(jù)id得到該頁面中的所有內(nèi)鏈接的id列表。該算法主要包括匹配、過濾和匯聚3個步驟:
1)匹配。即基于字典的命名實體識別(第1步~第4步)。對實體字典中的每一個實體名稱(稱為外部實體),以字典本身作為詞表,使用最長匹配原則從左到右識別出其中所包含的所有內(nèi)部實體。如果外部實體本身有歧義時,則不考慮該實體。如實體名稱“[上海交通大學(xué)徐匯校區(qū)]ns”,字典中包含“[上海交通大學(xué)]nt”和“[徐匯]ns”2個實體,因此可直接得到嵌套命名實體“[[上海交通大學(xué)]nt [徐匯]ns 校區(qū)]ns”。
2)過濾。把不滿足嵌套關(guān)系的內(nèi)部實體作為假正例過濾掉(第5步~第8步),原則如下:
(1)內(nèi)部實體的某一個含義和外部實體指向同一個維基頁面(第7步),如“[西藏自治區(qū)]ns”中的“[西藏]ns”指向同一個維基頁面,因此后者不能作為前者的內(nèi)部實體。事實上,“[西藏自治區(qū)]ns”是一個不能再分割的整體。
(2)內(nèi)部實體的任何一個含義所指向的實體都沒有出現(xiàn)在外部實體的頁面中(第8步),其中,WLK{WID{CNE[i]}}表示外部實體所指向的維基頁面中的所有內(nèi)鏈接id列表,即如果在外部實體的頁面中找不到對內(nèi)部實體的引用,則認為兩者之間的嵌套關(guān)系不存在,如實體“[奧雷爾韋爾拉克]ns”頁面中不存在對實體“[奧雷]ns”的引用,因而嵌套關(guān)系不成立。同樣,實體“[中國中央電視臺]nt”的頁面中出現(xiàn)了“中國”的一個含義“[中華人民共和國]ns”的引用,因此“[中國]ns”就是一個內(nèi)部實體。需要注意的是,這個規(guī)則也會把一些真正的正例過濾掉,如“[七十三軍抗戰(zhàn)陣亡將士墓]ns”中的內(nèi)部實體“[七十三軍]nt”,由于沒有出現(xiàn)在前者的頁面中而被濾掉。因此,直接把它從實體列表中移除,既不作為正例,也不作為負例。
3)匯聚。如果一個包含內(nèi)部實體的外部實體又作為內(nèi)部實體出現(xiàn)在另一個外部實體中(稱為上級實體),則將它的嵌套關(guān)系匯聚到上級實體中,這樣就可以保證一個外部實體包含所有可能層次的內(nèi)部實體(第9步~第11步)。如實體“[[上海]ns 交通大學(xué)]nt”和“[[上海交通大學(xué)]nt [徐匯]ns 校區(qū)]ns”可以匯聚成一個單一嵌套命名實體“[[[上海]ns 交通大學(xué)]nt[徐匯]ns校區(qū)]ns”。
3 語料庫統(tǒng)計和評估的自動構(gòu)建
3.1 語料庫統(tǒng)計的自動構(gòu)建
通過上述方法從維基百科中自動構(gòu)建出包含嵌套命名實體層次結(jié)構(gòu)的實體列表,稱為嵌套命名實體識別自動構(gòu)建語料,該語料可用于從外部實體中識別出它所包含的內(nèi)部實體。語料庫的統(tǒng)計情況如表1所示。

表1 維基語料實體統(tǒng)計
從表1可以看出:
1)人名沒有嵌套現(xiàn)象,但人名可以出現(xiàn)在內(nèi)部實體中。
2)無嵌套結(jié)構(gòu)的外部實體中大部分是人名(約55%)和地名(約39%),以及少量的組織名(約6%)。
3)有嵌套結(jié)構(gòu)的外部實體中地名(約53%)和組織名(約47%)差不多各占一半,而內(nèi)部實體則反之,大部分是地名(約82%),小部分是組織名(約13%)和人名(約5%)。
3.2 語料庫人工評估的自動構(gòu)建
為了衡量自動構(gòu)建語料庫的質(zhì)量,從中隨機選取了200個外部實體,首先進行嵌套命名實體的手工標注,然后再與自動標注的嵌套命名實體進行比較,并采用與準確率和召回率相類似的標對率和標全率以及F1指數(shù)來反映語料的自動標注質(zhì)量,抽樣統(tǒng)計結(jié)果如表2所示。
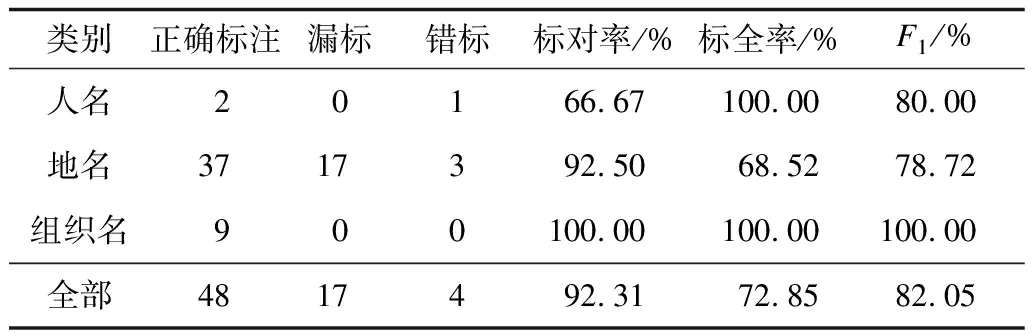
表2 自動標注語料質(zhì)量的抽樣統(tǒng)計
從表2可以看出,整體標對率達到了92.31%,然而整體標全率較低,只達到了72.85%。錯標17條地名漏標的主要原因有:
1)維基條目缺失(12條),如地名“境主廟水庫”應(yīng)該標注為“[[境主廟]ns 水庫]ns”,但是維基條目中沒有地名“境主廟”這個條目。
2)維基鏈接缺失(4條),如“大坂產(chǎn)業(yè)大學(xué)短期大學(xué)部”應(yīng)標注為“[[[大坂]ns 產(chǎn)業(yè)大學(xué)]nt 短期大學(xué)部]nt”,但因為“大坂產(chǎn)業(yè)大學(xué)”頁面沒有包含“大坂”的鏈接,所以最后標注為“[[大坂產(chǎn)業(yè)大學(xué)]nt 短期大學(xué)部]nt”。
3)條目類型錯誤(1條),即在維基條目實體分類時識別為非實體,如“汲水門燈籠洲燈塔”應(yīng)標注為“[[汲水門]ns [燈籠洲]ns 燈塔]ns”,但由于“燈籠洲”的條目類型識別為非實體,因此標注為“[[汲水門]ns 燈籠洲燈塔]ns”。
4 自動構(gòu)建語料的實驗評估
為了衡量自動標注語料的實用性,把它應(yīng)用于具體的嵌套命名實體識別任務(wù)中。首先在已有中文實體識別語料基礎(chǔ)上人工構(gòu)建一個嵌套命名實體的測試語料,稱為人工標注語料,然后再用它來衡量自動構(gòu)建語料上訓(xùn)練出來的模型的識別性能。
4.1 人工標注語料
目前,中文命名實體識別[19]中常用的語料有微軟語料和《人民日報》語料,其中后者還標注了嵌套命名實體,因此為了減少標注工作量,把《人民日報》語料作為測試語料。不過,該語料只標注了二層嵌套結(jié)構(gòu),且都是命名實體。如嵌套命名實體“[中共/j 北京/ns 市委/n 宣傳部/n]nt”不能滿足對嵌套命名實體的定義,其正確的標注應(yīng)該是“[[[中共]nt [北京]ns市委]nt宣傳部]nt”。
本文采用自動抽取加人工調(diào)整的方式來產(chǎn)生中文嵌套命名實體測試語料,同時為了減少重復(fù)標注,只對實體而非一個實體的多個引用進行標注,具體過程為:
1)自動抽取。從1998年1月的《人民日報》語料中抽取出復(fù)雜命名實體,并去除重復(fù)的實體引用,保留其中的命名實體標注。如實體“[中共/j 北京/ns 市委/n 宣傳部/n]nt”提取后變成實體“[中共 [北京]ns 市委宣傳部]nt”。
2)人工調(diào)整。人工標注提取出的嵌套命名實體,通常是添加新的內(nèi)部實體。如第1步中的實體“[中共 [北京]ns 市委宣傳部]nt” 經(jīng)人工調(diào)整后為“[[[中共]nt [北京]ns 市委]nt 宣傳部]nt”。
標注后的《人民日報》中所有實體統(tǒng)計情況如表3所示,從表3可以看出,無嵌套結(jié)構(gòu)的外部實體中的組成與維基語料差別不大,大部分是地名(約47%)和人名(約43%),再加少量的組織名(約10%);有嵌套結(jié)構(gòu)的外部實體的組成與維基語料大為不同,大部分是組織名(約90%),再加少量的地名(約10%),而內(nèi)部實體的組成與維基語料基本一致,大部分是地名(約75%),小部分是組織名(約24%),還有極少數(shù)是人名(約1%)。

表3 《人民日報》語料嵌套命名實體統(tǒng)計
4.2 實驗方法
嵌套命名實體識別是從外部實體中識別出嵌套的內(nèi)部實體,因此首先需要從文本中識別出外部實體,然后再從外部實體中識別出內(nèi)部嵌套命名實體。由于本文的研究重點在于語料庫的自動構(gòu)建,而不在于方法本身,因此選擇較易實現(xiàn)的基于序列標注的CRF模型來實現(xiàn)最外層實體的識別。
4.2.1 嵌套命名實體識別方法
對于嵌套命名實體識別,采用由內(nèi)而外的層次模型方法,即使用多個CRF模型來識別由內(nèi)到外不同嵌套層次的實體。初步實驗結(jié)果表明,由內(nèi)而外的方法總體上優(yōu)于其他嵌套命名實體識別方法。
圖1列出了嵌套命名實體“[[[中共]nt [北京]ns 市委]nt宣傳部]nt”中各個層次的標簽,其中零層標簽是指最外層實體識別時的標簽(為一致起見省略了其上下文),其生成的模型稱為零層模型,一層到三層標簽是指在識別嵌套命名實體時各層模型采用的標簽,這3層模型可以統(tǒng)稱為多層模型。零層模型的訓(xùn)練和測試需要考慮外層實體所在的上下文,而多層模型是在外層實體的范圍內(nèi)進行訓(xùn)練和測試,與外層實體的上下文無關(guān),因而訓(xùn)練和測試速度較快。
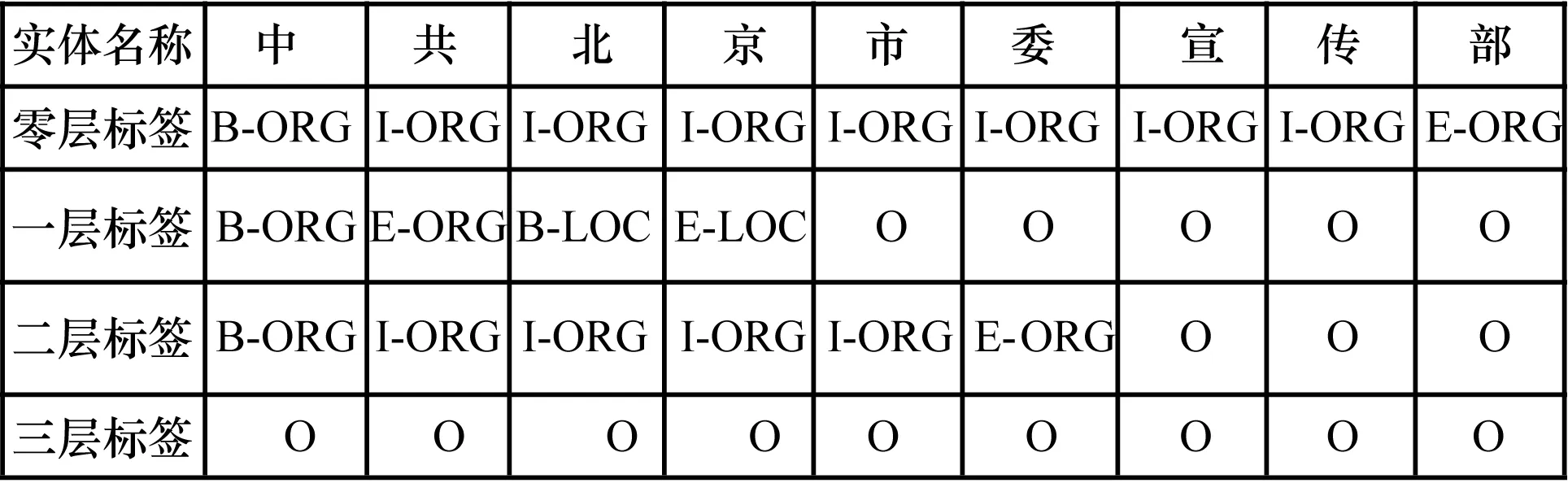
圖1 嵌套命名實體識別的各層標簽
4.2.2 CRF特征
以往的中文命名實體識別研究表明[20],以字為單位的CRF模型在資源最少(即不進行分詞)的情況下能取得較好的識別性能,因此本文也采用基于字符的CRF模型,且只采用了最基本的上下文特征,具體如下:
Cn(n=-2,-1,0,1,2)
CnCn+1(n=-1,0)
其中,C0代表當前的字,Cn代表當前位置之后第n位的字,CnCn+1代表第n位及其下一個字的組合。例如,對于序列“中華人民共和國”來說,當以字為單位時,若C0為“人”,則C1代表“民”,C-1代表“華”,而C0C1代表“人民”。
需要說明的是,訓(xùn)練零層模型時只有字特征,而訓(xùn)練多層模型時除包含字特征外,還包含所有下層的標簽作為特征,而在測試時多層模型則采用下層模型識別的結(jié)果作為其特征。
4.2.3 評估方法
采用常規(guī)的P、R、F1指數(shù)來評估實體識別的性能,P為準確率,R為召回率,F1為兩者的調(diào)和平均。實驗評估包含2個部分:一是交叉驗證,即和其他《人民日報》語料上的研究工作一樣[7]采用十折交叉方法,將《人民日報》語料劃分為10份,其中,1份作為測試集,另外9份作為訓(xùn)練集,總體性能取10次結(jié)果的平均值;二是跨庫驗證,即使用自動構(gòu)建語料庫訓(xùn)練出多層模型,然后在《人民日報》語料最外層實體識別出來的基礎(chǔ)上再進行嵌套命名實體的識別。
4.3 實驗結(jié)果
本文實驗結(jié)果主要包括以下方面:
1)外層實體識別的交叉驗證性能
表4列出了在《人民日報》語料上最外層實體識別的交叉驗證性能,同時也給出了各個類型的實體數(shù)量和占總數(shù)百分比。從表4可以看出,外層實體識別的總體F1性能達到了88%,且各個類型上的識別性能相差不大,盡管組織名實體所占比例較少(約20%)。
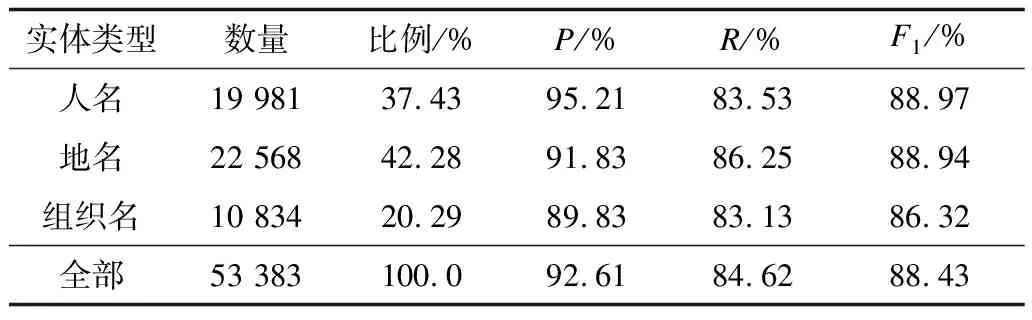
表4 外層實體識別的交叉驗證性能
2)嵌套命名實體識別的交叉驗證性能
表5列出了在《人民日報》語料上嵌套命名實體識別的交叉驗證性能,該性能是在外層實體識別的基礎(chǔ)上采用多層訓(xùn)練模型得到的結(jié)果。
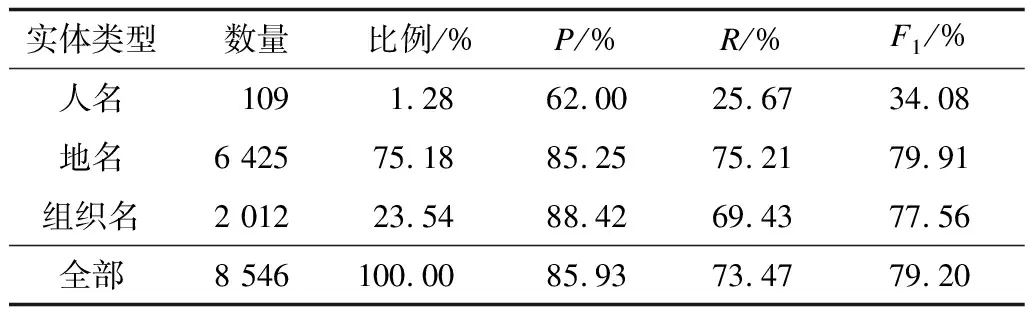
表5 嵌套命名實體識別的交叉驗證性能
從表5可以看出:
(1)嵌套命名實體識別的總體性能低于外層實體識別性能,特別是召回率較低,其主要原因是有些較長的外層實體在零層模型中沒有被召回,因而導(dǎo)致其中的嵌套命名實體在下一步也無法識別出來。
(2)人名實體的性能比地名和組織名實體的性能要低很多,這主要是由于其數(shù)量很少,但同時對總體性能的影響也微乎其微。
3)嵌套命名實體識別的跨庫驗證性能
利用維基條目自動構(gòu)建語料庫來訓(xùn)練多層模型,然后利用該模型來識別表4中已經(jīng)識別出的外層實體中的嵌套命名實體,從而通過實驗來驗證自動構(gòu)建語料庫的質(zhì)量。實驗結(jié)果如表6所示。
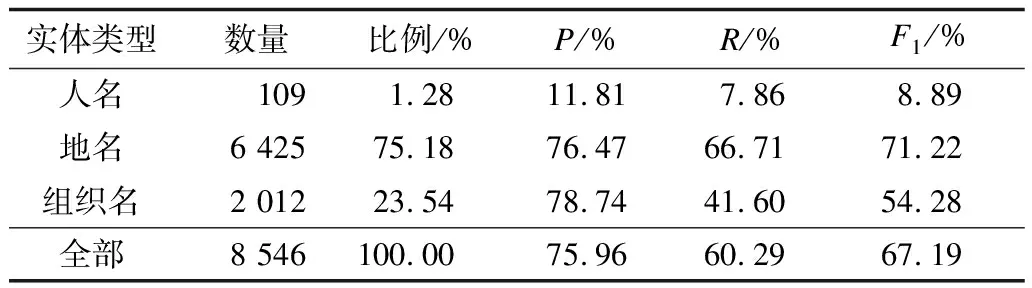
表6 嵌套命名實體識別的跨庫驗證性能
從表6可以看出:
(1)自動構(gòu)建語料在中文嵌套命名實體識別上取得了67.19%的F1值,雖然不如人工標注語料的性能高,但這是在沒有任何人工標注的前提下取得的結(jié)果。
(2)與人工標注語料相比,召回率仍然偏低,這可能是由于維基語料中還有不少噪音,即遺漏了需標注的嵌套命名實體,這也是今后進一步研究的方向。
4)與其他嵌套命名實體識別系統(tǒng)的性能比較
表7列出了各中文嵌套命名實體識別系統(tǒng)在《人民日報》語料上的實驗結(jié)果。需要指出的是,該結(jié)果僅供參考,主要原因是:
(1)文獻[6-7,10]采用的《人民日報》嵌套命名實體語料沒有任何的調(diào)整,它只標注了嵌套命名實體,因此只有二層嵌套,而本文重新標注了多層的嵌套命名實體。
(2)文獻[6-7]給出了所有實體(包含外層實體)的識別性能,而文獻[10]的計算方法和本文的方法相近,只考慮了嵌套命名實體的識別性能。
總體而言,嵌套命名實體的識別性能還不夠理想,今后還需要進一步的研究。
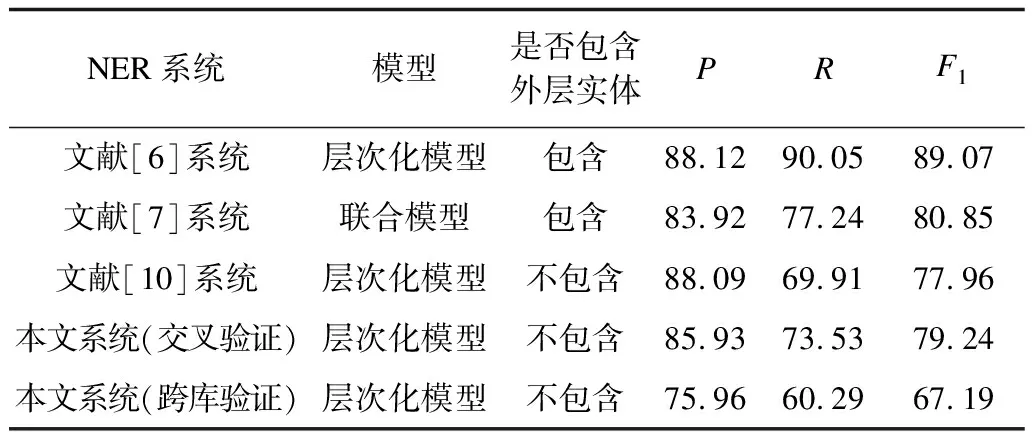
表7 中文嵌套命名實體識別系統(tǒng)的性能比較 %
5 結(jié)束語
本文在中文維基百科條目實體分類的基礎(chǔ)上,通過匹配、過濾和匯聚3個階段,自動構(gòu)建了一個大規(guī)模的中文嵌套命名實體識別語料庫。在人工標注的《人民日報》中文嵌套命名實體識別上的實驗結(jié)果表明,雖然自動構(gòu)建語料的性能不能與手工標注語料的性能相媲美,但是維基語料具有規(guī)模大和領(lǐng)域廣的特點,能夠適應(yīng)寬泛領(lǐng)域上的中文嵌套命名實體識別任務(wù)。本文的不足之處在于,目前自動構(gòu)建的維基百科語料在實驗性能上召回率不高,主要原因是維基條目中的部分嵌套命名實體沒有被自動標注出來,即標全率不高。因此,下一步的研究包括:改善該語料的標全率,使用更多的百科資源是一個有效的途徑;將維基百科語料進行領(lǐng)域劃分,從而更好地適應(yīng)不同目標領(lǐng)域的中文嵌套命名實體識別任務(wù)。
