多層卷積特征融合的行人檢測
2018-11-17 01:26:22呂俊奇邱衛根張立臣李雪武
計算機工程與設計 2018年11期
呂俊奇,邱衛根,張立臣,李雪武
(廣東工業大學 計算機學院,廣東 廣州 510006)
0 引 言
行人檢測在車輛輔助駕駛、智能視頻監控、人機交互等領域具有廣泛的應用[1],也是計算機視覺中極具挑戰問題。
Dalal等[2]提出了稠密的、重疊的、固定尺度的HOG局部特征描述子描述人體輪廓。該描述子借鑒了旋轉尺度不變特征(scale invariant feature transform,SIFT)中運用梯度方向直方圖表示目標的思想。
DPM(deformable parts model)[3]算法采用了傳統的滑動窗口檢測,通過構建尺度金字塔在多種尺度空間上搜索候選目標,對目標的形變具有很強的魯棒性。
Dollar等[4]提出融合積分圖和原始HOG特征的多通道特征(aggregate channel features,ACF),利用級聯決策樹構建AdaBoost分類器,進一步提高了行人檢測精度。
從2014年開始,基于深度學習的目標檢測取得了巨大的突破,以R-CNN[5]為代表的目標檢測框架在VOC目標檢測數據集上取得了較好的成績,通過結合候選區域提取和卷積神經網絡分類,利用卷積神經網絡強大的學習特征能力極大提高了特征提取的能力。
針對目標的多尺度問題,R-CNN使用Selective Search[6]生成多尺度的目標假設區域,然后將這些建議歸一化CNN支持的大小(例如224×224)。然而,從計算的角度來看,這種做法非常低效。最新的Faster RCNN[7]通過區域生成網絡(RPN)來共享卷積運算,該網絡實現了網絡端到端的快速高效訓練。RPN通過使用一組固定大小的濾波器在卷積特征圖上滑動,來產生多種尺度的目標候選區域。然而這種機制造成了可變大小的目標和固定過濾器感受野之間的匹配不一致。
特征金字塔是多尺度的行人檢測的常用技巧,但是構建金字塔會帶來存儲空間的消耗和計算量的巨大開銷,因此目前基于深度學習的行人檢測回避了使用特征金字塔進行特征表示。針對行人的多尺度問題,本文嘗試利用卷積神經網絡的金字塔結構構建內在的多尺度,并且引入全局和局部上下文信息,提高算法對小目標以及遮擋嚴重的行人檢測能力。
1 行人檢測系統架構
目標檢測的問題被定義為確定目標在圖像中的位置以及每個目標所屬的類別。上述定義為我們提供了如何解決這樣一個問題的線索:通過從圖像生成目標候選區域,然后將每個候選區域分類到不同的對象類別。在某種程度上,這種兩步解決方案與人類看到事物的注意機制相匹配,這首先是對整個場景進行粗略掃描,然后著重于我們感興趣的區域。
與Faster RCNN類似,我們的行人檢測算法也采用注意力機制,由兩大模塊組成:候選框提取模塊和檢測模塊。其中,候選框提取模塊是全卷積神經網絡,用于提取目標候選區域;檢測模塊針對區域生成模塊提取的候選區域識別并定位目標。
1.1 特征提取
傳統的目標檢測,構建圖像金字塔,將圖像放大或縮小為一組尺寸,然后提取特征,這樣帶來了巨大的計算量,在深度卷積網絡領域這種機制是無法接受的。然而,圖像金字塔不是計算多尺度特征表示的唯一方法。深度卷積網絡逐層計算層次化特征,子采樣層的特征層次結構具有固有的多尺度金字塔屬性。這種網絡內在的特征層次結構產生于不同空間分辨率的特征圖,我們使用特征上采樣替代輸入圖像上采樣,改變特征圖的尺度大小,這表明可以減少內存和計算成本。
深度卷積神經網絡的結構如圖1所示。

圖1 深度卷積神經網絡的結構
1.1.1 采樣
深度卷積網絡,通過多個卷積層提取圖像的特征,通過多個池化層不斷增大卷積核的感知野。這種機制使得高層的卷積具有較高層次的語義特征,但多次池化使得目標物體的尺寸不斷縮小。例如分辨率為32×32的物體,經過VGG16[8]的多層卷積之后,最后一個卷積層獲得特征圖分辨大小為1×1。深層卷積網絡中,小物體經過多層卷積和池化之后,特征圖逐步變小導致包含的信息太少,從而引入了分類錯誤。
HyperNet[9]提出對高層卷積采用去卷積,通過插值上采樣擴大特征圖的大小,使小物體能夠產生較強響應的較大區域。
1.1.2 特征融合
深度卷積網絡逐層計算層次化特征,產生不同空間分辨率的特征圖的同時。擁有較大特征圖的淺層卷積更注重目標的細節信息,但是包含的目標語義信息更少;卷積網絡中深層卷積更注重目標的語義信息,但經過多次池化操作之后,目標在特征圖上的分辨率很小。通過卷積層的特征融合,使得提取的特征既可以獲得高層語義信息,還可以得到小目標物體的更多信息。
1.2 候選區域生成模塊
給定輸入圖像(假設分辨率為600×1000),經過卷積操作得到最后一層的卷積特征圖,分辨率縮小了16倍。與傳統的滑動窗口類似,在這個特征圖上使用3×3的卷積核與特征圖進行卷積,VGG16的最后一層卷積層共有512個特征圖,那么這個3×3的區域卷積后可以獲得512維的特征向量,輸出到兩個并行的全連接層,分別用于分類和邊框回歸。
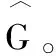
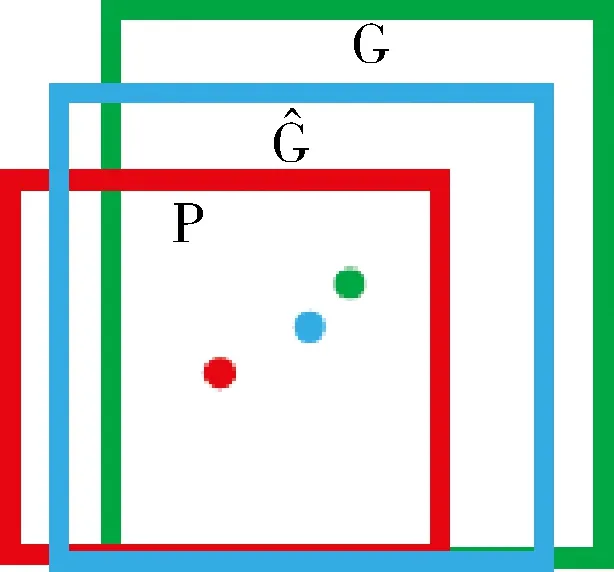
圖2 邊框回歸
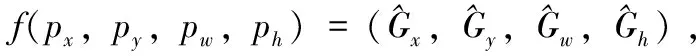
(1)先做平移(△x,△y),△x=pwdx(p),△y=phdy(p)即
(1)
(2)
(2)然后做尺度縮放(sw,sh),sw=pwdx(p),sh=phdy(p)
(3)
(4)
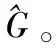
tx=(Gx-px)/pw
(5)
ty=(Gy-py)/ph
(6)
tw=log(Gw/pw)
(7)
th=log(Gh/ph)
(8)
(9)
1.3 目標檢測模塊
目標檢測網絡將整個圖像和一組帶類別和位置標記的目標作為輸入。網絡首先用多個卷積層以及池化層處理整個圖像,以產生最后的卷積特征圖。
采用FC-Dropout-FC-Dropout管道[10]是目標檢測的一個簡單而實用的做法。在FC層之前,我們添加一個Conv層(3×3×63),除了增強分類器的性能之外,該操作將特征圖的維度降低了一半,減少了計算量。與區域生成網絡相似,目標檢測網絡為每個區域候選框添加了的兩個全連接層。不同之處在于每個候選框都有N+1個輸出得分和4×N個邊界框回歸位置偏移(其中N為類別的數量,再加上背景類)。通過輸出層對每個候選框評分和調整。
根據它們的分數,對區域采用非極大值抑制算法[11],抑制高度重疊的候選區域,從而降低了冗余和減少了算法的計算量。
2 實 驗
2.1 數據集和評估指標
我們分別在VOC 2007數據集和Brainwash數據集[12]上評估了我們的方法。VOC 2007數據集中包含9964張帶有多種類別標記和目標位置的圖片,訓練樣本圖片5012張,測試樣本4952張。包含20種目標類別的VOC數據集一般作為通用目標檢測的數據集,其中包含的行人目標的數目為4690。同時我們還在更大的Brainwash數據集上進行實驗并驗證我們的方法。
Brainwash數據集從視頻片段中提取圖像,提取時間間隔為100 s,訓練集和測試集的樣本圖片沒有任何重疊,總共包含11 917張圖像和91 146個已標記的行人目標。其中訓練集包含了82 906個實例,測試集、驗證集分別包含4922個和3318個實例。
將分類器檢測到的行人目標與XML標記文件的標記矩形框對比,如果重合百分之七十以上判定為目標檢測正確。統計所有的檢測結果,使用P-R曲線衡量分類器的性能,統計分類器的準確率(precision)和召回率(recall),最后利用平均準確率(mean average precision,mAP)來衡量分類器的性能。
2.2 實驗結果以及對比分析
實驗基于caffe版本的Faster RCNN,使用VGG16架構的卷積網絡。利用在ILSVRC2012[13]上預訓練模型,通過遷移學習的方法在VOC數據集和Brainwash數據集重新訓練并評估我們的方法。
2.2.1 特征融合
由于CNN中的下采樣操作,不同卷積特征層的尺寸大小不同。為了融合多個卷積圖,需要將卷積特征圖規范化統一為相同尺寸大小。我們采取不同的采樣策略來融合不同層的特征。如圖1所示,對較低層Conv3_3進行最大池化,減小特征圖的大小。對于較高的卷積層,我們使用去卷積操作(Deconv)進行上采樣增大特征圖。將卷積層conv3_3,conv4_3,conv5_3融合后的特征輸入到后面的RPN模塊。如表1所示,增加特征融合使得VOC2007的檢測結果增加了2.9個百分點。

表1 多層卷積特征融合前后對比
2.2.2 上下文信息
在Faster RCNN算法中,RPN模塊獲得的候選區域,采用一種特殊的池化方法(RoI Pooling),使得在不同大小的圖像上獲得相同維度的卷積特征。如圖3所示,我們除了對目標候選區域進行RoI Pooling操作之外,我們還對整個圖像采用RoI Pooling操作來獲得全局上下文信息。相應的通過放大目標候選區域,獲得目標局部上下文信息,我們將放大比例設置為1.5倍。全局和局部上下文特征僅僅被用來目標分類,不參加邊框回歸。
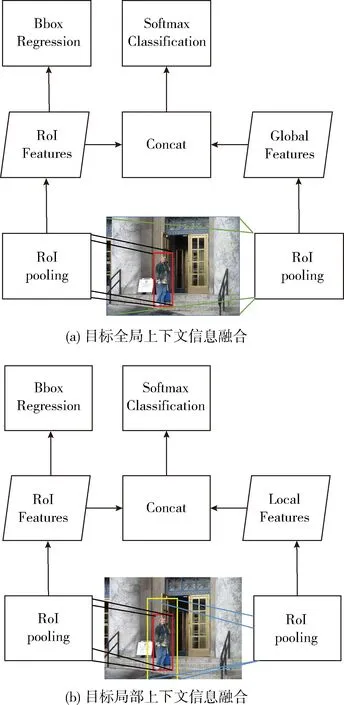
圖3 上下文信息融合
如表2所示,增加全局上下文信息和局部上下文信息使得檢測結果分別提升了1.5個以及1.1個百分點。融合多層卷積特征和目標上下文信息之后,相比原始的Faster RCNN算法,我們方法的檢測結果從69.9提升到74.2,提高了4.3個百分點。

表2 上下文信息融合前后對比
不同于VOC數據集,Brainwash數據集包含了大量遮擋比較嚴重的行人目標,而且行人的尺度比較小。實驗表明改變非極大值抑制的閾值,Faster RCNN算法的檢測結果相差很大。通過分析3種不同的nms閾值的Faster RCNN的結果以及我們的算法在Brandwish數據集上的結果,如圖4所示。其中nms的閾值為0.75時,Faster RCNN對同一個目標會產生多個連續預測結果,導致了較差的準確率。當nms的閾值為0.25時,Faster RCNN在Brainwash數據集的測試集上取得最好的檢測結果,但仍然落后于我們的方法。部分檢測結果對比如圖5所示,在當行人目標較小、較模糊時,原始的Faster RCNN算法存在大量的行人目標漏檢問題,而我們的方法在這方面好很多。
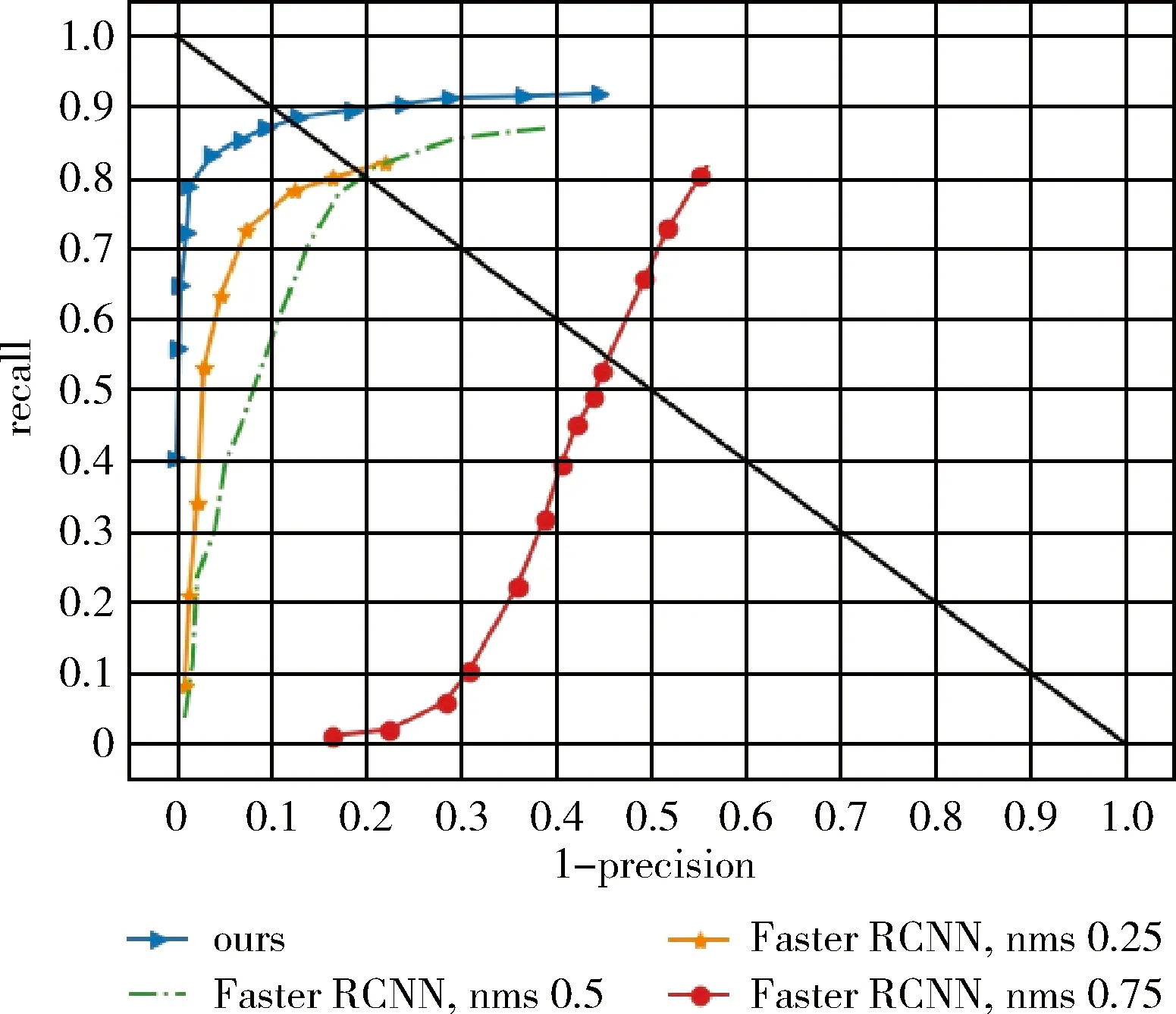
圖4 在Brainwash數據集的測試結果

圖5 在Brandwish數據集上部分檢測結果
3 結束語
本文提出的方法在Faster RCNN算法的基礎上,融合了多尺度以及目標全局和局部上下文信息。測評結果表明,相比于Faster RCNN算法,所提出的方法對不同尺寸、遮擋嚴重的目標檢測效果均有明顯的提升。模型融合多層卷積特征后,對于多尺度目標的平均檢測準確率提升了2.9%。在包含更多遮擋目標的Brainwash數據集的測評表明,融合上下文的檢測網絡相比原始的Faster RCNN,平均準確率提升了4.3%。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
電測與儀表(2015年5期)2015-04-09 11:30:52
