基于近紅外光譜波長優(yōu)選的土壤有機質(zhì)含量預(yù)測研究
2018-11-13 05:31:20張小鳴湯寧
現(xiàn)代電子技術(shù) 2018年22期
張小鳴 湯寧


摘 要: 近紅外光譜技術(shù)是檢測土壤信息的有效工具,為了提高預(yù)測模型的準(zhǔn)確度和建模效率,需要對波長進(jìn)行優(yōu)選。提出SiPLS?GA?SPA特征波長提取方法,即協(xié)同區(qū)間偏最小二乘算法(SiPLS)、遺傳算法(GA)和連續(xù)投影算法(SPA)對土壤有機質(zhì)特征波長進(jìn)行梯度提取,最終從1 050個波長中提取9個土壤有機質(zhì)的特征波長。利用偏最小二乘回歸(PLSR)和支持向量機回歸(SVMR)建立6種基于特征波長的土壤有機質(zhì)含量預(yù)測模型。結(jié)果表明:SiPLS?GA?SPA?SVMR模型的預(yù)測結(jié)果為RMSEP=1.15,R2=0.91,優(yōu)于其他模型;SiPLS?GA?SPA特征波長提取方法能夠簡化預(yù)測模型,提高模型預(yù)測精度,為開發(fā)便攜式近紅外光譜土壤養(yǎng)分檢測儀提供理論基礎(chǔ)。
關(guān)鍵詞: 近紅外光譜; 特征波長; 協(xié)同區(qū)間偏最小二乘; 遺傳算法; 連續(xù)投影算法; 支持向量機回歸
中圖分類號: TN929?34 文獻(xiàn)標(biāo)識碼: A 文章編號: 1004?373X(2018)22?0126?04
Abstract: The near infrared spectroscopy technology is an effective tool for detecting soil information, and wavelength optimization is necessary to improve the accuracy and modeling efficiency of the prediction model. Therefore, an SiPLS?GA?SPA feature wavelength extraction method is proposed. The synergy interval partial least squares (SiPLS), genetic algorithm (GA) and successive projection algorithm (SPA) are combined to conduct gradient extraction for feature wavelengths of soil′s organic matter, and 9 feature wavelengths of soil′s organic matter are extracted from 1050 wavelengths. The partial least squares regression (PLSR) and support vector machine regression (SVMR) are adopted to establish 6 soil′s organic matter content prediction models based on feature wavelengths. The results show that, the prediction results of the SiPLS?GA?SPA?SVMR model (RMSEP=1.15, R2=0.91) are superior to other models, and the SiPLS?GA?SPA feature wavelength extraction method can simplify the prediction model and improve the prediction accuracy of the model, which provides a theoretical basis for the development of the portable near infrared spectroscopy soil nutrient detector.
Keywords: near infrared spectrum; feature wavelength; synergy interval partial least squares; genetic algorithm; successive projection algorithm; support vector machine regression
可見/近紅外光譜區(qū)幾乎包含了有機物中所有含氫基團(tuán)的信息,信息量極為豐富,能夠?qū)崿F(xiàn)對物質(zhì)的定性和定量分析[1]。光譜檢測技術(shù)具有分析速度快、多組分同時測定、非破壞性分析、低分析成本和操作簡單等顯著特點[2]。能夠適應(yīng)現(xiàn)代精準(zhǔn)農(nóng)業(yè)(Precision Agriculture)對土壤養(yǎng)分信息實時準(zhǔn)確、快速、大范圍獲取的要求。土壤有機質(zhì)(SOM)是評價土壤肥力高低的重要指標(biāo),快速有效測定土壤有機質(zhì)含量,對指導(dǎo)農(nóng)業(yè)耕種中作物種植和施水施肥都有很大指導(dǎo)意義。
本文提出協(xié)同區(qū)間偏最小二乘(SiPLS)、遺傳算法(GA)和連續(xù)投影算法(SPA)對土壤有機質(zhì)的特征波長進(jìn)行梯度提取,從1 050個波長中選擇出9個土壤有機質(zhì)的特征波長,利用偏最小二乘回歸(PLSR)、支持向量機回歸(SVMR)建立基于特征波長的土壤有機質(zhì)含量預(yù)測模型,以期獲得計算量小、精度高的預(yù)測模型,為研究便攜式近紅外光譜土壤養(yǎng)分檢測儀提供技術(shù)參考。
1 實驗部分
土壤樣本光譜數(shù)據(jù)來源于網(wǎng)絡(luò)(http://www.models.life.ku.dk/NIRsoil),包含了在瑞典北部阿比斯庫地區(qū)進(jìn)行的一項長期田間試驗采集到的108個土壤樣本的近紅外吸光度光譜數(shù)據(jù),光譜波長區(qū)間為400~2 498 nm,光譜分辨率為2 nm,共1 050個波長點,其中土壤有機質(zhì)含量采用550 ℃條件下的灼燒失重法測定[3]。
2 結(jié)果與討論
2.1 異常樣本剔除與樣本劃分
土壤樣本采集和光譜數(shù)據(jù)獲取過程中可能會產(chǎn)生異常樣本,剔除異常樣本能夠提高模型的穩(wěn)定性和預(yù)測精度,采用蒙特卡洛異常值剔除法[4]剔除異常樣本,樣本預(yù)測誤差的平均值和標(biāo)準(zhǔn)偏差中有一項明顯大于其他樣本的可視為異常樣本。共剔除異常樣本6個,剔除后總樣本數(shù)變?yōu)?02。
具有代表性的校正集樣本能夠加速模型回歸,提高模型預(yù)測精度。利用SPXY[5]算法計算樣本光譜吸光度與待測有機質(zhì)含量之間的歐氏距離,相比于其他樣本劃分算法,SPXY考慮光譜矩陣的同時能將預(yù)測屬性也考慮在內(nèi)。有效覆蓋多維向量空間,改善模型預(yù)測能力[6]。SPXY算法劃分校正集樣本82個,預(yù)測集樣本20個,樣本的有機質(zhì)含量統(tǒng)計數(shù)據(jù)結(jié)果如表1所示。
2.2 光譜數(shù)據(jù)預(yù)處理
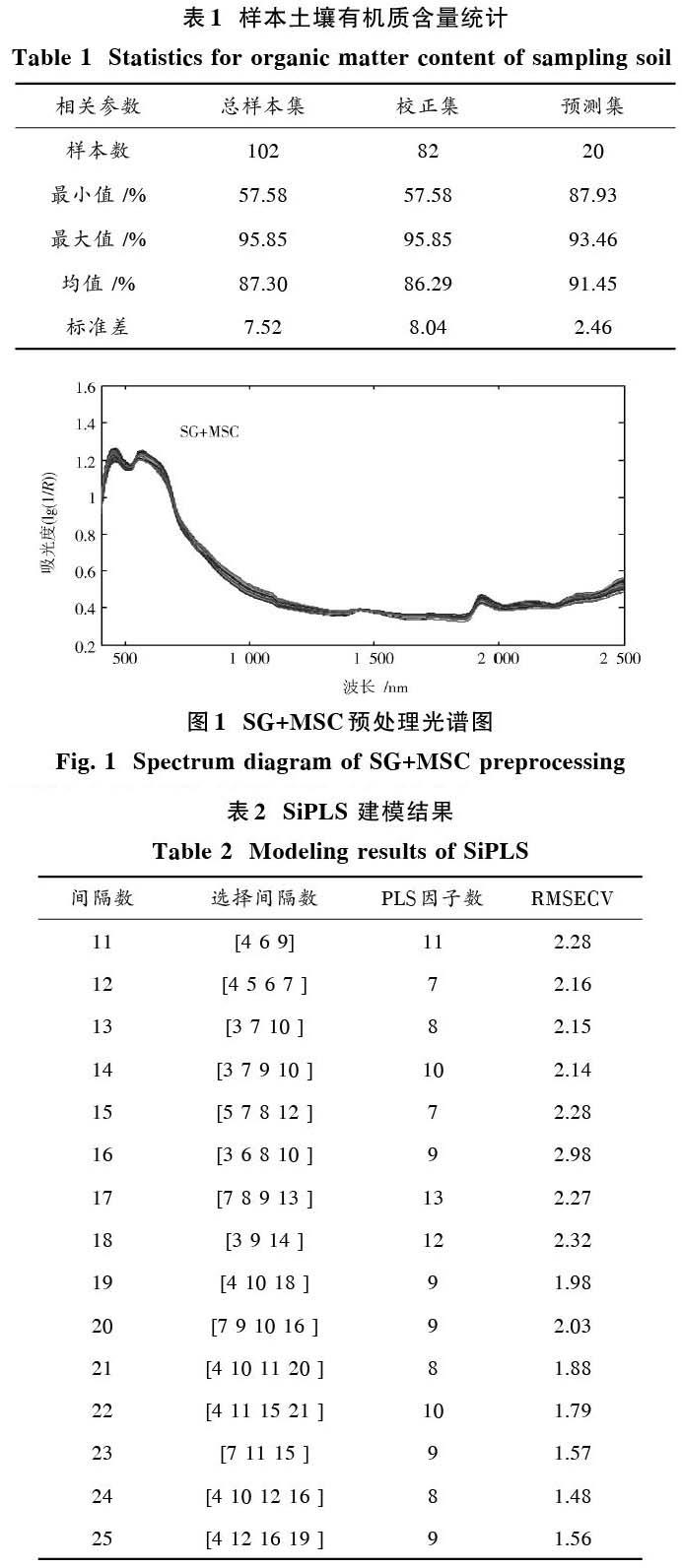
數(shù)據(jù)預(yù)處理技術(shù)能解決光譜數(shù)據(jù)中噪聲的抑制和消除,增強光譜吸收特征,提高模型性能。經(jīng)反復(fù)對比研究,采用平滑點數(shù)為5、多項式階數(shù)為2的Savitzky?Golay(SG)平滑對光譜數(shù)據(jù)進(jìn)行預(yù)處理,能消除光譜基線漂移和傾斜噪聲。由于土壤顆粒大小不均勻,其漫反射光譜中包含有光散射造成的噪聲,多元散射校正(Multiple Scattering Correction,MSC)將光譜中散射信號與化學(xué)吸收信息進(jìn)行分離,消除在漫反射光譜測量中由于樣本顆粒不均勻造成的樣本光譜差異[7],故對SG平滑后光譜數(shù)據(jù)再利用MSC進(jìn)行預(yù)處理。圖1為SG結(jié)合MSC預(yù)處理后的光譜曲線圖。
2.3 特征波長提取
SiPLS是將光譜數(shù)據(jù)劃分為一定數(shù)目的等長子區(qū)間,計算2,3或4個區(qū)間所有可能組合的PLS模型[8],在土壤有機質(zhì)特征區(qū)間不確定的情況下,對子區(qū)間的劃分?jǐn)?shù)進(jìn)行優(yōu)化,確定特征子區(qū)間,研究中將全部波長劃分為11~25個子區(qū)間。表2為不同區(qū)間數(shù)下SiPLS模型所對應(yīng)的最小交互驗證均方根誤差(RMSECV),將其最小的區(qū)間組合作為最優(yōu)選擇。由表2可知,當(dāng)全部波長劃分為24個子區(qū)間時,每個子區(qū)間44個波長,4個子區(qū)間分別為4,10,12,16組合后建立的PLS模型RMSECV值最小為1.48,即選擇特征區(qū)間波段為664~752 nm,1 192~1 280 nm,1 368~1 456 nm和1 720~1 808 nm。它們在全部光譜中的位置如圖2所示。
近紅外光譜都具有一定的連續(xù)性,有效波長點附近的波長點對預(yù)測的土壤養(yǎng)分也有較強解釋性和化學(xué)意義[9]。SiPLS算法從1 050個波長中篩選出4個子區(qū)間共176個波長,能夠很好地反映土壤有機質(zhì)含量,也很大程度減少了波長數(shù),但SiPLS算法優(yōu)選出的是波長區(qū)間,相鄰波長變量之間仍然存在較強共線性和冗余。遺傳算法(GA)是一種全局概率搜索算法,借鑒生物進(jìn)化和自然選擇機制,利用選擇、交換和突變等算子的操作使目標(biāo)函數(shù)值最優(yōu)的變量“優(yōu)勝劣汰”[10]。遺傳算法進(jìn)行波長選擇是產(chǎn)生大量的波長組合,能很好保留波長之間的協(xié)同效應(yīng)。因此利用GA進(jìn)一步篩選,GA主要參數(shù)設(shè)置:最大繁殖代數(shù)為100,交叉概率為0.5,變異概率為0.01,由于遺傳算法存在一定的隨機性,故運算10次以消除影響。圖3為各變量被選頻率圖。頻數(shù)大于黑色虛線的變量為入選變量,篩選波長變量53個。但被選變量仍然較多,還存在一定的冗余信息。連續(xù)投影算法(SPA)是利用向量的投影分析,尋找含有最低限度冗余信息的變量組,能有效克服光譜數(shù)據(jù)的共線性和冗余,減少建模變量,降低建模復(fù)雜度[11]。利用SPA在GA的基礎(chǔ)上進(jìn)一步提取與有機質(zhì)相關(guān)的特征波長,提取結(jié)果如圖4所示。
2.4 預(yù)測模型建立與分析
2.4.1 模型的評價指標(biāo)
模型評價指標(biāo)包括衡量自變量和因變量之間線性相關(guān)程度的決定系數(shù)(R2),反映樣本預(yù)測值和實測值之間誤差大小的預(yù)測均方根誤差(RMSEP)和能夠評價模型預(yù)測能力的相對分析誤差(RPD)。
2.4.2 偏最小二乘回歸
偏最小二乘回歸(PLSR)是應(yīng)用廣泛的定量分析方法,將典型相關(guān)性分析、主成分分析和回歸分析結(jié)合。盡可能多地保留光譜矩陣中有用信息的同時保證與待測成分的相關(guān)程度最大。能充分反映出波長與待測成分之間的相互關(guān)系[12]。構(gòu)建基于SiPLS優(yōu)選波長區(qū)間,SiPLS?GA和SiPLS?GA?SPA優(yōu)選特征波長的PLSR模型,采用留一交叉驗證法防止模型過擬合,需要優(yōu)化的參數(shù)是潛在變量(Latent Variables,LVs)個數(shù),并將預(yù)測集20個樣本作為建立的模型輸入,結(jié)果如表3所示。
2.4.3 支持向量機回歸(SVMR)
對于土壤養(yǎng)分的近紅外模型構(gòu)建,線性建模方法已經(jīng)有了廣泛應(yīng)用,是目前的主流方法,支持向量機算法(SVM)是一種基于核函數(shù)的學(xué)習(xí)算法,在分類和回歸中有很廣泛的應(yīng)用[13]。研究采用基于徑向基核函數(shù)(RBF)的SVMR算法對土壤的有機質(zhì)含量進(jìn)行預(yù)測分析,同樣建立了3種基于特征波長的SVMR土壤有機質(zhì)預(yù)測模型,并將預(yù)測集20個樣本作為建立的模型輸入進(jìn)行預(yù)測,結(jié)果如表4所示,核函數(shù)的懲罰參數(shù)c和核參數(shù)g采用網(wǎng)格法進(jìn)行優(yōu)化,最終選擇c=100;g=0.000 1。
比較建立的6種模型發(fā)現(xiàn)SVMR預(yù)測性能要優(yōu)于PLSR,可能是因為土壤的形成和發(fā)育過程復(fù)雜,土壤中的有機質(zhì)含量與光譜特征之間存在著非線性關(guān)系。在兩種回歸模型中基于SiPLS?GA?SPA優(yōu)選特征波長的預(yù)測模型要優(yōu)于其他兩種,且SiPLS?GA優(yōu)于SiPLS,說明由于SiPLS提取的是連續(xù)波長區(qū)間,相鄰波長之間仍然存在較強的共線性, GA進(jìn)一步選擇后能夠消除一部分冗余波長,但選擇的波長數(shù)還有較多冗余信息仍然存在,SPA算法擅長消除變量間的冗余。所以三種算法聯(lián)用時各自優(yōu)缺點能夠得到互補,提取出最有效的土壤有機質(zhì)特征波長。
3 結(jié) 語
采用SiPLS?GA?SPA方法選擇土壤有機質(zhì)的特征波長,將原始的1 050個波長減少到9個,減少了模型的計算量,簡化了模型的復(fù)雜度,SiPLS算法能夠減少建模變量同時能夠提高模型的穩(wěn)定性。但由于近紅外光譜高度重疊的特性,相鄰變量之間有很強的共線性。因此使用GA算法對SiPLS選擇的波長區(qū)間進(jìn)行變量的組合優(yōu)化,篩選出最有效的變量組合。在此基礎(chǔ)上利用SPA算法進(jìn)一步消除冗余,減少建模變量,結(jié)合SVMR算法預(yù)測土壤有機質(zhì)取得較高的精度,為便攜式近紅外光譜土壤養(yǎng)分檢測儀提供理論支撐。
參考文獻(xiàn)
[1] 宋海燕.土壤近紅外光譜檢測[M].北京:化學(xué)工業(yè)出版社,2013.
SONG Haiyan. The soil′s near infrared spectroscopy detection [M]. Beijing: Chemical Industry Press, 2013.
[2] 劉燕德,熊松盛,劉德力.近紅外光譜技術(shù)在土壤成分檢測中的研究進(jìn)展[J].光譜學(xué)與光譜分析,2014,34(10):2639?2644.
LIU Yande, XIONG Songsheng, LIU Deli. Application of near infrared reflectance spectroscopy technique (NIRS) to soil attributes research [J]. Spectroscopy and spectral analysis, 2014, 34(10): 2639?2644.
[3] RINNAN R, RINNAN A. Application of near infrared reflectance (NIR) and fluorescence spectroscopy to analysis of microbiological and chemical properties of arctic soil [J]. Soil biology & biochemistry, 2007, 39(7): 1664?1673.
[4] 楊峰,張勇,諶俊旭,等.高光譜數(shù)據(jù)預(yù)處理對大豆葉綠素密度反演的作用[J].遙感信息,2017,32(4):64?69.
YANG Feng, ZHANG Yong, CHEN Junxu, et al. Effects of hyperspectral data pretreatment on model inversion of soybean chlorophyll density [J]. Remote sensing information, 2017, 32(4): 64?69.
[5] 陳奕云,齊天賜,黃穎菁,等.土壤有機質(zhì)含量可見?近紅外光譜反演模型校正集優(yōu)選方法[J].農(nóng)業(yè)工程學(xué)報,2017,33(6):107?114.
CHEN Yiyun, QI Tianci, HUANG Yingjing, et al. Optimization method of calibration dataset for VIS?NIR spectral inversion model of soil organic matter content [J]. Transactions of the Chinese Society of Agricultural Engineering, 2017, 33(6): 107?114.
[6] GALV?O R K H, ARAUJO M C U, JOS? G E, et al. A method for calibration and validation subset partitioning [J]. Talanta, 2005, 67(4): 736?740.
[7] 王瑛瑛.土壤有機質(zhì)近紅外光譜分析及相關(guān)軟件開發(fā)[D].合肥:中國科學(xué)技術(shù)大學(xué),2014.
WANG Yingying. The near?infrared spectroscopy analysis of organic matter and related software development [D]. Hefei: University of Science and Technology of China, 2014.
[8] YANG M, CHEN Q, KUTSANEDZIE F Y H, et al. Portable spectroscopy system determination of acid value in peanut oil based on variables selection algorithms [J]. Measurement, 2017, 103: 179?185.
[9] 楊海清,祝旻.基于可見?近紅外光譜特征波長選擇的土壤有機質(zhì)快速檢測研究[J].紅外,2015,36(2):42?48.
YANG Haiqing, ZHU Min. Study of rapid detection of soil organic matter based on characteristic wavelength selection of visible?near infrared spectra [J]. Infrared, 2015, 36(2): 42?48.
[10] 賓俊,范偉,周冀衡,等.智能優(yōu)化算法應(yīng)用于近紅外光譜波長選擇的比較研究[J].光譜學(xué)與光譜分析,2017,37(1):95?102.
BIN Jun, FAN Wei, ZHOU Jiheng, et al. Application of intelligent optimization algorithms to wavelength selection of near?infrared spectroscopy [J]. Spectroscopy and spectral analysis, 2017, 37(1): 95?102.
[11] 章海亮,羅微,劉雪梅,等.應(yīng)用遺傳算法結(jié)合連續(xù)投影算法近紅外光譜檢測土壤有機質(zhì)研究[J].光譜學(xué)與光譜分析,2017,37(2):584?587.
ZHANG Hailiang, LUO Wei, LIU Xuemei, et al. Measurement of soil organic matter with near infrared spectroscopy combined with genetic algorithm and successive projection algorithm [J]. Spectroscopy and spectral analysis, 2017, 37(2): 584?587.
[12] MORELLOS A, PANTAZI X E, MOSHOU D, et al. Machine learning based prediction of soil total nitrogen, organic carbon and moisture content by using VIS?NIR spectroscopy [J]. Biosystems engineering, 2016, 152: 104?116.
[13] ROSSEL R A V, BEHRENS T, GUERRERO C, et al. Using data mining to model and interpret soil diffuse reflectance spectra [J]. Geoderma, 2010, 158(1): 46?54.
