HSMA:面向物聯網異構數據的模式分層匹配算法
2018-11-13 05:07:02郭忠文仇志金
計算機研究與發展 2018年11期
郭 帥 郭忠文 仇志金
(中國海洋大學信息科學與工程學院 山東青島 266100) (guoshuaiouc@163.com)
據物聯網行業統計數據顯示,2014年中國物聯網產業規模達到5 800億元,同比增長18.46%.2015 年全球物聯網市場規模達到 624 億美元,同比增長 29%.到 2018 年全球物聯網設備市場規模有望達到 1 036 億美元,2019 年新增的物聯網設備接入量將從2015 年的16.91 億臺增長到30.54 億臺[1].隨著物聯網的快速發展以及物聯網平臺的逐步成熟,無處不在的末端設備和設施,如智能傳感器、移動終端等通過物聯網連接在一起,萬物互聯已經成為必然趨勢.隨之興起的物聯網技術被廣泛應用到各個領域,產生了海量的異構數據.Mccrory[2]在2010年提出了“數據引力”的概念,將數據、軟件應用、接口服務等比作星體,含有各自的質量和密度,數據質量不斷地增加并且遠大于其他“星體”,而其他“星體”都將被巨大的引力吸引過來并以數據“星體”為中心.由此可見,對于物聯網異構數據,其處理技術的發展將會直接影響整個物聯網技術的發展和進步.目前大部分的異構數據都是獨立、分散地存儲于各個地區,形成了大量信息孤島,由結構化數據(如關系型數據庫)、半結構化數據(如XML,HTML)和非結構化數據(如NoSQL數據庫、圖片、視頻)等多種形式組成,如何通過“2次采集”將這些信息孤島互聯起來受到人們的關注.
模式匹配技術在數據互聯過程中發揮著巨大的作用[3],盡管目前對物聯網異構數據可以通過制定統一數據接口標準的方式進行互聯,但在實際應用中卻很難實現,因為對于已經存在的海量數據存儲模式的改造成本是巨大的,可以說數據異構的問題是不可避免的,數據模式匹配技術為解決以上問題提供了一個良好的解決方案.模式匹配是一個構建源模式和目標模式中元素間映射關系的過程,而傳統的模式匹配操作大多都是由IT技術人員手工完成,隨著數據規模的擴大以及模式復雜度的提升,手工匹配會耗費巨大的人力物力,并且容易破壞數據的完整性和準確性.目前已有的研究成果利用元素自身信息、語義信息、數據實例信息和結構信息來挖掘模式正確的元素映射關系.在之前的工作中,我們構建了一個面向物聯網的異構數據轉換模型,實現快速高效的物聯網異構數據互聯,然而在互聯過程中模式匹配過程的人工參與度過高,匹配效率低下.為了解決該問題,我們首先分析了物聯網異構數據的特征,即時間序列特征.并以此為切入點,通過解析時間序列數據來對物聯網異構數據進行分類識別,為自動模式匹配提供了可能.基于以上研究成果,本文提出了一種面向物聯網異構數據的模式分層匹配算法(hierarchical schema matching algorithm, HSMA),該算法基于數據模式的實例信息,通過3層映射匹配:特征分類匹配、關系特征聚類匹配和混合元素匹配,實現了物聯網異構數據的模式自動匹配,減小了復雜模式下元素間匹配空間,提高了自動匹配的效率和準確度.
1 相關研究及問題分析
1.1 相關研究
目前比較典型且已經廣泛應用的匹配算法有Auto-match,Clio,COMA,iMAP,Cupid,LSD,GLUE等.Cupid[4]利用屬性名稱、數據類型等模式信息計算屬性之間的語義相似性,將語義相似度和結構相似度結合起來進行匹配.COMA[5]利用多種匹配器協同工作,通過過濾、篩選來提高匹配結果的準確率和效率.LSD[6]應用機器學習算法實現匹配并且自動整合匹配結果,可以很好地發現1∶1和1∶n的匹配.基于數據實例信息的模式匹配的iMAP[7]方法是一種綜合利用模式中多種類型的信息同時得到模式間的簡單和復雜映射關系的方法,可以很好地發現1∶1和1∶n的匹配.
1.2 問題分析
文獻[8]提出了一種基于實體分類的數據庫模式匹配方法,根據數據實例信息的語義信息進行特征提取,運用樸素貝葉斯算法對特征進行分類,最后對子模式進行相應的模式匹配.由于物聯網數據的海量性和異構性,無論數據庫設計得多么規范化,但其屬性名稱和意義的定義因人而異,單一地以屬性名等語義信息進行模糊分類的方式是不可取的,因為這種分類僅僅基于人為理解而非源數據的本質特征.文獻[9]利用數據的概率分布統計特征,從另一個角度對數據特征進行提取,利用BP神經網絡算法提高了模式匹配效率和準確度.然而該算法針對的僅僅是1:1列之間的匹配,不適用于復雜模式匹配.隨著數據規模不斷增大,匹配空間和匹配次數也會急劇增加,導致匹配效率低下.與文獻[8-9]的算法相比,本文提出的HSMA算法能夠較好地解決在現實應用中自動獲取解析數據源模式信息困難的問題,通過解析海量異構的原始數據,按照物聯網數據的時間序列性特征將解析的特征進行分類,從而代表數據源的模式特征;其次,HSMA算法中的關系特征聚類方法具有一定創新性,尤其對物聯網傳感數據的特征聚類有良好的效果,消除了數據集數據間不同數據類型差異的影響;最后,HSMA運用分層的方法逐步縮小匹配空間,減少匹配次數,提高了匹配的效率.
2 HSMA算法
為了實現物聯網異構數據(結構化數據)的模式匹配的智能化,我們設計了一種模式分層匹配算法HSMA.對于輸入的一個未知源數據,我們首先根據時間序列特征和數據類型特征對其所有的數據集進行分類,獲得子模式集合.與此同時,通過之前的研究成果IFRAT算法,獲取未知數據源領域特征信息,根據領域的不同初始化相應的領域標準集合以及標準化數據庫進行關系特征聚類匹配,建立各類中源數據集合和目標數據庫之間的映射關系(第1層匹配);然后依據所提取的數據集特征,運用機器學習算法,對每個子模式中的數據集進行聚類,進一步縮小匹配空間和范圍,對聚類結果與相應的標準集合數據集進行相似度計算,建立匹配映射(第2層匹配);最后將相匹配的聚類中的元素混合并進行相似度計算(第3層匹配),產生源數據與目標數據庫之間的模式匹配結果.通過以上3層匹配,HSMA逐步縮小匹配空間,降低了匹配次數,從而提高匹配效率.HSMA算法的整體架構如圖1所示:
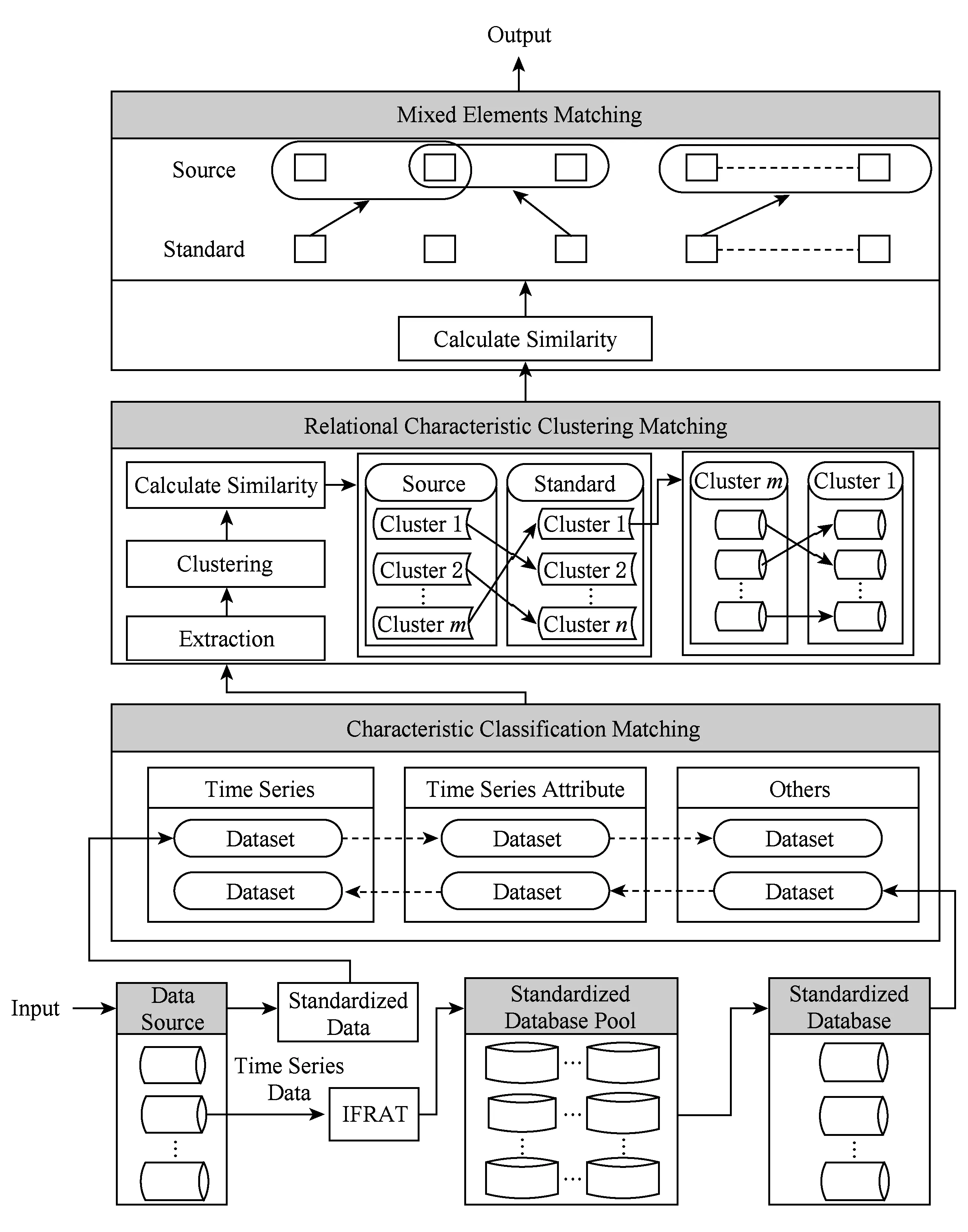
Fig. 1 Architecture of HSMA圖1 HSMA算法架構
2.1 源數據標準化
每個數據集中存在多種類型數據,以往的模式匹配算法都是對同一個數據集中不同類型元素進行單獨處理,處理方法多樣,雖然能夠保留單一元素特征,但是卻破壞了不同類型元素間的關聯關系,失去了整個數據集的特征.因此,針對數據集中常見的數據格式(如數值、字符、日期等),需要尋找一個統一的數據處理方式以保證其特征的完整性.首先,我們將每個結構化數據集都看作是一個存在行列關系的2維矩陣,矩陣中的相鄰行元素的差值變化結果作為新矩陣的行,我們將新的矩陣成為關系矩陣.差值變化結果用-,0,+表示,通過該方法,我們用關系值代替了原來的內容值,將不同類型的數據轉化為同一標準,最終得到關系矩陣.關系矩陣作為數據集的一個標準化形式,能夠更好地被用于數據集的特征挖掘.
為了更好地對HSMA算法進行理解,我們對本文中所用到的一些名詞進行定義.
定義1. 關系矩陣.對于任意常見的結構化數據Dm×n,都可以通過相鄰行做差的方法,差值結果用-,0,+這3種符號表示,我們將這樣的矩陣定義為關系矩陣,用M表示.
定義2. 關系鍵對.關系矩陣M的每一行中元素兩兩組合所形成的鍵對.
定義3. 特征列.對于關系矩陣M的任意一列,當且僅當同時滿足2個條件:1)該列元素的數值類型為日期類型或可以轉化成日期類型的其他數據類型;2)該列中的元素“+”或元素“-”的出現頻率大于閾值θ(我們取θ=90%),這樣的列被稱作時間序列特征列.如果僅滿足條件2,則該列被稱為主特征列.
定義4. 時間序列數據.物聯網傳感器產生的原始數據,按照時間順序以結構化的形式存儲,這樣的數據集合被稱為時間序列數據.
2.2 3層映射匹配
本節對HSMA的分層匹配算法進行了詳細的描述,共分為3層:第1層為特征分類匹配(時間序列特征和數據類型特征);第2層為關系特征聚類匹配;第3層為混合元素匹配.基于分層的思想,我們將復雜的異構數據模式匹配過程分割成3步,逐步縮小其匹配空間.對于每一步的匹配,都是基于物聯網異構數據特性,比較源數據與標準數據間的相似性,構建映射關系,最終實現物聯網異構數據的模式自動匹配.
2.2.1 特征分類匹配
HSMA算法在特征分類匹配過程中提供2種分類方法:
1) 時間序列特征分類
時間序列是物聯網異構數據的標志性特征,可以被用來進行物聯網異構數據分類.首先我們將物聯網異構數據的按時間序列特性分為3類:
① 時間序列數據類P.所有包含時間序列特征列的數據集屬于時間序列數據類(如傳感網傳感數據).
② 時間序列屬性類Q.包含主特征列的數據集歸于時間序列數據屬性類(如傳感網監測對象元數據),如描述時間序列屬性的相關信息.
③ 非時間序列類R.包含與時間序列無關的數據集,一般由許多相關輔助信息組成.
HSMA算法將物聯網異構數據按照時間序列特征分類,最后得到數據分類集合{時間序列數據類,時間序列屬性類,非時間序列類},其具體的分類算法如算法1所示:
算法1. 時間序列特征分類算法.
輸入:物聯網異構數據集合X={x1,x2,…,xn}(結構化數據);
輸出:時間序列特征類集合{P,Q,R}.
① 獲取物聯網異構數據集合(結構化數據),X={x1,x2,…,xn};
② 對X中所有數據集xi進行數據標準化,得到與X相對應的關系矩陣集合Y={M1,M2,…,Mn};
③ ?xi∈X,遍歷xi的每一列,依據時間序列特征對xi進行分類;
④ for eachxi∈Xdo
⑤ for eachcol屬于Mi的列集合 do
⑥n=Column_num(Mi);

⑧ ifθ≥90% then
⑨ ifcol∈Type.datethen
⑩xi∈P;
2) 數據類型特征分類
物聯網異構數據中,不同領域的源數據集合具有不同的數據類型分布特征,依據該特征對物聯網異構數據分類.數據類型按照物聯網異構數據的常見類型被分為5類:數值型(value)、字符類型(char)、時間類型(date)、字符-數值類型(char-value)、字符-時間類型(char-date),考慮在復雜模式匹配下,相同的數據可能被賦予不同的數據類型,數據類型間的相互轉換會導致其分布特征偏離,因此將字符串-數值等可以相互間進行轉換的情況列入數據類型特征.利用各個數據類型出現的頻率值,構建一個5維的特征向量,然后依據特征向量對物聯網異構數據進行特征分類:
① 時間主導類E.由于時間類型的特殊性,只要包含時間類型的數據集都屬于時間主導類.
② 數值主導類F.數值類型(如int,long,float,double等)占比重大的數據集屬于數值主導類.
③ 字符主導類G.字符類型(如char,varchar,nvarchar等)占比重大的數據集屬于字符導類.
HSMA算法將物聯網異構數據按照數據類型特征分類,最后得到數據分類集合{E,F,G},其具體的分類過程如算法2所示:
算法2. 數據類型特征分類算法.
輸入:物聯網異構數據集合X={x1,x2…,xn}(結構化數據);
輸出:數據類型特征類集合{E,F,G}.
① 獲取物聯網異構數據集合(結構化數據),X={x1,x2…,xn};
② 對X中所有數據集xi進行數據結構標準化;
③ ?xi∈X,遍歷xi的每一列,依據數據類型分布特征構建xi的特征向量vi,得到X相對應的特征矩陣V=(v1,v2,…,vn);
④ for eachxi∈Xdo
⑤ for eachcol∈xido
⑥ 統計過程①中各個數據類型發生次數;
⑦ end for
⑧ 構建數據類型特征向量vi;
⑨n=Column_num(xi);
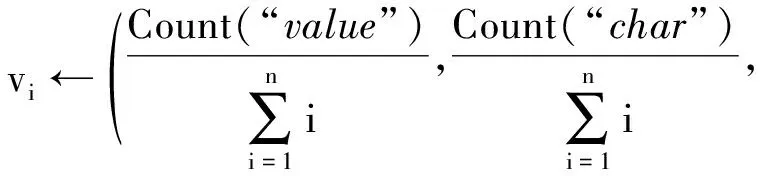

2.2.2 關系特征聚類匹配
通過2.2.1節中的特征分類匹配,對源數據S和標準化數據庫T中的數據分別進行時間序列特征分類和數據類型特征分類,得到的結果集合統稱為Scla和Tcla.在本節,我們采用SOM聚類方法對Scla和Tcla中的數據集進行歸類,進一步縮小匹配空間.在聚類過程中,我們采用關系矩陣M作為數據集的特征矩陣,因為關系矩陣M具有以下特點:1)M可以將數據集中不同類型的數據轉換成統一的符號表示;2)M可以保留元素間的相互關系,而傳統的匹配方法忽略了這一點;3)M解決了復雜模式匹配下元素排列順序多變的問題,更好地表現數據集特征.關系矩陣M中,每一行中所有項兩兩組合形成關系鍵對,HSMA算法通過對數據集進行行遍歷,提取數據集關系鍵對的頻率分布特征,作為該數據集的特征向量vi,基于得到的特征向量進行聚類匹配.詳細過程如算法3所示:
算法3. 關系特征聚類匹配算法.
輸入:Scla,Tcla;
輸出:Scla和Tcla的聚類集合.
① 獲取Scla和Tcla中的分類集合:Scla或Tcla={Classification1,Classification2,Classi-fication3};
②dataset∈{E,F,G};
③ for eachClassification∈Sclado
④ for eachds∈datasetdo
⑤ds→M;
⑥ for eachrow屬于M的行集合 do
⑦ 關系鍵Key←{(-,-),(-,0),(-,+),(0,0),(0,+),(+,+)};
⑧ 統計每種關系鍵Key出現的次數;
⑨ end for
⑩n←統計所有關系鍵Key出現的總次數;
在本節,我們基于關系矩陣中提取的特征向量,對Scla中的所有數據集進行聚類,得到聚類集合D={d1,d2,…,dl},通過計算歐氏距離,確定Tcla中的每一個數據集在Scla中最相似的聚類集合,從而進一步縮小匹配空間.我們假設并認定S中的每一個聚類對應T中唯一的數據集,即數據集之間只存在1∶n的關系.
2.2.3 混合元素匹配
基于2.2.2節得到的聚類集合D.?di∈D,我們將di中的所有元素混合在一起,采用文獻[10]的算法對于單一元素進行聚類匹配,該算法能夠快速有效地發現聚類中心,能夠在短時間內完成聚類過程且過程精簡,最終得到匹配結果集合R={r1,r2,…,rl}.考慮到現實情況的復雜性,我們很難做到元素1∶1的精準匹配,所以?ri∈R,我們規定ri中只包含1個標準化數據元素和φ個源數據的元素(這里的φ人為設定,本文選取φ=1,2,3),這φ個源數據的元素作為最相似的元素被推薦用戶,具體如算法4所示:
算法4. 混合元素匹配算法
輸入:聚類集合D←{d1,d2,…,dl};
輸出:匹配結果集合R←{r1,r2,…,rl}.
① 獲取聚類集合:D←{d1,d2,…,dl};
② for eachdi∈Ddo
③ 運用文獻[10]算法進行匹配;
④ 設定φ的數值;
⑤ri←di的匹配結果;
⑥ end for
⑦ return匹配結果集合R←{r1,r2,…,rl}.
3 實驗驗證及結果分析
3.1 數據選取
為了證明HSMA的可行性和有效性,我們選取工業物聯網家電產品測試領域的家用空調性能測試中13個不同廠家的30個數據庫作為源數據,將基于國際標準IEEE 1851的空調測試數據庫作為標準化數據庫(采用Oracle),數據詳細信息如表1所示:

Table 1 Performance Test Data of Residential Air Conditioner
我們認為一般情況下存在2種常見的異構形式:行列轉換和拆分.
1) 行列轉換.不是完全屬于同一列的內容被列入同一列中,為了消除結構不同對匹配造成的影響,我們需要對這一類型的列進行邏輯行轉換,同時記錄相應映射關系,如圖2所示:

Fig. 2 Row-column transforming of IoT heterogeneous data圖2 物聯網異構數據行列轉換
2) 拆分.通常情況下列的合并要么是字符串由特殊字符隔開,要么布爾型直接合并,所以找到合并字段進行邏輯拆分,同時記錄相應的映射關系,如圖3所示:

Fig. 3 Logic splitting of IoT heterogeneous data圖3 物聯網異構數據邏輯拆分
3.2 算法對比
我們采用不同的基于數據實例和數據庫模式信息的模式匹配算法與HSMA算法進行對比,詳細的對比信息如表2所示:
1) SMEC[8].通過樸素貝葉斯學習將實體分為不同的類,以同樣的類來匹配子模式之間的模式元素.
2) SMDD[9].基于神經網絡的模式匹配算法,通過分析模式元素所包含的數據實例的分布規律,自動完成模式匹配.
3) iMAP[7].一種綜合利用模式中多種類型的信息同時得到模式間的簡單和復雜映射關系的方法,在得到匹配關系的同時保存對每個匹配關系的判斷過程,當用戶對最終結果進行調整時,向用戶提供保存的判斷過程作為用戶進行調整的依據.

Table 2 Comparison of Different Algorithms表2 不同算法之間比較
3.3 實測結果
為了評估HSMA的匹配質量,我們采用3個通用指標[11]進行評估:
1) 查準率(Precision).匹配結果中正確匹配結果的比率.
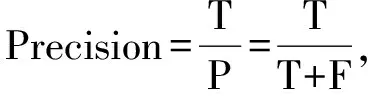
(1)
其中,T為正確識別的匹配結果,P為匹配方法返回的匹配結果,F為錯誤的匹配.
2) 查全率(Recall).匹配結果中正確匹配結果占實際匹配結果的比率.
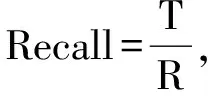
(2)
其中,R為手工匹配結果.
3)F1_measure.能夠全面評價匹配質量的統計量.

(3)
3.3.1 HSMA算法自測
1) HSMA算法的匹配質量受到參數φ選取的影響.通過對φ設定不同的值,分析比較其查準率、查全率和F1-measure,結果如圖4所示.與φ=1相比,當φ>1時,查全率、查準率和全面性都有提高,因為HSMA算法無法保證精準的1∶1匹配,模式的異構性導致存在多個相近的相似度結果.但并不是φ值越大越好,φ的增大會導致匹配干擾項增加,降低匹配質量,當φ=3時,可以看出其匹配質量大于φ=1但小于φ=2.
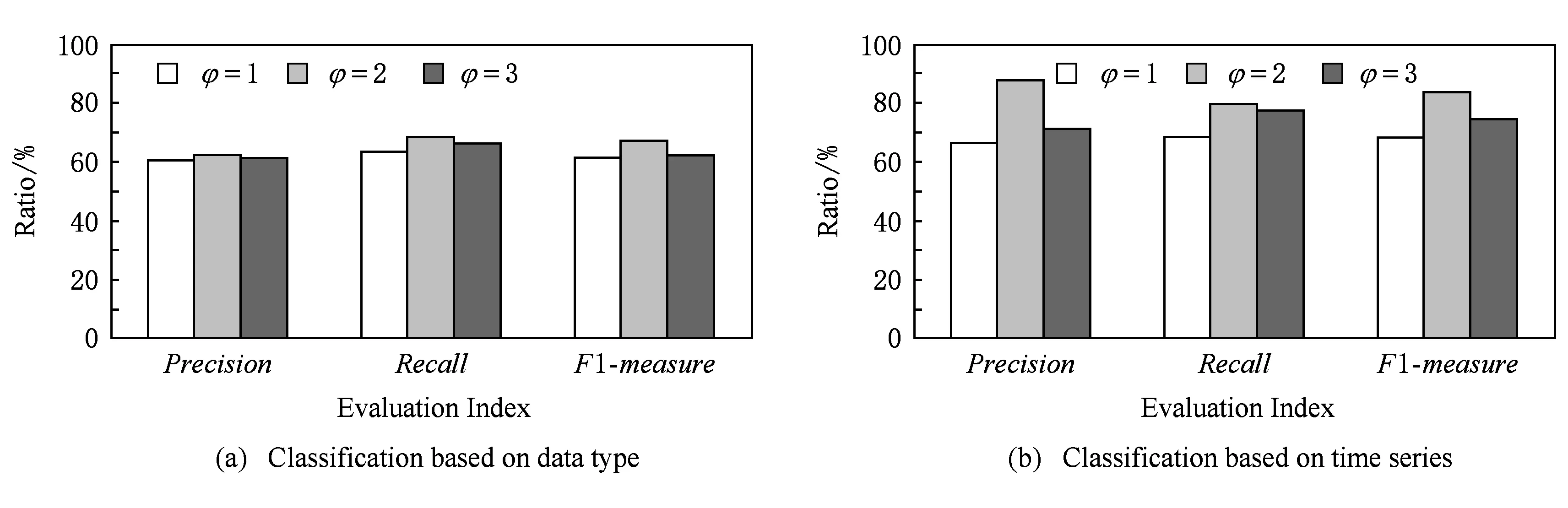
Fig. 4 Matching quality of HSMA under different φ圖4 在不同的φ下HSMA的匹配質量
2) HSMA算法的匹配質量受到輸入數據庫數量的影響.輸入數據庫的個數會直接影響關系特征聚類的效果,充足的數據會使數據特征更加明顯.如圖5所示,對于不同的φ值,當輸入數據庫數量在(0,15)范圍時,其匹配質量隨著輸入數據庫個數的增加而不斷提高且變化較為明顯;但當輸入數據庫數量大于15后,匹配質量增長緩慢.

Fig. 5 Matching quality of HSMA with the increasing number of input databases圖5 隨著輸入數據庫數量的增加HSMA的匹配質量

Fig. 6 Matching time of HSMA圖6 HSMA需要的匹配時間
3) HSMA算法的時間效率受參數φ選取的影響.圖6比較了在φ值的不同情況下源數據個數對HSMA算法時間效率的影響.如圖6所示,φ越大,HSMA算法所用的匹配時間就越大,因為φ值的增加導致在混合元素匹配過程中匹配次數的增多,提高了時間復雜度;當φ值固定時,采用時間序列特征分類的HSMA算法的匹配時間低于采用數據類型特征分類的HSMA算法.
4) HSMA算法的時間效率受特征分類的影響.我們隨機選取15個數據源作為HSMA算法的輸入,分別采用無分類、時間序列特征分類和數據類型特征分類并且設定不同的值,分析比較其每一層匹配所用時間,結果如圖7所示.φ的選取僅僅會影響混合元素匹配的匹配時間,φ值越大混合元素匹配過程所用的時間就越多;當φ值固定時,采用時間序列分類的HSMA算法的匹配時間相對較小.
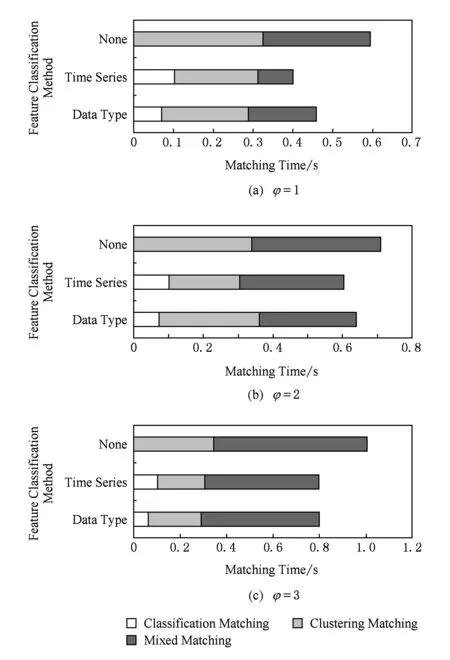
Fig. 7 Hierarchical matching time of HSMA圖7 HSMA的每一層匹配時間
3.3.2 算法性能對比
由3.3.1節可得,當選取φ=2,采用時間序列特征分類的HSMA算法的性能最高,因此將其與3.2節中各個模式匹配算法進行比較.我們選取了30個異構數據庫作為HSMA的輸入,比較所得結果如圖8所示.如圖8(a)所示,HSMA算法的匹配質量與其他算法相比較高,其中源數據庫的異構性和模式信息的不完整導致SMEC效率最差.如圖8(b)所示,由于HSMA算法采用預處理以及多次聚類,導致其所用時間明顯高于其他算法.

Fig. 8 Performance comparison of HSMA with other algorithms圖8 HSMA算法與其他算法的性能比較
4 總結和未來工作
我們設計了一種模式分層匹配算法HSMA,對于輸入的一個未知源數據,根據領域的不同初始化相應的領域標準集合以及標準化數據庫進行特征分類匹配,建立各分類中源數據集合和標準數據庫數據集合的映射關系;然后提取源數據集和目標數據庫表中的關系特征,運用SOM聚類算法,對每一個子模式中的數據集進行聚類,對聚類結果與相應的標準數據庫數據集進行相似度計算,建立匹配映射;最后將匹配結果集合中的混合元素進行相似度計算,進行單一元素匹配.通過以上3層匹配,HSMA算法逐步縮小匹配空間,降低了匹配次數,從而提高匹配質量和效率.
由于在關系特征聚類匹配及混合元素匹配的過程中,聚類算法的好壞直接決定了最后的匹配質量和總體的匹配時間,聚類雖然能夠縮小匹配空間,但同時有可能帶來匹配錯誤,導致相關元素并不在同一個類中.未來會嘗試使用不同的機器學習算法對HSMA算法進行改進,并且尋找最好的組合模式來提高聚類的效果.此外本文在實驗驗證環節采用iMAP,SMDD等經典算法與HSMA算法進行對比,提高了對比結果的可靠性,但是這些算法偏于老舊,下一步將采用近幾年的新算法進行比較,以驗證HSMA算法的先進性.
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
