社會網中基于主題興趣的影響最大化算法
2018-11-13 05:39:26謝勝男仲志偉李金寶任倩倩
計算機研究與發展 2018年11期
劉 勇 謝勝男 仲志偉 李金寶 任倩倩
(黑龍江大學計算機科學技術學院 哈爾濱 150080) (黑龍江省數據庫與并行計算重點實驗室(黑龍江大學) 哈爾濱 150080) (acliuyong@sina.com)
近年來,隨著社交應用的普及,人們信息獲取的方式發生了很大的改變.通過在線社交網絡轉發和分享消息逐漸成為了人們獲取信息的主要方式.很多在線社交網站允許用戶對信息進行轉發、評論、標記或其他一些類似的操作.如果能充分挖掘社交網絡中這些海量數據并發現傳播規律,將促進新思想、新產品在社交網上快速傳播.
為了利用社交網進行病毒式營銷, Kempe等人[1]首次提出了影響最大化問題:選取一個大小為k的初始用戶集合,使得在給定傳播模型下最終被影響的用戶數量最大.文獻[1]同時在獨立級聯(independent cascade, IC)模型和線性閾值(linear threshold, LT)模型上給出了貪心算法.此后,影響最大化及其相關問題被廣泛研究.一方面,為了擴展到大規模社交網絡上,經典傳播模型上高效地影響最大化算法[2-5]相繼被提出;另一方面,為了更準確地模擬信息傳播過程,一些新的傳播模型[6-8]相繼被提出.
現有的傳播模型幾乎都是利用朋友之間的影響來模擬傳播過程.例如:基于主題的獨立級聯(topic-aware independent cascade, TIC)模型[6]利用傳播項的主題分布和用戶在不同主題上的影響程度來計算朋友之間的影響概率.然而,在現實生活中,我們發現這樣一個現象:相對于朋友之間的影響,人們更容易被其感興趣的信息所吸引.例如:用戶使用新浪微博轉發好友發布的內容時,用戶更多的是被內容本身所吸引,被好友影響的可能性相對較小.即使一個不經常聯系的好友發布了令用戶感興趣的內容時,用戶也有很大可能性轉發該內容.
根據上述分析,在求解社會網中的影響最大化問題時理應考慮用戶對傳播項的興趣.使用用戶的興趣分布和傳播項的主題分布建立傳播模型,可以更精確地描述信息傳播過程,得到更準確的預測結果,具有重要的理論意義和廣泛的應用價值.
本文利用用戶興趣的主題分布和傳播項的主題分布,在傳統獨立級聯模型的基礎上,提出了基于主題-興趣的獨立級聯傳播(topic-interest independent cascade, TI-IC)模型,并在該模型的基礎上設計了基于主題興趣的影響最大化算法ACG-TIIM.通過在2個真實數據集上的實驗結果表明:TI-IC模型在均方根誤差MSE,F1-score,ROC曲線下面積等多個指標上均優于傳統的IC模型和TIC模型.ACG-TIIM算法可以得到和傳統貪心算法幾乎一樣的種集,但比傳統貪心算法快2個數量級以上.本文主要貢獻有4個方面:
1) 提出了基于主題興趣的傳播模型TI-IC,并使用期望最大化(expectation maximization, EM)算法學習該模型的參數.
2) 提出了新傳播項主題分布向量的學習算法.
3) 在TI-IC基礎上,提出了基于主題興趣的影響最大化問題(topic-interest based influence maxi-mization, TIIM),并給出了高效啟發式算法ACG-TIIM.ACG-TIIM算法也可用于求解其他傳播模型上的影響最大化問題.
4) 多個真實數據集上的實驗結果表明,TI-IC模型比IC模型和TIC模型能更準確地描述信息傳播規律, ACG-TIIM算法可高效求解影響最大化問題.
1 相關工作
Domingos等人[9]最先考慮社會網中具有影響力的結點選擇問題.2003年,Kempe等人[1]首次提出了影響最大化問題,證明了影響最大化問題在獨立級聯模型和線性閾值模型上都為NP-hard問題,并且設計出具有(1-1/e)近似比的貪心算法.貪心算法雖然簡單,但是由于在每次迭代選擇種子結點的過程中都需要進行大量的蒙特卡洛模擬來估計影響范圍,導致貪心算法的效率較低.為了擴展到大規模社交網絡上,很多高效的影響最大化算法[2-5]被提出.例如Li等人[5]提出了在線廣告的實時影響最大化問題,對于一個給定關鍵字的廣告,在線尋找k個結點的種集,利用反向可達集的概念設計了一個基于采樣的算法,不僅有近似比保證,也提升了算法的效率.
任何影響最大化算法都依賴于特定的傳播模型.社交網傳播模型大致可以分為帶有拓撲結構的傳播模型和無拓撲結的傳播模型兩大類.
帶有拓撲結構的傳播模型將社交網拓撲結構看作前置條件,要求信息沿著邊進行傳播.經典的IC模型和LT模型均屬于此類模型.Barbieri等人[6]擴展了傳統IC模型,提出了主題感知的獨立級聯模型TIC.Aslay等人[10]在該模型的基礎上,提出了基于主題的影響最大化問題,設計了一個樹形框架,利用索引來減少新傳播項的計算量,使得算法效率得到很大提升.Chen等人[11]估計每個用戶的影響上界,利用該上界對影響力小的用戶進行剪枝,并設計了高效的計算上界方法.文獻[12]考慮了時間因素的影響,在IC模型和LT模型基礎上提出了AsIC和AsLT模型.文獻[13]通過分析傳播內容來構造傳播模型.文獻 [14]考慮內在因素和外在因素的作用來模擬傳播過程.文獻[7]同時考慮外部影響、朋友影響和用戶興趣的聯合作用利用隨機過程構建傳播模型CMPP.文獻[8]考慮結點和結點之間的交互作用,在IC模型基礎上提出了情感交互模型OI.
無拓撲結構的傳播模型假定社交網拓撲結構無法獲取,只根據觀察到的事件序列來推斷傳播軌跡,預測傳播趨勢.文獻[15]推斷用戶之間的信息傳播速率,使得觀察事件序列出現概率最大.文獻[16]根據觀測的事件序列來推斷信息傳播路徑和網絡拓撲結構,通過追蹤新聞站點之間的新聞流通路徑驗證算法有效性.文獻[17]將用戶映射到一個連續隱藏空間中,根據與感染源的距離遠近來計算每個用戶被感染的概率.通過從觀察到的事件序列中學習傳播核函數來預測信息傳播.文獻[18]使用表示學習的方式將用戶映射到連續潛在空間.如果2個用戶在潛在空間的距離越近,則這2個用戶的影響概率越大.通過這種方式來構造傳播模型Embedded IC.
本文傳播模型是一種帶有拓撲結構的傳播模型.與現有模型的主要區別是,本文傳播模型只關注用戶的興趣,如果用戶對傳播項感興趣,則用戶接受傳播項.本文傳播模型在預測效果方面優于IC模型和TIC模型,因此更適合作為求解影響最大化問題的傳播模型.
2 傳播模型
本節介紹基于主題興趣的傳播模型TI-IC.該模型是IC模型的擴展,假設每個傳播項存在一個主題分布,并且每個用戶存在一個興趣分布.例如,一個電影可能會包含:喜劇、愛情、動作等基本的主題,一個用戶也會存在一個興趣分布,如對喜劇的喜愛程度是0.6,對愛情劇的喜愛程度是0.1,對動作片的喜愛程度是0.3.

TI-IC模型的工作原理如下:每個結點僅有一次機會由不活躍狀態變為活躍狀態,并且該過程不可逆.在時刻t= 0,只有種集S?V中的結點為傳播項i上的活躍結點;在時刻t≥1,如果結點u的任何鄰居v在時刻t-1變得活躍,那么它有一次機會去激活它的鄰居結點u,激活的概率為θi·θu.那么,在結點u的多個鄰居同時活躍的條件下,結點u被激活的概率為

(1)

IC模型和TI-IC模型最主要的區別在于:IC模型只考慮了活躍結點對相鄰目標結點的影響概率,而不考慮傳播項的具體情況,IC模型假定對所有傳播項邊上的影響概率都是相同的;而TI-IC模型在描述信息傳播過程中關注目標結點對傳播項的興趣,不同的傳播項對目標結點會有不同的興趣,從而產生不同的影響概率.
TIC模型和TI-IC模型最主要的區別在于:TIC模型考慮了傳播項的主題分布和用戶在不同主題上對相鄰目標用戶的影響,因此不同的朋友對目標用戶會產生不同的影響;而TI-IC模型只關注目標用戶對傳播項的興趣,而不考慮不同朋友對目標用戶的影響.當目標用戶看到他的任何朋友接受傳播項時,目標用戶都會以相同的概率被影響.
3 基于主題興趣的傳播模型的學習算法
本節使用EM算法求解基于主題興趣的傳播模型參數.該學習算法的輸入是:社會網絡G(V,E)、用戶歷史動作日志D(u,i,t)以及主題個數Z.在學習中我們假設每個用戶只能接受相同傳播項一次.另外,D中的u都屬于G中的結點集合V.我們令I代表傳播項集合,Di代表傳播項i的傳播軌跡.
學習算法的輸出結果是TI-IC模型的參數,我們記為Θ.現假設TI-IC傳播模型的每個傳播軌跡都是獨立的,則給定模型參數Θ的對數似然函數表示為
(2)



(3)


(4)

(5)

算法1. 學習興趣主題模型TI-IC參數的EM算法.
輸入:社會網G(V,E)、傳播軌跡D、主題個數Z;
輸出:TI-IC參數Θ={θu(?u∈V),θi(?i∈I)}.

② repeat
③ for alli∈Ido
④ for allz={1,2,…,Z} do

⑥ end for
⑧ for allz={1,2,…,Z} do

⑩ for allu∈Vdo
從歷史數據中學習TI-IC模型參數之后,在實際應用之前還需要獲得傳播項的主題分布向量.如果傳播項是一個已經存在的傳播項,TI-IC模型學習算法的輸出同時包含了傳播項的主題分布向量.然而,實際應用中的任務通常是促銷新產品.如何針對新產品選擇合適的主題分布向量是一個關鍵問題.下面給出3種新產品的主題分布向量構造方法:
1) 新產品的主題分布向量取自一個均分分布向量.這種方法顯然沒有考慮不同產品的特征,通常不能達到最佳的促銷效果.
2) 由領域專家為新產品選擇合適的主題分布向量.這種方法增加了人工的工作量,而且TI-IC模型中每個維度的具體含義,很難給出準確的定義,使得領域專家很難做出合適的選擇.

(6)
對式(6)的優化目標,我們使用梯度下降算法求解.具體求解過程如算法2所示,其中λ是學習步長.
算法2. 學習新傳播項的算法.

輸出:新傳播項i的主題分布向量θi.

② repeat

④ until convergence
4 基于主題興趣的影響最大化算法
本節首先提出了基于主題興趣的影響傳播最大化問題,然后給出了求解該問題的一個新的啟發式算法.
4.1 問題定義
本節在基于主題興趣的傳播模型TI-IC基礎上,提出了基于主題興趣的影響最大化問題TIIM,并給出了該問題的形式化定義.
基于主題興趣的影響最大化問題TIIM:給定有向圖G(V,E)、用戶的歷史動作日志D(u,i,t)、種集大小k、傳播項i.基于興趣主題的影響最大化問題是尋找大小為k的種集S,使得傳播項i的影響范圍最大.種集S形式化地表示為

(7)
其中,δi(S)表示種集S在傳播項i上的影響范圍.在TI-IC模型中,盡管邊上的影響概率需考慮主題和興趣,而傳播的機制并沒有發生變化.所以對于TI-IC模型而言,影響范圍函數δi(S)的單調性和子模性可直接由IC模型繼承而來.
4.2 基于主題興趣的啟發式算法
對TIIM問題,完全可以使用傳統貪心算法[1]求解.但是在大規模網絡上由于多次蒙特卡洛模擬而使得貪心算法復雜度太高變得實際上并不可行.
貪心算法每次從所有結點中選擇影響增益最大的結點直到達到k個結點為止.假設圖中有|V|個結點、|E|條邊,每次估計影響范圍使用R次蒙特卡洛模擬,則貪心算法時間復雜度為O(kR|V||E|).實驗中我們發現影響增益大的結點基本上都是本身影響范圍大的結點.如果我們有一個啟發式算法預先排序每個結點的影響范圍,從中選中少量影響范圍大的結點構成候選集,再使用貪心算法從候選集中選擇結點,也可以獲得和貪心算法一樣的結果.下面給出候選集的選擇過程.
從社交網中每個結點v出發,進行深度優先搜索,尋找影響概率大于等于閾值ε的所有路徑,可構造一棵以v為根的可達路徑樹,則結點v的影響范圍可以近似地估計為
(8)
其中,PATH(v,u)表示從結點v到結點u的可達路徑集合;p(path)表示沿著路徑path,結點v對結點u的影響概率.定義候選集合C,C中存儲δv值最大的前λk結點,我們僅對C中的結點利用蒙特卡洛模擬計算影響范圍,貪心選擇k個結點作為種集.實驗中λ=3就取得了和傳統貪心算法幾乎一樣的實驗結果.例1給出了生成候選集合的一個實例.
例1. 如圖1(a),給定有向圖G(V,E),邊上概率已學習獲得,期望選擇2個種子結點進行影響最大化,設置閾值ε=0.03.構造結點a的可達路徑樹T(a),如圖1(b)所示.由式(8)可得δa=0.878 5(沒有包括對自身結點a的影響).以此類推,可以計算出圖1(a)中所有結點的影響范圍,δb=0.1,δc=0.9, 其余結點的影響范圍都為0,因此C={a,c,b},再通過蒙特卡洛模擬方法貪心選擇2個具有最大影響范圍的結點作為種集.

Fig. 1 An example for reachable paths圖1 可達路徑的例子
在生成候選集之后,使用帶有CELF優化的貪心算法選擇種集,可得到有效解決TIIM問題的啟發式算法ACG-TIIM.算法的偽代碼如算法3所示.
算法3. 求解TIIM問題的啟發式算法ACG-TIIM.
輸入:圖G(V,E)、用戶興趣向量集合{θu|u∈V}、傳播項i的主題分布θi、種集大小k、主題個數Z、模擬次數R;
輸出:種集S.
①S=?,C=?;
② for (u,v)∈E

④ end for
⑤ for eachv∈V
⑥ CreateT(v);

⑧ end for
⑨Sort(V,δv);
⑩ fori=1 toλkdo
算法3的輸入是一個有向圖G(V,E)、由TI-IC模型學習得到的用戶興趣向量集合(其中向量θu表示用戶u的興趣分布)、傳播項i的主題分布θi、一個正整數k、代表蒙特卡洛模擬次數的正整數R.輸出具有最大影響范圍的種集S(|S|=k).
步驟②~④利用由TI-IC模型學習得到的用戶興趣分布向量及傳播項的主題分布向量來計算結點間的影響概率.步驟⑤~⑧預先估計每個結點本身的影響范圍,實際上這種估計只需要保證排序正確即可.步驟⑨~按照每個結點的估計范圍進行排序,將λk個結點放入候選集合C.步驟~將候選集合C的結點(連同當前增益、當前迭代次數)放入優先級隊列Q.步驟~使用CELF優化[19]的貪心算法選擇大小為k的種集S.
步驟②~④的復雜度為O(Z|E|).步驟⑤~⑧的復雜度為O(|V||E|).步驟⑨的復雜度為O(|V|log|V|).步驟~是傳統貪心過程,復雜度為O(kR|C||E|).所以ACG-TIIM算法總的復雜度為O(|V||E|+kR|C||E|).傳統貪心算法時間復雜度為O(kR|V||E|).因為|C|?|V|,所以ACG-TIIM算法要比傳統貪心算法快很多.
5 實驗結果與分析
本節在2個真實數據集上測試和評估本文提出的模型和算法,并且與多個現有的模型及算法進行比較.
5.1 實驗數據
我們使用2個真實數據集進行實驗.2個數據集都包含社會網G(V,E)和一組動作日志D(u,i,t).數據集分別是Digg[6]和Last.fm[6].其中,Digg數據集是一個社交新聞網站,用戶在網站上對文章進行投票評論,D中包含的元組(u,i,t)代表用戶u在時刻t投票給了故事i.如果用戶u投票給故事i,用戶u的朋友v在之后不久也投票給了故事i,采用與文獻[6]相同的處理方式,認為這個投票的動作從用戶u傳播到了朋友v.數據集Last.fm是世界最大的社交音樂平臺,用戶可以在這個網站中搜索、收聽以及評論自己喜歡的音樂.D中包含的元組(u,i,t)代表用戶u在時刻t評論了歌手i.
我們從Digg數據集中提取了15 000個結點和395 513條邊以及相應的動作日志.從Last.fm數據集中提取了5 100個結點和23 453條邊以及相應的動作日志.在2個數據集的動作日志上各選擇了1 000個傳播項,并且每個傳播項的傳播范圍都超過50.在2個數據集中,我們都不考慮孤立結點,即在D中有動作記錄,但是在圖G中卻沒有朋友的結點.
實驗中所有算法均用C++編寫,在Microsoft Visual Studio 2005環境下編譯.所有實驗都在Intel Core i7 6700 3.4 GHz-主頻 CPU、8 GB主存的臺式機上運行.
5.2 對比模型和對比指標
本文模型主要與下面6個模型進行對比.
1) 獨立級聯模型(IC模型).傳統的獨立級聯模型工作原理如下.網絡中結點共有2個狀態,活躍結點與不活躍結點,每個活躍結點有且僅有一次機會去激活未活躍的結點,并且該過程不可逆,傳播的停止條件是當前時刻沒有再被激活的結點.該模型的參數為結點間的影響傳播概率,由文獻[20]中的EM算法學習而來.
2) 基于主題的獨立級聯模型(TIC模型[6]).TIC模型工作原理與IC模型一致,與IC模型不同的是,活躍結點激活不活躍結點的概率為基于主題的影響傳播概率.該模型的參數為結點間基于主題的影響傳播概率,由文獻[6]中的EM算法學習而來.
3) 固定傳播概率的IC模型(NIC).固定邊上影響概率為0.02(多次實驗測試最佳的影響概率值),工作原理與IC模型一致.
3個模型共同需要設置的參數是延遲閾值Δ,通常的做法是設置Δ在3~5之間,但是通過實驗我們發現Δ的變化對3個模型的影響不大,為了減少模型的計算量,在實驗中我們都把Δ的值設置為無窮大.
4) 使用混合泊松過程建模社交影響、外部影響和內部影響的CMPP模型[7].取社交影響權重為0.3,內部影響權重為0.7,不考慮外部影響,這種配置是CMPP模型在本文實驗數據上的最好效果.
5) 本文基于興趣主題的傳播模型TI-IC-UN.在模擬傳播之前,對新傳播項的特征向量直接取均勻分布.
6) 本文基于興趣主題的傳播模型TI-IC.在模擬傳播之前,對新傳播項的特征向量使用梯度下降算法(算法2)進行學習.
對于新的傳播項i,我們通過限制條件選取感染源集合:首先找到傳播項i的所有活躍結點;然后依次檢查這些活躍結點,如果活躍結點v的任何鄰點在傳播項i上都沒有在v之前活躍,就把活躍結點v加入到感染源集合中.
對于TIC模型和TI-IC模型,如果沒有明確說明,我們設置傳播項主題分布個數Z=10.TIC模型也使用算法2學習了新傳播項的主題分布向量.
我們將所有傳播項按照8∶2的比例分成訓練集和測試集,保證一個傳播項的傳播軌跡或者全在訓練集或者全在測試集.顯然測試集中的每個傳播項都是新傳播項.首先在訓練集上學習模型中的參數,然后根據學習得到的模型預測測試集中每個新傳播項的傳播結果.具體預測過程為:對每個傳播項i,首先確定它的感染源集合(如果結點v接受了傳播項i,但是v的任何鄰居沒有在v之前接受傳播項i,則結點v是感染源);然后讓感染源中的結點為初始活躍結點,使用2 000次蒙特卡洛模擬模擬傳播項i的傳播過程,計算每個結點被激活的概率,最后根據預測的概率值計算如下10個指標.
1) 均方誤差(mean squared error,MSE).計算每個結點預測的概率值與真實值(被激活是1,沒被激活是0)差的平方,然后求平均值.
2) 準確率(Accuracy).給定一個激活閾值τ,如果預測的概率值大于等于τ,則預測該結點活躍;否則預測該結點不活躍.對每個傳播項i,計算預測正確的結點數占所有結點數的百分比.
3) 真正例(true positive,TP).預測為活躍實際為活躍的結點數.
4) 假正例(false positive,FP).預測為活躍實際為不活躍的結點數.
5) 真負例(true negative,TN).預測為不活躍實際為不活躍的結點數.
6) 假負例(false negative,FN).預測為不活躍實際為活躍的結點數.
7) 精確率(precision,P):
8) 召回率(recall,R):
9)F1分數(F1-score):
10) ROC曲線下面積AUC.按照預測的概率值對所有結點排序,計算ROC曲線下面積.
注意:對每個傳播項,都按照上述公式先計算MSE,Accuracy,F1-score,AUC;然后在所有傳播項上求均值.
5.3 不同模型上的對比結果
5.3.1 在MSE上的對比
表1和表2分別給出了不同模型在2個數據集合上的MSE.可以看出,NIC模型的誤差最大,因為NIC模型使用了固定的影響概率,使得預測效果較差.CMPP模型明顯優于NIC模型,但是比IC模型和TIC模型要差.在Digg數據集上,IC模型明顯優于TIC模型;而在Last.fm數據集上,IC模型與TIC模型差別不大.TI-IC-UN模型由于沒有學習新傳播項的主題分布向量,使得MSE要大于IC模型.但是當學習了新傳播項的分布向量后得到的TI-IC模型要明顯優于IC模型和TIC模型.這說明不同的傳播項有不同的特征,在傳播之前學習其特征是必要的.
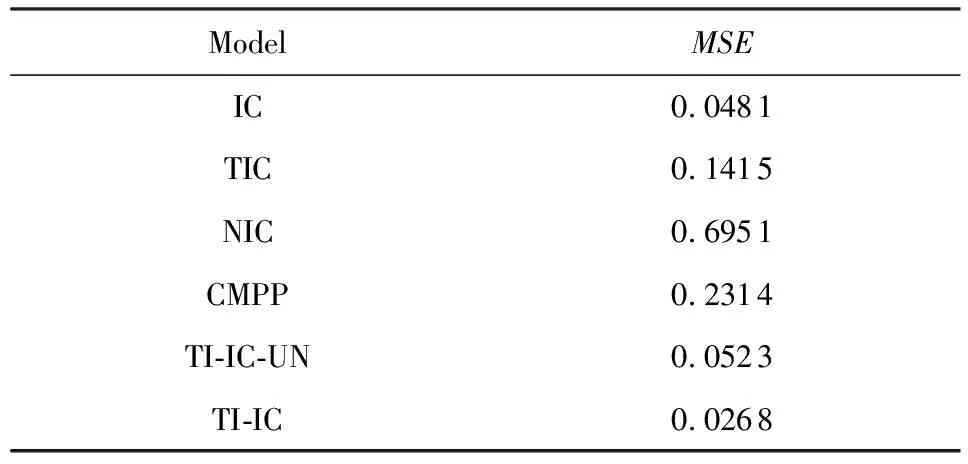
Table 1 Mean Squared Error of Different Models in Digg表1 Digg上不同模型的均方誤差

Table 2 Mean Squared Error of Different Models in Last.fm表2 Last.fm上不同模型的均方誤差
5.3.2 在準確率和F1分數上的對比
圖2和圖3分別給出了不同模型在數據集Digg和Last.fm上在不同激活閾值τ下的準確率.由圖2和圖3可知,在準確率性能的度量上設置激活閾值τ>0.1時,我們新提出的模型TI-IC都明顯高于其他模型.其中NIC模型性能最差,IC模型和TIC模型次于TI-IC模型,但是明顯高于其他模型;TI-IC-UN模型由于沒有考慮新傳播項的主題分布,與IC模型和TIC模型相比,在準確率方面仍然處于劣勢.

Fig. 2 Accuracy of different models in Digg dataset圖2 Digg數據集上不同模型下的準確率

Fig. 3 Accuracy of different models in Last.fm dataset圖3 Last.fm數據集上不同模型下的準確率
圖4和圖5分別給出了不同模型在數據集Digg和Last.fm 上在不同激活閾值τ下的F1-score.從圖4和圖5可以看出,TI-IC模型的F1-score始終高于其他模型;TI-IC-UN模型由于沒有考慮新傳播項的主題分布,在F1-score上也不具有優勢.
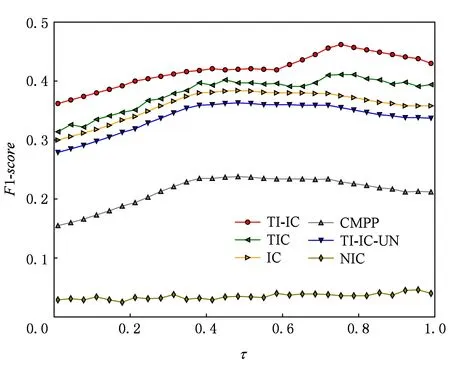
Fig. 4 F1-score of different models in Digg dataset圖4 Digg數據集上不同模型下的F1-score
Fig. 5 F1-score of different models in Last.fm dataset圖5 Last.fm數據集上不同模型下的F1-score
綜上所述,我們新提出的模型TI-IC在準確率和F1-score上均好于現有的IC模型和TIC模型,并且TI-IC,IC,TIC模型的預測效果明顯好于CMPP模型和固定影響概率的NIC模型.
5.3.3 在ROC曲線上的對比
我們對比了不同模型的ROC曲線,如圖6和圖7所示.在數據集Digg上TI-IC模型與IC模型、TIC模型在ROC曲線上有多處重疊,但是TI-IC模型在ROC曲線下面積仍然大于IC模型和TIC模型.在數據集Last.fm上,TI-IC模型的優勢更明顯.在2個數據集上,TI-IC-UN模型的ROC曲線下面積仍然低于IC模型和TIC模型,再次說明學習新傳播項自身特征的重要性.
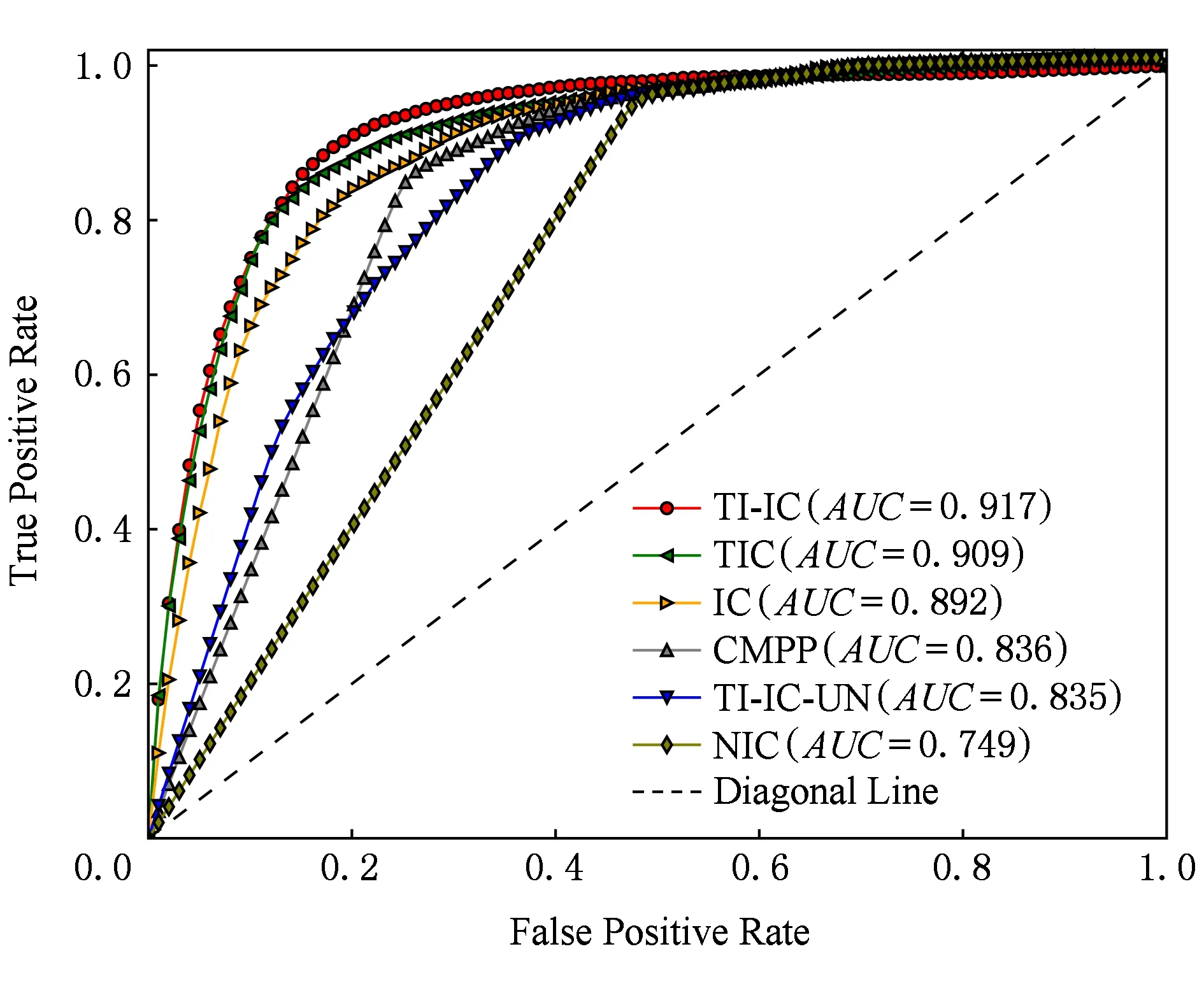
Fig. 6 ROC curve of different models in Digg dataset圖6 Digg數據集上不同模型下的ROC曲線

Fig. 7 ROC curve of different models in Last.fm dataset圖7 Last.fm數據集上不同模型下的ROC曲線
綜合5.3.1~5.3.3節中的實驗結果和分析,我們可以得出如下結論:TI-IC模型相比于其他現有模型能更有效地模擬傳播過程,更準確地預測傳播結果.
5.4 不同主題個數對結果的影響
本節實驗主要驗證不同主題個數對實驗結果的影響.圖8和圖9分別給出了數據集Digg和Last.fm上TI-IC模型和TIC模型在不同主題數下的ROC面積,其他模型沒有主題個數選項.從實驗圖中可以看出:當主題個數是10時,基本達到了理想的實驗結果;當主題個數大于10時,實驗效果沒有明顯改善.考慮到學習效率,本文設置主題個數為10.

Fig. 8 ROC area vs topic number in Digg dataset圖8 Digg數據集上主題個數對ROC面積的影響

Fig. 9 ROC area vs topic number in Last.fm dataset圖9 在Last.fm數據集上主題個數對ROC面積的影響
5.5 影響最大化算法對比
本文提出的啟發式算法ACG-TIIM,主要與如下影響最大化算法進行比較.
1) LDegree算法.在這個算法中,我們簡單選擇具有最大度的k個結點作為種集,再使用蒙特卡洛模擬估計影響范圍.
2) CELF-Gre算法.使用帶有CELF優化[19]的貪心算法選擇k個結點作為種集,該算法在影響最大化問題中被廣泛應用.
3) ACG-TIIM-UN算法.本文提出啟發式算法ACG-TIIM,但是不學習新傳播項的主題分布,直接取均勻分布.
本節實驗中,涉及蒙特卡洛模擬估計影響范圍時都將設置模擬次數R=2 000.CELF-Gre算法和ACG-TIIM算法在應用到TI-IC模型之前,都用本文EM算法獲取用戶的興趣分布以及新傳播項的主題分布,然后轉換成邊上的影響概率.新傳播項取自測試集合,并對所有傳播項的結果計算均值.CELF-Gre算法和ACG-TIIM算法在應用到IC模型之前,都用文獻[20]中算法直接獲取邊上的影響概率.CELF-Gre算法和ACG-TIIM算法在應用到TIC模型之前,都用文獻[6]中算法獲取邊上分主題的影響概率,再用本文算法學習新傳播項的主題分布,轉換成邊上的影響概率.在實驗中,我們將統一設置算法中的主題數目Z=10,選擇候選集合時設置λ=3.
5.5.1 種集大小與影響范圍的關系
本節實驗主要驗證種影響范圍與種集大小的關系.首先在TI-IC模型下,運行上述對比算法選擇不同大小的種集,在數據集Digg和Last.fm上的影響范圍如實驗圖10和圖11所示.

Fig.10 Influence spread vs seeds number in Digg dataset圖10 Digg數據集上種集大小對影響范圍的影響

Fig. 11 Influence spread vs seeds number in Last.fm dataset圖11 Last.fm數據集上種集大小對影響范圍的影響
從圖10和圖11可得出如下結論:LDegree算法的運行效果最差,是由于該算法只考慮社會網中的拓撲結構,選擇了全局具有最大度的結點,既沒有考慮用戶之間的影響,也沒有考慮用戶對傳播項的興趣.ACG-TIIM-UN算法得到的影響范圍遠遠好于LDegree算法,是由于該算法在真實的數據上學習了用戶的興趣,轉換成了影響概率,使得影響范圍計算更準確.然而,ACG-TIIM-UN算法獲得的影響范圍仍舊小于CELF-Gre算法和ACG-TIIM算法,這是因為CELF-Gre算法和ACG-TIIM算法除了學習用戶的興趣分布,還學習了新傳播項的主題分布,從而使得影響范圍更廣.而且,我們進一步檢查了算法ACG-TIIM-UN和算法ACG-TIIM返回的種集,在所有傳播項上,算法ACG-TIIM-UN返回的種集幾乎都一樣;但是算法ACG-TIIM在不同的傳播項上返回的種子集合差異很大,這再次說明在促銷新產品時,應該針對特定的產品選擇特定的用戶.CELF-Gre算法和ACG-TIIM算法得到幾乎相同的影響范圍.我們進一步檢查了這2個算法返回的種集,發現在不同的種集大小條件下,這2個算法返回的種集幾乎全完一樣.這是因為這2個算法在計算種集之前,學習了相同的參數(包括用戶興趣分布和新傳播項的主題分布).但是ACG-TIIM算法只考察了部分候選結點,而CELF-Gre算法需要考察全部候選結點,這使得這2個算法的運行效率會差別很大,具體差別見5.5.2節的實驗.
在IC模型和TIC模型下,我們也運行了上述對比算法.在IC模型下,ACG-TIIM算法和CELF-Gre算法的影響范圍幾乎完全一樣.在TIC模型下,ACG-TIIM-UN的影響范圍稍微低于ACG-TIIM算法和CELF-Gre算法,ACG-TIIM算法和CELF-Gre算法的影響范圍幾乎完全一樣.
5.5.2 種集大小與運行時間的關系
本節主要對影響最大化算法的運行時間進行比較.在TI-IC模型上,運行上述對比算法選擇不同大小的種集,在數據集Digg和Last.fm上的運行時間如實驗圖12和圖13所示:

Fig.12 Running time vs seeds number in Digg dataset圖12 Digg數據集上種集大小對運行時間的影響

Fig. 13 Running time vs seeds number in Last.fm dataset圖13 Last.fm數據集上種集大小對運行時間的影響
從實驗圖中可得出如下結論:LDegree算法的運行時間是最短的,由于該算法只是從整個網絡中選擇具有最大度的k個結點作為種集.ACG-TIIM算法和ACG-TIIM-UN算法的運行效率較為接近,ACG-TIIM算法在選擇種集之前需要學習新傳播項的主題分布,所以ACG-TIIM算法比ACG-TIIM-UN算法稍慢.但是ACG-TIIM算法比CELF-Gre算法快2個數量級,這是因為ACG-TIIM算法在選擇種集之前,先生成候選結點,僅對候選結點進行蒙特卡洛模擬估計影響范圍.候選結點數要遠遠小于所有結點數,所以ACG-TIIM算法效率比CELF-Gre算法高很多,這與4.2節算法復雜性分析結果基本一致.
在IC模型和TIC模型下,我們也運行了上述對比算法,ACG-TIIM算法效率遠遠優于CELF-Gre算法.
6 結束語
本文提出了基于用戶興趣和傳播項主題分布的傳播模型TI-IC,并給出了基于TI-IC模型的影響最大化算法ACG-TIIM.實驗結果表明,本文提出的模型TI-IC在多個測試指標上都優于現有的模型,能更準確地預測傳播結果.ACG-TIIM算法可高效求解TI-IC模型的影響最大化問題,而且ACG-TIIM算法也適用于IC模型和TIC模型上的影響最大化問題.
未來的研究工作擬對用戶的興趣分布和用戶之間的影響進行聯合建模,希望能獲得更有效的社交網傳播模型.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·八年級物理人教版(2022年3期)2022-03-16 05:55:08
當代陜西(2021年2期)2021-03-29 07:41:24
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
中國塑料(2016年3期)2016-06-15 20:30:00
商用汽車(2016年4期)2016-05-09 01:23:12
